| UML软件工程组织 | |||
| |
|||
|
|||
使用分析模块扩展 IBM Dump Analyzer for Java
2007-11-22 作者:Helen Beeken ,Toby Corbin
,Daniel Julin ,Julie Stalley,Martin Trotter 来源: IBM
在本系列的第一篇文章中,您了解到 IBM® Dump Analyzer for Java™ 工具可以针对格式化的系统转储执行分析并提供问题诊断建议。该工具的一个优点就是可以通过编写自己的分析模块对它进行功能扩展。本文将是介绍以 Java 为平台的 IBM 诊断工具系列文章的最后一篇,将向您展示如何构建分析程序以帮助您深入研究系统转储,并对 Java 代码进行调优。 本系列的第一篇文章 介绍了 IBM Dump Analyzer for Java(或者Dump Analyzer)。您已经了解了它的功能、如何获取以及运行方式。在开始这篇文章之前,您应该温习一下上一期的文章,确保您已经完全理解了 Dump Analyzer 的工作原理。 Dump Analyzer 工具的一个关键方面是它具有可扩展性。它是由一组分析模块 组成,每个模块负责对转储的一个特定方面进行分析,并帮助诊断特定类型的问题。本文将逐步说明如何编写新的分析模块以及如何在 Dump Analyzer 内部运行它。 概述Dump Analyzer 的构建基础是 Diagnostic Tooling Framework for Java(DTFJ),后者是 IBM 的 Java 平台实现的一部分。如果您想要编写一个 Dump Analyzer 分析模块,您应当熟悉 DTFJ(有关更多信息,请参阅 参考资料)。 Dump Analyzer 工具的目标就是提供一种已经基本构建完成的环境,供特定的分析模块在其中运行。首先,JVM 必须已经生成了系统转储并且使用 jextract 工具进行了格式化。Dump Analyzer 首先选择一个合适的映像工厂(将读取格式化后的转储),然后再读取文件来创建描述内存内容的 DTFJ Image 对象。随后为转储中的每个 Java 运行时构建独立的分析上下文。最后,选择一个特定分析模块在这些上下文中运行。 分析模块在运行时会访问全部的 Image,但它主要针对它所分析的特定 Java 运行时进行访问。此外,它将利用各种不同的工具来生成报告、报告进程和错误。也可以使用很多实用类来简化分析程序的编写。随着时间的推移,我们的团队期望在编写分析程序和分离有用基础架构时能够提供更多的实用类。 您可能需要构建三种类型的分析模块。第一种模块将运行并得出关于所分析的运行时内容的结论。结论类似于 “the JIT is active”、“there are deadlocks”、“this dump was caused by an application error” 或 “this dump contains WebSphere® classes”。第二种类型生成一个报告描述有关 分析程序(analyzer)指代任意类型的分析模块。 通常,第一种分析模块得出的结论将由另一种分析模块进一步进行检查,尝试诊断特定故障或提供推荐操作。最后,您应该能够生成类似如下内容的推荐操作:
这些类型的规则可以使用 Dump Analyzer 中附带的脚本语言编写。这种脚本代表了第三种类型的分析模块。Dump Analyzer 在设计时就考虑了简单性并且没有使用循环结构。在脚本内部,可以请求特定的分析操作并输出一些结论。这些脚本本身并没有实际执行分析,而是将其他分析模块在逻辑上链接起来。 设置无需执行任何特殊设置编写分析模块;访问需要的 JAR 文件即可。因此,本文假定您已经根据本系列第一篇文章(参阅 参考资料)中的说明通过 ISA 下载并安装了 Dump Analyzer。很多编程人员使用 IDE 进行开发。因此本文也详细说明了如何设置 Eclipse 环境(参阅 参考资料 中有关 Eclipse 的更多内容),使用它开发分析模块。当然,也可以使用其他的 IDE,但是本文主要针对 Eclipse。 要在 Eclipse 中开发分析模块,您需要执行以下操作:
可从 Eclipse 主页中的下载链接找到 Eclipse 下载说明。安装完成之后,切换到 Java Perspective(单击 Window > Open Perspective > Java)。在这个透视图中,按照以下步骤创建一个新的 Java 项目:
需要将四个 JAR 文件放入 AnalysisModule 项目的类路径:
在所有这些文件路径中,installDir 表示 ISA 的安装目录。(例如,Microsoft® Windows® 中的 ISA v3.1 的默认路径是 C:\Program Files\IBM\ISA and ESA\IBM Support Assistant)。要将这些 JAR 文件添加到 Eclipse 的类路径中,执行以下操作:
您应当在包内编写分析模块,要在 AnalysisModule 项目内创建包,执行以下操作:
现在,您已经为编写分析模块准备好了环境。 不同类型的分析程序在开始编写分析程序之前,您需要确定哪种类型的分析程序可以最好地满足您的需求。正如 “概述” 一节介绍的一样,这两种不同类型的分析程序的功能分别是:
这两种场景可以使用两种不同接口表示:分别是 IAnalyze 和 IReport(有关这两种接口的详细信息,请参阅 “接口” 一节或查找 Dump Analyzer 附带的 Javadoc 包)。 最后,您还需要了解一点,不论您需要编写何种类型,分析程序还必须实现一个接口:IAnalyzerBase(同样,参阅 “接口” 一节获得更多信息)。该接口提供所有分析程序都具备的常用功能。Dump Analyzer 提供了一个抽象的 AnalyzerBase 类;它包含很多有用的方法,因此您应该扩展 AnalyzerBase 而不是直接实现 IAnalyzerBase。 以下小节将展示如何创建这两种不同类型分析程序的示例。 实现 IAnalyze 的分析程序在 Eclipse 中创建实现 IAnalyze 接口的分析模块时,要使用 New Class 向导(右键单击在 设置 一节 中创建的包并选择 New > Class)。在出现的向导中,输入以下信息:
单击 Finish 即可使用 stub 方法创建 DWAnalyze 分析程序类。 要继续该示例,输入清单 1 所示的代码。这个简单的示例可以确定被分析的转储是否是在多处理器机器上创建的。 清单 1. 实现 IAnalyze 的分析程序
从上面的示例可以看到,必须实现两种方法: getShortDescription() 和 doAnalysis()。doAnalysis() 方法的目的是从转储中提取信息并以名称/值对的方式返回。这些信息将通过使用 AnalyzerBase(能够处理一些简单的分析规则)的默认行为进行进一步分析。针对名称/值对集使用各个规则并选择一个特定的名称对值进行检验。在清单 1 中,如果名称为 processorCount 的一项的值大于 1,规则处理结果将为真(true)。 要查看分析模块的运行,可跳至 “运行分析程序” 一节。 实现 IReport 的分析程序在创建实现 IReport 接口的分析模块时,可遵循上一节中介绍的新类创建步骤。但是,这一次应该在 New Class 向导中输入以下信息:
清单 2 中的代码演示了可以实现 IReport 接口的类。这个简单的示例将输出创建转储的机器的类型。这个类没有制定任何决策,它的惟一功能就是创建一个报告。将清单 2 中的内容输入新创建的 DWReport 类中,以继续本文的示例。 清单 2. 实现 IReport 的分析程序
从清单 2 中可以看出,必须实现两个方法:getShortDescription() 和 produceReport()。produceReport() 方法的目的是从转储中提取信息并以报告的方式返回,以便将其封装到 IAnalysisReport 对象中供稍后使用。报告对象将被发送到一个格式化程序中进行格式化以供查看。在清单 2 中,生成了一个简单的报告,可确定创建转储的系统的类型。 现在已了解了如何构建一个分析程序,您需要知道如何使用它实际分析一个 Java 应用程序。 运行分析程序有三种位置可以运行您的分析程序:在 IDE 内部、命令行和 IBM Support Assistant(ISA)。可以单独运行分析程序,也可以作为脚本的一部分运行(在 “SML:概述” 和 “使用 SML 将分析程序链接起来” 两节中会详细介绍后一种方法)。 同样,本文使用 Eclipse 演示分析模块在 IDE 中的运行。在 Eclipse 内运行 Dump Analyzer 的最简便方法是运行 DumpAnalyzer.main() 方法并传递需要进行分析的转储的完全限定名。为此,执行以下操作:
要从命令行运行分析程序,应首先将它们打包为一个 JAR 文件,名为 analyzers.jar。可使用两种方法完成,使用 jar 命令或在 Eclipse 中使用如下步骤:
要从命令行运行分析程序,需要将以下 JAR 文件添加到 boot 类路径:
此外,需要将以下 JAR 文件添加到类路径:
在本文的示例中,将这四个 JAR 文件从上面列出的位置复制到包含 analyzers.jar 包的目录中。运行分析程序的命令格式为:
以下是用于 Windows 命令行示例:
这将产生如清单 3 所示的输出,其中显示 DWReport 分析程序判断出转储是由 Windows XP 生成的。Error Summary 显示转储中未发现错误。 清单 3. 脚本输出
要通过 ISA 运行自己的分析程序,需要将它们打包为一个 JAR 文件,称为 analyzers.jar ,并使用您的文件替换 installDir/plugins/com.ibm.java.diagnostics.dbda.isa_(version number)/WEB-INF/lib 中的同名文件。要创建 JAR 文件,执行上一节 “从命令行运行分析程序” 开始部分介绍的步骤。 要运行分析程序,需要将完全限定名添加到 ISA Dump Analyzer 视图的 Optional Parameters 文本字段中。图 1 显示了所需的可选参数以及 清单 1 运行 DWAnalyze 示例的输出: 图 1. 通过 ISA 运行 DWAnalyze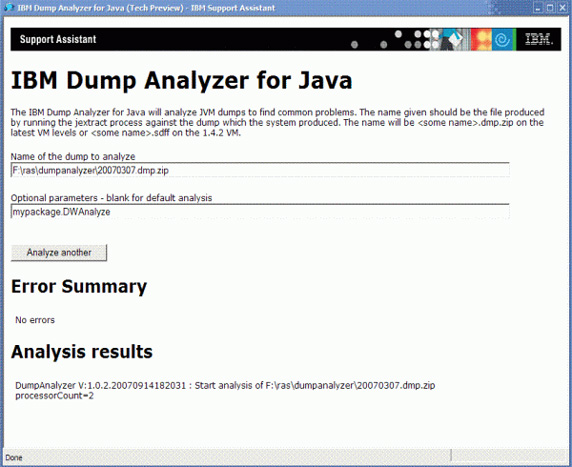
图 2 显示了所需的可选参数以及 清单 2 中运行 DWReport 示例的输出: 图 2. 通过 ISA 运行 DWReport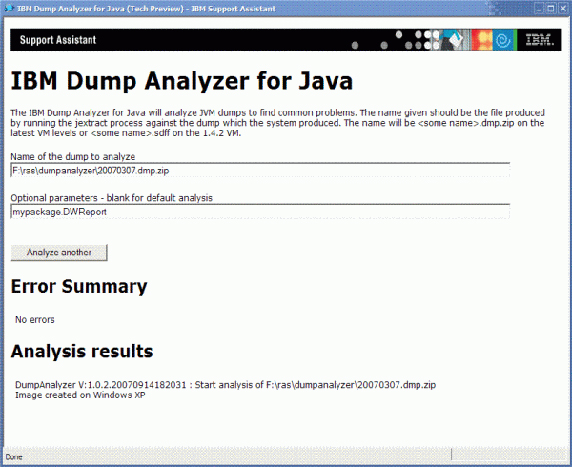
SML:概述可以使用 Java 语言编写所有四个分析模块,并在这在很多情况下都是一种适当的方法。然而,有时候您也许想避免 Java 语言的复杂性,而使用一些非常简单的脚本功能调用现有的分析程序。针对这些情况,我们的团队提供了一种基于状态机概念的语言,进入状态机之后会在各个状态之间移动,直到完成分析。我们将这种语言称为状态机语言(SML)。我们没有对 SML 使用任何循环结构并且进一步进行了限制:一个状态只能访问一次。目的是确保可以快速构建脚本并且避免发生无休止的重复分析。 SML 由以下关键字组成:
|
|
从清单 4 的注释可以看出,示例脚本运行 DWAnalyze 类包含的 isMultiProcessor
规则并根据结果输出相应的消息。随后又运行 DWReport 分析程序。
要使用该脚本运行您的分析程序,只需将脚本名作为运行时参数传递。和 “运行分析程序”
一节一样,您将依次了解运行新脚本的每个可能的运行时环境。
要在 Eclipse 中运行脚本,首先执行 “在
Eclipse 中运行分析程序” 中描述的所有 步骤。当为分析程序创建好运行时配置后,执行以下操作:
打开运行时配置(单击 Run > Open Run Dialog)。选择 Java Application 下的项目条目。单击 Arguments 选项卡。将 script.sml 的完全限定路径添加到 Program Arguments 部分,排在要进行分析的经过 jextract 的转储的完全限定名之后。单击 Run。
像以前一样,结果输出被发送到 Eclipse Console 视图。清单 5 显示了一个示例:
清单 5. Eclipse 中的脚本输出
|
要在命令行中运行脚本,需要将以下内容添加到在 “从命令行运行分析程序”
小节运行的命令中:
|
该命令将在您指定的目录中查找名为 script.sml 的脚本。输出类似于 清单
5。
要在 ISA 中运行脚本,执行 “在
ISA 中运行分析程序” 中的步骤,确保您的分析程序位于正确目录下名为 analyzers.jar 的 JAR 文件中。之后,启动
ISA 并查找希望进行分析的转储文件。最后,将如下内容添加到 Optional Parameters 文本框:
|
像之前一样,单击 Estimate Time 和 Analyze。ISA
窗口显示脚本运行结果。同样,输出内容类似于 清单 5。
接口
编写分析模块只涉及几个接口。本节将介绍这部分内容。
com.ibm.dtfj.analyzer.ext.IAnalyzerBase
所有分析程序必须实现 com.ibm.dtfj.analyzer.ext.IAnalyzerBase。这个接口定义了一些所有分析程序都应具备的常见属性和属性访问方法:
getName() 返回分析程序的惟一名称。getVersion() 返回分析程序的版本信息。getShortDescription() 返回一行对分析程序的描述,在显示分析程序列表时使用。getLongDescription() 返回对分析程序的更长的描述,用于帮助信息。setContext(IAnalyzerContext) 为分析程序设置上下文。分析程序必须实现该接口并保存应返回给 getContext() 的上下文。getContext() 返回与分析程序相关的上下文(参见下面的 IAnalyzerContext)。如果为主分析程序(primary analyzer),isPrimaryAnalyzer() 返回 true;就是说,与被嵌入到其他分析程序中不同,主分析程序指从工具的最顶层调用的分析程序。
com.ibm.dtfj.analyzer.ext.IAnalyze
如果分析程序的目的是对转储执行分析并根据分析得出结论,它应该实现 com.ibm.dtfj.analyzer.ext.IAnalyze。这种分析程序是由一组用户定义的规则(一个或多个)和一些分析组成,分析以名称/值对的形式生成输出。然后将输出与规则进行比较,得出结论。这种分析被划分为多个阶段,因此控制环境(例如脚本或分析程序)可以在进行分析时作出决策:
doAnalysis() 是第一个阶段。它以名称/值对的形式生成结果。analyzeResponse() 接受 doAnalysis() 生成的输出并对其应用规则以得出结论。结论以 true 或 false 表示。produceReport() 接受由 doAnalysis() 生成的输出,应用特定的规则,并以报告的形式描述结论。listRules() 生成一个规则列表,分析程序可以进行计算。
com.ibm.dtfj.analyzer.ext.IReport
分析程序可以实现 com.ibm.dtfj.analyzer.ext.IReport
接口,使用它将生成的关键信息创建为人类可读的报告。这个报告可能包含有关转储的信息或发现的问题。报告被设计为可以简单地生成多个格式的最终输出,例如
HTML、XML、原始文本等等。
produceReport() 生成一个报告(使用 allocateReport())并添加相关信息。
com.ibm.dtfj.analyzer.base.AnalyzerBase
要简化分析程序的实现,抽象基类 com.ibm.dtfj.analyzer.base.AnalyzerBase
提供了 IAnalyzerBase 的大多数方法的默认实现。您需要提供 getShortDescription() 的实现并且可能需要重写
getVersion() 和 isPrimaryAnalyzer()。该类还提供了一些实用方法,目的是简化 IAnalyze 接口的实现。
com.ibm.dtfj.analyzer.ext.IAnalyzerContext
com.ibm.dtfj.analyzer.ext.IAnalyzerContext
接口定义由工具的基础架构提供的常见函数,所有分析程序都可以使用这些函数。其中包括可以在分析过程中获得 Java 运行时的功能。每个分析程序需要通过
IAnalyzerBase 的 getContext() 方法返回的上下文对象访问这些函数:
getCurrentJavaRuntime() 返回对 DTFJ JavaRuntime 对象的引用,后者表示当前进行分析的 JVM 运行时。loadAnalyzer() 返回对另一个分析程序的引用,根据其类名指定。outputMessage() 向用户输出一条消息。addError() 添加一条错误,将在完成分析后输出到摘要中。allocateReport() 分配一个新的报告,方便分析程序添加内容。notifyAnalysisProgress() 为用户提供有关分析过程的反馈。如果分析需要占用大量时间,您可能需要使用这种方法。
com.ibm.dtfj.analyzer.ext.IAnalysisReport
com.ibm.dtfj.analyzer.ext.IAnalysisReport
接口定义报告创建功能,允许将分析程序生成的输出轻松转换为多种不同格式。接口提供了大量方法,但是其中一些示例就能够说明这种功能:
startSection() 启用一个新的格式化区域,可能包含标题和不同的格式化规则。printField() 通常用于输出字段的名称和内容。字段布局由格式化确定。printLiteral() 用于输出报告中的文字文本。printReport() 包含当前报告中的嵌入报告。endSection() 终止当前的格式化区域。
转储结构:概述
使用 ImageFactory 读取 jextract 化的转储后将产生 DTFJ
Image,本节将介绍其中的一些主要类。当然,最主要的类是 Image 本身,它表示整个转储。它提供了很多属性,例如对转储进行描述的
hostname;它还包含了一组 ImageAddressSpace 对象。通常,转储中只有一个地址空间,但有些环境允许多个地址空间。在地址空间内,您可以找到一个或多个
ImageProcess 对象,其中一个可能就是当前的对象。
通常,名称以 Image 开头的类表示该类不是特定于 Java 平台的;因此,在
ImageProcess 内,可以迭代一组 ImageModule,表示进程中加载的库,还可以迭代一组 ImageThread
,表示进程中活动的本地线程。ImageThread 返回对 ImageRegister 集合的迭代器,它提供对注册器当前值的访问。最后,ImagePointer
表示地址空间中一个特定的内存位置,通常用于惟一地识别某些对象。再回到 ImageProcess,您可以迭代很多独立的 ManagedRuntime
对象,这些对象定义了运行时的最常见形式。对于要分析的大多数转储,您需要找到一个运行时,这个运行时将是 JavaRuntime;这是
ManagedRuntime 的具体化形式。
找到 JavaRuntime 对象后,可以在转储的时候检查 JVM 的关键状态。因此,可以迭代
JavaClassLoader、JavaThread、JavaMonitor 和 JavaHeap(可能有多个 JavaHeap)。还可以对经过
JIT 编译的方法进行迭代。从 JavaClassLoader 中,可以迭代一组经过定义和缓存的类,从而进一步迭代方法和字段。在
JavaHeap 中,可以迭代堆内的所有对象,然后反映到对象字段值中。通过这些操作,您可以编写分析代码,详细地检查转储中表示的状态,然后得出结论确定状态是否有效。
实用类
在 DTFJ 映像中操作对象时,可以通过利用 Dump Analyzer 中附带的实用类简化某些常见操作。随时间推移,这些类的数量将逐渐增多,但是目前,一些类的目的就是简化
Iterator 和 Vector 的使用。
DTFJIterator 类接受由 DTFJ 返回的 Iterator 并在内部处理所有
CorruptData 对象,因此分析程序就不需要再进行处理。对象能够被容易地记录、而且对象数量会被统计和限制,这样一来,当转储被严重破坏,就不会强制分析程序处理长期运行的被破坏的对象。方法与
Iterator 中的一样,不过 getCorruptObjectCount() 将返回经过迭代器处理的被破坏对象的数量。
DTFJSortedIterator 类对 DTFJIterator 的功能进行扩展,将根据由对象类型确定的次序对返回的对象进行排序。例如,线程将按照名称顺序排序,而对象则按照地址顺序排序。该接口与
DTFJIterator 使用的接口完全相同。
SimpleVector 通过提供与 Vector 类相似的功能简化了对对象数组的处理:
addObject() 在第一个空槽中添加给定对象。addObjectOrExtend() 在第一个空槽中添加给定对象或扩展向量。deleteObject() 从向量的任何槽中删除对象。deleteObjectAndCompress() 从向量的任何槽中删除对象并将空槽 压缩到初始状态。toString() 将以 [item1,item2] 的形式输出向量。
实用分析程序
除了加载和执行分析程序的基本架构外,Dump Analyzer 还提供了一个实用工具库,可以简化较复杂分析程序的实现。这些实用程序是由经过预定义的特定分析程序提供。
这个实用工具库在不断增长,因为我们的团队一直在挑选新的通用函数,它们可以实现很多分析程序。本节描述了一些目前极为常用的实用工具。
ObjectFinder 对 JVM 运行时进行全面扫描,找出特定类型对象的所有实例,然后再由其他分析程序进行检查。ObjectFinder
将构建一个缓存,因此,即使多个不同的分析程序连续请求不同类型对象的实例,JVM 也只需执行一次扫描。下面展示了一些关键的函数:
findObjects() 返回一个向量,列出了在所分析的 JVM 运行时中找到的给定类的所有实例。
getObjectCount() 返回在所分析的 JVM 运行时中找到的给定类的实例数量。
produceReport() 生成一个报告,其中列出了在 JVM 运行时中找到的每个类的实例数量。
ClassFinder 分析程序对 JVM 进行全面扫描,找到当前加载的所有 Java
类,然后再由其他分析程序进行检查。ClassFinder 构建缓存,因此即使多个不同的分析程序连续请求不同的类,JVM 运行时也只需进行一次扫描。下面列出了关键的函数:
findClasses() 返回一个向量,列出了在所分析的 JVM 运行时中找到的具有给定类名的所有类定义。注意,如果运行时中具有多个类加载器,那么一个类名可能具有多个类定义。
produceReport() 生成一个报告,列出了 JVM 运行时中当前定义的所有类。
ObjectNavigatorCollection 分析程序表示 JVM 运行时中给定类的一组实例,从
ObjectFinder 获得。其中的关键函数包括:
getObjectNavigator() 返回一个 ObjectNavigator 分析程序,从 ObjectNavigatorCollection 提供的实例列表中封装对象的一个特定实例。
getObjectsCount() 返回由 ObjectNavigatorCollection 封装的对象实例的数量。
ObjectNavigator 分析程序表示 JVM 运行时中给定类的某种特定实例,并提供访问和输出对象实例字段的功能。其中的关键函数包括:
getFieldValueAtPath() 返回 ObjectNavigator 表示的对象实例的给定字段值,或者返回其他一些对象的字段值,这些对象的字段引用了第一个对象的字段,使用类似 field1/field2/field3/... 的路径表示printFieldValueAtPath() 输出 ObjectNavigator 表示的对象实例的给定字段值,或者其他一些对象的字段值,这些对象的字段引用了第一个对象的字段。
您还访问了一组包装器类分析程序,每个分析程序包含了一些必要的函数,可以解释和提取所分析的
JVM 运行时中给定类型对象的内容。它们包括:
VectorWrapper:提取 JVM 运行时中找到的 java.util.Vector 实例的内容。HashMapWrapper:提取 JVM 运行时中找到的 java.util.HashMap 实例的内容。PropertiesWrapper:提取 JVM 运行时中找到的 java.util.Properties 实例的内容。ThreadLocalWrapper:提取 JVM 运行时中找到的 java.lang.ThreadLocal 实例的内容。
结束语
现在,您已经了解了所有必需的知识,可以使用它们编写自己的分析模块并对转储文件诊断问题。如果出现任何问题,请与本文任一位作者联系,寻求帮助。我们希望您能够成功地编写出自己的分析程序并尽可解决遇到的问题。
本文是系列文章的最后一篇。这四篇文章向您展示了如何使用 IBM Dump Analyzer
for Java 对经过 jextract 的系统转储诊断问题、如何使用 Extensible Verbose Toolkit
显示详细的垃圾收集日志,以及如何使用 IBM Lock Analyzer for Java 分析性能问题。我们希望您能够使用这些工具解决
Java 应用程序中的问题并提升性能。
参考资料
学习 您可以参阅本文在 developerWorks 全球站点上的 英文原文 。-
Java 诊断,IBM 风格 :阅读本系列的所有文章。 “Java 技术,IBM 风格: 监视和判断问题”(Chris Bailey 和 Simon Rowland,developerWorks,2006 年 6 月):这篇文章详细介绍了 IBM 跟踪和转储引擎的信息,并介绍了 Diagnostic Toolkit 和 Framework for Java (DTFJ) API。-
诊断指南 1.4.2:提供 IBM 有关 1.4.2 版 Java 平台实现的功能诊断信息。 -
诊断指南 5.0:提供 IBM 有关 5.0 版 Java 平台实现的功能诊断信息。 -
Java 技术运行时:获得 IBM 有关 Java 平台实现的支持。
获得产品和技术 -
IBM Support Assistant:下载 ISA 并开始调整当前的 Java 应用程序。还可以查找有关在 ISA 中 安装产品插件 的信息。 -
IBM Developer Kits for the Java Platform:从此页下载用于 AIX®、Linux 和 z/OS® 的 SDK 以及其他面向 Java 技术的 IBM 开发人员工具包。 Eclipse:了解有关这个开源 IDE 的更多信息。
讨论 -
IBM SDKs and Runtimes:访问该论坛,讨论与 IBM Developer Kits for the Java Platform 有关的问题。
组织简介 | 联系我们 | Copyright 2002 ® UML软件工程组织 京ICP备10020922号 京公海网安备110108001071号 |