| ʵϰ���������ˣ���Щ�о��ɹ����ܽᡣ���ڸ��Dz��ԵĻ�����������������ģ�����ֱ�Ӵ��о��Աȿ�ʼ���ɡ���Ϊ����̫�࣬��ʼ֮ǰ�ȸ���Ŀ¼��
��1�����Dz��Թ��ߵļ�Ҫ�Ա�
��2��LINUX�¹���GCOV��ʵ��ԭ��
��3��LINUX�¹���GCOV��ʹ��˵��
��4�� WINDOWS�¹���coverage validatorԭ����ʹ��˵��
��5����GCOV�����ڷֲ�ʽ���Ը�����ͳ��ԭ���뷽��
�����Dz���C++ code coverage tool ��һ�����ԵĶԱȱ��������ص��о���GCOV,COVTOOL,coverage
validator��������ʱ��Ļ�������������ص��о���XCOVER. ��Щ����û�о����о�������Ȥ�Ļ������Բ鿴��Ӧ���ӡ�
| �� |
Free orcommercial |
Platform/complier |
Coverage level |
Show Execute counters |
Easy to use |
output |
Useable in large |
implement |
others |
|
gcov |
Free |
Linux ,only gcc |
Decision coverage |
Yes |
yes |
HTML report |
No |
Instrument as compiling |
nonsupport shared library |
|
COVTOOL |
Free |
linux |
Line |
boolean |
no |
Merge.db, ASCII report |
yes |
Instrument as compiling |
Nonsupport thread |
| xcover |
Free |
platform-independent
library, gcc4.3+ |
Line coverage |
Yes |
no |
HTML report |
? |
Source file only,denpend
on stlsoft |
Written in c |
|
GCT |
Free |
Unix,linux,Only
for c |
Branch/condition |
no |
yes |
No HTML |
yes |
Instrument as compiling |
Only for c,work well with
if,case,for |
| Coverage validator |
Commercial |
Windows |
decision |
yes |
yes |
HTML,XML, |
yes |
No recompile,With pdb
file |
Powerful filters,do not
affect performance |
|
BullseyeCoverage |
Commercial |
Windows,unix, |
Branch/condition |
no |
yes |
Csv report,Easy to change
to perl |
yes |
hook |
Work well with vc,cppunit |
| Pure coverage |
Commercial |
Unix,windows |
decision |
yes |
yes |
HTML,XML, |
yes |
Object Code Insertion |
Work well with Purify |
GCOV ʵ��ԭ��
1����������
GCOV��һ��GNU�ı��ظ��Dz��Թ���, ����GCC���������GCC��ͬʵ�ֶ�C����C++�ļ�����串�Ǻͷ�֧���Dz��ԡ���һ�������з�ʽ�Ŀ���̨������Ҫ��������֧�֡�
LCOV�� IBM �������� Linux Test Project ά���Ŀ���Դ���빤�ߡ���GCOV���չ�ֵ�һ��ǰ�ˡ����������һ�鹹���ڻ����ı���GCOV
���֮�ϵ� PERL �ű����ɣ���ʵ�ֻ��� HTML �����, ������һ�������� HTML ����������������ʰٷֱȡ�ͼ���Լ�����ҳ�����Կ���������������ݡ�֧�ִ���Ŀ���ṩ���ֵȼ���ͼ���ֱ�ΪĿ¼��ͼ���ļ���ͼ��Դ������ͼ��
2��GCOV����
2.1 ��������
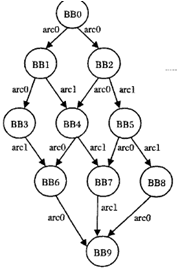
1�� ������BB
���һ�γ���ĵ�һ����䱻ִ�й�һ�Σ���γ����е�ÿһ����Ҫִ��һ�Σ���Ϊ�����顣һ��BB�е���������ִ�д���һ������ͬ�ġ�һ���ɶ��˳��ִ������߸�һ����ת�����ɡ�����һ�������BB�����һ�����һ����һ����ת��䣬��ת��Ŀ�ĵ�������һ��BB�ĵ�һ����䣬�����תʱ�������ģ��Ͳ����˷�֧����BB��������BB��ΪĿ�ĵء�
��ͼ�Ǹ����͵Ļ����飺
2����תARC
��һ��BB������һ��BB����ת����һ��arc,Ҫ��֪�������е�ÿ�����ͷ�֧��ִ�д������ͱ���֪��ÿ��BB��ARC��ִ�д���
3. ������ͼ
�����BB��Ϊһ���ڵ㣬����һ�������е�����BB������һ������ͼ��,Ҫ��֪�������е�ÿ�����ͷ�֧��ִ�д������ͱ���֪��ÿ��BB��ARC��ִ�д���������ͼ�ۿ���֪������ͼ��BB����Ⱥͳ�������ͬ�ģ�����ֻҪ֪���˲��ֵ�BB����arc��С���Ϳ����ƶ����еĴ�С��
����ѡ����arc��ִ�д������ƶ�BB��ִ�д�����
���ԶԲ��� ARC����ֻҪ�������ͳ�Ƴ������е�BB��ARC��ִ�д������ɡ�
���������ij�������ij�����ͼ��
2.2 GCOVԭ����ʵ��
2.2.1ԭ�����
GCOV��һ���������ĸ��Dz��Թ��ߣ���������Ԥ���������ͱ����Ŀ���ļ�����������GCCһ����ɡ�GCOV����ֻ�������ݴ����ͽ����ʾ����ͼ��GCOV�Ĺ���ԭ����
gcov����ԭ��
����ͼ���Կ�����GCOVͳ�Ƹ�������Ҫ���������Σ�

l �����
�������ѡ��gcc �Co hello �Cfprofile-arcs �Cftest-coverage
hello
����Ϊÿ��C�ļ�����*.oĿ���ļ����Ҫ���������ļ�*.bb��*.bbg(�����ڵ�GCC�汾���ǰ����������ļ������ڱ��*.gcno�ļ��������ڲ���Ȼ�����������ļ��Ľṹ)���ֱ��¼����Ϣ�ͳ�����ͼ��Ϣ����GCOV���㸲����ʱ�á�
l �����ռ�����ȡ�Σ�
./hello ִ��ʱ�ռ����ݡ�
����������к�Ϊÿ��Դ�ļ�����һ��*.da�����ļ������ڱ�������Ϊ.gcda�ļ����ֱ��¼��*.c�ļ��г����ִ�������
l �����γɽΣ�
gcov �Ca hello.c �ռ�ij��Դ�ļ��ĸ��������
ִ�к����������ļ�����������������ض��浽ij���ļ��У�ͬʱ����hello.c.gcov��ʽ���ļ����ļ���ʽ�Ǵ��б�ʾ��Ϣ��Դ�ļ���
���ұ�ͼ���Կ�����GCOV�IJ�ʱ�Σ����ڱ������ɣ�
��������ļ����Ⱦ�������Ԥ������Ȼ�����ɻ���ļ��������ɻ���ļ���ͬʱ��ɲ������������ɻ���ļ��Ľ���ɵģ���˲��ǻ��ʱ��IJ���ÿ�������3~4�������䣬ֱ�Ӳ������ɵ�*.s�ļ��У�������ļ��������Ŀ���ļ����ڳ������й������㸺���ռ������ִ����Ϣ��
2.2.2 �������ռ�����
gcov��ʵ��Դ�ļ�������coverge.c, gcov.c, gcov-io.c,
libgcov.c, profile.c ��libgcc2.c�Լ����ǵ�ͷ�ļ������´Ӿ���������������۸������ռ��Ĺ��̡�
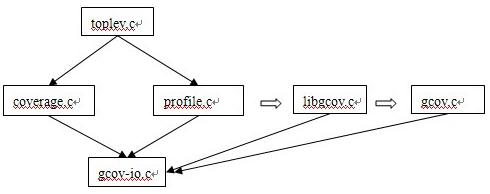
1�������
�ڱ���Σ���������Ӧ�ı���ѡ�����toplev.c�еĺ�������coverage.c��profile.c�еĺ�������Щ�����ֵ���gcov-io.c�еĺ���������coverage.c�е�build_gcov_info
����һЩ���ݽṹ��������gcov_init �� ͬʱprofile.c�ᴴ��������ͼ����profile.c�еĺ��������ij�����ͼ��ͬʱgcno�е�ÿ��arc�����insert_insn_on_edge����������counter.
2�������ռ���
�������ռ��Σ����ڳ�������ʱ�������libgcov.c�еĺ���������struct
gcov_info��count�ֶε���Ϣ���������˳�ʱ��gcov_exit�ᱻ���ã�����������ռ�����������Ϣд�뵽.gcda�ļ��С�
3�����ɱ����
���У�$gcov Դ�ļ�����Ͳ���������ļ���gcovҪ�����Ļ���Ҫ������.gcno��.gcda,.c�����ļ�,��ס�������һ��Ҫ��֤��.gcda������ʱ��������.gcnoҪһ�£�����˵��.gcda��.gcnoһ��Ҫ�����ġ�
gcov�ķ������̣�����.bbg��.bb����.gcno������
gcov��ȡ.bbg�еij�����ͼ��Ϣ����������Դ�ļ���ÿ�������ij�����ͼ
��ȡ.gcda��Ϣ������֪�Ļ�ִ�д������뵽������ͼ��
���ݽڵ���ȵ��ڳ��ȵ�ԭ������������Ļ���������ִ�д���
��ȡ.bb�ļ���������Ӧ��ϵ�����ÿ�д����ִ�д���
��Ӧ��֧�Ļ�����Ҫ�����֧����ʼλ��
���������
2.2.3 ������
����Ϊֹ������֪����
Gcc�������в�����ʲô�����Լ�gcov���������ʵĹ��̡�
������������:
a. gcc������������������
b. ��ʲôλ�ã�������ʲô�����أ�
1�� �������������
1�� ÿ��Դ�ļ���Ӧ�����飺
GCC�ڲ��Ĺ����л���Դ�ļ���ĩβ����һ����̬���飬BX2.������Ĵ�С�������Դ�ļ�����ĸ�����
BX2+0������0�����λ�ã�BX2+n������n�����λ�á�
�����ֵ�������ִ�д�����
2�� ÿ�����������䣺
�����ҵ��������Ļ�������inc$(BX2+n).
3�� BX2����������
Ϊ�˱���ͳ�ƣ�gcc��������Դ�ļ��е�BX2�������ӳ�һ����������������ṹ���ڲ���main����֮ǰ�Ͳ����ˣ��ڵ���main֮ǰ����һ�����ƹ��캯���ĺ��������й���������������������˳�ʱ����exit��������ִ�д�������.gcda�ļ���
2�� һЩ���ݽṹ�뺯������
1�� BX2���飺
ÿ��Դ�ļ���Ӧһ������¼ÿ�����ִ�д�����
2�� bb�ṹ��
��ΪҪ������Դ�ļ���BX2��֯����������ͳһ�����Ϊÿ��Դ�ļ�����һ��bb�ṹ���£�
struct bb
{
long zero_word; //�Ƿ��뵽������
const char *file_name; //��ǰ�������ļ���
long *count;//ָ��bx2��ָ��
long ncounts;//�����
struct bb *next;//��һ���ļ���BX2��Ϣ
};
3�� BX������
��BX2��֯������ͷָ��bb_head������Ԫ�ؽṹΪbb�ṹ������void
_bb_init_func(struct bb * block), ����ͷָ��bb_head������
4�� �����������̣�void _bb_init_func(struct
bb * block)
GCCΪ����Դ�ļ�������һ�����캯��_GLOBAL_$I$XXXGCOV()�Ķ��壬����XXXָ��ǰ�����ļ��еĵ�һ��ȫ�ֺ����ĺ����������ɣ��˺�����main��������֮ǰ��ͬ���캯��һ�𱻵��ã����ȫ�ֺ����Ĺ��ܾ��ǵ���_bb_init_func�������Ը��ļ���bb�ṹ����ʼ��ַΪ�������е��á�
�ú���������GCC�Դ��Ŀ��ļ�Libgcc.a�У�Դ��λ��gcc/libgcc2.c�У��������£�
void _bb_init_func(struct bb * blocks)
{
if(block->zero_word)//�Ѿ����Ӳ���
Return;
if(!bb_head)
ON_EXIT(_bb_exit_func,0);//�����˳�ʱ��д.gcda����
blocks->zero_word=0;
blocks->next=bb_head;//���뵽������
bb_head=blocks;
}
�ú������ȼ��bb�ṹ�Ƿ��뵽�����У�������أ����ż��bb�ṹ����ͷ�Ƿ�ʼ��������ע���˳�ʱִ�к���_bb_exit_func���ú�������bb���е�ÿ���ṹ��������.gcda�����ļ���
������main����֮ǰ�����е�bb�ṹ�������ӳ�һ��������
5��д�������ļ��Ĺ��̣�_bb_exit_func����
�ڱ�������������֮��ע���˳�ʱ��ִ�к���_bb_exit_func�������������������ͷ��ʼΪÿһ��bb�ṹ��ʼΪԴ�ļ�����.gcda�ļ���д����ļ���ʽ����BX2�������ݣ����Դ�bb�ṹ�е�BX2�ṹָ���ҵ���
���ˣ����������̾ͽ����ˡ� |


