| ±ύΦ≠ΆΤΦω: |
| ±ΨΈΡά¥Ή‘”Ύ51ctoΘ§±ΨΈΡ÷ς“ΣΫι…ήΆ®Ιΐ Ι”ΟDocker»ίΤςΘ§Ϋι…ήΝΥ―©«ρ «»γΚΈ‘Ύ“ΒΈώ÷–“ΐ»κΚΆ Ι”ΟΒΡΓΘ |
|
±ΨΈΡ÷ς“ΣΖ÷ΈΣ»γœ¬»ΐΗωΖΫΟφΗζ¥σΦ“Ζ÷œμ―©«ρ‘Ύ“ΒΈώ÷–“ΐ»κΚΆ Ι”Ο»ίΤςΦΦ θΒΡ–Ρ¬Ζάζ≥ΧΘΚ
1.ΈΣ ≤Ο¥“Σ“ΐ»κ Docker
2.Docker ‘Ύ―©«ρΒΡΦΦ θ ΒΦυ
3.Κσ–χ―ίΫχ
―©«ρ «“ΜΗωΆΕΉ ’ΏΫΜΝςΒΡ…γ«χΘ§”ΟΜßΩ…“‘‘Ύ…œΟφ¬ρ¬τΙ…Τ±Θ§¥ζœζΜυΫπΒ»Ης÷÷Ϋπ»Ύ―ή…ζ“ΒΈώΘ§Ά§ ±“≤Ω…“‘Ά®Ιΐ―©”·÷Λ»·ά¥Ϋχ––ΜΠΓΔ…νΓΔΗέΓΔΟάΙ…ΒΡΫΜ“ΉΓΘ
ΈΣ ≤Ο¥“Σ“ΐ»κ Docker
ΥφΉ≈“ΒΈώΒΡΖΔ’ΙΘ§≤ΜΆ§ΒΡ…γ«χ“ΒΈώ÷°ΦδΥυ ήΒΫ”ΑœλΒΡΗ≈¬ ’ΐ‘Ύ÷πΫΞ…ΐΗΏΘ§“ρ¥ΥΈ“Ο«œΘΆϊΗςΗω“ΒΈώ÷°ΦδΦ»ΡήΙΜ≤Μ±Μ¥ρ»≈Θ§”÷Ρή‘ΎΉ ‘¥…œΓΔΜζΤςΦδΓΔ…θ÷ΝΆχ¬γ…œΗυΨίΦύΙήΒΡ“Σ«σ”η“‘≤ΜΆ§≤ψΟφΒΡΗτάκΓΘ
‘γ‘Ύ 2014 Ρξ ±Θ§Έ“Ο«ΨΆΖΔœ÷»ίΤςΦΦ θΨΏ”–±Ψ…μΨΒœώ–ΓΓΔΝιΜνΓΔΤτΕ·ΥΌΕ»ΩλΒ»ΧΊΒψΘ§Εχ«“‘Ύ–‘Ρή…œ±»Ϋœ Κœ”ΎΈ“ϫ± ±ΈοάμΜζ≤ΜΕύΒΡΙφΡΘΜΖΨ≥ΓΘ
œύ±»Εχ―‘Θ§¥ΪΆ≥ΒΡ–ιΡβΜ·ΦΦ θ≤ΜΒΪ Βœ÷≥…±ΨΗΏΘ§Εχ«“–‘ΡήΥπΚΡ“≤≥§Ιΐ 10%ΓΘ“ρ¥ΥΘ§Μυ”ΎΕ‘ΨΒœώ¥σ–ΓΓΔΤτΕ·ΥΌΕ»ΓΔ–‘ΡήΥπΚΡΓΔΚΆΗτάκ–η«σΒΡΉέΚœΩΦ¬«Θ§Έ“Ο«―Γ”ΟΝΥΝΫ÷÷»ίΤς“ΐ«φΘΚLXC
ΚΆ DockerΓΘ
Έ“Ο«Α― MySQL ÷°άύ”–Ή¥Χ§ΒΡΖΰΈώΖ≈‘Ύ LXC άοΘΜΕχΫΪœΏ…œ“ΒΈώ÷°άύΈόΉ¥Χ§ΒΡΖΰΈώΖ≈‘Ύ Docker
÷–ΓΘ

»ίΤς Ι”ΟΖΫΖ®
÷ΎΥυ÷ή÷ΣΘ§Docker «“‘άύΥΤ”ΎΒΞΜζΒΡ»μΦΰ–ΈΧ§Έ άΒΡΘ§Ήν≥θΥϋΒΡ–ϊ¥ΪΩΎΚ≈ «ΘΚBuild/Ship/RunΓΘ
“ρ¥ΥΥϋ‘γΤΎΒΡ WorkflowΘ®Νς≥ΧΘ© «ΘΚ
1.‘Ύ“ΜΧ® Host ÷ςΜζ…œœ»‘Υ–– Docker BuildΓΘ
2.»ΜΚσ‘Υ”Ο Docker PullΘ§¥”ΨΒœώ≤÷ΩβάοΑ―ΨΒœώά≠œ¬ά¥ΓΘ
3.ΉνΚσ Ι”Ο Docker RunΘ§ΨΆ”–ΝΥ“ΜΗω‘Υ––ΒΡ ContainerΓΘ
–η“ΣΫβΨωΒΡΈ Χβ
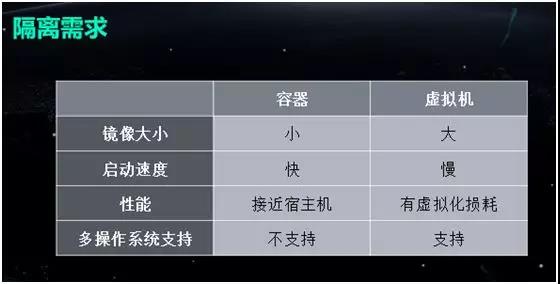
…œ ωΒΡΝς≥ΧΖΫΑΗΑιΥφΉ≈»γœ¬”–¥ΐΫβΨωΒΡΈ ΧβΘΚ
1.Άχ¬γΝ§Ά®–‘Θ§”…”Ύ «ΒΞΜζ»μΦΰΘ§Docker Ήν≥θΡ§»œ Ι”ΟΒΡ « Bridge
ΡΘ ΫΘ§≤ΜΆ§Υό÷ςΜζ÷°ΦδΒΡΆχ¬γ≤Δ≤ΜœύΆ®ΓΘ“ρ¥ΥΘ§‘γΤΎ¥σΦ“ΫΜΝςΉνΕύΒΡΨΆ «»γΚΈΫβΨωΆχ¬γΝ§Ά®–‘ΒΡΈ ΧβΓΘ
2.ΕύΫΎΒψΒΡΖΰΈώ≤Ω π”κΗϋ–¬Θ§‘Ύ…œ¬μΗΟ»ίΤςΖΫΑΗ÷°ΚσΘ§Έ“Ο«ΖΔœ÷”…”Ύ±Ψ…μ–‘ΡήΥπΚΡ±»Ϋœ–ΓΘ§ΤδΫΎΒψΒΡ ΐΝΩΜα≥ωœ÷±§’® Ϋ‘ω≥ΛΓΘ
“ρ¥ΥΘ§ΆυΆυΜα≥ωœ÷“ΜΧ®ΈοάμΜζ…œΡήΙΜ‘Υ––ΦΗ °ΗωΫΎΒψΒΡΉ¥ΩωΓΘ»ίΤςΫΎΒψΒΡΨχΕ‘ ΐΝΩΜα±»ΈοάμΫΎΒψΒΡ ΐΝΩ¥σ“ΜΗω ΐΝΩΦΕΘ§…θ÷ΝΗϋΕύΓΘΡ«Ο¥’βΟ¥ΕύΫΎΒψΒΡΖΰΈώ≤Ω π”κΗϋ–¬Θ§÷±Ϋ”ΒΦ÷¬ΝΥΙΛΉςΝΩΒΡ±Ε ΐ‘ωΦ”ΓΘ
3.ΦύΩΊΘ§Ά§ ±Θ§Έ“Ο«–η“ΣΈΣ’βΟ¥ΕύΫΎΒψΒΡ‘Υ––Ή¥Χ§≤…”ΟΚœ ΒΡΦύΩΊΖΫΑΗΓΘ
Docker ‘Ύ―©«ρΒΡΦΦ θ ΒΦυ
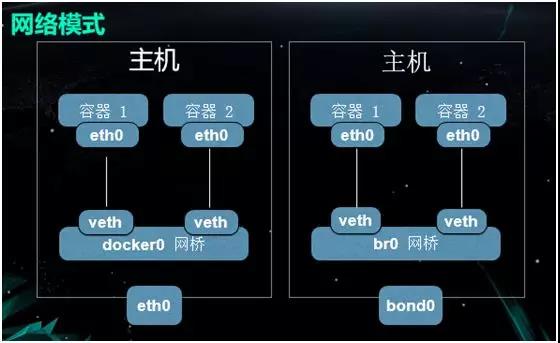
Άχ¬γΡΘ Ϋ
Ήœ»Ηχ¥σΦ“Ϋι…ή“Μœ¬Έ“Ο«‘γΤΎΒΡΆχ¬γΫβΨωΖΫΑΗΘΚ‘Ύ…œΆΦΒΡΉσ±ΏΘ§Έ“Ο«Ρ§»œ≤…”ΟΒΡ « Docker ΒΡ Bridge
ΡΘ ΫΓΘ
¥σΦ“÷ΣΒάΘ§Ρ§»œ«ιΩωœ¬ Docker Μα‘ΎΈοάμΜζ…œ¥¥Ϋ®“ΜΗωΟϊΈΣ docker0 ΒΡΆχ«≈ΓΘ
ΟΩΒ±“ΜΗω–¬ΒΡ Container ±Μ¥¥Ϋ® ±Θ§ΥϋΨΆΜαœύ”ΠΒΊ¥¥Ϋ®≥ω“ΜΗω vethΘ§»ΜΚσΫΪΤδΝ§ΒΫ»ίΤςΒΡ
eth0 …œΓΘ
Ά§ ±Θ§ΟΩ“ΜΗω veth ΕΦΜα±ΜΖ÷≈δΒΫ“ΜΗωΉ”ΆχΒΡ IP ΒΊ÷ΖΘ§“‘±Θ≥÷”κœύΆ§÷ςΜζάοΗςΗω»ίΤςΒΡΜΞΆ®ΓΘ
”…”Ύ‘Ύ…ζ≤ζΜΖΨ≥÷–≤Μ÷Μ“Μ’≈ΆχΩ®Θ§“ρ¥ΥΈ“Ο«Ε‘ΥϋΫχ––ΝΥΗΡ‘λΓΘΈ“Ο«≤ζ…ζΝΥ“ΜΗωΓΑΆχΩ®ΑσΕ®Γ±Θ§Φ¥…ζ≥…ΝΥ bond0
ΆχΩ®ΓΘΈ“Ο«Ά®Ιΐ¥¥Ϋ®“ΜΗω br0 Άχ«≈Θ§ά¥ΧφΜΜ‘≠ά¥ΒΡ docker0 Άχ«≈ΓΘ
‘ΎΗΟ br0 Άχ«≈÷–Θ§Έ“Ο«Υυ≈δ÷ΟΒΡΆχΕΈΚΆΈοάμΜζΥυ¥ΠΒΡΆχΕΈ «œύΆ§ΒΡΓΘ”…”Ύ»ίΤςΚΆΈοάμΜζΆ§¥Π“ΜΗωΆχΕΈΘ§“ρ¥ΥΚΥ–Ρ…œΝΣΒΡΫΜΜΜΜζΡήΙΜΩ¥ΒΫΗΟ»ίΤςΚΆ≤ΜΆ§Υό÷ςΜζΒΡ
MAC ΒΊ÷ΖΓΘ’βΨΆ «“ΜΗωΆχ¬γΕΰ≤ψΜΞΆ®ΒΡΫβΨωΖΫΑΗΓΘ

ΗΟΆχ¬γΡΘ ΫΨΏ”–”≈Ν”ΝΫΟφ–‘ΘΚ
”≈ΒψΘΚ”…”Ύ‘ΎΆχ¬γΕΰ≤ψ…œ Βœ÷ΝΥΝ§Ϋ”ΜΞΆ®Θ§Εχ«“Ϋω”ΟΒΫΝΥΡΎΚΥΉΣΖΔΘ§“ρ¥Υ’ϊΧε–‘ΡήΖ«≥ΘΚΟΘ§”κΈοάμΜζ’φ ΒΆχΩ®ΒΡ–ß¬ ≤νΨύ≤Μ¥σΓΘ
»±ΒψΘΚΙήάμΫœΈΣΗ¥‘”Θ§–η“ΣΈ“Ο«Ή‘ΦΚ ÷Ε·ΒΡ»ΞΙήάμ»ίΤςΒΡ IP ΚΆ MAC ΒΊ÷ΖΓΘ
”…”Ύ’ϊΧε¥Π”ΎΆχ¬γ¥σΕΰ≤ψΘ§“ΜΒ©œΒΆ≥¥οΒΫΝΥ“ΜΕ®ΙφΡΘΘ§Άχ¬γ÷–ΒΡ ARP ΑϋΜα≤ζ…ζΆχ¬γΙψ≤ΞΖ㱩ȧ…θ÷ΝΜα≈ΦΖΔ≥ωœ÷
PPSΘ®Package Per SecondΘ©ΙΐΗΏΘ§Άχ¬γΦδ–Σ–‘≤ΜΆ®Β»ΤφΙ÷ΒΡœ÷œσΓΘ
”…”Ύ¥Π”ΎΒΉ≤ψΆχ¬γΝ§Ϋ”Θ§‘Ύ Βœ÷Άχ¬γΗτάκ ±“≤ΫœΈΣΗ¥‘”ΓΘ
ΖΰΈώ≤Ω π
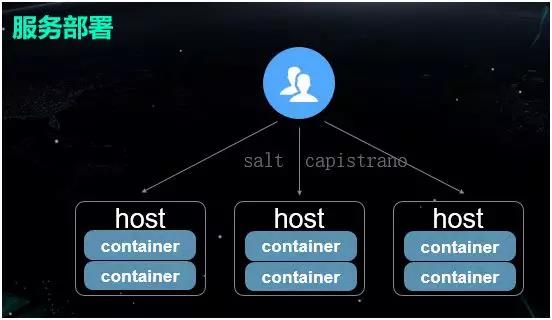
Ε‘”ΎΖΰΈώΒΡ≤Ω πΕχ―‘Θ§Έ“Ο«Ήν≥θ―Ί”Ο–ιΡβΜζΒΡΉωΖ®Θ§ΫΪ»ίΤςΤτΕ·Τπά¥ΚσΨΆ≤Μ‘ΌΆΘœ¬ΝΥΘ§“ρ¥ΥΘΚ
1.»γΙϊΫΎΒψ–η“Σ–¬‘ωΘ§Έ“Ο«ΨΆΆ®Ιΐ Salt ά¥ΙήάμΜζΤςΒΡ≈δ÷ΟΓΘ
2.»γΙϊΫΎΒψ–η“ΣΗϋ–¬Θ§Έ“Ο«ΨΆΆ®Ιΐ Capistrano Ϋχ––ΖΰΈώΒΡΖ÷ΖΔΘ§ΚΆΕύΗωΫΎΒψΒΡ≤Ω π≤ΌΉςΘ§±δΗϋ»ίΤς÷–ΒΡ“ΒΈώ≥Χ–ρΓΘ

Τδ÷–Θ§”≈ ΤΈΣΘΚ
1.”κ‘≠ά¥ΒΡΜυ¥Γ…η ©œύ±»Θ§«®“ΤΒΡ≥…±ΨΖ«≥ΘΒΆΓΘ”…”ΎΈ“Ο«Ά®ΙΐΗ¥”Ο‘≠ά¥ΒΡΜυ¥Γ…η ©Θ§÷±Ϋ”ΫΪΗς÷÷ΖΰΈώ≤Ω π‘Ύ‘≠œ»ΒΡΈοάμΜζ…œΫχ––Θ§“ρ¥ΥΈ“Ο«Κή»ί“ΉΒΊ«®“ΤΒΫΝΥ»ίΤς÷°÷–ΓΘ
2.ΕχΕ‘”ΎΩΣΖΔ»Υ‘±ά¥ΥΒΘ§ΥϊΟ«Ω¥≤ΜΒΫ»ίΤς’β“Μ≤ψΘ§“≤ΨΆ»γΆ§‘Ύ Ι”Ο‘≠ά¥ΒΡΈοάμΜζ“Μ―υΘ§ΚΝΈόΓΑΈΞΚΆΗ–Γ±ΓΘ
3.”κ–ιΡβΜζœύ±»Θ§ΤτΕ·±»ΫœΩλΘ§‘Υ–– ±ΟΜ”––ιΡβΜ·ΒΡΥπΚΡΓΘ
4.Ήν÷Ί“ΣΒΡ «“ΜΕ®≥ΧΕ»…œ¬ζΉψΝΥΈ“Ο«Ε‘”ΎΗτάκΒΡ–η«σΓΘ
ΕχΝ” Τ‘ρ”–ΘΚ
1.«®“ΤΚΆά©»ίΖ«≥ΘΖ±ΥωΓΘάΐ»γΘΚΒ±Ρ≥ΗωΖΰΈώ–η“Σά©»ί ±Θ§Έ“Ο«ΨΆ–η“Σ”–»ΥΒ«¬ΦΒΫΗΟΈοάμΜζ…œΘ§…ζ≥…≤ΔΤτΕ·“ΜΗωΩ’ΒΡ»ίΤςΘ§‘ΌΑ―ΖΰΈώ≤Ω πΫχ»ΞΓΘ¥ΥΨΌΫœΈΣΒΆ–ßΓΘ
2.»±ΖΠΆ≥“ΜΒΡΤΫΧ®Ϋχ––Ης÷÷άζ ΖΑφ±ΨΒΡΙήάμ”κΈ§ΜΛΓΘΈ“Ο«–η“ΣΆ®ΙΐΈΡΒΒά¥Φ«¬Φ’ϊΗωΜζΖΩΒΡ»ίΤς ΐΝΩΘ§ΚΆΗςΗω»ίΤςΒΡ
IP/MAC ΒΊ÷ΖΘ§“ρ¥Υ≥ω¥μΒΡΩ…Ρή–‘ΦΪΗΏΓΘ
3.»±…ΌΝς≥ΧΚΆ»®œόΒΡΩΊ÷ΤΓΘΈ“Ο«Μυ±Ψ…œ≤…”ΟΒΡ «‘≠ ΦΒΡΙήΩΊΖΫ ΫΓΘ
Ή‘―–»ίΤςΙήάμΤΫΧ®
ΟφΕ‘…œ ω»±ΒψΘ§Έ“Ο«–η“ΣΉ‘––―–ΖΔ“ΜΗω»ίΤςΙήάμΤΫΧ®Θ§»ΞΙήάμΗς÷÷ΈοάμΜζΓΔ»ίΤςΓΔIP ”κ MAC ΒΊ÷ΖΓΔ“‘ΦΑΫχ––Νς≥ΧΩΊ÷ΤΓΘ
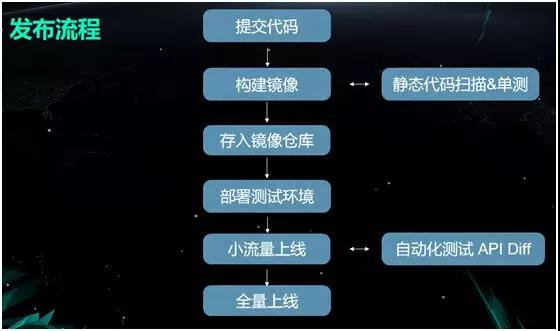
“ρ¥ΥΈ“Ο«±δΗϋΒΡ’ϊΧΉΖΔ≤ΦΝς≥ΧΈΣΘΚ
1.”…ΩΣΖΔ»Υ‘±ΫΪ¥ζ¬κΧαΫΜΒΫ¥ζ¬κ≤÷ΩβΘ®»γ GithubΘ©÷°÷–ΓΘ
2.¥ΞΖΔ“ΜΗω Hook »ΞΙΙΫ®ΨΒœώΘ§‘ΎΙΙΫ®ΒΡΆ§ ±Ήω“Μ–© CIΘ®≥÷–χΦ·≥…Θ©Θ§Αϋά®Ψ≤Χ§¥ζ¬κ…®ΟηΚΆΒΞ≤βΒ»ΓΘ
3.ΫΪ±®ΗφΗΫΦ”ΒΫΨΒœώΒΡ–≈œΔάοΘ§≤Δ¥φ»κΨΒœώ≤÷Ωβ÷–ΓΘ
4.≤Ω π≤β ‘ΜΖΨ≥ΓΘ
5.–ΓΝςΝΩ…œœΏΘ§…œœΏ÷°ΚσΘ§Ήω“Μ–©Ή‘Ε·Μ·ΒΡ API Diff ≤β ‘Θ§“‘≈–Εœ «ΖώΩ…”ΟΓΘ
6.ΦΧ–χ»ΪΝΩ…œœΏΓΘ
ΨΒœώΙΙΫ®
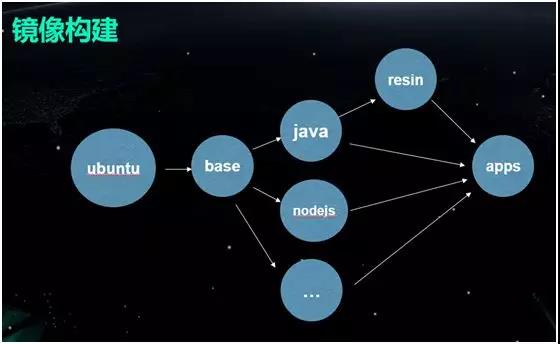
”–ΝΥ»ίΤςΙήάμΤΫΧ®Θ§ΨΆΜα…φΦΑΒΫΨΒœώΒΡΉ‘Ε·ΙΙΫ®ΓΘΚΆ“ΒΫγΤδΥϊΙΪΥΨΒΡΉωΖ®άύΥΤΘ§Έ“Ο«“≤ Ι”ΟΒΡ «Μυ”ΎΆ®”Ο≤ΌΉςœΒΆ≥ΒΡΨΒœώΓΘ
»ΜΚσœρΨΒœώ÷–ΧμΦ”Ρ«–©Έ“Ο«ΙΪΥΨΡΎ≤ΩΜαΧΊ±π”ΟΒΫΒΡΑϋΘ§ΒΟΒΫ“ΜΗωΆ®”ΟΒΡ base ΨΒœώΘ§‘ΌΆ®ΙΐΖ÷±πΦ”»κ≤ΜΆ§”ο―‘ΒΡ“άάΒΘ§ΒΟΒΫ≤ΜΆ§ΒΡΨΒœώΓΘ
ΟΩ¥Έ“ΒΈώΑφ±ΨΖΔ≤ΦΘ§ΫΪ¥ζ¬κΖ≈»κœύ”Π”ο―‘ΒΡΨΒœώΦ¥Ω…ΒΟΒΫ“ΜΗω“ΒΈώΒΡΨΒœώΓΘΙΙΫ®ΨΒœώΒΡ ±Κρ–η“ΣΉΔ“βΨΓΝΩ±ήΟβΈό”ΟΒΡ≤ψΦΕΚΆΡΎ»ίΘ§’β”–÷ζ”ΎΧα…ΐ¥φ¥ΔΚΆ¥Ϊ δ–߬ ΓΘ
œΒΆ≥“άάΒ
Έ“Ο«ΒΡ’β“Μ’ϊΧΉΫβΨωΖΫΑΗ…φΦΑΒΫΝΥ»γœ¬÷ή±ΏΒΡΩΣ‘¥œνΡΩ”κΦΦ θΘΚ
ΗΚ‘ΊΨυΚβ
”…”ΎΜαΤΒΖ±ΖΔ…ζΫΎΒψΒΡ‘ωΦθΘ§Έ“Ο«ΗΟ»γΚΈΆ®ΙΐΝςΝΩΒΡΒςΕ»ΚΆΖΰΈώΒΡΖΔœ÷Θ§ά¥ Βœ÷Ή‘Ε·Φ”»κΗΚ‘ΊΨυΚβΡΊΘΩΕ‘”ΎΡ«–©Ζ«
Http –≠“ιΒΡ RPCΘ§”÷ΗΟ»γΚΈΉ‘Ε·Α≤»ΪΒΊ’ΣΒτΡ≥ΗωΫΎΒψΡΊΘΩ
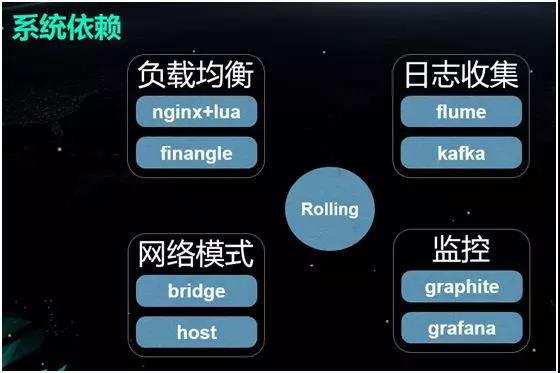
Έ“Ο«‘Ύ¥Υ Ι”ΟΝΥ Nginx+LuaΘ®Φ¥ OpenRestyΘ©Θ§»Ξ Βœ÷¬ΏΦ≠≤ΔΕ·Χ§ΗϋΗΡ UpstreamΓΘ
Β±”–ΫΎΒψΤτΕ· ±Θ§Έ“Ο«ΨΆΡήΙΜΫΪΥϋΉ‘Ε·ΉΔ≤α”κΦ”»κΘΜΕχΒ±”–ΫΎΒψ±ΜœζΜΌ ±Θ§“≤ΡήΦΑ ±ΫΪΤδ’ΣΒτΓΘ
Ά§ ±Θ§Έ“Ο«‘ΎΡΎ≤Ω Ι”ΟΝΥ Finagle ΉςΈΣ RPC ΒΡΩρΦήΘ§≤ΔΆ®Ιΐ ZooKeeper Βœ÷ΝΥΖΰΈώΒΡΖΔœ÷ΓΘ
»’÷Ψ ’Φ·
”…”ΎΫΎΒψ÷ΎΕύΘ§Έ“Ο«–η“ΣΫχ––Ης÷÷»’÷ΨΒΡ ’Φ·ΓΘ‘Ύ¥ΥΘ§Έ“Ο«¥σ÷¬Ζ÷ΈΣΝΫάύ ’Φ·ΖΫ ΫΘΚ
1.“Μάύ « Nginx ’β÷÷≤Μ“Ή«÷»κ¥ζ¬κΒΡΘ§Έ“Ο«≤ΔΟΜ”–…ηΖ®»ΞΗΡ±δ»’÷ΨΒΡΝςœρΘ§Εχ «»ΟΥϋ÷±Ϋ”ΓΑ¥ρΓ±ΒΫΈοάμΜζΒΡ”≤≈Χ…œΘ§»ΜΚσ Ι”Ο
Flume Ϋχ–– ’Φ·Θ§¥Ϊ δΒΫ Kafka ÷–ΓΘ
2.Νμ“Μάύ «Έ“Ο«Ή‘ΦΚΒΡ“ΒΈώΓΘΈ“Ο« Βœ÷ΝΥ“ΜΗω Log4 AppenderΘ§Α―»’÷Ψ÷±Ϋ”–¥ΒΫ
KafkaΘ§‘Ό¥” Kafka ΉΣ–¥ΒΫ ElasticSearch άοΟφΓΘ
Άχ¬γΡΘ Ϋ
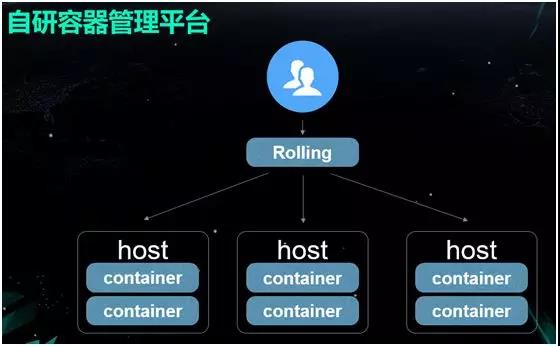
‘ΎΗΟ≥ΓΨΑœ¬Θ§Έ“Ο«≤…”ΟΒΡ «…œ ωΧαΒΫΒΡΗΡΫχΚσΒΡ Bridge+Host ΡΘ ΫΓΘ
ΦύΩΊœΒΆ≥
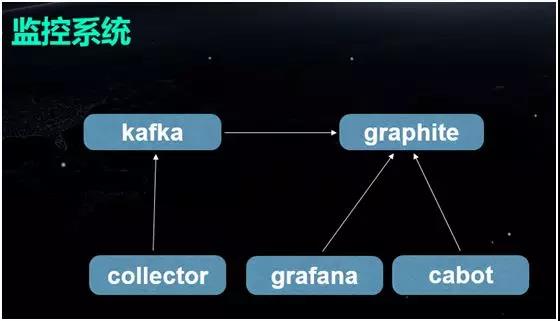
ΦύΩΊœΒΆ≥”……œΆΦΥυ ΨΒΡΦΗΗωΉιΦΰΥυΙΙ≥…ΓΘΥϋΫΪ ’Φ·Θ®CollectorΘ©ΒΫΒΡ≤ΜΆ§ΦύΩΊ÷Η±ξ ΐΨίΘ§¥Ϊ δΒΫ Graphite
…œΘ§Εχ Grafana Ω…ΕΝ»Γ Graphite ΒΡ–≈œΔΘ§≤Δ”ΟΆΦ–Έ”η“‘’Ι ΨΓΘ
Ά§ ±Θ§Έ“Ο«“≤ΗυΨίΡΎ≤Ω“ΒΈώΒΡ ≈δ–η“ΣΘ§Ε‘±®Ψ·ΉιΦΰ Cabot Ϋχ––ΝΥΗΡ‘λΚΆΕ®÷ΤΓΘ
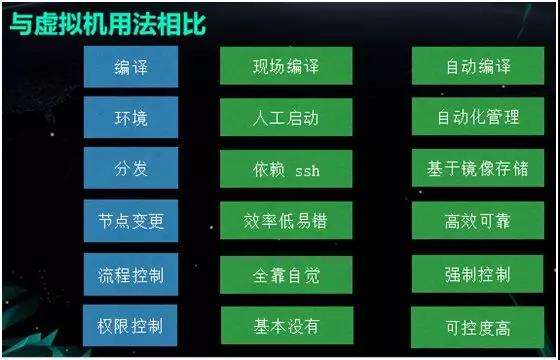
¥Υ ±Έ“Ο«ΒΡΤΫΧ®“―Ψ≠”κ–ιΡβΜζΒΡ”ΟΖ®”–ΝΥΫœ¥σΒΡ«χ±πΓΘ»γ…œΆΦΥυ ΨΘ§÷ς“ΣΒΡ≤ΜΆ§÷°¥ΠΧεœ÷‘Ύ±ύ“κΓΔΜΖΨ≥ΓΔΖ÷ΖΔΓΔΫΎΒψ±δΗϋΘ§Νς≥ΧΩΊ÷ΤΓΔ“‘ΦΑ»®œόΩΊ÷Τ÷°…œΓΘΈ“Ο«ΒΡ”ΟΖ®ΗϋΨΏΉ‘Ε·Μ·ΓΘ

”…”Ύ «Ή‘––―–ΖΔΒΡ»ίΤςΙήάμΤΫΧ®Θ§’βΗχΈ“Ο«¥χά¥ΒΡ÷±Ϋ”ΚΟ¥ΠΑϋά®ΘΚ
1.Νς≥Χ”κ»®œόΒΡΩΊ÷ΤΓΘ
2.¥ζ¬κΑφ±Ψ”κΜΖΨ≥ΒΡΙΧΜ·Θ§ΕύΗωΑφ±ΨΒΡΖΔ≤ΦΘ§ΨΒœώΒΡΙήάμΓΘ
3.≤Ω π”κά©»ί–߬ ΒΡ¥σΖυΧα…ΐΓΘ
ΒΪ «ΤδΉ‘…μ“≤”–Ή≈“ΜΕ®ΒΡ»±ΒψΘ§Αϋά®ΘΚ
1.‘ΎΝς≥ΧΩΊ÷Τ¬ΏΦ≠Θ§ΜζΤς”κΆχ¬γΙήάμΘ§“‘ΦΑ±Ψ…μΒΡώνΚœ≥ΧΕ»…œΕΦ¥φ‘ΎΉ≈»±œίΓΘ“ρ¥ΥΥϋ≤Δ≤ΜΥψ «“ΜΗωΖ«≥ΘΚΟΒΡΦήΙΙΘ§“≤ΟΜΡή’φ’ΐ Βœ÷ΓΑΗΏΡΎΨέΒΆώνΚœΓ±ΓΘ
2.”…”Ύ «Ή‘―–ΒΡ≤ζΤΖΘ§ΤδΙΠΡή…œ≤Δ≤ΜΆξ…ΤΘ§ΟΜΡή Βœ÷Ή‘”ζΘ§ΈόΖ®ΗυΨί–¬‘ωΫΎΒψ»ΞΉ‘Ε·―Γ‘ώΈοάμΜζΓΔ≤ΔΉ‘Ε·Ζ÷≈δ”κΙήάμ
IP ΒΊ÷ΖΓΘ
“ΐ»κ Swarm
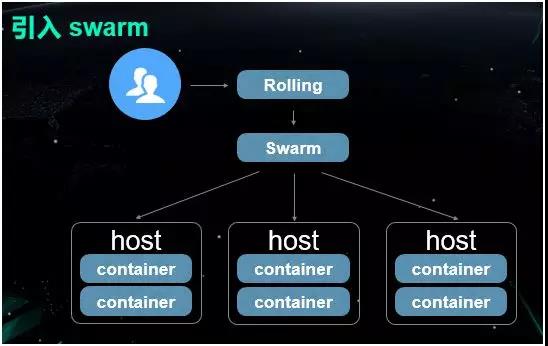
2015 ΡξΘ§Έ“Ο«ΩΣ ΦΉ≈ ÷ΗΡ‘λΗΟ»ίΤςΙήάμΤΫΧ®ΓΘ”…”ΎΗΟΤΫΧ®÷°«ΑΕΦ «Μυ”Ύ DockerAPI ΙΙΫ®ΒΡΓΘ
Εχ Swarm «ΓΚΟΡήΕ‘ Docker ΒΡ‘≠…ζ API ΧαΙ©Ζ«≥ΘΚΟΒΡ÷ß≥÷Θ§“ρ¥ΥΈ“Ο«ΨθΒΟ»γΙϊ“ΐ»κ Swarm
ΒΡΜΑΘ§Ε‘”Ύ“‘«Α¥ζ¬κΒΡΗΡ‘λ≥…±ΨΫΪΜαΫΒΒΫΉνΒΆΓΘ
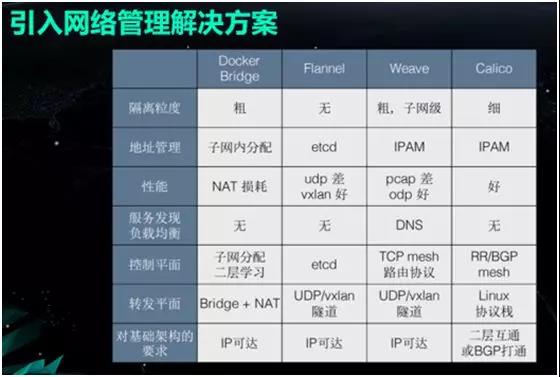
Ρ«Ο¥Έ“Ο«ΗΟ»γΚΈΕ‘‘≠œ»ΒΡΆχ¬γΕΰ≤ψΖΫΑΗΫχ––ΗΡ‘λΡΊΘΩ»γ«ΑΥυ ωΘ§Έ“Ο«“Μ÷± Βœ÷ΒΡ «»Ο»ίΤςΒΡ IP ΒΊ÷Ζ”κΈοάμΜζΒΡ
IP ΒΊ÷ΖœύΕ‘Β»ΓΘ
“ρ¥Υ≤Δ≤Μ¥φ‘ΎΆχ¬γ≤ΜΆ®ΒΡ«ιΩωΓΘΆ§ ±Θ§Έ“Ο«ΒΡ Redis «÷±Ϋ”≤Ω π‘ΎΈοάμΜζ…œΒΡΓΘ
Υυ“‘“άΨί…œΆΦ÷–ΗςΗωΝ–±μΒΡΕ‘±»Θ§Έ“Ο«ΨθΒΟ Calico ΖΫΑΗΗϋ ΚœΈ“Ο«ΒΡ“ΒΈώ≥ΓΨΑΓΘ
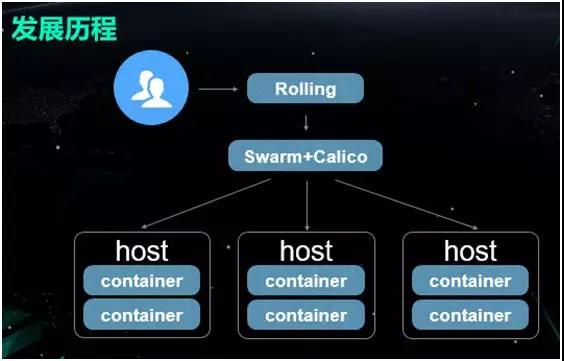
“ρ¥ΥΘ§Έ“Ο«‘Ύ…œ≤ψ Ι”Ο Rolling ά¥Ϋχ––Ης÷÷Νς≥ΧΒΡ≤ΌΉςΘ§÷–œ¬≤ψ‘ρ”Ο Swarm+Calico
ά¥”η“‘»ίΤςΚΆΆχ¬γΒΡΙήάμΓΘ
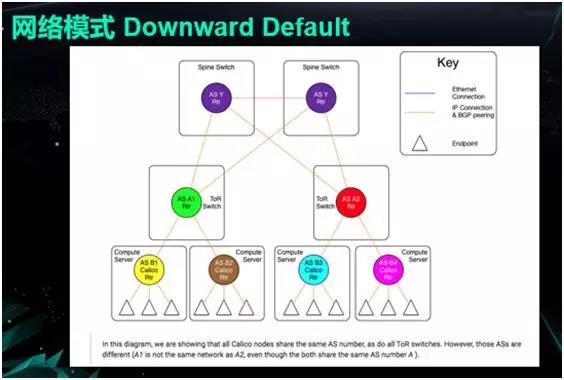
Calico Ι”ΟΒΡ « DownwardDefault ΡΘ ΫΘ§ΗΟΡΘ ΫΆ®Ιΐ‘Υ”Ο BGP –≠“ιΘ§ά¥ Βœ÷Ε‘”Ύ≤ΜΆ§ΜζΤς÷°Φδ¬Ζ”…–≈œΔΒΡΖ÷ΖΔΓΘ
‘ΎΡ§»œ«ιΩωœ¬Θ§Calico « Node ”κ Node ÷°ΦδΒΡ Mesh ΖΫ ΫΘ§Φ¥ΘΚ»Έ“βΝΫΗω Node
÷°ΦδΕΦ”–Ή≈ BGP Ν§Ϋ”ΓΘ
Β±Έ“Ο«‘Ύ“ΜΧ®ΈοάμΜζ…œΤτΕ·ΝΥΡ≥Ηω»ίΤς÷°ΚσΘ§ΥϋΨΆΜαΧμΦ”“ΜΧθΑϋΚ§Ή≈¥”»ίΤς IP ΒΊ÷ΖΒΫΈοάμΜζΒΡ¬Ζ”…–≈œΔΓΘ
”…”ΎΕύΧ®ΈοάμΜζΆ§¥Π“ΜΗω MeshΘ§Ρ«Ο¥ΟΩ“ΜΧ®ΜζΤςΕΦΜα―ßœΑΒΫΗΟ¬Ζ”…–≈œΔΓΘΕχΥφΉ≈Έ“Ο«œΒΆ≥ΙφΡΘΒΡ÷πΫΞ‘ω¥σΘ§ΟΩ“ΜΧ®ΈοάμΜζ…œΒΡ¬Ζ”…±μ“≤Μαœύ”ΠΒΊ‘ωΕύΘ§’βΨΆΜα”ΑœλΒΫΆχ¬γΒΡ’ϊΧε–‘ΡήΓΘ
“ρ¥ΥΈ“Ο«–η“Σ≤…”Ο’β÷÷ Downward Default ≤Ω πΡΘ ΫΘ§ ΙΒΟ≤Μ±Ί»ΟΟΩΧ®ΈοάμΜζΕΦ”Β”–»ΪΝΩΒΡ¬Ζ”…±μΘ§ΕχΫω»ΟΫΜΜΜΜζ≥÷”–±ψΩ…ΓΘ
÷ΎΥυ÷ή÷ΣΘ§BGP ΜαΗχΟΩ“ΜΧ®ΈοάμΜζΖ÷≈δ“ΜΗω ASΘ®Ή‘÷Έ”ρ « BGP ÷–ΒΡ“ΜΗωΗ≈ΡνΘ©Κ≈Θ§Ρ«Ο¥Έ“Ο«ΨΆΩ…“‘ΗχΗςΧ®ΈοάμΜζΕΦΖ÷≈δœύΆ§ΒΡ
AS Κ≈ΓΘ
ΕχΗχΥϋΟ«ΒΡ…œΝΣΫΜΜΜΜζΖ÷≈δΝμ“ΜΗω AS Κ≈Θ§Ά§ ±“≤ΗχΚΥ–ΡΫΜΜΜΜζ‘ΌΖ÷≈δΒΎ»ΐ÷÷ AS Κ≈ΓΘ
Ά®Ιΐ¥ΥΖ®Θ§ΟΩ“ΜΧ®ΈοάμΜζ÷ΜΜαΚΆΉ‘ΦΚ…œΝΣΒΡΫΜΜΜΜζΉω¬Ζ”…Ζ÷ΖΔȧѫϥ±”–“ΜΗω–¬ΒΡΫΎΒψΤτΕ·÷°ΚσΘ§Έ“Ο«±ψΩ…“‘ΫΪ’βΧθ¬Ζ”…–≈œΔ≤ε»κΒΫΗΟΫΎΒψΉ‘ΦΚΒΡ¬Ζ”…±μ÷–Θ§»ΜΚσ‘ΌΗφ÷Σ”κΤδœύΝ§ΒΡ…œΝΣΫΜΜΜΜζΓΘ
…œΝΣΫΜΜΜΜζ‘Ύ―ßœΑΒΫΝΥ’βΧθ¬Ζ”…÷°ΚσΘ§‘ΌΫχ“Μ≤ΫΆΤΗχΚΥ–ΡΫΜΜΜΜζΓΘ
ΉήΫαΤπά¥Θ§ΗΟΡΘ ΫΒΡΧΊΒψ «ΘΚ
ΒΞΗωΫΎΒψ≤Μ±Ί÷ΣΒάΤδΥϊΈοάμΜζΒΡœύΙΊ–≈œΔΘ§Υϋ÷Μ–ηΫΪ ΐΨίΑϋΖΔΆυΆχΙΊ±ψΩ…ΓΘ“ρ¥ΥΒΞΧ®ΈοάμΜζ…œΒΡ¬Ζ”…±μ“≤Μα¥σΖυΦθ…ΌΘ§Τδ ΐΝΩΩ…±Θ≥÷‘ΎΓΑΒΞΜζ…œΒΡ»ίΤς ΐΝΩ
+“ΜΗω≥Θ ΐΘ®Ή‘––≈δ÷ΟΒΡ¬Ζ”…Θ©Γ±ΒΡΥ°ΤΫ…œΓΘ
ΟΩΗω…œΝΣΫΜΜΜΜζ÷Μ–η’ΤΈ’Ή‘ΦΚΜζΦή…œΥυ”–ΈοάμΜζΒΡ¬Ζ”…±μ–≈œΔΓΘ
ΚΥ–ΡΫΜΜΜΜζ‘ρ–η“Σ≥÷”–Υυ”–ΒΡ¬Ζ”…±μΓΘΕχ’β«Γ «ΤδΉ‘…μ–‘Ρή”κΙΠΡήΒΡΧεœ÷ΓΘ
Β±»ΜΘ§ΗΟΡΘ Ϋ“≤¥χά¥ΝΥ“Μ–©≤Μ±ψ÷°¥ΠΘ§Φ¥ΘΚΕ‘”ΎΟΩ“ΜΗω ΐΨίΝςΝΩΕχ―‘Θ§Φ¥ ΙΡΩ±ξ IP ‘Ύ’ϊΗωΆχ¬γ÷–≤Δ≤Μ¥φ‘ΎΘ§ΥϋΟ«“≤–η“Σ“Μ≤Ϋ“Μ≤ΫΒΊœρ…œ≤ι―·÷±ΒΫΚΥ–ΡΫΜΜΜΜζ¥ΠΘ§ΉνΚσ‘Ό≈–Εœ «Ζώ’φΒΡ–η“ΣΕΣΤζΗΟ ΐΨίΑϋΓΘ
Κσ–χ―ίΫχ
‘Ύ¥Υ÷°ΚσΘ§Έ“Ο«“≤ΫΪ DevOps ΒΡΥΦœκΚΆΡΘ Ϋ÷π≤Ϋ“ΐ»κΝΥΒ±«ΑΒΡΤΫΧ®ΓΘΨΏΧεΑϋά®»γœ¬»ΐΗωΖΫΟφΘΚ
1.Ά®ΙΐΗϋΦ”Ή‘÷ζΜ·ΒΡΝς≥ΧΘ§ά¥ΫβΖ≈‘ΥΈ§ΓΘ»ΟΩΣΖΔ»Υ‘±Ή‘÷ζ ΫΒΊ¥¥Ϋ®ΓΔΧμΦ”ΓΔΦύΩΊΥϊΟ«Ή‘ΦΚΒΡœνΡΩΘ§Έ“Ο«÷Μ–ηΝΥΫβΗςΗωœνΡΩ‘ΎΤΫΧ®÷–Υυ’Φ”ΟΒΡΉ ‘¥«ιΩω±ψΩ…Θ§¥”ΕχΡήΙΜ ΙΒΟΉ‘ΦΚΒΡΨΪΝΠΗϋΦ”Ή®ΉΔ”ΎΤΫΧ®ΒΡΩΣΖΔ”κΆξ…ΤΓΘ
2.»γΫώΘ§”…”Ύ Kubernetes Μυ±Ψ…œ“―≥…ΈΣΝΥ“ΒΫγΒΡ±ξΉΦΘ§“ρ¥ΥΈ“Ο«÷π≤ΫΧφΜΜΝΥ÷°«ΑΥυ”ΟΒΫΒΡ
SwarmΘ§≤ΔΆ®Ιΐ Kubernetes ά¥ Βœ÷ΗϋΚΟΒΡΒςΕ»ΖΫΑΗΓΘ
3.÷ß≥÷ΕύΜζΖΩΚΆΕύ‘ΤΜΖΨ≥Θ§“‘¥οΒΫΗϋΗΏΒΡ»ί‘÷Β»ΦΕΘ§¬ζΉψ“ΒΈώΒΡΖΔ’Ι–η«σΘ§≤ΔΆξ…ΤΦ·»ΚΒΡΙήάμΓΘ
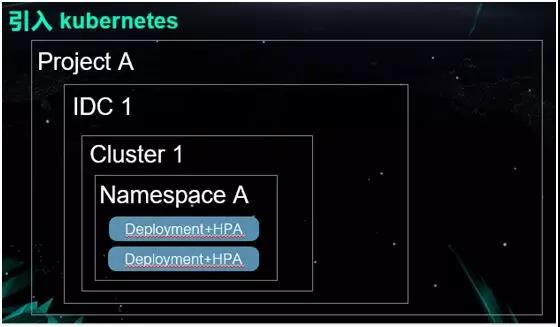
…œΆΦ’Ι ΨΝΥ“Μ÷÷«ΕΧΉ ΫΒΡΙΊœΒΘΚ‘ΎΈ“Ο«ΒΡΟΩ“ΜΗω Project ÷–Θ§ΕΦΩ…“‘”–ΕύΗω IDCΓΘ
ΕχΟΩΗω IDC άο”÷”–Ή≈≤ΜΆ§ΒΡ Kubernetes Φ·»ΚΓΘΆ§ ±‘ΎΟΩ“ΜΗωΦ·»ΚάοΘ§Έ“Ο«ΈΣΟΩ“ΜΗωœνΡΩΕΦΖ÷≈δΝΥ“ΜΗω
NamespaceΓΘ
ΗυΨί≤ΜΆ§ΒΡΜΖΨ≥Θ§’β–©œνΡΩΒΡ Namespace Μα”Β”–≤ΜΆ§ΒΡ DeploymentΓΘάΐ»γœκ“ΣΉωΒΫ≤Ω π”κΖΔ≤ΦΒΡΖ÷άκΘ§Έ“Ο«ΨΆœύ”ΠΒΊΉωΝΥΕύΗω
DeploymentΘ§≤ΜΆ§ΒΡ Deployment ±ξ Ψ≤ΜΆ§ΒΡΜΖΨ≥ΓΘ
Ρ§»œΫΪΝςΝΩ“ΐ»κΒΎ“ΜΗω DeploymentΘ§Β»ΒΫΒΎΕΰΗω Deployment ±Μ≤Ω πΚΟ“‘ΚσΘ§–η“ΣΖΔ≤ΦΒΡ ±ΚρΘ§Έ“Ο«‘Ό÷±Ϋ”Α―ΝςΝΩΓΑ«–Γ±Ιΐ»ΞΓΘ
Ά§ ±Θ§Φχ”ΎΈ“Ο«ΒΡΤΫΧ®…œ‘≠ά¥ΨΆ“―Ψ≠ΨΏ”–ΝΥ÷ν»γ»’÷ΨΓΔΗΚ‘ΊΨυΚβΓΔΦύΩΊ÷°άύΒΡΫβΨωΖΫΑΗΓΘ
Εχ Kubernetes ±Ψ…μ”÷ «“ΜΗωΫœΈΣ»ΪΟφΒΡΫβΨωΖΫΑΗΘ§“ρ¥ΥΈ“Ο«“‘ΫΒΒΆ≥…±ΨΈΣ‘≠‘ρΘ§Ϋς…ςΒΊœρ Kubernetes
Ϋχ––ΙΐΕ…Θ§ΨΓΝΩ±Θ≥÷ΤΫΧ®ΒΡΦφ»ί–‘Θ§≤Μ÷Ν»ΟΩΣΖΔ»Υ‘±≤ζ…ζΓΑΈΞΚΆΗ–Γ±ΓΘ
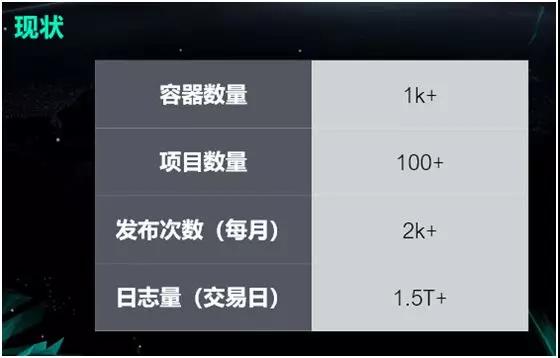
»γΫώΘ§Έ“Ο«ΒΡ»ίΤς÷Μ”–“Μ«ßΕύΗωΘ§œνΡΩ ΐΝΩ¥σΗ≈”–“ΜΑΌΕύΗωΓΘΒΪ «Έ“Ο«‘Ύ≤Ω π–߬ ΖΫΟφΒΡΧα…ΐΜΙ «Ζ«≥Θœ‘÷χΒΡΘ§Έ“Ο«ΒΡΦΗ °ΗωΩΣΖΔ»Υ‘±ΟΩΗω‘¬ΥυΖΔ≤ΦΒΡ¥Έ ΐΨΆΡή¥οΒΫΝΫ«ßΕύ¥ΈΘ§ΟΩΗωΫΜ“Ή»’ΒΡ»’÷ΨΝΩ¥σΗ≈”–
1.5TΓΘ
|