| ±ајНЖјц: |
| ±ѕОДАґЧФУЪcloud.tencent.com
Ј¬±ѕОДЦчТЄКЗ¶ФУЪDockerµДОў·юОсКµјщЅшРРјјКх·Ѕ°ёСЎРНТФј°ЅйЙЬЎЈ |
|
З°СФ
»щУЪ Docker µДИЭЖчјјКхКЗФЪ2015ДкµДК±єтїЄКјЅУґҐµДЈ¬БЅДк¶аµДК±јдЈ¬ЧчОЄТ»Гы Docker
µД DevOpsЈ¬ТІјыЦ¤БЛ Docker µДјјКхМеПµµДїмЛЩ·ўХ№ЎЈ±ѕОДЦчТЄКЗЅбєПФЪ№«ЛѕґоЅЁµДОў·юОсјЬ№№µДКµјщ№эіМЈ¬ЧцТ»ёцјтµҐµДЧЬЅбЎЈПЈНыёшФЪґґТµіхЖЪМЅЛчИзєОІјѕЦ·юОсјЬ№№МеПµµД
DevOpsЈ¬»тХЯПліхІЅБЛЅвЖуТµј¶јЬ№№µДН¬С§ГЗТ»Р©ІОїјЎЈ
Microservice єН Docker
¶ФУЪґґТµ№«ЛѕµДјјКхІјѕЦЈ¬єЬ¶аЙщТф»щ±ѕЙПКЗЈ¬ґґТµ№«ЛѕѕНКЗТЄїмЛЩЙППЯїмЛЩКФґнЎЈУГµҐУ¦УГ»тХЯЗ°єуМЁУ¦УГ·ЦАлµД·ЅКЅїмЛЩјЇіЙЈ¬їмЛЩїЄ·ўЈ¬їмЛЩ·ўІјЎЈµ«ЖдКµХвЦЦЅб№ыФміЙµДТюРФіЙ±ѕ»бёьёЯЎЈµ±ТµОс·ўХ№ЖрАґЈ¬їЄ·ўИЛФ±¶аБЛЦ®єуЈ¬ѕН»бГжБЩЕУґуПµНіµДІїКрР§ВКЈ¬їЄ·ўРН¬Р§ВКОКМвЎЈИ»єуНЁ№э·юОсµДІр·ЦЈ¬КэѕЭµД¶БРґ·ЦАлЎў·Цїв·Ц±нµИ·ЅКЅЦШРВјЬ№№Ј¬¶шЗТХвЦЦ·ЅКЅИз№ыТЄЧцµДі№µЧЈ¬РиТЄ»Ё·СґуБїИЛБ¦ОпБ¦ЎЈ
ёцИЛЅЁТйЈ¬DevOps ЅбєПЧФјє¶ФУЪТµОсДїЗ°ТФј°і¤ЖЪµД·ўХ№ЕР¶ПЈ¬ДЬ№»ФЪПоДїіхЖЪК№УГОў·юОсјЬ№№Ј¬¶аОЄєуИЛД±ёЈЎЈ
ЛжЧЕ Docker ЦЬО§їЄФґЙзЗшµД·ўХ№Ј¬ИГОў·юОсјЬ№№µДёЕДоДЬУРёьєГµДТ»ёцВдµШКµК©µД·Ѕ°ёЎЈІўЗТФЪГїТ»ёцОў·юОсУ¦УГДЪІїЈ¬¶јїЙТФК№УГ
DDDЈЁDomain-Drive DesignЈ©µДБщ±ЯРОјЬ№№АґЅшРР·юОсДЪµДЙијЖЎЈ№ШУЪ DDD µДТ»Р©ёЕДоТІїЙТФІОїјЦ®З°РґµДјёЖЄОДХВЈєБмУтЗэ¶ЇЙијЖХыАнЎЄЎЄёЕДо&јЬ№№ЎўБмУтЗэ¶ЇЙијЖХыАнЎЄЎЄКµМеєНЦµ¶ФПуЙијЖЎўБмУт·юОсЎўБмУтКВјюЎЈ
ЗеОъµДОў·юОсµДБмУт»®·ЦЈ¬·юОсДЪІїУРјЬ№№ІгґОµДУЕСЕµДКµПЦЈ¬·юОсјдНЁ№э RPC »тХЯКВјюЗэ¶ЇНкіЙ±ШТЄµД
IPCЈ¬К№УГ API gateway ЅшРРЛщУРОў·юОсµДЗлЗуЧЄ·ўЈ¬·ЗЧиИыµДЗлЗуЅб№ыєПІўЎЈ±ѕОДПВГж»бѕЯМеЅйЙЬЈ¬ИзєОФЪ·ЦІјКЅ»·ѕіПВЈ¬ТІїЙТФїмЛЩґоЅЁЖрАґѕЯУРТФЙПјёµгМШХчµДЈ¬Оў·юОсјЬ№№
with DockerЎЈ
·юОс·ўПЦДЈКЅ
Из№ыК№УГ Docker јјКхАґјЬ№№Оў·юОсМеПµЈ¬·юОс·ўПЦѕНКЗТ»ёц±ШИ»µДїОМвЎЈДїЗ°ЦчБчµД·юОс·ўПЦДЈКЅУРБЅЦЦЈєїН»§¶Л·ўПЦДЈКЅЈ¬ТФј°·юОс¶Л·ўПЦДЈКЅЎЈ
їН»§¶Л·ўПЦДЈКЅ
їН»§¶Л·ўПЦДЈКЅµДјЬ№№НјИзПВЈє
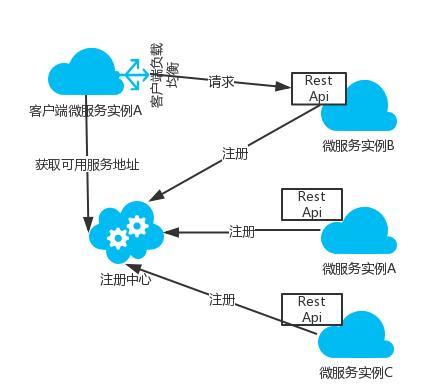
їН»§¶Л·ўПЦДЈКЅµДµдРНКµПЦКЗNetflixМеПµјјКхЎЈїН»§¶ЛґУТ»ёц·юОсЧўІб·юОсЦРРДІйСЇЛщУРїЙУГ·юОсКµАэЎЈїН»§¶ЛК№УГёєФШѕщєвЛг·ЁґУ¶аёцїЙУГµД·юОсКµАэЦРСЎФсіцТ»ёцЈ¬И»єу·ўіцЗлЗуЎЈ±ИЅПµдРНµДТ»ёцїЄФґКµПЦѕНКЗ
Netflix µД EurekaЎЈ
Netflix-Eureka
Eureka µДїН»§¶ЛКЗІЙУГЧФЧўІбµДДЈКЅЈ¬їН»§¶ЛРиТЄёєФрґ¦Ан·юОсКµАэµДЧўІбєНЧўПъЈ¬·ўЛНРДМшЎЈ
ФЪК№УГ SpringBoot јЇіЙТ»ёцОў·юОсК±Ј¬ЅбєП SpringCloud ПоДїїЙТФєЬ·Ѕ±гµГКµПЦЧФ¶ЇЧўІбЎЈФЪ·юОсЖф¶ЇАаЙПМнјУ@EnableEurekaClientјґїЙФЪ·юОсКµАэЖф¶ЇК±Ј¬ПтЕдЦГєГµД
Eureka ·юОс¶ЛЧўІб·юОсЈ¬ІўЗТ¶ЁК±·ўЛНТФРДМшЎЈїН»§¶ЛµДёєФШѕщєвУЙ Netflix Ribbon
КµПЦЎЈ·юОсНш№ШК№УГ Netflix ZuulЈ¬ИЫ¶ПЖчК№УГ Netflix HystrixЎЈ
іэБЛ·юОс·ўПЦµДЕдМЧїтјЬЈ¬SpringCloud µД Netflix-FeignЈ¬МṩБЛЙщГчКЅµДЅУїЪАґґ¦Ан·юОсµД
Rest ЗлЗуЎЈµ±И»Ј¬іэБЛК№УГ FeignClientЈ¬ТІїЙТФК№УГ Spring RestTemplateЎЈПоДїЦРИз№ыК№УГ@FeignClientїЙТФК№ґъВлµДїЙФД¶БРФёьєГЈ¬Rest
API ТІТ»ДїБЛИ»ЎЈ
·юОсКµАэµДЧўІб№ЬАнЎўІйСЇЈ¬¶јКЗНЁ№эУ¦УГДЪµчУГ Eureka МṩµД REST API ЅУїЪЈЁµ±И»К№УГ
SpringCloud-Eureka І»РиТЄ±аРґХвІї·ЦґъВлЈ©ЎЈУЙУЪ·юОсЧўІбЎўЧўПъКЗНЁ№эїН»§¶ЛЧФЙн·ўіцЗлЗуµДЈ¬ЛщТФХвЦЦДЈКЅµДТ»ёцЦчТЄОКМвКЗ¶ФУЪІ»Н¬µД±аіМУпСФ»бЧўІбІ»Н¬·юОсЈ¬РиТЄОЄГїЦЦїЄ·ўУпСФµҐ¶АїЄ·ў·юОс·ўПЦВЯјЎЈБнНвЈ¬К№УГ
Eureka К±РиТЄПФКЅЕдЦГЅЎїµјмІйЦ§іЦЎЈ
·юОс¶Л·ўПЦДЈКЅ
·юОс¶Л·ўПЦДЈКЅµДјЬ№№НјИзПВЈє
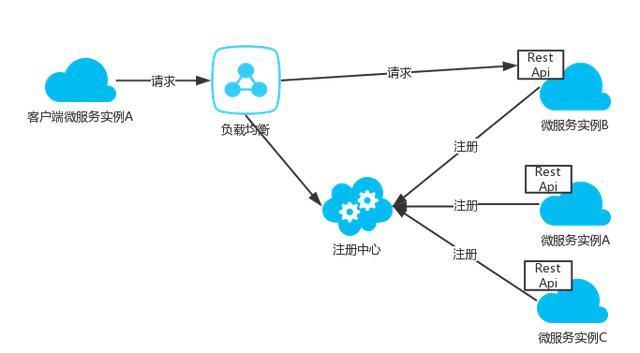
їН»§¶ЛПтёєФШѕщєвЖч·ўіцЗлЗуЈ¬ёєФШѕщєвЖчПт·юОсЧўІб±н·ўіцЗлЗуЈ¬Ѕ«ЗлЗуЧЄ·ўµЅЧўІб±нЦРїЙУГµД·юОсКµАэЎЈ·юОсКµАэТІКЗФЪЧўІб±нЦРЧўІбЈ¬ЧўПъµДЎЈёєФШѕщєвїЙТФК№УГїЙТФК№УГ
Haproxy »тХЯ NginxЎЈ·юОс¶Л·ўПЦДЈКЅДїЗ°»щУЪ Docker µДЦчБч·Ѕ°ёЦчТЄКЗ ConsulЎўEtcd
ТФј° ZookeeperЎЈ
Consul
Consul МṩБЛТ»ёц API ФКРнїН»§¶ЛЧўІбєН·ўПЦ·юОсЎЈЖдТ»ЦВРФЙП»щУЪRAFTЛг·ЁЎЈНЁ№э WAN
µД Gossip РТйЈ¬№ЬАніЙФ±єН№гІҐПыПўЈ¬ТФНкіЙїзКэѕЭЦРРДµДН¬ІЅЈ¬ЗТЦ§іЦ ACL ·ГОКїШЦЖЎЈConsul
»№МṩБЛЅЎїµјмІй»ъЦЖЈ¬Ц§іЦ kv ґжґў·юОсЈЁEureka І»Ц§іЦЈ©ЎЈConsul µДТ»Р©ёьПкПёµДЅйЙЬїЙТФІОїјЦ®З°РґµДТ»ЖЄЈєDocker
ИЭЖчІїКр Consul јЇИєЎЈ
Etcd
Etcd ¶јКЗЗїТ»ЦВµДЈЁВъЧг CAP µД CPЈ©Ј¬ёЯїЙУГµДЎЈEtcd ТІКЗ»щУЪ RAFT Лг·ЁКµПЦЗїТ»ЦВРФµД
KV КэѕЭН¬ІЅЎЈKubernetes ЦРК№УГ Etcd µД KV Ѕб№№ґжґўЛщУР¶ФПуµДЙъГьЦЬЖЪЎЈ
№ШУЪ Etcd µДТ»Р©ДЪІїФАнїЙТФїґПВetcd v3ФАн·ЦОц
Zookeeper
ZK ЧоФзУ¦УГУЪ HadoopЈ¬ЖдМеПµТСѕ·ЗіЈіЙКмЈ¬іЈ±»УГУЪґу№«ЛѕЎЈИз№ыТСѕУРЧФјєµД ZK јЇИєЈ¬ДЗГґїЙТФїјВЗУГ
ZK АґЧцЧФјєµД·юОсЧўІбЦРРДЎЈ
Zookeeper Н¬ Etcd Т»СщЈ¬ЗїТ»ЦВРФЈ¬ёЯїЙУГРФЎЈТ»ЦВРФЛг·ЁКЗ»щУЪ Paxos µДЎЈ¶ФУЪОў·юОсјЬ№№µДіхКјЅЧ¶ОЈ¬Г»УР±ШТЄУГ±ИЅП·±ЦШµД
ZK АґЧц·юОс·ўПЦЎЈ
·юОсЧўІб
·юОсЧўІб±нКЗ·юОс·ўПЦЦРµДТ»ёцЦШТЄЧйјюЎЈіэБЛ KubernetesЎўMarathon Жд·юОс·ўПЦКЗДЪЦГµДДЈїйЦ®НвЎЈ·юОс¶јКЗРиТЄЧўІбµЅЧўІб±нЙПЎЈЙПОДЅйЙЬµД
EurekaЎўconsulЎўetcd ТФј° ZK ¶јКЗ·юОсЧўІб±нµДАэЧУЎЈ
Оў·юОсИзєОЧўІбµЅЧўІб±нТІКЗУРБЅЦЦ±ИЅПµдРНµДЧўІб·ЅКЅЈєЧФЧўІбДЈКЅЈ¬µЪИэ·ЅЧўІбДЈКЅЎЈ
ЧФЧўІбДЈКЅ Self-registration pattern
ЙПОДЦРµД Netflix-Eureka їН»§¶ЛѕНКЗТ»ёцµдРНµДЧФЧўІбДЈКЅµДАэЧУЎЈТІјґГїёцОў·юОсµДКµАэ±ѕЙнЈ¬РиТЄёєФрЧўІбТФј°ЧўПъ·юОсЎЈEureka
»№МṩБЛРДМш»ъЦЖЈ¬Аґ±ЈЦ¤ЧўІбРЕПўµДЧјИ·Ј¬ѕЯМеµДРДМшµД·ўЛНјдёфК±јдїЙТФФЪОў·юОсµД SpringBoot
ЦРЅшРРЕдЦГЎЈ
ИзПВЈ¬ѕНКЗК№УГ Eureka ЧцЧўІб±нК±Ј¬ФЪОў·юОсЈЁSpringBoot У¦УГЈ©Жф¶ЇК±»бУРТ»Мх·юОсЧўІбµДРЕПўЈє
<pre style="margin: 15px 0px;
padding: 10px; border-radius: 3px; background: rgb(240,
240, 240 ); font-size: 12px; line-height: 1.5em; display:
block; font-family: monaco, Consolas, " Liberation
Mono ", Courier, monospace; white- space: pre;
word-wrap: normal; overflow- x: auto ; color: rgb
(93, 93, 93); font- style: normal; font-variant-ligatures:
normal; font-variant-caps : normal; font- weight:
400; letter-spacing: normal; orphans: 2; text-align:
start; text-indent : 0px; text- transform: none; widows:
2; word-spacing: 0px; - webkit-text- stroke-width
: 0px ; text- decoration-style : initial; text-decoration-color:
initial;"> com.netflix .discovery .DiscoveryClient
: DiscoveryClient_ SERVICE-USER/{your_ ip}:service-user:
{port} : cc9f93c54a0820c7a845422f9ecc73fb : registering
service...
</pre>
Н¬СщЈ¬ФЪУ¦УГНЈУГК±Ј¬·юОсКµАэРиТЄЦч¶ЇЧўПъ±ѕКµАэРЕПўЈє
<pre style="margin: 15px 0px;
padding: 10px; border-radius: 3px; background: rgb(240,
240, 240 ) ; font-size : 12px; line-height: 1.5em;
display: block; font-family: monaco, Consolas, "
Liberation Mono ", Courier, monospace; white-space:
pre; word-wrap: normal; overflow-x: auto; color :
rgb(93, 93, 93); font-style : normal; font-variant-ligatures
: normal; font-variant-caps : normal; font-weight:
400; letter-spacing: normal; orphans: 2; text-align:
start; text-indent : 0px; text- transform: none; widows
: 2; word- spacing: 0px; -webkit-text-stroke-width
: 0px ; text- decoration- style: initial; text- decoration-color:
initial;">2018-01-04 20:41 : 37 .290 INFO
49244 --- [ Thread- 8] c.n.e.EurekaDiscoveryClientConfiguration
: Unregistering application service-user with eureka
with status DOWN
2018-01-04 20: 41: 37.340 INFO 49244
--- [ Thread- 8] com.netflix .discovery .DiscoveryClient
: Shutting down DiscoveryClient ...
2018-01-04 20:41:37.381 INFO 49244
--- [ Thread- 8] com.netflix .discovery .DiscoveryClient
: Unregistering ...
2018-01-04 20:41 :37.559 INFO 49244
--- [ Thread- 8] com.netflix .discovery .DiscoveryClient
: DiscoveryClient_ SERVICE- USER/ {your_ip}:service-user
:{port} : cc9f93c54a0820c7a845422f9ecc73fb - deregister
status : 200
</pre>
ЧФЧўІб·ЅКЅКЗ±ИЅПјтµҐµД·юОсЧўІб·ЅКЅЈ¬І»РиТЄ¶оНвµДЙиК©»тґъАнЈ¬УЙОў·юОсКµАэ±ѕЙнАґ№ЬАн·юОсЧўІбЎЈµ«КЗИ±µгТІєЬГчПФЈ¬±ИИз
Eureka ДїЗ°Ц»МṩБЛ Java їН»§¶ЛЈ¬ЛщТФІ»·Ѕ±г¶аУпСФµДОў·юОсА©Х№ЎЈТтОЄРиТЄОў·юОсЧФјєИҐ№ЬАн·юОсЧўІбВЯјЈ¬ЛщТФОў·юОсКµПЦТІсоєПБЛ·юОсЧўІбєНРДМш»ъЦЖЎЈїзУпСФРФ±ИЅПІоЎЈ
µЪИэ·ЅЧўІбДЈКЅ Third party registration pattern
µЪИэ·ЅЧўІбЈ¬ТІјґ·юОсЧўІбµД№ЬАнЈЁЧўІбЎўЧўПъ·юОсЈ©НЁ№эТ»ёцЧЁГЕµД·юОс№ЬАнЖчЈЁRegistarЈ©АґёєФрЎЈRegistrator
ѕНКЗТ»ёцїЄФґµД·юОс№ЬАнЖчµДКµПЦЎЈRegistrator МṩБЛ¶ФУЪ Etcd ТФј° Consul µДЧўІб±н·юОсЦ§іЦЎЈ
Registrator ЧчОЄТ»ёцґъАн·юОсЈ¬РиТЄІїКрЎўФЛРРФЪОў·юОсЛщФЪµД·юОсЖч»тХЯРйДв»ъЦРЎЈ±ИЅПјтµҐµД°ІЧ°·ЅКЅѕНКЗНЁ№э
DockerЈ¬ТФИЭЖчµД·ЅКЅАґФЛРРЎЈИэ·ЅЧўІбДЈКЅµДјЬ№№НјИзПВЈє
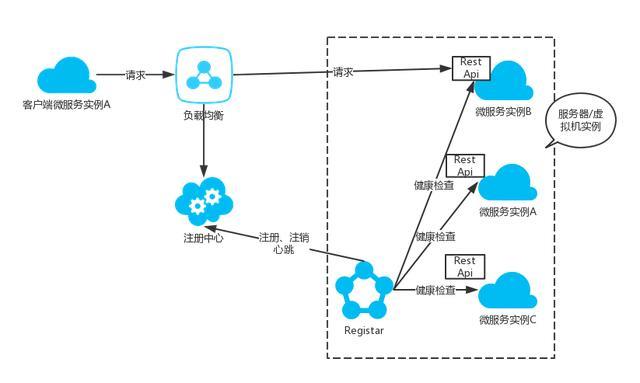
НЁ№эМнјУТ»ёц·юОс№ЬАнЖчЈ¬Оў·юОсКµАэІ»ФЩЦ±ЅУПтЧўІбЦРРДЧўІбЈ¬ЧўПъЎЈУЙ·юОс№ЬАнЖчЈЁRegistarЈ©НЁ№э¶©ФД·юОсЈ¬ёъЧЩРДМшЈ¬Аґ·ўПЦїЙУГµД·юОсКµАэЈ¬ІўПтЧўІбЦРРДЈЁconsulЎўetcd
µИЈ©ЧўІбЈ¬ЧўПъКµАэЈ¬ТФј°·ўЛНРДМшЎЈХвСщѕНїЙТФКµПЦ·юОс·ўПЦЧйјюєНОў·юОсјЬ№№µДЅвсоЎЈПлС§ОДЦРµДјјКхїЙТФјУИлОТµДИєЈє619881427
Registrator ЕдєП ConsulЈ¬ТФј° Consul Template ґоЅЁ·юОс·ўПЦЦРРДЈ¬їЙТФІОїјЈє
Scalable Architecture DR CoN: Docker, Registrator,
Consul, Consul Template and Nginx ЎЈґЛОДКѕАэБЛ Nginx АґЧцёєФШѕщєвЈ¬ФЪѕЯМеµДКµК©№эіМЦРТІїЙТФУГ
Haproxy »тЖдЛы·Ѕ°ёЅшРРМжґъЎЈПлС§ОДЦРµДјјКхїЙТФјУИлОТµДИєЈє619881427
РЎЅб
іэБЛТФЙПјёЦЦЧц·юОс·ўПЦµДјјКхЈ¬Kubernetes ЧФґшБЛ·юОс·ўПЦДЈїйЈ¬ёєФрґ¦Ан·юОсКµАэµДЧўІбєНЧўПъЎЈKubernetes
ТІФЪГїёцјЇИєЅЪµгЙПФЛРРґъАнЈ¬АґКµПЦ·юОс¶Л·ўПЦВ·УЙЖчµД№¦ДЬЎЈИз№ы±аЕЕјјКхК№УГµД k8nЈ¬їЙТФУГ k8n
µДТ»ХыМЧ Docker Оў·юОс·Ѕ°ёЈ¬¶Ф k8n ёРРЛИ¤µДїЙТФФД¶БПВKubernetes јЬ№№ЙијЖУлєЛРДФАнЎЈ
ФЪКµјКµДјјКхСЎРНЦРЈ¬ЧоЦчТЄ»№КЗТЄЅбєПТµОсЎўПµНіµДОґАґ·ўХ№µДМШХчЅшРРєПАнЕР¶ПЎЈ
ФЪ CAP АнВЫЦРЎЈEureka ВъЧгБЛ APЈ¬Consul КЗ CAЈ¬ZK єН Etcd КЗ
CPЎЈ ФЪ·ЦІјКЅіЎѕ°ПВ Eureka єН Consul ¶јДЬ±ЈЦ¤їЙУГРФЎЈ¶шґоЅЁ Eureka ·юОс»бПа¶ФёьїмЛЩЈ¬ТтОЄІ»РиТЄґоЅЁ¶оНвµДёЯїЙУГ·юОсЧўІбЦРРДЈ¬ФЪРЎ№жДЈ·юОсЖчКµАэК±Ј¬К№УГ
Eureka їЙТФЅЪКЎТ»¶ЁіЙ±ѕЎЈ
EurekaЎўConsul ¶јМṩБЛїЙТФІйїґ·юОсЧўІбКэѕЭµД WebUI ЧйјюЎЈConsul »№МṩБЛ
KV ґжґўЈ¬Ц§іЦЦ§іЦ http єН dns ЅУїЪЎЈ¶ФУЪґґТµ№«ЛѕЧоїЄКјґоЅЁОў·юОсЈ¬±ИЅПНЖјцХвБЅХЯЎЈ
ФЪ¶аКэѕЭЦРРД·ЅГжЈ¬Consul ЧФґшКэѕЭЦРРДµД WAN ·Ѕ°ёЎЈZK єН Etcd ѕщІ»Мṩ¶аКэѕЭЦРРД№¦ДЬµДЦ§іЦЈ¬РиТЄ¶оНвµДїЄ·ўЎЈ
їзУпСФРФЙПЈ¬Zookeeper РиТЄК№УГЖдМṩµДїН»§¶Л apiЈ¬їзУпСФЦ§іЦЅПИхЎЈEtcdЎўEureka
¶јЦ§іЦ httpЈ¬Etcd »№Ц§іЦ grpcЎЈConsul іэБЛ http Ц®Нв»№МṩБЛ DNS µДЦ§іЦЎЈ
°ІИ«·ЅГжЈ¬ConsulЈ¬Zookeeper Ц§іЦ ACLЈ¬БнНв ConsulЎўEtcd Ц§іЦ°ІИ«НЁµА
HttpsЎЈ
SpringCloud ДїЗ°¶ФУЪ EurekaЎўConsulЎўEtcdЎўZK ¶јУРПаУ¦µДЦ§іЦЎЈ
Consul єН Docker Т»СщЈ¬¶јКЗУГ Go УпСФКµПЦЈ¬»щУЪ Go УпСФµДОў·юОсУ¦УГїЙТФУЕПИїјВЗУГ
ConsulЎЈ
·юОсјдµД IPC »ъЦЖ
°ґХХОў·юОсµДјЬ№№МеПµЈ¬ЅвѕцБЛ·юОс·ўПЦµДОКМвЦ®єуЎЈѕНРиТЄСЎФсєПККµД·юОсјдНЁРЕµД»ъЦЖЎЈИз№ыКЗФЪ SpringBoot
У¦УГЦРЈ¬К№УГ»щУЪ Http РТйµД REST API КЗТ»ЦЦН¬ІЅµДЅвѕц·Ѕ°ёЎЈ¶шЗТ Restful ·зёсµД
API їЙТФК№ГїёцОў·юОсУ¦УГёьјУЗчУЪЧКФґ»ЇЈ¬К№УГЗбБїј¶µДРТйТІКЗОў·юОсТ»Ц±Мбі«µДЎЈ
Из№ыГїёцОў·юОсКЗК№УГ DDDЈЁDomain-Driven DesignЈ©ЛјПлµД»°Ј¬ДЗГґРиТЄГїёцОў·юОсѕЎБїІ»К№УГН¬ІЅµД
RPC »ъЦЖЎЈТмІЅµД»щУЪПыПўµД·ЅКЅ±ИИз AMQP »тХЯ STOMPЈ¬АґЛЙсоєПОў·юОсјдµДТААµ»бКЗєЬєГµДСЎФсЎЈДїЗ°»щУЪПыПўµДµг¶ФµгµД
pub/sub µДїтјЬСЎФсТІ±ИЅП¶аЎЈПВГжѕЯМеЅйЙЬПВБЅЦЦ IPC µДТ»Р©·Ѕ°ёЎЈ
Н¬ІЅ
¶ФУЪН¬ІЅµДЗлЗу/ПмУ¦ДЈКЅµДНЁРЕ·ЅКЅЎЈїЙТФСЎФс»щУЪ Restful ·зёсµД Http РТйЅшРР·юОсјдНЁРЕЈ¬»тХЯїзУпСФРФєЬєГµД
Thrift РТйЎЈИз№ыКЗК№УГґї Java УпСФµДОў·юОсЈ¬ТІїЙТФК№УГ DubboЎЈИз№ыКЗ SpringBoot
јЇіЙµДОў·юОсјЬ№№МеПµЈ¬ЅЁТйСЎФсїзУпСФРФєГЎўSpring ЙзЗшЦ§іЦ±ИЅПєГµД RPCЎЈ
Dubbo
DubboКЗУЙ°ўАп°Н°НїЄ·ўµДїЄФґµД Java їН»§¶ЛµД RPC їтјЬЎЈDubbo »щУЪ TCP РТйµДі¤Б¬ЅУЅшРРКэѕЭґ«КдЎЈґ«КдёсКЅКЗК№УГ
Hessian ¶юЅшЦЖРтБР»ЇЎЈ·юОсЧўІбЦРРДїЙТФНЁ№э Zookeeper КµПЦЎЈ
ApacheThrift
ApacheThrift КЗУЙ Facebook їЄ·ўµД RPC їтјЬЎЈЖдґъВлЙъіЙТэЗжїЙТФФЪ¶аЦЦУпСФЦРЈ¬Из
C++Ўў JavaЎўPythonЎўPHPЎўRubyЎўErlangЎўPerl µИґґЅЁёЯР§µД·юОсЎЈґ«КдКэѕЭІЙУГ¶юЅшЦЖёсКЅЈ¬ЖдКэѕЭ°ьТЄ±ИК№УГ
Json »тХЯ XML ёсКЅµД HTTP РТйРЎЎЈёЯІў·ўЈ¬ґуКэѕЭіЎѕ°ПВёьУРУЕКЖЎЈ
Rest
Rest »щУЪ HTTP РТйЈ¬HTTP РТй±ѕЙнѕЯУРУпТеµД·бё»РФЎЈЛжЧЕ Springboot ±»№г·єК№УГЈ¬ФЅАґФЅ¶аµД»щУЪ
Restful ·зёсµД API БчРРЖрАґЎЈREST КЗ»щУЪ HTTP РТйµДЈ¬ІўЗТґу¶аКэїЄ·ўХЯТІКЗКмЦЄ
HTTP µДЎЈ
ХвАпБнНвМбТ»µгЈ¬єЬ¶а№«Лѕ»тХЯНЕ¶УТІКЗК№УГSpringbootµДЈ¬ТІФЪЛµЧФјєКЗ»щУЪ Restful
·зёсµДЎЈµ«КЗКВКµЖдКµНщНщКЗКµК©µГІўІ»µЅО»ЎЈ¶ФУЪДгµД Restful КЗ·сКЗХжµД RestfulЈ¬їЙТФІОїјХвЖЄОДХВЈ¬¶ФУЪ
Restful ·зёс API µДіЙКм¶ИЅшРРБЛЛДёцІгґОµД·ЦОцЈє Richardson Maturity
Model steps toward the glory of RESTЎЈ
Из№ыК№УГSpringbootµД»°Ј¬ОЮВЫК№УГКІГґ·юОс·ўПЦ»ъЦЖЈ¬¶јїЙТФНЁ№э Spring µДRestTemplateАґЧц»щґЎµДHttpЗлЗу·вЧ°ЎЈ
Из№ыК№УГµДЗ°ОДМбµЅµДNetflix-EurekaµД»°Ј¬їЙТФК№УГNetflix-FeignЎЈFeignКЗТ»ёцЙщГчКЅ
Web Service їН»§¶ЛЎЈїН»§¶ЛµДёєФШѕщєвК№УГ Netflix-RibbonЎЈ
ТмІЅ
ФЪОў·юОсјЬ№№ЦРЈ¬ЕЕіэґїґвµДЎ°КВјюЗэ¶ЇјЬ№№Ў±Ј¬К№УГПыПў¶УБРµДіЎѕ°Т»°гКЗОЄБЛЅшРРОў·юОсЦ®јдµДЅвсоЎЈ·юОсЦ®јдІ»РиТЄБЛЅвКЗУЙДДёц·юОсКµАэАґПы·С»тХЯ·ўІјПыПўЎЈЦ»ТЄґ¦АнєГЧФјєБмУт·¶О§µДВЯјЈ¬И»єуНЁ№эПыПўНЁµААґ·ўІјЈ¬»тХЯ¶©ФДЧФјє№ШЧўµДПыПўѕНїЙТФЎЈДїЗ°їЄФґµДПыПў¶УБРјјКхТІєЬ¶аЎЈ±ИИз
Apache KafkaЈ¬RabbitMQЈ¬Apache ActiveMQ ТФј°°ўАп°Н°НµД RocketMQ
ДїЗ°ТСѕіЙОЄ Apache ПоДїЦ®Т»ЎЈПыПў¶УБРµДДЈРНЦРЈ¬ЦчТЄµДИэёцЧйіЙѕНКЗЈє
ProducerЈєЙъІъПыПўЈ¬Ѕ«ПыПўРґИл channelЎЈ
Message BrokerЈєПыПўґъАнЈ¬Ѕ«РґИл channel µДПыПў°ґ¶УБРµДЅб№№ЅшРР№ЬАнЎЈёєФрґжґў/ЧЄ·ўПыПўЎЈBroker
Т»°гКЗРиТЄµҐ¶АґоЅЁЎўЕдЦГµДјЇИєЈ¬¶шЗТ±ШРлКЗёЯїЙУГµДЎЈ
ConsumerЈєПыПўµДПы·СХЯЎЈДїЗ°ґу¶аКэµДПыПў¶УБР¶јКЗ±ЈЦ¤ПыПўЦБЙЩ±»Пы·СТ»ґОЎЈЛщТФёщѕЭК№УГµДПыПў¶УБРЙиК©І»Н¬Ј¬Пы·СХЯТЄЧцєГГЭµИЎЈ
І»Н¬µДПыПў¶УБРµДКµПЦЈ¬ПыПўДЈРНІ»Н¬ЎЈёчёцїтјЬµДМШРФТІІ»Н¬Јє
RabbitMQ
RabbitMQ КЗ»щУЪ AMQP РТйµДїЄФґКµПЦЈ¬УЙТФёЯРФДЬЎўїЙЙмЛхРФіцГыµД
Erlang РґіЙЎЈДїЗ°їН»§¶ЛЦ§іЦ JavaЎў.Net/C# єН ErlangЎЈФЪ AMQPЈЁ Advanced
Message Queuing Protocol Ј©µДЧйјюЦРЈ¬Broker ЦРїЙТФ°ьє¬¶аёцExchangeЈЁЅ»»»»ъЈ©ЧйјюЎЈExchange
їЙТФ°у¶Ё¶аёц Queue ТФј°ЖдЛы ExchangeЎЈПыПў»б°ґХХ Exchange ЦРЙиЦГµД Routing
№жФтЈ¬·ўЛНµЅПаУ¦µД Message QueueЎЈФЪ Consumer Пы·СБЛХвёцПыПўЦ®єуЈ¬»бёъ Broker
ЅЁБўБ¬ЅУЎЈ·ўЛНПы·СПыПўµДНЁЦЄЎЈФт Message Queue ІЕ»бЅ«ХвёцПыПўТЖіэЎЈ
Kafka
Kafka КЗТ»ёцёЯРФДЬµД»щУЪ·ўІј/¶©ФДµДїзУпСФ·ЦІјКЅПыПўПµНіЎЈKafka µДїЄ·ўУпСФОЄ ScalaЎЈЖд±ИЅПЦШТЄµДМШРФКЗЈє
ТФК±јдёґФУ¶ИОЄO(1)µД·ЅКЅїмЛЩПыПўіЦѕГ»ЇЈ»
ёЯНМНВВКЈ»
Ц§іЦ·юОсјдµДПыПў·ЦЗшЈ¬ј°·ЦІјКЅПы·СЈ¬Н¬К±±ЈЦ¤ПыПўЛіРтґ«КдЈ»
Ц§іЦФЪПЯЛ®ЖЅА©Х№,ЧФґшёєФШѕщєвЈ»
Ц§іЦЦ»Пы·СЗТЅцПы·СТ»ґОЈЁExactly OnceЈ©ДЈКЅµИµИЎЈ
ЛµёцИ±µгЈє №ЬАнЅзГжКЗёц±ИЅПј¦АЯБЛµгЈ¬їЙТФК№УГїЄФґµДkafka-manager
ЖдёЯНМНВµДМШРФЈ¬іэБЛїЙТФЧчОЄОў·юОсЦ®јдµДПыПў¶УБРЈ¬ТІїЙТФУГУЪИХЦѕКХјЇЈ¬ АлПЯ·ЦОцЈ¬ КµК±·ЦОцµИЎЈ
Kafka №Щ·ЅМṩБЛ Java °ж±ѕµДїН»§¶Л APIЈ¬Kafka ЙзЗшДїЗ°ТІЦ§іЦ¶аЦЦУпСФЈ¬°ьАЁ
PHPЎўPythonЎўGoЎўC/C++ЎўRubyЎўNodeJS µИЎЈ
ActiveMQ
ActiveMQ КЗ»щУЪ JMSЈЁJava Messaging ServiceЈ©КµПЦµД JMSProviderЎЈJMSЦчТЄМṩБЛБЅЦЦАаРНµДПыПўЈєµг¶ФµгЈЁPoint-to-PointЈ©ТФј°·ўІј/¶©ФДЈЁPublish/SubscribeЈ©ЎЈДїЗ°їН»§¶ЛЦ§іЦ
JavaЎўCЎўC++Ўў C#ЎўRubyЎўPerlЎўPythonЎўPHPЎЈ¶шЗТ ActiveMQ Ц§іЦ¶аЦЦРТйЈєStompЎўAMQPЎўMQTT
ТФј° OpenWireЎЈ
RocketMQ/ONS
RocketMQ КЗУЙ°ўАп°Н°НСР·ўїЄФґµДёЯїЙУГ·ЦІјКЅПыПў¶УБРЎЈONSКЗМṩЙМТµ°жµДёЯїЙУГјЇИєЎЈONS
Ц§іЦ pull/pushЎЈїЙЦ§іЦЦч¶ЇНЖЛНЈ¬°ЩТЪј¶±рПыПў¶С»эЎЈONS Ц§іЦИ«ѕЦµДЛіРтПыПўЈ¬ТФј°УРУСєГµД№ЬАнТіГжЈ¬їЙТФєЬєГµДјаїШПыПў¶УБРµДПы·СЗйїцЈ¬ІўЗТЦ§іЦКЦ¶ЇґҐ·ўПыПў¶аґОЦШ·ўЎЈ
РЎЅб
НЁ№эЙПЖЄµДОў·юОсµД·юОс·ўПЦ»ъЦЖЈ¬јУЙП Restful APIЈ¬їЙТФЅвѕцОў·юОсјдµДН¬ІЅ·ЅКЅµДЅшіМјдНЁРЕЎЈµ±И»Ј¬јИИ»К№УГБЛОў·юОсЈ¬ѕНПЈНыЛщУРµДОў·юОсДЬУРєПАнµДПЮЅзЙППВОДЈЁПµНі±ЯЅзЈ©ЎЈОў·юОсЦ®јдµДН¬ІЅНЁРЕУ¦ѕЎБї±ЬГвЈ¬ТФ·АЦ№·юОсјдµДБмУтДЈРН»ҐПаЗЦИлЎЈОЄБЛ±ЬГвХвЦЦЗйїцЈ¬ѕНїЙТФФЪОў·юОсµДјЬ№№ЦРК№УГТ»ІгAPI
gatewayЈЁ»бФЪПВОДЅйЙЬЈ©ЎЈЛщУРµДОў·юОсНЁ№эAPI gatewayЅшРРНіТ»µДЗлЗуµДЧЄ·ўЈ¬єПІўЎЈІўЗТAPI
gatewayТІРиТЄЦ§іЦН¬ІЅЗлЗуЈ¬ТФј°NIOµДТмІЅµДЗлЗуЈЁїЙТФМбёЯЗлЗуєПІўµДР§ВКТФј°РФДЬЈ©ЎЈПлС§ОДЦРµДјјКхїЙТФјУИлОТµДИєЈє619881427
ПыПў¶УБРїЙТФУГУЪОў·юОсјдµДЅвсоЎЈФЪ»щУЪDockerµДОў·юОсµД·юОсјЇИє»·ѕіПВЈ¬НшВз»·ѕі»б±ИТ»°гµД·ЦІјКЅјЇИєёґФУЎЈСЎФсТ»ЦЦёЯїЙУГµД·ЦІјКЅПыПў¶УБРКµПЦјґїЙЎЈИз№ыЧФјєґоЅЁЦоИзKafkaЎўRabbitMQјЇИє»·ѕіµД»°Ј¬ДЗ¶ФУЪBrokerЙиК©µДёЯїЙУГРФ»бТЄЗуєЬёЯЎЈ»щУЪSpringbootµДОў·юОсµД»°Ј¬±ИЅПНЖјцК№УГKafka
»тХЯONSЎЈЛдИ»ONSКЗЙМУГµДЈ¬µ«КЗТЧУЪ№ЬАнТФј°ОИ¶ЁРФёЯЈ¬УИЖд¶ФУЪ±ШТЄіЎѕ°ІЕТААµУЪПыПў¶УБРЅшРРНЁРЕµДОў·юОсјЬ№№АґЛµ,»бёьККєПЎЈИз№ыїјВЗµЅ»бґжФЪИХЦѕКХјЇЈ¬КµК±·ЦОцµИіЎѕ°Ј¬ТІїЙТФґоЅЁKafkaјЇИєЎЈДїЗ°°ўАпФЖТІУРБЛ»щУЪKafkaµДЙМУГјЇИєЙиК©ЎЈ
К№УГ API Gateway ґ¦АнОў·юОсЗлЗуЧЄ·ўЎўєПІў
З°ГжЦчТЄЅйЙЬБЛИзєОЅвѕцОў·юОсµД·юОс·ўПЦєННЁРЕОКМвЎЈФЪОў·юОсµДјЬ№№МеПµЦРЈ¬К№УГDDDЛјПл»®·Ц·юОсјдµДПЮЅзЙППВОДµДК±єтЈ¬»бѕЎБїјхЙЩОў·юОсЦ®јдµДµчУГЎЈОЄБЛЅвсоОў·юОсЈ¬±гУРБЛ»щУЪAPI
Gateway·ЅКЅµДУЕ»Ї·Ѕ°ёЎЈ
ЅвсоОў·юОсµДµчУГ
±ИИзЈ¬ПВГжТ»ёціЈјыµДРиЗуіЎѕ°ЎЄЎЄЎ°УГ»§¶©µҐБР±нЎ±µДТ»ёцѕЫєПТіГжЎЈРиТЄЗлЗуЎ±УГ»§·юОсЎ°»сИЎ»щґЎУГ»§РЕПўЈ¬ТФј°Ў±¶©µҐ·юОсЎ°»сИЎ¶©µҐРЕПўЈ¬ФЩНЁ№эЗлЗуЎ°ЙМЖ··юОсЎ±»сИЎ¶©µҐБР±нЦРµДЙМЖ·НјЖ¬Ўў±кМвµИРЕПўЎЈИзПВНјЛщКѕµДіЎѕ°
Јє
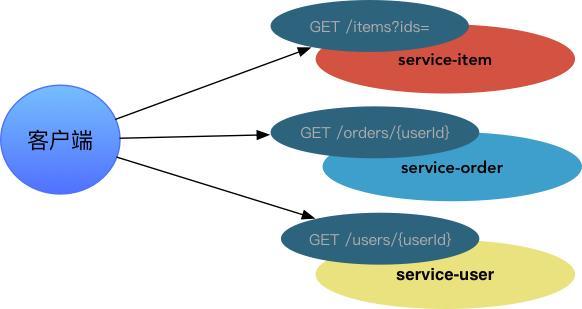
Из№ыИГїН»§¶ЛЈЁ±ИИзH5ЎўAndroidЎўiOSЈ©·ўіц¶аёцЗлЗуАґЅвѕц¶аёцРЕПўѕЫєПЈ¬Фт»бФцјУїН»§¶ЛµДёґФУ¶ИЎЈ±ИЅПєПАнµД·ЅКЅѕНКЗФцјУAPI
GatewayІгЎЈAPI GatewayёъОў·юОсТ»СщЈ¬ТІїЙТФІїКрЎўФЛРРФЪDockerИЭЖчЦРЈ¬ТІКЗТ»ёцSpringbootУ¦УГЎЈИзПВЈ¬НЁ№эGateway
APIЅшРРЧЄ·ўєуЈє
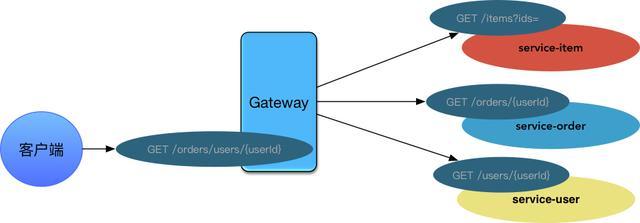
ЛщУРµДЗлЗуµДРЕПўЈ¬УЙGatewayЅшРРѕЫєПЈ¬GatewayТІКЗЅшИлПµНіµДОЁТ»ЅЪµгЎЈІўЗТGatewayєНЛщУРОў·юОсЈ¬ТФј°МṩёшїН»§¶ЛµДТІКЗRestful·зёсAPIЎЈGatewayІгµДТэИлїЙТФєЬєГµДЅвѕцРЕПўµДѕЫєПОКМвЎЈ¶шЗТїЙТФёьєГµГККЕдІ»Н¬µДїН»§¶ЛµДЗлЗ󣬱ИИзH5µДТіГжІ»РиТЄХ№КѕУГ»§РЕПўЈ¬¶шiOSїН»§¶ЛРиТЄХ№КѕУГ»§РЕПўЈ¬ФтЦ»РиТЄМнјУТ»ёцGateway
APIЗлЗуЧКФґјґїЙЈ¬Оў·юОсІгµДЧКФґІ»РиТЄЅшРР±дёьЎЈ
API Gateway µДМШµг
API gatewayіэБЛїЙТФЅшРРЗлЗуµДєПІўЎўЧЄ·ўЎЈ»№РиТЄУРЖдЛыµДМШµгЈ¬ІЕДЬіЙОЄТ»ёцНкХыµДGatewayЎЈ
ПмУ¦КЅ±аіМ
GatewayКЗЛщУРїН»§¶ЛЗлЗуµДИлїЪЎЈАаЛЖFacadeДЈКЅЎЈОЄБЛМбёЯЗлЗуµДРФДЬЈ¬ЧоєГСЎФсТ»МЧ·ЗЧиИыI/OµДїтјЬЎЈФЪТ»Р©РиТЄЗлЗу¶аёцОў·юОсµДіЎѕ°ПВЈ¬¶ФУЪГїёцОў·юОсµДЗлЗуІ»Т»¶ЁРиТЄН¬ІЅЎЈЗ°ОДѕЩАэµДЎ°УГ»§¶©µҐБР±нЎ±µДАэЧУЦРЈ¬»сИЎУГ»§РЕПўЈ¬ТФј°»сИЎ¶©µҐБР±нЈ¬ѕНКЗБЅёц¶АБўЗлЗуЎЈЦ»УР»сИЎ¶©µҐµДЙМЖ·РЕПўЈ¬РиТЄµИ¶©µҐРЕПў·µ»ШЦ®єуЈ¬ёщѕЭ¶©µҐµДЙМЖ·idБР±нФЩИҐЗлЗуЙМЖ·Оў·юОсЎЈОЄБЛјхЙЩХыёцЗлЗуµДПмУ¦К±јдЈ¬РиТЄGatewayДЬ№»Іў·ўґ¦АнП໥¶АБўµДЗлЗуЎЈТ»ЦЦЅвѕц·Ѕ°ёѕНКЗІЙУГПмУ¦КЅ±аіМЎЈ
ДїЗ°К№УГJavaјјКхХ»µДПмУ¦КЅ±аіМ·ЅКЅУРЈ¬Java8µДCompletableFutureЈ¬ТФј°ReactiveXМṩµД»щУЪJVMµДКµПЦ-RxJavaЎЈ
ReactiveXКЗТ»ёцК№УГїЙ№ЫІмКэѕЭБчЅшРРТмІЅ±аіМµД±аіМЅУїЪЈ¬ReactiveXЅбєПБЛ№ЫІмХЯДЈКЅЎўµьґъЖчДЈКЅєНєЇКэКЅ±аіМµДѕ«»ЄЎЈіэБЛRxJava»№УРRxJS,RX.NETµИ¶аУпСФµДКµПЦЎЈ
¶ФУЪGatewayАґЛµЈ¬RxJavaМṩµДObservableїЙТФєЬєГµДЅвѕцІўРРµД¶АБўI/OЗлЗуЈ¬ІўЗТИз№ыОў·юОсПоДїЦРК№УГJava8Ј¬НЕ¶УіЙФ±»б¶ФRxJavaµДєЇКэС§П°ОьКХ»бёьїмЎЈН¬Сщ»щУЪLambda·зёсµДПмУ¦КЅ±аіМЈ¬їЙТФК№ґъВлёьјУјтЅаЎЈ№ШУЪRxJavaµДПкПёЅйЙЬїЙТФїЙТФФД¶БRxJavaОДµµєНЅМіМЎЈ
НЁ№эПмУ¦КЅ±аіМµДObservableДЈКЅЈ¬їЙТФєЬјтЅаЎў·Ѕ±гµГґґЅЁКВјюБчЎўКэѕЭБчЈ¬ТФј°УГјтЅаµДєЇКэЅшРРКэѕЭµДЧйєПєНЧЄ»»Ј¬Н¬К±їЙТФ¶©ФДИОєОїЙ№ЫІмµДКэѕЭБчІўЦґРРІЩЧчЎЈ
НЁ№эК№УГRxJava,Ў°УГ»§¶©µҐБР±нЎ±µДЧКФґЗлЗуК±РтНјЈє
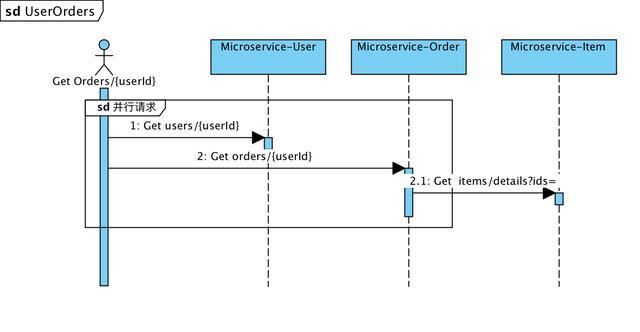
ПмУ¦КЅ±аіМїЙТФёьєГµДґ¦АнёчЦЦПЯіМН¬ІЅЎўІў·ўЗлЗуЈ¬НЁ№эObservablesєНSchedulersМṩБЛНёГчµДКэѕЭБчЎўКВјюБчµДПЯіМґ¦АнЎЈФЪГфЅЭїЄ·ўДЈКЅПВЈ¬ПмУ¦КЅ±аіМК№ґъВлёьјУјтЅаЈ¬ёьєГО¬»¤ЎЈ
јшИЁ
GatewayЧчОЄПµНіµДОЁТ»ИлїЪЈ¬»щУЪОў·юОсµДЛщУРјшИЁЈ¬¶јїЙТФО§ИЖGatewayИҐЧцЎЈФЪSpringboot№¤іМЦРЈ¬»щґЎµДКЪИЁїЙТФК№УГspring-boot-starter-securityТФј°Spring
SecurityЈЁSpring SecurityТІїЙТФјЇіЙФЪSpring MVCПоДїЦРЈ©ЎЈ
Spring SecurityЦчТЄК№УГAOPЈ¬¶ФЧКФґЗлЗуЅшРРА№ЅШЈ¬ДЪІїО¬»¤БЛТ»ёцЅЗЙ«µДFilter
ChainЎЈТтОЄОў·юОс¶јКЗНЁ№эGatewayЗлЗуµДЈ¬ЛщТФОў·юОсµД@SecuredїЙТФёщѕЭGatewayЦРІ»Н¬µДЧКФґµДЅЗЙ«ј¶±рЅшРРЙиЦГЎЈ
Spring SecurityМṩБЛ»щґЎµДЅЗЙ«µДРЈСйЅУїЪ№ж·¶ЎЈµ«їН»§¶ЛЗлЗуµДTokenРЕПўµДјУГЬЎўґжґўТФј°СйЦ¤Ј¬РиТЄУ¦УГЧФјєНкіЙЎЈ¶ФУЪTokenјУГЬРЕПўµДґжґўїЙТФК№УГRedisЎЈХвАпФЩ¶аМбТ»µгЈ¬ОЄБЛ±ЈЦ¤Т»Р©јУГЬРЕПўµДїЙ±дРФЈ¬ЧоєГФЪТ»їЄКјЙијЖTokenДЈїйµДК±єтѕНїјВЗµЅЦ§іЦ¶аёц°ж±ѕГЬФїЈ¬ТФ·АЦ№НтТ»ДЪІїГЬФї±»Р№В¶ЈЁЦ®З°МэТ»ёцЕуУСЛµЖ乫˾µДTokenјУГЬґъВл±»Ф±№¤№«ІјіцИҐЈ©ЎЈЦБУЪјУГЬЛг·ЁЈ¬ТФј°ѕЯМеµДКµПЦФЪґЛѕНІ»ФЩХ№їЄЎЈ
ФЪGatewayјшИЁНЁ№эЦ®єуЈ¬ЅвОцєуµДtokenРЕПўїЙТФЦ±ЅУґ«µЭёшРиТЄјМРшЗлЗуµДОў·юОсІгЎЈПлС§ОДЦРµДјјКхїЙТФјУИлОТµДИєЈє619881427
Из№ыУ¦УГРиТЄКЪИЁЈЁ¶ФЧКФґЗлЗуРиТЄ№ЬАнІ»Н¬µДЅЗЙ«ЎўИЁПЮЈ©Ј¬ТІЦ»ТЄФЪGatewayµДRest API»щґЎЙП»щУЪAOPЛјПлАґЧцјґїЙЎЈНіТ»№ЬАнјшИЁєНКЪИЁЈ¬ХвТІКЗК№УГАаЛЖFacadeДЈКЅµДGateway
APIµДєГґ¦Ц®Т»ЎЈ
ёєФШѕщєв
API GatewayёъMicroserviceТ»СщЈ¬ЧчОЄSpringbootУ¦УГЈ¬МṩRest
apiЎЈЛщТФН¬СщФЛРРФЪDockerИЭЖчЦРЎЈGatewayєНОў·юОсЦ®јдµД·юОс·ўПЦ»№КЗїЙТФІЙУГЗ°ОДЛщКцµДїН»§¶Л·ўПЦДЈКЅЈ¬»тХЯ·юОс¶Л·ўПЦДЈКЅЎЈ
ФЪјЇИє»·ѕіПВЈ¬API Gateway їЙТФ±©В¶НіТ»µД¶ЛїЪЈ¬ЖдКµАэ»бФЛРРФЪІ»Н¬IPµД·юОсЖчЙПЎЈТтОЄОТГЗКЗК№УГ°ўАпФЖµДECSЧчОЄИЭЖчµД»щґЎЙиК©Ј¬ЛщТФФЪјЇИє»·ѕіµДёєФШѕщєвТІКЗК№УГ°ўАпФЖµДёєФШѕщєвSLB,УтГыЅвОцТІК№УГAliyunDNSЎЈПВНјКЗТ»ёцјтµҐµДНшВзЗлЗуµДКѕТвЈє
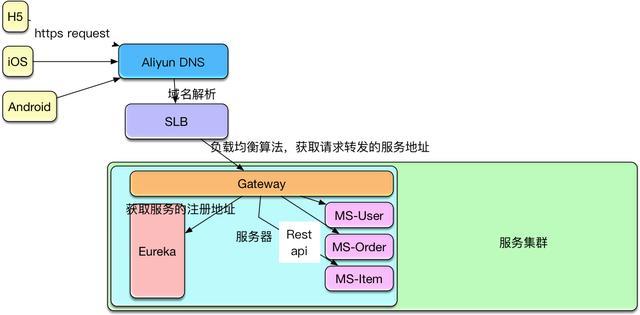
ФЪКµјщЦРЈ¬ОЄБЛІ»±©В¶·юОсµД¶ЛїЪєНЧКФґµШЦ·Ј¬ТІїЙТФФЪ·юОсјЇИєЦРФЩІїКрNginx·юОсЧчОЄ·ґПтґъАнЈ¬НвІїµДёєФШѕщєвЙиК©±ИИзSLBїЙТФЅ«ЗлЗуЧЄ·ўµЅNginx·юОсЖчЈ¬ЗлЗуНЁ№эNginxФЩЧЄ·ўёшGateway¶ЛїЪЎЈИз№ыКЗЧФЅЁ»ъ·їµДјЇИєЈ¬ѕНРиТЄґоЅЁёЯїЙУГµДёєФШѕщєвЦРРДЎЈОЄБЛУ¦¶Фїз»ъЖчЗлЗуЈ¬ЧоєГК№УГConsul,ConsulЈЁConsul
TemplateЈ©+Registor+HaproxyАґЧц·юОс·ўПЦєНёєФШѕщєвЦРРДЎЈ
»єґж
¶ФУЪТ»Р©ёЯQPSµДЗлЗуЈ¬їЙТФФЪAPI GatewayЧц¶ај¶»єґжЎЈ·ЦІјКЅµД»єґжїЙТФК№УГRedisЈ¬MemcachedµИЎЈИз№ыКЗТ»Р©¶ФКµК±РФТЄЗуІ»ёЯµДЈ¬±д»ЇЖµВКІ»ёЯµ«КЗёЯQPSµДТіГжј¶ЗлЗуЈ¬ТІїЙТФФЪGatewayІгЧц±ѕµШ»єґжЎЈ¶шЗТGatewayїЙТФИГ»єґж·Ѕ°ёёьБй»оєННЁУГЎЈ
API GatewayµДґнОуґ¦Ан
ФЪGatewayµДѕЯМеКµПЦ№эіМЦРЈ¬ґнОуґ¦АнТІКЗТ»ёцєЬЦШТЄµДКВЗйЎЈ¶ФУЪGatewayµДґнОуґ¦АнЈ¬їЙТФК№УГHystrixАґґ¦АнЗлЗуµДИЫ¶ПЎЈІўЗТRxJavaЧФґшµДonErrorReturn»ШµчТІїЙТФ·Ѕ±гµГґ¦АнґнОуРЕПўµД·µ»ШЎЈ¶ФУЪИЫ¶П»ъЦЖЈ¬РиТЄґ¦АнТФПВјёёц·ЅГжЈє
·юОсЗлЗуµДИЭґнґ¦Ан
ЧчОЄТ»ёцєПАнµДGatewayЈ¬ЖдУ¦ёГЦ»ёєФрґ¦АнКэѕЭБчЎўКВјюБчЈ¬¶шІ»У¦ёГґ¦АнТµОсВЯјЎЈФЪґ¦Ан¶аёцОў·юОсµДЗлЗуК±Ј¬»біцПЦОў·юОсЗлЗуµДі¬К±ЎўІ»їЙУГµДЗйїцЎЈФЪТ»Р©МШ¶ЁµДіЎѕ°ПВЈ¬
РиТЄДЬ№»єПАнµГґ¦АнІї·ЦК§°ЬЎЈ±ИИзЙПАэЦРµДЎ°УГ»§¶©µҐБР±нЎ±Ј¬µ±Ў°UserЎ±Оў·юОсіцПЦґнОуК±Ј¬І»У¦ёГУ°ПмЎ°OrderЎ±КэѕЭµДЗлЗуЎЈЧоєГµДґ¦Ан·ЅКЅѕНКЗёшµ±К±ґнОуµДУГ»§РЕПўЗлЗу·µ»ШТ»ёцД¬ИПµДКэѕЭЈ¬±ИИзПФКѕТ»ёцД¬ИПН·ПсЈ¬Д¬ИПУГ»§кЗіЖЎЈИ»єу¶ФУЪЗлЗуХэіЈµД¶©µҐЈ¬ТФј°ЙМЖ·РЕПўёшУлХэИ·µДКэѕЭ·µ»ШЎЈИз№ыКЗТ»ёц№ШјьµДОў·юОсЗлЗуТміЈЈ¬±ИИзµ±Ў°OrderЎ±БмУтµДОў·юОсТміЈК±Ј¬ФтУ¦ёГёшїН»§¶ЛТ»ёцґнОуВлЈ¬ТФј°єПАнµДґнОуМбКѕРЕПўЎЈХвСщµДґ¦АнїЙТФѕЎБїФЪІї·ЦПµНіІ»їЙУГК±МбЙэУГ»§МеСйЎЈК№УГRxJavaК±Ј¬ѕЯМеµДКµПЦ·ЅКЅѕНКЗХл¶ФІ»Н¬µДїН»§¶ЛЗлЗуµДЗйїцЈ¬РґєГonErrorReturnЈ¬ЧцєГґнОуКэѕЭјжИЭјґїЙЎЈ
ТміЈµДІ¶ЧЅєНјЗВј
GatewayЦчТЄКЗЧцЗлЗуµДЧЄ·ўЎўєПІўЎЈОЄБЛДЬЗеіюµГЕЕІйОКМвЈ¬¶ЁО»µЅѕЯМеДДёц·юОсЎўЙхЦБКЗДДёцDockerИЭЖчµДОКМвЈ¬РиТЄGatewayДЬ¶ФІ»Н¬АаРНµДТміЈЎўТµОсґнОуЅшРРІ¶ЧЅєНјЗВјЎЈИз№ыК№УГFeignClientАґЗлЗуОў·юОсЧКФґЈ¬їЙТФНЁ№э¶ФErrorDecoderЅУїЪµДКµПЦЈ¬АґХл¶ФResponseЅб№ыЅшРРЅшТ»ІЅµД№эВЛґ¦АнЈ¬ТФј°ФЪИХЦѕЦРјЗВјПВЛщУРЗлЗуРЕПўЎЈИз№ыКЗК№УГSpring
Rest Template,ФтїЙТФНЁ№э¶ЁТеТ»ёц¶ЁЦЖ»ЇµДRestTempateЈ¬Іў¶Ф·µ»ШµДResponseEntityЅшРРЅвОцЎЈФЪ·µ»ШРтБР»ЇЦ®єуµДЅб№ы¶ФПуЦ®З°Ј¬¶ФґнОуРЕПўЅшРРИХЦѕјЗВјЎЈ
і¬К±»ъЦЖ
GatewayПЯіМЦРґу¶аКЗIOПЯіМЈ¬ОЄБЛ·АЦ№ТтОЄДіТ»Оў·юОсЗлЗуЧиИыЈ¬µјЦВGateway№э¶аµДµИґэПЯіМЈ¬єДѕЎПЯіМіШЎў¶УБРµИПµНіЧКФґЎЈРиТЄGatewayЦРМṩі¬К±»ъЦЖЈ¬¶Фі¬К±ЅУїЪДЬЅшРРУЕСЕµД·юОсЅµј¶ЎЈ
ФЪSpringCloudµДFeignПоДїЦРјЇіЙБЛHystrixЎЈHystrixМṩБЛ±ИЅПИ«ГжµДі¬К±ґ¦АнµДИЫ¶П»ъЦЖЎЈД¬ИПЗйїцПВЈ¬і¬К±»ъЦЖКЗїЄЖфµДЎЈіэБЛїЙТФЕдЦГі¬К±Па№ШµДІОКэЈ¬Netflix»№МṩБЛ»щУЪHytrixµДКµК±јаїШNetflix
-Dashboard,ІўЗТјЇИє·юОсЦ»РиФЩёЅјУІїКрNetflix-TurbineЎЈНЁУГµДHytrixµДЕдЦГПоїЙТФІОїјHystrix-ConfigurationЎЈ
Из№ыКЗК№УГRxJavaµДObservableµДПмУ¦КЅ±аіМЈ¬Пл¶ФІ»Н¬µДЗлЗуЙиЦГІ»Н¬µДі¬К±К±јдЈ¬їЙТФЦ±ЅУФЪObservableµДtimeout()·Ѕ·ЁµДІОКэЅшРРЙиЦГ»ШµчµД·Ѕ·ЁТФј°і¬К±К±јдµИЎЈ
ЦШКФ»ъЦЖ
¶ФУЪТ»Р©№ШјьµДТµОсЈ¬ФЪЗлЗуі¬К±К±Ј¬ОЄБЛ±ЈЦ¤ХэИ·µДКэѕЭ·µ»ШЈ¬РиТЄGatewayДЬМṩЦШКФ»ъЦЖЎЈИз№ыК№УГSpringCloudFeignЈ¬ФтЖдДЪЦГµДRibbonЈ¬»бМṩµДД¬ИПµДЦШКФЕдЦГЈ¬їЙТФНЁ№эЙиЦГspring.cloud.loadbalancer.retry.enabled=falseЅ«Жд№Ш±ХЎЈRibbonМṩµДЦШКФ»ъЦЖ»бФЪЗлЗуі¬К±»тХЯsocket
read timeoutґҐ·ўЈ¬іэБЛЙиЦГЦШКФЈ¬ТІїЙТФ¶ЁЦЖЦШКФµДК±јд·§ЦµТФј°ЦШКФґОКэµИЎЈ
¶ФУЪіэБЛК№УГFeignЈ¬ТІК№УГSpring RestTemplate
µДУ¦УГЈ¬їЙТФНЁ№эЧФ¶ЁТеµДRestTemplate ,¶ФУЪ·µ»ШµДResponseEntity ¶ФПуЅшРРЅб№ыЅвОцЈ¬Из№ыЗлЗуРиТЄЦШКФЈЁ±ИИзДіёц№М¶ЁёсКЅµДerror-code
µД·ЅКЅК¶±рЦШКФІЯВФЈ©Ј¬ФтНЁ№эInterceptor ЅшРРЗлЗуА№ЅШЈ¬ТФј°»ШµчµД·ЅКЅinvoke¶аґОЗлЗуЎЈ
РЎЅб
¶ФУЪОў·юОсµДјЬ№№Ј¬НЁ№эТ»ёц¶АБўµДAPI Gateway,їЙТФЅшРРНіТ»µДЗлЗуЧЄ·ўЎўєПІўТФј°РТйЧЄ»»ЎЈїЙТФёьБй»оµГККЕдІ»Н¬їН»§¶ЛµДЗлЗуКэѕЭЎЈ¶шЗТ¶ФУЪІ»Н¬їН»§¶ЛЈЁ±ИИзH5єНiOSµДХ№КѕКэѕЭІ»Н¬Ј©ЎўІ»Н¬°ж±ѕјжИЭµДЗлЗу,їЙТФєЬєГµШФЪGatewayЅшРРЖБ±ОЈ¬ИГОў·юОсёьјУґїґвЎЈОў·юОсЦ»ТЄ№ШЧўДЪІїµДБмУт·юОсµДЙијЖЈ¬КВјюµДґ¦АнЎЈ
API gateway»№їЙТФ¶ФОў·юОсµДЗлЗуЅшРРТ»¶ЁµДИЭґнЎў·юОсЅµј¶ЎЈК№УГПмУ¦КЅ±аіМАґКµПЦAPI gatewayїЙТФК№ПЯіМН¬ІЅЎўІў·ўµДґъВлёьјтЅаЈ¬ёьТЧУЪО¬»¤ЎЈФЪ¶ФУЪОў·юОсµДЗлЗуїЙТФНіТ»НЁ№эFeignClintЎЈґъВлТІ»бєЬУРІгґОЎЈИзПВНјЈ¬КЗТ»ёцКѕАэµДЗлЗуµДАаІгґОЎЈ
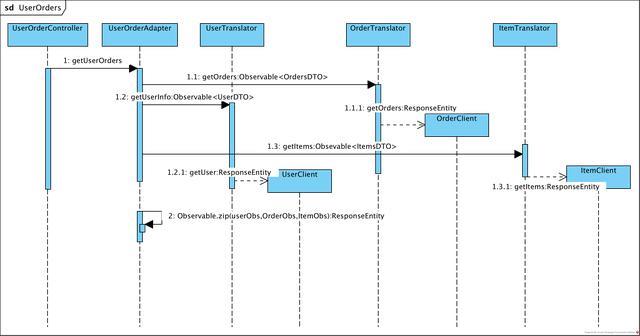
ClintёєФрјЇіЙ·юОс·ўПЦЈЁ¶ФУЪК№УГEurekaЧФЧўІб·ЅКЅЈ©ЎўёєФШѕщєвТФј°·ўіцЗлЗуЈ¬Іў»сИЎResponseEntity¶ФПуЎЈ
TranslatorЅ«ResponseEntityЧЄ»»іЙObservable<XDTO>¶ФПуЈ¬ТФј°¶ФТміЈЅшРРНіТ»ИХЦѕІЙјЇЈ¬АаЛЖУЪDDDЦР·АёЇІгµДёЕДоЎЈ
AdapterµчУГёчёцTranslatorЈ¬К№УГObservableєЇКэЈ¬¶ФЗлЗуµДКэѕЭБчЅшРРєПІўЎЈИз№ыґжФЪ¶аёцКэѕЭµДЧйЧ°Ј¬їЙТФФцјУТ»ІгAssemblerЧЁГЕґ¦АнDTO¶ФПуµЅModelµДЧЄ»»ЎЈ
Controller,МṩRestfulЧКФґµД№ЬАнЈ¬ГїёцControllerЦ»ЗлЗуОЁТ»µДТ»ёцAdapter·Ѕ·ЁЎЈ
Оў·юОсµДіЦРшјЇіЙІїКр
З°ОДЦчТЄЅйЙЬБЛОў·юОсµД·юОс·ўПЦЎў·юОсНЁРЕТФј°API GatewayЎЈХыМеµДОў·юОсјЬ№№µДДЈРНіхјыЎЈФЪКµјКµДїЄ·ўЎўІвКФТФј°ЙъІъ»·ѕіЦРЎЈК№УГDockerКµПЦОў·юОсЈ¬јЇИєµДНшВз»·ѕі»бёьјУёґФУЎЈОў·юОсјЬ№№±ѕЙнѕНТвО¶ЧЕРиТЄ¶ФИфёЙёцИЭЖч·юОсЅшРРЦОАнЈ¬ГїёцОў·юОс¶јУ¦їЙТФ¶АБўІїКрЎўА©ИЭЎўјаїШЎЈПВГж»бјМРшЅйЙЬИзєОЅшРРDockerОў·юОсµДіЦРшјЇіЙІїКрЈЁCI/CDЈ©ЎЈ
ѕµПсІЦїв
УГDockerАґІїКрОў·юОс,РиТЄЅ«Оў·юОсґт°ьіЙDockerѕµПсЈ¬ѕНИзН¬ІїКрФЪWeb serverґт°ьіЙwarОДјюТ»СщЎЈЦ»І»№эDockerѕµПсФЛРРФЪDockerИЭЖчЦРЎЈПлС§ОДЦРµДјјКхїЙТФјУИлОТµДИєЈє619881427
Из№ыКЗSpringboot·юОсЈ¬Фт»бЦ±ЅУЅ«°ьє¬Apache Tomcat serverµДSpringbootЈ¬ТФј°°ьє¬JavaФЛРРївµД±аТлєуµДJavaУ¦УГґт°ьіЙDockerѕµПсЎЈ
ОЄБЛДЬНіТ»№ЬАнґт°ьТФј°·Ц·ўЈЁpull/pushЈ©ѕµПсЎЈЖуТµТ»°гРиТЄЅЁБўЧФјєµДѕµПсЛЅївЎЈКµПЦ·ЅКЅТІєЬјтµҐЎЈїЙТФФЪ·юОсЖчЙПЦ±ЅУІїКрDocker
hubµДѕµПсІЦївµДИЭЖч°жRegistry2ЎЈДїЗ°ЧоРВµД°ж±ѕКЗV2ЎЈ
ґъВлІЦїв
ґъВлµДМбЅ»Ўў»Ш№цµИ№ЬАнЈ¬ТІКЗПоДїіЦРшјЇіЙµДТ»»·ЎЈТ»°гТІКЗРиТЄЅЁБўЖуТµµДґъВлІЦївµДЛЅївЎЈїЙТФК№УГSVN,GITµИґъВл°ж±ѕ№ЬАн№¤ѕЯЎЈ
ДїЗ°№«ЛѕК№УГµДКЗGitlab,НЁ№эGitµДDockerѕµПс°ІЧ°ЎўІїКрІЩЧчТІєЬ±гЅЭЎЈѕЯМеІЅЦиїЙТФІОїјdocker
gitlab installЎЈОЄБЛДЬїмЛЩ№№ЅЁЎўґт°ьЈ¬ТІїЙЅ«GitєНRegistryІїКрФЪН¬Т»МЁ·юОсЖчЙПЎЈ
ПоДї№№ЅЁ
ФЪSpringbootПоДїЦРЈ¬№№ЅЁ№¤ѕЯїЙТФУГMaven,»тХЯGradleЎЈGradleПа±ИMavenёьјУБй»оЈ¬¶шЗТSpringbootУ¦УГ±ѕЙнИҐЕдЦГ»ЇµДМШµгЈ¬УГ»щУЪGroovyµДGradle»бёьјУККєПЈ¬DSL±ѕЙнТІ±ИXMLёьјУјтЅаёЯР§ЎЈ
ТтОЄGradleЦ§іЦЧФ¶ЁТеtaskЎЈЛщТФОў·юОсµДDockerfileРґєГЦ®єуЈ¬ѕНїЙТФУГGradleµДtaskЅЕ±ѕАґЅшРР№№ЅЁґт°ьіЙDocker
ImageЎЈ
ДїЗ°ТІУРТ»Р©їЄФґµДGradle№№ЅЁDockerѕµПсµД№¤ѕЯЈ¬±ИИзTransmode-GradlewІејюЎЈЖдіэБЛїЙТФ¶ФЧУПоДїЈЁµҐёцОў·юОсЈ©ЅшРР№№ЅЁDockerѕµПсЈ¬ТІїЙТФЦ§іЦН¬К±ЙПґ«ѕµПсµЅФ¶іМѕµПсІЦївЎЈФЪЙъІъ»·ѕіЦРµДbuild»ъЖчЙПЈ¬їЙТФНЁ№эТ»ёцГьБоЦ±ЅУЦґРРПоДїµДbuild,Docker
ImageµДґт°ь,ТФј°ѕµПсµДpushЎЈ
ИЭЖч±аЕЕјјКх
DockerѕµПс№№ЅЁЦ®єуЈ¬ТтОЄГїёцИЭЖчФЛРРЧЕІ»Н¬µДОў·юОсКµАэЈ¬ИЭЖчЦ®јдТІКЗёфАлІїКр·юОсµДЎЈНЁ№э±аЕЕјјКхЈ¬їЙТФК№DevOpsЗбБї»Ї№ЬАнИЭЖчµДІїКрТФј°јаїШЈ¬ТФМбёЯИЭЖч№ЬАнµДР§ВКЎЈ
ДїЗ°Т»Р©НЁУГµД±аЕЕ№¤ѕЯ±ИИзAnsibleЎўChefЎўPuppetЈ¬ТІїЙТФЧцИЭЖчµД±аЕЕЎЈµ«ЛыГЗ¶јІ»КЗЧЁГЕХл¶ФИЭЖчµД±аЕЕ№¤ѕЯЈ¬ЛщТФК№УГК±РиТЄЧФјє±аРґТ»Р©ЅЕ±ѕЈ¬ЅбєПDockerµДГьБоЎЈ±ИИзAnsibleЈ¬И·КµїЙТФКµПЦєЬ±гАыµДјЇИєµДИЭЖчµДІїКрєН№ЬАнЎЈДїЗ°AnsibleХл¶ФЖдНЕ¶УЧФјєСР·ўµДИЭЖчјјКхМṩБЛјЇіЙ·Ѕ°ё:Ansible
ContainerЎЈ
јЇИє№ЬАнПµНіЅ«Цч»ъЧчОЄЧКФґіШЈ¬ёщѕЭГїёцИЭЖч¶ФЧКФґµДРиЗуЈ¬ѕц¶ЁЅ«ИЭЖчµч¶ИµЅДДёцЦч»ъЙПЎЈ
ДїЗ°Ј¬О§ИЖDockerИЭЖчµДµч¶ИЎў±аЕЕЈ¬±ИЅПіЙКмµДјјКхУРGoogleµДKubernetes(ПВОД»бјтРґk8s)Ј¬MesosЅбєПMarathon№ЬАнDockerјЇИє,ТФј°ФЪDocker
1.12.0°ж±ѕТФЙП№Щ·ЅМṩµДDocker SwarmЎЈ±аЕЕјјКхКЗИЭЖчјјКхµДЦШµгЦ®Т»ЎЈСЎФсТ»ёцККєПЧФјєНЕ¶УµДИЭЖч±аЕЕјјКхТІїЙТФК№ФЛО¬ёьёЯР§ЎўёьЧФ¶Ї»ЇЎЈ
Docker Compose
Docker ComposeКЗТ»ёцјтµҐµДDockerИЭЖчµД±аЕЕ№¤ѕЯЈ¬НЁ№эYAMLОДјюЕдЦГРиТЄФЛРРµДУ¦УГЈ¬И»єуНЁ№эcompose
upГьБоЖф¶Ї¶аёц·юОс¶ФУ¦µДИЭЖчКµАэЎЈDockerЦРГ»УРјЇіЙCompose,РиТЄБнНв°ІЧ°ЎЈ
ComposeїЙТФУГУЪОў·юОсПоДїµДіЦРшјЇіЙЈ¬µ«ЖдІ»ККєПґуРНјЇИєµДИЭЖч№ЬАнЈ¬ґујЇИєЦРЈ¬їЙТФComposeЅбєПAnsibleЧцјЇИєЧКФґ№ЬАнЈ¬ТФј°·юОсЦОАнЎЈ
¶ФУЪјЇИєЦР·юОсЖчІ»¶аµДЗйїцЈ¬їЙТФК№УГComposeЈ¬ЖдК№УГІЅЦиЦчТЄКЗЈє
ЅбєПОў·юОсФЛРР»·ѕіЈ¬¶ЁТеєГ·юОсµДDockerfile
ёщѕЭ·юОсѕµПсЎў¶ЛїЪЎўФЛРР±дБїµИ±аРґdocker-compose.ymlОДјюЈ¬ТФК№·юОсїЙТФТ»ЖрІїКрЈ¬ФЛРР
ФЛРРdocker-compose up ГьБоЖф¶ЇІўЗТЅшИлИЭЖчКµАэЈ¬Из№ыРиТЄК№УГєуМЁЅшіМ·ЅКЅФЛРРЈ¬К№УГdocker-compose
up -dјґїЙЎЈ
Docker Swarm
ФЪ16ДкЈ¬DockerµД1.12°ж±ѕіцАґЦ®єу,К№УГРВ°ж±ѕµДDocker,ѕНЧФґшDocker swarm
modeБЛЎЈІ»РиТЄ¶оНв°ІЧ°ИОєОІејю№¤ѕЯЎЈїЙТФїґіцИҐДкїЄКјDockerНЕ¶УТІїЄКјЦШКУ·юОс±аЕЕјјКхЈ¬НЁ№эДЪЦГSwarm
modeЈ¬ТІТЄЗАХјТ»Ії·Ц·юОс±аЕЕКРіЎЎЈ
Из№ыНЕ¶УїЄКјК№УГРВ°ж±ѕµДDocker,їЙТФСЎФсDocker swarm modeАґЅшРРјЇИє»ЇµДИЭЖчµч¶ИєН№ЬАнЎЈSwarm»№Ц§іЦ№ц¶ЇёьРВЎўЅЪµгјдґ«КдІг°ІИ«јУГЬЎўёєФШѕщєвµИЎЈ
DockerSwarmµДК№УГКѕАэїЙТФІОїјЦ®З°РґµДТ»ЖЄЈєК№УГdocker-swarmґоЅЁіЦРшјЇіЙјЇИє·юОсЎЈ
Kubernetes
KubernetesКЗGoogleїЄФґµДИЭЖчјЇИє№ЬАнПµНіЈ¬К№УГGoУпСФКµПЦЈ¬ЖдМṩӦУГІїКрЎўО¬»¤Ўў
А©Х№»ъЦЖµИ№¦ДЬЎЈДїЗ°їЙТФФЪGCEЎўvShpereЎўCoreOSЎўOpenShiftЎўAzureµИЖЅМЁК№УГk8sЎЈ№ъДЪДїЗ°AliyunТІМṩБЛ»щУЪk8sµД·юОсЦОАнЖЅМЁЎЈИз№ыКЗ»щУЪОпАн»ъЎўРйДв»ъґоЅЁµДDockerјЇИєµД»°Ј¬ТІїЙТФЦ±ЅУІїКрЎўФЛРРk8sЎЈФЪОў·юОсµДјЇИє»·ѕіПВЈ¬KubernetesїЙТФєЬ·Ѕ±г№ЬАнїз»ъЖчµДОў·юОсИЭЖчКµАэЎЈ
ДїЗ°k8s»щ±ѕКЗ№«ИПµДЧоЗїґуїЄФґ·юОсЦОАнјјКхЦ®Т»ЎЈЖдЦчТЄМṩТФПВ№¦ДЬЈє
1.ЧФ¶Ї»Ї¶Ф»щУЪDocker¶Ф·юОсКµАэЅшРРІїКрєНёґЦЖ
2.ТФјЇИєµД·ЅКЅФЛРРЈ¬їЙТФ№ЬАнїз»ъЖчµДИЭЖчЈ¬ТФј°№ц¶ЇЙэј¶Ўўґжґў±аЕЕЎЈ
3.ДЪЦГБЛ»щУЪDockerµД·юОс·ўПЦєНёєФШѕщєвДЈїй
4.K8sМṩБЛЗїґуµДЧФОТРЮёґ»ъЦЖ,»б¶Ф±ААЈµДИЭЖчЅшРРМж»»(¶ФУГ»§Ј¬ЙхЦБїЄ·ўНЕ¶У¶јОЮёРЦЄ)Ј¬ІўїЙЛжК±А©ИЭЎўЛхИЭЎЈИГИЭЖч№ЬАнёьјУµЇРФ»ЇЎЈ
k8sЦчТЄНЁ№эТФПВјёёцЦШТЄµДЧйјюНкіЙµЇРФИЭЖчјЇИєµД№ЬАнµДЈє
1.PodКЗKubernetesµДЧоРЎµД№ЬАнФЄЛШЈ¬Т»ёц»т¶аёцИЭЖчФЛРРФЪpodЦРЎЈpodµДЙъГьЦЬЖЪєЬ¶МФЭЈ¬»бЛжЧЕµч¶ИК§°ЬЈ¬ЅЪµг±ААЈЈ¬»тХЯЖдЛыЧКФґ»ШКХК±ПыНцЎЈ
2.LabelКЗkey/valueґжґўЅб№№µДЈ¬їЙТФ№ШБЄpodЈ¬ЦчТЄУГАґ±кјЗpodЈ¬ёш·юОс·ЦЧйЎЈОў·юОсЦ®јдНЁ№эlabelСЎФсЖчЈЁSelectorsЈ©АґК¶±рPodЎЈ
3.Replication ControllerКЗk8s MasterЅЪµгµДєЛРДЧйјюЎЈУГАґИ·±ЈИОєОК±єтKubernetesјЇИєЦРУРЦё¶ЁКэБїµДpodё±±ѕ(replicas)ФЛРРЎЈјґМṩБЛЧФОТРЮёґ»ъЦЖµД№¦ДЬЈ¬ІўЗТ¶ФЛхИЭА©ИЭЎў№ц¶ЇЙэј¶ТІєЬУРУГЎЈ
4.ServiceКЗ¶ФТ»ЧйPodµДІЯВФµДійПуЎЈТІКЗk8s№ЬАнµД»щ±ѕФЄЛШЦ®Т»ЎЈServiceНЁ№эLabelК¶±рТ»ЧйPodЎЈґґЅЁК±ТІ»бґґЅЁТ»ёц±ѕµШјЇИєµДDNSЈЁґжґўService¶ФУ¦µДPodµД·юОсµШЦ·Ј©ЎЈЛщТФФЪїН»§¶ЛЗлЗуНЁ№эЗлЗуDNSАґ»сИЎТ»Чйµ±З°їЙУГµДPodsµДipµШЦ·ЎЈЦ®єуНЁ№эГїёцNodeЦРФЛРРµДkube-proxyЅ«ЗлЗуЧЄ·ўёшЖдЦРТ»ёцPodЎЈХвІгёєФШѕщєвКЗНёГчµДЈ¬µ«КЗДїЗ°µДk8sµДёєФШѕщєвІЯВФ»№І»КЗєЬНкЙЖЈ¬Д¬ИПКЗЛж»ъµД·ЅКЅЎЈ
РЎЅб
Оў·юОсјЬ№№МеПµЦРЈ¬Т»ёцєПККµДіЦРшјЇіЙµД№¤ѕЯЈ¬їЙТФєЬєГµГМбЙэНЕ¶УµДФЛО¬ЎўїЄ·ўР§ВКЎЈДїЗ°АаЛЖJenkinsТІУРХл¶ФDockerµДіЦРшјЇіЙµДІејюЈ¬µ«КЗ»№КЗґжФЪєЬ¶аІ»НкЙЖЎЈЛщТФЅЁТй»№КЗСЎФсЧЁГЕУ¦¶ФDockerИЭЖч±аЕЕјјКхµДSwarm,k8s,MesosЎЈ»тХЯ¶аёцјјКхЅбєПЖрАґЈ¬±ИИзJenkinsЧцCI+k8sЧцCDЎЈ
Swarm,k8s,MesosёчУРёчµДМШРФЈ¬ЛыГЗ¶ФУЪИЭЖчµДіЦРшІїКрЎў№ЬАнТФј°јаїШ¶јМṩБЛЦ§іЦЎЈMesos»№Ц§іЦКэѕЭЦРРДµД№ЬАнЎЈDocker
swarm modeА©Х№БЛПЦУРµДDocker APIЈ¬НЁ№эDocker Remote APIµДµчУГєНА©Х№Ј¬їЙТФµч¶ИИЭЖчФЛРРµЅЦё¶ЁµДЅЪµгЎЈKubernetesФтКЗДїЗ°КРіЎ№жДЈЧоґуµД±аЕЕјјКхЈ¬ДїЗ°єЬ¶аґу№«ЛѕТІ¶јјУИлµЅБЛk8sјТЧеЈ¬k8sУ¦¶ФјЇИєУ¦УГµДА©Х№ЎўО¬»¤єН№ЬАнёьјУБй»оЈ¬µ«КЗёєФШѕщєвІЯВФ±ИЅПґЦІЪЎЈ¶шMesosёьЧЁЧўУЪНЁУГµч¶ИЈ¬МṩБЛ¶аЦЦµч¶ИЖчЎЈПлС§ОДЦРµДјјКхїЙТФјУИлОТµДИєЈє619881427
¶ФУЪ·юОс±аЕЕЈ¬»№КЗТЄСЎФсЧоККєПЧФјєНЕ¶УµДЈ¬Из№ыіхЖЪ»ъЖчКэБїєЬЙЩЈ¬јЇИє»·ѕіІ»ёґФУТІїЙТФУГAnsible+Docker
Compose,ФЩјУЙПGitlab CIАґЧціЦРшјЇіЙЎЈ
·юОсјЇИєµДЅвѕц·Ѕ°ё
ЖуТµФЪКµјщК№УГDockerІїКрЎўФЛРРОў·юОсУ¦УГµДК±єтЈ¬ОЮВЫКЗТ»їЄКјѕНІјѕЦОў·юОсјЬ№№Ј¬»тХЯґУґ«НіµДµҐУ¦УГјЬ№№ЅшРРОў·юОс»ЇЗЁТЖЎЈ¶јРиТЄДЬ№»ґ¦АнёґФУµДјЇИєЦРµД·юОсµч¶ИЎў±аЕЕЎўјаїШµИОКМвЎЈПВГжЦчТЄОЄЅйЙЬФЪ·ЦІјКЅµД·юОсјЇИєПВЈ¬ИзєОёь°ІИ«ЎўёЯР§µГК№УГDocker,ТФј°ФЪјЬ№№ЙијЖЙПЈ¬РиТЄїјВЗµД·Ѕ·ЅГжГжЎЈ
ёєФШѕщєв
ХвАпЛµµДКЗјЇИєЦРµДёєФШѕщєвЈ¬Из№ыКЗґї·юОс¶ЛAPIµД»°ѕНКЗЦёGateway APIµДёєФШѕщєвЈ¬Из№ыК№УГБЛNginxµД»°Ј¬ФтКЗЦёNginxµДёєФШѕщєвЎЈОТГЗДїЗ°К№УГµДКЗ°ўАпФЖµДёєФШѕщєв·юОсSLBЎЈЖдЦРТ»ёцЦчТЄФТтКЗїЙТФёъDNSУтГы·юОсЅшРР°у¶ЁЎЈ¶ФУЪёХїЄКјЅшРРґґТµµД№«ЛѕАґЛµЈ¬їЙТФНЁ№эWebЅзГжАґЙиЦГёєФШѕщєвµДИЁЦШЈ¬±ИЅП±гУЪІї·Ц·ўІјЎўІвКФСйЦ¤,ТФј°ЅЎїµјмІйјаїШµИµИЎЈґУР§ВКєНЅЪФјФЛО¬іЙ±ѕЙПАґЛµ¶јКЗёц±ИЅПККєПµДСЎФсЎЈ
Из№ыЧФјєґоЅЁЖЯІгёєФШѕщєвИзК№УГNginx»тHaproxyµД»°Ј¬ТІРиТЄ±ЈЦ¤ёєФрёєФШѕщєвµДјЇИєТІКЗёЯїЙУГµД,ТФј°Мṩ±гЅЭµДјЇИєјаїШЈ¬А¶ВМІїКрµИ№¦ДЬЎЈ
іЦѕГ»Їј°»єґж
№ШПµРНКэѕЭївЈЁRDBMSЈ©
¶ФУЪОў·юОсАґЛµЈ¬К№УГµДґжґўјјКхЦчТЄКЗёщѕЭЖуТµµДРиТЄЎЈОЄБЛЅЪФјіЙ±ѕµД»°Ј¬Т»°г¶јКЗСЎУГMysqlЈ¬ФЪMysqlµДТэЗжСЎФсµД»°ЅЁТйСЎФсInnoDBТэЗж(5.5°ж±ѕЦ®З°Д¬ИПMyISAM)ЎЈInnoDBФЪґ¦АнІў·ўК±ёьёЯР§Ј¬ЖдІйСЇРФДЬµДІоѕаТІїЙТФНЁ№э»єґжЎўЛСЛчµИ·Ѕ°ёЅшРРГЦІ№ЎЈInnoDBґ¦АнКэѕЭїЅ±ґЎў±ё·ЭµДГв·С·Ѕ°ёУРbinlogЈ¬mysqldumpЎЈІ»№эТЄЧцµЅЧФ¶Ї»ЇµД±ё·Э»ЦёґЎўїЙјаїШµДКэѕЭЦРРД»№КЗРиТЄDBA»тХЯФЛО¬НЕ¶УЎЈПа¶Ф»Ё·СµДіЙ±ѕТІЅПёЯЎЈИз№ыіхґґЖуТµЈ¬ТІїЙТФїјВЗТАНРТ»Р©№ъДЪНв±ИЅПґуРНµДФЖјЖЛгЖЅМЁМṩµДPaaS·юОсЎЈ
Оў·юОсТ»°г°ґХХТµОсБмУтЅшРР±ЯЅз»®·ЦЈ¬ЛщТФОў·юОсЧоєГКЗТ»їЄКјѕНЅшРР·ЦївЙијЖЎЈКЗ·сРиТЄЅшРР·Ц±нРиТЄёщѕЭГїёцОў·юОсѕЯМеµДТµОсБмУтµД·ўХ№ТФј°КэѕЭ№жДЈЅшРРѕЯМе·ЦОцЎЈµ«ЅЁТй¶ФУЪ±ИЅПєЛРДµДБмУтµДДЈРНЈ¬±ИИзЎ°¶©µҐЎ±МбЗ°ЧцєГ·Ц±нЧЦ¶ОµДЙијЖєНФ¤БфЎЈ
KVДЈРНКэѕЭївЈЁKey-Value-storesЈ©
RedisКЗїЄФґµДKey-ValueЅб№№µДКэѕЭївЎЈЖд»щУЪДЪґжЈ¬ѕЯУРёЯР§»єґжµДРФДЬЈ¬Н¬К±ТІЦ§іЦіЦѕГ»ЇЎЈRedisЦчТЄУРБЅЦЦіЦѕГ»Ї·ЅКЅЎЈТ»ЦЦКЗRDBЈ¬НЁ№эЦё¶ЁК±јдјдёфЙъіЙКэѕЭјЇµДК±јдµгїмХХЈ¬ґУДЪґжРґИлґЕЕМЅшРРіЦѕГ»ЇЎЈRDB·ЅКЅ»бТэЖрТ»¶ЁіМ¶ИµДКэѕЭ¶ЄК§Ј¬µ«РФДЬєГЎЈБнНвТ»ЦЦКЗAOF,ЖдРґИл»ъЦЖЈ¬УРµгАаЛЖInnoDBµДbinlogЈ¬AOFµДОДјюµДГьБо¶јКЗТФRedisРТйёсКЅ±ЈґжЎЈХвБЅЦЦіЦѕГ»ЇКЗїЙТФН¬К±ґжФЪµДЈ¬ФЪRedisЦШЖфК±Ј¬AOFОДјю»б±»УЕПИУГУЪ»ЦёґКэѕЭЎЈТтОЄіЦѕГ»ЇКЗїЙСЎПоЈ¬ЛщТФТІїЙТФЅыУГRedisіЦѕГ»ЇЎЈ
ФЪКµјКµДіЎѕ°ЦРЈ¬ЅЁТй±ЈБфіЦѕГ»ЇЎЈ±ИИзДїЗ°±ИЅПБчРРµДЅвѕц¶МРЕСйЦ¤ВлµДСйЦ¤Ј¬ѕНїЙК№УГRedisЎЈФЪОў·юОсјЬ№№МеПµЦРЈ¬ТІїЙТФУГRedisґ¦АнТ»Р©KVКэѕЭЅб№№µДіЎѕ°ЎЈЗбБїј¶µДКэѕЭґжґў·Ѕ°ёЈ¬ТІєЬККєП±ѕЙнЗїµчЗбБїј¶·Ѕ°ёµДОў·юОсЛјПлЎЈ
ОТГЗФЪКµјщЦРЈ¬КЗ¶ФRedisЅшРРБЛ»єґжЎўіЦѕГ»ЇЈ¬БЅёц№¦ДЬМШХчЅшРР·ЦївµДЎЈ
ФЪјЇіЙSpringbootПоДїЦР»бК№УГµЅspring-boot-starter-data-redisАґЅшРРRedisµДКэѕЭївБ¬ЅУТФј°»щґЎЕдЦГЎўТФј°spring-data-redisМṩµД·бё»µДКэѕЭAPIOperationsЎЈ
БнНвЈ¬Из№ыКЗТЄЗуёЯНМНВБїµДУ¦УГЈ¬їЙТФїјВЗУГMemcachedАґЧЁГЕЧцјтµҐµДKVКэѕЭЅб№№µД»єґжЎЈЖд±ИЅПККєПґуКэѕЭБїµД¶БИЎЈ¬µ«Ц§іЦµДКэѕЭЅб№№АаРН±ИЅПµҐТ»ЎЈ
НјРОКэѕЭївЈЁGraph DatabaseЈ©
Йжј°µЅЙзЅ»Па№ШµДДЈРНКэѕЭµДґжґўЈ¬НјРОКэѕЭївКЗТ»ЦЦПаЅ»№ШПµРНКэѕЭївёьёЯР§ЎўёьБй»оµДСЎФсЎЈНјРОКэѕЭївТІКЗNosqlµДТ»ЦЦЎЈЖдєНKVІ»Н¬Ј¬ґжґўµДКэѕЭЦчТЄКЗКэѕЭЅЪµгЈЁnodeЈ©,ѕЯУРЦёПтРФµД№ШПµЈЁRelationshipЈ©ТФј°ЅЪµгєН№ШПµЙПµДКфРФЈЁPropertyЈ©ЎЈ
Из№ыУГJavaЧчОЄОў·юОсµДЦчїЄ·ўУпСФЈ¬ЧоєГСЎФсNeo4jЎЈNeo4jКЗТ»ЦЦ»щУЪJavaКµПЦµДЦ§іЦACIDµДНјРОКэѕЭївЎЈЖдМṩБЛ·бё»µДJavaAPIЎЈФЪРФДЬ·ЅГжЈ¬НјРОКэѕЭївµДѕЦІїРФК№±йАъµДЛЩ¶И·ЗіЈїмЈ¬УИЖдКЗґу№жДЈЙо¶И±йАъЎЈХвёцКЗ№ШПµРНКэѕЭївµД¶а±н№ШБЄОЮ·ЁЖуј°µДЎЈ
ПВНјКЗК№УГNeo4jµДWebUI№¤ѕЯХ№КѕµДТ»ёц№Щ·ЅGetting startedКэѕЭДЈРНКѕАэЎЈКѕАэЦРµДУпѕдMATCH
p=()-[r:DIRECTED]->() RETURN p LIMIT 25КЗNeo4jМṩµДІйСЇУпСФЎЄЎЄCypherЎЈ
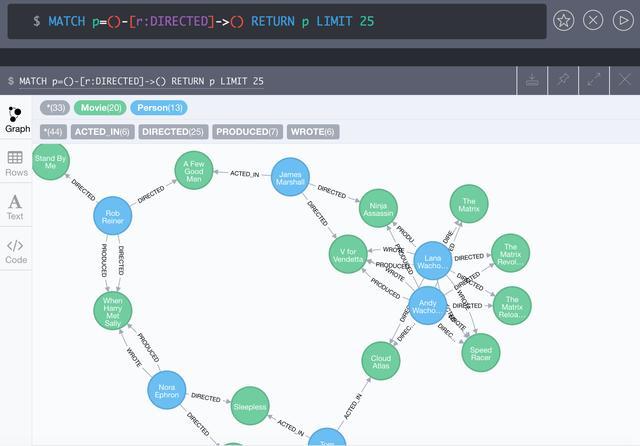
ФЪПоДїК№УГК±їЙТФјЇіЙSpringDataµДПоДїSpring Data Neo4jЎЈТФј°SpringBootStartersspring-boot-starter-data-neo4j
ОДµµКэѕЭївЈЁDocument databaseЈ©
ДїЗ°У¦УГµД±ИЅП№г·єµДїЄФґµДГжПтОДµµµДКэѕЭївїЙТФУГMongodbЎЈMongoѕЯУРёЯїЙУГЎўёЯїЙЙмЛхРФТФј°Бй»оµДКэѕЭЅб№№ґжґўЈ¬УИЖдКЗ¶ФУЪJsonКэѕЭЅб№№µДґжґўЎЈ±ИЅПККєПІ©їНЎўЖАВЫµИДЈРНµДґжґўЎЈ
ЛСЛчјјКх
ФЪїЄ·ўµД№эіМЦРЈ¬УРК±єтѕіЈ»бїґµЅУРИЛРґБЛєЬі¤єЬИЖЎўєЬДСО¬»¤µД¶а±нІйСЇSQLЈ¬»тХЯКЗёчЦЦ¶а±н№ШБЄµДЧУІйСЇУпѕдЎЈ¶ФУЪДіТ»БмУтДЈРНЈ¬µ±ХвЦЦіЎѕ°¶аµДК±єтЈ¬ѕНёГїјВЗЅУИлТ»МЧЛСЛч·Ѕ°ёБЛЎЈІ»ТЄКІГґ¶јУГSQLИҐЅвѕцЈ¬УИЖдКЗІйСЇµДіЎѕ°ЎЈВэІйСЇУпѕдµДОКМвУРК±єтЙхЦБ»бНПїеDBЈ¬Из№ыDBµДјаїШМеПµЧцµДІ»µЅО»Ј¬їЙДЬОКМвТІєЬДСЕЕІйЎЈ
ElasticsearchКЗТ»ёц»щУЪApache LuceneКµПЦµДїЄФґµДКµК±·ЦІјКЅЛСЛчєН·ЦОцТэЗжЎЈSpringbootµДПоДїТІМṩБЛјЇіЙ·ЅКЅ:
spring-boot-starter-data-elasticsearchТФј°spring-data-elasticsearchЎЈ
¶ФУЪЛСЛчјЇИєµДґоЅЁЈ¬їЙТФК№УГDockerЎЈѕЯМеґоЅЁ·Ѕ·ЁїЙТФІОїјУГDockerґоЅЁElasticsearchјЇИє,¶ФУЪSpringbootПоДїµДјЇіЙїЙТФІОїјФЪSpringbootОў·юОсЦРјЇіЙЛСЛч·юОсЎЈЦБЅсЈ¬ЧоРВ°ж±ѕµДSpringDataElasticsearchТСѕЦ§іЦµЅБЛ5.x°ж±ѕµДESЈ¬їЙТФЅвѕцєЬ¶а2.x°ж±ѕµДНґµгБЛЎЈ
Из№ыКЗРЎ№жДЈµДЛСЛчјЇИєЈ¬їЙТФУГИэМЁµНЕдЦГµД»ъЖчЈ¬И»єуУГESµДDockerЅшПоЅшРРґоЅЁЎЈТІїЙТФК№УГТ»Р©ЙМТµ°жµДPaaS·юОсЎЈИзєОСЎФс»№КЗТЄёщѕЭНЕ¶УєНТµОсµД№жДЈЎўіЎѕ°АґїґЎЈ
ДїЗ°іэБЛES,К№УГ±ИЅП№г·єµДїЄФґЛСЛчТэЗж»№УРSolr,SolrТІ»щУЪLucene,ЗТЧЁЧўФЪОД±ѕЛСЛчЎЈ¶шESµДОД±ѕЛСЛчИ·КµІ»ИзSolr,ESЦчТЄЧЁЧўУЪ¶Ф·ЦІјКЅµДЦ§іЦЈ¬ІўЗТДЪЦГБЛ·юОс·ўПЦЧйјюZenАґО¬»¤јЇИєЧґМ¬Ј¬Па¶ФSolrЈЁРиТЄЅиЦъАаЛЖZookeeperКµПЦ·ЦІјКЅЈ©ІїКрТІёьјУЗбБїј¶ЎЈESіэБЛ·ЦОцІйСЇЈ¬»№їЙТФјЇіЙИХЦѕКХјЇТФј°Чц·ЦОцґ¦АнЎЈ
ПыПў¶УБР
ПыПў¶УБРИзЗ°ЖЄЛщКцЈ¬їЙТФЧчОЄєЬєГµДОў·юОсЅвсоНЁРЕ·ЅКЅЎЈФЪ·ЦІјКЅјЇИєµДіЎѕ°ПВЈ¬¶ФУЪ·ЦІјКЅПВµДЧоЦХТ»ЦВРФТІїЙТФМṩјјКх»щґЎ±ЈХПЎЈІўЗТПыПў¶УБРТІїЙТФУГАґґ¦АнБчБїПч·жЎЈ
ПыПў¶УБРµД¶Ф±ИФЪґЛІ»ФЩЧёКцЎЈДїЗ°№«ЛѕК№УГµДКЗ°ўАпФЖµДONSЎЈТтОЄК№УГПыПў¶УБР»№КЗїјВЗУГФЪ¶ФёЯїЙУГТФј°ТЧУЪ№ЬАнЎўјаїШЙПµДТЄЗуЈ¬ЛщТФСЎФсБЛ°ІИ«їЙїїµДПыПў¶УБРЖЅМЁЎЈ
°ІИ«јјКх
°ІИ«РФКЗЧцјЬ№№РиТЄїјВЗµД»щґЎЎЈ»ҐБЄНшµД»·ѕіёґФУЈ¬±Ј»¤єГ·юОсµД°ІИ«Ј¬ТІКЗ¶ФУГ»§µД»щ±ѕіРЕµЎЈ°ІИ«јјКхЙжј°µЅµД·¶О§±ИЅП№гЈ¬±ѕОДСЎјёёціЈјыОКМвТФј°іЈУГ·ЅКЅАґјтµҐЅйЙЬПВЎЈ
·юОсКµАэ°ІИ«
·ЦІјКЅјЇИє±ѕЙнѕНКЗ¶ФУЪ·юОсКµАэ°ІИ«µДТ»ЦЦ±ЈХПЎЈТ»МЁ·юОсЖч»тХЯДіТ»ёц·юОсКµАэіцПЦОКМвµДК±єтЈ¬ёєФШѕщєвїЙТФЅ«ЗлЗуЧЄ·ўµЅЖдЛыїЙУГµД·юОсКµАэЎЈµ«єЬ¶аЖуТµКЗЧФЅЁ»ъ·їЈ¬¶шЗТКЗµҐ»ъ·їµДЈ¬ХвЦЦІјѕЦЖдКµ±ИЅПОЈПХЎЈТтОЄ·юОсЖчµД±ё·ЭИЭФЦТІµГІ»µЅНкХыµД±ЈХПЎЈЧоЕВµДѕНКЗКэѕЭївТІКЗФЪН¬Т»»ъ·їЈ¬Цч±ёИ«¶јФЪТ»ЖрЎЈІ»µҐКЗ°ІИ«РФµГІ»µЅєЬёЯµД±ЈХПЈ¬ЖЅіЈµДФЛО¬»ЁПъТІ»б±ИЅПґуЎЈ¶шЗТРиТЄЧўТвЕдЦГ·А»рЗЅ°ІИ«ІЯВФЎЈ
Из№ыїЙТФЈ¬ѕЎБїК№УГТ»Р©ёЯїЙУГЎўёЯїЙЙмЛхµДОИ¶ЁРФIaaSЖЅМЁЎЈ
НшВз°ІИ«
1. Ф¤·АНшВ繥»ч
ДїЗ°ЦчТЄµДНшВ繥»чУРТ»ПВјёЦЦЈє
SQLЧўИлЈєёщѕЭІ»Н¬µДіЦѕГІгїтјЬЈ¬У¦¶ФІЯВФІ»Н¬ЎЈИз№ыК№УГJPAЈ¬ФтЦ»ТЄЧсСJPAµД№ж·¶Ј¬»щ±ѕІ»УГµЈРДЎЈ
XSS№Ґ»чЈєЧцєГІОКэµДЧЄТ崦АнєНРЈСйЎЈѕЯМеІОїјXSSФ¤·А
CSRF№Ґ»чЈєЧцєГHttpµДHeaderРЕПўµДTokenЎўReferСйЦ¤ЎЈѕЯМеІОїјCSRFФ¤·А
DDOS№Ґ»чЈєґуБчБїµДDDoS№Ґ»чЈ¬Т»°гКЗІЙУГёЯ·АIPЎЈТІїЙТФЅУИлТ»Р©ФЖјЖЛгЖЅМЁµДёЯ·АIPЎЈ
ТФЙПЦ»КЗБРѕЩБЛјёЦЦіЈјыµД№Ґ»чЈ¬ПлТЄЙоИлБЛЅвµДїЙТФ¶аїґїґREST°ІИ«·А·¶±нЎЈФЪНшВз°ІИ«БмУтЈ¬Т»°гєЬИЭТЧ±»іхґґЖуТµєцКУЈ¬Из№ыГ»УРТ»ёцФЛО¬°ІИ«НЕ¶УЈ¬ЧоєГК№УГАаЛЖ°ўАпФЖ-ФЖ¶ЬЦ®АаµДІъЖ·ЎЈКЎРДКЎіЙ±ѕЎЈ
2. К№УГ°ІИ«РТй
ХвёцІ»УГ¶аЛµЈ¬ОЮВЫКЗ¶ФУЪК№УГRestful APIµДОў·юОсНЁРЕЈ¬»№КЗК№УГµДCDN»тХЯК№УГµДDNS·юОсЎЈЙжј°µЅHttpРТйµДЈ¬ЅЁТй¶јНіТ»К№УГHttpsЎЈОЮВЫКЗКІГґ№жДЈµДУ¦УГЈ¬¶јТЄ·А·¶БчБїЅЩіЦЈ¬·сФтЅ«»бёшУГ»§ґшАґєЬІ»єГµДК№УГМеСйЎЈ
3. јшИЁ
№ШУЪОў·юОсµДјшИЁЗ°ГжAPI GatewayТСѕУРЅйЙЬЎЈіэБЛОў·юОс±ѕЙнЦ®НвЈ¬ОТГЗК№УГµДТ»Р©ИзMysqlЈ¬Redis,Elasticsearch,EurekaµИ·юОсЈ¬ТІРиТЄЙиЦГєГјшИЁЈ¬ІўЗТѕЎБїНЁ№эДЪНш·ГОКЎЈІ»ТЄ¶ФНⱩ¶№э¶аµД¶ЛїЪЎЈ¶ФУЪОў·юОсµДAPI
Gateway,іэБЛјшИЁЈ¬ЧоєГЗ°¶ЛНЁ№эNginx·ґПтґъАнАґЗлЗуAPIІгЎЈ
ИХЦѕІЙјЇЎўјаїШ
»щУЪИЭЖчјјКхµДОў·юОсµДјаїШМеПµГжБЩЧЕёьёґФУµДНшВзЎў·юОс»·ѕіЎЈИХЦѕІЙјЇЎўјаїШИзєОДЬ¶ФОў·юОсјхЙЩЗЦИлРФЎў¶ФїЄ·ўХЯёьНёГчЈ¬Т»Ц±КЗєЬ¶аОў·юОсµДDevOpsФЪІ»¶ПЛјїјєНКµјщµДЎЈ
1. Оў·юОсИХЦѕµДІЙјЇ
Оў·юОсµДAPIІгµДјаїШЈ¬РиТЄґУAPI GatewayµЅГїёцОў·юОсµДµчУГВ·ѕ¶µДёъЧЩЈ¬ІЙјЇТФј°·ЦОцЎЈК№УГRest
APIµД»°Ј¬ОЄБЛ¶ФЛщУРЗлЗуЅшРРІЙјЇЈ¬їЙТФК№УГSpring WebµДOncePerRequestFilter¶ФЛщУРЗлЗуЅшРРА№ЅШЈ¬ФЪІЙјЇИХЦѕµДК±єтЈ¬ТІЧоєГ¶ФЗлЗуµДrtЅшРРјЗВјЎЈ
іэБЛјЗВјaccessЈ¬requestµИРЕПўЈ¬»№РиТЄ¶ФAPIµчУГЅшРРЗлЗуёъЧЩЎЈИз№ыµҐґїјЗВјГїёц·юОсТФј°GatewayµДИХЦѕЈ¬ДЗГґµ±Gateway
LogіцПЦТміЈµДК±єтЈ¬ѕНІ»ЦЄµАЖдѕЯМеКЗОў·юОсµДДДёцИЭЖчКµАэіцПЦБЛОКМвЎЈИз№ыИЭЖчґпµЅТ»¶ЁКэБїЈ¬ТІІ»їЙДЬЕЕІйЛщУРИЭЖчТФј°·юОсКµАэµДИХЦѕЎЈ±ИЅПјтµҐµДЅвѕц·ЅКЅѕНКЗ¶ФlogРЕПў¶јappendТ»¶Оє¬УРИЭЖчРЕПўµДЎўОЁТ»їЙ±кК¶µДTraceґ®ЎЈ
ИХЦѕІЙјЇЦ®єуЈ¬»№РиТЄ¶ФЖдЅшРР·ЦОцЎЈИз№ыК№УГE.L.KµДјјКхМеПµЈ¬ѕНїЙТФБй»оФЛУГElasticsearchµДКµК±·ЦІјКЅМШРФЎЈLogstashїЙТФЅшРРИХЦѕЅшРРКХјЇЎў·ЦОцЈ¬ІўЅ«КэѕЭН¬ІЅµЅElasticsearchЎЈKibanaЅбєПLogstashєНElasticSearchЈ¬МṩБјєГµД±гУЪИХЦѕ·ЦОцµДWebUIЈ¬ФцЗїИХЦѕКэѕЭµДїЙКУ»Ї№ЬАнЎЈ
¶ФУЪКэѕЭБїґуµДИХЦѕµДІЙјЇЈ¬ОЄБЛМбЙэІЙјЇРФДЬЈ¬РиТЄК№УГЙПОДМбµЅµДПыПў¶УБРЎЈУЕ»ЇєуµДјЬ№№ИзПВЈє
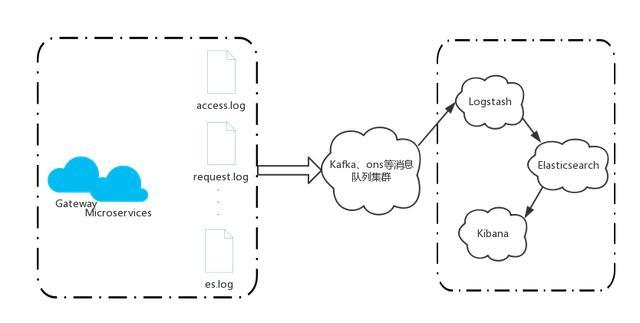
2. »щґЎ·юОсµДµчУГИХЦѕІЙјЇ
НЁ№э¶ФОў·юОсµДЛщУРRest APIµДИХЦѕІЙјЇЎў·ЦОцїЙТФјаїШЗлЗуРЕПўЎЈ
ФЪ·юОсДЪІїЈ¬¶ФУЪЦРјдјюЎў»щґЎЙиК©ЈЁ°ьАЁRedis,Mysql,ElasticsearchµИЈ©µчУГµДРФДЬµДИХЦѕІЙјЇєН·ЦОцТІКЗ±ШТЄµДЎЈ
¶ФУЪЦРјдјю·юОсµДИХЦѕІЙјЇЈ¬ОТГЗДїЗ°їЙТФНЁ№э¶ЇМ¬ґъАнµД·ЅКЅЈ¬¶ФУЪ·юОсµчУГµДИзcacheЎўrepositoryЈЁ°ьАЁЛСЛчєНDBЈ©µД»щґЎ·Ѕ·ЁЈ¬ЅшРРА№ЅШј°»ШµчИХЦѕјЗВј·Ѕ·ЁЎЈѕЯМеµДКµПЦ·ЅКЅїЙТФІЙУГЧЦЅЪВлЙъіЙїтјЬASM,№ШУЪ·Ѕ·ЁµДВЯјЧўИлЈ¬їЙТФІОїјЦ®З°РґµДТ»ЖЄASM(ЛД)
АыУГMethod Чйјю¶ЇМ¬ЧўИл·Ѕ·ЁВЯјЈ¬Из№ыѕхµГASMґъВлІ»М«єГО¬»¤Ј¬ТІїЙТФК№УГПа¶ФAPIУСєГµДCglibЎЈ
јЬ№№ОеТЄЛШЈє
ЧоєуЈ¬ЅбєПјЬ№№єЛРДµДОеТЄЛШАґ»Ш№ЛПВОТГЗФЪґоЅЁDockerОў·юОсјЬ№№К№УГµДјјКхМеПµЈє
1.ёЯРФДЬ
ПыПў¶УБРЎўRxJavaТмІЅІў·ўЎў·ЦІјКЅ»єґжЎў±ѕµШ»єґжЎўHttpµДEtag»єґжЎўК№УГElasticsearchУЕ»ЇІйСЇЎўCDNµИµИЎЈ
2.їЙУГРФ
ИЭЖч·юОсјЇИєЎўRxJavaµДИЫ¶Пґ¦АнЎў·юОсЅµј¶ЎўПыПўµДГЭµИґ¦АнЎўі¬К±»ъЦЖЎўЦШКФ»ъЦЖЎў·ЦІјКЅЧоЦХТ»ЦВРФµИµИЎЈ
3.ЙмЛхРФ
·юОсЖчјЇИєµДЙмЛхЎўИЭЖч±аЕЕKubernetesЎўКэѕЭїв·Цїв·Ц±нЎўNosqlµДПЯРФЙмЛхЎўЛСЛчјЇИєµДїЙЙмЛхµИµИЎЈ
4.А©Х№РФ
»щУЪDockerµДОў·юОс±ѕЙнѕНКЗОЄБЛА©Х№РФ¶шЙъЈЎ
5.°ІИ«РФ
JPA/Hibernate,SpringSecurityЎўёЯ·АIPЎўИХЦѕјаїШЎўHttpsЎўNginx·ґПтґъАнЎўHTTP/2.0µИµИЎЈ
РЎЅб
¶ФУЪ·юОсјЇИєµДЅвѕц·Ѕ°ёЈ¬ЖдКµОЮВЫКЗОў·юОсјЬ№№»тХЯSOAјЬ№№Ј¬¶јКЗ±ИЅПНЁУГµДЎЈЦ»КЗ¶ФУЪТ»Р©ЦРјдјюјЇИєµДґоЅЁЈ¬їЙТФК№УГDockerЎЈТ»ѕдDocker
psѕНїЙТФєЬ·Ѕ±гІйСЇФЛРРµД·юОсРЕПўЈ¬ІўЗТЙэј¶»щґЎ·юОсТІєЬ·Ѕ±гЎЈ
¶ФУЪУЕРгµДјЇИєјЬ№№ЙијЖµДЧ·ЗуКЗУАОЮЦ№ѕіµДЎЈФЪёъєЬ¶аґґТµ№«ЛѕµДјјКхЕуУСГЗЅУґҐПВАґЈ¬ґујТ¶јКЗ±ИЅПЖ«ПтУЪїмЛЩґоЅЁТФј°їЄ·ўЎў·ўІј·юОсЎЈИ»¶шТ»·ЅГжТІ№ЛВЗОў·юОсµДјЬ№№»б±ИЅПёґФУЈ¬Й±ј¦УГЕЈµ¶ЎЈµ«КЗОў·юОс±ѕЙнѕНКЗТ»ЦЦГфЅЭДЈКЅµДУЕРгКµјщЎЈХвР©ЕуУСНщНщ»бФЪТµОс·ЙЛЩ·ўХ№µДК±єтГжБЩТ»ёцА§ИЕЈ¬ѕНКЗ·юОсІр·ЦЈ¬КэѕЭївµД·Цїв·Ц±нЎўНЁ№эПыПўИҐЅвсоПсГжМхТ»СщµДН¬ІЅґъВлЈ¬ПлТЄУЕ»ЇРФДЬµ«КЗОЮґУПВКЦµДЮПЮОЎЈ |






