| 编辑推荐: |
本文主要介绍了GPU 和 CUDA入门相关内容,希望对你的学习有帮助。
本文来自于知乎 ,由火龙果软件Linda编辑推荐。 |
|
简介
GPU
GPU(图形处理单元)是一种专门处理图像和视频的计算设备。最初,GPU主要用于渲染高质量的图像和视频,因为它们能并行处理大量的像素和顶点数据。然而,随着科学和工程领域对大规模并行计算的需求增加,GPU开始被用于更广泛的应用,包括科学计算、机器学习和数据分析等。
与CPU(中央处理单元)相比,GPU有更多的核心(通常是数百到数千个),能同时处理大量的计算任务。这使得GPU在处理大规模并行计算任务时,比如机器学习和深度学习的训练过程,能有非常高的效率。
CUDA
CUDA(Compute Unified Device Architecture)是NVIDIA公司开发的一种编程模型和软件环境,它允许开发者使用C、C++、Python等高级语言来编写GPU程序。
在CUDA模型中,程序员编写一种被称为内核的函数,这些函数在GPU的多个线程上并行执行。程序员还可以控制线程的组织和通信,以优化性能和资源利用。
CUDA提供了一套丰富的开发工具,包括编译器、库、调试器和性能分析工具,这些工具使得开发者可以更容易地开发和优化CUDA程序。
通过使用CUDA,开发者可以利用NVIDIA的GPU来加速各种类型的计算密集型任务,从而极大地提高了这些任务的性能。
前置知识
在开始学习 GPU 和 CUDA 之前,你可能需要了解和准备以下技术或软件:
计算机科学基础:理解计算机系统的基本概念,包括计算机硬件、操作系统、编程语言等。特别是对于计算机硬件,理解CPU和内存的工作原理将有助于你理解
GPU 的工作原理。
并行计算基础:GPU 的优势在于其强大的并行计算能力。因此,你需要了解并行计算的基本概念,包括并行计算模型(如
SIMD 和 MIMD)、并行算法、并行性能评估等。
C/C++ 编程:CUDA 是一种 C/C++ 扩展,所以你需要熟悉 C/C++ 语言。你应该熟悉
C/C++ 的基本语法,包括变量、数据类型、控制流、函数、指针等。此外,理解C/C++ 的内存管理也很重要,因为在
CUDA 编程中,你需要手动管理 GPU 的内存。
基本的线性代数、微积分和概率知识:这些数学知识在 GPU 编程和深度学习中都会用到。你不需要成为数学专家,但至少需要对这些概念有基本的理解。
操作系统:你需要熟悉你的操作系统(Linux 或 Windows),因为你需要在命令行环境中进行 CUDA
编程。你需要知道如何在命令行环境中操作,如何安装软件,如何管理文件和目录等。
硬件设备:你需要有一台 NVIDIA 的 GPU。CUDA 是 NVIDIA 的一项技术,只能在 NVIDIA
的 GPU上运行。
以上是你在开始学习 GPU 和 CUDA 之前可能需要了解和准备的技术或软件。每一项都是一个大的主题,需要花费一定的时间去学习和实践。但不用担心,你可以一步一步来,学习
GPU 和 CUDA 是一个持续的过程,祝你学习愉快!
学习计划
在一小时内基本学习 GPU 和 CUDA,我建议你可以按照以下步骤来进行:
步骤一:了解 GPU 和 CUDA 的基础知识(20 分钟)
首先了解什么是 GPU,以及它如何用于加速并行计算。
然后了解什么是 CUDA,以及它如何在 NVIDIA 的 GPU 上进行编程。
你可以阅读 NVIDIA 官方网站或者相关教材中的简介部分,或者观看一些在线教程或视频。
步骤二:设置 CUDA 环境(10 分钟)
确认你的机器是否有 NVIDIA 的 GPU,并且是否支持 CUDA。
安装 NVIDIA 的驱动程序和 CUDA 工具包。
步骤三:编写并运行你的第一个 CUDA 程序(20 分钟)
学习 CUDA 编程的基本概念,包括线程、块、网格和内存模型。
编写一个简单的 CUDA 程序,例如使用 GPU 进行向量加法。
你可以找一些 CUDA 的教程或样例代码,然后自己动手实践。
步骤四:理解并优化 CUDA 程序(10 分钟)
学习如何使用 CUDA 的内存管理功能,包括全局内存、共享内存和常量内存。
学习如何优化 CUDA 程序,包括线程并行度、内存访问模式和指令级并行。
以上就是一小时内学习 GPU 和 CUDA 的一个可能的学习计划。这只是一个初级的介绍,要熟练掌握
GPU 和 CUDA 编程,还需要更深入的学习和实践。如果在学习过程中遇到任何问题,你可以查阅 CUDA
的官方文档,或者在网上寻找相关的教程和问答。
步骤三和步骤四主要涉及到 CUDA C/C++ 编程,这不需要任何额外的库或技术,只需要 NVIDIA
提供的 CUDA Toolkit。
了解 GPU 和 CUDA 的基础知识
什么是 GPU,以及它如何用于加速并行计算
什么是 GPU?
GPU (Graphics Processing Unit,图形处理单元)最初是为了加速计算机图形渲染而设计的。与中央处理单元(CPU)不同,CPU
是为了处理一系列的任务而设计的,而 GPU 是为了并行处理大量的数据而设计的。这种并行性使 GPU
特别适合处理那些可以分解为多个小任务并且可以同时执行的问题,例如图形渲染。
GPU 的特点:
大量的核心 :传统的 CPU 可能有 4、8、16 或更多的核心,而 GPU 可能有上千个核心。这些核心可以同时处理大量的任务。
高吞吐量 :尽管每个单独的 GPU 核心的速度可能比 CPU 核心慢,但由于其数量众多,GPU 可以处理的总任务数量远远超过
CPU。
专为并行处理设计 :GPU 的设计原则是大量并行处理。每个核心都是为了处理独立的、相对简单的任务而设计的。
内存体系结构 :GPU 通常有自己的专用内存,这使得数据的读取和写入非常快。但这也意味着数据需要在主机(CPU)和设备(GPU)之间进行传输。
GPU 如何用于加速并行计算?
随着 GPU 的发展,人们逐渐意识到除了图形渲染之外,它们还可以用于其他类型的并行计算任务。以下是
GPU 用于并行计算的一些方式:
通用 GPU 计算 :人们开发了一系列工具和技术,如 NVIDIA 的 CUDA 和 OpenCL,允许开发人员直接为
GPU 编写代码,以执行非图形相关的计算任务。
大数据处理 :由于其并行性,GPU 非常适合处理大数据集。例如,在数据科学、金融建模和物理模拟中,可以使用
GPU 加速数据处理和分析。
深度学习和人工智能 :近年来,GPU 已经成为深度学习和 AI 研究的关键工具。神经网络的训练涉及大量的矩阵运算,这些运算可以在
GPU 上并行执行,从而大大减少训练时间。
分子建模和仿真 :GPU 可以用于并行处理与药物设计、气候模型和其他科学应用相关的复杂计算。
图形和视频处理 :除了传统的3D图形渲染,GPU 也被用于视频编解码、图像分析和其他多媒体任务。
总结:
GPU 由于其高度并行的结构和设计,已经从一个专门用于图形渲染的设备发展成为一个通用的、高性能的计算工具。从科学研究到商业分析,从游戏到艺术创作,GPU
在许多领域都发挥着关键作用,加速了各种各样的并行计算任务。
了解什么是 CUDA,以及它如何在 NVIDIA 的 GPU 上进行编程
CUDA(Compute Unified Device Architecture)是NVIDIA公司开发的一个并行计算平台和编程模型。它允许开发者直接使用NVIDIA的GPU来执行通用计算任务,从而获得比传统CPU计算更高的性能。CUDA基本上是将GPU从一个纯粹的图形渲染设备转变为一个通用并行处理器。
CUDA的主要特点:
并行处理 :NVIDIA的GPU由数千个处理核心组成,可以并行处理大量的任务。
适用于高度并行的计算任务 :如图形渲染、科学计算、深度学习等。
与C/C++语言集成 :CUDA提供了一个C语言的扩展,使得开发者可以在C/C++代码中直接编写运行在GPU上的函数(称为kernels)。
CUDA编程的基本概念:
Kernel :在GPU上运行的函数,可以并行处理多个数据元素。
Thread:执行kernel的基本单位。每个线程都会处理数据的一个或多个元素。
Block :线程的集合。一个block内的所有线程都可以共享一定的内存资源。
Grid :block的集合。整个grid是在GPU上并行执行kernel的所有线程的集合。
CUDA编程的基本步骤:
数据分配 :在主机(CPU)和设备(GPU)之间分配和初始化内存。
数据传输 :将数据从主机传输到设备。
Kernel启动 :指定grid和block的大小,并在GPU上启动kernel。
数据检索 :将结果从设备传输回主机。
清理 :释放设备和主机上的内存资源。
示例:向量加法
假设我们有两个大小为N的向量A和B,我们想要得到一个向量C,其中每个元素 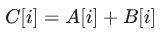
在CUDA中,此操作可以分解为以下步骤:
在主机上分配内存并初始化向量A和B。
在设备上为向量A、B和C分配内存。
将向量A和B从主机传输到设备。
定义一个kernel,其中每个线程处理一个元素的加法。
启动该kernel,指定足够多的线程以覆盖所有的向量元素。
将结果向量C从设备传输回主机。
释放所有分配的内存。
结论:
CUDA为开发者提供了一个强大的工具,可以轻松地利用NVIDIA GPU的并行计算能力。通过简单的C/C++扩展,开发者可以编写运行在GPU上的代码,而不需要深入了解图形编程或GPU架构的细节。这使得CUDA成为科学计算、机器学习、图形渲染等领域的流行选择。
设置 CUDA 环境
确认机器是否有NVIDIA的GPU的方法
1. 使用NVIDIA系统管理工具 (nvidia-smi)
如果您的系统上已经安装了NVIDIA的驱动程序,那么您可能已经有了 nvidia-smi这个工具。这是一个命令行工具,可以显示有关NVIDIA
GPU的详细信息。
在命令行或终端中运行以下命令:
运行结果
E:\>nvidia-smi
Mon Jul 24 14:05:47 2023
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 531.68 Driver Version: 531.68 CUDA Version: 12.1 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name TCC/WDDM | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce RTX 3060 L... WDDM | 00000000:01:00.0 Off | N/A |
| N/A 67C P8 14W / N/A| 0MiB / 6144MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
+---------------------------------------------------------------------------------------+
E:\>
|
在nvidia-smi的输出中,以下部分给出了关于NVIDIA软件和驱动的版本信息:
NVIDIA-SMI 531.68:这表示你正在使用的NVIDIA System Management
Interface (SMI)工具的版本号。SMI工具用于查询和控制NVIDIA GPU的状态和配置。
Driver Version: 531.68:这表示你的系统上安装的NVIDIA GPU驱动程序的版本号。这个数字通常与NVIDIA-SMI的版本匹配,因为它们都是驱动程序套件的一部分。
CUDA Version: 12.1:这表示与你的驱动程序兼容的CUDA版本。CUDA是NVIDIA的并行计算平台和应用程序接口,允许开发者使用NVIDIA
GPU进行通用计算。需要注意的是,这表示驱动程序支持的CUDA版本,但不一定是你系统上实际安装的CUDA工具包版本。
总的来说,这些版本信息对于确保软件和硬件的兼容性、进行故障排除、以及确定是否需要软件或驱动程序更新都很重要。
上面显示中的名词解释(链接):GPU、Name、TCC、WDDM、Disp.A、Volatile
Uncorr. ECC、Fan、Temp、Perf、Pwr:Usage/Cap、Memory-Usage、GPU-Util、Compute
M.、MIG M.、N/A。
如果您的机器上有NVIDIA GPU,并且已经安装了驱动程序,该命令将显示关于GPU的信息,包括型号、驱动版本、温度、利用率等。
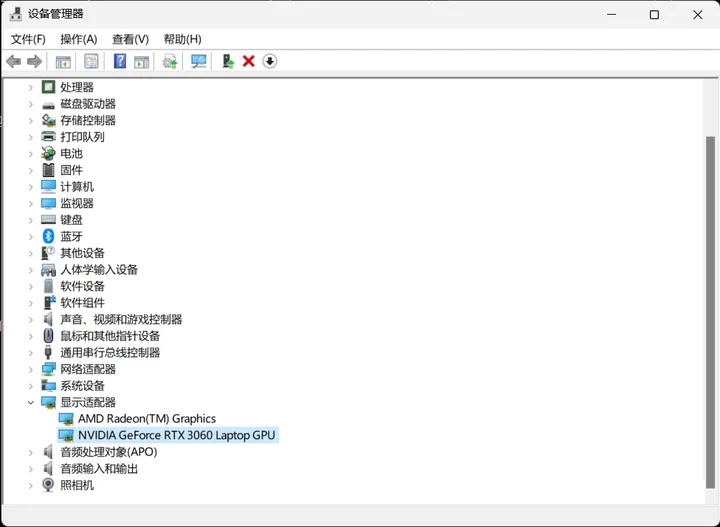
2. 查看设备管理器 (仅限Windows)
打开"设备管理器"(可以在开始菜单中搜索"设备管理器")。
在"设备管理器"窗口中,展开"显示适配器"部分。
在那里,您应该能够看到所有的显卡,包括NVIDIA GPU(如果有的话)。
判断NVIDIA的GPU是否支持CUDA
1. 使用 nvidia-smi
如果你已经安装了NVIDIA驱动,你可以使用 nvidia-smi命令来查看GPU的详细信息。在命令行或终端中运行:
这将显示一个关于你的NVIDIA GPU的详细报告。如果你的GPU支持CUDA,它会在输出中列出,并显示CUDA版本。
我的运行结果
E:\>nvidia-smi
Mon Jul 24 14:05:47 2023
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 531.68 Driver Version: 531.68 CUDA Version: 12.1 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name TCC/WDDM | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce RTX 3060 L... WDDM | 00000000:01:00.0 Off | N/A |
| N/A 67C P8 14W / N/A| 0MiB / 6144MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
+---------------------------------------------------------------------------------------+
E:\>
|
结果分析
从您给出的 nvidia-smi输出中,我们可以得到以下关于CUDA的信息:
是否支持CUDA :由于您的输出中显示了"CUDA Version: 12.1",这意味着您的NVIDIA
GPU确实支持CUDA。
CUDA的版本 :
驱动支持的CUDA最大版本 :在输出中的"CUDA Version: 12.1"表示您的NVIDIA驱动程序支持的CUDA最大版本是12.1。这不是您实际安装的CUDA工具包版本,而是驱动程序兼容的最高版本。
正在使用的CUDA版本 :要查找实际安装的CUDA工具包版本,您需要检查CUDA安装目录(比如:C:\Program
Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7)或使用特定的CUDA
API/functions。在您的 nvidia-smi输出中,"Driver Version:
531.68"只是告诉我们您的NVIDIA驱动程序版本,而不是您正在使用的CUDA版本。
GPU型号 :您的GPU是NVIDIA GeForce RTX 3060 Laptop GPU。这是一款支持CUDA的现代GPU。
总之,从您的 nvidia-smi输出中,我们可以确认您的GPU支持CUDA,并且您的驱动程序支持的最大CUDA版本是12.1。但要确定您实际安装并正在使用的CUDA版本,您需要查看CUDA的安装目录或使用其他方法。
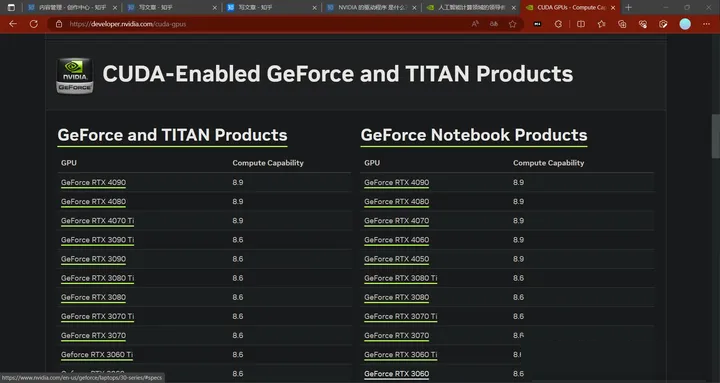
2. 查看NVIDIA的官方支持列表
NVIDIA在其官方网站上有一个CUDA GPUs的支持列表。你可以访问这个列表来查看你的GPU型号是否被列出。如果它在列表上,那么它肯定支持CUDA。
以下是一个直接链接到NVIDIA CUDA GPUs的支持列表的链接(请注意,随着时间的推移,链接可能会发生变化,因为NVIDIA可能会更新其网站结构):
NVIDIA CUDA GPUs支持列表
点击链接将带您到一个页面,列出了各种NVIDIA GPU和它们支持的CUDA计算能力。您可以在此列表中查找您的GPU型号,以确定它是否支持CUDA。
3. 使用CUDA工具
如果你已经安装了CUDA工具包,你可以使用 deviceQuery实用程序来检查你的GPU是否支持CUDA。通常,这个实用程序位于CUDA安装目录下的
CUDA\v11.7\extras\demo_suite子目录中。运行 deviceQuery会显示关于你的GPU的信息,包括它是否支持CUDA。
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\extras\demo_suite>deviceQuery.exe
deviceQuery.exe Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "NVIDIA GeForce RTX 3060 Laptop GPU"
CUDA Driver Version / Runtime Version 12.1 / 11.7
CUDA Capability Major/Minor version number: 8.6
Total amount of global memory: 6144 MBytes (6441926656 bytes)
(30) Multiprocessors, (128) CUDA Cores/MP: 3840 CUDA Cores
GPU Max Clock rate: 1425 MHz (1.42 GHz)
Memory Clock rate: 7001 Mhz
Memory Bus Width: 192-bit
L2 Cache Size: 3145728 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: zu bytes
Total amount of shared memory per block: zu bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 1536
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: zu bytes
Texture alignment: zu bytes
Concurrent copy and kernel execution: Yes with 1 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
CUDA Device Driver Mode (TCC or WDDM): WDDM (Windows Display Driver Model)
Device supports Unified Addressing (UVA): Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: No
Device PCI Domain ID / Bus ID / location ID: 0 / 1 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 12.1, CUDA Runtime Version = 11.7, NumDevs = 1, Device0 = NVIDIA GeForce RTX 3060 Laptop GPU
Result = PASS
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\extras\demo_suite>
|
部分解释(链接):Runtime API、CUDART static linking、CUDA Capability
Major/Minor version number、Total amount of global
memory、(30) Multiprocessors, (128) CUDA Cores/MP、GPU
Max Clock rate、Memory Clock rate、Memory Bus Width、L2
Cache Size、Maximum Texture Dimension Size (x,y,z)、Maximum
Layered 1D Texture Size, (num) layers、Maximum Layered
2D Texture Size, (num) layers、Total amount of constant
memory。
4. 使用第三方软件
有一些第三方软件和应用程序,如GPU-Z,可以显示关于你的GPU的详细信息,包括是否支持CUDA。
总之,有多种方法可以检查你的NVIDIA GPU是否支持CUDA。最简单和最直接的方法是使用 nvidia-smi或查看NVIDIA的官方支持列表。如果你打算进行CUDA编程或使用CUDA应用程序,确保你的GPU支持CUDA是非常重要的。
安装 NVIDIA 的驱动程序(一般电脑上是装有的,如果没有再自己装)
安装 NVIDIA 的驱动程序是一个相对直接的过程,但为了确保驱动程序的稳定性和兼容性,建议遵循以下步骤:
检查显卡型号 :
在 Windows 中,可以右键点击“开始”按钮,选择“设备管理器”,然后展开“显示适配器”来查看显卡型号。
在 Linux 中,可以在终端中运行 lspci | grep -i nvidia 命令。
下载驱动程序 :
访问 NVIDIA 官方网站的驱动下载页面。
根据你的显卡型号、操作系统等选择相应的选项,然后点击“搜索”。
在搜索结果中,选择与你的显卡和操作系统最匹配的驱动版本并下载。
卸载旧的驱动程序 (建议但不是必需):
为了避免旧驱动与新驱动之间的冲突,建议先卸载旧的驱动程序。
在 Windows 的“控制面板” -> “卸载程序”中,找到 NVIDIA 相关的程序并卸载。
重启计算机。
安装新驱动程序 :
双击你刚刚下载的 NVIDIA 驱动程序安装包。
如果出现 UAC 提示,选择“是”。
选择“NVIDIA Graphics Driver”软件组件以及其他相关组件(如 NVIDIA GeForce
Experience),然后点击“下一步”。
选择“快速”(推荐)或“高级”安装,然后点击“下一步”。
安装程序将自动安装驱动程序并可能需要几次重启。
验证安装 :
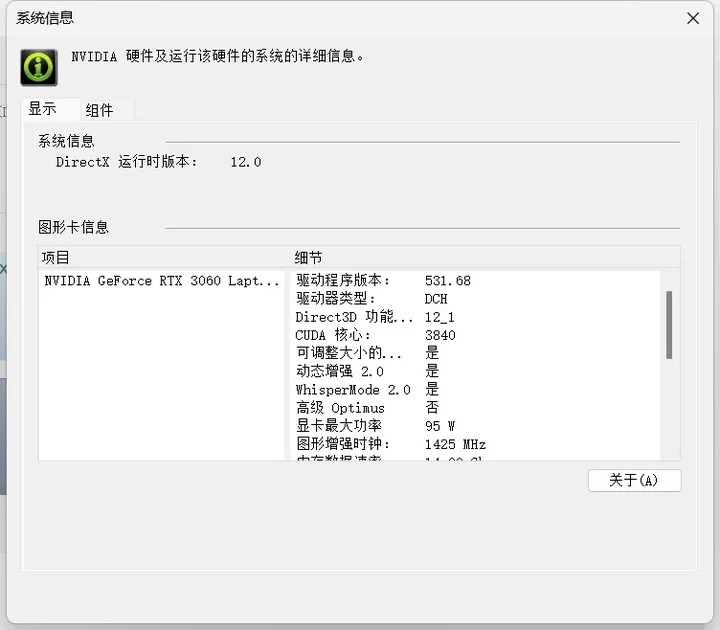
重启计算机后,可以右键点击桌面并选择 NVIDIA 控制面板来验证驱动程序是否正确安装。
如果控制面板正常打开并显示了所有相关的设置和选项,那么这通常意味着驱动程序已经正常安装。
在“系统信息”部分,您可以查看到驱动程序的版本、CUDA版本以及其他与显卡相关的信息。
另外,可以使用之前提到的 nvidia-smi 命令(如果已安装)来查看驱动详细信息。
如果驱动程序正常安装,nvidia-smi 会显示有关安装的NVIDIA驱动的信息,包括但不限于驱动版本、CUDA版本、GPU名称、温度、使用率等。
如果您收到如“NVIDIA 不是内部或外部命令,也不是可运行的程序或批处理文件”的错误消息,或者与此类似的消息,那么可能驱动程序没有正确安装或配置。
优化设置 (可选):
打开 NVIDIA 控制面板,你可以根据你的需要调整各种图形设置,例如 3D 设置、分辨率和多显示器设置等。
注意:在安装驱动程序时,确保关闭所有正在运行的应用程序和游戏,以避免任何潜在的问题。
安装 CUDA 工具包
我之前已经装过了,这一步没具体实操,如果有问题可以找其他相关攻略
当你想要在NVIDIA GPU上运行和开发CUDA加速应用时,你需要安装CUDA工具包。以下是详细的步骤,解释如何在Windows环境中安装CUDA工具包:
系统要求:
一个带有CUDA支持的NVIDIA GPU。
对应的NVIDIA驱动。
支持的操作系统(例如,Windows 10、Linux发行版)。
下载CUDA工具包:
访问NVIDIA官方网站的CUDA下载页面。
根据你的操作系统和版本选择合适的CUDA版本。
为Windows,你会看到一个EXE安装程序。点击下载。
安装:
双击下载的 .exe文件以启动安装程序。
选择“Express”(快速安装)或“Custom”(自定义安装)。
如果你不确定,建议选择“Express”。
等待安装程序安装所有组件。这可能需要一些时间,因为CUDA工具包包括编译器、库文件、头文件和其他工具。
环境变量:
为了在命令行或脚本中方便地使用CUDA,你可能需要将CUDA的 bin目录添加到系统的 PATH环境变量中。
默认情况下,CUDA通常安装在 C:\Program Files\NVIDIA GPU Computing
Toolkit\CUDA\vX.Y目录下,其中 X.Y是你的CUDA版本。
验证安装:
验证CUDA的安装是否成功是一个重要步骤,确保你的环境已经配置正确并且可以正常使用。以下是一些步骤和方法来验证CUDA的安装是否成功:
检查CUDA版本:
打开终端或命令提示符,输入以下命令:
如果CUDA已正确安装,此命令应显示 nvcc的版本信息。
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\extras\demo_suite>nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Tue_May__3_19:00:59_Pacific_Daylight_Time_2022
Cuda compilation tools, release 11.7, V11.7.64
Build cuda_11.7.r11.7/compiler.31294372_0
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\extras\demo_suite>
|
运行CUDA示例程序:
CUDA安装包通常会包含一些示例程序。这些示例程序位于CUDA的安装目录下的 \CUDA\v11.7\extras\demo_suite文件夹中。
如果 deviceQuery 和 bandwidthTest 位于 C:\Program Files\NVIDIA
GPU Computing Toolkit\CUDA\v11.7\extras\demo_suite,那么你可以使用它们来验证CUDA是否正确安装。
打开命令提示符或PowerShell并导航到相应的目录:
cd C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\extras\demo_suite
|
运行deviceQuery:
这个程序将列出系统中所有NVIDIA GPU的详细信息。如果它正确列出了你的GPU,并指出了GPU支持的CUDA版本,那么你可以确信CUDA运行时已经正确安装。
运行结果上面放过了,这里不再重复。
运行bandwidthTest:
这个程序将测试GPU的内存带宽。它是一个简单的性能测试,可以让你知道GPU的内存带宽是否与规格书上的相符。
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\extras\demo_suite>bandwidthTest.exe
[CUDA Bandwidth Test] - Starting...
Running on...
Device 0: NVIDIA GeForce RTX 3060 Laptop GPU
Quick Mode
Host to Device Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 6516.1
Device to Host Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 6428.5
Device to Device Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 235205.0
Result = PASS
NOTE: The CUDA Samples are not meant for performance measurements. Results may vary when GPU Boost is enabled.
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\extras\demo_suite>
|
这是bandwidthTest.exe的输出结果,这个测试给出了你的NVIDIA GeForce RTX
3060 Laptop GPU在不同数据传输场景中的内存带宽。这些数字可以为你提供关于你的GPU在实际应用中可能的性能表现的参考。
如果这两个程序都能正常运行并产生期望的输出,那么可以认为CUDA已经成功安装并且可以在你的系统上正确运行。
检查环境变量:
确保CUDA的二进制文件和库的路径已经被添加到你的 PATH和 LD_LIBRARY_PATH(在Linux上)或
PATH(在Windows上)环境变量中。
使用NVIDIA System Management Interface (nvidia-smi):
在终端或命令提示符中输入:
此命令应该显示关于你的NVIDIA GPU的信息,包括驱动版本、GPU温度、内存使用情况等。此工具的输出还会显示CUDA版本。
通过上述步骤,你应该能够确认CUDA是否已经成功安装在你的计算机上,并且可以正常工作。如果遇到任何问题或错误消息,你可能需要检查安装过程中的步骤,或查阅NVIDIA的官方文档和社区论坛以获取帮助。
安装其他工具(可选):
NVIDIA Nsight Visual Studio Edition:这是一个集成开发环境(IDE),用于CUDA开发。
cuDNN:这是一个深度神经网络库,如果你打算进行深度学习开发,可能会需要它。
NCCL:用于多GPU和多节点通信的库。
完成上述步骤后,你应该已经成功地在你的机器上安装了CUDA工具包,现在可以开始开发和运行CUDA应用程序了。 |







 订阅
订阅