|
±ѕОДКЗПµБРОДХВЈ¬ОДХВµДµЪТ»ЖЄОў·юОсЈєґУЙијЖµЅІїКр(Т»),µЪ¶юЖЄОў·юОсЈєґУЙијЖµЅІїКр(¶ю)
5ЎўКВјюЗэ¶ЇКэѕЭ№ЬАн
±ѕКйЦчТЄЅйЙЬИзєОК№УГОў·юОс№№ЅЁУ¦УГіМРтЈ¬ХвКЗ±ѕКйµДµЪОеХВЎЈµЪТ»ХВЅйЙЬБЛОў·юОсјЬ№№ДЈКЅЈ¬МЦВЫБЛК№УГОў·юОсµДУЕµгУлИ±µгЎЈµЪ¶юєНµЪИэХВГиКцБЛОў·юОсјЬ№№ДЪНЁРЕ·ЅКЅµД¶Ф±ИЎЈµЪЛДХВМЅМЦБЛУл·юОс·ўПЦПа№ШµДДЪИЭЎЈФЪ±ѕХВЦРЈ¬ОТГЗЙФОўЧцБЛµгµчХыЈ¬СРѕїОў·юОсјЬ№№ЦРіцПЦµД·ЦІјКЅКэѕЭ№ЬАнОКМвЎЈ
5.1ЎўОў·юОсєН·ЦІјКЅКэѕЭ№ЬАнОКМв
µҐМеУ¦УГіМРтНЁіЈѕЯУРТ»ёцµҐТ»µД№ШПµРНКэѕЭївЎЈК№УГ№ШПµРНКэѕЭївµДТ»ёцЦчТЄУЕµгКЗДъµДУ¦УГіМРтїЙТФК№УГ
ACID КВОсЈ¬ХвР©КВОсМṩБЛТФПВЦШТЄ±ЈХПЈє
ФЧУРФЈЁAtomicityЈ© ЎЄ ЛщЧчіцµДёьёДКЗФЧУІЩЧчЈ¬І»їЙ·Цёо
Т»ЦВРФЈЁConsistencyЈ© ЎЄ КэѕЭївµДЧґМ¬КјЦХ±ЈіЦТ»ЦВ
ёфАлРФЈЁIsolationЈ© ЎЄ јґК№КВОсІў·ўЦґРРЈ¬µ«ЛыГЗїґЖрАґёьПсКЗґ®РРЦґРР
УАѕГРФЈЁDurableЈ© ЎЄ Т»µ©КВОсМбЅ»Ј¬ЛьЅ«І»їЙі·Пъ
ТтґЛЈ¬ДъµДУ¦УГіМРтїЙТФєЬИЭТЧµШїЄКјКВОсЎўёьёДЈЁІеИлЎўёьРВєНЙѕіэЈ©¶аРРјЗВјЈ¬ІўМбЅ»КВОсЎЈ
К№УГ№ШПµРНКэѕЭївµДБнТ»ґуєГґ¦КЗЛьМṩБЛ SQLЈ¬ХвКЗТ»ЦЦ·бё»ЎўЙщГчКЅєН±кЧј»ЇµДІйСЇУпСФЎЈДъїЙТФЗбЛЙµШ±аРґТ»ёцІйСЇЧйєПАґЧФ¶аёц±нµДКэѕЭЈ¬Ц®єуЈ¬RDBMS
ІйСЇјЖ»®іМРтЅ«И·¶ЁЦґРРІйСЇµДЧојС·ЅКЅЎЈДъІ»±ШµЈРДИзєО·ГОККэѕЭївµИµЧІгПёЅЪЎЈТтОЄДъЛщУРµДУ¦УГіМРтКэѕЭ¶јґж·ЕФЪН¬ёцКэѕЭївЦРЈ¬ТтґЛєЬИЭТЧІйСЇЎЈ
єЬІ»РТµДКЗЈ¬µ±ОТГЗЧЄПтОў·юОсјЬ№№К±Ј¬КэѕЭ·ГОКЅ«±дµГ·ЗіЈёґФУЎЈТтОЄГїёцОў·юОсЛщУµУРµДКэѕЭ¶Фµ±З°Оў·юОсАґЛµКЗЛЅУРµДЈ¬Ц»ДЬНЁ№эЖдМṩµД
API ЅшРР·ГОКЎЈ·вЧ°КэѕЭїЙИ·±ЈОў·юОсЛЙсоєПЎў¶АБўСЭЅшЎЈИз№ы¶аёц·юОс·ГОКПаН¬µДКэѕЭЈ¬ДЈКЅЈЁschemaЈ©ёьРВРиТЄ¶ФЛщУР·юОсЅшРРєДК±ЎўРµчµДёьРВЎЈ
ёьФгёвµДКЗЈ¬І»Н¬µДОў·юОсѕіЈК№УГІ»Н¬АаРНµДКэѕЭївЎЈПЦґъУ¦УГіМРтґжґўєНґ¦АнЧЕёчЦЦКэѕЭЈ¬¶ш№ШПµРНКэѕЭївІўІ»ЧЬКЗЧојССЎФсЎЈФЪДіР©іЎѕ°Ј¬МШ¶ЁµД
NoSQL КэѕЭївїЙДЬѕЯУРёь·Ѕ±гµДКэѕЭДЈРНЈ¬МṩБЛёьєГµДРФДЬєНїЙА©Х№РФЎЈАэИзЈ¬ґжґўєНІйСЇОД±ѕµД·юОсК№УГОД±ѕЛСЛчТэЗжЈЁИз
ElasticsearchЈ©КЗєПАнµДЎЈАаЛЖµШЈ¬ґжґўЙзЅ»НјКэѕЭµД·юОсУ¦ёГїЙТФК№УГНјКэѕЭївЈ¬АэИз Neo4jЎЈТтґЛЈ¬»щУЪОў·юОсµДУ¦УГіМРтНЁіЈ»мєПК№УГ
SQL єН NoSQL КэѕЭївЈ¬јґЛщОЅµД»мєПіЦѕГ»ЇЈЁpolyglot persistenceЈ©·ЅКЅЎЈ
·ЦЗшµДКэѕЭґжґў»мєПіЦѕГ»ЇјЬ№№ѕЯУРРн¶аУЕµгЈ¬°ьАЁБЛЛЙсоєПµД·юОсТФј°ёьєГµДРФДЬУлїЙА©Х№РФЎЈИ»¶шЈ¬ЛьТІТэИлБЛТ»Р©·ЦІјКЅКэѕЭ№ЬАн·ЅГжµДМфХЅЎЈ
µЪТ»ёцМфХЅКЗИзєОКµПЦО¬»¤¶аёц·юОсЦ®јдµДТµОсКВОсТ»ЦВРФЎЈТЄБЛЅвґЛОКМвЈ¬ИГОТГЗПИАґїґТ»ёцФЪПЯ B2B
ЙМµкµДКѕАэЎЈCustomer Service ЈЁ№ЛїН·юОсЈ©О¬»¤їН»§Па№ШµДРЕПўЈ¬°ьАЁРЕУГ¶о¶ИЎЈOrder
Service ЈЁ¶©µҐЈ©ёєФр№ЬАн¶©µҐЈ¬ІўЗТ±ШРлСйЦ¤РВ¶©µҐЈ¬І»µГі¬№эїН»§µДРЕУГ¶о¶ИЎЈФЪґЛУ¦УГіМРтµДµҐМе°ж±ѕЦРЈ¬Order
Service їЙТФјтµҐµШК№УГ ACID Ѕ»ТЧАґјмІйїЙУГРЕУГ¶о¶ИІўґґЅЁ¶©µҐЎЈ
Па±ИЦ®ПВЈ¬ФЪОў·юОсјЬ№№ЦРЈ¬ORDER ЈЁ¶©µҐЈ©єН CUSTOMER ЈЁ№ЛїНЈ©±н¶ФЖдёчЧФµД·юОс¶јКЗЛЅУРµДЈ¬ИзНј
5-1 ЛщКѕЈє
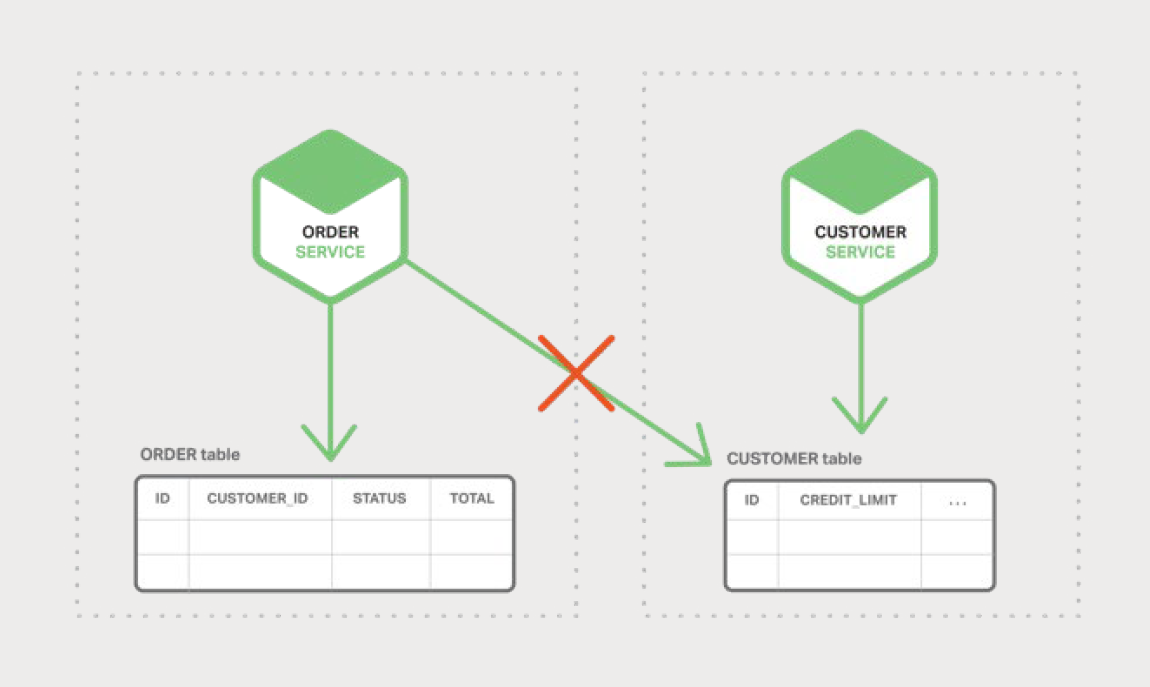
Order Service ОЮ·ЁЦ±ЅУ·ГОК CUSTOMER ±нЎЈЛьЦ»ДЬК№УГїН»§·юОсМṩµД APIЎЈ¶©µҐ·юОсїЙДЬК№УГБЛ·ЦІјКЅКВОсЈ¬ТІіЖОЄБЅЅЧ¶ОМбЅ»ЈЁ2PCЈ©ЎЈИ»¶шЈ¬2PC
ФЪПЦґъУ¦УГЦРНЁіЈКЗІ»їЙРРµДЎЈCAP ¶ЁАнТЄЗуДъФЪїЙУГРФУл ACID КЅТ»ЦВРФЦ®јдЧціцСЎФсЈ¬їЙУГРФНЁіЈКЗёьєГµДСЎФсЎЈґЛНвЈ¬Рн¶аПЦґъјјКхЈ¬Изґу¶аКэ
NoSQL КэѕЭївЈ¬¶јІ»Ц§іЦ 2PCЎЈО¬»¤·юОсєНКэѕЭївЦ®јдµДКэѕЭТ»ЦВРФЦБ№ШЦШТЄЈ¬ТтґЛОТГЗРиТЄБнТ»МЧЅвѕц·Ѕ°ёЎЈ
µЪ¶юёцМфХЅКЗИзєОКµПЦґУ¶аёц·юОсЦРјмЛчКэѕЭЎЈАэИзЈ¬ОТГЗјЩЙиУ¦УГіМРтРиТЄПФКѕТ»ёц№ЛїНєНЛыЧоЅьµД¶©µҐЎЈИз№ы
Order Service МṩБЛУГУЪјмЛчїН»§¶©µҐµД APIЈ¬ДЗГґДъїЙТФК№УГУ¦УГіМРт¶ЛБ¬ЅУТФјмЛчКэѕЭЎЈУ¦УГіМРтґУ
Customer Service ЦРјмЛчїН»§Ј¬ІўґУ Order Service ЦРјмЛчїН»§µД¶©µҐЎЈµ«КЗЈ¬јЩЙи
Order Service ЅцЦ§іЦНЁ№эЦчјьІйХТ¶©µҐЈЁТІРнЛьК№УГБЛЅцЦ§іЦ»щУЪЦчјьјмЛчµД NoSQL КэѕЭївЈ©ЎЈФЪХвЦЦЗйїцПВЈ¬Г»УРУРР§µД·Ѕ·ЁАґјмЛчЛщРиµДКэѕЭЎЈ
5.2ЎўКВјюЗэ¶ЇјЬ№№
Рн¶аУ¦УГК№УГБЛКВјюЗэ¶ЇјЬ№№ЧчОЄЅвѕц·Ѕ°ёЎЈФЪґЛјЬ№№ЦРЈ¬Оў·юОсФЪ·ўЙъДіР©ЦШТЄКВјюК±·ўІјТ»ёцКВјюЈ¬АэИзёьРВТµОсКµМеК±ЎЈЖдЛыОў·юОс¶©ФДБЛХвР©КВјюЈ¬µ±Оў·юОсЅУКХµЅТ»ёцКВјюК±Ј¬ЛьїЙТФёьРВЧФјєµДТµОсКµМеЈ¬ХвїЙДЬµјЦВёь¶аµДКВјю±»·ўІјЎЈ
ДъїЙТФК№УГКВјюКµПЦїз¶а·юОсµДТµОсКВОсЎЈТ»ёцКВОсУЙТ»ПµБРµДІЅЦиЧйіЙЎЈГїёцІЅЦи°ьАЁБЛОў·юОсёьРВТµОсКµМеєН·ўІјКВјюЛщґҐ·ўµДПВТ»ІЅЦиЎЈПВНјТАґОХ№КѕБЛИзєОФЪґґЅЁ¶©µҐК±К№УГКВјюЗэ¶Ї·Ѕ·ЁАґјмІйїЙУГРЕУГ¶о¶ИЎЈ
Оў·юОсНЁ№э Message Broker ЈЁПыПўґъАнЈ©ЅшРРЅ»»»КВјюЈє
Order Service ЈЁ¶©µҐ·юОсЈ©ґґЅЁТ»ёцЧґМ¬ОЄ NEW µД¶©µҐЈ¬Іў·ўІјТ»ёц Order Created
ЈЁ¶©µҐґґЅЁЈ©КВјюЎЈ
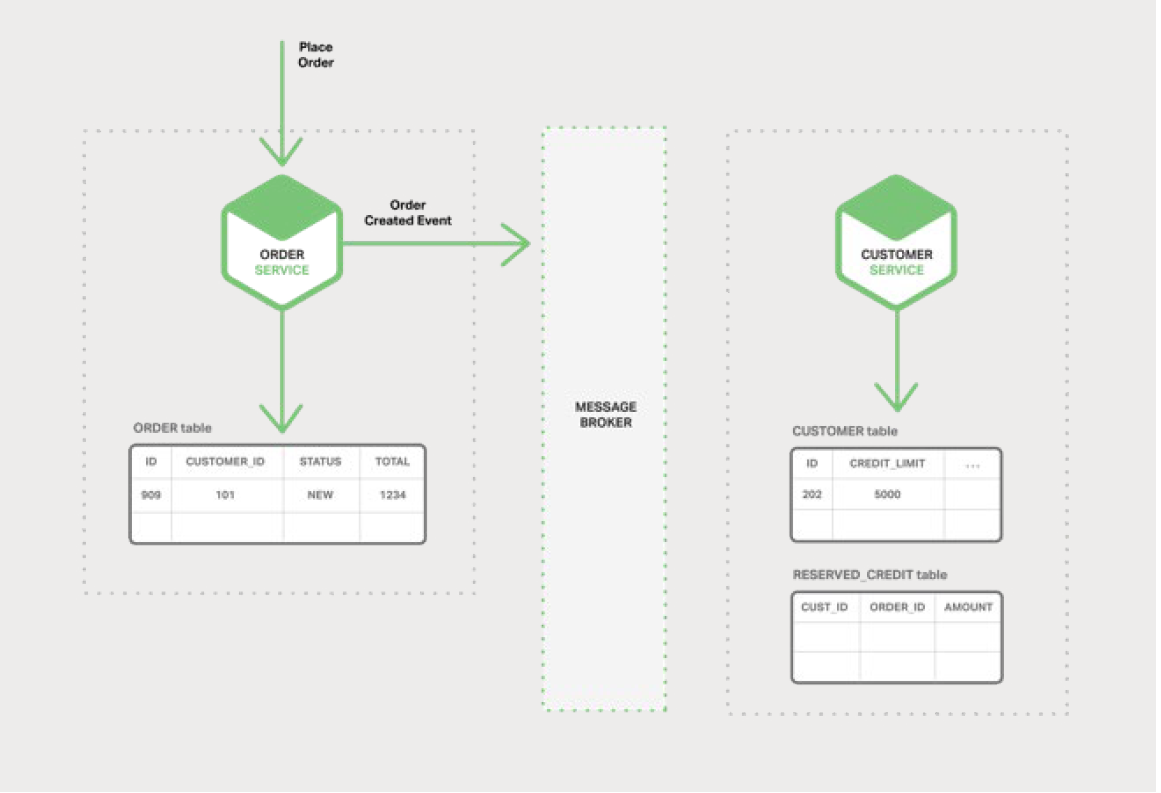
Customer Service ЈЁїН»§·юОсЈ©Пы·СБЛ Order Created КВјюЈ¬ОЄ¶©µҐФ¤БфРЕУГ¶о¶ИЈ¬Іў·ўІј
Credit Reserved КВјюЎЈ
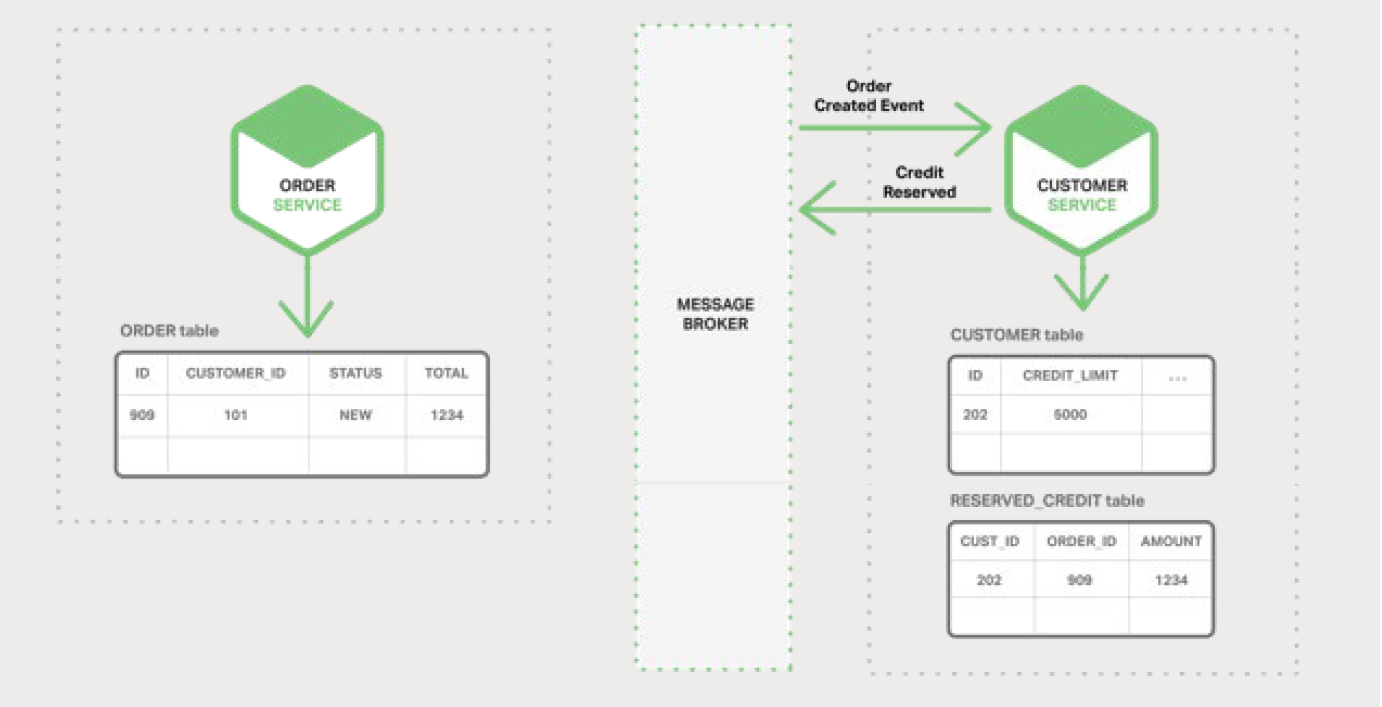
Order Service Пы·СБЛ Credit Reserved ЈЁРЕУГФ¤БфЈ©КВјюІўЅ«¶©µҐµДЧґМ¬ёьёДОЄ
OPENЎЈ
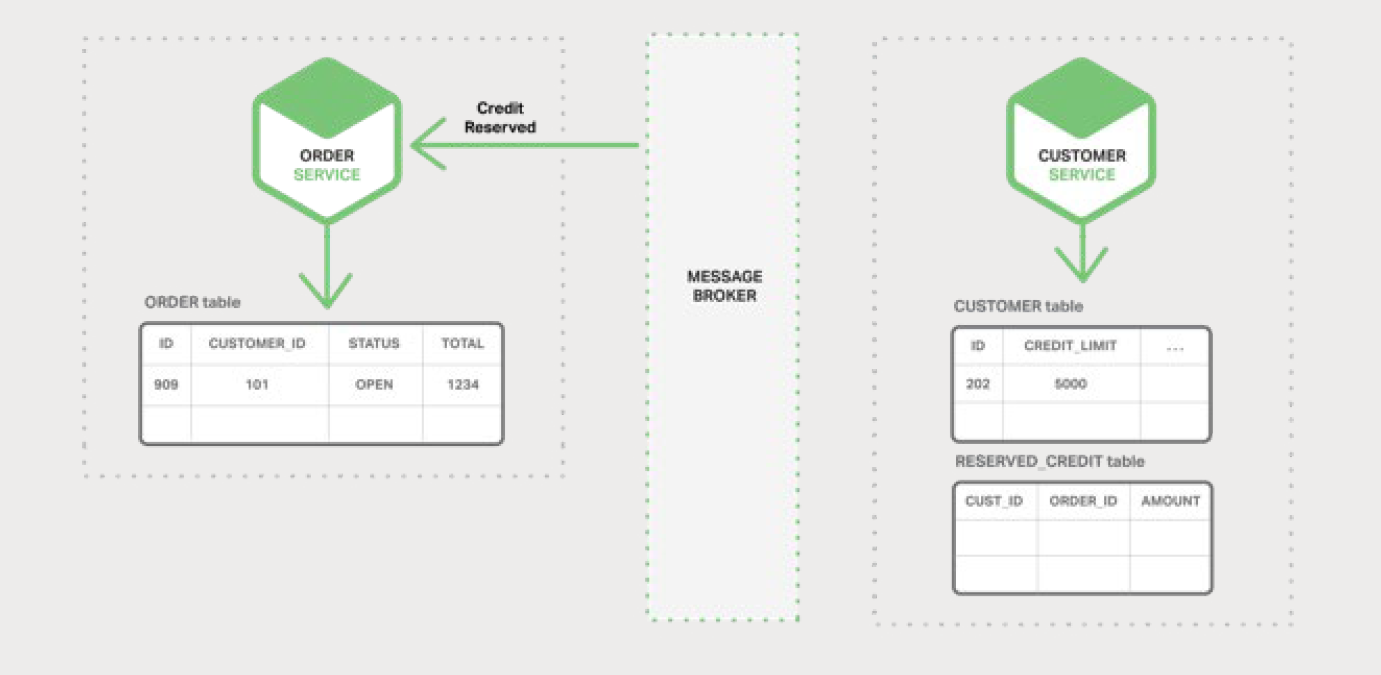
ёьёґФУµДіЎѕ°їЙДЬ»бЙжј°¶оНвµДІЅЦиЈ¬АэИзФЪјмІйїН»§РЕУГµДН¬К±±ЈБфївґжЎЈ
јЩЙиЈЁaЈ©Гїёц·юОсФЧУµШёьРВКэѕЭївІў·ўІјКВјюЈ¬ЙФєуФЩёьРВЈ¬ЈЁbЈ©Message Broker ±ЈЦ¤КВјюЦБЙЩ±»ґ«ЛНТ»ґОЈ¬ДъїЙТФКµПЦїз¶а·юОсµДТµОсКВОсЎЈРиТЄЧўТвµДКЗЈ¬ХвР©ІўІ»КЗ
ACID КВОсЎЈЛьГЗЦ»МṩБЛёьИхµД±ЈЦ¤Ј¬ИзЧоЦХТ»ЦВРФЎЈёГКВОсДЈРНіЖОЄ BASE ДЈРНЎЈ
Дъ»№їЙТФК№УГКВјюАґО¬»¤¶аёцОў·юОсФ¤ПИјУИлЛщУµУРµДКэѕЭµДОп»ЇКУНјЈЁmaterialized viewЈ©ЎЈО¬»¤КУНјµД·юОс¶©ФДБЛПа№ШКВјюІўёьРВКУНјЎЈНј
5-5 Х№КѕБЛ Customer Order View Updater Service ЈЁїН»§¶©µҐКУНјёьРВ·юОсЈ©ёщѕЭ
Customer Service єН Order Service ·ўІјµДКВјюёьРВ Customer
Order View ЈЁїН»§¶©µҐ·юОсЈ©ЎЈ
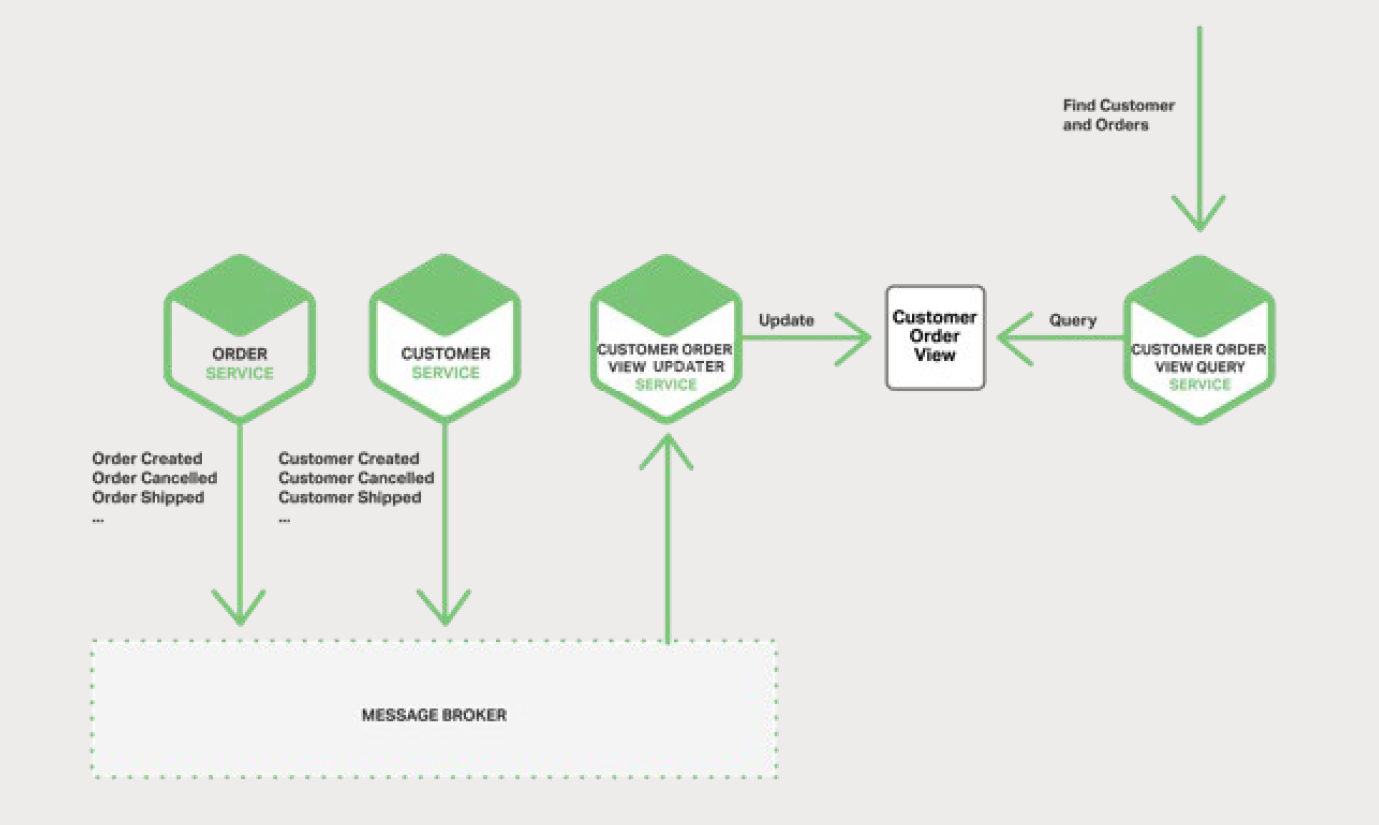
µ± Customer Order View Updater Service ЅУКХµЅ Customer
»т Order КВјюК±Ј¬Ль»бёьРВ Customer Order View КэѕЭґжґўЎЈДъїЙТФК№УГИз MongoDB
Ц®АаµДОДµµКэѕЭївКµПЦ Customer Order ViewЈ¬ІўОЄГїёц Customer ґжґўТ»ёцОДµµЎЈCustomer
Order View Query ServiceЈЁїН»§¶©µҐКУНјІйСЇ·юОсЈ©НЁ№эІйСЇ Customer
Order View КэѕЭґжґўАґґ¦Ан»сИЎТ»О»їН»§єНЧоЅьµД¶©µҐµДЗлЗуЎЈ
КВјюЗэ¶ЇµДјЬ№№УРјёёцУЕµгУлИ±µгЎЈЛьДЬ№»КµПЦїзФЅ¶а·юОсІўМṩЧоЦХТ»ЦВРФКВОсЎЈБнТ»ёцєГґ¦КЗЛь»№К№µГУ¦УГіМРтДЬ№»О¬»¤Оп»ЇКУНјЎЈ
Т»ёцИ±µгКЗЖд±аіМДЈРН±ИК№УГ ACID КВОсёьјУёґФУЎЈНЁіЈЈ¬Дъ±ШРлКµПЦІ№іҐКВОсТФґУУ¦УГіМРтј¶±рµД№КХПЦР»ЦёґЎЈАэИзЈ¬Из№ыРЕУГјмІйК§°ЬЈ¬Дъ±ШРлИЎПы¶©µҐЎЈґЛНвЈ¬У¦УГіМРт±ШР봦АнІ»Т»ЦВµДКэѕЭЎЈТтОЄОґМбЅ»µДКВОсЛщЧцµДёьёДКЗїЙјыµДЎЈИз№ыґУОґёьРВµДОп»ЇКУНјЦР¶БИЎЈ¬У¦УГіМРтТАИ»їЙТФїґµЅІ»Т»ЦВРФЎЈБнТ»ёцИ±µгКЗ¶©ФДХЯ±ШРлТЄјмІвєНєцВФЦШёґµДКВјюЎЈ
5.3ЎўКµПЦФЧУРФ
ФЪКВјюЗэ¶ЇјЬ№№ЦРЈ¬Н¬СщґжФЪЧЕФЧУёьРВКэѕЭївєН·ўІјКВјюПа№ШОКМвЎЈАэИзЈ¬Order Service ±ШРлФЪ
ORDER ±нЦРІеИлТ»РРКэѕЭЈ¬Іў·ўІј Order Created КВјюЎЈХвБЅёцІЩЧч±ШРлФЧУНкіЙЎЈИз№ыФЪёьРВКэѕЭївєуµ«ФЪ·ўІјКВјюЦ®З°·ўЙъ·юОс±ААЈЈ¬ПµНіЅ«іцПЦІ»Т»ЦВРФЎЈИ·±ЈФЧУРФµД±кЧј·Ѕ·ЁКЗК№УГЙжј°µЅКэѕЭївєН
Message Broker µД·ЦІјКЅКВОсЎЈИ»¶шЈ¬УЙУЪЙПКцФТтЈ¬Из CAP ¶ЁАнЈ¬ХвІўІ»КЗОТГЗПлЧцµДЎЈ
5.4ЎўК№УГ±ѕµШКВОс·ўІјКВјю
КµПЦФЧУРФµДТ»ЦЦ·ЅКЅКЗУ¦УГіМРтК№УГЅцЙжј°±ѕµШКВОсµД¶аІЅЦи№эіМАґ·ўІјКВјюЎЈѕчЗПФЪУЪґжґўТµОсКµМеЧґМ¬µДКэѕЭївЦРУРТ»ёцУГЧчПыПў¶УБРµД
EVENT ±нЎЈУ¦УГіМРтїЄЖфТ»ёцЈЁ±ѕµШЈ©КэѕЭївКВОсЈ¬ёьРВТµОсКµМеЧґМ¬Ј¬Ѕ«КВјюІеИлµЅ EVENT ±нЦРЈ¬Ц®єуМбЅ»КВОсЎЈТ»ёцµҐ¶АµДУ¦УГіМРтПЯіМ»тЅшіМІйСЇ
EVENT ±нЈ¬Ѕ«КВјю·ўІјµЅ Message BrokerЈ¬И»єуК№УГ±ѕµШКВОсЅ«КВјю±кјЗОЄТС·ўІјЎЈЙијЖИзНј
5-6 ЛщКѕЎЈ
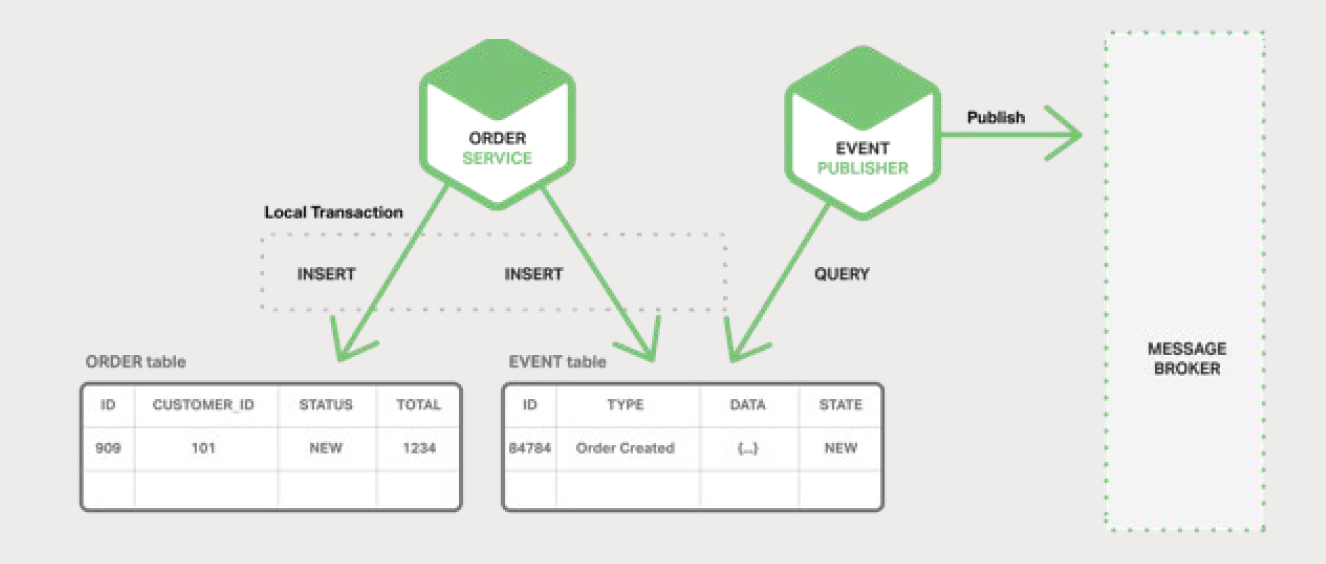
Order Service Ѕ«Т»РРјЗВјІеИлµЅ ORDER ±нЦРЈ¬ІўЅ«Т»ёц Order Created
КВјюІеИлµЅ EVENT ±нЦРЎЈEvent PublisherЈЁКВјю·ўІјХЯЈ©ПЯіМ»тЅшіМґУ EVENT
±нЦРІйСЇОґ·ўІјµДКВјюЈ¬Ц®єу·ўІјХвР©КВјюЈ¬ЧоєуёьРВ EVENT ±нТФЅ«КВјю±кјЗОЄТС·ўІјЎЈ
ХвЦЦ·Ѕ·ЁУРєГУР»µЎЈєГґ¦КЗЛь±ЈЦ¤БЛ±»·ўІјµДКВјюГїґОёьРВ¶јІ»ТААµУЪ 2PCЎЈґЛНвЈ¬У¦УГіМРт·ўІјТµОсј¶КВјюЈ¬ХвР©КВјюїЙТФПыіэНЖ¶ПµДРиТЄЎЈХвЦЦ·Ѕ·ЁµДИ±µгКЗЛьєЬИЭТЧіцґнЈ¬ТтОЄїЄ·ўИЛФ±±ШРлТЄјЗµГ·ўІјКВјюЎЈХвЦЦ·Ѕ·ЁµДѕЦПЮРФФЪУЪЈ¬УЙУЪЖдУРПЮµДКВОсєНІйСЇ№¦ДЬЈ¬ФЪК№УГДіР©
NoSQL КэѕЭївК±Ј¬КµПЦЖрАґЅ«КЗТ»ґуМфХЅЎЈ
ёГ·Ѕ·ЁНЁ№эИГУ¦УГіМРтК№УГ±ѕµШКВОсёьРВЧґМ¬єН·ўІјКВјюАґПыіэ¶Ф 2PC µДТААµЎЈПЦФЪОТГЗАґїґТ»ПВНЁ№эУ¦УГіМРтјтµҐµШёьРВЧґМ¬АґКµПЦФЧУРФµД·Ѕ·ЁЎЈ
5.5ЎўНЪѕтКэѕЭївКВОсИХЦѕ
І»ТАїї 2PC АґКµПЦФЧУРФµДБнТ»ЦЦ·ЅКЅКЗК№УГПЯіМ»тЅшіМ·ўІјКВјюЈ¬ёГПЯіМ»тЅшіМ¶ФКэѕЭївµДКВОс»тХЯМбЅ»ИХЦѕЅшРРНЪѕтЎЈµ±У¦УГіМРтёьРВКэѕЭївК±Ј¬ёьёДРЕПў±»јЗВјµЅКэѕЭївµДКВОсИХЦѕЦРЎЈTransaction
Log Miner ПЯіМ»тЅшіМ¶БИЎКВОсИХЦѕІўПт Message Broker ·ўІјКВјюЎЈЙијЖИзНј 5-7
ЛщКѕЎЈ
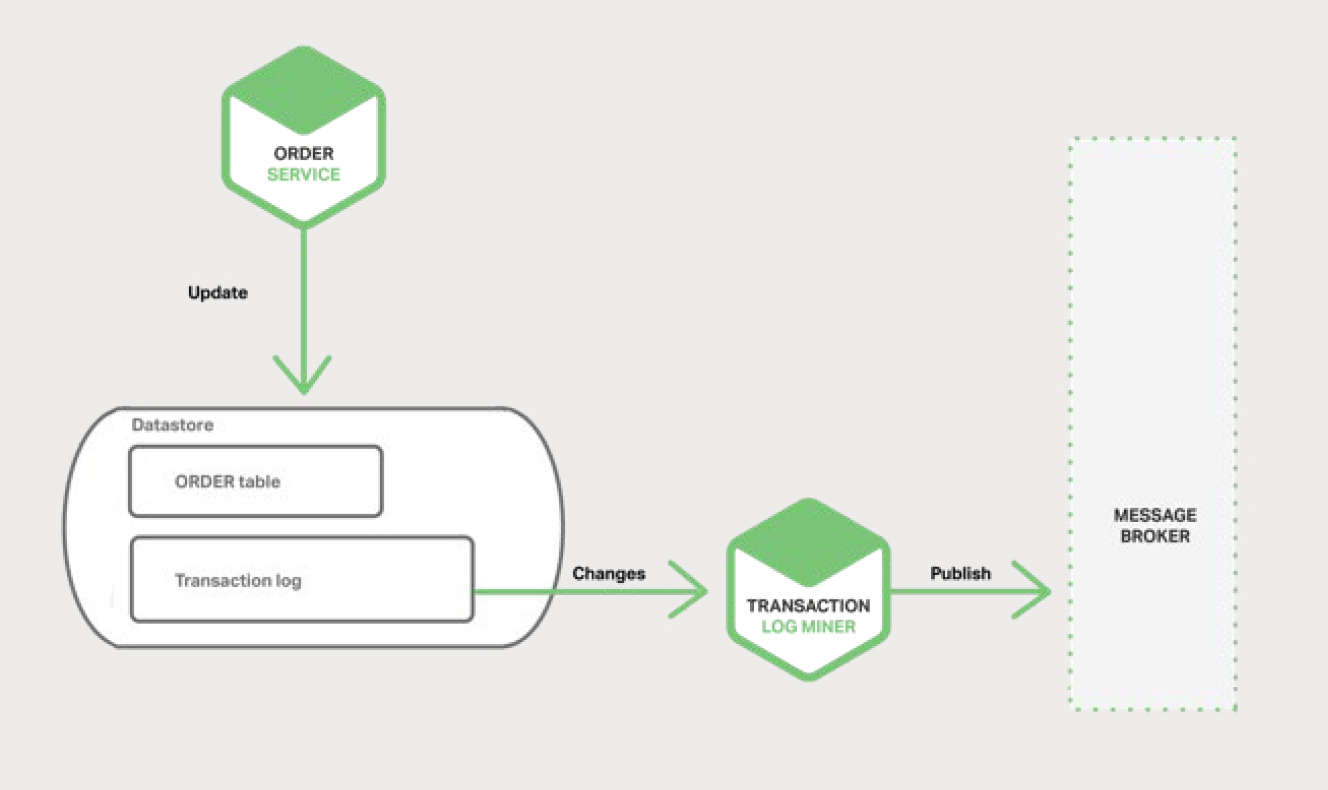
Т»ёцК№УГґЛ·Ѕ·ЁµДКѕАэКЗ LinkedIn Databus їЄФґПоДїЎЈDatabus НЪѕт Oracle
КВОсИХЦѕІў·ўІјУлёьёДПа¶ФУ¦µДКВјюЎЈLinkedIn К№УГ Databus ±ЈіЦУлјЗВјПµНіТ»ЦВµДёчЦЦЕЙЙъКэѕЭґжґўЎЈ
БнТ»ёцАэЧУКЗ AWS DynamoDB ЦРµДБч»ъЦЖЈ¬ЛьКЗТ»ёцНР№ЬµД NoSQL КэѕЭївЎЈDynamoDB
Бч°ьє¬БЛФЪ№эИҐ 24 РЎК±ДЪ¶Ф DynamoDB ±нЦРµДПоЅшРРµДёьёДЈЁґґЅЁЎўёьРВєНЙѕіэІЩЧчЈ©Ј¬Жд°ґК±јдЛіРтЕЕБРЎЈУ¦УГіМРтїЙТФґУБчЦР¶БИЎХвР©ёьёДЈ¬±ИИзЈ¬Ѕ«ЖдЧчОЄКВјю·ўІјЎЈ
КВОсИХЦѕНЪѕтУРёчЦЦєГґ¦Ул»µґ¦ЎЈТ»ёцєГґ¦КЗЛьДЬ±ЈЦ¤±»·ўІјµДКВјюГїґОёьРВ¶јІ»ТААµУЪ 2PCЎЈКВОсИХЦѕНЪѕт»№їЙТФНЁ№эЅ«КВјю·ўІјУлУ¦УГіМРтµДТµОсВЯј·ЦАлАґјт»ЇУ¦УГіМРтЎЈТ»ёцЦчТЄµДИ±µгКЗКВОсИХЦѕµДёсКЅ¶ФУЪГїёцКэѕЭївАґЛµ¶јКЗЧЁУРµДЈ¬ЙхЦБФЪКэѕЭїв°ж±ѕЦ®јдёсКЅѕН·ўЙъБЛёД±дЎЈ¶шЗТЈ¬јЗВјУЪКВОсИХЦѕЦРµДµНј¶±рёьРВїЙДЬДСТФ¶ФёЯј¶ТµОсКВјюЅшРРДжПт№¤іМЎЈ
КВОсИХЦѕНЪѕтПыіэБЛУ¦УГіМРтФЪЧцТ»јюКВК±¶Ф 2PC µДТААµЈєёьРВКэѕЭївЎЈПЦФЪОТГЗАґїґїґБнТ»ЦЦїЙТФПыіэёьРВІўЅцТААµУЪКВјюµДІ»Н¬·ЅКЅЎЈ
5.6ЎўК№УГКВјюЛЭФґ
КВјюЛЭФґНЁ№эК№УГНкИ«І»Н¬µДЎўІ»јд¶ПµД·ЅКЅАґіЦѕГ»ЇТµОсКµМеЈ¬КµПЦОЮ 2PC ФЧУРФЎЈУ¦УГіМРтІ»ґжґўКµМеµДµ±З°ЧґМ¬Ј¬¶шКЗґжґўТ»ПµБРЧґМ¬ёД±дКВјюЎЈёГУ¦УГіМРтНЁ№э»Ш·ЕКВјюАґЦШЅЁКµМеµДµ±З°ЧґМ¬ЎЈОЮВЫТµОсКµМеµДЧґМ¬єОК±·ўЙъ±д»ЇЈ¬Жд¶ј»бЅ«РВКВјюЧ·јУµЅКВјюБР±нЦРЎЈУЙУЪ±ЈґжКВјюКЗТ»ёцµҐТ»ІЩЧчЈ¬ТтґЛѕЯУРФЧУРФЎЈ
ТЄБЛЅвКВјюЛЭФґµД№¤ЧчФАнЈ¬ТФ OrderЈЁ¶©µҐЈ©КµМеОЄАэЎЈФЪґ«Ні·ЅКЅЦРЈ¬Гїёц¶©µҐ¶јУл ORDER
±нЦРµДДіРРјЗВјПаУіЙдЈ¬ТІїЙТФУіЙдµЅАэИз ORDER_LINE_ITEM ±нЦРµДјЗВјЎЈ
µ«µ±К№УГКВјюЛЭФґК±Ј¬Order Service Ѕ«ТФЧґМ¬ёьёДКВјюµДРОКЅґжґў OrderЈєCreatedЈЁґґЅЁЈ©ЎўApprovedЈЁЕъЧјЈ©ЎўShippedЈЁ·ў»хЈ©ЎўCancelledЈЁИЎПыЈ©ЎЈГїёцКВјю°ьє¬Чг№»µДКэѕЭАґЦШЅЁ
Order µДЧґМ¬ЎЈ
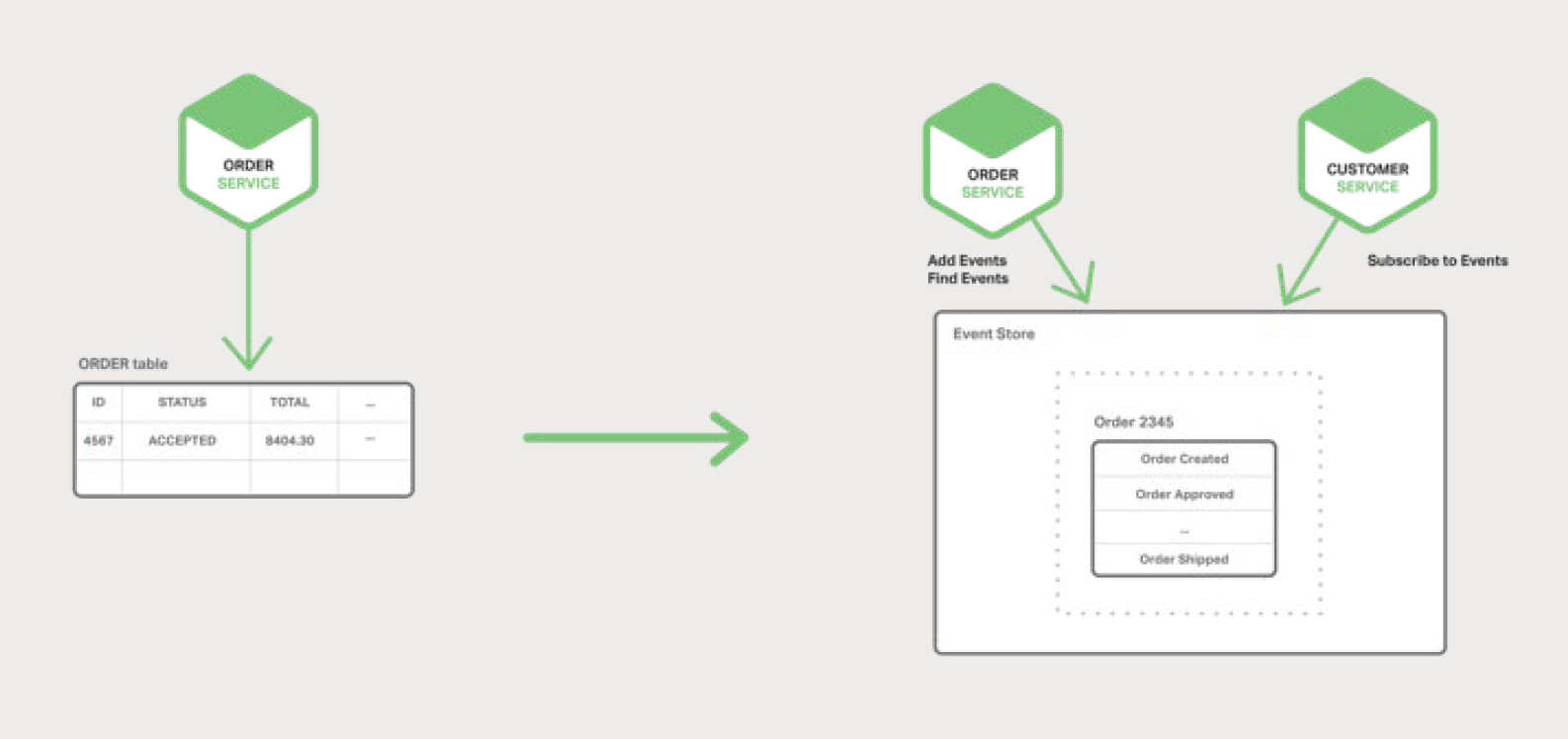
КВјю±»іЦѕГ»ЇФЪКВјюґжґўЦРЈ¬КВјюґжґўКЗТ»ёцКВјюКэѕЭївЎЈёГґжґўУРТ»ёцУГУЪМнјУєНјмЛчКµМеКВјюµД APIЎЈКВјюґжґў»№УлОТГЗЦ®З°ГиКцµДјЬ№№ЦРµД
Message Broker АаЛЖЎЈЛьМṩБЛТ»ёц APIЈ¬К№µГ·юОсДЬ№»¶©ФДКВјюЎЈКВјюґжґўПтЛщУРёРРЛИ¤µД¶©ФДХЯЕЙ·ўЛщУРКВјюЎЈїЙТФЛµКВјюґжґўКЗКВјюЗэ¶ЇОў·юОсјЬ№№µДЦ§ЦщЎЈ
КВјюЛЭФґУРјёёцєГґ¦ЎЈЛьЅвѕцБЛКµПЦКВјюЗэ¶ЇјЬ№№µД№ШјьОКМвЦ®Т»Ј¬їЙТФФЪЧґМ¬·ўЙъ±д»ЇК±їЙїїµШ·ўІјКВјюЎЈТтґЛЈ¬ЛьЅвѕцБЛОў·юОсјЬ№№ЦРµДКэѕЭТ»ЦВРФОКМвЎЈґЛНвЈ¬УЙУЪЛьіЦѕГ»ЇµДКЗКВјюЈ¬¶шІ»КЗБмУт¶ФПуЈ¬ЛщТФЛьЦчТЄ±ЬГвБЛ¶ФПу№ШПµЧиї№К§ЕдОКМвЎЈКВјюЛЭФґ»№МṩБЛ¶ФТµОсКµМеЛщЧцёьёДµД
100ЈҐ їЙїїµДЙујЖИХЦѕЈ¬їЙТФКµПЦФЪИОєОК±јдµг¶ФКµМеЅшРРК±јдІйСЇТФИ·¶ЁЧґМ¬ЎЈКВјюЛЭФґµДБнТ»ёцЦчТЄєГґ¦КЗДъµДТµОсВЯј°ьАЁЛЙсоєПµДЅ»»»КВјюТµОсКµМеЈ¬ХвК№µГґУµҐМеУ¦УГіМРтЗЁТЖµЅОў·юОсјЬ№№Ѕ«±дµГёьјУИЭТЧЎЈ
КВјюЛЭФґН¬СщУРИ±µгЎЈХвКЗТ»ЦЦІ»Н¬¶шД°ЙъµД±аіМ·зёсЈ¬ТтґЛґжФЪС§П°ЗъПЯЎЈКВјюґжґўЅцЦ§іЦНЁ№эЦчјьІйХТТµОсКµМеЎЈДъ±ШРлК№УГГьБоІйСЇФрИО·ЦАлЈЁCQRSЈ©АґКµПЦІйСЇЎЈТтґЛЈ¬У¦УГіМРт±ШР봦АнЧоЦХТ»ЦВµДКэѕЭЎЈ
5.7ЎўЧЬЅб
ФЪОў·юОсјЬ№№ЦРЈ¬ГїёцОў·юОс¶јУРЛЅУРµДКэѕЭґжґўЎЈІ»Н¬µДОў·юОсїЙДЬ»бК№УГІ»Н¬µД SQL »тХЯ NoSQL
КэѕЭївЎЈЛдИ»ХвЦЦКэѕЭївјЬ№№ѕЯУРГчПФµДУЕКЖЈ¬µ«ЛьґґФмБЛТ»Р©·ЦІјКЅКэѕЭ№ЬАнМфХЅЎЈµЪТ»ёцМфХЅКЗИзєОКµПЦО¬»¤¶аёц·юОсјдµДТµОсКВОсТ»ЦВРФЎЈµЪ¶юёцМфХЅКЗИзєОКµПЦґУ¶аёц·юОсЦРјмЛчКэѕЭЎЈ
ґуІї·ЦУ¦УГК№УГµДЅвѕц·Ѕ°ёКЗКВјюЗэ¶ЇјЬ№№ЎЈКµПЦКВјюЗэ¶ЇјЬ№№µДТ»ёцМфХЅКЗИзєОТФФЧУµД·ЅКЅёьРВЧґМ¬ТФј°ИзєО·ўІјКВјюЎЈУРјёЦЦ·Ѕ·ЁїЙТФКµПЦХвµгЈ¬°ьАЁБЛЅ«КэѕЭївЧчОЄПыПў¶УБРЎўКВОсИХЦѕНЪѕтєНКВјюЛЭФґЎЈ
Оў·юОсКµХЅЈєNGINX УлґжґўУЕ»Ї
by Floyd Smith
»щУЪОў·юОсµДґжґў·ЅКЅЙжј°ґуКэБїєНёчЦЦКэѕЭґжґўЈ¬·ГОКєНёьРВКэѕЭЅ«±дµГёьјУёґФУЈ¬DevOps ФЪО¬»¤КэѕЭТ»ЦВРФ·ЅГжГжБЩЧЕёьґуµДМфХЅЎЈNGINX
ОЄХвЦЦКэѕЭ№ЬАнМṩБЛЦШТЄЦ§іЦЈ¬ЦчТЄУРИэёц·ЅГжЈє
КэѕЭ»єґжУлОў»єґжЈЁmicrocachingЈ©
К№УГ NGINX »єґжѕІМ¬ОДјюєНОў»єґжУ¦УГіМРтЙъіЙµДДЪИЭїЙјхЗбУ¦УГіМРтµДёєФШЎўМбёЯРФДЬІўјхЙЩОКМвµД·ўЙъЎЈ
КэѕЭґжґўµДБй»оРФУлїЙА©Х№РФ
Т»µ©Ѕ« NGINX ЧчОЄ·ґПтґъАн·юОсЖчЈ¬ДъµДУ¦УГіМРтФЪґґЅЁЎўµчХыґуРЎЎўФЛРРєНµчХыКэѕЭґжґў·юОсЖчµДґуРЎК±їЙ»сµГєЬґуµДБй»оРФЈ¬ТФВъЧгІ»¶П±д»ЇµДРиЗу
ЎЄ Гїёц·юОс¶јУµУРЧФјєµДКэѕЭґжґўКЗєЬЦШТЄµДЎЈ
·юОсјаїШУл№ЬАнЈ¬°ьАЁКэѕЭ·юОс
ЛжЧЕКэѕЭ·юОсЖчКэБїµДФцјУЈ¬Ц§іЦёґФУІЩЧчєНѕЯУРјаїШєН№ЬАн№¤ѕЯПФµГ·ЗіЈЦШТЄЎЈNGINX Plus ДЪЦГБЛХвР©№¤ѕЯєНУ¦УГіМРтРФДЬ№ЬАнєПЧч»п°йµДЅУїЪЈ¬Из
Data DogЎўDynatrace єН New RelicЎЈ
Оў·юОсПа№ШµДКэѕЭ№ЬАнКѕАэїЙФЪ NGINX Оў·юОсІОїјјЬ№№µДИэґуДЈРНЦРХТµЅЈ¬ЖдОЄДъЙијЖѕцІЯєНКµК©МṩБЛЖрµгЎЈ
6ЎўСЎФсІїКрІЯВФ
±ѕКйЦчТЄЅйЙЬ№ШУЪИзєОК№УГОў·юОс№№ЅЁУ¦УГіМРтЈ¬ХвКЗ±ѕКйµДµЪБщХВЎЈµЪТ»ХВЅйЙЬБЛОў·юОсјЬ№№ДЈКЅЈ¬МЦВЫБЛК№УГОў·юОсµДУЕµгУлИ±µгЎЈЦ®єуµДХВЅЪМЦВЫБЛОў·юОсјЬ№№µД·Ѕ·ЅГжГжЈєК№УГ
API Нш№ШЎўЅшіМјдНЁРЕЎў·юОс·ўПЦєНКВјюЗэ¶ЇКэѕЭ№ЬАнЎЈФЪ±ѕХВЦРЈ¬ОТГЗЅ«ЅйЙЬІїКрОў·юОсµДІЯВФЎЈ
6.1Ўў¶Ї»ъ
ІїКрµҐМеУ¦УГіМРтТвО¶ЧЕФЛРРТ»ёц»т¶аёцПаН¬ё±±ѕµДµҐёцЅПґуµДУ¦УГіМРтЎЈДъНЁіЈ»бФЪГїМЁ·юОсЖчЙПЕдЦГ N
ёц·юОсЖчЈЁОпАн»тРйДвЈ©ІўФЛРР M ёцУ¦УГіМРтКµАэЎЈµҐМеУ¦УГіМРтµДІїКрІўІ»ЧЬКЗ·ЗіЈјтµҐЈ¬µ«Ль±ИІїКрОў·юОсУ¦УГіМРтТЄјтµҐµГ¶аЎЈ
Оў·юОсУ¦УГіМРтУЙКэК®ЙхЦБЙП°Щёц·юОсЧйіЙЎЈ·юОсТФІ»Н¬µДУпСФєНїтјЬ±аРґЎЈГїёц¶јКЗТ»ёцГФДгµДУ¦УГіМРтЈ¬ѕЯУРЧФјєМШ¶ЁµДІїКрЎўЧКФґЎўА©Х№єНјаКУТЄЗуЎЈАэИзЈ¬ДъРиТЄёщѕЭёГ·юОсµДРиЗуФЛРРГїёц·юОсµДТ»¶ЁКэБїµДКµАэЎЈґЛНвЈ¬±ШРлОЄГїёц·юОсКµАэМṩПаУ¦µД
CPUЎўДЪґжєН I/O ЧКФґЎЈёьѕЯМфХЅРФµДКЗѕЎ№ЬИзґЛёґФУЈ¬ІїКр·юОсТІ±ШРлїмЛЩЎўїЙїїєНѕЯУРіЙ±ѕР§ТжЎЈ
УРјёЦЦІ»Н¬µДОў·юОсІїКрДЈКЅЎЈОТГЗКЧПИїґїґµҐЦч»ъ¶а·юОсКµАэДЈКЅЎЈ
6.2ЎўµҐЦч»ъ¶а·юОсКµАэДЈКЅ
ІїКрОў·юОсµДТ»ЦЦ·ЅКЅКЗК№УГµҐЦч»ъ¶а·юОсКµАэЈЁMultiple Service Instances
per HostЈ©ДЈКЅЎЈµ±К№УГґЛДЈКЅК±Ј¬ДъїЙТФМṩһёц»т¶аёцОпАнЦч»ъ»тРйДвЦч»ъЈ¬ІўФЪГїёцЙПФЛРР¶аёц·юОсКµАэЎЈґУ¶а·ЅГжАґЅІЈ¬ХвКЗУ¦УГіМРтІїКрµДґ«Ні·ЅКЅЎЈГїёц·юОсКµАэФЪТ»ёц»т¶аёцЦч»ъµД±кЧј¶ЛїЪЙПФЛРРЎЈЦч»ъНЁіЈ±»µ±ЧчіиОп¶ФґэЎЈ
Нј 6-1 Х№КѕБЛёГДЈКЅµДЅб№№Јє
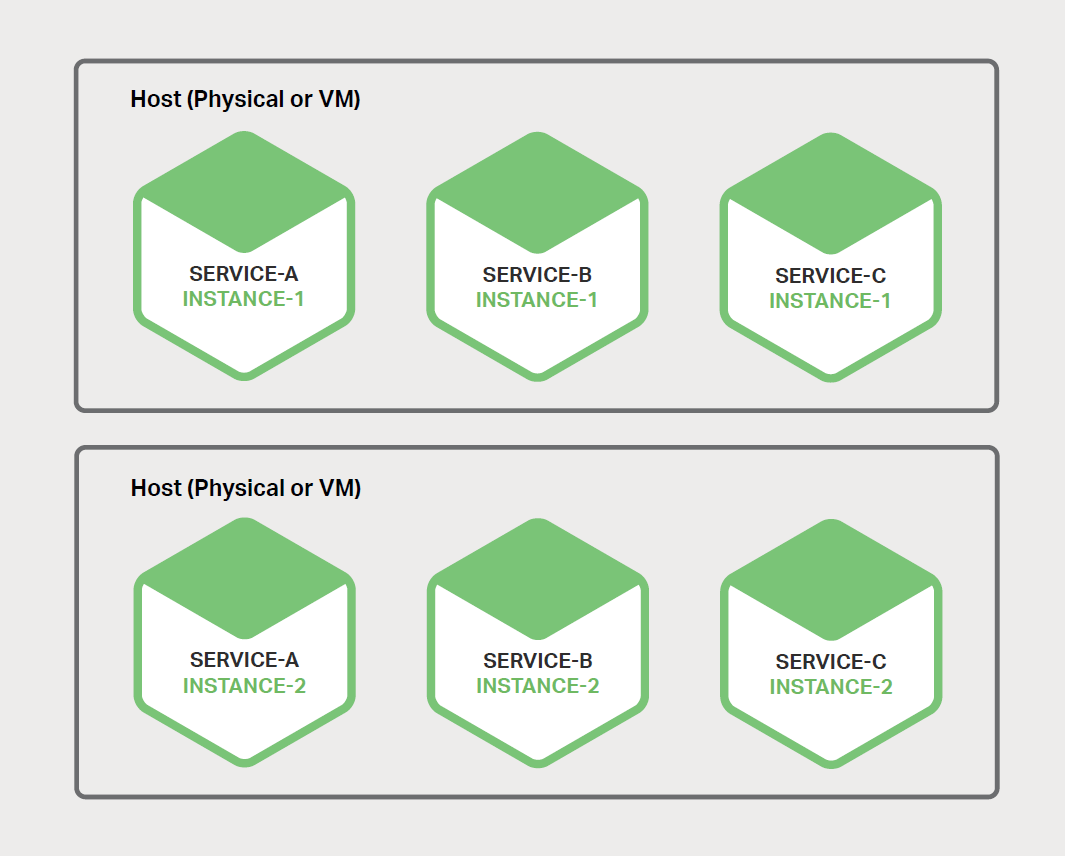
ХвЦЦДЈКЅУРјёёц±дМеЎЈТ»ёц±дМеКЗГїёц·юОсКµАэ¶јКЗТ»ёцЅшіМ»тЅшіМЧйЎЈАэИзЈ¬ДъїЙТФФЪ Apache Tomcat
·юОсЖчЙПЅ« Java ·юОсКµАэІїКрОЄ Web У¦УГіМРтЎЈТ»ёц Node.js ·юОсКµАэїЙДЬ°ьє¬Т»ёцёёЅшіМєНТ»ёц»т¶аёцЧУЅшіМЎЈ
ґЛДЈКЅµДБнТ»ёц±дМеКЗФЪН¬Т»ЅшіМ»тЅшіМЧйЦРФЛРР¶аёц·юОсКµАэЎЈАэИзЈ¬ДъїЙТФФЪН¬Т»ёц Apache Tomcat
·юОсЖчЙПІїКр¶аёц Java Web У¦УГіМРтЈ¬»тФЪН¬Т» OSGI ИЭЖчЦРФЛРР¶аёц OSGI Инјю°ьЎЈ
µҐЦч»ъ¶а·юОсКµАэДЈКЅУРУЕµгТІУРИ±µгЎЈЦчТЄУЕµгКЗЖдЧКФґК№УГВКПа¶ФЅПёЯЎЈ¶аёц·юОсКµАэ№ІПн·юОсЖчј°ЖдІЩЧчПµНіЎЈИз№ыЅшіМ»тЅшіМЧйФЛРРБЛ¶аёц·юОсКµАэЈЁАэИзЈ¬№ІПнПаН¬µД
Apache Tomcat ·юОсЖчєН JVM µД¶аёц Web У¦УГіМРтЈ©Ј¬ФтР§ВКёьёЯЎЈ
ХвЦЦДЈКЅµДБнТ»ёцУЕµгКЗІїКр·юОсКµАэПа¶ФЅПїмЎЈДъЦ»РиЅ«·юОсёґЦЖµЅЦч»ъІўЖф¶ЇЛьЎЈИз№ы·юОсКЗК№УГ Java
±аРґµДЈ¬ФтїЙТФёґЦЖ JAR »т WAR ОДјюЎЈ¶ФУЪЖдЛыУпСФЈ¬АэИз Node.js »т RubyЈ¬ДъїЙТФЦ±ЅУёґЦЖФґґъВлЎЈФЪИОТ»ЗйїцПВЈ¬НЁ№эНшВзёґЦЖµДЧЦЅЪКэ¶јКЗПа¶ФЅПРЎµДЎЈ
БнНвЈ¬УЙУЪИ±·¦їЄПъЈ¬НЁіЈЖф¶ЇТ»ёц·юОсКЗ·ЗіЈїмµДЎЈИз№ыёГ·юОсКЗЧФјєµДЅшіМЈ¬ДгЦ»РиТЄЖф¶ЇЛьјґїЙЎЈИз№ы·юОсКЗФЪН¬Т»ИЭЖчЅшіМ»тЅшіМЧйЦРФЛРРµДјёёцКµАэЦ®Т»Ј¬ФтїЙТФЅ«Жд¶ЇМ¬ІїКрµЅИЭЖчЦР»тХЯЦШРВЖф¶ЇИЭЖчЎЈ
ѕЎ№ЬХвєЬУРОьТэБ¦Ј¬µ«µҐЦч»ъ¶а·юОсКµАэДЈКЅУРТ»Р©ГчПФµДИ±µгЎЈТ»ёцЦчТЄµДИ±µгКЗ·юОсКµАэєЬЙЩ»тХЯГ»УРёфАлЈ¬іэ·ЗГїёц·юОсКµАэКЗТ»ёцµҐ¶АµДЅшіМЎЈЛдИ»ДъїЙТФЧјИ·µШјаКУГїёц·юОсКµАэµДЧКФґАыУГВКЈ¬µ«КЗДъІ»ДЬПЮЦЖГїёцКµАэК№УГµДЧКФґЎЈТ»ёцРРОЄІ»µ±µД·юОсКµАэїЙДЬ»бХјУГµфЦч»ъµДЛщУРДЪґж»т
CPUЎЈ
Из№ы¶аёц·юОсКµАэФЪН¬Т»ЅшіМЦРФЛРРЈ¬ДЗГґЅ«єБОЮёфАлїЙСФЎЈАэИзЈ¬ЛщУРКµАэїЙДЬ№ІПнПаН¬µД JVM ¶СЎЈРРОЄІ»µ±µД·юОсКµАэїЙДЬ»бЗбТЧµШЖЖ»µФЪН¬Т»ЅшіМЦРФЛРРµДЖдЛы·юОсЎЈґЛНвЈ¬ДъОЮ·ЁјаїШГїёц·юОсКµАэК№УГµДЧКФґЎЈ
ХвЦЦ·ЅКЅµДБнТ»ёцЦШТЄОКМвКЗІїКр·юОсµДФЛО¬НЕ¶У±ШРлБЛЅвЦґРРґЛІЩЧчµДѕЯМеПёЅЪЎЈ·юОсїЙТФУГ¶аЦЦУпСФєНїтјЬ±аРґЈ¬ТтґЛїЄ·ўНЕ¶У±ШРлУлФЛО¬Ѕ»ґъРн¶аПёЅЪЎЈХвЦЦёґФУРФОЮТЙјУґуБЛІїКр№эіМЦРµДґнОу·зПХЎЈ
ХэИзДъЛщјыЈ¬ѕЎ№ЬХвЦЦ·ЅКЅјтµҐЈ¬µ«µҐЦч»ъ¶а·юОсКµАэДЈКЅИ·КµґжФЪТ»Р©ГчПФµДИ±µгЎЈПЦФЪИГОТГЗАґїґїґїЙТФИЖ№эХвР©ОКМвІїКрОў·юОсµДЖдЛы·ЅКЅЎЈ
6.3ЎўГїёцЦч»ъТ»ёц·юОсКµАэДЈКЅ
ІїКрОў·юОсµДБнТ»ЦЦ·ЅКЅКЗК№УГГїёцЦч»ъТ»ёц·юОсКµАэЈЁService Instance per HostЈ©ДЈКЅЎЈµ±К№УГґЛДЈКЅК±Ј¬ДъїЙТФФЪЦч»ъЙПµҐ¶АФЛРРГїёц·юОсКµАэЎЈХвЦЦДЈКЅУРБЅЦЦІ»Н¬РОКЅЈєГїёцРйДв»ъТ»ёц·юОсКµАэДЈКЅєНГїёцИЭЖчТ»ёц·юОсКµАэДЈКЅЎЈ
6.3.1ЎўГїёцРйДв»ъТ»ёц·юОсКµАэДЈКЅ
µ±ДъК№УГГїёцРйДв»ъТ»ёц·юОсКµАэДЈКЅК±Ј¬Ѕ«Гїёц·юОсґт°ьіЙТ»ёцРйДв»ъЈЁVMЈ©ѕµПсЈЁИз Amazon EC2
AMIЈ©ЎЈГїёц·юОсКµАэ¶јКЗТ»ёцК№УГёГ VM ѕµПсЖф¶ЇµД VMЈЁАэИзЈ¬Т»ёц EC2 КµАэЈ©ЎЈ
Нј 6-2 Х№КѕБЛёГДЈКЅµДЅб№№Јє
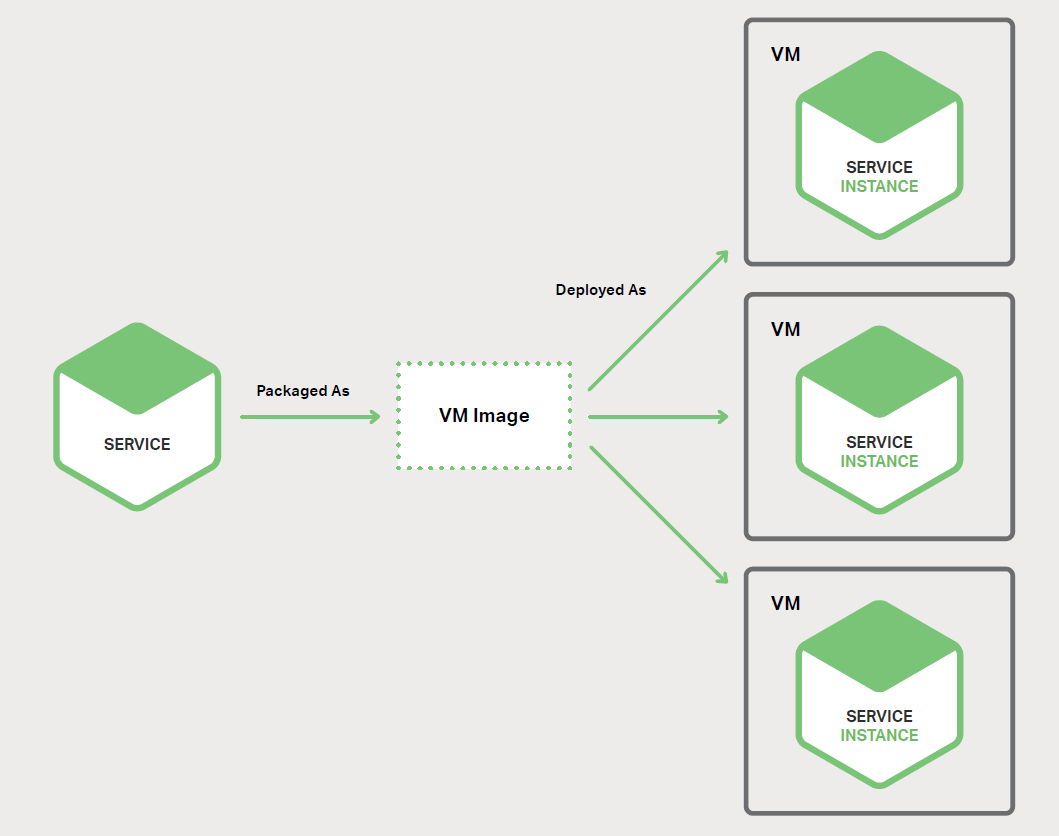
ХвКЗ Netflix ІїКрЖдКУЖµБч·юОсµДЦчТЄ·ЅКЅЎЈNetflix К№УГ Aminator Ѕ«Гїёц·юОсґт°ьОЄ
EC2 AMIЎЈГїёцФЛРРµД·юОсКµАэ¶јКЗТ»ёц EC2 КµАэЎЈ
ДъїЙТФК№УГ¶аЦЦ№¤ѕЯАґ№№ЅЁЧФјєµДРйДв»ъЎЈДъїЙТФЕдЦГДъµДіЦРшјЇіЙЈЁCIЈ©·юОсЖчЈЁ±ИИз JenkinsЈ©АґµчУГ
Aminator Ѕ«·юОсґт°ьОЄТ»ёц EC2 AMIЎЈPacker КЗЧФ¶Ї»ЇРйДв»ъѕµПсґґЅЁµДБнТ»ёцСЎФсЎЈУл
Aminator І»Н¬Ј¬ЛьЦ§іЦёчЦЦРйДв»ЇјјКхЈ¬°ьАЁ EC2ЎўDigitalOceanЎўVirtualBox
єН VMwareЎЈ
Boxfuse №«ЛѕУРТ»ЦЦ·ЗіЈ°фµД·ЅКЅУГАґ№№ЅЁРйДв»ъѕµПсЈ¬ЖдїЛ·юБЛОТЅ«ФЪПВГжГиКцµДРйДв»ъµДИ±µгЎЈBoxfuse
Ѕ«ДъµД Java У¦УГіМРтґт°ьіЙТ»ёцЧоРЎ»ЇµД VM ѕµПсЎЈХвР©ѕµПсїЙ±»їмЛЩ№№ЅЁЎўїмЛЩЖф¶ЇЗТёьјУ°ІИ«Ј¬ТтОЄЛьГЗ±©В¶БЛТ»ёцУРПЮµД№Ґ»чГжЎЈ
CloudNative №«ЛѕУµУР BakeryЈ¬ХвКЗТ»ЦЦУГУЪґґЅЁ EC2 AMI µД SaaS ІъЖ·ЎЈДъїЙТФЕдЦГДъµД
CI ·юОсЖчЈ¬ТФФЪОў·юОсНЁ№эІвКФєуµчУГ BakeryЎЈЦ®єу Bakery Ѕ«ДъµД·юОсґт°ьіЙТ»ёц AMIЎЈК№УГТ»ёцИз
Bakery µД SaaS ІъЖ·ТвО¶ЧЕДъІ»±ШАЛ·С±¦№уµДК±јдАґЙиЦГ AMI ґґЅЁ»щґЎјЬ№№ЎЈ
ГїёцРйДв»ъТ»ёц·юОсКµАэДЈКЅУРРн¶аУЕµгЎЈVM µДЦчТЄУЕµгКЗГїёц·юОсКµАэФЛРРКЗНкИ«ёфАлµДЎЈЛьУР№М¶ЁКэБїµД
CPU єНДЪґжЈ¬ЗТІ»ДЬґУЖдЛы·юОсЗФИЎЧКФґЎЈ
Ѕ«Оў·юОсІїКрОЄРйДв»ъµДБнТ»ёцУЕµгКЗїЙТФАыУГіЙКмµДФЖ»щґЎјЬ№№ЎЈИз AWS Ц®АаµДФЖМṩБЛУРУГµД№¦ДЬЈ¬АэИзёєФШЖЅєвєНЧФ¶ЇА©ЛхЎЈ
Ѕ«·юОсІїКрОЄРйДв»ъµДБнТ»ёцєГґ¦КЗЛь·вЧ°БЛ·юОсµДКµПЦјјКхЎЈТ»µ©·юОс±»ґт°ьіЙТ»ёцРйДв»ъЈ¬ЛьѕНіЙОЄТ»ёцєЪП»ЧУЎЈVM
µД№ЬАн API іЙОЄІїКр·юОсµД APIЎЈІїКр±дµГёьјУјтµҐЎўїЙїїЎЈ
И»¶шЈ¬ГїёцРйДв»ъТ»ёц·юОсКµАэДЈКЅТІУРТ»Р©И±µгЎЈТ»ёцИ±µгКЗЧКФґАыУГВКЅПµНЎЈГїёц·юОсКµАэ¶јУРТ»Хыёц VM
їЄПъЈ¬°ьАЁІЩЧчПµНіЎЈґЛНвЈ¬ФЪТ»ёцµдРНµД№«№І IaaS ЦРЈ¬VM ѕЯУР№М¶ЁґуРЎЈ¬ІўЗТ VM їЙДЬОґ±»ід·ЦАыУГЎЈ
ґЛНвЈ¬№«№І IaaS ЦРµД VM НЁіЈКЗКХ·СµДЈ¬ОЮВЫЛьГЗКЗґ¦УЪ·±Г¦»№КЗїХПРЎЈИз AWS Ц®АаµД IaaS
ЛдИ»МṩБЛЧФ¶ЇА©Лх№¦ДЬЈ¬µ«єЬДСїмЛЩПмУ¦РиЗу±д»ЇЎЈТтґЛЈ¬ДъѕіЈРиТЄ№э¶ИЕдЦГ VMЈ¬ґУ¶шФцјУІїКріЙ±ѕЎЈ
ХвЦЦ·Ѕ·ЁµДБнТ»И±µгКЗІїКрРВ°ж±ѕµД·юОсК±НЁіЈєЬВэЎЈУЙУЪґуРЎФТтЈ¬НЁіЈ VM ѕµПс№№ЅЁєЬВэЎЈґЛНвЈ¬VM
КµАэ»ЇТІєЬВэЈ¬Н¬СщКЗТтОЄЛьГЗµДґуРЎЎЈ¶шЗТЈ¬ІЩЧчПµНіТІРиТЄТ»Р©К±јдАґЖф¶ЇЎЈµ«ЗлЧўТвЈ¬ХвІўІ»ЖХ±йЈ¬ТтОЄТСѕґжФЪУЙ
Boxfuse №№ЅЁµДЗбБїј¶ VMЎЈ
ГїёцРйДв»ъТ»ёц·юОсКµАэДЈКЅµДБнТ»ёцИ±µгКЗНЁіЈДъЈЁ»тЧйЦЇЦРµДЖдЛыИЛЈ©ТЄ¶ФєЬ¶аОґ»®·ЦµДЦШµЈёєФрЎЈіэ·ЗДъК№УГ
Boxfuse ХвСщµД№¤ѕЯАґґ¦Ан№№ЅЁєН№ЬАнРйДв»ъµДїЄПъЈ¬·сФтХвЅ«КЗДъµДФрИОЎЈХвёц±ШТЄ¶шУЦєДК±µД»о¶Ї»б·ЦЙўДъµДєЛРДТµОсЎЈ
ЅУПВАґИГОТГЗїґїґБнТ»ЦЦІїКрёьЗбБїј¶Оў·юОсµДМжґъ·ЅКЅЈ¬ЛьТІУРРн¶аУлРйДв»ъТ»СщµДУЕКЖЎЈ
6.3.2ЎўГїёцИЭЖчТ»ёц·юОсКµАэДЈКЅ
µ±ДъК№УГГїёцИЭЖчТ»ёц·юОсКµАэДЈКЅЈЁService Instance per ContainerЈ©ДЈКЅК±Ј¬Гїёц·юОсКµАэ¶јФЪЖдЧФјєµДИЭЖчЦРФЛРРЎЈИЭЖчКЗТ»ёцІЩЧчПµНіј¶РйДв»Ї»ъЦЖЎЈТ»ёцИЭЖчКЗУЙТ»ёц»т¶аёцФЛРРФЪЙіПдЦРµДЅшіМЧйіЙЎЈґУЅшіМµДЅЗ¶ИАґїґЈ¬ЛьГЗУРЧФјєµД¶ЛїЪГьГыїХјдєНёщОДјюПµНіЎЈДъїЙТФПЮЦЖИЭЖчµДДЪґжєН
CPU ЧКФґЎЈТ»Р©ИЭЖчКµПЦТІѕЯУР I/O ЛЩВКПЮЦЖЎЈИЭЖчјјКхµДПа№ШАэЧУУР Docker єН Solaris
ZonesЎЈ
Нј 6-3 Х№КѕБЛёГДЈКЅµДЅб№№Јє
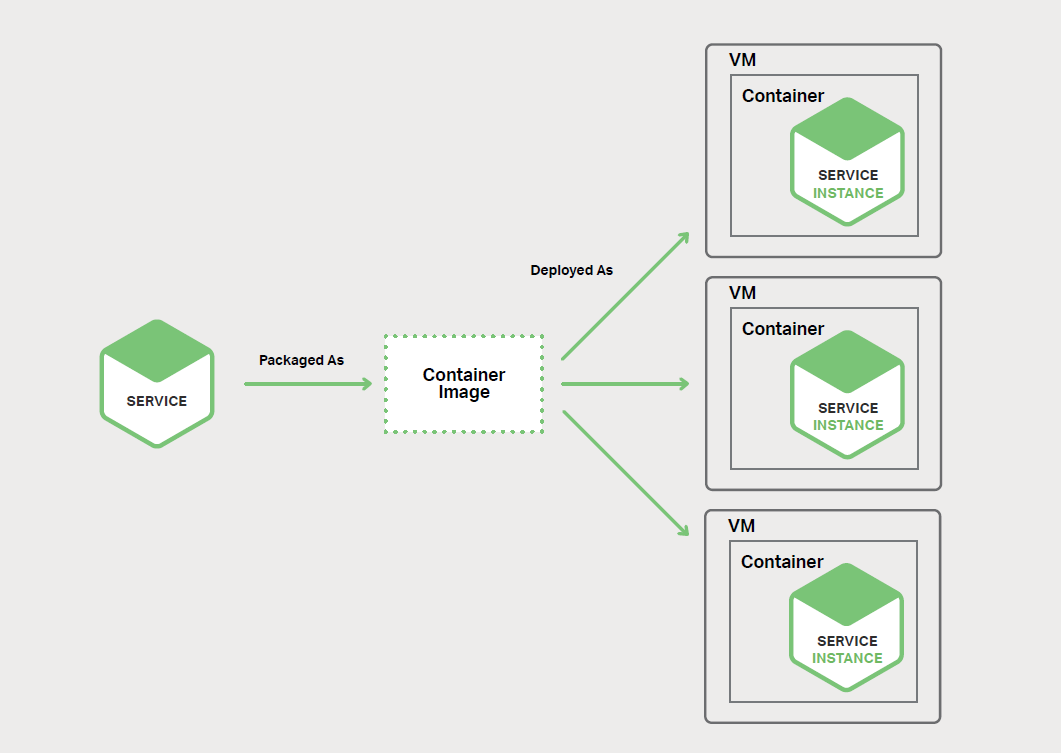
ТЄК№УГґЛДЈКЅЈ¬ЗлЅ«ДъµД·юОсґт°ьіЙТ»ёцИЭЖчѕµПсЎЈИЭЖчѕµПсКЗУЙФЛРР·юОсЛщРиµДУ¦УГіМРтєНївЧйіЙµДОДјюПµНіѕµПсЎЈТ»Р©ИЭЖчѕµПсУЙНкХыµД
Linux ёщОДјюПµНіЧйіЙЎЈґЛНвЛьёьјУЗб±гЎЈАэИзЈ¬ТЄІїКрТ»ёц Java ·юОсЈ¬ДъїЙТФ№№ЅЁТ»ёц°ьє¬БЛ
Java ФЛРРК±µДИЭЖчѕµПсЈ¬їЙДЬКЗТ»ёц Apache Tomcat ·юОсЖчєН±аТлєГµД Java У¦УГіМРтЎЈ
Ѕ«·юОсґт°ьіЙТ»ёцИЭЖчѕµПсєуЈ¬ДъЅ«Жф¶ЇТ»ёц»т¶аёцИЭЖчЎЈНЁіЈФЪГїёцОпАн»тРйДвЦч»ъЙПФЛРР¶аёцИЭЖчЎЈДъїЙТФК№УГјЇИє№ЬАн№¤ѕЯЈЁИз
Kubernetes »т MarathonЈ©Аґ№ЬАнИЭЖчЎЈјЇИє№ЬАн№¤ѕЯЅ«Цч»ъКУОЄТ»ёцЧКФґіШЎЈЛьёщѕЭИЭЖчЛщРиµДЧКФґєНГїёцЦч»ъЙПїЙУГµДЧКФґАґѕц¶ЁГїёцИЭЖч·ЕЦГµДО»ЦГЎЈ
ГїёцИЭЖчТ»ёц·юОсКµАэДЈКЅДЈКЅУРУЕµгєНИ±µгЎЈИЭЖчµДУЕµгУлРйДв»ъµДАаЛЖЎЈЛьГЗЅ«·юОсКµАэ±ЛґЛёфАлЎЈДъїЙТФЗбЛЙµШјаїШГїёцИЭЖчЛщПыєДµДЧКФґЎЈґЛНвЈ¬Ул
VM Т»СщЈ¬ИЭЖч·вЧ°БЛ·юОсКµПЦјјКхЎЈИЭЖч№ЬАн API ЧчОЄ№ЬАнДъµД·юОсµД APIЎЈ
И»¶шЈ¬УлРйДв»ъІ»Н¬Ј¬ИЭЖчКЗЗбБїј¶јјКхЎЈИЭЖчѕµПсНЁіЈїЙТФ·ЗіЈїмЛЩµШ№№ЅЁЎЈАэИзЈ¬ФЪОТµД±КјЗ±ѕµзДФЙПЈ¬Ѕ«Т»ёц
Spring Boot У¦УГіМРтґт°ьіЙТ»ёц Docker ИЭЖчЦ»РиТЄ 5 ГлЦУµДК±јдЎЈИЭЖчТІїЙТФєЬїмµШЖф¶ЇЈ¬ТтОЄГ»УР·±ЛцµДІЩЧчПµНіТэµј»ъЦЖЎЈµ±Т»ёцИЭЖчЖф¶ЇК±Ј¬ЛьЛщФЛРРµДѕНКЗ·юОсЎЈ
К№УГИЭЖчУРТ»Р©И±µгЎЈЛдИ»ИЭЖч»щґЎјЬ№№ХэФЪїмЛЩ·ўХ№ЧЯПтіЙКмЈ¬µ«ЛьІўІ»ПсРйДв»ъµД»щґЎјЬ№№ДЗГґіЙКмЎЈґЛНвЈ¬ИЭЖчІ»Пс
VM ДЗСщ°ІИ«Ј¬ТтОЄИЭЖч±ЛґЛ№ІПнБЛЦч»ъµД OS ДЪєЛЎЈ
ИЭЖчµДБнТ»ёцИ±µгКЗДъРиТЄёєФрОґ»®·ЦµДИЭЖчѕµПс№ЬАнЦШµЈЎЈґЛНвЈ¬іэ·ЗДъК№УГБЛНР№ЬИЭЖчЅвѕц·Ѕ°ёЈЫИз Google
Container Engine »т Amazon EC2 Container ServiceЈЁECSЈ©ЈЭЈ¬·сФтДъ±ШРлЧФјє№ЬАнИЭЖч»щґЎЙиК©ТФј°їЙДЬФЛРРµД
VM »щґЎјЬ№№ЎЈ
ґЛНвЈ¬ИЭЖчНЁіЈІїКрФЪТ»ёц°ґµҐёц VM КХ·СµД»щґЎЙиК©ЙПЎЈТтґЛЈ¬ИзЦ®З°ЛщКцЈ¬їЙДЬ»бІъЙъі¬¶оЕдЦГ VM
µД¶оНвіЙ±ѕЈ¬ТФґ¦АнёєФШ·еЦµЎЈ
УРИ¤µДКЗЈ¬ИЭЖчєН VM Ц®јдµДЗш±рїЙДЬ»бУРР©ДЈєэЎЈИзЦ®З°ЛщКцЈ¬Boxfuse VM їЙТФєЬїмµШ№№ЅЁєНЖф¶ЇЎЈClear
Containers ПоДїЦјФЪґґЅЁЗбБїј¶РйДв»ъЎЈUnikernels ТІХэФЪЕоІЄ·ўХ№ЎЈDocker
№«ЛѕУЪ 2016 ДкіхКХ№єБЛ Unikernel ПµНіЎЈ
»№УРТ»ёцИХТжБчРРµД server-lessЈЁОЮ·юОсЖчЈ©ІїКрёЕДоЈ¬ХвКЗТ»ЦЦ±ЬГвБЛЎ°ФЪИЭЖчЦР»№КЗФЪРйДв»ъЦРІїКр·юОсЎ±ОКМвµД·Ѕ·ЁЎЈЅУПВАґОТГЗАґїґїґЎЈ
6.4ЎўServerless ІїКр
AWS Lambda ѕНКЗТ»ёц serverless ІїКрјјКхКѕАэЎЈЛьЦ§іЦ JavaЎўNode.js
єН Python ·юОсЎЈТЄІїКрОў·юОсЈ¬ЗлЅ«Ждґт°ьіЙ ZIP ОДјюІўЅ«ЙПґ«µЅ AWS LambdaЎЈДъ»№ТЄМṩԪКэѕЭЈ¬ЖдЦР°ьАЁБЛ±»µчУГАґґ¦АнЗлЗуЈЁУЦіЖОЄКВјюЈ©µДєЇКэµДГыіЖЎЈAWS
Lambda ЧФ¶ЇФЛРРЧг№»µДОў·юОс·юОсКµАэАґґ¦АнЗлЗуЎЈДъЦ»РиёщѕЭГїёцЗлЗуЛщУГК±јдєНДЪґжПыєДАґё¶·СЎЈµ±И»Ј¬ОКМвНщНщіцПЦФЪПёЅЪЙПЈ¬ДъєЬїмЧўТвµЅБЛ
AWS Lambda µДѕЦПЮРФЎЈµ«КЗЈ¬ЧчОЄїЄ·ўИЛФ±µДДъ»тЧйЦЇЦРµДИОєОИЛ¶јОЮРиµЈРД·юОсЖчЎўРйДв»ъ»тИЭЖчµДИОєО·ЅГж
Ј¬Хв·ЗіЈУРОьТэБ¦Ј¬ЧгТФБоИЛДСТФЦГРЕЎЈ
Lambda єЇКэКЗОЮЧґМ¬·юОсЎЈЛьНЁіЈНЁ№эµчУГ AWS ·юОсАґґ¦АнЗлЗуЎЈАэИзЈ¬µ±НјЖ¬ЙПґ«µЅ S3
ґжґўН°К±Lambda єЇКэЅ«±»µчУГЈ¬їЙІеИлТ»МхјЗВјµЅ DynamoDB НјЖ¬±нЦРЈ¬ІўЅ«ПыПў·ўІјµЅ Kinesis
БчТФґҐ·ўНјЖ¬ґ¦АнЎЈ Lambda єЇКэ»№їЙТФµчУГµЪИэ·Ѕ Web ·юОсЎЈ
УРЛДЦЦ·Ѕ·ЁµчУГ Lambda єЇКэЈє
Ц±ЅУК№УГ Web ·юОсЗлЗу
ЧФ¶ЇПмУ¦Т»ёц AWS ·юОсЈЁИз S3ЎўDynamoDBЎўKinesis »т Simple Email
ServiceЈ©ЙъіЙµДКВјю
НЁ№э AWS API Нш№ШЧФ¶Їґ¦АнАґЧФУ¦УГіМРтїН»§¶ЛµД HTTP ЗлЗу
°ґХХТ»ёцАаЛЖ cron µДК±јд±нЈ¬¶ЁЖЪЦґРР
ХэИзДъЛщјыЈ¬AWS Lambda КЗТ»ёц±гЅЭµДОў·юОсІїКр·ЅКЅЎЈ»щУЪЗлЗуµД¶ЁјЫТвО¶ЧЕДъЦ»РиОЄ·юОсКµјКЦґРРµД№¤ЧчЦ§ё¶ЎЈБнНвЈ¬УЙУЪДъІ»РиТЄ¶Ф
IT »щґЎјЬ№№ёєИОєОФрИОЈ¬ТтґЛїЙТФЧЁЧўУЪїЄ·ўУ¦УГіМРтЎЈ
И»¶шЈ¬ЖдТІґжФЪТ»Р©ГчПФµДѕЦПЮРФЎЈLambda єЇКэІ»ККУГУЪІїКрі¤К±јдФЛРРµД·юОсЈ¬АэИзПыєДµЪИэ·ЅПыПўґъАнПыПўµД·юОсЎЈЗлЗу±ШРлФЪ
300 ГлДЪНкіЙЎЈ·юОс±ШРлКЗОЮЧґМ¬µДЈ¬ТтОЄАнВЫЙПЈ¬AWS Lambda їЙДЬОЄГїёцЗлЗуФЛРРТ»ёцµҐ¶АµДКµАэЎЈЛыГЗ±ШРлК№УГКЬЦ§іЦµДУпСФЦ®Т»Аґ±аРґЎЈ·юОсТІ±ШРлїмЛЩЖф¶ЇЈ¬·сФтЈ¬ЛыГЗїЙДЬ»бТті¬К±¶шЦХЦ№ЎЈ
6.5ЎўЧЬЅб
ІїКрОў·юОсУ¦УГіМРтідВъЧЕМфХЅЎЈДъїЙДЬУРКэёцЙхЦБКэ°ЩёцК№УГБЛёчЦЦУпСФєНїтјЬ±аРґµД·юОсЎЈГїёцУ¦УГіМРт¶јКЗТ»ёцГФДгУ¦УГіМРтЈ¬УРЧФјєМШ¶ЁµДІїКрЎўЧКФґЎўА©Х№єНјаКУРиЗуЎЈУРјёёцОў·юОсІїКрДЈКЅЈ¬°ьАЁГїёцРйДв»ъТ»ёц·юОсКµАэєНГїёцИЭЖчТ»ёц·юОсКµАэДЈКЅЎЈІїКрОў·юОсµДБнТ»ёцУРИ¤µДСЎФсКЗ
AWS LambdaЈ¬Т»ЦЦ serverless ·ЅКЅЎЈФЪ±ѕКйµДПВТ»ХВТІКЗЧоєуТ»ХВЦРЈ¬ОТГЗЅ«ЅйЙЬИзєОЅ«µҐМеУ¦УГіМРтЗЁТЖµЅОў·юОсјЬ№№ЎЈ
Оў·юОсКµХЅЈєК№УГ NGINX ФЪІ»Н¬Цч»ъЙПІїКрОў·юОс
by Floyd Smith
NGINX ¶ФУЪёчЦЦАаРНµДІїКрѕЯУРРн¶аУЕКЖ ЎЄ ОЮВЫКЗµҐМеУ¦УГіМРтЎўОў·юОсУ¦УГіМРт»№КЗ»мєПУ¦УГіМРтЈЁЅ«ФЪПВТ»ХВЅйЙЬЈ©ЎЈК№УГ
NGINXЈ¬ДъїЙТФЦЗДЬійИЎІ»Н¬µДІїКр»·ѕііцАґІўХыєПИл NGINXЎЈИз№ыДъК№УГХл¶ФІ»Н¬ІїКр»·ѕіµД№¤ѕЯЈ¬ФтУРРн¶аУ¦УГіМРт№¦ДЬЅ«ТФІ»Н¬µД·ЅКЅ№¤ЧчЈ¬µ«Из№ыК№УГ
NGINXЈ¬ДЗГґФЪЛщУР»·ѕіЦР¶јїЙТФК№УГПаН¬µД·ЅКЅЅшРР№¤ЧчЎЈ
ХвТ»МШРФТІОЄ NGINX єН NGINX Plus ґшАґБЛµЪ¶юёцУЕКЖЈєНЁ№эФЪ¶аёцІїКр»·ѕіЦРН¬К±ФЛРРУ¦УГіМРтАґА©Х№У¦УГіМРтµДДЬБ¦ЎЈјЩЙиДъУµУРєН№ЬАнЧЕµД±ѕµШ·юОсЖчЈ¬µ«КЗДъµДУ¦УГіМРтК№УГЗйїцХэФЪФці¤Ј¬ІўЗТФ¤јЖЅ«і¬іцХвР©·юОсЖчїЙТФґ¦АнµД·еЦµЎЈИз№ыДгТСѕК№УГБЛ
NGINXЈ¬ДъѕНУРБЛТ»ёцЗїґуµДСЎФсЈєА©Х№µЅФЖ¶Л ЎЄ АэИзЈ¬А©Х№µЅ AWS ЙПЈ¬¶шІ»КЗ№єВтЎўЕдЦГєН±ЈіЦ¶оНвµД·юОсЖчАґОЄБЛТФ·АНтТ»ЎЈТІѕНКЗЛµЈ¬µ±ДъµД±ѕµШ·юОсЖчЙПµДБчБїґпµЅИЭБїПЮЦЖК±Ј¬їЙёщѕЭРиТЄФЪФЖЦРЖф¶ЇЖдЛыОў·юОсКµАэАґґ¦АнЎЈ
ХвЦ»КЗТтК№УГ NGINX ±дµГёьјУБй»оµДТ»ёцАэЧУЎЈО¬»¤µҐ¶АµДІвКФєНІїКр»·ѕіЎўЗР»»»·ѕіµД»щґЎЙиК©ЎўТФј°№ЬАнёчЦЦ»·ѕіЦРµДУ¦УГіМРтЧйєП¶ј±дµГёьјУПЦКµєНїЙКµПЦЎЈ
NGINX Оў·юОсІОїјјЬ№№±»ГчИ·ЙијЖОЄЦ§іЦХвЦЦБй»оІїКрЈ¬ЖдјЩЙиФЪїЄ·ўєНІїКрЖЪјдК№УГИЭЖчјјКхЎЈИз№ыДъ»№Г»іўКФЈ¬їЙТФїјВЗЧЄТЖµЅИЭЖчЎўNGINX
»т NGINX PlusЈ¬ТФЗбЛЙµШЧЄТЖµЅОўРН·юОсЈ¬ТФј°К№ДъµДУ¦УГіМРтЎўїЄ·ўєНІїКрБй»оРФТФј°ИЛФ±ёьѕЯЗ°Х°РФЎЈ
7ЎўЦШ№№µҐМеОЄОў·юОс
±ѕКйЦчТЄЅйЙЬИзєОК№УГОў·юОс№№ЅЁУ¦УГіМРтЈ¬ХвКЗ±ѕКйµДµЪЖЯХВЈ¬ТІКЗЧоєуТ»ХВЎЈµЪТ»ХВЅйЙЬБЛОў·юОсјЬ№№ДЈКЅЈ¬МЦВЫБЛК№УГОў·юОсµДУЕµгУлИ±µгЎЈЛжєуµДХВЅЪМЦВЫБЛОў·юОсјЬ№№µД·Ѕ·ЅГжГжЈєК№УГ
API ??Нш№ШЎўЅшіМјдНЁРЕЎў·юОс·ўПЦЎўКВјюЗэ¶ЇКэѕЭ№ЬАнєНІїКрОў·юОсЎЈФЪ±ѕХВЦРЈ¬ОТГЗЅ«ЅйЙЬµҐМеУ¦УГЗЁТЖµЅОў·юОсµДІЯВФЎЈ
ОТПЈНыХв±ѕµзЧУКйДЬ№»ИГДъ¶ФОў·юОсјЬ№№ЎўЖдУЕµгєНИ±µгТФј°єОК±К№УГЛьУРєЬєГµДБЛЅвЎЈОў·юОсјЬ№№ТІРнєЬККєПДъµДЧйЦЇЎЈ
ДъХэ№¤ЧчУЪґуРНёґФУµДµҐМеУ¦УГіМРтЙПЈ¬ХвКЗПаµ±І»ґнµД»ъ»бЎЈИ»¶шЈ¬ДъїЄ·ўєНІїКрУ¦УГіМРтµДИХіЈѕАъКЗ»єВэ¶шНґїаµДЎЈОў·юОсЛЖєхКЗТ»ёцТЈІ»їЙј°µДМмМГЎЈРТФЛµДКЗЈ¬УРТ»Р©ХЅВФїЙТФУГАґМУА뵥МеµШУьЎЈФЪ±ѕОДЦРЈ¬ОТЅ«ГиКцИзєОЅ«µҐМеУ¦УГіМРтЦрЅҐЦШ№№ОЄТ»ЧйОў·юОсЎЈ
7.1ЎўОў·юОсЦШ№№ёЕКц
µҐМеУ¦УГіМРтЧЄ»»ОЄОў·юОсµД№эіМКЗУ¦УГіМРтПЦґъ»ЇµДТ»ЦЦРОКЅЎЈХвКЗјёК®ДкАґїЄ·ўИЛФ±Т»Ц±ФЪЧцµДКВЗйЎЈТтґЛЈ¬ФЪЅ«У¦УГіМРтЦШ№№ОЄОў·юОсК±Ј¬УРТ»Р©Пл·ЁКЗїЙТФЦШУГµДЎЈ
Т»ёцІ»ТЄК№УГµДІЯВФКЗЎ°ґу±¬ХЁЎ±ЦШРґЎЈѕНКЗДъЅ«ЛщУРµДїЄ·ў№¤Чч¶јјЇЦРФЪґУН·їЄКј№№ЅЁРВµД»щУЪОў·юОсµДУ¦УГіМРтЎЈЛдИ»ХвМэЖрАґєЬОьТэИЛЈ¬µ«·ЗіЈОЈПХЈ¬УРїЙДЬ»бК§°ЬЎЈѕЭ
AsMartin Fowler ЅІµЅЈєЎ°ґу±¬ХЁЦШРґµДОЁТ»±ЈЦ¤ѕНКЗґу±¬ХЁЈЎЎ±ЈЁ"the only
thing a Big Bang rewrite guarantees is a Big Bang!"Ј©ЎЈ
ДъУ¦ёГЦрІЅЦШ№№µҐМеУ¦УГіМРтЈ¬¶шІ»КЗНЁ№эґу±¬ХЁЦШРґЎЈДъїЙТФЦрЅҐМнјУРВ№¦ДЬЈ¬ІўТФОў·юОсµДРОКЅґґЅЁПЦУР№¦ДЬµДА©Х№
ЎЄ ТФ»ҐІ№µДРОКЅРЮёДµҐМеУ¦УГЈ¬ІўЗТТ»Н¬ФЛРРОў·юОсєНРЮёДєуµДµҐМеЎЈЛжЧЕК±јдНЖТЖЈ¬µҐМеУ¦УГіМРтКµПЦµД№¦ДЬБї»бЛхРЎЈ¬Ц±µЅЛьНкИ«ПыК§»т±діЙБнТ»ёцОў·юОсЎЈХвЦЦІЯВФАаЛЖУЪФЪ
70№«Ап/РЎК±µДёЯЛЩ№«В·ЙПјЭК»Т»БѕЖыіµЈ¬єЬѕЯМфХЅРФЈ¬µ«±ИіўКФґу±¬ХЁёДРґµД·зПХТЄРЎµГ¶аЎЈ

Martin Fowler Ѕ«ХвЦЦУ¦УГПЦґъ»ЇІЯВФіЖОЄЙ±КЦУ¦УГЈЁStrangler ApplicationЈ©ЎЈХвёцГыЧЦАґЧФ·ўПЦУЪИИґшУкБЦЦРµДЖПМСКчЈЁТІіЖОЄЅКЙ±йЕЈ©ЎЈТ»їГЖПМСКчЙъі¤ФЪТ»їГКчЙПЈ¬ТФ»сИЎЙБЦ№ЪІгЦ®ЙПµДСф№вЎЈУРК±Ј¬КчЛАБЛЈ¬БфПВТ»ёцКчРОµДМЪЎЈУ¦УГПЦґъ»ЇТІЧсСПаН¬µДДЈКЅЎЈОТГЗЅ«№№ЅЁТ»ёцРВµДУ¦УГіМРтЈ¬°ьАЁБЛО§ИЖТЕБфУ¦УГµДОў·юОсЈЁЛьЅ«»бВэВэЛхРЎ»тХЯЧоЦХПыНцЈ©ЎЈ
ИГОТГЗАґїґїґДЬЧцµЅХвµгµДІ»Н¬ІЯВФЎЈ
7.2ЎўІЯВФТ»ЈєНЈЦ№НЪѕт
¶ґСЁ¶ЁВЙЛµµЅЈ¬Гїµ±ДъЙнґ¦ФЪТ»ёц¶ґСЁЦРЈ¬ДъУ¦ёГНЈЦ№НЪѕтЎЈµ±ДъµДµҐМеУ¦УГ±дµГДСТФ№ЬАнК±Ј¬ХвКЗТ»ёцєЬєГµДЅЁТйЎЈ»»ѕд»°ЛµЈ¬ДъУ¦ёГНЈЦ№А©ХЕЈ¬±ЬГвК№µҐМе±дµГёьґуЎЈХвТвО¶ЧЕµ±ДъТЄКµПЦРВ№¦ДЬК±Ј¬ДъІ»У¦ёГПтµҐМеМнјУёь¶аµДґъВлЎЈПа·ґЈ¬ХвТ»ІЯВФµДЦчТЄЛјПлКЗЅ«РВґъВл·ЕФЪ¶АБўµДОў·юОсЦРЎЈ
У¦УГґЛ·Ѕ·ЁєуЈ¬ПµНіјЬ№№ИзНј 7-1 ЛщКѕЎЈ
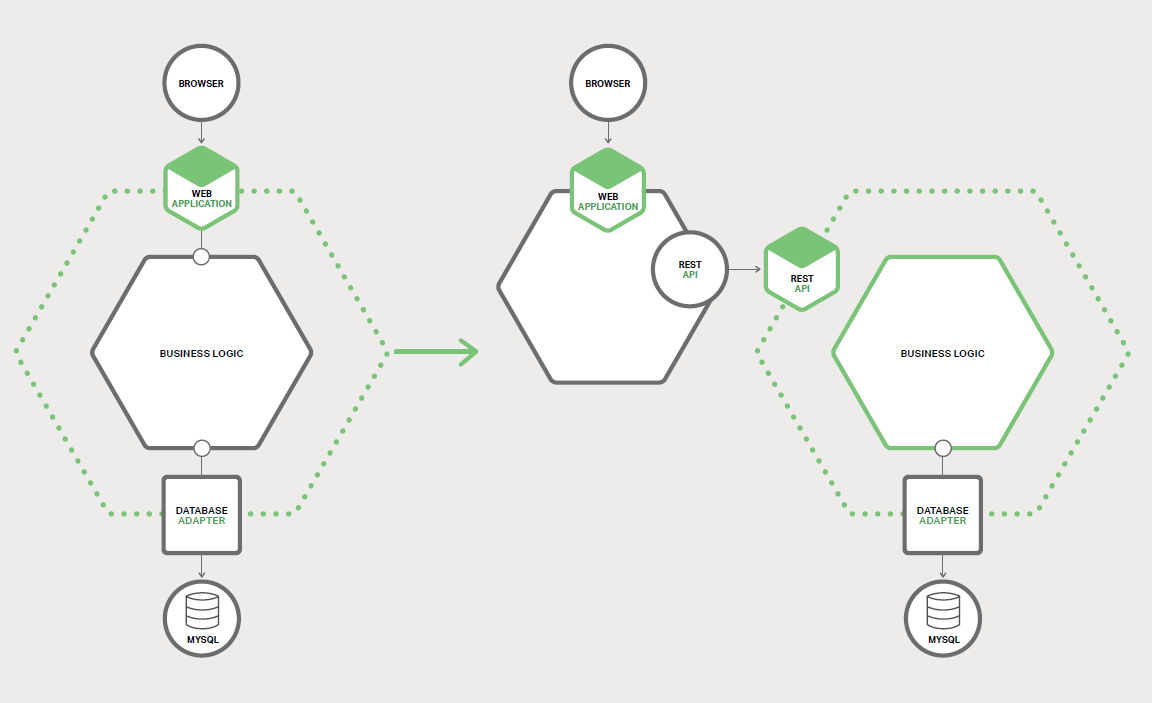
іэБЛРВ·юОсєНґ«НіµДµҐМеЈ¬»№УРБнНвБЅёцЧйјюЎЈµЪТ»ёцКЗЗлЗуВ·УЙЈ¬Льґ¦Анґ«ИлµДЈЁHTTPЈ©ЗлЗуЈ¬АаЛЖУЪµЪ¶юХВЦРГиКцµД
API Нш№ШЎЈВ·УЙПтРВ·юОс·ўЛНУлРВ№¦ДЬПа¶ФУ¦µДЗлЗуЎЈЛьЅ«ТЕБфµДЗлЗуВ·УЙµЅµҐМеЎЈ
БнТ»ёцЧйјюКЗХієПґъВлЈ¬ЛьЅ«·юОсУ뵥МејЇіЙЎЈТ»ёц·юОсєЬЙЩ№ВБўґжФЪЈ¬НЁіЈРиТЄ·ГОКµҐМеµДКэѕЭЎЈО»УЪµҐМеЎў·юОс»тБЅХЯЦРµДХієПґъВлёєФрКэѕЭјЇіЙЎЈёГ·юОсК№УГХієПґъВлАґ¶БИЎєНРґИ뵥МеКэѕЭЎЈ
·юОсїЙТФК№УГИэЦЦІЯВФАґ·ГОКµҐМеКэѕЭЈє
µчУГУЙµҐМеМṩµДФ¶іМ API
Ц±ЅУ·ГОКµҐМеКэѕЭїв
О¬»¤ЧФјєµДКэѕЭё±±ѕЈ¬У뵥МеКэѕЭївН¬ІЅ
ХієПґъВлУРК±±»іЖОЄ·А»¤ІгЈЁanti-corruption layerЈ©ЎЈХвКЗТтОЄХієПґъВлЧиЦ№БЛ·юОс±»ТЕБфµДµҐМеБмУтДЈРНµДёЕДоЛщОЫИѕЈ¬ХвР©·юОсѕЯУРЧФјєµДФКјБмУтДЈРНЎЈХієПґъВлФЪБЅЦЦІ»Н¬µДДЈРНЦ®јдЧЄ»»ЎЈ·А»¤ІгТ»ґККЧПИіцПЦУЪ°ЈАпїЛЎ¤°ЈОДЛ№ЈЁEric
EvansЈ©ЛщЦшµД±Ш¶БНјКйЎ¶БмУтЗэ¶ЇЙијЖЎ·ЈЁDomain Driven DesignЈ©ЦРЈ¬ІўФЪ°ЧЖ¤КйЦРЅшРРБЛёДЅшЎЈїЄ·ўТ»ёц·А»¤ІгІўІ»КЗТ»јюјтµҐµДКВЗйЎЈµ«КЗЈ¬Из№ыДъПлТЄґУµҐМеµШУьЦРЧЯіцАґЈ¬ХвКЗ±ШІ»їЙЙЩµДІЅЦиЎЈ
К№УГЗбБїј¶·юОсАґКµПЦРВ№¦ДЬУРјёёцєГґ¦ЎЈЛь·АЦ№µҐМе±дµГёьјУДСТФ№ЬАнЎЈёГ·юОсїЙТФ¶АБўУЪµҐМеїЄ·ўЎўІїКрєНА©Х№ЎЈїЙИГДъґґЅЁµДГїёцРВ·юОсМеСйµЅОў·юОсјЬ№№µДУЕКЖЎЈ
И»¶шЈ¬ХвЦЦ·Ѕ·ЁГ»УРЅвѕцµҐМеОКМвЎЈТЄЅвѕцХвР©ОКМвЈ¬ДъРиТЄ·ЦЅвµҐМеЎЈИГОТГЗАґїґїґХвСщЧцµДІЯВФЎЈ
7.3ЎўІЯВФ¶юЈєЗ°єу¶Л·ЦАл
ЛхРЎµҐМеУ¦УГµДТ»ёцІЯВФКЗґУТµОсВЯјІгєНКэѕЭ·ГОКІгІр·Ціц±нПЦІгЎЈТ»ёцµдРНµДЖуТµУ¦УГУЙЦБЙЩИэЦЦІ»Н¬АаРНµДЧйјюЧйіЙЈє
±нПЦІгЈЁPresentation LayerЈ¬PLЈ©
ґ¦Ан HTTP ЗлЗуІўКµПЦЈЁRESTЈ©API »т»щУЪ HTML µД Web UI ЧйјюЎЈФЪѕЯУРёґФУУГ»§ЅзГжµДУ¦УГЦРЈ¬±нПЦІгНЁіЈґжФЪґуБїґъВлЎЈ
ТµОсВЯјІгЈЁBusiness Logic LayerЈ¬BLLЈ©
ЧчОЄУ¦УГіМРтєЛРДЈ¬КµПЦТµОс№жФтµДЧйјюЎЈ
КэѕЭ·ГОКІгЈЁData Access LayerЈ¬DALЈ©
·ГОК»щґЎјЬ№№ЧйјюµДЧйјюЈ¬ИзКэѕЭївєНПыПўґъАнЎЈ
Т»·ЅµД±нПЦВЯјєНБнТ»·ЅµДТµОсєНКэѕЭ·ГОКВЯјЦ®јдНЁіЈУРТ»ёцНкИ«µДёфАлЎЈТµОсІгѕЯУРУЙТ»ёц»т¶аёцГЕГжЧйіЙµДґЦБЈ¶И
APIЈ¬Жд·вЧ°БЛТµОсВЯјЧйјюЎЈХвёц API КЗТ»ёцМмИ»µД±ЯЅзЈ¬ДъїЙТФСШЧЕёГ±ЯЅзЅ«µҐМеІр·ЦіЙБЅёцЅПРЎµДУ¦УГіМРтЎЈТ»ёцУ¦УГіМРт°ьє¬±нПЦІгЎЈБнТ»ёцУ¦УГіМРт°ьє¬ТµОсєНКэѕЭ·ГОКВЯјЎЈ·ЦёоєуЈ¬±нПЦВЯјУ¦УГіМРт¶ФТµОсВЯјУ¦УГіМРтЅшРРФ¶іМµчУГЎЈ
ЦШ№№Ц®З°єНЦ®єуµДјЬ№№ИзНј 7-2 ЛщКѕЎЈ
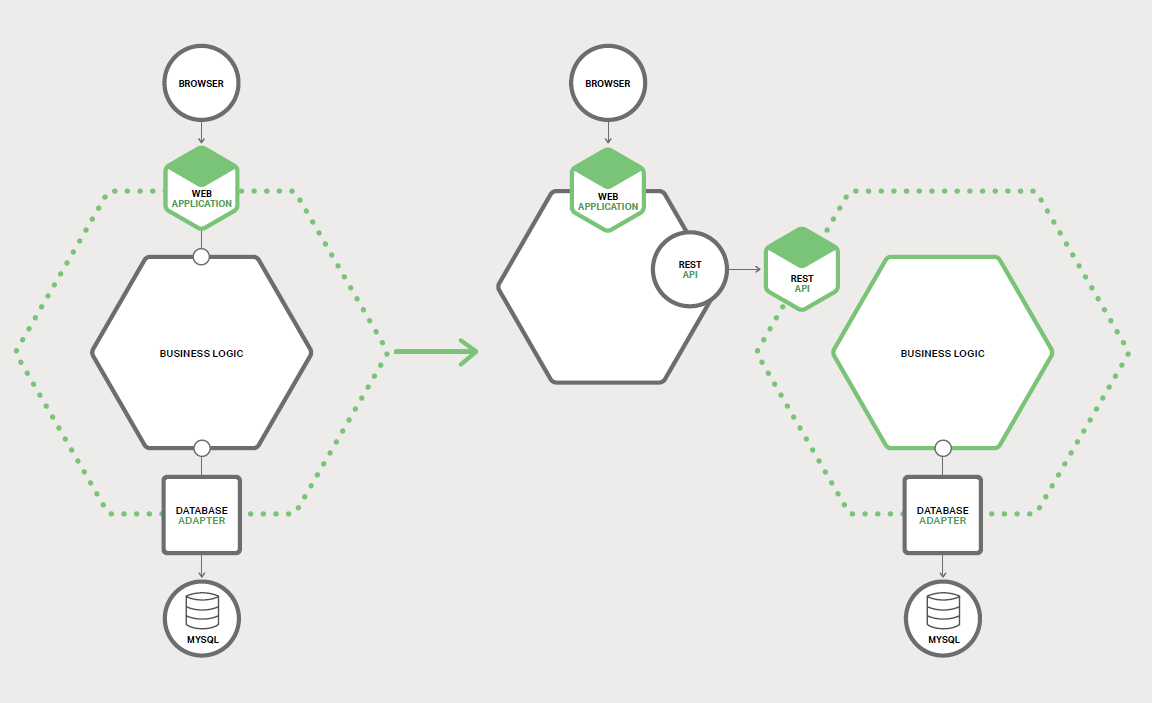
ТФХвЦЦ·ЅКЅІр·ЦµҐМеУРБЅёцЦчТЄУЕµгЎЈЛьК№ДъДЬ№»¶АБўУЪ±ЛґЛїЄ·ўЎўІїКрєНА©Х№ХвБЅёцУ¦УГЎЈМШ±рКЗЛьФКРн±нПЦІгїЄ·ўИЛФ±ФЪУГ»§ЅзГжЙПїмЛЩµьґъЈ¬ІўЗТїЙТФЗбЛЙЦґРР
A/B ІвКФЎЈХвЦЦ·Ѕ·ЁµДБнТ»ёцУЕµгКЗЛь±©В¶БЛїЙТФ±»ДъїЄ·ўµДОў·юОсµчУГµДФ¶іМ APIЎЈ
И»¶шЈ¬ХвТ»ІЯВФЦ»КЗТ»ёцѕЦІїЅвѕц·Ѕ°ёЎЈБЅёцУ¦УГіМРтЦРµДТ»ёц»тБЅёцєЬїЙДЬКЗТ»ёцОЮ·Ё№ЬАнµДµҐМеЎЈДъРиТЄК№УГµЪИэЦЦІЯВФАґПыіэКЈУаµДХыМе»тµҐМеЎЈ
7.4ЎўІЯВФИэЈєМбИЎ·юОс
µЪИэёцЦШ№№ІЯВФКЗЅ«ЕУґуµДПЦУРДЈїйЧЄ±дОЄ¶АБўµДОў·юОсЎЈГїґОМбИЎТ»ёцДЈїйІўЅ«ЖдЧЄ»»іЙ·юОсК±Ј¬µҐМеѕН»бЛхРЎЎЈТ»µ©ДъЧЄ»»БЛЧг№»µДДЈїйЈ¬µҐМеЅ«І»ФЩКЗТ»ёцОКМвЎЈ»тХЯЛьНкИ«ПыК§Ј¬»тХЯ±дµГЧг№»РЎЈ¬ЛьѕНїЙТФ±»µ±ЧцТ»ёц·юОсїґґэЎЈ
7.4.1ЎўУЕПИЅ«ДДР©ДЈїйЧЄ»»ОЄОў·юОс
Т»ёцЕУґу¶шёґФУµДµҐМеУ¦УГУЙјёК®ёц»тјё°ЩёцДЈїйЧйіЙЈ¬ЛщУРДЈїй¶јКЗМбИЎµДєтСЎПоЎЈЕЄЗеіюТЄПИЧЄ»»ДДР©ДЈїйНщНщґжФЪТ»¶ЁµДМфХЅЎЈТ»ёцєГµД·Ѕ·ЁКЗґУИЭТЧМбИЎµДјёёцДЈїйїЄКјЎЈДъЅ«µГµЅОў·юОсµДПа№ШѕСйЈ¬МШ±рКЗФЪМбИЎ№эіМ·ЅГжЎЈЦ®єуЈ¬ДъУ¦ёГМбИЎДЗР©ДЬёшДъЧоґуАыТжµДДЈїйЎЈ
Ѕ«ДЈїйЧЄ»»ОЄ·юОсНЁіЈКЗєДК±µДЎЈДъПл°ґХХДъЅ«»сµГµДАыТж¶ФДЈїйЅшРРЕЕБРЎЈМбИЎЖµ·±ёьёДµДДЈїйНЁіЈКЗУРТжµДЎЈТ»µ©Ѕ«ДЈїйЧЄ»»ОЄ·юОсЈ¬ДъѕНїЙТФ¶АБўУЪµҐМеїЄ·ўєНІїКрЈ¬ХвЅ«јУїмїЄ·ў№¤ЧчЎЈ
МбИЎХвР©У뵥МеµДЖдЛыДЈїйУРПФЦшІ»Н¬µДДЈїйТІКЗУРТжµДЎЈАэИзЈ¬Ѕ«УРТ»ёцУРДЪґжКэѕЭївµДДЈїйЧЄ»»ОЄ·юОсКЗєЬУРУГµДЈ¬ХвСщїЙТФІїКрФЪѕЯУРґуБїДЪґжµДЦч»ъЙПЈ¬ОЮВЫКЗВг»ъ·юОсЖчЎўРйДв»ъ»№КЗФЖКµАэЎЈН¬СщЈ¬МбИЎКµПЦБЛјЖЛг°є№уЛг·ЁµДДЈїйТІКЗЦµµГµДЈ¬ТтОЄёГ·юОсїЙТФІїКрФЪѕЯУРґуБї
CPU µДЦч»ъЙПЎЈНЁ№эЅ«ѕЯУРМШ¶ЁЧКФґРиЗуµДДЈїйЧЄ»»ОЄ·юОсЈ¬ДъїЙТФК№У¦УГіМРтёьјУИЭТЧЎўБ®јЫµША©Х№ЎЈ
µ±ХТµЅТЄМбИЎµДДЈїйК±Ј¬С°ХТПЦУРµДґЦБЈ¶И±ЯЅзЈЁУЦіЖОЄЅУ·мЈ©КЗУРУГµДЎЈЛьГЗК№ДЈїйЧЄіЙ·юОс±дµГёьИЭТЧєНёьБ¬Б®јЫЎЈУР№ШХвЦЦ±ЯЅзµДТ»ёцАэЧУКЗТ»ёцЅцНЁ№эТмІЅПыПўУлУ¦УГіМРтµДЖдЛыІї·ЦЅшРРНЁРЕµДДЈїйЎЈЅ«ёГДЈїйЧЄ±дОЄОў·юОсПа¶Ф±ИЅПБ®јЫєНјтµҐЎЈ
7.4.2ЎўИзєОМбИЎДЈїй
МбИЎДЈїйµДµЪТ»ІЅКЗФЪДЈїйєНµҐМеЦ®јд¶ЁТеТ»ёцґЦБЈ¶ИµДЅУїЪЎЈТтОЄµҐМеРиТЄ·юОсУµУРµДКэѕЭЈ¬ЛьєЬїЙДЬКЗТ»ёцЛ«Пт
APIЈ¬·ґЦ®ТаИ»ЎЈУЙУЪДЈїйєНУ¦УГіМРтµДЖдУаЦ®јдґжФЪЧЕёґФУµДТААµ№ШПµєНПёБЈ¶ИµДЅ»»ҐДЈКЅЈ¬ТтґЛКµПЦХвСщµД
API НЁіЈґжФЪМфХЅЎЈУЙУЪБмУтДЈРНАаЦ®јдµДЦЪ¶а№ШБЄЈ¬К№УГБмУтДЈРНДЈКЅАґКµПЦµДТµОсВЯјУИЖдѕЯУРМфХЅРФЎЈДъНЁіЈРиТЄЅшРРЦШґуµДґъВлёьёДІЕДЬґтЖЖХвР©ТААµЎЈНј
7-3 Х№КѕБЛЦШ№№ЎЈ
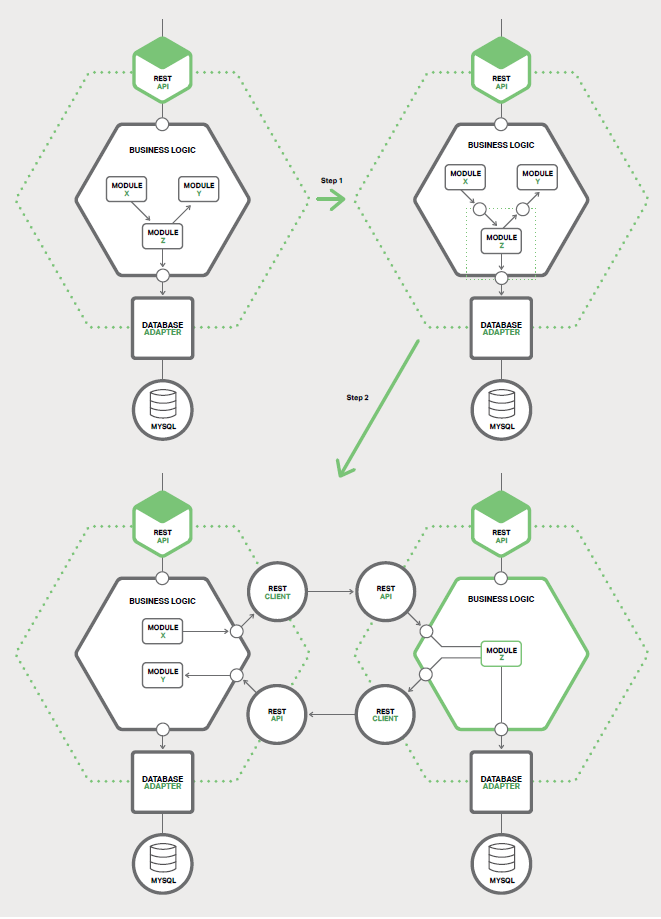
Т»µ©КµПЦБЛґЦБЈ¶ИµДЅУїЪЈ¬ДъѕНїЙТФЅ«ДЈїй±діЙ¶АБўµД·юОсЎЈТЄЧцµЅХвµгЈ¬Дъ±ШРл±аРґґъВлТФК№µҐМеєН·юОсНЁ№эК№УГЅшіМјдНЁРЕЈЁIPCЈ©»ъЦЖµД
API ЅшРРНЁРЕЎЈНј 7-3 ПФКѕБЛЦШ№№З°ЎўЦШ№№ЦРєНЦШ№№єуµДјЬ№№ЎЈ
ФЪґЛАэЦРЈ¬ДЈїй Z КЗТЄМбИЎµДєтСЎДЈїйЎЈЖдЧйјюУЙДЈїй X К№УГЈ¬ІўЗТЛьК№УГБЛДЈїй YЎЈµЪТ»ёцЦШ№№ІЅЦиКЗ¶ЁТеТ»¶ФґЦБЈ¶ИµД
APIЎЈµЪТ»ёцЅУїЪКЗТ»ёцК№УГДЈїй X АґµчУГДЈїй Z µДИлХѕЅУїЪЎЈµЪ¶юёцЅУїЪКЗТ»ёцК№УГДЈїй Z µчУГДЈїй
Y µДіцХѕЅУїЪЎЈ
µЪ¶юёцЦШ№№ІЅЦиКЗЅ«ДЈїйЧЄ»»ОЄТ»ёц¶АБў·юОсЎЈИлХѕєНіцХѕЅУїЪК№УГ IPC »ъЦЖµДґъВлАґКµПЦЎЈДъЅ«єЬїЙДЬРиТЄНЁ№эЅ«
Module Z Ул Microservice Chassis їтјЬПаЅбєПАґ№№ЅЁ·юОсЈ¬ёГїтјЬёєФрґ¦АнЦоИз·юОс·ўПЦЦ®АаµДєбЗРµгЎЈ
Т»µ©ДъМбИЎБЛТ»ёцДЈїйЈ¬ДъѕНїЙТФ¶АБўУЪµҐМеєНИОєОЖдЛы·юОсїЄ·ўЎўІїКрєНА©Х№ЖдЛы·юОсЎЈДъЙхЦБїЙТФґУН·їЄКјЦШРґ·юОсЎЈФЪХвЦЦЗйїцПВЈ¬ХыєП·юОсУ뵥МеµД
API ґъВліЙОЄФЪБЅёцБмУтДЈРНЦ®јдЧЄ»»µД·А»¤ІгЎЈГїґОМбИЎ·юОсК±Ј¬Дъ¶ј»біЇОў·юОс·ЅПтВхЅьТ»ІЅЎЈЛжЧЕК±јдµДНЖТЖЈ¬µҐМеЅ«ЛхРЎЈ¬ДъЅ«УµУРФЅАґФЅ¶аµДОў·юОсЎЈ
7.5ЎўЧЬЅб
Ѕ«ПЦУРУ¦УГіМРтЗЁТЖµЅОў·юОсµД№эіМКЗУ¦УГіМРтПЦґъ»ЇµДТ»ЦЦРОКЅЎЈДъІ»У¦ёГґУН·їЄКјЦШРґДъµДУ¦УГАґЗЁТЖµЅОў·юОсЎЈПа·ґЈ¬ДъУ¦ёГЅ«У¦УГіМРтЦрЅҐЦШ№№ОЄТ»ЧйОў·юОсЎЈїЙТФК№УГХвИэЦЦІЯВФЈєЅ«РВ№¦ДЬКµПЦОЄОў·юОсЈ»ґУТµОсЧйјюєНКэѕЭ·ГОКЧйјюЦР·ЦАліц±нПЦЧйјюЈ»Ѕ«µҐМеЦРµДПЦУРДЈїйЧЄ»»ОЄ·юОсЎЈЛжЧЕК±јдНЖТЖЈ¬Оў·юОсµДКэБїЅ«»бФці¤Ј¬ДъµДїЄ·ўНЕ¶УµДБй»оРФєНЛЩ¶ИТІН¬Сщ»бФцјУЎЈ
Оў·юОсКµХЅЈєУГ NGINX Хч·юµҐМе
by Floyd Smith
Из±ѕХВЛщКцЈ¬Ѕ«µҐМеЧЄ»»ОЄОў·юОсїЙДЬКЗТ»ёц»єВэ¶шѕЯУРМфХЅРФµД№эіМЈ¬µ«ХвН¬СщѕЯУРРн¶аєГґ¦ЎЈК№УГ NGINXЈ¬ДъїЙТФФЪКµјКїЄКјЧЄ»»№эіМЦ®З°»сµГОў·юОсЖчµДТ»Р©УЕКЖЎЈ
ДъїЙТФНЁ№эЅ« NGINX ·ЕФЪДъПЦУРµДµҐМеУ¦УГЦ®З°Ј¬ТФЅЪКЎЗЁТЖОў·юОсЛщ»Ё·СµДґуБїК±јдЎЈТФПВјтТЄЛµГчУлОў·юОсУР№ШµДєГґ¦Јє
ёьєГµШЦ§іЦОў·юОс
ИзµЪОеХВОІАёЛщКцЈ¬NGINX єН NGINX Plus ѕЯУРАыУЪїЄ·ў»щУЪОў·юОсµДУ¦УГµД№¦ДЬЎЈµ±ДъїЄКјЦШРВЙијЖµҐМеУ¦УГК±Ј¬УЙУЪ
NGINX µД№¦ДЬЈ¬ДъµДОў·юОсЅ«ЦґРеøьєГЎўёьТЧУЪ№ЬАнЎЈ
їз»·ѕіµД№¦ДЬійПу
ґУДъ№ЬАнµД·юОсЖчЙхЦБКЗёчЦЦ№«№ІФЖЎўЛЅУРФЖєН»мєПФЖЙПЅ«№¦ДЬЗЁТЖµЅ NGINX ЧчОЄ·ґПтґъАн·юОсЖчїЙТФјхЙЩІїКрФЪРВ»·ѕіЦРµДЙиК©КэБї±д»ЇЎЈХвІ№ідА©Х№БЛОў·юОсЛщ№МУРµДБй»оРФЎЈ
NGINX Оў·юОсІОїјјЬ№№їЙУГРФ
µ±ДъЗЁТЖµЅ NGINX К±Ј¬ДъїЙТФЅијш NGINX Оў·юОсІОїјјЬ№№ЈЁMRAЈ¬Microservices
Reference ArchitectureЈ©Ј¬ТФ±гФЪЗЁТЖµЅОў·юОсЦ®єу¶ЁТеУ¦УГіМРтµДЧоЦХЅб№№Ј¬ІўёщѕЭРиТЄК№УГµД
MRA Ії·ЦУ¦УГУЪДъґґЅЁµДГїёцРВµДОў·юОсЎЈ
ЧЬ¶шСФЦ®Ј¬КµПЦК№УГ NGINX ЧчОЄДъЧЄРНµДµЪТ»ІЅЈ¬С№µ№ДъµДµҐМеУ¦УГіМРтЈ¬К№ЖдёьИЭТЧ»сµГОў·юОсµДЛщУРУЕКЖЈ¬ІўОЄДъМṩУГУЪЅшРРЧЄ»»µДДЈРНЎЈДъїЙТФБЛЅвУР№Ш
MRA µДёь¶аРЕПўЈ¬Іў»сµГ NGINX Plus µДГв·СКФУГ°жЎЈ |






