| UML����������֯ | |||
| |
|||
|
|||
�����������塪���ڶ����� ִ��ƪ
���ߣ������� ������CSDN
ִ��ƪ��Ȼ���Ƕ���Ϊ����Ч�IJ��Լƻ���ָ������������ơ�����ִ�е�ָ�����ļ����dzɹ����Ե�ǰ��ͱ�Ҫ������������������Dz��Թ����ĺ��ģ����������ijɹ�����Ѿ������һ��IJ��������Dz��Ե�ִ���ǻ������Dz��Լƻ��Ͳ�������ʵ�ֵĻ������ϸ�IJ���ִ��ʹ���Թ��������;���ϡ����ң�����ִ�еĹ�����Ը���Щ������������ִ�н��У�������Ҫ���һϵ�����⣬�磺
Ҫʵ������Ŀ�꣬�õ�һ����ʵ������Ҫ���ִ�й��̣���Ҫ�ܺõ�ȫ�̸��ٲ��Թ��̡����̶�������������Ч�IJ��Թ���ϵͳ����ʵ�֡���Ҫ�ķ����ʹ�ʩ�У�
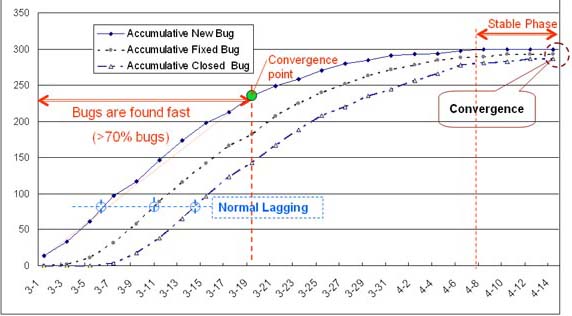
��Ŀ�Ľ��ȹ�����һ����������һ����̬�Ĺ��̣���Ҫ���ϵ��ȡ�Э������֤��Ŀ�ľ��ⷢչ��ʵ����Ŀ����Ķ�̬ƽ�⡣��Ŀ��ʼǰ�ļƻ���������IJ���������һ���������ʶ������Ȳ��������ȱ�����ֻ��һ��ʱ���ϵĿ�ܣ�����һ���̶����ǿ��ƻ��ƶ��ߵľ��������յġ�����ʱ������ơ����ԵIJ������룬��������н�һ������ʶ���Ժܶ����ⶼ����ͣ���ڱȽϴֵĹ����ϣ���Ŀ���ȱ�����Խ��Խ��ϸ��Խȷ�� ��Ŀ�Ľ��ȹ�����Ҫͨ����̱����ؼ�·���Ŀ��Ʋ�����������ʵ�֣�ͬʱҪ���պý������������ɱ��Ĺ�ϵ���Լ�����˽���ȵ�������������˫�����ԡ� 1�����ȵ�������������˫������ �κ�һ������ʼ���Ǻ����������ȣ��ͱ���Ƿ��ӣ������У��仯�Ǻ����Եġ�����Խ�����������Ľ���Խ��Խ�����ԡ���������Ҳ����ˣ���ʼ����֮����Bug�Ƚ������֣������ԵĽ�չ�����ǰ�Bug������������ģ�Խ�����棬BugԽ��Խ�ѷ��֡�Ҫ��߲��Խ��ȵ������������صġ��ؼ��������ڵ�һʱ�䷢�ֳ����������Ų�����������ʹ�ÿ�����ԱҪ�Դ��������ģ�ı䶯������֤���Ե�ʱ�䣬�Ӷ�Ӱ������������������Dz�����Ŀ���ȵ�������������˫�����ԣ������ڹ�ע���ȵ�ͬʱҪ���պ����������ԣ���ע�ؽ����ٶȵ�ͬʱ����Ҫ������ǰ�ڵ������� 2�����Խ��ȵĹ������� ���ȣ�����������ʷ���ݣ�����ǰ��ɹ�����Ŀ��������ȷ�������ȷ�������ͽ��������ڵ�ij��������ϵ�������ƽ��Ⱥ������������Բ��öԽ��ȹ����ƻ��������������ķ�����Ҳ����ͨ�������������Ⱥ������Ĺ�ϵ�� ��Σ����Բ��ò�����Ŀ���ȵĶ������������Խ���S���߷���ȱ�ݸ������߷����ڽ���ѹ��֮�£���ѹ����ʱ��ͨ���Dz���ʱ�䣬���ʵ�ʵĽ�������ʱ������ƣ�������ƶ��ļƻ����Խ��ԽԶ�������������ʽ�Ķ�����������������ͺ��ѳ��֣���Ϊ�������֮ǰ���п��ܲ�ȡ���ж��� ����ȱ�ݵ�������������ȱ�ݱ���Ļ������֣�Ҳ�Dz�����Ա��һ�����������뿪��С�齻�����������õĻ��ᡣһ���õ���������Ҫʹ�üġ�ȷ�ġ�רҵ��������ץסȱ�ݵı��ʡ��������ͻ�ʹ��Ϣ�������壬���ܻ�������Ա��ȷ��������ȱ���Ƿdz���Ҫ�ģ���Ϊ��
�ڶ���ʵ���Ļ����ϣ����ǻ����˽϶������ȱ�ݵ���Ч����������Ҫ�ǣ�
����ȱ��������ȱ�ݱ�ʶ��ȱ�����͡�ȱ�����س̶ȡ�ȱ�ݲ��������ԡ�ȱ�����ȼ���ȱ��״̬��ȱ����Դ��ȱ����Դ��ȱ��ԭ�� 1. ȱ�ݱ�ʶ���DZ��ij��ȱ�ݵ�Ψһ�ı�ʾ������ʹ��������ű�ʾ�� 2. ȱ�����ͣ��Ǹ���ȱ�ݵ���Ȼ���Ի���ȱ�����࣬���1��ʾ ��1����ȱ�������б�
3. ȱ�����س̶ȣ���ָ��ȱ������Ĺ��϶�������Ʒ��Ӱ��̶ȣ���ν�������ԡ���ָ�����ڲ��������£�һ��������ϵͳ�еľ���Ӱ�졣���2��ʾ ��2����ȱ�����صȼ��б�
4. ȱ�ݲ����Ŀ����ԣ�ָȱ���ڲ�Ʒ�з����Ŀ����ԣ�ͨ��������Ƶ������ʾ�����3��ʾ�� ��3 ȱ�ݲ����������б�
5. ȱ�����ȼ���ָȱ�ݱ��뱻���Ľ����̶ȡ������ȼ����ĺ���ץס������������û�п��ǵ���Ҫ�̶����أ����4��ʾ�� ��4 ����ȱ�����ȼ��б�
һ��������ȱ�����صȼ���ȱ�����ȼ�����Ժ�ǿ�����ǣ����е����ȼ��������ԵĴ����ǿ��ܵģ���֮��Ȼ�����磬��Ʒ�ձ�����Ҫ�ģ�һ������ʧ�ˣ�����ȱ�����û�����IJ�Ʒȱ�ݣ��������谭��Ʒ��������ô�������ȼ��ܸߵ�����ȱ�ݡ� 6. ȱ��״̬��ָȱ��ͨ��һ�����������̵Ľ�չ�����Ҳ�������������������е�״̬�������壬���5��ʾ�� ��5 ����ȱ��״̬�б�
7. ȱ����Դ��ָȱ�����ڵĵط������ĵ�������ȣ����6��ʾ�� ��6 ����ȱ����Դ�б�
8. ȱ�ݸ�Դ��ָ�����������ĸ������أ���Ѱ�������������̵ĸĽ�������ˮƽ����ߣ����7��ʾ�� ��7 ����ȱ�ݸ�Դ�б�
���Ը��Ƕ������Ǻ���������������ִ��״̬����Ҫ�ֶ�֮һ����ȷ�������Ƿ�ﵽ�����趨�IJ���������ɵı������Ը��������Dz��Ը��Ƕ�������һ�������ı�ʾ������һ��ͨ�������Ե�������Ʒ�����ܵ㡢�������������������е������м��㡣 �������Ը����ʳ��õļ��㹫ʽ��
����֮�⣬�����ʻ������า���ʡ����������ʡ�����鸲���ʵȣ���EMMA�� ������������˵�ᴩ�����������Թ��̣������ڲ���ÿ���ν���ǰ���У�Ҳ�����ڲ��Թ�����ijһ��ʱ����У�Ŀ��ֻ��һ������߲��Ը��Ƕȣ���֤���Ե�������ͨ�����ϵIJ��Ը��Ƕ���������Ը����ʼ��㣬��ʱ���ղ��Ե�ʵ��״������Ը��Ƕ�Ŀ��IJ�࣬��ʱ��ȡ��ʩ���Ϳ�����߲��Եĸ��Ƕȡ� ���Ը��Ƕȵ����������ڲ�ͬ�IJ��Խλ�ͬ�IJ��Է��������ڵ�Ԫ�����У����Ը������ǽ����ڱ����ԵĴ����С������֧�ͳ���·���ȵĶ���֮�ϣ�������������֤��Ҫ���������Ԫ���Եĸ�����Ҫ�ﵽ80��֮�ϡ��в��Է�����Ҫ�Գ�����䡢�ж���������������Ϻͣ�������·���ȸ��������������͵�Ԫ�������Ǻϵġ�����ϵͳ���ܲ����У����Թ��ܵ㡢�����������������ȸ������������� Ҫ��á���߲��Ը����ʣ�������Ҫ�������Թ��ߡ���������������Թ���Ϊ���� 1. EMMA EMMA ��һ�����ڼ��ͱ��� JAVA ���븲���ʵĿ�Դ���ߣ�֧�������ּ���ĸ�����ָ�꣺�����࣬���������飨basic block�����У��ر����ܲ��ijһ���Ƿ�ֻ�DZ����ָ��ǣ�����������·�������EMMA������ text��xml��html ����ʽ�ı��棬�����㲻ͬ�������� html �����ṩ���ϸ����ѯ���ܣ��ܹ��� package ��ʼһ�������ӵ���������ע��ij��������EMMA �ܺ� Makefile �� Ant ���ɣ�Ч�ʺܸߣ�����Ӧ���ڴ�����Ŀ�� EMMA ��ͨ���� .class �ļ��в����ֽ���ķ�ʽ�����ټ�¼�����д�����Ϣ�ġ�EMMA ֧������ģʽ��On the fly �� Offline ģʽ��On the fly ģʽ�����ص����м����ֽ��룬�൱���� EMMA ʵ�ֵ� application class loader ���ԭ���� application class loader��On the fly ģʽ�ȽϷ��㣬ȱ��Ҳ�Ƚ����ԣ��粻��Ϊ�� boot class loader ���ص������ɸ����ʱ��棬Ҳ����Ϊ�� J2EE ���������Լ��ж��� class loader �������ɸ����ʱ��档��ʱ������������ Offline ģʽ��Offline ģʽ�����౻����ǰ�������ֽ��롣EMMA Ҳ֧���������з�ʽ��Command line �� Ant�� 2. Rational PureCoverage PureCoverage ��һ������VC, VB ����Java �����IJ��Ը��dz̶ȼ���,�����Զ������������Ժ�δ�����Եķ�Χ����ÿһ�����Խ������꾡�IJ��Ը��dz̶ȱ��档PureCoverage ����һ���Ի������г�����Ӧ�ó���ģ�飬������Աֻ�����ÿ��Ӧ�ó������Ϳ��Լ����û��ڴ����л����Ĵ��븲�Ǽ��𡣲������Բ鿴ÿ�γ������е�ͼ�λ��������ݣ�������ֱ�ӵء�ʵʱ�ؿ��Ƹ������ݵļ�¼����������Ļ�����Ҫ�Ĺ���ģ�飬������ϸ���ռ��������ݣ������ڲ�̫��Ҫ��ģ�飬 ֻ�ռ��ϳ���ĸ������ݣ�����������Ա������Ч�ز��ԡ� ϵͳ�IJ��Ի�����ݲ���Ŀ�꣬����������һ�����Ը��Dz��Ի����ϣ������Dz��������в��Ը��Ƕȵ���Ч���������Dz�����
������������Ѿ���ȫ���࣬���������ĸ��Dz��Կ����������ɲ�����ȫ�̶����������ָ�ꡣ���磬����Ѿ�ȷ�����������ܲ���������������ò��Խ�����õ����⣬���Ѿ���ʵ��90�������ܲ���������֮�⣬������������������ϴ�Ҫ������������ ��ͬ�����dz���Ա�ijɹ�֮һ�����Ա�������������Dz�����Ա����Ҫ�ɹ�֮һ������һ���õIJ��Ա��棬�ǽ�������ȷ�ġ��㹻�IJ��Խ���Ļ���֮�ϣ�����Ҫ�ṩ��Ҫ�IJ��Խ����ʵ�����ݣ�ͬʱҪ�Խ�����з��������ֲ�Ʒ������ı��ʣ��Բ�Ʒ��������ȷ�������� 1��ȱ�ݷ��� ��ȱ�ݽ��з�����ȷ�������Ƿ�ﵽ�����ı���Ҳ�����ж������Ƿ��Ѵﵽ�û��ɽ��ܵ�״̬��������ȱ��ʱӦ����ȱ�ݷ����������ƶ��ķ���������õ�ȱ�ݷ��������У�
ͬʱ��Ҳ��������Ŀ���������ȱ�ݷ������ԸĽ������Ͳ��Խ��̣��磺
2����Ʒ������������ �Բ��ԵĽ���������������ɺͷ�����һ�������Excel�ļ������ݿ��һЩֱ��ͼ��Բ��ͼ������ͼ�������з����ͱ�ʾ����Ҫ�ķ����жԱȷ���������ԭ��Root Cause�����ҡ�������ࡢ���ƣ�ʱ�����У������ȡ�
���ԽεĹ��̶������ݻ���Ŀ�Ƚ϶࣬�����������Խ��ȡ����Ը��Ƕȡ�����ȱ�ݳ���/�������ߡ�����ȱ���ۻ����ߡ�����Ч�ʵȡ��ڽ��в��Թ��̶���ʱ��Ҫ����������ģ�������繦�ܵ㡢�����ȣ��������Զ�������Ŀ�����ȷ�������������ͬ�IJ���������������ԵĹ���״̬��
��ǰ���������Թ��̵Ķ������Խ�����״̬�������̽��������������������Dz��Թ��̶�������Ч�� �ڲ��ԽΣ���Ҫ�Ĺ������������У�
ȱ�ݶ����Dz��Խε���Ҫ�������ݣ�������Ʒȱ�ݶ�����ȱ�ݹ��̶�������Ʒȱ�ݶ���������һ������ϸ���ܣ������Ի������ȶ��Ի���Ч�Զ���������������Ч��һ������MTTF���������������潫���������������ݣ�������ȱ�ݵ���ģʽ��PTR����/��ѹģ�͡����������Ķ�������������IJ��Ը������������ڴ���IJ��Ը��������ȵȡ� 1. ����ʱ���ȱ�ݵ���ģʽ ��Ʒ��ȱ���ܶȡ����߲��Խε�ȱ������һ��������ָ�꣬ȱ�ݵ���ģʽ�����ṩ����Ĺ�����Ϣ����ʱ��ʹ�õ�������ȱ������һ���ģ���������������ܽϴ�ԭ�����ȱ�ݵ����ģʽ��һ����Խ���ȱ�ݵ���Խ�磬����Թ���������Խ�á������ǴӲ��Խ�չ�Ĺ۵㣬���Ǵ��û����·���(customer rediscoveries)�Ĺ۵�������ȱ�ݵĹ��̸����Ƿdz���Ҫ�ģ��������������������ȱ�ݽ��п�����ֹ���ԵĽ�չ��Ҳ��Ȼֱ��Ӱ��������Ʒ�����������ܡ� ��Բ�Ʒ����ʱ�䡢��һ���汾��ȱ��ˮƽ��˵�������ᱻ��Ŀ�����������ʵľ��ǣ�
�ش���Щ���⣬����ȱ�ݴﵽģʽҪʵ�ֵ�Ŀ�ꡣ���Եķ����Ƚ����ף������Ŷ�Խ���죬��ֵ�����Խ�磬��ʱ�����ڵ�һ��ĩ��ڶ��ܾ͵���ֵ�������ֵ����ֵȡ���ڴ���������������������������Ͳ���ִ�еIJ��ԡ�ˮƽ�ȣ���������£����Ը��ݻ��ߣ�����ʷ���ݣ��Ƶá���һ����ֵ�ﵽһ���Ͷ��ȶ���ˮƽ����Ҫ���ö��ʱ�䣬�����Ǵﵽ��ֵ���õ�ʱ���4-5�������ʱ��ȡ���ڷ�ֵ��ȱ���Ƴ�Ч�ʵȵȡ� 2. PTR�ۻ�ģ�� ���Ե�Ŀ�����ھ���ط�������ȱ�ݣ�ͨ�������������Ը���Ч������ط���������ȱ�ݣ�������ȱ��ͨ��PTR��������ٱ��棬Problem Tracking Report������������ˣ�PTR������һ���̶��ϴ�����������������ÿ��ȱ��/PTR����һ���������ڣ��Ӳ�����Ա�������Ⲣ�γɱ��棨��ΪPTR���֣�Ҳ��ȱ�ݵ��������/�����ԱҪ���֡��������PTR/ȱ�ݣ����������ύ����������PTR/ȱ�ݵ���������(New Build)�������飬������������õ���ֱ֤��������ͨ������Ϊֹ����ΪPTR�رգ������Թ������ض�ʱ��PTR���ֵ������������·��ֵ�PTR�رյ�PTR�IJ�ֵ������PTR�ۻ�/��ѹֵ��PTR���֣��ۻ�ģ�;��Ǹ���������ٱ�����������ݡ���ij��ʱ�䵥λ�ڵ�PTR����ֵ��ij��ʱ��PTR�ۻ�ֵ�����������������ֵ�ȱ�ݱ仯���̣���������Ʒ����״̬�ı仯���̡� 3��������������ȡ���������Ч�� ���������Dz���ִ�еĻ������������ĺû�ֱ�ӹ�ϵ�����Ե�������Ҳ��Ӱ�������������ı�֤���̡����������Ķ���������������������ȡ���������Ч�ԣ����Ұ����Զ����̶ȵĶ����������ٱ����IJ��������ѱ��Զ����ˡ� TCQ = �����������ֵ�ȱ������/�ܵ�ȱ������ ��Ϊ����һ����ȱ�ݿ���ͨ��ad-hoc ���ԣ���������ɵIJ��ԣ��������߲�(Work-through)��Fire-drill����(��������ѵ�����û�ѹ��/���ղ���)�������ֶη���ȱ�� 4������ִ�е�Ч�ʺ����� ����ִ�е�����һ�����������������������������ȱ�ݺ���ȱ�����ı�ֵ��������һ��Ҫ�����0.5%��Ҳ����ͨ�����ӹ�ʽ����Եȷ�������������ִ�е�Ч�ʿ��������м��ַ������ۺ϶�����
5��ȱ�ݱ�������� ȱ�ݱ���������������������Ա���������ķ���֮һ����ɲ�����ָ���У�
6����������IJ��Ը������� ��������IJ��Ը��������������ڶ���ִ��/���еIJ��������ĺ�ʵ�ͷ��������Ի�������IJ��Ը��������ת��Ϊ�����������������ʣ����Ե�Ŀ����ȷ��100%�IJ�������ȫ���ɹ���ִ�С�һ���ڲ��Լƻ��У��Ͷ����˲��ԵĹ��������������������Ͳ������������ʣ�98%-100%�������Ǹ�������ȷ���IJ����ճ̰��ţ����Խ����Լƻ�ֵ�������ߣ�Ȼ�����ʵ��ִ�н�������ڣ�ÿ���ÿ�ܣ�ȥ��ʵ��ֵ���ߣ��Ӷ����Խ��в���ȫ���̼�غ�Ԥ�⡣ ��ִ�в��Ի�У��������������������ֿɷ�Ϊ����������������ʹ��㣺
7�����ڴ���IJ��Ը������� ���ڴ���IJ��Ը��������ǶԱ����Եij��������䡢·���������ĸ����ʷ��������Ӧ�û��ڴ���ĸ��ǣ�����Բ����Ǹ��ݲ����Ѿ�ִ�е�Դ����Ķ�������ʾ�ġ����ֲ��Ը��Dz������Ͷ��ڰ�ȫ���ϵ�ϵͳ��˵�dz���Ҫ�� �������븲���ʣ���Ҫ�϶�����Ŀ�������ġ��ܵIJ��Դ����������ڲ���������ִ�еĴ�����������ٷֱȣ����˽����¼�ڲ������������С����Թ������Ѿ�ִ�еĴ���Ķ��٣���֮��Ե���Ҫִ�е�ʣ�����Ķ��١����븲�ǿ��Խ����ڿ���������䡢��֧��·�������������Ļ����ϡ����������ǵ�Ŀ���Dz��Դ����С���֧�����������е�·��������������������Ԫ�ء����������ǵ�Ŀ����ͨ������������������״̬�Ƿ���Ч�����磬����Ԫ����ʹ��֮ǰ�Ƿ��Ѿ����塣 ���ڴ���IJ��Ը���ͨ�����¹�ʽ���㣺��ִ�еIJ��Ը��� �� Tc��Tnc ����Tc���ô�����䡢������֧������·��������״̬�ж��������Ԫ������ʾ����ִ����Ŀ����Tnc��Total number of items in the code���Ǵ����е���Ŀ������ ������Ʒ������������������������Ҫ���֮һ��������Ķ�����������Ʒ������������ƽ��ʧЧʱ�䡢ȱ���ܶȡ������ԡ��ɿ��ԵȲ�Ʒ���������ԣ����ڶ�������Ʒ�������ۣ����ڴ˻���֮�ϲ����Ż���Ʒ��ơ���Ʒ����Ͳ�Ʒ���� ������Ʒ�������������������Ӷȡ��ͻ�����ȵĶ���������ƪ�����ޣ��ڴ���ȥ�� ������Ʒ��������������Ҫ����������ȱ�ݵĶ����������������������ֱ�ӵĹ�ϵ�� �����Ƿ�ӳ��������������̶ȵ�ָ�꣬��ȱ�ݱ���Ϊ������������һ�µ�ij�ֱ��֣�����ͨ���Բ��Թ����������ѷ��ֵ�ȱ�ݽ��������������˽�����������״����Ҳ����˵������ȱ������������������������Ҫ;��֮һ������ȱ������ָ����Կ���������������Ʒ��������Ҫָ�꣬����ȱ�ݷ���Ҳ��������������ǰ�����Ŀɿ��Ի�Ԥ��������Ʒ�Ŀɿ��Ա仯�� �������������ǽ������ߣ�Ϊ������Ʒ��������������������������㣬��������������ò��Ե�Ŀ�꣬��Ϊ��ϵͳ�����Ƿ�ͨ���ı���ȱ������Ļ����Ƕ�ijһ���ijһ��֯�Ľ����һ�ֶ��������ֽ�������dz����Ļ���͵ģ���10000��Դ����(LOC)�dz����ģ��һ������ÿһǧ�д�����3�������Dz����д������ʵĻ�����������ֵ�Ĺ����кܴ������Ŀ�������Ի������ڣ�Ҳ���Ƕ���ɽ�����Ϊ�Ļ������1��ʾ�� ��1ij��������Ŀ�����Ļ���Ŀ��
����ȱ�������ķ�����ԱȽ϶࣬�Ӽ�ȱ�ݼ������ϸ��ͳ�ƽ�ģ������ȱ�ݷ����IJ�Ʒ�����������������¼��֣�
1��ȱ���ܶ� Myers��һ�������������Ե������ķ�ֱ��ԭ���ڲ����з���ȱ�ݶ�ĵط������и����ȱ�ݽ��ᱻ���֡����ԭ���ԭ�����ڣ����ȱ�ݷ���ȱ�ݶ�ĵط���©����ȱ�ݿ�����Ҳ��Խ���߸������Dz���Ч��û�б���������֮ǰ����ô�ھ���ȱ��ʱ������϶�Ĵ�������ԭ������ѧ�������ȱ���ܶȵĶ�������ÿKLOC��ÿ�����ܵ㣨�����ƹ��ܵ�Ķ�����������㡢���ݵ㡢������ȣ���ȱ������ȱ���ܶ�Խ����ζ�Ų�Ʒ����Խ�ߡ�
2��ȱ���� ȱ���ʵ�ͨ�ø�����һ��ʱ�䷶Χ�ڵ�ȱ����������ʣ�OFE��opportunities for error���ı�ֵ��ǰ�������Ѿ����۹�����ȱ�ݺ�ʧ�ܵĶ��壬ʧ����ȱ�ݵ�ʵ�����������ù۲��ʧ�ܵIJ�ͬԭ����Ŀ�����ƹ��������е�ȱ����Ŀ�� ������Ʒȱ���ʣ���ʹ��һ���ض��IJ�Ʒ�����䷢����ͬʱ��Ҳ�Dz�ͬ�ġ����磬��Ӧ�������ĽǶ���˵��90%���ϵ�ȱ�����ڷ����������ڱ����ֳ��������Բ���ϵͳ��90%���ϵ�ȱ��ͨ���ڲ�Ʒ��������Ҫ�����ʱ����ܱ����ֳ����� 3������ȱ������� �����������뼸��������FΪ����������ģ�õĹ��ܵ㣻D1Ϊ���������������з��ֵ�����ȱ������D2Ϊ�����������ֵ�ȱ������DΪ���ֵ���ȱ��������ˣ�D=D1+D2�� ����һ��Ӧ��������Ŀ���������¼��㷽��ʽ���Ӳ�ͬ�ĽǶȹ�����������������
������100�����ܵ㣬��F=100�����ڿ��������з�����20�������ύ���ַ�����3��������D1 =20��D2 =3, D= D1+D2 =23
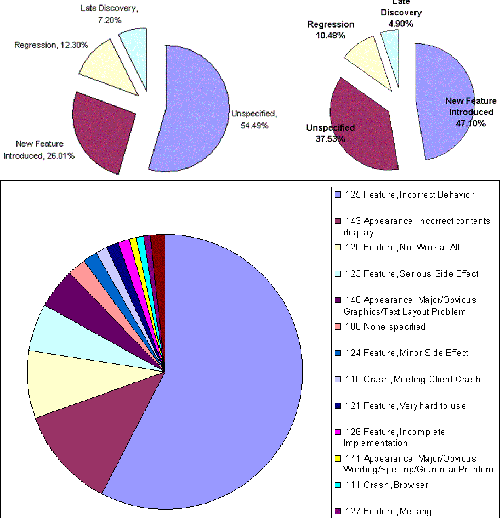
������ͳ�ƣ�������ƽ������ȱ�������Ŀǰֻ�ﵽ��Լ85%������һЩ�������õĹ��������̵�������������˾��������������Ʒ��ȱ������ʿ��Գ���98%�� ������֪���������ȱ�ݵ����׳̶��ڸ�����Ҳ�Dz�ͬ����������˵����������⼰����������������ģ����2��ʾ�� ��2 ��ͬȱ��Դ�����Ч��
��3��ӳ����CMM����ȼ������Ӱ�����������ģ���������Դ�������վ�1994��ί��SPR������һ�������ĵ��鹫˾�����е�һ���о����ӱ��п��Կ�����CMM����Խ�ߣ�ȱ�������ҲԽ�ߡ� ��3 SEI CMM����DZ��ȱ���������
4������ȱ������� ����ȱ��������Dz���ȱ���ܶȶ�������չ���������⣬��Ҫ����ٿ����������н��е�ȱ�ݣ������������������������顣��Ϊ���ȱ���еĺܴ�ٷֱ���ͬ��������йصģ�������ʽ���������֤����ǿǰ�ڹ��̵�ȱ������������ڼ��ٳ�����ע�롣���ڽε�ȱ�����ģ�ͷ�ӳ���������ܵ�ȱ����������� ��һ������ȱ�������Ч��(DRE��Defect Remove Efficiency)��DRE���Զ���Ϊ�� �����������ȱ����/��ƷDZ����ȱ������ x 100�� ��ΪDZ��ȱ�ݵ������Dz�֪���ģ�����ͨ��һЩ������������ֵ���羭������ӹ�ʽ������������ǰ�ڵĺ��ض��ε�ʱ��ʱDRE��Ӧ�ر���Ϊ����ȱ�������Ч�Ժͽ���Ч�ԣ��Ը����ε�DZ��ȱ���������Թ���Ϊ�� ��ǰ�ε�DZ��ȱ���� = ��ǰ���ų���ȱ�������Ժ��ֵ�ȱ���� �����ε�DRE����ֵԽ�ߣ���©����һ���ε�ȱ�ݾ�Խ�١� ȱ�����ڸ�����ע�뵽���Բ�Ʒ���߳ɹ���ȥ��ͨ����4 ��������ȱ��ע������������Ļ���������Ը��õ�����ȱ�������Ч�ԡ��ع�ȱ��������������ǰȱ��ʱ��������صġ��µ�ȱ�ݣ����Լ�ʹ�ڲ��ԽΣ�Ҳ������µ�ȱ�ݡ� �� 4 ��ȱ��ע������������Ļ
�����ȱ�������ڼ���ȱ������ȥ����ȷ������ȱ�������������ȷ������ȱ������ռ�ı����ܵͣ��������ݱ��������Խδ��Ϊ2�����������ȱ�����ͽ����ڼ���ȱ������ �����������塪���и�ϵ�У���Ҫ�����ˣ�������Ϊ������ǿ�ʼ�������ණ��Ҫѧ�������ණ��Ҫ������ȥ������̽�֣�������������������ϵ�ʹ��...... ���Ҫ�� �������������塰 ��һ���ܽ�Ļ���������һ�仰������������������һ�ŵصص�����ѧ�ʣ�ͬʱҲ��һ�������� ���Ե�ѧϰ��Ҳ�ǴӺ����ٴӱ�����������������������������������DzŻᷢ�֡��������е������ණ��Ҫѧ�� ˵����������ѧ�ʣ��� ��������ȫò ������Լ�һ�ߣ��羲������������
ͬʱ��Ҫ�˽��������Ե�һЩ�µļ������µ�ƽ̨�������в����µĿ�Դ���Թ�����Ҫ�˽⣬��Selenium/EMMA�ȣ����и�����Զ������Կ�ܣ���:
�Զ����ű�����Ҳ���ڲ��Ϸ�չ�������������(data-driven)��ؼ���������Keyword-driven����ʹ���Խű���ҵ������������action�������ݵõ����룬�����������ݺͽű�����ķ��롣 ��������ʼ�ոе���ѹ�����ǣ�����������չ�ܿ죬��������Ҫ������Ӧ�����ķ�չ�������漰���ԣ�ASP/PHP/Java, C++/C��, Ruby.. .) ��ƽ̨��OS + .NET, J2EE, ...) �ȱ仯�����漰ģʽ�������ͼ����ı仯������������OO, Object-Oriented�������IJ��ԣ�������(CO, Component-Oriented)��������(AO, Aspect-Oriented)���������ܹ���SOA��Service-oriented architecture��������SaaS(Software as a service, ����������) ���������ȵIJ��ԣ����ϴ��£���һ��Ҫ������ѧϰ����ѧϰ�� ����������Ϊ�����������˺ܶ�ı�֤ͳһ��ì���壺
��������ս���ǣ���Ч�ʺ����������л��ƽ�⣬�ڲ��Ϻͷ��ա���Ļ�����ϡ�����IJ����������Ƚ��в�������Ҫ��֤�شӶ���ӽ�ȥ�����������ϵ�˼���Ի�����˵IJ��Է����Ͳ��ԣ�����������TA��ʵ�֡���Ч�Ĺ������ﵽ���ǵ�����Ŀ�ꡣ �Ӳ�����Ա���˽���Ҫ���ϵ�ʵ������ǰ�ߴ����Ƕ���ʿ������ð취������Ҳ��һ�������Է���������������ơ����Խű����������Թ���ʹ�ú�ִ�еȣ�����Ҫ��ʵ����Ŀ���������Ҳ���������Ҫ�� �Ӳ����Ŷӽ�������Ҫ���Ͻ��� ���Եĸ��������ݡ����Գ����ģ�͡����ƽ��Ŷӵij��졢��չ��ʹ�ŶӲ���ӵ�в��Ը�������ļ����;��飬����Ҫ�γ�һ���ŵġ����ҸĽ��ġ�������ƵIJ�����ϵ������˼�롢���������ߺͻ�����ʩ�ȡ� Ҫ�Դ����һ��������һ���������ܽᣬ�����ٽ������д��һ��ϵͳ�ġ�ʵ�õġ��ְ��̴ֽ�������Եġ���ˮƽ����������ָ���顣Ŀǰ�����ں͵��ӹ�ҵ������IJ����ӵ㣨BroadView������������8-9�·������ʹ�Ҽ��档 |

��֯��� | ��ϵ���� | Copyright 2002 ® UML����������֯ ��ICP��10020922�� ������������110108001071�� |