| UML软件工程组织 | |||
| |
|||
|
|||
开发一个基于 JUnit 的存储过程自动化测试的 Eclipse 插件
作者:李嘉涛,张俊青,赵雄伟 出处:IBM
本文将以一个真实的项目为背景,从分析过去存储过程的测试方法中存在的问题入手,逐步阐述我们分析问题,寻找问题根源和寻求解决办法的过程,介绍我们开发这个基于 JUnit 的存储过程自动化测试的 Eclipse 插件的过程和存储过程单元测试的解决方案。 1 摘要存储过程的测试,是数据库开发人员经常要面临的任务,多数情况下这是一项繁琐、费时、又没有太多创新的工作。有没有办法改变这一现状呢?有没有可能实现快速、批量、自动化的存储过程测试呢? 本文将以一个真实的项目为背景,从分析过去存储过程的测试方法中存在的问题入手,逐步阐述我们分析问题,寻找问题根源和寻求解决办法的过程,介绍我们开发这个基于 JUnit 的存储过程自动化测试的 Eclipse 插件的过程和存储过程单元测试的解决方案。 开始之前,我们希望读者有以下基本知识,如果您没有接触过这些方面的技术,那也不要紧,我们在文章中对相关的技术做了简单的说明,以帮助您的理解。
2 一个真实的项目项目 A 是一个使用了 200 多个存储过程的 J2EE 电子商务应用项目,数据库系统是 DB2 V8.2,Web 应用程序采用 WSAD 5.1 开发。有 5 位程序员参与开发这些存储过程,并负责存储过程的单元测试和性能测试。在现有的技术条件下,通常我们是如何进行测试的呢? 首先,程序员会打开 DB2 的命令行窗口,连接到数据库,提交类似这样的命令: db2 call SP_QUERY('1','2',?) 程序员希望获得的测试结果包括:
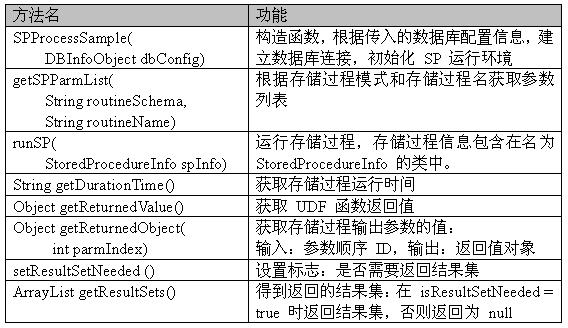
程序员通常会把命令窗口中的结果信息拷贝下来,存到一个文件里,以后可以分析或者比较用。有时候我们也使用类似 Rapid SQL 等图形化的工具来帮助我们做一些工作,但完成测试工作的工作量基本相当。在完成这些测试后,通常我们还需要根据测试的结果手工来完成测试报告。 这样的测试工作通常情况下不只做一次,例如有相关的存储过程、UDF、Table 或者其他所依赖的数据库对象更改之后,都需要重新验证这些更改所涉及到的存储过程。这也就意味着我们的程序员需要再次重复上面的工作,一个一个的验证每个存储过程,评测它们的性能,并最终形成所需的测试报告。就项目 A 的情况而言,按照每个程序员负责 40 个存储过程计算,整个开发周期平均下来,每个人每天都要花上大约 2 个小时的时间来做这些测试工作和测试报告。 尽管我们的程序员在开发过程中做了很多测试工作来保证存储过程的可用性、可靠性和高性能,但是在项目后期尤其是上生产系统后的回归测试中我们依然需要做类似的测试,来保证所有的存储过程在生产系统上运行正常,同时完成生产系统的性能测试报告。显而易见,很多工作不得不重复进行。 3 存在的问题这样大部分依靠手工进行的存储过程单元测试,有着如下一些问题: 1) 效率低下:程序员要花每天近 1/4 的时间来进行重复的测试工作,这段时间应该通过使用可重复的测试方式应该是可以缩短的。下图是在我们项目 A 中的一位程序员的平均时间分配图,可以看出单元测试和回归测试占用了他 40% 的工作量。 
2) 手工进行性能测试,测试结果不准确。 3) 无法重用,没有留下可供重用的工具或代码。 4) 无法进行自动化的回归测试。 5) 没有直观的测试结果,需要程序员自己整理测试结果并生成测试报告。 4 如何解决这些问题?既然进行存储过程单元测试的原始方式有如此多的问题,那我们该如何改进这种测试方式以解决这些问题呢。下面我们就来分析解决问题的方法。
5 自动生成测试代码在存储过程测试用例的开发过程中我们发现,开发这些测试代码需要的代中近 90% 的测试代码都是重复或者基本类似的。测试用例中变化最多的是存储过程的名称和所需的参数值,其他代码都是为调用存储过程服务的。因此,自动生成测试代码,然后再由用户做小小的改动是最理想的模式。那么如何自动生成测试代码呢?在实现存储过程测试代码的自动生成过程中,我们遇到并解决了以下问题:
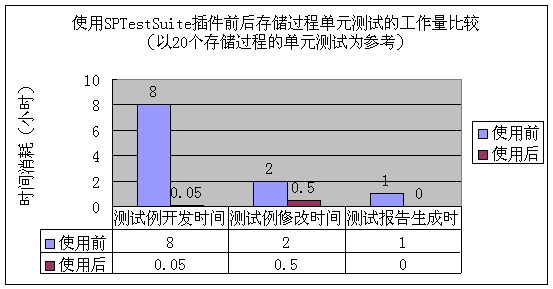
6 编写一个 Eclipse 插件使用 Eclipse 插件的原因,还得从Eclipse本身说起。自从2001年11月IBM宣布了捐出价值4千万美金的开发软件给开放源码的Eclipse项目,Eclipse便开始向能够进行任何语言开发的IDE集大成者的方向发展。Eclipse是替代 IBM Visual Age for Java 的新一代的 IDE 开发环境,它的目标不仅仅是成为专门的Java 程序的 IDE 环境,根据 Eclipse 体系结构,通过开发插件,它能扩展到任何语言的开发,甚至能成为图片编辑等多媒体工具。更难能可贵的是,Eclipse是一个开放源代码的项目,任何人都可以下载 Eclipse 的源代码,并且在此基础上开发自己的功能插件。可以无限扩展,有着统一的外观、操作和系统资源管理,这正是 Eclipse 的潜力和魅力所在。 除了 Eclipse 平台本身所具有的强大魅力之外,插件易于安装,且操作方便简单也是我们考虑用插件的方式来完成测试用例的自动生成问题的原因之一。另外的一个原因是我们在项目开发过程中使用的是 WSAD,即 WebSphere Application Developer Integration Edition 5.1。WSAD 就是基于 Eclipse2.1.1 平台的,因此可以无缝的将 SPTestSuite 插件集成到项目统一的开发环境中。 基于以上考虑,我们决定开发一个 Eclipse 插件来解决测试用例自动生成的问题,这个插件就是 SPTestSuite(此插件只适合 Eclipse 2.1.1)。SPTestSuite 插件要完成自动代码生成所需的全部功能,它以向导的方式运行,引导用户完成代码的创建。用户只需
SPTestSuite 插件将根据用户选择的存储过程,连接数据库获取相应的存储过程参数,然后依据代码模板自动生成测试用例,并在 workbench 的工作环境中打开。用户需要对生成的代码做一些改动,一般来说,只需要修改存储过程的调用参数即可。如果用户需要定制自己的代码模板,需要在生成代码前对代码模板进行修改。这样就基本上解决了手工完成存储过程测试用例工作量较大、效率较低的问题,并且通过采用代码模板的方式实现了可定制和扩展。 7 插件扩展了 JUnit 框架为了解决测试效率低下和回归测试的问题,我们选择使用 JUnit 测试框架。通过对 JUnit 测试框架进行扩展,我们可以增加以下特性:
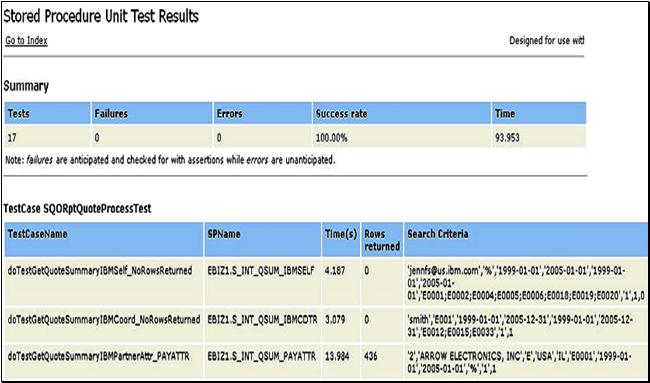
8 执行测试用例存储过程测试代码生成后,怎样运行并查看测试结果呢?在 Eclipse 中,左键双击将要运行的 Java 文件,再从工具栏上找到"跑动的小人儿",从点开的下拉列表框中选择 Run As->JUnit Test 就可以在工作环境中运行测试文件了,运行完毕后,您可以在 JUnit 视图下查看简单的结果。 运行完毕后,会在 C:\ 根目录下生成一个 XML 文件,其中保存着这次测试的结果,文件名格式为 TestCaseName_年_月_日_时_分_秒.xml。为了能够在浏览器中友好的显示测试结果,你需要把
spTest-report.xsl 样式表文件放在与测试结果文件相同的目录中。这个文件可以在 SPTestSuite 插件的根目录可以找到。在浏览器中打开
XML 文件后,您看到的测试结果可能是下图所示的样子: 结果页面中显示了测试例名称,存储过程名称,耗费时间,返回记录数以及存储过程调用参数表等信息。那么图 1 中的存储过程性能指标是如何统计出来的呢?存储过程的性能指标包括运行时间和返回记录数(如果有结果集返回的话)。在测试代码中统计 runSP() 方法的运行时间是不准确的。因为在 runSP() 方法中,除了运行存储过程之外,还要进行参数分析和结果集分析,这段时间是不能忽略的。因此,我们在类 SPProcessSample 中的存储过程执行语句前后进行运行时间的统计。然后提供方法:String getDurationTime(),来返回运行时间统计结果。而返回记录数在获取到运行时间之后进行统计,并作为 runSP() 方法的返回值返回给用户。测试代码中就是使用了以上这些方法才轻松的获取到了存储过程的两个性能指标。 9 自动验证测试结果在测试代码中,用户可以通过以下一些方法来获取存储过程的返回值和结果集,随后测试用例就可以自动进行一些正确性验证的工作了。 Java 类 SPProcessSample 封装了运行存储过程的功能,但必须解决的新问题,这就是如何使用户能够获取存储过程的运行结果以便对结果进行验证。我们在 SPProcessSample 里面设置了三个方法来解决这个问题。 第一个是Object getReturnedObject (int parmIndex),用来得到输出参数的值。 第二个是Object getReturnedValue()方法,用来得到UDF的返回值。 第三个是void setResultSetNeeded (boolean b)方法,用来指定是否要求 SPProcessSample返回存储过程的结果集。 第四个是ArrayList getResultSets(),用来得到存储过程返回的结果集。只有在调用runSP()之前调用了setResultSetNeeded(true),才能获取的结果集,否则为空值。 10 不同时间点的测试结果的比较很多时候,我们不仅需要知道这次测试的结果,更重要的,我们需要知道这次的测试结果比上次是否有所改进,或者系统在不同时间点的性能变化情况。这些数据必须利用不同时间点的测试结果历史纪录才能得到。幸运的是,在使用新的测试方法后,每次运行测试例后,都会生成一个具有时间戳的测试结果文件,例如:
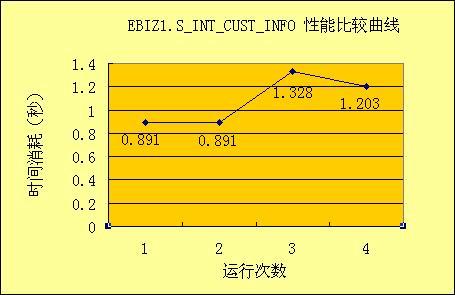
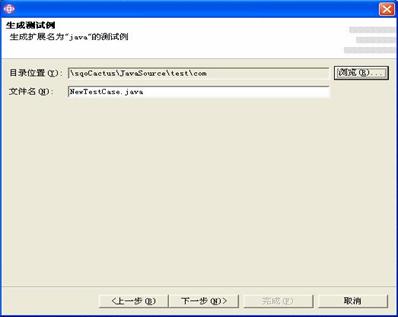
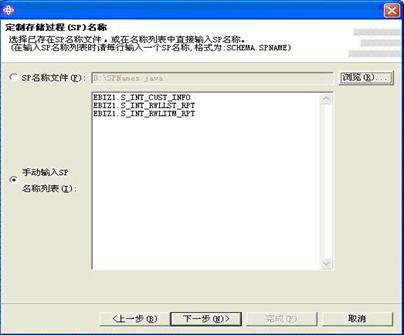
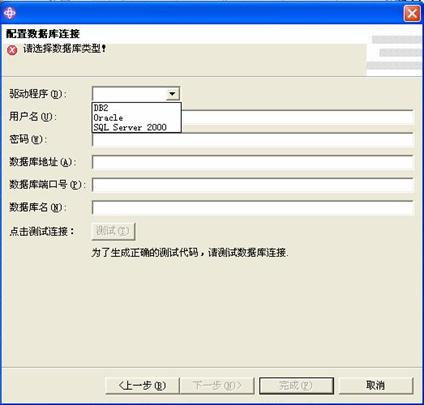
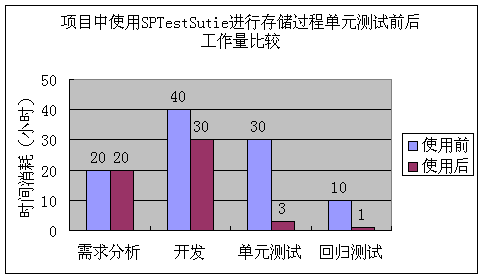
文件名告诉我们在2005年10月18日17点的27分、30分和32分进行了三次测试,对应的文件中存放的是每次测试的结果。现在可以通过比较这三个文件中同一个存储过程的运行耗时、返回记录数等指标来得出结论。可以很轻松的自己开发一个程序来对这些数据进行分析,并且以饼图、曲线图、柱状图等多种形式形象的展现比较结果。下面就是我们做的一个性能比较曲线的例图: 11 SPTestSuite插件的运行步骤使用SPTestSuite插件自动生成存储过程测试代码大体上有如下步骤,具体的操作说明,请见插件安装后根目录中的说明手册。 第一步,安装SPTestSutie插件。 第二步,导入样本Web项目。 我们提供了一个叫做sampleSPTestPrj的样本项目,这是一个已经为将来生成的测试例配置好运行环境的空Web项目,其中没有包含任何Java文件和JSP文件。在开始生成之前,您首先应该把此项目放到您的工作区中。 第三步,使用插件的向导自动生成代码 下图是插件运行后的第一个界面: 向导的第二个界面,在这里由程序员指定存储过程的名称或者包含存储过程名称的文件: 下图是插件第三个画面,用户在这里指定数据库连接参数,点完成后,将开始生成代码: 目前系统支持三种数据库:DB2,Oracle和SQL Server。选择适当的数据库之后,再填写所需的数据库连接参数,包括数据库类型,用户名,密码,数据库地址,数据库端口号,数据库名称等,点击"完成"后即可由插件自动查询存储过程参数信息,并借此来生成完整的测试代码。 12 SPTestSuite插件提高了程序员的工作效率了吗?使用SPTestSuite生成存储过程单元测试代码,与手动编写单元测试代码相比,工作效率提高了么?请看下面这个图形: 以40个存储过程为例,程序员们在项目A中一开始使用手工方式进行开发存储过程单元测试代码,每个人平均花费了大约8小时时间,而使用SPTestSuite插件自动生成代码,最多只用3分钟就完成了;而由于需要统一修改测试代码而花费的时间,在使用SPTestSuite之前每个人用了大约2小时,而使用该插件后,总共需要半个小时就足够了,其中5分钟用于修改代码模板,另外25分钟用于修改生成的代码中的存储过程调用参数。从上图的分析可以看出,效率的提升是显而易见的。 而对于整个项目而言,使用了新的方法之后,项目的时间有什么变化呢,请见下图: 由于单元测试工作量的大幅减少以及带来的存储过程潜在问题的减少,总体的开发工作量也会有相当减轻。 13 总结通过实践,我们发现 Eclipse 的插件开发并不像想象中那么复杂,相反,Eclipse 先进框架概念和优越的可扩展性,使得开发过程简单、快速、高效。我们也亲身体会到了 Eclipse 卓越的扩展性,为开发人员解决开发过程中遇到的问题,提供了更多的解决途径和平台。 利用Java来进行存储过程的测试,使得原本繁琐的测试工作,变得像写程序一样有趣(真的很有趣,我们不是在开玩笑);利用JUnit的自动化、可重复,我们实现了以往存储过程测试中很难进行的回归测试;利用XML技术在数据存储和易于定制、分析的特性,为开发人员提供了直观的测试结果。 现有的测试框架可以非常容易的扩展到Cactus框架上,实现从浏览器进行存储过程测试用例的调用执行,可以克服因为开发和生产环境之间可能存在的网络、安全等影响测试准确性的问题,这一点在全球化开发的大背景下尤其重要。 14 资源列表您可以在解压插件压缩包SPTestSuite.zip之后,解压后的目录中找到以下资源:
参考资料
|


组织简介 | 联系我们 | Copyright 2002 ® UML软件工程组织 京ICP备10020922号 京公海网安备110108001071号 |