虽然我是一个面向对象实现途径(指前文的使用POJO和LIGHTFRAMEWORK)的倡导者,但是有些情况下面向对象实现途径有些大材小用,比如你只想实现一个非常简单的业务逻辑。而且,有时候,面向对象实现途径不太可行-—比如,你没有持久层构架来将你的对象映射到数据库中,在这种情况下,更好的方法是编写面向过程的代码,而且采用Martin
Fowler称作事务脚本(Transaction Script)的设计模式,要比采用面向对象实现途径设计要好,因为你只需要写一个方法来调用事务处理脚本去处理表示层的请求。
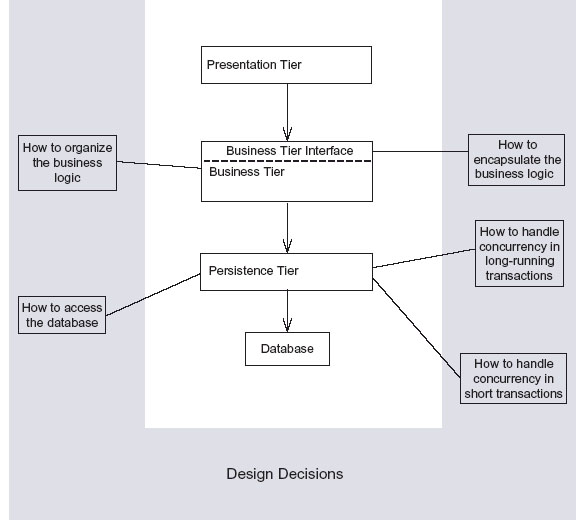
采种这种实现途径的一个很重要的特点是,用于实现某种行为的类和数据存储区是分开的。在EJB2的应用程序中,这种方式的业务逻辑和图表2中的设计是非常相似的。这种设计的核心全都集中在EJB或者POJO的行为上,因为他们实现了事务脚本,并且还操作那些
“哑”对象数据(因为他们只拥有很少的行为,大部分都是数据)。因为大部分的行为都集中在少量的大型类上,所以代码会变的很难理解与维护。
Figure 2. The structure of a procedural design: large transaction
script classes and many small data objects
这种设计具有高面向过程的特性,而且基本不依靠面向对象语言的特性。如果你曾经使用过C或者其他非面向对象语言的话,你应该用过这种设计模式。如果这种模式很适合你的设计的话,用这种模式设计也是一种不错的选择。
这种直观的过程式开发途径,非常的诱人,因为你只需要写代码就好了,不用考虑如何组织你的类文件。但问题是,如果你的业务逻辑非常的复杂,那么你的代码会变的噩梦般的难以维护。所以,除非你要写的程序非常的简单,否则你应该用面向对象设计你的程序,而不要受面向过程的代码的诱惑。
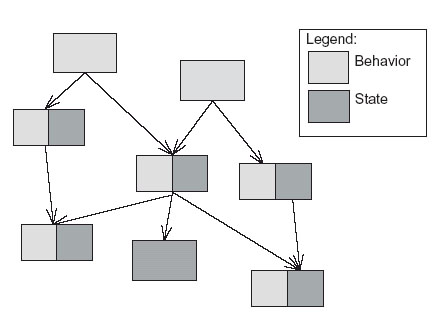
在面向对象设计中,业务逻辑是由对象模型构成的,对象模型是由许多小类组成的关系网。这些类直接体现的是问题域的解决方法,如图3所示,在这种模式中,有些类只有数据,有些类只有行为,但是大多数的则两者都有,这是优秀的类设计的一种特点。
Figure 3. The structure of a domain model: small classes
that have state and behavior
面向对象设计有许多的好处,包括可以提高可维护性和可延展性。你可以用EJB2的实体bean来实现一个简单的对象模型。但是如果像要获得更多的好处的话,必须要使用POJOs技术和轻量级持久层构架——比如Hibernate和JDO技术。POJO可以让你开发丰富的模型,这些模型可以拥有继承和回调等特点。而轻量级持久层构架可以让你很简单的从对象模型映射到数据库。
对象模型的另外一个名字是域模型,Fowler称这种由面向对象途径来开发的业务逻辑叫做域模型设计模式。(就是类的设计是直接用来解决问题的,则这种设计模式叫做域模型设计模式)
表模型设计模式
我曾经一直用域模型和事务处理脚本模型设计应用程序。但是有一次我听说JAVA企业应用程序可以用第三种途径来实现,这种途径就是Fowler所说的表模型设计模式。这种模式比事务处理脚本模式更加的结构化,因为它为数据库中的每个表都写了一个类,而这个类中实现了所有对这个表的操作代码,这个类就是表模型类。(我的解释就是为每个表专门写个类,对表的所有操作,全都由这个类中的方法实现,相当于用一个类模拟的数据库中的表)。和事务处理脚本模式相比,它将数据和行为分别封装到了不同的类中,因为表模型类的实例相当于真实数据库中的数据,这当然要比单独的一条记录要好的多。最后,可维护性成了问题,然而表模型设计模式还是有一些好处的。
决策2:封装业务逻辑
前面几章,我没有提及如何组织业务逻辑。你必须决定业务逻辑有什么样的接口。业务逻辑的接口由一些数据和方法组成,这些数据和方法由表示层来调用。在设计接口时重点需要考虑的是:应该封装哪些业务逻辑的操作,而哪些操作不应该显示给表示层。封装接口可以提高程序的可维护性,因为通过隐藏业务逻辑的操作细节,可以实现修改业务逻辑而不影响表示层。缺点是,你必须为封装业务逻辑而特意的写很多的代码。
你还需要考虑其他重要的问题,比如如何处理事务处理,安全,和远程调用问题。通常这些也是业务逻辑接口要负责的问题。为了保证数据的连贯性,业务层的接口必须保证每个事务处理中的调用都能执行。同样,也要验证调用者是否有权限调用业务方法。业务层接口还要负责处理一些远程客户端的问题。
来考虑一下选项。
EJB session faç;ade
经典的J2EE解决方案是:用EJB来封装业务逻辑-基本的session facade.EJB容器提供事务处理管理,安全,分布式事务处理和远程访问。Facade方式可以通过封装业务逻辑来提高程序可维护性。粗糙型(Coarse-grained)
API通过减少表示层对业务层的访问次数,而提高性能(因为它将对各个业务流程的处理再封装了一次,所以对底层的业务流程来说,它的API是比较粗糙的,这里也许翻译的不好。请大家见谅)。因为减少调用的次数,可以减少对数据库事务处理的次数,还可以提高对象在缓冲区的机会。如果表示层通过远程访问业务层,则这种API还可以减少网络负担。图表4给出了一个EJB-based
session facade的例子。
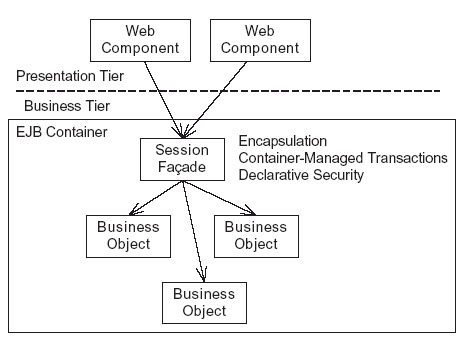
Figure 4. Encapsulating the business logic with an EJB
session faç;ade
在这种设计模式中,表示层也许是通过远程来调用facade(相当于session的一个高级接口),EJB容器从facade中得到这个调用,并验证调用者的权限,然后开始一个业务处理。这个时候facade调用底层的业务对象,而这些业务对象负责实现具体的业务逻辑。等Facade返回后,EJB容器提交业务处理或者让该业务处理循环等待。
不幸的是,使用EJB session facade有一些严重的缺点。比如,EJB的会话bean只能在EJB容器中运行,这样就托慢了开发和测试周期。另外,如果用EJB2,则用来向表示层传输数据的数据传输对象的开发和维护就会变的很枯燥而且旷日持久。
POJO facade
对于许多程序来说,更好的实现途径是用POJO facade和AOP协作。比如负责管理事务处理、表示层的连接和安全问题的Spring
构架。POJO facade对业务层的封装风格和EJB facade很相似,通常也可以用一样的公共方法。而POJO和EJB关键区别是用POJO代替了EJB,用AOP提供的服务(例如业务处理管理和安全机制)替代了EJB容器。表5中,显示了用POJO
facade的例子。
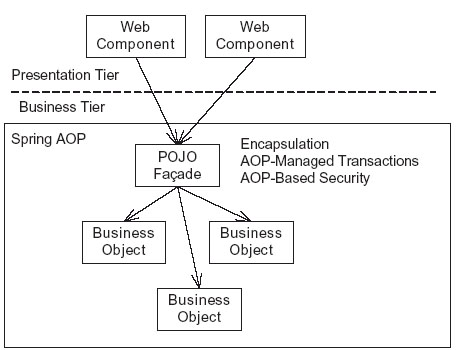
Figure 5. Encapsulating the business logic with a POJO
faç;ade
表示层调用POJO facade, POJO facade 调用业务对象。和EJB容器截获EJB facade方式一样,AOP通过“拦截机”来截获POJO
facade,并验证调用者的权限,然后开始提交业务处理或让该业务循环等待。
通过在应用程序服务器外部开发和调试业务逻辑,对POJO facade的开发可以变的很简单,同时还可以获得许多EJB中会话Bean的好处,比如声明事务处理和安全。关键是,你可以少写点代码。你可以避免写数据传输对象类,因为POJO
facade可以将对象域直接反馈给表示层;你可以使用依赖注射的方式来将应用程序组装起来,而不用在为JNDI写查找代码了。
然而,有些时候不能那用POJO facade,比如它不能参与到远程客户端建立的分布式事务处理。
暴露模型域模式
使用facade的一个缺点是你必须写额外的代码,而且负责将对象域返回给表示层的代码很容易出错。如果表示层设法调用某个对象,而业务层却没有提供该对象,也会增加runtime
error出现的机会。如果你用JDO , Hibernate或者EJB3,则可以避免这种问题,方法是:将模型域(session区域)暴露给表示层,再将相应的对象域(存储对象的区域)返回给表示层,根据表示层在对象域之间的操作关系,持久层来导入相应的对象。(也就是把session区域给表示层,然后分析它需要的对象,再让持久层去加载这些对象)这就是所谓的lazy
loading 技术。图表6中显示了表示层自由的访问对象域的设计图。
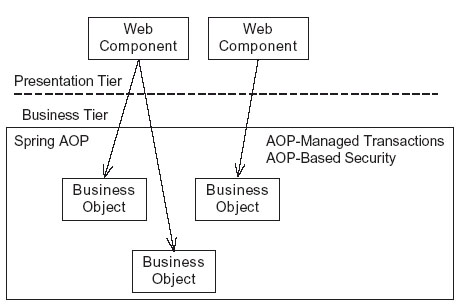
Figure 6. Using an exposed domain model
在图表6的设计中,表示层不通过facade而直接调用域对象,Spring AOP仍然提供服务,例如事务处理管理和安全。
用这种实现途径的一个重要的好处是,业务层不需要知道哪些对象需要调用,也不用知道那些需要返回给表示层。尽管这挺起来很简单,但是你会发现一些缺点。这会增加表示层的复杂度,因为你必须处理对数据库的连接。而且在基于Web的应用程序中,事务处理管理也要非常小心,因为在表示层将数据反馈给浏览器之前,事务处理的数据必须保持正确。
决策3:访问数据库
无论你怎样对业务逻辑怎样的组织和封装,最终你还是要从数据库中取数据出来。在经典的J2EE应用程序中,你有2个选择:JDBC——这个需要很多的底层代码;或者实体Bean——这个用起来非常困难,而且缺少重要特征。相比来说,使用轻量级构架令人高兴的事情之一就是:你有一些新的而且更有力的方法去访问数据库,而且这种方法可以显著的减少访问数据库的代码。让咱们来进一步研究
直接用JDBC会有什么问题
最近突然出现了对象/关系 映射构架(比如JDO和Hibernate) 和SQL映射构架(比如iBATIS)这些不是凭空出现的。相反,他们是在JAVA
联盟在JDBC屡造挫折之后才出现的。为了了解新构架出现的原因,这里咱们回顾一下直接使用JDBC会出现的问题。在许多程序中直接使用JDBC不是一个好的选择,主要有以下三个原因:。
开发和维护SQL非常的困难而且耗费时间——一些开发者发现要写庞大而且复杂的SQL语句非常的困难。反映数据库变化的SQL语句会变得非常耗时。你必须小心的考虑牺牲可维护性是否值得。。
用SQL会使移植性变的很差——因为需要数据库的特殊SQL语句。如果一个程序和多个数据库有关系,那么你就要写多个版本的SQL语句,这使得可维护性变变成噩梦。。
直接写JDBC代码要会非常耗时,而且容易出错。你必须写很多的样板代码去获得连接,创建和初始化适当的声明,还要用精确的声明去清理连接。而且你还要写代码去将JAVA
对象映射到SQL声明。由于要无奈的去写,JDBC代码很容易出错。
如果你的程序必须直接运行SQL语句的话,那前面两个问题是无法避免的。有时候为了获得好的性能,必须要全力的写SQL语句,包括供应商提供的那些特殊东西。由于许多业务上的原因,持久层可能会产生混乱的SQL语句,为了防止这种情况,DBA可能要求你的程序来完全控制SQL语句的执行。通常,团队买进的关系型数据库过于庞大,以至于应用程序工作时会出现一些和数据库有关的琐碎事务。根据“iBATIS
in Action”的作者说这里会有一种情况出现:“数据库或者SQL语句本身存在的时间比程序代码存在的时间还要长,或者同一段SQL语句或数据库有多个程序的版本。有些情况下,程序已经用另外一种语言重写了,但是SQL语句和数据库却没有太大的改变。”
如果直接使用SQL弄的你筋疲力尽,那么很幸运,这里有一种直接执行SQL语句的构架,它可比用JDBC要容易多了。当然了,这就是iBATIS.
使用iBATIS
我开发过的所有企业JAVA应用程序,都是直接执行SQL语句的。早期的程序是执行特定的SQL语句的,后来是用持久层构架再用少量的SQL语句构成的。一开始我直接用JDBC来执行SQL语句,但是后来,我经常写一些小的构架去完成JDBC中那些比较无聊的部分。我也用过一段Spring的JDBC类,这些类除去了JDBC中的许多样板代码。但是无论是我自己写的构架还是使用Spring的类,在Java类映射到SQL语句的时候都会存在问题,这就是我为什么那么高兴的加入iTATIS
那边的原因了。
iBATIS 不仅将应用程序完全的与“数据库连接”、具体的SQL语句隔绝开来,更实现了通过XML描述文档来将JavaBean
映射到SQL语句。它用Java bean 内省机制来将“道具bean(bean properties)”映射为相应的数据库语句占位符,而且它可以将ResultSet后的结果构造为bean.它还可以通过数据库生成主键,自动加载相关的对象、实现缓存和lazy
loading.这样,iBATIS 就除去了许多执行SQL语句带来的苦差。通过编辑XML描述文档和调用少量的iBATIS的API,代替了写大量的JDBC底层代码。