| UML软件工程组织 | |||
| |
|||
|
|||
《LoadRunner 没有告诉你的》之二
作者: 陈雷 来源: cnblogs
| 理解性能 在这篇短文中,我将尽可能用简洁清晰的文字写下我对“性能”的看法,并澄清几个容易混淆的概念,帮助大家更好的理解“性能”的含义。 如何评价性能的优劣: 用户视角 vs. 系统视角 对于最终用户(End-User)来说,评价系统的性能好坏只有一个字――“快”。最终用户并不需要关心系统当前的状态――即使系统这时正在处理着成千上万的请求,对于用户来说,由他所发出的这个请求是他唯一需要关心的,系统对用户请求的响应速度决定了用户对系统性能的评价。 而对于系统的运营商和开发商来说,期望的是能够让尽可能多的用户在任意时刻都拥有最好的体验,这就要确保系统能够在同一时间内处理更多的用户请求。正如在《理发店模型》一文中所描述的:系统的负载(并发用户数)与吞吐量(每秒事务数)、响应时间以及资源利用率(包括软硬件资源)之间存在着一个“此消彼长”的关系。因此,从系统的运营商和开发商的角度来看,所谓的“性能”是一个整体的概念,是系统的负载与吞吐量、可接受的响应时间以及资源利用率之间的平衡。 换句话说,“好的性能”意味着更大的最佳并发用户数(The Optimum Number of Concurrent Users)和
最大并发用户数(The Maximum Number of Concurrent Users)。有关“最佳/最大并发用户数”的概念请参见《理发店模型》一文。
响应时间
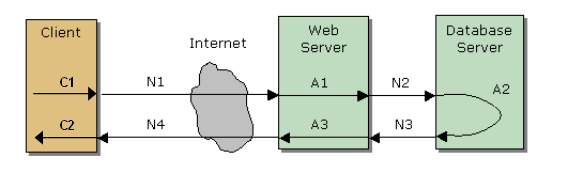
上面这张图引自段念兄的一份讲义,不过我略作了些修改。从图中我们可以清楚的看到一个请求的响应时间是由几部分时间组成的,包括 从用户的角度来看,响应时间=(C1+C2)+(A1+A2+A3)+(N1+N2+N3+N4);但是从系统的角度来看,响应时间只包括(A1+A2+A3)+(N1+N2+N3+N4)。 在理解了响应时间的组成之后,可以帮助我们通过对响应时间的分析来更好的识别和定位系统的性能瓶颈。 吞吐量 vs. 吞吐量 在不同的测试工具中,对于吞吐量(Throughput)会有不同的解释。例如,在LoadRunner中,这个指标是以字节数为单位来衡量网络吞吐量的,而在JMeter中则是以事务数/秒为单位来衡量系统的响应能力的。不过在大多数英文的性能测试方面的书籍或资料中,吞吐量的定义使用的是后者。 并发用户数 ≠ 每秒请求数 这是两个容易让初学者混淆的概念。 简单说,当你在性能测试工具或者脚本中设置了100并发用户数后,并不能期望着一定会有每秒100个请求发给服务器。事实上,对于一个虚拟用户来说,每秒发出多少请求只跟服务器返回响应的速度有关。如果虚拟用户在0.5秒内就收到了响应,那么它会立即发出第二个请求;而如果要一直等待3秒才能得到响应,它将会一直等到收到响应后才发出第二个请求。也就是说,并发用户数的设置只是保证服务器在任一时刻都有100个请求需要处理,而并不一定是保证每秒中发送100个请求给服务器。 所以,只有当响应时间恰好是1秒时,并发用户数才会等于每秒请求数;否则,每秒请求数可能大于并发用户数或小于并发用户数。 无所不在的性能测试 提到性能测试,相信大家可以在网上找到很多种不同的定义、解释以及分类方法。不过归根结底,在大多数情况下,我们所要做的性能测试的目的是“观察系统在一个给定的环境和场景中的性能表现是否与预期目标一致,评判系统是否存在性能缺陷,并根据测试结果识别性能瓶颈,改善系统性能”。 本文是《LoadRunner没有告诉你的》系列的第五篇,在这篇文章中,我希望可以跟大家一起来探讨“如何将性能测试应用到软件开发过程的各个阶段中,如何通过尽早的开展性能测试来规避因为性能缺陷导致的损失”。 因此,本文的结构也将依据软件开发过程的不同阶段来组织。 另外,建议您在阅读本文前先阅读本系列文章的第三篇《理发店模型》和第四篇《理解性能》。 需求阶段 我们不可能将一辆设计载重为0.75吨的皮卡改装成载重15吨的大型卡车,如果你面对的正是这样的问题,那么恐怕你只能重做一辆,而且客户不会为你之前那辆付钱。对于一个已经完成的应用系统来说也是如此。 如果我们在系统结构确定之前就能够了解到系统的将要面对的压力,用户的使用习惯和使用频度,我们就可以更早也更有效的提前解决或预防可能发生的性能缺陷,也将会极大的减少后期返工和反复调优所带来的工作量。如果我们预期到系统的容量将会不断的增长,我们还可以给出相应的解决方案来低成本的解决这类问题,就像上面那辆皮卡,也许你可以有办法把20辆皮卡捆在一起,或者把15吨的东西分由20辆来运。 分析设计阶段 系统性能的优化并不是要等待整个系统全部集成后才能开始的,早在分析设计阶段,我们就可以开始考虑系统的技术架构和数据库部分的优化。 数据库通常位于整个系统的最底层,如果直到系统上线前才发现因为数据库设计不合理而导致性能极差,通常使用任何一种方法来优化都已经于事无补了。要避免这类问题,最常见的做法是在数据库结构确定后,通过工具或脚本向数据库中注入大量的数据,并模拟各种业务的数据库操作。根据对数据库性能的观察和分析,对数据库表结构和索引进行调整以优化数据库性能。 在系统的技术架构方面,要明白先进的技术并不是解决问题的唯一方法,过于强调技术的作用反而会将你带入歧途。例如:某些业务虽然经常面临着巨大的压力,并且业务本身的复杂性决定了通过算法的优化来提高系统的性能收效甚微。但是我们知道用户对于该业务的实时性要求并不高,并且返回结果对于不同用户来说是相同的。那么我们完全可以考虑将每次请求都动态生成返回结果的方式改为每次用户请求都返回一个定期更新的静态页面。 另外,所谓“先进技术”通常都会在带来某一方面改进的同时带来另一方面的问题,未经试验就盲目的在系统中加入各种流行元素未必是最好的选择。例如ORM可以提供一些方便,但是它生成的SQL是未经优化的,有时甚至比人工编写的SQL效率更低。 最后,要知道不同厂家的设备性能是不同的,而且不同的硬件设备搭载不同的操作系统、数据库、中间件以及应用服务器,表现出来的性能也是不同的。如果有足够的资源,应当考虑提前进行软硬件平台的对比选型;如果没有足够的资源,可以考虑通过一些专业的组织或网站来获取或购买相关的评估报告。 编码阶段 一片树叶在哪里最难被发现?――当这片树叶落在一堆树叶里面的时候。 如果你只是在系统测试完成后才开始性能测试,那么即使发现系统存在性能缺陷,并且已经有了几个可供怀疑的对象,但是当一段因为使用了不当的算法而导致执行效率很低的代码藏身于一个庞大的系统中时,找出它是非常困难的。避免这种情况出现的方法是尽早开始核心业务代码的性能测试,重点集中在对算法和实现方法的优化上。 另外,及早开始的测试也可以帮你更容易找到内存泄漏的问题。 测试阶段 产品终于交到我们手上了,搭建测试环境,设计测试场景,执行测试,找到系统的最佳并发用户数和最大并发用户数,将系统进行分类,评判系统的性能表现是否满足需求中定义的目标――如果有需求的话 ^_^ 如果发现系统的性能表现与预期目标相去甚远,则需要根据执行测试过程中收集到的数据来分析和识别性能瓶颈,优化系统性能。 在这个阶段还有很多值得我们深入思考和讨论的东西,在本系列后续的文章中,我们将会更多的关注这一部分的内容。 维护阶段 维护阶段通常遇到的问题是需要在实验室中模拟客户环境,重现在客户那里发现的缺陷并修复缺陷。相比功能缺陷,性能缺陷与某一具体环境和场景的关联更加密切,所以在测试前需要检查生产环境中各服务器的资源利用率、系统访问日志、应用服务器的日志、数据库的日志。如果客户使用了专门的系统来监测各个服务器的软硬件资源使用情况的话,检查该系统是否记录下了软硬件资源的异常或者警告。 与性能测试相关的其他测试 可靠性测试(Reliability Testing) 对于一个运营商级的系统来说,能够保证提供7×24的连续稳定的服务是非常重要的。当然,你可以通过一些“高可用性(High Availability)”技术方案来增强系统的可靠性,但是对于系统本身的可靠性测试是不能被忽略的。 常用的测试方法是使用一定的负载长时间向服务器加压,并观察随着加压时间的延长,响应时间、吞吐量以及资源利用率的变化。要注意的是,所使用的负载应当是系统的最佳并并发用户数,而不是最大并发用户数。 可伸缩性测试(Scalability Testing) 对于一个系统来说,在一个给定的环境下,它的最佳并发用户数和最大并发用户数是客观存在的,但是系统所面临的压力却有可能随上线时间的延长而增大。例如,一个在线购物站点,注册用户数量不断增多,访问站点查询商品信息和购买商品的人也不断的增多,我们应该用一种什么样的方案,在不影响系统继续为用户提供服务的前提下来实现系统的扩容? 一种常用的方案是使用负载均衡(Load Balance)和集群(Cluster)技术。但是在我们为客户提供这种方案之前,需要先自己进行测试,保证该技术的有效性――我们是否真的可以通过简单的增加服务器数据和修改某些参数配置,就能够使得系统的容量得到线性的增长? 可恢复性测试(Recoverability Testing) 虽然我们已经可以准确的估算出系统上线后将要面对的压力,并且可以保证系统的最佳并发用户数和最大并发用户数是足以应对这些压力的,但是这个世界上总是有些事情上我们所无法预料到的――例如9.11事件发生后,AOL的网站访问量在短时间内增长到了平时的数十倍。 我们无法保证系统可以在任何情况下都能为用户正确无误的提供服务,但是我们需要确保当意外过去后,系统可以恢复到正常的状态,并继续后来的用户提供服务――就像从未发生过任何事情一样。 如果要实现“可恢复性测试”,我们可以借助于测试工具或脚本来逐渐的增大并发用户数,直至并发用户数已经超过了系统所能承受的最大并发用户数,并导致软硬件资源利用率饱和,响应时间无限延长,大量的请求因为超过响应时间要求或无法获得响应而失败;之后,我们逐渐的减少并发用户数,并观察资源利用率、响应时间、吞吐量以及交易成功率的变化是否与预期目标一致。 当然,这一切的前提是在系统负载达到峰值前,Server一直在顽强的挣扎着而没有down掉
性能测试,并非网络应用专属 软件的性能和性能测试都是伴随着网络应用的兴起而逐渐被重视起来的,但是软件性能和性能测试却并非网络应用的专属名词,因为单机版的应用同样需要考虑性能问题。下面举几个简单的例子来方便大家的理解: 1. 当使用Word来编辑一个500多页,并包含了丰富图表、图片和各种格式、样式信息的文档时,是否每次对大段的文字或表格的修改、删除或重新排版,都要等待系统花几秒钟的时间进行处理? 2. 当在Excel中使用嵌套的统计和数学函数对几万行记录进行统计分析时,是否每次都要两三分钟才能看到结果? 3. 杀毒软件是否每次都要花费两个小时才能完成一次对所有的分区的扫描? 4. 是否每次在手机的通讯簿中根据姓名搜索某个人的联系方式都要三四秒钟才有响应? 如果大家有兴趣,也可以通过Google搜索到更多的有关单机应用性能测试的资料。 获取有效的性能需求 一个实际的例子 为了便于大家的理解,我们先来看一个性能需求的例子,让大家有一个感性的认识,本文后面的讨论也会再次提到这个例子。 这是一个证券行业系统中某个业务的“实际需求”――实际上是我根据通过网络搜集到的数据杜撰出来的,不过看起来像是真实的 ^_^ 系统总容量达到日委托6000万笔,成交9000万笔 系统处理速度每秒7300笔,峰值处理能力达到每秒10000笔 实际股东帐号数3000万 这个例子中已经包括几个明确的需求: 最佳并发用户数需求:每秒7300笔 最大并发用户数需求:峰值处理能力达到每秒10000笔 基础数据容量:实际股东帐号数3000万 业务数据容量:日委托6000万笔,成交9000万笔――可以根据这个推算出每周、每月、每年系统容量的增长模型 什么是“有效的”性能需求? 要想获得有效的性能需求,就要先了解什么样的需求是“有效的”。有效的性能需求应该符合以下三个条件。 1. 明确的数字,而不是模糊的语句。 结合上面的例子来看,相信这个应该不难理解。但是有的时候有了数字未必就不模糊。例如常见的一种需求是“系统需要支持5000用户”,或者“最大在线用户数为8000”。这些有数字的需求仍然不够明确,因为还需要考虑区分系统中不同业务模块的负载,以及区分在线用户和并发用户的区别。关于这方面的内容,在下面两篇文章中的留言内容中有精彩的讨论: 2. 有凭有据,合理,有实际意义。 通常来说,性能需求要么由客户提出,要么由开发方提出。对于第一种情况,要保证需求是合理的,有现实意义的,不能由着客户使劲往高处说,要让客户明白性能是有成本的。对于第二种情况,性能需求不能简单的来源于项目组成员、PM或者测试工程师的估计或者猜测,要保证性能需求的提出是有根据的,所使用的数据和计算公式是有出处的――本文后面的部分会介绍获得可用的数据和计算公式的方法。 3. 相关人员达成一致。 这一点非常关键。如果相关人不能对性能需求达成一致,可能测了也白测――特别是在客户没有提出明确的性能需求而由开发方提出时。这里要注意“相关人员”的识别,通常项目型的项目的需要与客户方的项目经理或负责人进行确认,产品型的项目需要与直属领导或者市场部进行确认。如果实在不知道该找谁确认,那就把这个责任交给你的直属领导;如果你就是领导了,那这领导也白当了 如何获得有效的性能需求 上面提到了“有效的”性能需求的一个例子和三个条件,下面来我们将看到有哪些途径可以帮助我们获得相关的数据――这些方法我在实际的工作中都用过,并且已经被证实是可行的。这几种方法由易到难排列如下: 1. 客户方提出 这是最理想的一种方式,通常电信、金融、保险、证券以及一些其他运营商级系统的客户――特别是国外的客户都会提出比较明确的性能需求。 2. 根据历史数据来分析 根据客户以往的业务情况来分析客户的业务量以及每年、每月、每周、每天的峰值业务量。如果客户有旧的系统,可以根据已有系统的访问日志,数据库记录,业务报表来分析。要特别注意的是,不同行业、不同应用、不同的业务是有各自的特点的。例如,购物网站在平时的负载主要集中在晚上,但是节假日时访问量和交易量会是平时的数倍;而地铁的售票系统面临的高峰除了周末,还有周一到周五的一早一晚上下班时间。 3. 参考历史项目的数据 如果该产品已有其他客户使用,并且规模类似的,可以参考其他客户的需求。例如在线购物网站,或者超市管理系统,各行业的进销存系统。 4. 参考其他同行类似项目的数据 如果本企业没有做过类似的项目,那么可以参考其他同行企业的公布出来的数据――通常在企业公布的新闻或者成功解决方案中会提到,包括系统容量,系统所能承受的负载以及系统响应能力等。 5. 参考其他类似行业应用的数据 如果无法找打其他同行的数据,也可以参考类似的应用的需求。例如做IPTV或者DVB计费系统的测试,可以参考电信计费系统的需求――虽然不能完全照搬数据,但是可以通过其他行业成熟的需求来了解需要测试的项目有哪些,应该考虑到的情况有哪些种。 6. 参考新闻或其他资料中的数据 最后的一招,特别是对于一些当前比较引人关注的行业,涉及到所谓的“政绩”的行业,通常可以通过各种新闻媒体找到一些可供参考的数据,但是需要耐心的寻找。例如我们在IPTV和DVB系统的测试中,可以根据新闻中公布的各省、各市,以及国外各大运营商的用户发展情况和用户使用习惯来估算系统容量和系统各个模块的并发量。 |
组织简介 | 联系我们 | Copyright 2002 ® UML软件工程组织 京ICP备10020922号 京公海网安备110108001071号 |