| 编辑推荐: |
本文主要讲解了两方面:一是从基础概念的角度给大家介绍一下这个产品设计框架;二是使用了一个小示例来讲解如何应用框架。希望对你有帮助。
本文来自人人都是产品经理,由火龙果软件Linda编辑、推荐。 |
|
我是一名PC/移动互联网的产品经理,现在正在努力转型进入人工智能领域,这是我的第2篇学习总结。本篇文章总结了一个刚刚学习到的AI产品设计框架,框架中整合了很多目前AI方面的知识体系。也许这个设计框架能够给想学习AI的朋友们一个知识框架,也就是学习AI到底都要学习哪些知识的一个框架,希望借此文章能够给大家抛砖引玉,与大家共同学习。
本文分为两个主要章节。首先,从基础概念的角度给大家介绍一下这个产品设计框架。第二章则使用了一个小示例来讲解如何应用框架。

一、AI产品设计框架基础知识
如上图,这就是本篇要讲解的AI产品设计框架。其中左侧的Agent就是今天的主角,可以称为“学习的基于效用的Agent”。这个名称中包含了三个部分,我们就先来解释一下这三个部分:
Agent:能够行动的某种东西。(第二章示例所讲解的Agent,对应的就是一个可以自主玩牌的Agent)。
学习的Agent:可以简单理解为可以自主学习自我升级的Agent。
基于效用的Agent:可以简单理解为此类Agent在选择执行的行为时,总是选择期望能得到最大化收益的行为。
上图中右侧的是环境,也就是Agent所处的环境,可以理解为Agent的外部环境。这个环境可以是真实环境,也可以是网络虚拟环境。
Agent可以通过传感器来感知环境的当前情况,通过执行器对环境产生影响。举个例子:假如一个机器人Agent,就是将摄像头或麦克风作为传感器来获取图像与声音,将机器手臂与机器腿作为执行器来进行特的定操作与移动物理位置。再比如微软的聊天机器人小冰也是一个Agent,只不过所处的环境是网络,他通过获取文字输入的接口作为传感器,通过发送回复信息的接口作为执行器。
已经讲解了最基本的一个Agent的结构情况,如果说想让Agent在环境下运行,那么首先要做的事情就是定义环境。
1.1 环境定义
Agent都会有其需要完成的任务,在设计Agent时,第一步就是尽可能完整地详细说明任务环境。任务环境的定义内容包括:性能度量、环境以及Agent的执行器与传感器,称之为PEAS描述(Performance(性能度量),Environment(环境),Actuators(执行器),Sensors(传感器))。我们通过以下描述来理解各个定义内容:
Agent在其所处的环境中,通过传感器收集感知信息,形成Agent内部的感知序列。
Agent在其所处的环境中,针对感知信息会生成一个行动序列,并由执行器完成。
一个理性Agent,对每一个可能的感知序列,根据已知的感知序列和Agent具备的当前知识信息,选择能使其性能度量最大化的行动。
下面给出一个示例:

1.2 基于效用的Agent的设计
定义好环境,我们就要回到对主体Agent的设计上来了。
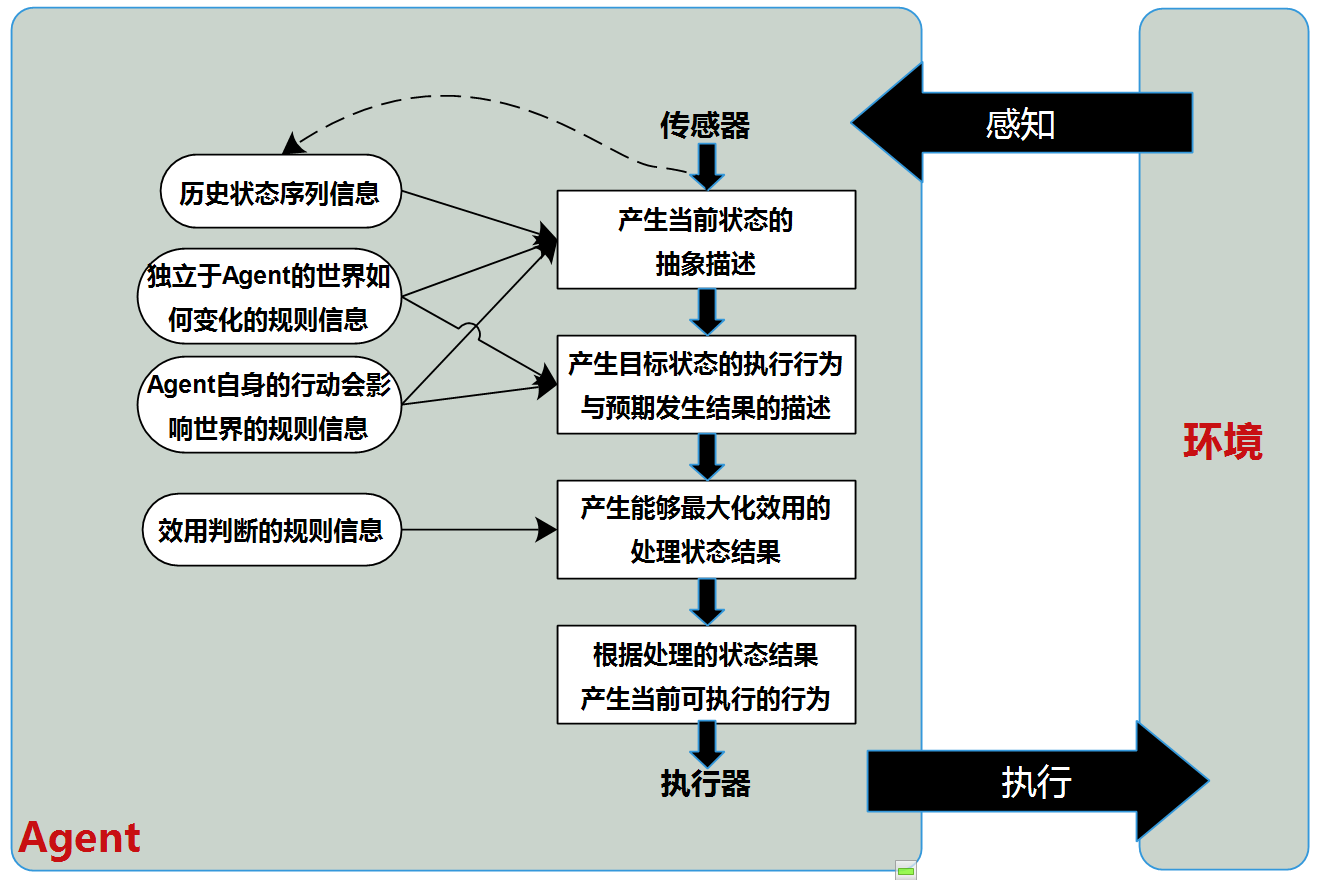
上图就是基于效用的Agent的设计框架。其中,矩形表示Agent决策处理过程,椭圆形表示对应处理过程所中用到的背景知识信息。
下面我们将按照Agent的处理顺序依次说明每一个处理步骤的具体处理方法,并且会说明每一个步骤为下一步骤所输入的信息。

1.3 学习的基于效用的Agent的设计
以上已经完成了对一个基于效用的Agent的设计描述。但真的一个智能Agent就这样就完成了么?如果对于一个不能自主学习并进化系统逻辑的Agent,还不能称其为智能化的。那么我们只需将上述的Agent设计加入一个能够学习的环境中即可。接下来我们看看能够学习的基于效用的Agent是如何设计的吧。
学习Agent可以被划分为4个概念上的组件:学习组件、性能组件、评判组件、问题产生器。在此部分中的性能组件,就是“学习的基于效用的Agent”中“基于效用的Agent”的整体。设计框架如下图所示:
下面将对于除性能组件外的其他组件进行简单说明:
学习元件:利用来自评判元件的反馈评价Agent做的如何,并确定应该如何修改性能元件以便将来做得更好。
评判元件:根据固定的性能标准告诉学习元件Agent的运转情况。评判元件是必要的,原因是感知信息自身无法指出Agent的成功程度。性能标准是固定的。概念上说,应该把性能标准置于Agent之外加以考虑,理由是Agent不应该修改性能标准来适应他自己的行为。
问题产生器:负责可以得到新的和有信息的经验的行动建议。如果性能元件自行其是,他会一直根据已知的知识采取最佳行动。但是,如果Agent希望进行少量探索,做一些短期内可能次优的行动,那么他也许会发现对长期而言更好的行动。问题发生器的任务就是建议探索性行动。它的目标是发现一种更好的物体运动的理论并改进自己的头脑。
到现在为止我们已经简单了解了如何搭建一个“学习的基于效用的Agent”。此时是不是非常希望从概念的层次实操一把?由于笔者正在学习AI的入门阶段,还没有真正了解到每个具体概念的应用方法,因此我也只能从最表面的层次演练一下。对于没有描述清楚的内容,笔者会在今后的学习中逐步完善并分享。同时,如果文章中存在错误,也希望大牛们多多指出。
二、一个简单的产品定义示例

下面将要分享的简单事例是《自动斗地主Agent》,一个YY的成果,自己玩耍而已大家不要太过认真。
我的想法是,设计一款能够自主学习优化并且帮我最大化获胜的某个移动端斗地主App游戏的智能自动化游戏Agent。
第一步:首先定义一下游戏的环境

模型信息:关于独立于Agent的世界如何变化的规则信息与Agent自身的行动会影响世界的规则信息,此处会将游戏中对于斗地主的全部规则录入,诸如:发牌规则、叫地主规则、出牌规则、加分规则、获胜规则等等。并且会录入一般化的出牌策略,诸如:压制策略、辅助同伙策略等等。
第二步:对于基于效用的Agent,我们做如下定义
效用判断的规则信息:这里根据环境中已经出过的牌,每个选手的出牌历史、角色以及猜测可能剩余的牌等信息,判断出最能符合最大化收益的出牌行为。
传感器就是获取环境中当前的游戏状态信息,如:谁出了什么牌等;
执行器就是能够模拟手机点击来执行叫地主、出牌等操作;
第三步:对于学习的Agent,我们做如下定义
性能标准:根据初始时手中的牌、过程中的得分情况与最终完成后其他选手中剩余牌的情况给出一个对于一轮玩牌结果的奖励或惩罚的分数。
学习组件:会不断对更为一般化的开局与出牌策略、更为一般化的农民合作策略、针对识别某个人或某种类型的人的开局与出牌策略、如何试探其他玩家的出牌策略等策略提出学习目标,并根据结果修正Agent中的效用判断。 | 








