| 编辑推荐: |
本文主要介绍了GPU基础与CUDA编程入门相关内容。 希望对你的学习有帮助。
本文来自于CSDN ,由火龙果软件Linda编辑推荐。 |
|
一、GPU和CPU的区别
GPU: 高吞吐量导向设计
缓存少: 提高内存吞吐
控制简单: 没有分支预测机制和数据转发机制,但是同样存在Prefetch机制。
运算单元精简: 长延时流水线来实现高吞吐量,需要大量线程来容忍延迟。
适合场景: 并行计算占比多,吞吐优先,GPU单位时间执行指令数大大超过CPU
CPU: 低延迟导向设计
大内存,多分级缓存。多级缓存结构提高缓存速度。
控制复杂: 具备分支预测机制和流水线Prefetch机制,加速数据读取。
运算单元强大: CPU对复杂的整型和浮点型的运算速度支持较好,速度快。
适合场景: 连续计算部分,对时延要求高,对单条复杂指令延迟远远低于GPU
GPU适合什么场景:
计算密集,当数值计算的比例远远高于内存操作时; 数据并行,当一个大任务可以拆分成若干个小任务时,因此对复杂流程控制的需求较低
什么是Prefetch?
预取是一种内存管理策略,旨在减少内存访问延迟,从而提高计算性能。预取机制通过预先加载数据到高速缓存(例如,从全局内存到共享内存或纹理内存)来实现这一目标,以便在执行计算任务时减少等待时间。
GPU的预取机制有两种形式:
硬件预取:这是由GPU硬件自动实现的预取机制,不需要程序员进行显式操作。GPU内部的内存控制器会预测内存访问模式,提前将可能需要的数据加载到高速缓存中。这种预取机制在许多现代GPU架构(如NVIDIA的Pascal、Volta和Ampere架构)中都有实现。
软件预取:程序员可以通过编写代码显式地实现预取,以便更好地控制数据加载的过程。在CUDA编程中,可以使用__builtin_prefetch()函数来实现软件预取,该函数将根据程序员的指示将数据加载到L1或L2高速缓存中。软件预取的好处是程序员可以根据任务的特点精确地控制预取行为,从而进一步提高性能。
实际上,预取机制是一种平衡延迟和吞吐量的策略,旨在最大限度地提高GPU的计算效率。需要注意的是,预取机制在不同的GPU架构和设备上可能有所差异。因此,在优化GPU代码时,需要充分了解目标硬件的特性。
二、CUDA与OpenCL
CUDA(Compute Unified Device Architecture)和OpenCL(Open
Computing Language)是用于加速计算的并行计算框架。
CUDA是由英伟达公司开发的框架,支持在NVIDIA的GPU上运行。CUDA提供了一组库和工具,可让开发人员使用C、C++和Fortran等编程语言来编写GPU加速的应用程序。CUDA的优点是它的性能非常高,而且支持广泛的NVIDIA
GPU硬件,这使得它成为开发GPU加速应用程序的首选框架之一。
OpenCL是一个由多家公司共同开发的框架,可以在支持OpenCL的GPU、CPU和其他处理器上运行。OpenCL的优点是它是一个跨平台的框架,这意味着可以在不同的硬件和操作系统上运行。OpenCL还支持多种编程语言,包括C、C++、Java和Python等。
虽然CUDA和OpenCL都是用于加速计算的框架,但它们有一些不同之处。CUDA主要用于NVIDIA
GPU上的计算,而OpenCL则可以在不同的硬件上运行。此外,CUDA的编程模型比较简单,而OpenCL则更加灵活。选择哪种框架取决于具体的应用场景和硬件设备。
三、CUDA编程并行计算整体流程
假设有这么一个GPU Kernel Function:
void GPUKernel(float *A,float *B,float *C,int n){}
其流程可以分为下面几个步骤:
1. Allocate GPU memory for A and B and C.
2. Copy A, B to GPU memory.
3. Run GPUKernel Function to have the GPU perform the actual vector operator.
4. Copy C from GPU to CPU.
|
内存模型
内存模型是CUDA编程中的核心。其内存模型可以分为如下几个层次:
每一个线程处理器SP都拥有自己的寄存器。
每一个线程处理器SP都有自己的Local Memory, 且Register和Local Memory只能被该线程进行访问。
每一个多核处理器(SM)内部都有自己的shared memory, shared memory 可以被线程块内部所有线程访问。
所有SM共有一块Global Shared Memory,可以被不同核的不同线程块的所有线程进行访问

线程块
线程块是将线程数组分成多个块的结构。块内的线程通过共享内存,原子操作和屏障同步进行同步和协作。不同块中的线程不能进行协作。如下图,一个线程使用256个线程进行向量相加,最终将结果进行同步
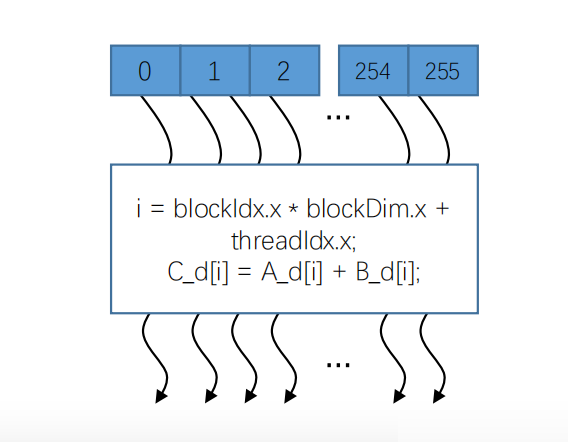
网格Grid:并行线程块组合
每一个线程块中的每一个线程都有一个索引,用于计算内存地址和做出控制决策

我们使用线程块Block ID和线程Thread ID来定位每一个独立线程:

线程ID计算公式:

线程束
线程束(warp)是 GPU 中执行并行计算任务的基本单元,它由一组线程组成,可以同时执行相同的指令序列。在软件端,程序员将并行计算任务编写成
CUDA 或 OpenCL 的代码,并将代码编译成适合 GPU 的指令集。
在硬件端,GPU 的计算单元可以同时执行大量的线程束,每个线程束中包含了一定数量的线程。当计算单元收到一个指令序列时,它会同时启动多个线程束来执行这个指令序列。每个线程束中的线程都会同时执行相同的指令,但是对于每个线程的输入数据和输出结果是不同的。
为了高效地执行线程束,GPU 通常采用SIMD(Single Instruction Multiple
Data)架构。这种架构允许计算单元同时执行多个相同的指令,但是每个指令所操作的数据可以不同。因此,在执行一个线程束时,GPU
可以高效地利用 SIMD 架构,同时处理多个线程的计算任务。
在具体实现上,GPU 的控制单元将计算任务分配给计算单元,并为每个线程分配一些资源,例如寄存器、共享内存和常量内存等。然后,计算单元会同时启动多个线程束来执行指令序列。在执行过程中,GPU
可以动态地调整线程束的数量和分配的资源,以最大化并行计算的效率。
总的来说,线程束是 GPU 中执行并行计算任务的基本单元,它由一组线程组成,可以同时执行相同的指令序列。在软件端,程序员编写并行计算任务的代码,并将其编译成适合
GPU 的指令集。在硬件端,GPU 的计算单元可以同时执行大量的线程束,通过 SIMD 架构来高效地执行计算任务。

SIMD
在GPU中,SIMD是一种重要的线程分配策略。 当一个Kernel 函数被执行的时候,Grid中的线程块被分配到SM上。注意,一个SM可以调度多个线程块,但是同一个线程块内的所有线程只能在一个SM上。
每一个Thread拥有自己的程序计数器和状态寄存器,并且使用线程自带的数据执行同一个指令。这就被称作SIMD:
Single Instruction Multi Data. SIMT的设计也是线程束是执行核函数最基本单元的原因。
四、CUDA编程实例:向量相加
现在假设我们希望通过并行计算完成下列函数:
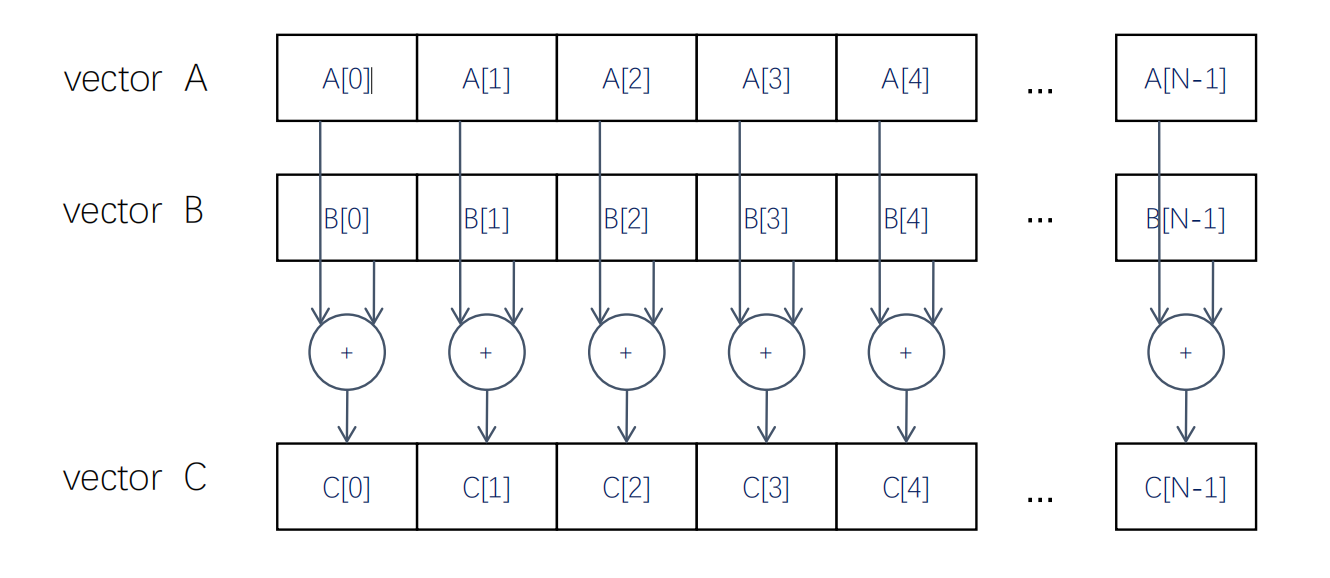
可以看到这个函数访问内存少,控制简单,计算简单,并行度高,所以适合在GPU上运算
在GPU侧,需要完成的功能是:
读写线程寄存器
读写Grid中全局内存
读写Block中共享内存
在CPU侧,需要完成的功能是:
Grid中全局内存拷贝转移
需要涉及到的函数有:
cudaMalloc( )
• cudaError_t cudaMalloc (void **devPtr, size_t size)
• 在设备全局内存中分配对象
• 两个参数
• 地址
• 申请内存大小
cudaFree( )
• cudaError_t cudaFree ( void* devPtr ) • 从设备全局内存中释放对象
• 指向释放对象的指针
cudaMemcpy( )
• cudaError_t cudaMemcpy (void *dst, const void *src,
size_t count, cudaMemcpyKind kind)
• 内存数据复制传递
• 目前支持的四种选项
• cudaMemcpyHostToDevice
• cudaMemcpyDeviceToHost
• cudaMemcpyDeviceToDevice
• cudaMemcpyDefault
• 调用cudaMemcpy( )传输内存是同步的
首先,我们可以先给出一个代码框架,写好除了kernel function以外的所有东西,随后再写kernel
function
void vecAdd(float* A, float* B, float* C, int n)
{int size = n * sizeof(float);
float* A_d, *B_d, *C_d;
1.
cudaMalloc((void **) &A_d, size);
cudaMemcpy(A_d, A, size, cudaMemcpyHostToDevice);
cudaMalloc((void **) &B_d, size);
cudaMemcpy(B_d, B, size, cudaMemcpyHostToDevice);
cudaMalloc((void **) &C_d, size);
2.
…
3.
cudaMemcpy(C, C_d, size, cudaMemcpyDeviceToHost);
cudaFree(A_d); cudaFree(B_d); cudaFree (C_d);
}
|
核函数调用
• 在GPU上执行的函数。
• 一般通过标识符__global__修饰。 • 调用通过<<<参数1,参数2>>>,用于说明内核函数中的线程数量,以及线程是如何组织的。
• 以网格(Grid)的形式组织,每个线程格由若干个线程块(block)组成,而每个线程块又由若干个线程(thread)组成。
• 调用时必须声明内核函数的执行参数。
• 在编程时,必须先为kernel函数中用到的数组或变量分配好足够的空间,再调用kernel函数,否则在GPU计算时会发生错误。
在CUDA编程中的标识符有这些:

__global__
void vecAddKernel(float* A_d, float* B_d, float* C_d, int n)
{int i = threadIdx.x + blockDim.x * blockIdx.x;
if(i<n) C_d[i] = A_d[i] + B_d[i];
}
int vectAdd(float* A, float* B, float* C, int n)
{
vecAddKernel<<<ceil(n/256), 256>>>(A_d, B_d, C_d, n);
}
|
CUDA 编译流程 
五. 代码实例
在CPU上计算向量相加:
#include<bits/stdc++.h>
#include <sys/time.h>
using namespace std;
void vecAdd(float *A, float *B, float *C, int n){for(int i=0;i<n;i++){
C[i] = A[i] + B[i];
}
}
int main(int argc,char *argv[]){
int n = atoi(argv[1]);
cout<<n<<endl;
size_t size = n * sizeof(float);
float *a = (float *)malloc(size);
float *b = (float *)malloc(size);
float *c = (float *)malloc(size);
for(int i=0;i<n;i++){float af = rand()/double(RAND_MAX);
float bf = rand()/double(RAND_MAX);
a[i]=af;
b[i]=bf;
}
struct timeval t1,t2;
gettimeofday(&t1,NULL);
vecAdd(a,b,c,n);
gettimeofday(&t2,NULL);
double timeuse = t2.tv_sec - t1.tv_sec + (t2.tv_usec - t1.tv_usec)/1000000.0;
cout<<"timeuse: "<<timeuse<<endl;
}
|
在GPU上计算向量相加:
#include<bits/stdc++.h>
#include<sys/time.h>
using namespace std;
__global__
void vecAddKernel(float *A, float *B, float *C, int n){
int i = threadIdx.x + blockDim.x * blockIdx.x;
if(i<n) C[i] = A[i] + B[i];
}
int main(int argc,char *argv[]){
int n = atoi(argv[1]);
cout<<n<<endl;
size_t size = n * sizeof(float);
float *a = (float *)malloc(size);
float *b = (float *)malloc(size);
float *c = (float *)malloc(size);
for(int i=0;i<n;i++){float af = rand()/double(RAND_MAX);
float bf = rand()/double(RAND_MAX);
a[i]=af;
b[i]=bf;
}
float *da = NULL;
float *db = NULL;
float *dc = NULL;
cudaMalloc((void **)&da,size);
cudaMalloc((void **)&db,size);
cudaMalloc((void **)&dc,size);
cudaMemcpy(da,a,size,cudaMemcpyHostToDevice);
cudaMemcpy(db,b,size,cudaMemcpyHostToDevice);
cudaMemcpy(dc,c,size,cudaMemcpyHostToDevice);
int threadsPerBlock = 256;
int blockPerGrid = (n + threadsPerBlock - 1) / threadsPerBlock;
struct timeval t1,t2;
gettimeofday(&t1,NULL);
vecAddKernel<<<blockPerGrid,threadsPerBlock>>>(da,db,dc,n);
cudaMemcpy(c,dc,size,cudaMemcpyDeviceToHost);
gettimeofday(&t2,NULL);
double timeuse = t2.tv_sec - t1.tv_sec + (t2.tv_usec - t1.tv_usec)/1000000.0;
cout<<"timeuse: "<<timeuse<<endl;
cudaFree(da);
cudaFree(db);
cudaFree(dc);
}
|
|







 订阅
订阅