ORACLE��˾��86���Ƴ��汾5��ʼ,ϵͳ���зֲ����ݿ������.88���Ƴ��汾6,ORACLE RDBMS(V6.0)�ɴ�������ѡ��(TPO),��������������ٶ�.1992���Ƴ��˰汾7,��ORACLE
RDBMS�пɴ��������ݿ�ѡ��(procedural database option)�Ͳ��з�����ѡ�parallel
server option��,��ΪORACLE7���ݿ����ϵͳ�����ͷ��˿��ŵĹ�ϵ��ϵͳ������DZ����ORACLE7��Эͬ���������ṩ����һ�����ɵ������������ڿ���������������ʵ�ָ������ʡ��������������ͻ�/�������ṹ��Ӧ��ϵͳ��Эͬ�����������п���ֲ�ԣ�֧�ֶ���������Դ������ͼ���û����漰��ý�塢���������ԡ�CASE��ЭͬӦ��ϵͳ��
һ. ORACLEϵͳ
1�� ORACLE��Ʒ�ṹ�����
ORACLEϵͳ������RDBMSΪ���ĵ�һ��������Ʒ���ɣ����Ʒ�ṹ������ͼ��ʾ��
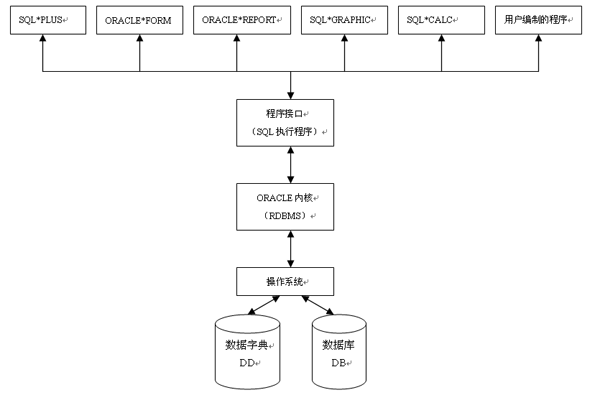
2�� ORACLEϵͳ�ص�
ORACLE��˾��1979�꣬�����Ƴ�����SQL���Ĺ�ϵ���ݿ��Ʒ������100����Ӳ��ƽ̨�����У�������������վ��С�ͻ������ͻ��ʹ��ͻ�����֧�ֺܶ��ֲ���ϵͳ���û���ORACLEӦ�ÿɷ���ش�һ�ּ��������������һ�ּ���������ϡ�ORACLE�ķֲ�ʽ�ṹ�ɽ����ݺ�Ӧ��פ���ڶ�̨������ϣ�������ͨ�������ġ�1992��6��ORACLE��˾�Ƴ���ORACLE7Эͬ���������ݿ⣬ʹ��ϵ���ݿ⼼����������̨�ס�����IDG���������ݼ��ţ�1992��ȫ��UNIX���ݿ��г����棬ORACLEռ�г�������50%����֮���Ա����û�ϲ������Ϊ��������ͻ�����ص㣺
�� ֧�ִ����ݿ⡢���û��ĸ����ܵ���������ORACLE֧��������ݿ⣬���С�ɵ�����ǧ�ף��ɳ������Ӳ���豸��֧�ִ����û�ͬʱ��ͬһ������ִ�и�������Ӧ�ã���ʹ����������С����֤����һ���ԡ�ϵͳά�����иߵ����ܣ�ORACLEÿ�������24Сʱ������������ϵͳ���������������ϵͳ���ϣ������ж����ݿ��ʹ�á��ɿ������ݿ����ݵĿ����ԣ��������ݿ⼶���������ݿ⼶�Ͽ��ơ�
�� ORACLE�������ݴ�ȡ���ԡ�����ϵͳ���û��ӿں�����ͨ��Э��Ĺ�ҵ������������һ������ϵͳ���������û���Ͷ�ʡ����������ͼ����о�����NIST����ORACLE7
SERVER���м��飬100%����ANSI/ISO SQL89���Ķ�������ݡ�
�� ʵʩ��ȫ�Կ��ƺ������Կ��ơ�ORACLEΪ���Ƹ�������ݴ�ȡ�ṩϵͳ�ɿ��İ�ȫ�ԡ�ORACLEʵʩ���������ԣ�Ϊ�ɽ��ܵ�����ָ������
�� ֧�ֲַ�ʽ���ݿ�ͷֲ�������ORACLEΪ�˳�����ü����ϵͳ�����磬������������Ϊ���ݿ�������Ϳͻ�Ӧ�ó������й��������ݹ��������ݿ����ϵͳ�ļ�������������������ݿ�Ӧ�õĹ���վ�����ڽ��ͺ���ʾ���ݡ�ͨ���������ӵļ����������ORACLE������ڶ�̨������ϵ�������ϳ�һ�������ݿ⣬�ɱ�ȫ�������û���ȡ���ֲ�ʽϵͳ����ʽ���ݿ�һ���������Ժ�����һ���ԡ�
�� ���п���ֲ�ԡ��ɼ����ԺͿ������ԡ�����ORACLE�����������ͬ�IJ���ϵͳ�����У�����ORACLE����������Ӧ�ÿ���ֲ���κβ���ϵͳ��ֻ������Ļ����ġ�ORACLE����ͬ��ҵ������ݣ��������ҵ���IJ���ϵͳ��������Ӧ��ϵͳ�����κβ���ϵͳ�����С�����������ָORALCE������ͬ���͵ļ�����Ͳ���ϵͳͨ������ɹ�����Ϣ��
��. ORACLE���ݿ�ϵͳ����ϵ�ṹ
ORACLE���ݿ�ϵͳΪ���й���ORACLE���ݿ�ܵļ����ϵͳ��ÿһ�����е�ORACLE���ݿ���һ��ORACLEʵ����INSTANCE������ϵ��һ��ORACLEʵ��Ϊ��ȡ�Ϳ���һ���ݿ���������ơ�ÿһ�������ݿ������������һ���ݿ�ʱ����Ϊϵͳȫ������SYSTEM
GLOBAL AREA����һ�ڴ��������SGA�������䣬��һ������ORACLE���̱���������SGA �� ORACLE���̵Ľ�ϳ�Ϊһ��ORACLE���ݿ�ʵ����һ��ʵ����SGA�ͽ���Ϊ�������ݿ����ݡ�Ϊ�����ݿ�һ�������û������������
��ORACLEϵͳ�У�������ʵ��������Ȼ����ʵ��װ�䣨MOUNT��һ���ݿ⡣�������ϵͳ�У��ھ���ORACLE PARALLEL
SERVER ѡ��ʱ���������ݿ�ɱ����ʵ��װ�䣬�����ʵ������ͬһ�������ݿ⡣
1�� ORACLEʵ���Ľ��̽ṹ���ڴ�ṹ
1�� ���̽ṹ
�����Dz���ϵͳ�е�һ�ֻ��ƣ�����ִ��һϵ�еIJ�����������Щ����ϵͳ��ʹ����ҵ(JOB)������(TASK)�����һ������ͨ�������Լ���ר�ô洢����ORACLE���̵���ϵ�ṹ���ʹ�������
ORACLEʵ�����������ͣ�������ʵ���Ͷ����ʵ����
������ORACLE���ֳƵ��û�ORACLE����һ�����ݿ�ϵͳ��һ������ִ��ȫ��ORACLE���롣����ORACLE���ֺͿͻ�Ӧ�ó����ֱܷ��Խ���ִ�У�����ORACLE�Ĵ�����û������ݿ�Ӧ���ǵ�������ִ�С�
�ڵ����̻����µ�ORACLE ʵ����������һ���û��ɴ�ȡ��������MS-DOS������ORACLE ��
�����ORACLEʵ�����ֳƶ��û�ORACLE��ʹ�ö��������ִ��ORACLE�IJ�ͬ���֣�����ÿһ�����ӵ��û�����һ�����̡�
�ڶ����ϵͳ�У����̷�Ϊ���ࣺ�û����̺�ORACLE���̡���һ�û�����һӦ�ó�����PRO*C�����һ��ORACLE���ߣ���SQL*PLUS����Ϊ�û����е�Ӧ�ý���һ���û����̡�ORACLE�����ַ�Ϊ���ࣺ���������̺ͺ�̨���̷������������ڴ������ӵ���ʵ�����û����̵�����Ӧ�ú�ORACELE����ͬһ̨���������У�������ͨ�����磬һ�㽫�û����̺�����Ӧ�ķ�����������ϳɵ����Ľ��̣��ɽ���ϵͳ������Ȼ������Ӧ�ú�ORACLE�����ڲ�ͬ�Ļ�����ʱ���û����̾���һ�����������������ORACLEͨ�š�����ִ����������
���Ӧ����������SQL�������������ִ�С�
��Ӵ��̣������ļ����ж����Ҫ�����ݿ鵽SGA�Ĺ������ݿ�������ÿ鲻�ڻ�����ʱ����
������ظ�Ӧ�ó�������
ϵͳΪ��ʹ������ú�Э������û����ڶ����ϵͳ��ʹ��һЩ���ӽ��̣���Ϊ��̨���̡����������ϵͳ�У���̨��������ʵ������ʱ�Զ��ؽ�����һ��ORACLEʵ�������������̨���̣������Dz���һֱ���ڡ���̨���̵�����Ϊ��
DBWR ���ݿ�д�����
LGWR ��־д�����
CKPT ����
SMON ϵͳ���
PMON ���̼��
ARCH �鵵
RECO �ָ�
LCKn ����
Dnnn ���Ƚ���
Snnn ������
ÿ����̨������ORACLE���ݿ�IJ�ͬ���ֽ�����
����Ժ�̨���̵Ĺ��������ܣ�
DBWR���̣��ý���ִ�н�������д�������ļ����Ǹ���洢��������һ��ORACLE��̨���̡����������е�һ���������ģ�������־Ϊ��Ū�ࡱ��DBWR����Ҫ�����ǽ���Ū�ࡱ�Ļ�����д����̣�ʹ���������֡��ɾ��������ڻ���洢���Ļ������������ݿ���û�����Ū�࣬δ�õĻ���������Ŀ���١���δ�õĻ������½������٣������û�����Ҫ�Ӵ��̶���鵽�ڴ�洢��ʱ���ҵ�δ�õĻ�����ʱ��DBWR����������洢����ʹ�û������ܿɵõ�δ�õĻ�������
ORACLE����LRU��LEAST RECENTLY USED���㷨���������ʹ���㷨�������ڴ��е����ݿ������ʹ�õģ�ʹI/O��С�����������ԤʾDBWR
Ҫ��Ū��Ļ�����д����̣�
�� ��һ�����������̽�һ���������롰Ū�ࡱ������Ū����ﵽ�ٽ糤��ʱ���÷�����̽�֪ͨDBWR����д�����ٽ糤����Ϊ����DB-BLOCK-WRITE-BATCH��ֵ��һ�롣
�� ��һ��������������LRU���в���DB-BLOCK-MAX-SCAN-CNT������ʱ��û�в鵽δ�õĻ���������ֹͣ���Ҳ�֪ͨDBWR����д��
�� ���ֳ�ʱ��ÿ��3�룩��DBWR ��֪ͨ������
�� �����ּ���ʱ��LGWR��֪ͨDBWR
��ǰ��������£�DBWR��Ū����еĿ�д����̣�ÿ�ο�д�Ŀ����ɳ�ʼ������DB-BLOCK-WRITE-BATCH��ָ�������Ū�����û�иò���ָ�������Ļ�������DBWR��LUR���в�������һ��Ū�������
���DBWR��������δ�������ֳ�ʱ�������������DBWR��LRU������ָ����Ŀ�Ļ������������ҵ��κ�Ū�����д����̡�ÿ�����ֳ�ʱ��DBWR����һ���µĻ������顣ÿ����DBWR���ҵĻ���������Ŀ��Ϊ������DB-BLOCK-WRITE-BATCH��ֵ�Ķ�����������ݿ����ת��DBWR���ս�ȫ���������洢��д����̡�
�ڳ��ּ���ʱ��LGWRָ��һ�Ļ�����������д�뵽���̡�DBWR��ָ���Ļ�����д����̡�
����Щƽ̨�ϣ�һ��ʵ�����ж��DBWR����������ʵ���У�һЩ���д��һ���̣���һЩ���д���������̡�����DB-WRITERS����DBWR���̸�����
LGWR���̣��ý��̽���־������д������ϵ�һ����־�ļ������Ǹ��������־��������һ��ORACLE��̨���̡�LGWR���̽����ϴ�д�����������ȫ����־�������LGWR�����
���û������ύһ����ʱд��һ���ύ��¼��
�� ÿ���뽫��־�����������
�� ����־��������1/3����ʱ����־�����������
��DBWR���Ļ�����д�����ʱ����־�����������
LGWR����ͬ����д�뵽��ľ���������־�ļ��顣�������һ���ļ���ɾ�����ã�LGWR �ɼ�����д�����������ļ���
��־��������һ��ѭ������������LGWR����־����������־��д����־�ļ����������̿ɽ��µ���־��д�뵽����־��������LGWR
ͨ��д�úܿ죬��ȷ����־���������пռ��д���µ���־�
ע�⣺��ʱ����Ҫ�������־������ʱ��LWGR��һ�������ύǰ�ͽ���־��д��������Щ��־��������Ժ������ύ������û���
ORACLEʹ�ÿ����ύ���ƣ����û�����COMMIT���ʱ��һ��COMMIT��¼����������־������������Ӧ�����ݻ������ı��DZ��ӳ٣�ֱ���ڸ���Чʱ�Ž�����д�������ļ�����һ�����ύʱ��������һ��ϵͳ�ĺţ�SCN������ͬ������־��һ���¼����־�С�����SCN��¼����־�У������ڲ��з�����ѡ����������£��ָ���������ͬ����
CKPT���̣��ý����ڼ������ʱ����ȫ�������ļ��ı�������ģ�ָʾ�ü��㡣��ͨ��������£���������LGWRִ�С�Ȼ��������������Եؽ���ϵͳ����ʱ����ʹCKPT�������У���ԭ����LGWR����ִ�еļ���Ĺ��������������CKPT����ʵ�֡���������Ӧ�������CKPT�����Dz���Ҫ�ġ�ֻ�е����ݿ������������ļ���LGWR�ڼ���ʱ���Եؽ������ܲ�ʹCKPT���С�CKPT���̲�����д����̣��ù�������DBWR��ɵġ�
��ʼ������CHECKPOINT-PROCESS����CKPT���̵�ʹ�ܻ�ʹ���ܡ�ȱʡʱΪFALSE����Ϊʹ���ܡ�
SMON���̣��ý���ʵ������ʱִ��ʵ���ָ�����������������ʹ�õ���ʱ�Ρ��ھ��в��з�����ѡ��Ļ����£�SMON���й���CPU��ʵ������ʵ���ָ���SMON�����й��ɵر����ѣ�����Ƿ���Ҫ�������������̷�����Ҫʱ���Ա����á�
PMON���̣��ý������û����̳��ֹ���ʱִ�н��ָ̻������������ڴ洢�����ͷŸý�����ʹ�õ���Դ��������Ҫ���û�������״̬���ͷŷ��������ù��ϵĽ��̵�ID�ӻ���̱�����ȥ��PMON�����ڵؼ����Ƚ��̣�DISPATCHER���ͷ��������̵�״̬���������������������������������ɾ���Ľ��̣���
PMON�й��ɵر����ѣ�����Ƿ���Ҫ�������������̷�����Ҫʱ���Ա����á�
RECO���̣��ý������ھ��зֲ�ʽѡ��ʱ��ʹ�õ�һ�����̣��Զ��ؽ���ڷֲ�ʽ�����еĹ��ϡ�һ�����RECO��̨�����Զ������ӵ�����������δ���ķֲ�ʽ������������ݿ��У�RECO�Զ��ؽ�����е����������������κ���Ӧ���Ѵ���������������������н���ÿһ�����ݿ�������������ɾȥ��
��һ���ݿ��������RECO��̨������ͼ����ͬһԶ�̷�������ͨ�ţ����Զ�̷������Dz����û����������Ӳ��ܽ���ʱ��RECO�Զ�����һ��ʱ����֮���ٴ����ӡ�
RECO��̨���̽����������ֲ�ʽ�����ϵͳ�г��֣�����DISTRIBUTED �C TRANSACTIONS�����Ǵ���0��
ARCH���̣��ý��̽���������������־�ļ�������ָ���Ĵ洢�豸������־��ΪARCHIVELOGʹ�÷�ʽ�������Զ��ع鵵ʱARCH���̲Ŵ��ڡ�
LCKn���̣����ھ��в��з�����ѡ��������ʹ�ã��ɶ���10�����̣�LCK0��LCK1������LCK9��������ʵ����ķ���
Dnnn���̣����Ƚ��̣����ý��������û����̹������ķ��������̣�SERVER PROCESS����û�е��Ƚ���ʱ��ÿ���û�������Ҫһ��ר�÷�����̣�DEDICATEDSERVER
PROCESS�������ڶ�������������MULTI-THREADED SERVER����֧�ֶ���û����̡������ϵͳ�о��д����û�����������������֧�ִ����û��������ڿͻ�_�����������С�
��һ�����ݿ�ʵ���пɽ���������Ƚ��̡���ÿ������Э�����ٽ���һ�����Ƚ��̡����ݿ����Ա���ݲ���ϵͳ��ÿ�����̿�������Ŀ�����ƾ��������ĵ��ȳ��������������ʵ������ʱ�����ӻ�ɾ�����Ƚ��̡���������������ҪSQL*NET�汾2�����İ汾���ڶ������������������£�һ��������������̵ȴ��ͻ�Ӧ������������ÿһ�����͵�һ�����Ƚ��̡�������ܽ��ͻ�Ӧ�����ӵ�һ���Ƚ���ʱ��������������̽�����һ��ר�÷��������̡���������������̲���ORACLEʵ������ɲ��֣����Ǵ�����ORACLE�йص�������̵���ɲ��֡���ʵ������ʱ�����������������Ϊ�û����ӵ�ORACLE����һͨ��·����Ȼ��ÿһ�����Ƚ��̰���������ĵ��Ƚ��̵ĵ�ַ���������Ľ���������һ���û���������������ʱ��������������̷������������û��Ƿ��ʹ��һ���Ƚ��̡�����ǣ���������������̷��ظõ��Ƚ��̵ĵ�ַ��֮���û�����ֱ�����ӵ��õ��Ƚ��̡���Щ�û����̲��ܵ��Ƚ���ͨ�ţ����ʹ��SQL*NET��ǰ�İ汾���û�����������������̲��ܽ�����û����ӵ�һ���Ƚ��̡�����������£��������������һ��ר�÷��������̣�����һ�ֺ��ʵ����ӡ�
2����ORACLE�ڴ�ṹ
ORACLE���ڴ�洢������Ϣ��
��ִ�еij�����롣
�����ӵĻỰ��Ϣ
�����ִ���ڼ��������ݺ�������Ϣ
��洢����洢�ϵĻ�����Ϣ��
ORACLE�������л������ڴ�ṹ��
������������
��ϵͳȫ����,�������ݿ��洢������־������������.
�����ȫ����,����ջ����������.
�� ������
����������
���ڴ洢����ִ�еĻ����ִ�еij�����롣
��������ֻ�����ɰ�װ�ɹ�����ǹ�����ORACLEϵͳ�����ǿɹ����ģ����¶��ORACLE�û��ɴ�ȡ����������Ҫ���ڴ��ж���������û�������Թ���Ҳ���Բ�������
ϵͳȫ����
Ϊһ����ORACLE����Ĺ������ڴ�ṹ���ɰ���һ�����ݿ�ʵ�������ݻ������Ϣ���������û�ͬʱ���ӵ�ͬһʵ��ʱ����ʵ����SGA�����ݿ�Ϊ����û��������������ֳ�Ϊ����ȫ��������ʵ����ʱ��SGA�Ĵ洢�Զ��ر����䣻��ʵ���ر�ʱ���ô洢�����ա��������ӵ���������ݿ�ʵ����ȫ���û����Զ��ر����䣻��ʵ���ر�ʱ���ô洢�����ա��������ӵ���������ݿ�ʵ����ȫ���û���ʹ����SGA�е���Ϣ���������м������̿�д����Ϣ����SGA�д洢��Ϣ���ڴ滮�ֳɼ����������ݿ��洢������־�������������ء��������Ӧ���С������ֵ�洢��������������Ϣ��
����ȫ����
PGA��һ���ڴ����������������̵����ݺͿ�����Ϣ�������ֳ�Ϊ����ȫ������PROCESS GLOBAL AREA����
������
������Ҫ�ڴ�ռ䣬ORACLE���ø��ڴ��������ݣ��ⲿ�ֿռ��Ϊ������������������������������û����̵��ڴ��У��ÿռ�Ĵ�СΪ�ʾ������������Ĵ�С�������������ܳ�ʼ������SORT-AREA-SIZER�����ơ�
2�� ORACLE�����÷���
�������ӵ�ORACLE���û�����ִ����������ģ��ɴ�ȡһ��ORACLE���ݿ�ʵ����
�� Ӧ�û�ORACLE���ߣ�һ���ݿ��û�ִ��һ���ݿ�Ӧ�û�һ��ORACLE���ߣ�����ORACLE���ݿⷢ��SQL��䡣
��ORACLE��������������ͺʹ���Ӧ���е�SQL��䡣
�ڶ����ʵ���У������û��Ĵ���ɰ��������ַ���֮һ���ã�
�� ����ÿһ���û��������ݿ�Ӧ�ó���ͷ�����������ϳɵ����û�����
�� ����ÿһ���û��������ݿ�Ӧ�������û����������У�����һ��ר�÷��������̡�ִ��ORACLE�������Ĵ��롣���������ó�Ϊר�÷�������ϵ�ṹ
��ִ�����ݿ�Ӧ�õĽ��̲�ͬ��ִ��ORACLE����������Ľ��̣�����ÿһ�����������̣�ִ��ORACLE���������룩�ɷ����ڶ���û����̣����������ó�Ϊ��������������ϵ�ṹ��
1) USER/SERVER�������ϵĽṹ
�����������£����ݿ�Ӧ�ú�ORACLE��������������ͬһ�����������У��ý��̳�Ϊ�û����̡�
����ORACLE������ʱ��Ϊ������ORACLE��single_task ORACLE���������������������IJ���ϵͳ��������ͬһ�����е����ݿ�Ӧ�ú�ORACLE����֮��ά��һ�����룬�ø�����Ϊ���ݰ�ȫ�Ժ����������衣���г���ӿڣ�program
interface���Ǹ���ORACLE����������ĸ���ͱ����������ݿ�Ӧ�ú�ORACLE�û�����֮�䴫�����ݡ�
2) ʹ��ר�÷��������̵�ϵͳ�ṹ
ʹ��ר�÷��������̵�ORACLEϵͳ����̨����������С�������ϵͳ�У���һ��������û�����ִ�����ݿ�Ӧ�ã�������һ̨������ϵķ���������ִ����Ӧ��ORACLE���������룬�����������Ƿ���ġ�Ϊÿ���û����̽����IJ�ͬ�ķ��������̳�Ϊר�÷��������̣���Ϊ�÷��������̽����������û����������á����������ֳ�Ϊ������ORACLE��ÿһ�����ӵ�ORACLE���û�������һ����Ӧ��ר�÷�����̡�����ϵͳ�ṹ�����ͻ�Ӧ�����й���վ��ִ�У�ͨ������������ORACLE�ļ����ͨ�š����ͻ�Ӧ�ú�ORACLE��������������ͬһ̨�������ִ��ʱ�����ֽṹҲ���á�
3) ��������������ϵͳ�ṹ
�������������������������û����̹������ٷ��������̡���û�ж������������������У�ÿһ���û�������Ҫ�Լ���ר�÷��������̡��ھ��ж������������������У������û��������ӵ����Ƚ��̣��ɵ��Ƚ��̽��ͻ������͵�һ���������������̡����������������õ��ŵ��ǽ���ϵͳ�����������û�������
��ϵͳ����Ҫ�������͵Ľ��̣�
�� ������������̣����û��������ӵ����Ƚ��̺�ר�÷��������̡�
��һ���������Ƚ���
��һ��������������������
����������������̵ȴ�����������������ÿһ�û������ܷ��ù������������̡��������ʹ�ã����������̽�һ���Ƚ��̵ĵ�ַ���ظ��û����̡�����û���������һר�÷��������ý��������̽�����һ��ר�÷��������̣����û��������ӵ���ר�÷��������̡��������ݿ�ͻ�����ʹ�õ�ÿ������Э����������һ�����Ƚ��̣�����������
���û���һ�ε���ʱ�����Ƚ��̽����������SGA����������У��ɿ��õĹ������������̻�ȡ����������������Ϊ���ÿһ���û����̵����������б�Ҫ�����ݿ���á����������������ʱ����������ص����Ƚ��̵Ķ��У�Ȼ���ɵ��Ƚ��̽���ɵ����ظ��û����̡�
�������������̣����������������̲�������ָ�����û������⣬�������������̺�ר�÷����������ṩ��ͬ�Ĺ��ܣ�һ�����������������ڶ������������������п�Ϊ�κοͻ��������һ���������������̵�SGA�����������û���ص����ݣ�����Ϣ��Ϊ���й������������̴�ȡ����������ջ�ռ䡢����ָ��������������Ự�йص���Ϣ�ǰ�����SGA�С�ÿһ���������������̿ɴ�ȡȫ���Ự�����ݿռ䣬�����κη�����̿ɴ����κλỰ��������ÿһ���Ự�����ݿռ�����SGA�з���ռ䡣
ORACLE����������еij��ȿɶ�̬�ص����������������̡��ɽ����Ĺ������������̽�����ŵ�������С�һ���û������Ƕ����ݿ��һ�γ���ӿڵ��ã�ΪSQL��䡣��SGA��������ж�ʵ����ȫ�����Ƚ����ǹ��õġ�����������Ϊ�������鹫��������У����Ƚ��ȳ���ԭ��Ӷ��м��һ������Ȼ��Ϊ��ɸ���������ݿ�����Ҫ�ĵ��á��������������̽���Ӧ���ڵ��Ƚ��̵���Ӧ���С�ÿһ�����Ƚ�����SGA�����Լ�����Ӧ���У�ÿ�����Ƚ��̸�����ɵ����������Ӧ���û����̡�
3.ORACLE����
1) ʹ��ר�÷�����̵�ORACLE������
�����������£�ORACLE���й������£�
��1�� ���ݿ�������������ǰ��������ORACLE����̨���̣���
��2�� ��һ�ͻ�����վ����һ�����ݿ�Ӧ�ã�Ϊ�û����̣�����SQL*PLUS���ͻ�Ӧ��ʹ��SQL*NET DRIVER�����Է����������ӡ�
��3�� ���ݿ�������������ǰ�����к��ʵ�SQL*NET DRIVER���û��Ͻ��������̼���ͻ����ݿ�Ӧ�õ����������ڸû���Ϊ�û����̽���ר�÷��������̡�
��4�� �û���������SQL��䡣
��5�� ר�÷��������̽��ո���䣬�ڴ˴������ַ�������SQL��䣺
������ڹ�����һ����SQL���а�������ͬSQL���ʱ���÷��������̿������Ѵ��ڵĹ���SQL��ִ�пͻ���SQL��䡣
������ڹ�������û��һ��SQL����������ͬ��SQL���ʱ���ڹ�������Ϊ��������һ�µĹ���SQL����
��ÿһ��������ڻỰ��PGA�н���һ��ר��SQL����ר�÷��������̼���û��Բ�ѯ���ݵĴ�ȡȨ�ޡ�
(6) �����Ҫ�����������̴������ļ��м������ݿ飬���߿�ʹ���Ѵ洢��ʵ��SGA�еĻ���洢�������ݿ顣
(7) ����������ִ�д洢�ڹ���SQL���е�SQL��䡣����������SGA���ģ���DBWR����������Чʱ����д����̡�LGWR������������־�ļ��м�¼�û��ύ���������
��8���������ɹ�����������ͨ�����緢��һ��Ϣ��������ɹ�����������Ӧ�Ĵ�����Ϣ��
��9�������������У������ĺ�̨���������еģ�ͬʱע����Ҫ��Ԥ�����������⣬ORACLE������������ֹ��ͬ����֮������ͬһ���ݵľ�����
2) ʹ�ö�������������ORACLE������
�����������£�ORACLE���й������£�
��1�� һ���ݿ���������������ʹ�ö��������������õ�ORACLE��
��2�� ��һ�ͻ�����վ����һ���ݿ�Ӧ�ã���һ�û������У����ͻ�Ӧ�ú��ʵ�SQL*NET��������ͼ���������ݿ����������������ӡ�
��3�� ���ݿ�������������ǰ���к��ʵ�SQL*NET������������������������̼���û����̵��������������û�����������ӡ�����û���ʹ��SQL*NET�汾2�������������֪ͨ�û�����ʹ��һ�����õĵ��Ƚ��̵ĵ�ַ�������ӡ�
��4�� �û���������SQL���
��5�� ���Ƚ��̽��û����̵��������������У��ö���λ��SGA�У���Ϊ���е��Ƚ��̹�����
��6�� һ�����ù������������鹫�õ��Ƚ���������У����Ӷ����м����һ��SQL��䡣Ȼ������SQL��䣬ͬǰһ��5������6���ͣ�7����ע�⣺�Ự��ר��SQL���ǽ�����SGA�С�
��7�� һ�������������������SQL�������ý��̽�������÷��������ĵ��Ƚ��̵���Ӧ���С�
��8�� ���Ƚ��̼��������Ӧ���У�������ɵ������ͻ�������û����̡�
4.���ݿ�ṹ�Ϳռ����
һ��ORACLE���ݿ������ݵļ��ϣ���������һ����λ��һ��ORACLE���ݿ���һ�������ṹ��һ�����ṹ��
�������ݿ�ṹ��physical database structure�����ɹ������ݿ�IJ���ϵͳ�ļ���������ÿһ��ORACLE���ݿ������������͵��ļ���ɣ������ļ�����־�ļ��Ϳ����ļ������ݿ���ļ�Ϊ���ݿ���Ϣ�ṩ�����������洢��
�����ݿ�ṹ���û����漰�����ݿ�ṹ��һ��ORACLE���ݿ�����ṹ���������ؾ�����
�� һ���������ռ�
�����ݿ�ģʽ����������ͼ���������ۼ������С��洢���̣�
���洢�ṹ����ռ�(dataspace)����(segment)�ͷ�Χ��֧��һ�����ݿ�������ռ����ʹ�á�ģʽ����(schema
object)������֮�����ϵ�����һ�����ݿ�Ĺ�ϵ��ơ�
1�� �����ṹ
��1�� �����ļ�
ÿһ��ORACLE���ݿ���һ�����������������ļ�(data file)��һ�����ݿ�������ļ�����ȫ�����ݿ����ݡ������ݿ�ṹ(���������)�����������ش洢�����ݿ�������ļ��С������ļ�������������
��һ�������ļ�����һ�����ݿ���ϵ��
��һ�������������ļ����ܸı��С
�� һ�����ռ䣨���ݿ�洢������λ����һ�����������ļ���ɡ�
�����ļ��е���������Ҫʱ���Զ�ȡ���洢��ORACLE�ڴ洢���С����磺�û�Ҫ��ȡ���ݿ�һ����ijЩ���ݣ����������Ϣ�������ݿ���ڴ�洢���ڣ������Ӧ�������ļ��ж�ȡ���洢���ڴ档���ĺͲ���������ʱ����������д�������ļ���Ϊ�˼��ٴ��������������������ܣ����ݴ洢���ڴ棬Ȼ����ORACLE��̨����DBWR������ν���д�뵽��Ӧ�������ļ���
��2�� ��־�ļ�
ÿһ�����ݿ�������������־�ļ���redo log file�����飬ÿһ����־�ļ��������ռ����ݿ���־����־����Ҫ�����Ǽ�¼�������������ģ����Զ����ݿ�����ȫ�����Ǽ�¼����־�С��ڳ��ֹ���ʱ��������ܽ����������õ�д�������ļ������������־�õ����ģ����ԴӲ��ᶪʧ���в����ɹ���
��־�ļ���Ҫ�DZ������ݿ��Է�ֹ���ϡ�Ϊ�˷�ֹ��־�ļ������Ĺ��ϣ�ORACLE����������־(mirrored redo
log)�����¿��ڲ�ͬ������ά������������־������
��־�ļ��е���Ϣ����ϵͳ���ϻ���ʹ��ϻָ����ݿ�ʱʹ�ã���Щ������ֹ�����ݿ�����д�뵽���ݿ�������ļ���Ȼ���κζ�ʧ����������һ�����ݿ��ʱ��ORACLE�Զ���Ӧ����־�ļ��е���Ϣ���ָ����ݿ������ļ���
��3�� �����ļ�
ÿһORACLE���ݿ���һ�������ļ�(control file)������¼���ݿ�������ṹ������������Ϣ���ͣ�
�� ���ݿ�����
�� ���ݿ������ļ�����־�ļ������ֺ�λ�ã�
�� ���ݿ⽨�����ڡ�
Ϊ�˰�ȫ��������������ļ�������
ÿһ��ORACLE���ݿ��ʵ������ʱ�����Ŀ����ļ����ڱ�ʶ���ݿ����־�ļ������������ݿ����ʱ���DZ��뱻�������ݿ��������ɸ���ʱ��ORACLE�Զ����ĸ����ݿ�Ŀ����ļ������ݻָ�ʱ��ҲҪʹ�ÿ����ļ���
2�� ���ṹ
���ݿ����ṹ�������ռ䡢�Ρ���Χ(extent)�����ݿ��ģʽ����
��1�� ���ռ�
һ�����ݿ⻮��Ϊһ����������λ��������λ��Ϊ���ռ䣨TABLESPACE����һ�����ռ�ɽ���ص����ṹ�����һ��DBA�����ñ��ռ������й�����
��������ݿ����ݵĴ��̷��䡣
�� ��ȷ���Ŀռ�ݶ��������ݿ��û���
��ͨ��ʹ�������ռ��������ߣ��������ݵĿ����ԡ�
��ִ�в������ݿ��ָ�������
��Ϊ������ܣ���Խ�豸�������ݴ洢��
���ݿ⡢���ռ�������ļ�֮��Ĺ�ϵ����ͼ��ʾ��
ÿ�����ݿ��������Ϊһ���������ռ䡣
��ÿһ�����ռ�����һ�����������ļ���ɣ��ñ��ռ������ش洢���ռ���ȫ�����ṹ�����ݡ�DBA���Խ����µı��ռ䣬��Ϊ���ռ����������ļ����ɾ�������ļ������û����ȱʡ�Ķδ洢λ�á�
ÿһ��ORACLE���ݿ������һ����ΪSYSTEM�ı��ռ䣬�����ݿ⽨�����Զ��������ڸñ��ռ����ܰ������������ݿ�������ֵ������С�����ݿ��ֻ��ҪSYSTEM���ռ䡣�ñ��ռ�����������ߡ����ʹ洢��PL/SQL����Ԫ�����̺��������ʹ���������ȫ���洢�����Ǵ洢��SYSTEM���ռ��С������ЩPL/SQL������Ϊ���ݿ⽨�ģ�DBA��SYSTEM���ռ�����Ҫ�滮��Щ��������Ҫ�Ŀռ䡣
���ռ��������������ļ�������ռ䣬���ռ�Ĵ�СΪ��ɸñ��ռ�������ļ���С�ĺ͡�
DBA����ʹORACLE���ݿ����κα��ռ䣨��SYSTEM���ռ��⣩���ߣ�ONLINE�������ߣ�OFFLINE�������ռ�ͨ�������������������������ݶ����ݿ��û��ǿ��õġ������ռ�Ϊ����ʱ�������ݲ���ʹ�á�����������£�DBA����ʹ�����ߡ�
ʹ�������ݲ����ã���ʣ��IJ�������������ȡ
ִ�����ߵı��ռ��
��Ϊ���Ļ�ά��һӦ�ã�ʹ��������һ�����ʱ�����á�
���������ڻ�Ļع��εı��ռ䲻�ܱ����ߣ������ع��β�����ʹ��ʱ���ñ��ռ�ſ����ߡ�
�������ֵ��м�¼���ռ��״̬�����������ߡ���������ݿ�ر�ʱһ���ռ�Ϊ���ߣ���ô���´����ݿ�װ������´�����Ȼ�������ߡ�
������ijЩ����ʱ��һ�����ռ���Զ��������߸ı�Ϊ���ߡ�ͨ��ʹ�ö�����ռ䣬����ͬ���͵����ݷֿ���������DBA���������ݿ⡣
ORACLE���ݿ���һ���ռ�����һ���������������ļ���ɣ�һ�������ļ�ֻ����һ�����ռ�����ϵ����Ϊһ���ռ佨��һ�����ļ�ʱ��ORACLE�������ļ�������ָ���Ĵ��̿ռ��������������ļ���ʱ������������Ĵ��̲������κ����ݡ����ռ�����������ߡ���ORACLE�л��������������ļ��������ߡ�
��2�� �Ρ���Χ�����ݿ�
ORACLEͨ���Ρ���Χ�����ݿ������ݽṹ�ɸ�ϸ�ؿ��ƴ��̿ռ��ʹ�á�
��
�Σ�SEGMENT���������ռ���һ��ָ�����͵����洢�ṹ������һ�鷶Χ��ɡ���ORACLE���ݿ����м������͵ĶΣ����ݶΡ�ǣ���Ρ��ع��κ���ʱ�Ρ�
���ݶΣ�����ÿһ���Ǿۼ��ı���һ���ݶΣ������������ݴ���ڸöΡ�ÿһ�ۼ���һ�����ݶΣ��ۼ���ÿһ���������ݴ洢�ڸö��С�
�����Σ�ÿһ��������һ�����Σ��洢�������ݡ�
�ع��Σ�����DBA������������ʱ�洢Ҫ��������Ϣ����Щ��Ϣ�������ɶ�һ�������ݿ���Ϣ�������ݿ�ָ�ʱʹ�á��ع�δ�ύ������
��ʱ�Σ���һ��SQL�����Ҫ��ʱ������ʱ����ORACLE�����������ִ����ϣ���ʱ�εķ�Χ�˻ظ�ϵͳ��
ORACLE�����жεĿռ���䣬�Է�ΧΪ��λ��
��Χ
һ����Χ��EXTENT�������ݿ�洢�ռ�����һ������λ�������������ݿ�����ɡ�ÿһ��������һ��������Χ��ɡ���һ���м����пռ�����ȫʹ��ʱ��ORACLEΪ�öη���һ���µķ�Χ��
Ϊ��ά����Ŀ�ģ������ݿ��ÿһ�κ��жα���飨segment header block��˵���ε������Լ��ö��еķ�ΧĿ¼��
���ݿ�
���ݿ飨data block����ORACLE���������ļ��д洢�ռ�ĵ�λ��Ϊ���ݿ�ʹ�õ�I/O����С��λ�����С�ɲ�ͬ�ڲ���ϵͳ�ı�I/O���С��
���ݿ�ĸ�ʽ��
���õı䳤���� |
��Ŀ¼ |
��Ŀ¼ |
δ�ÿռ� |
������ |
��3�� ģʽ��ģʽ����
һ��ģʽ(schema)Ϊģʽ����(scehma object)��һ�����ϣ�ÿһ�����ݿ��û���Ӧһ��ģʽ��ģʽ����Ϊֱ���������ݿ����ݵ����ṹ��ģʽ��������������ͼ���������ۼ������С�ͬ��ʡ����ݿ��������̺Ͱ��Ƚṹ��ģʽ�����������ݴ洢�ṹ��ÿһ��ģʽ�����ڴ�����û��һ����Ӧ�ļ��洢����Ϣ��һ��ģʽ�������ش洢�����ݿ��һ�����ռ��У�ÿһ����������������ذ����ڱ��ռ��һ�����������ļ��С�
��
����table��Ϊ���ݿ������ݴ洢�Ļ�����λ�������ݰ��С��д洢��ÿ��������һ�������еļ��ϡ�ÿһ����һ���������������͡����Ȼȡ�������һ���Ƕ�Ӧ������¼������Ϣ�ļ��ϡ�
��ͼ
һ����ͼ��view)����һ������������������ͼ���е����ݵ�һ�ֶ��Ƶı�ʾ������һ����ѯ���壬���Կ���Ϊ��һ���洢�IJ�ѯ��stored
query������һ�����(virtual table)����ͼ����ʹ�ñ�������ط�ʹ�á�
������ͼ���ɱ������ģ���ͼ�ͱ������������ƣ���ͼ������ɶ���254�С���ͼ���Ա���ѯ�������ġ������ɾ��ʱ����һ�������ƣ�����ͼ��ִ�е�ȫ������������Ӱ����ͼ�Ļ������е����ݣ��ܵ���������������Լ���ʹ����������ơ�
��ͼ�����ͬ��һ����ͼ�������κδ洢�ռ䣬��ͼ�������ذ������ݡ��ɲ�ѯ�������ͼ��Ӧ����ͼ���ñ��е����ݡ���ͼֻ�������ֵ��д洢�䶨�塣
������ͼ�����кô���
��ͨ�����ƶԱ�����Ԥ���弯�ϵĴ�ȡ��Ϊ���ṩ���ӵİ�ȫ��
���������ݸ����ԡ�
��Ϊ�û�������
��Ϊ�������������ṩ��һ�ֹ۵㡣
���ɽ�Ӧ�ø���������������
�����ڲ�����ͼ����ʾ�IJ�ѯ��
�������ڱ��渴�Ӳ�ѯ��
�ۼ�
�ۼ���cluster���Ǵ洢�����ݵĿ�ѡ��ķ�����һ���ۼ���һ�����������ͬһ������ֵ���д洢��һ�𣬲������Ǿ���һ��ʹ�á���Щ�����й��ɾۼ��롣���磺EMP����DEPT������DEPTNO�У�����EMP����DEPT���ɾۼ���һ�𣬾ۼ������ΪDEPTNO�У��þۼ���ÿ�����ŵ�ȫ��ְ���и��ò��ŵ��������ش洢��ͬһ���ݿ��С�
����
����(index)������;ۼ���ص�һ��ѡ��ṹ��������Ϊ������ݼ��������ܶ��������������ɿ��ٵ�ȷ��ָ������Ϣ��ORACLE����Ϊ�������ṩ���ٴ�ȡ·��������������һ��Χ���в�ѯ��ָ���еIJ�ѯ��
�����ɽ�����һ����һ�л�����ϣ�һ����������ORACLE�Զ�ά����ʹ�ã����û�����ȫ���ġ����������غ������ض��������ݣ����ǵĽ�����ɾ���Ա�û��Ӱ�죬Ӧ�ÿɼ����������������ݵļ������ܼ������ֳ���������һ���ϴ�����������ʱ���ġ�ɾ���Ͳ�����������ܻ��½���
������Ψһ��������Ψһ������Ψһ������֤����û�������ڶ������������Ͼ����ظ�ֵ��ORACLE��Ψһ�����Զ��ض���Ψһ����ʵʩUNIQUE������Լ����
����������ڱ���ij��������������һ��������ȫ�����ɼӿ�SELECT���ļ����ٶȣ�����WHERE�Ӿ��п��������������ȫ������Ҫ����
�������ڶ����и����еĴ���������ȡ�Ļ�ѡ�������з�����λ��
�ڽ�������ʱ�����ڱ��ռ��Զ��ؽ���һ�����Σ������οռ����ͱ����ռ��ʹ�������з�ʽ���ƣ�
�����η�Χ�ķ��䳣פ�������εĴ洢�������ơ�
�����ݿ���δ�ÿռ���ܸöε�PCTFREE�������������ơ�
����������
����������(sequence generator)�������кš��ڶ��û������¸������������ر����ã������ɸ��������кŶ�����Ҫ����I/O�����������
���к�ΪORACLE������������38�����֡�һ�����ж���ָ��һ����Ϣ�����е����֡��������½������к�֮�����������Ϣ�����������е�ȷ�Ķ������д洢��SYSTEM���ռ��е������ֵ���У������������ж������ǿ��á����������кŵ�SQL���ʹ�����кţ�������һ���µ����кŻ�ʹ�õ�ǰ���кš�һ�����û��Ự�е�SQL�������һ���кţ������кŽ�Ϊ�ûỰ���á����к������Ƕ����ڱ�������ͬһ����������������һ���Ͷ���������������кſ���������Ψһ�����롣
ͬ���
һ��ͬ���(synonym)Ϊ�κα�����ͼ�����ա����С����̡���������ı������䶨��洢�������ֵ��С�ͬ�����ȫ�Ժͷ���ԭ�������ʹ�ã������ڣ�
������ζ�������ּ�������ߡ�
��Ϊ�ֲ�ʽ���ݿ��Զ�̶����ṩλ�����ԡ�
��Ϊ�û���SQL��䡣
������ͬ��ʣ����ú�ר�á�һ������ͬ���Ϊ����ΪPUBLIC�����û��������У���Ϊ���ݿ���ÿһ���û�����ȡ��һ��ר��ͬ����ǰ�����ָ���û���ģʽ�У���Ϊ���û�����Ȩ���û���ʹ�á�
�Ӵ�
�Ӵգ�hashing���Ǵ洢������һ�ֿ�ѡ��ķ��������ԸĽ����ݼ��������ܡ�Ҫʹ���Ӵգ���Ҫ�����Ӵվۼ�������װ�뵽�þۼ��������վۼ��еı��и����Ӵպ����Ľ����������ѧ�洢�ͼ������Ӵպ�����������һ����ֵ�ķֲ�������ֵ��Ϊ�Ӵ�ֵ�����ǻ���ָ���ľۼ���ֵ��
����Ԫ
����Ԫ��program unit����ָ�洢���̡������Ͱ���PACKAGE����һ�����̺ͺ���������SQL����PL/SQL��������һ��Ϊִ��ijһ�������һ����ִ�е�λ��һ�����̻����ɱ������������ݿ��д洢�������ʽ�������û������ݿ�Ӧ����ִ�С����̺ͺ�������ں����ܷ��ص���ֵ�������ߣ�������û��ֵ���ظ������ߡ�
���ṩ��صĹ��̡��������������������ṹ��װ������������һ���һ�ַ��������������ߺ�Ӧ�ÿ��������ø÷�����֯��˵ij���routine��,���ṩ����Ĺ��ܺ�������ܡ�
���ݿ���
���ݿ�����һ�������Ķ���˵����һ���ݿ��һ���ݿ��һ·����PATH�����ڷֲ�ʽ���ݿ��У���ȫ�ֶ���������ʱ�����ݿ�����ʽ��ʹ�á�
��. ���ݿ��ʵ���������ر�
һ��ORACLE���ݿ�û�б�Ҫ�������û����ǿ��ã����ݿ����Ա���������ݿ⣬���������������ݿ������£��û��ɴ�ȡ���ݿ��е���Ϣ�������ݿⲻʹ��ʱ��DBA�ɹر������رպ�����ݿ⣬�û����ܴ�ȡ����Ϣ��
���ݿ�������ر��Ƿdz���Ҫ�Ĺ������ܣ�ͨ����INTERNAL���ӵ�ORACLE����������������INTERNAL ���ӵ�ORACLE��Ҫ�������Ⱦ�������
���û��IJ���ϵͳ�˺ž���ʹ��INTERNAL���ӵIJ���ϵͳ��Ȩ��
��INTERNAL���ݿ���һ������û�֪������
���⣺���û���INTERNAL����ʱ�������ӵ�ר�÷������������ǰ�ȫ���ӡ�
1�� ���ݿ�����
�������ݿⲢʹ������������������
������һ��ʵ����
��װ�����ݿ�
������ݿ�
1�� ����һ��ʵ��
����һʵ���Ĵ�����������һ��SGA�����ݿ���Ϣʹ�õ��ڴ湲�������ͺ�̨���̵Ľ�����ʵ����ִ�����ڸ�ʵ��װ��һ���ݿ⡣���������ʵ������û�����ݿ����ڴ洢�ṹ�ͽ�������ϵ
2�� װ��һ���ݿ�
װ�����ݿ��ǽ�һ���ݿ�����������ʵ����������ʵ����װһ���ݿ�֮�����ݿⱣ�ֹرգ���DBA�ɴ�ȡ��
3�� ��һ���ݿ�
��һ���ݿ���ʹ���ݿ���Խ����������ݿ�����Ĵ�������һ���ݿ�������û������ӵ������ݿ��ô�ȡ����Ϣ�������ݿ��ʱ�����������ļ���������־�ļ�Ҳ�������һ���ռ�����һ�����ݿ�ر�ʱΪ���ߣ������ݿ��ٴδ�ʱ���ñ��ռ������������������ļ��������ߵġ�
2�� ���ݿ��ʵ���Ĺر�
�ر�һʵ���Լ��������ӵ����ݿ�Ҳ������������
1�� �ر����ݿ�
���ݿ�ֹͣ�ĵ�һ���ǹر����ݿ⡣�����ݿ�رպ�������SGA�е����ݿ����ݺͻָ�������Ӧ��д�뵽�����ĺ���־�ļ����������֮���������������ļ�����������־�ļ�Ҳ���رգ��κ����߱��ռ��������ļ������ѹرյġ������ݿ�رպ���װʱ�������ļ��Ա��ִ�
2�� ж�����ݿ�
ֹͣ���ݿ�ĵڶ����Ǵ�ʵ��ж�����ݿ⡣�����ݿ�ж�º��ڼ�����ڴ��н�����ʵ���������ݿ�ж�º����ݿ�Ŀ����ļ�Ҳ���رա�
3�� ֹͣʵ��
ֹͣ���ݿ�����һ����ֹͣʵ������ʵ��ֹͣ��SAG�Ǵ��ڴ��г�������̨���̱���ֹ��
3�� ��ʼ�������ļ�
������һ��ʵ��ʱ��ORACLE�������һ��ʼ�������ļ���initialization parameter file�����ò����ļ���һ���ı��ļ���������ʵ�����ò�������Щ�����ó�����ֵ�����ڳ�ʼORACLEʵ���������ڴ�ͽ������ã��ò����ļ�����
��һ��ʵ�������������ݿ�����
�� ��SGA�д洢�ṹʹ�ö����ڴ棻
�� ������������־�ļ�����ʲô��
�� ���ݿ�����ļ������ֺ�λ�ã�
�������ݿ���ר�ûع��ε����֡�
��. �����ֵ��ʹ��
�����ֵ���ORACLE���ݿ������Ҫ�IJ���֮һ������һ��ֻ���ı�������ͼ����ɡ����ṩ�йظ����ݿ����Ϣ�����ṩ����Ϣ���£�
�� ORACLE�û������֣�
�� ÿһ���û����ڵ���Ȩ�ͽ�ɫ��
��ģʽ��������֣�������ͼ�����ա��������ۼ���ͬ��ʡ����С����̡������������������ȣ���
�� ����������Լ������Ϣ��
�� �е�ȱʡֵ��
�� �й����ݿ��ж���Ŀռ�ֲ�����ǰʹ�������
�� �����Ϣ����˭��ȡ���ĸ��ֶ���
������һ������ݿ���Ϣ��
����SQL��ȡ�����ֵ䣬���������ֵ�Ϊֻ����������ѯ��
1�� �����ֵ�Ľṹ
���ݿ������ֵ����ɻ��������û��ɴ�ȡ����ͼ��ɡ�
�������������ֵ�Ļ�����һ���������ɣ��洢��ص����ݿ����Ϣ����Щ��Ϣ����ORACLE����д�����Ǻ��ٱ�ORACLE�û�ֱ�Ӵ�ȡ��
�û��ɴ�ȡ��ͼ�������ֵ�����û��ɴ�ȡ��ͼ���ɸ����ط������ʾ�����ֵ�Ļ���������Ϣ����ͼ������������Ϣ����ɿ�����Ϣ��
2�� �����ֵ��ʹ��
�����ݿ��ʱ�������ֵ����ǿ��ã���פ����SYSTEM���ռ��С������ֵ������ͼ��������������£�ÿһ��ͼ����������ͼ������������Ϣ���˴���
ǰ ������ǰ USER��ALL��DBA��
�� ǰΪUSER����ͼ��Ϊ�� ��ͼ�������û���ģʽ�ڡ�
��ǰΪALL����ͼ��Ϊ��չ���û���ͼ��Ϊ�û��ɴ�ȡ����ͼ����
��ǰΪDBA����ͼΪDBA����ͼ��Ϊȫ���û��ɴ�ȡ����ͼ����
�����ݿ���ORACLE��ά����һ�������¼��ǰ���ݿ�Ļ����Щ����Ϊ��̬���ܱ�����̬���ܱ����������ı��������û����ܴ�ȡ��DBA�ɲ�ѯ��Щ�������Խ�����ͼ���������û������ȡ��ͼȨ��
��. �������
1�� ����
һ������Ϊ������һ������λ����һ������SQL�����ɡ�һ��������һ��ԭ�ӵ�λ�����������ȫ��SQL���Ľ���ɱ�ȫ���ύ����ȫ���ع���һ�������ɵ�һ����ִ��SQL��俪ʼ�����ύ��ع���������������ʽ�ģ�Ҳ������ʽ�ģ�ִ��DDL��䣩��
��ִ��һ��SQL�����ִ���ʱ�����������Ӱ�챻�ع�����������û�б�ִ��һ����������������ǰ������ǰ�Ĺ����Ķ�ʧ��
2�� ORACLE���������
��ORACLE��һ����������һ����ִ�е�SQL��俪ʼ��һ����ִ��SQL��������ʵ���ĵ��á�������ʼʱ��������һ�����ûع��Σ���¼������Ļع��һ�������������κ�һ�����ֶ�������
��COMMIT��ROLLBACK��û��SAVEPOINT�Ӿ䣩��䷢����
��һ��DDL��䱻ִ�С���DDL���ִ��ǰ������ʽ���ύ��
�� �û�������ORACLE�����ӣ���ǰ�����ύ����
���û������쳣��ֹ����ǰ����ع�����
1�� �ύ����
�ύһ����������������SQL�����ִ�еĸı����û������ύǰ��ORACLE�������������
����SGA�Ļع��λ����������ɻع��μ�¼���ع���Ϣ����������ֵ����ֵ��
����SGA����־��������������־���Щ�ı��������ύǰ�ɽ�����̡�
���SGA�����ݿ���������ģ���Щ�������������ύ֮ǰ�ɽ�����̡�
�������ύ֮�������������
�������ع�����ص��ڲ��������¼�ύ��������һ����Ӧ��Ψһϵͳ�ĺţ�SCN������¼�ڱ��С�
�� ��SGA����־����������־����LGWR����д�뵽������־�ļ��� ���ǹ����ύ�����ԭ������
�������Ϻͱ��ϵķ������ͷš�
��������־Ϊ��� ��
ע�⣺�����ύ����������IJ�����DBWR��̨��������д�������ļ����ɼ����洢��SGA�����ݿ�����У�������Чʱ����д�������ļ���
2�� �ع�����
�ع�����ĺ����dz���δ�ύ�����е�SQL��������Ķ������ġ�ORALCE��������δ�ύ����������Ҳ�����������֡�
�ڻع���������û�����ñ����㣩ʱ�������������
��������������SQL�������ȫ���ģ�������Ӧ�Ļع��α�������
�� �������ݵ�����������ͷš�
�����������
������ع���һ�����㣨����SAVEPOINT��ʱ�������������
�� ���ڸñ�����֮��ִ�е���䱻������
�� ��ָ���ı�������Ȼ���������ñ�����֮���������ı����㱻ɾ����
���Ըñ�����֮������ȡ��ȫ�����������з������ͷţ���ָ���ı�������ǰ����ȡ��ȫ�����ݷ����������֡�
��������Կɼ�����
3�� ������
�����㣨savepoint������һ����Χ�ڵ��м��־���������ڽ�һ����������ΪС�IJ��֡�������ɱ�־�������е��κε㣬�����ɻع��õ�֮��Ĺ�������Ӧ�ó����о���ʹ�ñ����㣻����һ���̰���������������ÿ������ǰ�ɽ���һ�������㣬�������ʧ�ܣ��������ص�ÿһ��������ʼ��������ڻع���һ��������֮�ñ��ֵ�֮������õ����ݷ������ͷš�
��. ���ݿⴥ����
1�� ����������
���ݿⴥ����(database trigger)�Ǵ洢�����ݿ��еĹ��̣���������ʱ����ʽ�ر�������ִ�У�����ORACLE�������ڶԱ�����INSERT��UPDATE��DELETE���ʱ��ʽ��ִ��������Ĺ��̣���Щ���̳�Ϊ���ݿⴥ�������������洢�����ݿ��У���������ر��ֱ�洢�������������ڱ��϶��塣����������д����������ṩ�ܸ���ר�����ݿ����ϵͳ��������ORACLE�ı����ܡ�������һ�����ڣ�
�� �Զ������ɵ�������ֵ��
�� ��ֹ��Ч������
��ʵʩ�����ӵİ�ȫ�Լ��
���ڷֲ�ʽ���ݿ���ʵʩ��Խ�������������ԣ�
��ʵʩ���ӵ��������
�� �ṩ���¼���־��
���ṩ������ƣ�
��ά��ͬ�������ƣ�
���ռ����ڴ�ȡ����ͳ�ơ�
ע�⣺���ݿⴥ������SQL*FORMS������֮��IJ�����ݿⴥ�����Ƕ����ڱ��ϣ��洢�����ݿ��У����Ա�ִ��INSERT��UPDATE��DELETE���ʱ��������������˭����һӦ�÷�������SQL*FORMS��������SQL*FORMӦ�õIJ��֣�������ָ��SQL*FORMSӦ����ִ��һ��ָ����������ʱ�ű�������
��������˵����������Լ����������Լ�����ݵ����룬������֮����һ������
˵����������Լ���ǹ������ݿ�����Ϊ���桱����䡣һ��������Լ��Ӧ���ڱ����������ݺͲ��ݱ����κ���䡣
��������Լ������Ӧ�����ڶ��崥����ǰ��װ������ݣ����������ܱ�֤����ȫ�����ݷ��Ӹô������Ĺ�������ʵʩ˲ʱԼ�����������ݸı�ʱʵʩһԼ����
2�� ����������ɣ�
һ�����������������������������¼�����䡢�����������ơ�������������
�����¼�����䣺Ϊ������������SQL��䣬�Ƕ�ָ����INSERT��UPDATE��DELETE��䡣
���������ƣ�Ϊһ��������ʽ��������������ʱ����������ΪTRUE������������������WHEN�Ӿ���ָ����
�������Ķ�����Ϊһ��PL/SQL�飨���̣�����SQL����PL/SQL�����ɡ���������䷢���������������Ƽ����TRUEʱ������ִ�С��ڴ���������������У���ʹ�ô������Ĵ����ĵ�ǰ�е���ֵ����ֵ����ֵ����ʹ����ʽΪ��
NEW.���� ������ֵ
OLE.���� ������ֵ
�ڶ��崥����ʱ��ָ������������ִ�д������ܴ������Ӱ��ÿһ��ִ��һ�λ��ǶԴ������ִ��һ�Ρ�
��ÿһ�����������������ʹ�������
�д����������ܴ��������Ӱ���ÿһ�У��д���������һ�Ρ�
��䴥�����������ʹ������Դ������ִ��һ�Σ���������Ӱ��������
���崥��������ָ������ʱ�䣬ָ��������������ִ������ڴ������ִ��֮���֮ǰ��
BEFORE���������ô�����ִ�д������������ڴ������ִ��֮ǰ��
AFTER���������ô�����ִ�д������������ڴ������ִ��֮��
һ���������ɴ������ֲ�ͬ�ķ�ʽ��ʹ�ܴ�������ʹ���ܴ�������
ʹ�ܴ�������ֻҪ��������䷢�������������Ƽ���ΪTRUE���������͵Ĵ�����ִ���䴥��������
ʹ���ܴ����������ִ�������ʹ�䴥����䱻���������������Ƽ���ΪTRUE��Ҳ��ִ�д�����������
��������Դ����洢�����ݿ��У��ڵ�һ��ִ��ʱ����������Դ���뱻���룬�洢�ڹ������С�����������ӹ������м��ˣ���ʹ��ʱ���������±��롣
��. �ֲ������ͷֲ�ʽ���ݿ�
1�� ���
һ���ֲ�ʽ���ݿ����û���ǰΪ���������ݿ⣬��ʵ�������ɴ洢�ڶ�̨������ϵ�һ�����ݿ���ɡ��ڼ�̨����� �ϵ����ݿ�ͨ�������ͬʱ�ĺʹ�ȡ��ÿһ���ݿ������ľֲ���DBMS���ơ��ֲ�ʽ���ݿ���ÿһ�����ݿ������������ά��ȫ�����ݿ��һ���ԡ�
��ϵͳ�е�ÿһ̨�������Ϊ��㡣���һ�����й������ݿ� �������ý���Ϊ���ݿ�����������һ�����Ϊ�������������Ϣ��һӦ�ã��ý���Ϊ�ͻ�����ORACLE�ͻ���ִ�����ݿ�Ӧ�ã��ɴ�ȡ������Ϣ�����û��������ڷ�������ִ��ORACLE������������ORACLE���ݿⲢ�����������ݴ�ȡ��ORACLE����������������ͬһ̨������ϣ������ͻ����ֺͷ������������������ӵIJ�ͬ�������ʱ������Ч��
�ֲ��������ɶ�̨�������ֵ���������Ĵ�������ORACLE���ݿ�ϵͳ�зֲ������������磺
�ͻ��ͷ�������λ���������ӵIJ�ͬ������ϡ�
��̨��������ж������������ͬ�������ֱ�ִ�пͻ�Ӧ�á�
SQL*NET��ORACLE����ӿڣ��������������繤��վ��ORACLE���ߺͷ������ϣ��ɴ�ȡ���ġ������ʹ洢�������������ϵ����ݡ�SAQL*NET�ɱ���Ϊ������ͨ�ŵij���ӿڡ�SQL*NET����ͨ��Э���Ӧ�ó���ӿڣ�API��ΪOARCLE�ṩһ���ֲ�ʽ���ݿ�ͷֲ�������
SQL*NET������Ϊ�����ݿ�����������е�ORACLE������ORACLE���ߵ��û�����֮���ṩһ���ӿڡ�
����ֲ�ʽ���ݿ��ÿһ�������Ƿֱ�ض����ع������ݿ⣬�� ��ÿһ���ݿⲻ�����绯�����ݿ⡣ÿһ�����ݿ�����ر���������Ϊ���������ԡ����������������кô���
��ϵͳ�Ľ��ɷ�ӳ��˾������֯��
�� �ɾֲ����ݿ����Ա���ƾֲ����ݣ�����ÿһ�����ݿ����Ա������ҪСһЩ���ɸ�
�ù�����
��ֻҪһ�����ݿ�������ǿ��ã���ôȫ�����ݿ�ɲ��ֿ��á�������һ�����ݿ�Ĺ�
�϶�ֹͣȫ����������������ƿ����
�� ���ϻָ�ͨ���ڵ�������Ͻ��С�
��ÿ���ֲ����ݿ����һ�������ֵ䡣
����ɶ���������������
�ɴӷֲ�ʽ���ݿ�����н���ȡģʽ�����������Ƿֲ��ľֲ���DBMS�������ṩһ�ֻ��ƣ����ھֲ����ݿ�������һ�����ֲ�ʽDBMS�����ṩһ������ģʽ�����·ֲ�ʽ���ݿ���һ���������Ӧ����Ψһ��ʶ�����á�һ����ڲ�νṹ��ÿһ��ʵʩΨһ�ԡ��ֲ�ʽDVMS������������ģ�ͣ�ʵʩ��������Ψһ���ݿ����������һ�������ȫ�ֶ�������֤�ڷֲ�ʽ���ݿ�����Ψһ��
ORACLE������SQL�����ʹ�������������÷ֲ�ʽ���ݿ��е�ģʽ��������ͼ���̣�����ORACLE�У�һ��ģʽ�����ȫ��������������ɣ����������ģʽ���������������ݿ���������ʽ�磺
SCOTT.EMP@SALES.DIVISION3.ACME.COM
����SCOTTΪģʽ��,EMPΪ����,@����֮��Ϊ���ݿ���.
һ��Զ�̲�ѯΪһ��ѯ,�Ǵ�һ������Զ�̱���ѡ����Ϣ,��Щ��פ����ͬһ��Զ�̽��.
һ���ֲ�ʽ��ѯ�ɴ�������������������.һ���ֲ�ʽ���¿����������������Ͻ�������.
һ��Զ������Ϊһ������,����һ�˻���Զ�����,�������õ�ȫ������ͬһ��Զ�̽����.һ���ֲ�ʽ������һ������,����һ����������ķֲ�ʽ���ݿ������������ͬ��������.
�ڷֲ�ʽ���ݿ���,������Ʊ�����������ֱϽ��,��֤����һ����.�����ύ���Ʊ�֤����ֲ�ʽ�����ȫ�����ݿ��������ȫ���ύ��ȫ���ع������е����.
ORACLE�ֲ�ʽ���ݿ�ϵͳ�ṹ����ORACLE���ݿ����ԱΪ�ն��û���Ӧ���ṩλ������,������ͼ��ͬ��ʡ����̿��ṩORACLE�ֲ�ʽ���ݿ�ϵͳ�е�λ������.
ORACLE������SELECT(��ѯ)��INSERT��UPDATE��DELETE��SELECT��FOR UPDATE��LOCK
TABLE���������Զ�����ݡ����ڲ�ѯ�����������ӡ��ۺϡ��Ӳ�ѯ��SELECT ��FOR UPDATE�������ñ��صġ�Զ�̵ı�����ͼ������UPDATE��INSERT��DELETE��LOCK
TABLE�������ñ��صĺ�Զ�̵ı���ע��������LONG��LONG RAW�С����С��ı��ͷ�����ʱ������λ��ͬһ����㡣ORACLE��������Զ��DDL��䡣
�ڵ����ػ�ֲ�ʽ���ݿ��У�������������COMMIT��ROLLBACK�����ֹ��ORACLE�ṩ���ֻ���ʵ�ֲַ�ʽ���ݿ��б��ظ������ԣ��������ṩ�첽�ı��ظ���������ʵ��ͬ���ı����ظ�������������£���ʵ���˶Ա��ظ������ԡ�
2�� �ֲ�ʽ���ݿ�ȫ���������ݿ���
1�� �ֲ�ʽ���ݿ�ȫ������ÿһ�����ݿ���һ��Ψһ��ȫ����������������ɣ����ݿ�����С�ڵ���8�ַ�����������ȫ�����ݿ�����������ɷֱ�����ӱ��������淶�������еIJ��
�ɷ��š�.���ֿ��������Ĵ�����Ҷ�������������ҡ�
2�� ���ݿ�����Ϊ�Թ������ݿⶨ���һ·�������ݿ����Էֲ�ʽ���ݿ���û������ģ����ݿ���������������ָ������ݿ��ȫ������ͬ�����ɶ�������ɣ�Զ���˺ź����ݿ�����������ݿ�������ʽ��
CREAT PUBLIC DATEBASE LINK sale��Division3��acme��com
CONNECT TO guest IDENTIFIED BY password
USING��DB������
���У�sales��Divisin3��acme��comΪ�����������guest/password ΪԶ�����ݿ���û��˺źͿ��DB������Զ�����ӡ����˺ź�DB��������ȫ·�������ֻ��һ����Ϊ����·����
���������ݿ��������ھ����û���ȫ�������������ã�
ר�����ݿ�����Ϊһָ���û�������ר�����ݿ������������˿�ʹ�á���SQL���������ָ��һȫ�ֶ����������ڳ����ߵ���ͼ���̶�����ʹ�á�
�������ݿ�����Ϊ������û���PUBLIC�������������ݿ�����Ϊ�κ��û�ʹ�ã���SQL���������ָ��һ��ȫ�ֶ�����������塣
�������������������������������������Ϊ�����е��κ����ݿ���κ��û�ʹ�ã�����SQL�����ָ��ȫ�ֶ��������������ʹ�á�ע�⣺��ǰ�������������ORACLE�����ã������������ݿ��������á�
3�� ������
ORACLE�ı�������������һ�������ڷֲ�ʽ���ݿ�����������и��ơ�ֻ������������������ֻ�ɶ���������ʽÿһ�����Ƴ�Ϊһ�����ա������첽��ˢ�£���ӳ������һ���������һ��״̬��
һ�����տ�Ϊ������ȫ��������Ϊ����һ���Ӽ���������һ��������������ͼ���������յķֲ�ʽ��ѯ�����塣�������������ݿ��Ϊ�����ݿ⡣
�����м��պ��ӿ��ա����յ�ÿ���ǻ��ڵ���Զ�̱��е�һ�С����Զ�����յIJ�ѯ�в�����GROUB BY��CONNECT
BY�Ӿ䣬���Ӳ�ѯ�����ӻϲ���������ڿ��ն���IJ�ѯ�а����������Ӿ����������ֿ��ճ�Ϊ���ӿ��ա�
�ڿ��ս���ʱ��ORACLE�ڿ��յ�ģʽ�н��������ڲ�����
�ڿ��ս�㣬ORACLE����һ�������ڴ洢�ɿ��ն���IJ�ѯ���������У�Ȼ��Ϊ�ñ�����һ��ֻ������ͼ����ΪԶ����������һ��ͼ������ͼ�����¿��ա�
һ���������ڵر�ˢ�£���ӳ���������ĵ�ǰ�����Ϊ��ˢ��һ���գ����ն����ѯ�DZ����������ѯ������ڴ洢�ڿ����У�������ǰ�Ŀ������ݡ�
������Ϊ����ʱ�������ɿ�����־��ˢ�£������ɼӿ�ˢ�´�����������־�����������ݿ��е�һ������������ء�ORACLEʹ�ÿ�����־�������������ĵ��С������������ļ���ˢ��ʱ������Ҫ������־����Ӧ����ˢ�¿��գ�����ˢ�³�Ϊ����ˢ�¡�
���ݿ�İ�ȫ�ԡ������ԡ��������ƺͻָ�
Ϊ�˱�֤���ݿ����ݵİ�ȫ�ɿ��Ժ���ȷ��Ч��DBMS�����ṩͳһ�����ݱ������ܡ����ݱ���ҲΪ���ݿ��ƣ���Ҫ�������ݿ�İ�ȫ�ԡ������ԡ��������ƺͻָ���
һ. ���ݿ�İ�ȫ��
���ݿ�İ�ȫ����ָ�������ݿ��Է�ֹ���Ϸ���ʹ������ɵ�����й¶�����Ļ��ƻ��������ϵͳ����������⣬�����ݿ�ϵͳ�д������ݼ��д�ţ�Ϊ�����û�������ʹ��ȫ�����Ϊͻ����
��һ��ļ����ϵͳ�У���ȫ��ʩ��һ��һ�����õġ�
��DB�洢��һ���ɲ������뼼�����������洢�豸ʧ�Ժ����������á������ݿ�ϵͳ��һ�����ṩ���ֿ��ƣ��û���ʶ�ͼ��������ݴ�ȡ���ơ�
��ORACLE���û����ݿ�ϵͳ�У���ȫ���������й�����
�� ��ֹ����Ȩ�����ݿ��ȡ��
�� ��ֹ����Ȩ�Ķ�ģʽ����Ĵ�ȡ��
�� ���ƴ���ʹ�ã�
�����ϵͳ��Դʹ�ã�
�� ����û�������
���ݿⰲȫ�ɷ�Ϊ���ࣺϵͳ��ȫ�Ժ����ݰ�ȫ�ԡ�
ϵͳ��ȫ����ָ��ϵͳ���������ݿ�Ĵ�ȡ��ʹ�õĻ��ƣ�������
�� ��Ч���û���/�������ϣ�
�� һ���û��Ƿ���Ȩ���������ݿ⣻
�� �û�������õĴ��̿ռ��������
�� �û�����Դ���ƣ�
�� ���ݿ�����Ƿ�����Ч�ģ�
�� �û���ִ����Щϵͳ������
���ݰ�ȫ����ָ�ڶ��������ݿ�Ĵ�ȡ��ʹ�õĻ��ƣ�������
����Щ�û��ɴ�ȡһָ����ģʽ�����ڶ�������������Щ�������͡�
��ORACLE���������ṩ��һ�������ȡ���ƣ���һ�ֻ�����Ȩ������Ϣ��ȡ�ķ������û�Ҫ��ȡһ�����������Ӧ����Ȩ�ڸ����û�������Ȩ���û�������ؿɽ�����Ȩ�������û����������ԭ�����ְ�ȫ�����ͽ��������͡�
ORACLE�������л��ƹ������ݿⰲȫ�ԣ�
�� ���ݿ��û���ģʽ��
�� ��Ȩ��
���ɫ��
��洢���úͿռ�ݶ
����Դ���ƣ�
����ơ�
1�� ���ݿ�Ĵ�ȡ����
ORACLE������Ϣ�ķ������������ȡ����������ȫ���û�����������Ĵ�ȡ���û��Զ���Ĵ�ȡ����Ȩ���ơ�һ����Ȩ�Ǵ�ȡһ������������ɣ�Ϊһ�ֹ涨��ʽ��
ORACLEʹ�ö��ֲ�ͬ�Ļ��ƹ������ݿⰲȫ�ԣ����������ֻ��ƣ�ģʽ���û���ģʽΪģʽ����ļ��ϣ�ģʽ�����������ͼ�����̺Ͱ��ȡ���һ���ݿ���һ��ģʽ��
ÿһORACLE���ݿ���һ��Ϸ����û����ɴ�ȡһ���ݿ⣬������һ���ݿ�Ӧ�ú�ʹ�ø��û������ӵ�������û������ݿ⡣������һ���ݿ��û�ʱ���Ը��û�����һ����Ӧ��ģʽ��ģʽ�����û�����ͬ��һ���û�����һ���ݿ⣬���û��Ϳɴ�ȡ��Ӧģʽ�е�ȫ������һ���û�����ͬ����ģʽ����ϵ�������û���ģʽ�����Ƶġ�
�û��Ĵ�ȡȨ�����û���ȫ������������ƣ��ڽ���һ�����ݿ�����û������һ�����û�ʱ����ȫ����Ա���û���ȫ�������о��ߣ�
���������ݿ�ϵͳ�����ɲ���ϵͳά���û���Ȩ��Ϣ��
�������û���ȱʡ���ռ����ʱ���ռ䡣
���г��û��ɴ�ı��ռ���ڱ��ռ��п�ʹ�ÿռ�ݶ
�������û���Դ���ƵĻ����ļ��������ƹ涨���û����õ�ϵͳ��Դ��������
��涨�û����е���Ȩ�ͽ�ɫ���ɴ�ȡ��Ӧ�Ķ���
ÿһ���û���һ����ȫ������һ�����ԣ��ɾ����������ݣ�
���û����õ���Ȩ�ͽ�ɫ��
���û����õı��ռ�ķݶ
���û���ϵͳ��Դ���ơ�
1�� �û�����
Ϊ�˷�ֹ����Ȩ�����ݿ��û���ʹ�ã�ORACLE�ṩ����ȷ�Ϸ���
����ϵͳȷ�Ϻ���Ӧ��ORACLE���ݿ�ȷ�ϡ�
�������ϵͳ������ORACLE��ʹ�ò���ϵͳ��ά������Ϣ�������û����ɲ���ϵͳ�����û����ŵ��ǣ�
���û��ɸ���������ӵ�ORACLE������Ҫָ���û����Ϳ��
����û���Ȩ�Ŀ��Ƽ����ڲ���ϵͳ��ORACLE����Ҫ�洢�����û����Ȼ���û��������ݿ�����ȻҪά����
�������ݿ��е��û�����Ͳ���ϵͳ��Ƹ������Ӧ��
ORACLE���ݿⷽʽ���û�ȷ�ϣ�ORACLE���ô洢�����ݿ��е���Ϣ�ɼ�����ͼ�ӵ����ݿ��һ�û������ּ�����������ϵͳ�����������ݿ��û�����ʱ��ʹ�á����û�ʹ��һORACLE���ݿ�ʱִ���û�����ÿ���û��ڽ���ʱ��һ������û������ڽ��������ݿ�����ʱʹ�ã��Է�ֹ�����ݿ����Ȩ��ʹ�á��û��Ŀ���������ĸ�ʽ�洢�����ݿ������ֵ��У��û�����ʱ������
2�� �û��ı��ռ����úͶ���
���ڱ��ռ��ʹ���м�������ѡ��
���û���ȱʡ���ռ䣻
���û�����ʱ���ռ䣻
�����ݿ���ռ�Ŀռ�ʹ�ö��
3�� �û���Դ���ƺͻ����ļ�
�û����õĸ���ϵͳ��Դ�������������û���ȫ��IJ��֡�������ʽ��������Դ���ƣ���ȫ����Ա�ɷ�ֹ�û����Ƶ����ı����ϵͳ��Դ����Դ�������ɻ����ļ�������һ�������ļ���������һ�鸳���û�����Դ���ơ�����ORACLEΪ��ȫ����Ա�����ݿ⼶�ṩʹ�ܻ�ʹ����ʵʩ�����ļ���Դ���Ƶ�ѡ��
ORACLE�����Ƽ������͵�ϵͳ��Դ��ʹ�ã�ÿ����Դ���ڻỰ�������ü��������Ͽ��ơ��ڻỰ����ÿһ���û����ӵ�һ���ݿ⣬����һ�Ự��ÿһ���Ự��ִ��SQL���ļ�����Ϻķ�CPUʱ����ڴ����������ơ���ORACLE�ļ�����Դ���ƿ��ڻỰ�������á�����Ự����Դ���Ʊ���������ǰ��䱻��ֹ���ع�����������ָ���Ự�����Ѵﵽ����Ϣ����ʱ����ǰ����������֮ǰִ�е���䲻��Ӱ�죬��ʱ������COMMIT��ROLLBACK��ɾ�������ݿ�����ӵȲ���������������������������
�ڵ��ü�����SQL���ִ��ʱ������������кü�����Ϊ�˷�ֹ����ص���ϵͳ��ORACLE�ڵ��ü������ü�����Դ���ơ�������ü�����Դ���Ʊ���������䴦����ֹͣ����
��䱻�ع���������һ����Ȼ����ǰ�������ִ��������䲻��Ӱ�죬�û��Ự�������ӡ�
��������Դ���ƣ�
��Ϊ�˷�ֹ���Ƶ�ʹ��CPUʱ�䣬ORACLE������ÿ��ORACLE���õ�CPUʱ�����һ�λỰ�ڼ�ORACLE������ʹ�õ�CPU��ʱ�䣬��0.01��Ϊ��λ��
��Ϊ�˷�ֹ�����I/O��ORACLE������ÿ�ε��ú�ÿ�λỰ�������ݿ������Ŀ��
��ORACLE�ڻỰ�����ṩ����������Դ���ơ�
ÿ���û��IJ��лỰ�������ƣ�
�Ự����ʱ������ƣ����һ�λỰ��ORACLE����֮��ʱ��ﵽ�ÿ���ʱ�䣬��ǰ���ع����Ự����ֹ���Ự��Դ���ظ�ϵͳ��
ÿ�λỰ������ʱ������ƣ����һ�λỰ�ڼ䳬��������ʱ������ƣ���ǰ���ع����Ự��ɾ�����ûỰ����Դ���ͷţ�
ÿ�λỰ��ר��SGA�ռ��������ơ�
�û������ļ���
�û������ļ���ָ����Դ���Ƶ����������ɸ���ORACLE���ݿ����Ч���û��������û������ļ������ع�����Դ���ơ�Ҫʹ���û������ļ�������Ӧ�����ݿ��е��û����࣬���������ݿ���ȫ���û�������Ҫ�������û������ļ����ڽ��������ļ�֮ǰ��Ҫ����ÿһ����Դ���Ƶ�ֵ������һ���û�ͨ����ִ�д��������ݿ�����ǾͿɽ�LOGICAL-READS-PER-SESSION��LOGICAL-READS-PER-CALL������Ӧ��ֵ������������о���һ�û��Ļ����ļ��ĺ�����Դ���Ƶ���õķ������ռ�ÿ����Դʹ�õ���ʷ��Ϣ��
2�� ��Ȩ�ͽ�ɫ
1�� ��Ȩ����Ȩ��ִ��һ���������͵�SQL�����ȡ��һ�û��Ķ����Ȩ������������Ȩ��ϵͳ��Ȩ�Ͷ�����Ȩ��
ϵͳ��Ȩ����ִ��һ������������ڶ���������ִ��һ���������Ȩ����ORACLE��60���ֲ�ͬϵͳ��Ȩ,ÿһ��ϵͳ�����û�ִ��һ����������ݿ������һ�����ݿ����.
ϵͳ��Ȩ����Ȩ���û����ɫ,һ��,ϵͳ��Ȩȫ������Ա��Ӧ�ÿ�����Ա,�ն��û�����Ҫ��Щ��ع���.��Ȩ��һ�û���ϵͳ��Ȩ�����и�
ϵͳ��Ȩ��Ȩ�������û����ɫ.��֮,�ɴ���Щ����Ȩ���û����ɫ����ϵͳ��Ȩ.
������Ȩ����ָ���ı�����ͼ�����С����̡����������ִ���������Ȩ�������ڲ�ͬ���͵Ķ���,�в�ͬ���͵Ķ�����Ȩ��������Щģʽ������ۼ��������������������ݿ���û����صĶ�����Ȩ��������ϵͳ��Ȩ���ơ�
���ڰ�����ij�û�����ģʽ�еĶ����û�����Щ�����Զ��ؾ���ȫ��������Ȩ����ģʽ�ij����߶�ģʽ�еĶ������ȫ��������Ȩ����Щ����ij����߿ɽ���Щ�����ϵ��κζ�����Ȩ����Ȩ�������û�����������߰�����GRANT
OPTION ��Ȩ����ô�ñ�����Ҳ�ɽ���Ȩ������Ȩ�������û���
2�� ��ɫ��Ϊ�����Ȩ�������飬����Ȩ���û��ͽ�ɫ��ORACEL���ý�ɫ�����ؽ�����Ȩ�������������ŵ㣺
�������Ȩ��������Ҫ��ʽ�ؽ�ͬһ��Ȩ����Ȩ�������û���ֻ�轫����Ȩ���ڸ���ɫ��Ȼ��ɫ��Ȩ��ÿһ�û���
�� ��̬��Ȩ���������һ����Ȩ��Ҫ�ı䣬ֻ���Ľ�ɫ����Ȩ�������ڸ��ý�ɫ��ȫ���û��İ�ȫ���Զ��ط�ӳ�Խ�ɫ�������ġ�
�� ��Ȩ��ѡ������ԣ���Ȩ���û��Ľ�ɫ��ѡ���ʹ��ʹ�ܣ����ã���ʹ���ܣ������ã���
�� Ӧ�ÿ�֪�ԣ���һ�û���һ�û���ִ��Ӧ��ʱ�������ݿ�Ӧ�ÿɲ�ѯ�ֵ䣬���Զ���ѡ��ʹ��ɫʹ�ܻ��ܡ�
��ר�ŵ�Ӧ�ð�ȫ�ԣ���ɫʹ�ÿ��ɿ������Ӧ�ÿ��ṩ��ȷ�Ŀ���ʹ��Ȩ��ɫʹ�ܣ��ﵽר�õ�Ӧ�ð�ȫ�ԡ����û���֪��������ʹ��ɫʹ�ܡ�
һ�㣬������ɫ����������Ŀ�ģ�Ϊ���ݿ�Ӧ�ù�����Ȩ��Ϊ�û��������Ȩ����Ӧ�Ľ�ɫ��ΪӦ�ý�ɫ���û���ɫ��
Ӧ�ý�ɫ�����������һ���ݿ�Ӧ�������ȫ����Ȩ��һ��Ӧ�ý�ɫ���ڸ�������ɫ��ָ���û���һ��Ӧ�ÿ��м��ֲ�ͬ��ɫ�����в�ͬ��Ȩ���ÿһ����ɫ��ʹ��Ӧ��ʱ�ɽ��в�ͬ�����ݴ�ȡ��
�û���ɫ��Ϊ���й�����Ȩ�����һ�����ݿ��û��������ġ��û���Ȩ��������Ӧ�ý�ɫ����Ȩ��Ȩ���û���ɫ�����ƣ�Ȼ���û���ɫ��Ȩ����Ӧ���û���
���ݿ��ɫ�������й��ܣ�
�� һ����ɫ������ϵͳ��Ȩ�������Ȩ��
��һ����ɫ����Ȩ��������ɫ��������ѭ����Ȩ��
�� �κν�ɫ����Ȩ���κ����ݿ��û���
����Ȩ��һ�û���ÿһ��ɫ������ʹ�ܵĻ���ʹ���ܵġ�һ���û��İ�ȫ���������ǰ�Ը��û�ʹ�ܵ�ȫ����ɫ����Ȩ��
�� һ�������Ȩ��ɫ����Ȩ����һ��ɫ�Ľ�ɫ����һ�û�����ʽ��ʹ���ܻ�ʹ���ܡ�
��һ�����ݿ��У�ÿһ����ɫ������Ψһ����ɫ�����û���ͬ����ɫ���������κ�ģʽ�У����Խ���һ��ɫ���û���ɾ��ʱ��Ӱ��ý�ɫ��
ORACLEΪ���ṩ����ǰ�汾�ļ����ԣ�Ԥ�������н�ɫ��CONNENT��RESOURCE��DBA��EXP-FULL-DATABASE��IMP-FULL-DATABASE��
3�� ���
����Ƕ�ѡ�����û������ļ�غͼ�¼��ͨ�����ڣ�
�������ɵĻ�����磺���ݱ�����Ȩ�û���ɾ������ʱ��ȫ����Ա�ɾ����Ը� ���ݿ���������ӽ�����ƣ��Լ������ݿ�����б��ijɹ��ػɹ���ɾ��������ơ�
�� ���Ӻ��ռ�����ָ�����ݿ������ݡ����磺DBA���ռ���Щ���ġ�ִ���˶��ٴ�����I/O��ͳ�����ݡ�
ORACLE֧������������ͣ�
�������ƣ���ij�����͵�SQL�����ƣ���ָ���ṹ�����
�� ��Ȩ��ƣ���ִ����Ӧ������ϵͳ��Ȩ��ʹ����ơ�
�������ƣ���һ����ģʽ�����ϵ�ָ��������ơ�
ORACLE�����������ѡ���������з��棺
�� ������ijɹ�ִ�С����ɹ�ִ�У����������ߡ�
�� ��ÿһ�û��Ự������ִ��һ�λ��߶����ÿ��ִ�����һ�Ρ�
���ȫ���û���ָ���û��Ļ����ơ�
�����ݿ�������ʹ�ܵģ������ִ�нβ�����Ƽ�¼����Ƽ�¼��������ƵIJ������û�ִ�еIJ��������������ں�ʱ�����Ϣ����Ƽ�¼�ɴ��������ֵ������Ϊ��Ƽ�¼�������ϵͳ��Ƽ�¼�С����ݿ���Ƽ�¼����SYSģʽ��AUD$���С�
��. ����������
����ָ���ݵ���ȷ�Ժ������ԡ����ݵ���������Ϊ�˷�ֹ���ݿ���ڲ�������������ݣ���ֹ������Ϣ����������������Ҫ������DBA��Ӧ�ÿ�������������һ��Ԥ����Ĺ���ORACLEӦ���ڹ�ϵ���ݿ�ı����������������������ͣ�
�� �ڲ�����ı�����ʱ���������������п�ֵ���У���Ϊ����ǿչ���
�� Ψһ��ֵ��������������ĵı����ڸ����ϵ�ֵΨһ��
�����������Թ���ͬ��ϵģ�Ͷ���
�� �û��Զ���Ĺ���Ϊ�����������Լ�顣
ORACLE���������ʵʩ����ÿһ�����͵����������Թ�����Щ�������������Լ�������ݿⴥ�������塣
������Լ�����ǶԱ����ж���һ�����˵���Է�����
���ݿⴥ��������ʹ�÷�˵������ʵʩ�����Թ����������ݿⴥ�������洢�����ݿ���̣��ɶ����ʵʩ�κ����͵������Թ���
1�� ������Լ��
ORACLE����������Լ�����Ʒ�ֹ��Ч�����ݽ������ݿ�Ļ���������κ�DMLִ�н���ƻ�������Լ��������䱻�ع�������һ�ϸ�����ORACLEʵ�ֵ�������Լ����ȫ����ANSI
X3��135-1989��ISO9075-1989����
����������Լ��ʵʩ���������Թ����������ŵ㣺
�������ı�ʱ������Ҫ������ƣ�������ر�д�������������Դ����书������ORACLE���ơ�����˵����������Լ������Ӧ�ô�������ݿⴥ������
�� �Ա��������������Լ���Ǵ洢�������ֵ��У��������κ�Ӧ�ý�������ݶ�������������������������Լ����
��������Ŀ�������������������Լ����ʵʩ���������ı�ʱ������Աֻ��ı�������Լ���Ķ��壬����Ӧ���Զ����������ĵ�Լ����
������������Լ���洢�������ֵ��У����ݿ�Ӧ�ÿ�������Щ��Ϣ����SQL���ִ��֮ǰ����ORACLE���֮ǰ���Ϳ�����������Ϣ��
������������Լ��˵��������������ض��壬����ÿһָ��˵�������ʵ�������Ż���
������������Լ������ʱ��ʹ���ܣ�������װ���������ʱ�ɱ���Լ�������Ŀ����������ݿ�װ�����ʱ��������Լ��������ʹ���ܣ��κ��ƻ�������Լ�����κ���������������г���
ORACLE��DBA��Ӧ�ÿ�ʼ�߶��е�ֵ�����ʹ�õ�������Լ�����������ͣ�
�� NOT NULLԼ��:����ڱ���һ�е�ֵ������Ϊ�գ������ڸ���ָ��NOT NULLԼ����
��UNIQUE��Լ�����ڱ�ָ�����л������ϲ����������Ǿ����ظ�ֵʱ������Ҫ���л�������ָ��UNIQUE��������Լ������UNIQUE��Լ�������е��л����г�ΪΨһ�롣����Ψһ������Լ��������������ʵʩ��
��PRIMARY KEYԼ���������ݿ���ÿһ��������һ��PRIMARY KEYԼ����������PRIMARY KEY������Լ�����л����г�Ϊ���룬ÿ��������һ�����롣ORACLEʹ������ʵʩPRIMARY
KEYԼ����
�� FOREIGN KEYԼ�����ɳ�����Լ�������ڹ�ϵ���ݿ��б���ͨ����������������� ������Ʊ���ά������֮��Ĺ�ϵ������������������Լ��������л����г�Ϊ�����롣�������������õı��е�Ψһ����룬��Ϊ�����롣������������ı���Ϊ�ӱ�������������ӱ��������������õı���Ϊ˫�ױ������ñ�������Ա���ÿһ�У����������ֵ������������һֵ��ƥ�䣬����ָ������������Լ����
�� CHECKԼ��������ÿ�ж�һָ��������������TRUE��δ֪��������һ�л�������ָ��CHECK������Լ��������ڷ���һ��DML���ʱ��CHECKԼ�������������FALSEʱ������䱻�ع���
2�� ���ݿⴥ����
ORACLE����������̣�������صı���INSERT��UPDATE��DELETE���ʱ����Щ���̱���ʽ��ִ�С���Щ���̳�Ϊ���ݿⴥ�����������������ڴ洢�Ĺ��̣��ɰ���SQL����PL/SQL��䣬�ɵ��������Ĵ洢���̡������봥����������ڵ��÷������������û���Ӧ����ʽִ�У�����������Ϊһ�������
��INSERT��UPDATE��DELETE����������ORACLE��ʽ�ش�����һ�����ݿ�Ӧ�ÿ���ʽ�ش����洢�����ݿ��ж����������
����������д���������ORACLE�ı����ܣ��ṩ�߶�ר�õ����ݿ����ϵͳ��һ�㴥�������ڣ�
���Զ������ɵ�����ֵ��
���ֹ��Ч����
�� ʵʩ���ӵİ�ȫ��ˡ�
���ڷֲ�ʽ���ݿ���ʵʩ��������������ԡ�
�� ʵʩ���ӵ��������
���ṩ�����¼���¼��
�� �ṩ������ơ�
��ά��ͬ���ı�������
�� �ռ�����ȡ��ͳ����Ϣ��
ע�⣺��ORACLE����������ORACLE����SQL*FORMSҲ�ɶ��塢�洢��ִ�д�����������Ϊ��SQL*FORMS��������Ӧ�õ�һ���֣������ڱ��϶�������ݿⴥ�����в�����ݿⴥ�����ڱ��϶��壬�洢����ص����ݿ��У��ڶԸñ�����IMSERT��UPDATE��DELETE���ʱ���������ݿⴥ������ִ�У���������Щ�û���Ӧ�÷�����Щ��䡣��SQL*FORMS�Ĵ�������SQL*FORMSӦ�õ���ɣ�������ָ��SQL*FORMSӦ����ִ��ָ����������ʱ�ż����ô�������
һ������������������ɣ������¼�����䡢�������ƺʹ����������������¼��������ָ������������SQL��䣬��Ϊ��һָ������INSERT��UNPDATE��DELETE��䡣����������ָ��һ����������ʽ��������������ʱ�ò�������ʽ�DZ���Ϊ�档��������Ϊ���̣���PL/SQL�飬��������䷢�����������Ƽ���Ϊ��ʱ�ù��̱�ִ�С�
3�� ��������
���ݿ���һ��������Դ����Ϊ���Ӧ�ó�������������Щ����ɴ������У�������������£�����Ӧ�ó����漰�����������ܴܺ������漰����/����Ľ�����Ϊ����Ч���������ݿ���Դ�����ܶ�������һ������Ķ�����̲��е����У���������ݿ�IJ��в������ڶ��û����ݿ���У�����û�����ɲ��еش�ȡ���ݿ⣬������Բ����������п��ƣ����ȡ����ȷ�����ݣ����ƻ����ݿ����ݵ�һ���ԡ�
�����ڷɻ�Ʊ��Ʊ�У���������ƱԱ��T1��T2����ij���ߣ�A���Ļ�����Ʊ��������������������ͼ��ʾ��
���ݿ��е�A 1 1 1 1 0 0
T1 READ A A��=A-1 WRITE A
T2 READ A A��=A-1 WRITE A
T1�������е�A 1 1 0 0 0 0
T2�������е�A 1 1 0 0 0
����T1��A������T2Ҳ��A��Ȼ��T1���乤�����е�A��1��T2Ҳ��ȡͬ�����������Ƕ���0ֵ�����ֱ�0ֵд�����ݿ⡣���������û���κηǷ���������ʵ���϶��һ�Ż�Ʊ�����������Ϊ���ݿ�IJ�һ���ԣ����ֲ�һ���������ڲ��в����������ġ���ν��һ�£�ʵ���������ڴ������������е����������ݿ��е����ݲ�һ������ɵġ���������������ݿ��е����ݽ����ģ������������κβ�һ�¡���һ���棬���û�в��в�����������������ʱ�IJ�һ��Ҳ�������ʲô���⡣���ݲ�һ��������������������ɣ�һ�Ƕ����ݵ��ģ����Dz��в����ķ��������Ϊ�˱������ݿ��һ���ԣ�����Բ��в������п��ơ���õĴ�ʩ�Ƕ����ݽ��з�����
1�� ���ݿⲻһ�µ�����
��һ����
��һ�����ڼ䣬�����ύ�Ļ�δ�ύ�����������Ȼ�ģ������ɲ�ѯ�����ص����ݼ������κε���һ�¡�
���ظ���
��һ������Χ�ڣ�������ͬ��ѯ�����ز�ͬ���ݣ����ڲ�ѯע������ύ������Ķ�����
�� ��������
�������T1��һֵ��A���ģ�Ȼ������T2����ֵ������֮��T1����ij��ԭ�����Ը�ֵ���ģ��������T2��ȡ��ֵ����ġ�
�� ��ʧ����
��һ������һ����д��һ������ģ��������ɻ�Ʊ��Ʊ���ӡ�
�� �ƻ��Ե�DDL����
��һ�û���һ��������ʱ����һ�û�ͬʱ���Ļ�ɾ���ñ���
2) ����
�ڶ��û����ݿ���һ�����ijЩ���ݷ�����������������е�����һ���Ժ����������⡣�����Ƿ�ֹ��ȡͬһ��Դ���û�֮���ƻ��Եĸ��ŵĻ��ƣ��ø�����ָ����ȷ�������ݻ���ȷ�ظ������ݽṹ��
�ڶ��û����ݿ���ʹ�����ַ�����������ר�ã�������������������������ֹ�����Դ�Ĺ��������һ������������ʽ����һ��Դ������������ɸ��ĸ���Դ��ֱ���ͷ����������������������������Դ���Թ����������û���ͬʱ��ͬһ���ݣ������������ͬһ��Դ�ϻ�ȡ�������������������������������и��ߵ����ݲ����ԡ�
�ڶ��û�ϵͳ��ʹ�÷�������������������һЩ�����ܼ��������������������û��˴˵ȴ�����������ʱ�ɷ���������
3) ORACLE����һ����ģ�͡�
ORACLE��������ͷ��������ṩ���ݲ�����ȡ�����������ԡ���һ������������ȡ��ȫ�������������ڼ䱻���֣���ֹ��������������ƻ��Ը��š�һ�������SQL����������������ύ֮���������������в��ǿɼ��ġ���һ���������������ȡ��ȫ�������ڸ������ύ��ع�ʱ���ͷš�
ORACLE��������ͬ�����ṩ��һ���ԣ���伶��һ���Ժ�����һ���ԡ�ORCLE����ʵʩ��伶��һ���ԣ���֤������ѯ�����ص�������ò�ѯ��ʼʱ����һ�¡�����һ����ѯ�Ӳ��ῴ���ڲ�ѯִ�й������ύ�����������������κ��ġ�Ϊ��ʵ����伶��һ���ԣ��ڲ�ѯ����ִ�н�ʱ����ע��SCN��ʱ��Ϊֹ���ύ����������Ч�ģ��������ִ�п�ʼ֮�����������ύ���κ��ģ���ѯ���ǿ������ġ�
ORACLE����ѡ��ʵʩ����һ���ԣ�����֤��ͬһ���������в�ѯ������
4) ��������
ORACLE�Զ���ʹ�ò�ͬ�����������������ݵIJ��д�ȡ����ֹ�û�֮����ƻ��Ը��š�ORACLEΪһ�����Զ��ط���һ��Դ�Է�ֹ���������ͬһ��Դ��������������ij���¼����ֻ���������Ҫ����Դʱ�Զ����ͷš�
ORACLE��������Ϊ�����ࣺ
�����ݷ��������ݷ������������ݣ��ڶ���û����д�ȡ����ʱ��֤���ݵ������ԡ����ݷ�����ֹ���ͻ��DML��DDL�������ƻ��Ը��š�DML����������������ȡ���ݷ�����ָ���з������������������ڷ�ֹ��ͻ��DDL����ʱҲ�������������Ҫ����ʱ�������ڸ��л�ȡ�������ݷ��������������������з�ʽ���й���������������������������������������������
��DDL�������ֵ������
DDL��������ģʽ����������Ķ��壬DDL������Ӱ�����һ��DDL�����ʽ���ύһ�������κ�DDL������Ҫʱ��ORACLE�Զ���ȡ�ֵ�������û�������ʽ������DDL��������DDL�����ڼ䣬���Ļ����õ�ģʽ��������
�� �ڲ������������ڲ����ݿ���ڴ�ṹ����Щ�ṹ���û��Dz��ɼ��ġ�
5) �ֹ������ݷ���
�����������ʹ��ѡ�����ORACLEȱʡ�ķ������ƣ�
�� Ӧ����Ҫ����һ�»���ظ�����
��Ӧ����Ҫһ�����һ��Դ��������ȡ��Ϊ�˼���������䣬���ж���Դ������ȡ�����صȴ�����������ɡ�
ORACLE�Զ��������ڶ��������������ϵͳ����
��������������SQL�����������ORACLEȱʡ������LOCK TABLE���SELECT��FOR UPDATE�������READ
ONLYѡ���SET TRANSACTIN�������Щ�������õķ����������ύ��ع������ͷš�
��ϵͳ����ͨ��������ʼ������SERIALIZABLE��REO-LOCKING��ʵ�����÷�ȱʡ�������������������ݵ�ȱʡֵΪ��
SERIALIZABLE=FALSE
ORW-LOCKING=ALWAYS
4�� ���ݿ�ͻָ�
������ʹ��һ�����ݿ�ʱ����ϣ�����ݿ�������ǿɿ��ġ���ȷ�ģ������ڼ����ϵͳ�Ĺ��ϣ�Ӳ�����ϡ��������ϡ�������ϡ����̹��Ϻ�ϵͳ���ϣ�Ӱ�����ݿ�ϵͳ�IJ�����Ӱ�����ݿ������ݵ���ȷ�ԣ������ƻ����ݿ⣬ʹ���ݿ���ȫ�������ݶ�ʧ����˵������������Ϻ�ϣ�������½���һ�����������ݿ⣬�ô�����Ϊ���ݿ�ָ����ָ���ϵͳ�����ݿ����ϵͳ��һ����Ҫ��ɲ��֡��ָ��������������Ĺ���������Ӱ��Ľṹ���仯��
1�� �ָ����ݿ���ʹ�õĽṹ
ORACLE���ݿ�ʹ�ü��ֽṹ�Կ��ܹ������������ݣ����ݿ����־���ع��κͿ����ļ���
���ݿ�����ɹ���ORACLE���ݿ�������ļ��IJ���ϵͳ������ɡ������ʹ���ʱ�������ݿ�ָ������ú��ļ��ָ��ٻ��������ļ�������ļ���
��־��ÿһ��ORACLE���ݿ�ʵ�����ṩ����¼���ݿ���������ȫ���ġ�һ��ʵ������־������������־�ļ���ɣ���ʵ�����ϻ���ʹ���ʱ�������ݿⲿ�ָֻ����������ݿ���־�еĸı�Ӧ���������ļ��������ݿ����ݵ����ϳ��ֵ�ʱ�̡����ݿ���־����������ɣ�������־�鵵��־��
ÿһ�����е�ORACLE���ݿ�ʵ����Ӧ����һ��������־������ORACLE��̨����LGWRһ������������¼��ʵ��������ȫ���ġ�������־����������Ԥ�ڷ�����ļ���ɣ���ѭ����ʽʹ�á�
�鵵��־�ǿ�ѡ��ģ�һ��ORACLE���ݿ�ʵ��һ��������־�������γ�������־�Ĺ鵵�ļ����鵵��������־�ļ���Ψһ��ʶ���ϳɹ鵵��־��
�ع������ڴ洢���ڽ��е�����Ϊδ�ύ����������ֵ����ֵ������Ϣ�����ݿ�ָ����������ڳ����κη��ύ���ġ�
�����ļ���һ�����ڴ洢���ݿ�������ṹ��״̬�������ļ���ijЩ״̬��Ϣ��ʵ���ָ��ͽ��ʻָ��ڼ���������ORACLE��
2�� ������־
һ��ORACLE���ݿ��ÿһʵ����һ���������������־��һ��������־�ɶ��������־�ļ���ɡ�������־�ļ�������־���־���¼�����������ع������ݿ�������ȫ���ġ���̨����LGWR��ѭ����ʽд��������־�ļ�������ǰ��������־�ļ�д����LGWRд�뵽��һ����������־�ļ������һ�����õ�������־�ļ��ļ��������ʱ����ʹ�á�����鵵��ʵʩ��һ����������������־�ļ�һ��������������־�ļ��ļ�����ɣ����ļ��ѱ��鵵��ʹ�á����κ�ʱ����һ��������־�ļ���д��洢��־�������Ϊ��Ļ�ǰ������־�ļ���������������־�ļ�Ϊ�����������־�ļ���
ORCLE����д��һ������־�ļ�����ʼд�뵽��һ��������־�ļ��ĵ��Ϊ��־���ء���־�����ڵ�ǰ������־�ļ���ȫ�������������д�뵽��һ��������־�ļ�ʱ�ܳ��֣�Ҳ����DBAǿ����־���ء�ÿһ��־���س���ʱ��ÿһ������־�ļ�����һ���µ���־���кš����������־�ļ����鵵���ڹ鵵��־�ļ��а�����������־���кš�
ORACLE��̨����DBWR�����ݿ�д����SGA�����б��ĵ����ݿ�����������ύ��δ�ύ�ģ�д�뵽�����ļ����������¼���Ϊ����һ�����㡣������ԭ��ʵ�ּ��㣺
�� ����ȷ�����ڴ��о����ı�����ݶο�ÿ��һ��ʱ��д�뵽�����ļ�������DBWRʹ���������ʹ���㷨�������ĵ����ݶο�Ӳ�����Ϊ�������ʹ�ÿ飬������㲻���֣����Ӳ���д����̡�
������ֱ������ʱ���е����ݿ����Ѽ�¼�������ļ������ڼ������־����ʵ���ָ�ʱ������ҪӦ���������ļ������Լ���ɼӿ�ʵ���ָ���
��Ȼ������һЩ��������ORACLE�Ȳ�ֹͣ��ֲ�Ӱ�쵱ǰ��������DBWR���ϵؽ����ݿ����д�뵽���̣�����һ������һ�β���д�������ݿ顣һ�����㱣֤��ǰһ������������ȫ�������ݿ�д�뵽���̡����㲻��������������־�ļ��Ƿ����ڹ鵵�������dz��֡����ʵʩ�鵵����LGWR����������־�ļ�֮ǰ�����������ɲ�����������������־�ļ����뱻�鵵��
����ɶ����ݿ��ȫ�������ļ����֣���Ϊ���ݿ���㣩��Ҳ�ɶ�ָ���������ļ����֡�����˵��һ��ʲôʱ����ּ��㼰����ʲô�����
����ÿһ����־���ش��Զ��س���һ���ݿ���㡣���ǰһ�����ݿ�������ڴ���������־����ʵʩ�ļ������ڵ�ǰ���㡣
�� ��ʼ��������LOG-CHECKPOINT-INTERVAL������ʵʩ�����ݿ���㣬��Ԥ������־�����������������һ�����ݿ������������ʵʩһ���ݿ���㡣��һ������LOG-CHECKPOINT-TIMEOUT����������һ�����ݿ���㿪ʼ֮��ָ��������ʵʩһ���ݿ���㡣����ѡ���ʹ�÷dz������־�ļ�ʱ���ã�������־��ͷ֮�����Ӽ��㡣�ɳ�ʼ�����������������ݿ����ֻ����ǰһ��������ɺ����������
��һ���߱��ռ俪ʼ��ʱ�����Թ��ɸÿռ�������ļ�ʵʩһ���㣬�ü���ѹ�����ڽ����е��κμ��㡣
�� ��DBAʹһ���ռ�����ʱ�����Թ��ɸñ��ռ�������ļ�ʵʩһ���㡣
��DBA��������������ʽ�ر�һʵ��ʱ��ORACLE��ʵ���ر�֮ǰʵʩһ���ݿ���㣬�ü���ѹ���κ����м��㡣
�� DBA��Ҫ��ʵʩһ���ݿ���㣬�ü���ѹ���κ����м��㡣
������ƣ����������ʱ�������̨���̼�סд�������ļ�����һ��־�е�λ�ã���֪ͨ���ݿ�д��̨���̽�SGA���ĵ����ݿ����д�뵽�����ϵ������ļ���Ȼ����CKPT��ȫ�������ļ��������ļ��ı�ͷ����ӳ�������㡣�����㲻������DBWR����Ҫʱ�����������ʹ�õ����ݿ����д����̣�Ϊ����������������
����������־�ļ���Ϊ�˰�ȫ��ʵ����������־�ļ���������������־�ļ�ORACLE�ṩ�����ܡ������о���������־�ļ�ʱ��LGWRͬʱ��ͬһ��־��Ϣд�뵽���ͬ����������־�ļ�����־�ļ��ֳ��飬ÿ�����е���־�ļ���Ϊ��Ա��ÿ�����е�ȫ����Աͬʱ�����LGWR������ͬ����־���кš����ʹ�þ���������־����ɽ���������־�ļ��飬�����е�ÿһ��ԱҪ����ͬһ��С��
����������־�Ļ��ƣ�LGWR����Ѱ�����ȫ����Ա����һ���ȫ����Ա���е�д��Ȼ��ת������һ���ȫ����Ա�����е�д��
ÿ�����ݿ�ʵ�����Լ���������־�飬��Щ������־������Ǿ���Ļ��ǣ���Ϊʵ����������־�������ڵ��������У�һ�����ݿ�ʵ����ȡһ��ORACLE���ݿ⣬���ǽ�һ���������ڡ�Ȼ��������ORACLE���з������У���������ʵ�����еش�ȡ�������ݿ⣬����������£�ÿ��ʵ�����Լ���������
3�� �鵵��־
ORACLEҪ��������������־�ļ���鵵ʱ����Ҫ�����鵵��־�����������־��������ݿ�ͻָ��������ô���
�� ���ݿ���Լ����ߺ鵵��־�ļ����ڲ���ϵͳ����̹����пɱ�֤ȫ���ύ������ɱ��ָ���
�������ݿ��ʱ������ϵͳʹ���£�����鵵��־�����ñ��֣����ߺ��Խ��к�ʹ�á�
����û����ݿ�Ҫ�����κδ��̹��ϵ��¼��в���ʧ�κ����ݣ���ô�鵵��־����Ҫ���ڡ��鵵��������������־�ļ�������ҪDBAִ�ж���Ĺ���������
�鵵���ƣ������ڹ鵵���ã��鵵��������������־��Ļ��ƿ���ORACLE��̨����ARCH�Զ��鵵�����û����̷�������ֹ��ع鵵������־���Ϊ�������־����ָ����һ�������ʱ��ARCH�ɹ鵵һ�飬�ɴ�ȡ������κλ�ȫ����Ա����ɹ鵵�顣������־�ļ��鵵֮��ſ�ΪLGWR���á���ʹ�ù鵵ʱ������ָ���鵵Ŀ��ָ��һ�洢�豸������ͬ�ڸ��������ļ���������־�ļ��Ϳ����ļ����豸��������ǽ��鵵��־�ļ����õ��Ƶ����ߴ洢�豸����Ŵ���
���ݿ�����������ֲ�ͬ��ʽ�£�NOARCHIVELOG��ʽ��ARCHIVELOG��ʽ�����ݿ���NOARCHIVELOG��ʽ��ʹ��ʱ�����ܽ���������־�Ĺ鵵���ڸ����ݿ�����ļ�ָ���������鲻��Ҫ�鵵������һ�����������Ϊ�������־���صļ�����ɣ����鼴�ɱ�LGWR���á��ڸ÷�ʽ�½��ܱ������ݿ�ʵ�����ϣ����ܱ������ʣ����̣����ϡ����ô洢��������־�е���Ϣ����ʵ��ʵ�����ϻָ���
������ݿ���ARCHIVELOG��ʽ��,��ʵʩ������־�Ĺ鵵���ڿ����ļ���ָ����������־�ļ����ڹ鵵֮ǰ�������á�һ�����Ϊ�����ִ�й鵵�Ľ���������ʹ�ø��顣
��ʵ����ʱ��ͨ������LOG-ARCHIVE-START���ã�������ARCH���̣�����ARCH������ʵ������ʱ���ܱ�������Ȼ��DBA��ƾ��ʱ��ɽ�����������ֹͣ�Զ��鵵��
һ��������־�ļ����Ϊ���ʱ��ARCH�����Զ������鵵��
������ݿ���ARCHIVELOG��ʽ�����У�DBA���ֹ��鵵�����IJ������־�ļ��飬�����Զ��鵵�ǿ��Ի��Dz����ԡ�
4�� ���ݿ��
����ΪORACLE���ݿ���Ƴ�ʲô���ĺ�ָ�ģʽ�����ݿ������ļ�����־�ļ��Ϳ����ļ��IJ���ϵͳ���Ǿ�����Ҫ�ģ����DZ������ʹ��ϵIJ��Բ��֡�����ϵͳ������ȫ�Ͳ��ֺ�
����ȫ��һ����ȫ������ORACLE���ݿ��ȫ�����ݿ��ļ���������־�ļ��Ϳ����ļ���һ������ϵͳ��һ����ȫ�������ݿ������ر�֮����У�������ʵ�����Ϻ���С��ڴ�ʱ�����й������ݿ��ȫ���ļ��ǹرյģ����뵱ǰ����һ�¡������ݿ��ʱ���ܽ�����ȫ������ȫ�õ��������ļ����κ����͵Ľ��ʻָ�ģʽ�������õġ�
�� ���ֺ�
���ֺ�Ϊ����ȫ������κβ���ϵͳ���������ݿ��ر��½��С��絥�����ռ���ȫ�������ļ������������ļ��Ϳ����ļ������ֺ�����ARCHIVELOG��ʽ���������ݿ����ã���Ϊ���ڵĹ鵵��־�������ļ����ɲ��ָֺ����ڻָ������������ݿ���������һ�¡�
5�� ���ݿ�ָ�
��ʵ�����ϵĻָ�
��ʵ������أ�����硢��̨���̹��ϵȣ���Ԥ�ϵأ�����SHUTDOUM
ABORT��䣩��ֹʱ����ʵ�����ϣ���ʱ��Ҫʵ���ָ���ʵ���ָ������ݿ�ָ�һ����֮ǰ������һ��״̬����������ߺ���ʵ�����ϣ�������ʻָ������������ORACLE���´����ݿ���ʱ������ʵ��װ��ʹ����Զ���ִ��ʵ���ָ��������Ҫ����װ��״̬��Ϊ��״̬���Զ��ؼ���ʵ���ָ��������д�����
��1�� Ϊ�˽�ָ������ļ���û�м�¼�����ݣ�������ǰ���������ݼ�¼��������־�������Իع��ε����ݻָ���
��2�� �ع�δ�ύ��������1�������ɻع�����ָ���IJ�����
��3�� �ͷ��ڹ���ʱ���ڴ������������е���Դ��
��4�� ����ڹ���ʱ������һ���ύ���κ�����δ���ķֲ�����
����ʹ��ϵĻָ�
���ʹ����ǵ�һ���ļ���һ���ļ��IJ��ֻ�һ���̲��ܶ�����дʱ���ֵĹ��ϡ����ʹ��ϵĻָ���������ʽ�����������ݿ����еĹ鵵��ʽ��
��������ݿ��ǿ����еģ���������������־�������õ����ܹ鵵����ʱ���ʻָ�Ϊʹ�����µ���ȫ�ļָ�������ȫ��ִ�еĹ��������ֹ���������
��������ݿ�����У���������־�DZ��鵵�ģ��ý��ʹ��ϵĻָ���һ��ʵ�ʻָ����̣��ع���������ݿ�ָ������ʹ���ǰ��һ��ָ������һ��״̬��
����������ʽ�����ʹ��ϵĻָ����ǽ��������ݿ�ָ�������֮ǰ��һ������һ��״̬��������ݿ�����ARCHIVELOG��ʽ���У����в�ͬ���͵Ľ��ʻָ�����ȫ���ʻָ��Ͳ���ȫ���ʻָ���
��ȫ���ʻָ��ɻָ�ȫ����ʧ���ġ��������б�Ҫ����־����ʱ�ſ��ܡ��в�ͬ���͵���ȫ���ʻָ���ʹ�ã�������ڻٻ��ļ������ݿ�Ŀ����ԡ�����
�� �ر����ݿ�Ļָ��������ݿ�ɱ�װ��ȴ�ǹرյģ���ȫ��������ʹ�ã���ʱ�ɽ���ȫ���Ļ��ٻ������ļ�����ȫ���ʻָ���
������ݿ�����߱��ռ�Ļָ��������ݿ��Ǵģ���ȫ���ʻָ����Դ�����δ������ݿ���ռ������ߵĿ���ʹ�ã�������IJ��ռ������ߵģ������������ļ���Ϊ�ָ��ĵ�λ��
�� �����ݿ�����߱���ĵ��������ļ��Ļָ��������ݿ��Ǵģ���ȫ���ʻָ����Դ�����δ������ݿ���ռ������ߵĿ���ʹ�ã�������ı��ռ������ߵģ��ñ��ռ��ָ������������ļ��ɱ��ָ���
��ʹ�úĿ����ļ�����ȫ���ʻָ����������ļ����п������ڴ��̹��϶�����ʱ���ɽ��н��ʻָ�������ʧ���ݡ�
����ȫ���ʻָ�������ȫ���ʻָ������ܻ�Ҫ��ʱ���еĽ��ʻָ����ع���������ݿ⣬ʹ��ָ����ʹ���ǰ���û�����֮ǰ��һ������һ����״̬������ȫ���ʻָ��в�ͬ���͵�ʹ�ã���������Ҫ����ȫ���ʻָ�����������������ͣ����ڳ���������ʱ��ͻ����ĵIJ���ȫ�ָ���
���ڳ����ָ�����ij�����������ȫ���ʻָ����뱻���ƣ�DBA�ɳ�����ָ����IJ��������ڳ����Ļָ�����һ��������־�飨���ߵĻ�鵵�ģ��ѱ����ʹ������ƻ����������ڻָ�����ʱʹ�ã����Խ��ʻָ�������ƣ�������ʹ������ġ�δ�����־���������ļ�����ֹ�ָ�������
����ʱ��ͻ����ĵĻָ������DBAϣ���ָ�����ȥ��ij��ָ���㣬����ȫ���ʻָ�������ġ��������������ʹ�ã�
���û������ɾ��һ������ע������ύ�Ĺ���ʱ�䣬DBA�������ر����ݿ⣬�ָ������û�����֮ǰʱ�̡�
������ϵͳ���ϣ�һ��������־�ļ��IJ��ֱ��ƻ������Ի����־�ļ�ͻȻ����ʹ�ã�ʵ������ֹ����ʱ��Ҫ���ʻָ����ڻָ��п�ʹ�õ�ǰ������־�ļ���δ�֣�DBA���û���ʱ��Ļָ���һ���н�Ч��������־��Ӧ���������ļ���ֹͣ�ָ����̡�
������������£�����ȫ���ʻָ����յ����ʱ����ϵͳ�ĺţ�SCN����ָ����
Pro * C ��ʹ��
һ. Pro*C ���������
1��ʲô��Pro*C����
��ORACLE���ݿ������ϵͳ�У� �����ַ������ݿ�ķ�����
��1�� ��SQL*Plus�� ����SQL�����Խ�����Ӧ�ó���������ݿ⣻
��2�� �õ��Ĵ�����Ӧ�ÿ������߿�����Ӧ�ó���������ݿ⣬��Щ������SQL*Froms��QL*Reportwriter,SQL*Menu�ȣ�
��3�� �����ڵ�����������Ƕ���SQL���Ի�ORACLE�⺯�����������ʡ�
Pro*C�����ڵ����ֿ�������֮һ�� ���ѹ��̻�����C�ͷǹ��̻�����SQL�����Ƶؽ�������� �����걸�Ĺ��̴�����������������κ����ݿ�Ĵ���Ʒ����ʹ�û�����ͨ�������ɸ������͵ı�������Pro*C�����п���Ƕ��SQL���ԣ�
������ЩSQL���Կ�����ɶ�̬�ؽ������ĺ�ɾ�����ݿ��еı���Ҳ���Բ�ѯ�����롢�ĺ�ɾ�����ݿ���е��У� ������ʵ��������ύ�ͻع���
��Pro*C�����л�����Ƕ��PL/SQL�飬 �ԸĽ�Ӧ�ó�������ܣ� �ر��������绷���£����Լ������紫��ʹ������ܿ�����
2��Pro*C�ij���ṹͼ
ͨ����˵��Pro*C����ʵ������Ƕ��SQL����PL/SQL���C���� ���������ɺ�����C���� ����Ϊ����Ƕ��SQL����PL/SQL�飬
��������������֮��ͬ�ijɷݡ�Ϊ���ô�Ҷ�Pro*C�и����Ե���ʶ�� �ؽ����߲��Ƚ����£�
C��ȫ�̱���˵��
CԴ���� ����1��ͬ����K��
����2��ͬ����K��
C�ľֲ�����˵��
����K
��ִ�����
Ӧ�ó����ײ� C���ⲿ����˵��
�ⲿ˵���Σ�ORACLE����˵����
ͨѶ��˵��
Pro*CԴ���� ����1��ͬ����K��
����2��ͬ����K��
C�ֲ�����˵��
������ �ڲ�˵������ �ڲ�˵����
ͨѶ��˵��
����K C�Ŀ�ִ�����
��ִ����� SQL�Ŀ�ִ�����
��PL/SQL��
��. Pro*C�������ɽṹ
ÿһ��Pro*C�����������֣���1��Ӧ�ó����ײ�����2��Ӧ�ó�����
Ӧ�ó����ײ�������ORACLE���ݿ���йر����� Ϊ��C�����в���ORACLE���ݿ�����������Ӧ�ó������������Pro*C��SQL��������ɡ���Ҫָ��ѯSELECT��INSERT��UPDATE��DELETE����䡣
Ӧ�ó������ɽṹ��ͼ��ʾ��
EXEC SQL BEGIN DECLARE SECTION
��SQL�����Ķ��壩
EXEC SQL END DECLARE SECTION��
EXEC SQL INCLUDE SQLLA��EXEC SQL CONNECT��< �û���>
IDENTIFIED BY: < ���� >
SQL ��估�α��ʹ��
1. Ӧ�ó����ײ�
Ӧ�ó�����ײ�����Pro*C�Ŀ�ʼ���֡����������������֣�
�� C�����������֣�
��SQL�����������֣�DECLARE���֣���
��SQLͨ������
(1) .DECLARE���֣��������֣�
��������˵�������SQL������ ���岿����EXEC SQL BEGIN DECLARE SECTION ;��ʼ����
EXEC SQL END DECLARE SECTION �������ġ������Գ����ڳ����������Ҳ�ɳ����ھֲ�
SQL������˵����ʹ��
��˵������ΪSQL����ָ�����������������ʾ��
�������� ����
CHAR
CHAR(n)
INT
SHORT
LONG
FLOAT
DOUBLE
VARCHAR ���ַ�
n���ַ�����
����
������
�����ȸ�����
˫���ȸ�����
�䳤�ַ���
��Щ��������ʵ���Ͼ���C���Ե��������ͣ� ����VARCHAR����ΪC�������͵����䡣�����Ժ��̸����
SQL������ʹ��Ӧע�����¼��㣺
����������������ȷ����
����ʹ�����䶨����ͬ�Ĵ�Сд��ʽ
��SQL�����ʹ��ʱ����������֮ǰ��һ��������(ð��)������C���������ʱ�����ð�š�
������SQL�����еı����֡�
���Դ�ָʾ������
���磺EXEC SQL BEGIN DECLARE SECTIONS;
VARCHAR programe[30];
Int porgsal, pempno;
EXEC SQL END DECLARE SECTION;
EXEC SQL SELECT ENAME , SAL
INTO: programe, : progsal
FROM EMP
WHERE EMPNO = : pempno;
(2). ָʾ��������˵��������
ָʾ����ʵ����Ҳ��һ��SQL����,�������������������������������������SQL����г� �����������ı�������ÿһ�������������ɶ���һ��ָʾ����������Ҫ���ڴ�����ֵ��NULL��
ָʾ��������˵������ͬһ��SQL����һ���� �����붨���2�ֽڵ����ͣ���SHORT��INT����SQL���������ʱ��
��ǰҲӦ�ӡ�����(ð��)�����ұ��븽�������������������֮����C����У��ɶ���ʹ�á���ָʾ������Ϊ-1ʱ����ʾ��ֵ�����磺
EXEC SQL BEGIN DECLARE SECTION ;
INT dept- number;
SHORT ind �C num;
CHAR emp �Cname;
EXEC SQL END DECLARE SECTION ;
Scanf(��90d %s��, & dept- number , dept �C name );
If (dept �C number ==0)
Ind �C num = -1;
Else
Ind �C num = 0;
EXEC SQL INSERT INTO DEPT (DEPTNO, DNAME)
VALUES(:dept �C number : ind- num , :dept �C name);
����ind �C num��dept �C number ��ָʾ���������������dept �C number ֵ��0ʱ�� ����DEPT
����DEPTNO�в����ֵ��
��3��.ָ��SQL������˵����ʹ��
ָ��SQL����������ǰҲ������DECLARE ������˵������˵����ʽͬC���ԡ���SQL���������ʱ��ָ������ǰҪ��ǰ��������ð�ţ������ӡ�*�����Ǻţ�����C������÷���ͬC���Ե�ָ�������
��4��.����SQL�����˵��������
��SQL�������������ʱ��ֻ��д������������ǰ��ð�ţ��� ����д�±꣬��C������÷���ͬC���Ե����������
ʹ������ɴ�����紫�俪������Ҫ��һ������100�����ݣ����û�����飬��Ҫ�ظ�100�Σ� �����ú�ֻ��ִ��һ��insert��䡢���һ���Բ��롣���磺
EXEC SQL BEGIN DECLARE SECTION;
Int emp_number[100];
Char emp_name[100][15];
Float salary[100],commission[100];
Int dept_number;
EXEC SQL END DECLARE SECTION;
��.
EXEC SQL SELECT EMPNO,ENAME,SAL,COMM
INTO :emp_number,:emp_name,:salary,:commission
FROM EMP
WHERE DEPTNO=:dept_number;
��ʹ������ʱ��Ӧע�����¼��㣻
��֧��ָ������
ֻ֧��һά���飬 �� emp-name [100][15]��Ϊһά�ַ���
�������ά��Ϊ32767
��һ��SQL��������ö������ʱ����Щ����ά��Ӧ��ͬ
��VALUES , SET, INTO ��WHERE�����У� �������Ѽ�SQL����������SQL��������
������DELARE���ֳ�ʼ������
���磺����������ǷǷ���
EXEC SQL BEGIN DECLARE SECTION;
Int dept �C num [3] = {10,20,30};
EXEC SQL END DECLARE SECTION ;
EXEC SQL SELECT EMPNO, ENAME , SAL
INTO : emp �C num [ i ], : emp �C name [ i ], : salarg [ i ]
FROM EMP
(5) α����VARCHAR��˵��������
VARCHAR����������֮ǰҲ������˵����˵���� ˵��ʱ����ָ���������
���ȣ��磺
EXEC SQL BEGIN DECLARE SECTION��
Int book �C number;
VARCHAR book �C name [ 50 ];
EXEC SQL END DECLARE SECTION ;
��Ԥ����ʱ�� book �C name �������C�����е�һ���ṹ������
Struct { unsigned short len ;
Unsigned chart arr [ 20 ] ;
} boo �C name
�ɴ˿����� VARCHAR����ʵ�����Ǻ����ȳ�Ա�������Ա�Ľṹ��������SQL���������ʱ��Ӧ������ð��Ϊǰ�Ľṹ����
�������±꣬��C��� �����ýṹ��Ա��
VARCHAR���������������ʱ����ORACLE�Զ����ã� ����Ϊ�������ʱ������Ӧ�Ȱ��ַ������������Ա�У� �䳤�ȴ��볤�ȳ�Ա�У�Ȼ������SQL��������á����磺
Main( )
{ .......
scanf(��90s, 90d��, book �C name .arr, & book �C number );
book �C name .len = strlen (book �C name .arr);
EXEC SQL UPDATE BOOK
SET BNAME = : book �C name ;
BDESC = : book �C number ;
}
SQLͨ����
SQL ͨ��������������������ģ�
EXEC SQL INCLUDE SQLCA��
�˲����ṩ���û����г���ijɰܼ�¼�ʹ�������
SQLCA�����
SQLCA��һ���ṹ���͵ı���������ORACLE ��Ӧ�ó����һ���ӿڡ���ִ�� Pro*C����ʱ�� ORACLE ��ÿһ��Ƕ��SQL���ִ�е�״̬��Ϣ����SQLCA�У�
������Щ��Ϣ�����ж�SQL����ִ���Ƿ�ɹ���������������������Ϣ�ȣ�����������ʾ��
Struct sqlca
{ char sqlcaid [ 8 ] ; ----?��ʶͨѶ��
long sqlabc; ---? ͨѶ���ij���
long sqlcode; ---?�������ִ�е�SQL����״̬��
struct { unsigned short sqlerrml; -----?��Ϣ�ı�����
}sqlerrm;
char sqlerrp [ 8 ];
long sqlerrd [ 6 ];
char sqlwarn [ 8 ];
char sqlext [ 8 ];
}
struct sqlca sqlca;
���У� sqlcode�ڳ�������õ��������������ִ�е�SQL����״̬�롣����Ա������Щ״̬��������Ӧ�Ĵ�������Щ״̬��ֵ���£�
0: ��ʾ��SQL��䱻��ȷִ�У�û�з�����������⡣
>0:ORACLEִ���˸���䣬������һ�����⣨��û�ҵ��κ����ݣ���
<0:��ʾ�������ݿ⡢ϵͳ�������Ӧ�ó���Ĵ���ORACLEδִ�и�SQL��䡣
�����ִ������ʱ����ǰ����һ��Ӧ�ع���
2��Ӧ�ó�����
��Pro*C�����У� �ܰ�SQL����C������ɵػ����д��������SQL�����ʹ��SQL������Ƕ��ʽSQL������д�ķ��ǣ�
�Թؼ���EXEC SQL��ʼ
��C���Ե�����ս�����ֺţ��ս�
SQL����������Ҫ����ͬ���ݿ����C���Գ������ڿ��ƣ����룬��������ݴ����ȡ�
���ӵ�ORACLE���ݿ�
�ڶ����ݿ��ȡ֮ǰ�������Ȱѳ�����ORACLE���ݿ���������������¼��ORACLE�ϡ�����������Ӧ����Ӧ�ó���ĵ�һ����ִ��������������ʽ���£�
EXEC SQL CONNECT��< �û��� > IDENTIFIED BY : < ���� >
��EXEC SQL CONNECT�� < �û��� > / < ���� >
��ʹ���������ָ�ʽ���е���ʱ�� Ӧ��������˵���ζ�������û����Ϳ����
SQL ����������ִ��CONNECT֮ǰ�������ǣ��������ɵ�¼ʧ�ܡ����磺
EXEC SQL BEGIN DECLARE SECTION ��
VARCHAR usename [20];
VARCHAR password[20];
EXEC SQL END DECLARE
..........
strcpy ( usename.arr, ��CSOTT��);
usename.len = strlen (username.arr);
strcpy (password.arr , ��TIGER��);
password .len = strlen( password .arr);
EXEC SQL WHENEVER SQLERROR GOTO SQLERR;
EXEC SQL CONNECT :username INDNTIFIED BY : password;
ע��: ���ܰ��û����Ϳ���ֱ�ӱ�д��CONNECT����У����߰������ţ���������������ĸ����CONNECT ����У�
��������������Ч�ġ�
EXEC SQL CONNECT SCOTT INENTIFIED BY TIGER;
EXEC SQL CONNECT ��SCOTT�� IDENTIFIED BY ��TIGER��;
(2). ���롢���º�ɾ��
�ڽ���SQL����ʱ����ϸ������ ����Ͳ�����˵���ˡ�
(3). ���ݿ��ѯ���α��ʹ��
��PRO*C��, ��ѯ�ɷ�Ϊ��������:
���ص��л������IJ�ѯ;
���ض��еIJ�ѯ.���ֲ�ѯҪ��ʹ���α�������ÿһ�л�ÿһ�飨�����������飩.
���ص��л������IJ�ѯ
��PRO*C�еIJ�ѯSQL SELECT��������¼����Ӿ����:
SELECT
INTO
FROM
WHERE
CONNECT BY
UNION
INTERSECT
MINUS
GROUP BY
HAVING
ORDER BY
����WHERE�Ӿ��еIJ�ѯ����������һ�����Ի������Եļ���,��ִ���Ǹ�ֵ��������Ҳ�ɷ���WHERE�Ӿ���.WHERE�Ӿ������õ���������Ϊ�������������磺
SELECT EMPNO, JOB, SAL
INTO:PNAME, :PJOB, :PSAL
FROM EMP
WHERE EMPNO=:PEMPNO;
��û���ҵ�������, ��SQLCA.SQLCODE���ء�+1403��, ������û���ҵ�����
INTO�Ӿ��е�����������������������ṩ�˲�ѯʱ����Ҫ����Ϣ��
���κ�����������֮ǰ����Ҫ��ORACLE����Щ��ת�������������������͡�����������ͨ���ض�����ɵģ��磺9.23ת��Ϊ9����
�����ȷ����ѯֻ����һ�У���ô�Ͳ���ʹ���αֻ꣬��SELECT�������һ��INTO�Ӿ伴�ɡ���������INTO�����FROM֮ǰ�IJ�ѯ���ж��ٸ�ѡ������ж��ٸ����������������SELECT���б���ʽ����Ŀ������INTO�Ӿ�������������Ŀ���Ͱ�SQLCA.SQLWARN[3]��Ϊ��W����
2�����в�ѯ���α��ʹ��
�����ѯ���ض��л�֪�����ض����У�ʹ�ô���ORACLE�α꣨CURSOR����SELECT��䡣
�α���ORACLE��PRO*C��Ų�ѯ����Ĺ�������һ���α꣨�������ģ���һ��SELECT���������������α�����4�������1��DECLARE
CURSOR����2��OPEN CURSOR����3��FETCH����4��CLOSE CURSOR��
�����α�
һ���α�������ȶ��壬 ����ʹ�������Ϊ��
EXEC SQL DECLARE �������CORSOR FOR
SELECT ����
FROM ������
���磺
EXEC SQL DECLARE CSOR�� CURSOR FOR
SELECT ENAME �� JOB�� SAL
FROM EMP
WHERE DEPTNO=��DEPTNO��
������һ�����ѯ��������α�CURSOR֮�� ��SELECT��ѯEMPʱ�ɴ����ݿ��з��ض��У���Щ�о���CURSOR��һ�������
ע�⣺
�����α�����ڶ��α����֮ǰ��ɣ�
PRO*C��������û�ж�����αꣻ
�α궨��������÷�Χ�������������Զ�һ������������ ͬʱ����������ͬ���α��Ǵ���ġ�
B. ���α�
���α��OPEN�����Ҫ�������������������ݣ���Щ��Ҫ��WHERE��ʹ�õ������������α������ǣ�EXEC SQL
OPEN �������
�����α���Դ���صIJ�ѯ��ȡ������һ�еĽ�������������ѯ���������һ���ϣ��������α�������ͨ��ȡ����������е�ÿһ�л�ÿһ����һ��һ�����صģ���ѯ��ɺ�
�α�Ϳɹر��ˡ���ͼ��ʾ��
�����α꣺DECLARE
��ʼ��ѯ��SELECT���α꣺OPEN
�ӻ��ȡ���ݣ�FETCH
��ѯ���
�ر��α꣺CLOSE
ע�⣺1���α괦�ڻ���ĵ�һ��ǰ�棻
2�����ı��������������ͱ������´��αꡣ
C. ȡ����
�ӻ����ȡ��һ�л�һ��ѽ���͵�����������еĹ��̽�ȡ���ݡ�����������Ķ�����ȡ��������С�ȡ���ݵ�������£�
EXEC SQL FETCH�������INTO��������1��������2������
FETCH�Ĺ���������ͼ��ʾ��
��ѯ�����ѯ���
����
��ͼ��ʾ�IJ�ѯ���ָ�����ѯ�����IJ�ѯ�����ʹ��FETCHӦע�����¼��㣺
�α�����ȶ����ٴ�
ֻ�����α��֮�����ȡ���ݣ���ִ��FETCH��䡣
FETCH���ÿִ��һ�Σ��ӵ�ǰ�л�ǰ��ȡ����һ�Σ���һ�л���һ��������һ�Ρ��α�ÿ����ָ���л��鶼Ϊ��ǰ�л�ǰ�飬��FETCHÿ�ζ���ȡ�α���ָ�����л�������ݡ�
���α�����֮��ORCLE����һ��SQLCA��SQLCA��=1403����
��ϣ�����α��ٲ����� �����ȹر��ٴ�����
��C�����п��Կ���һ���ڴ�ռ䣬����Ų�������������������ÿ��ٵĿռ��������ݲ�ѯ�Ľ����
D���ر��α�
ȡ�����������к���ر��α꣬���ͷ�����α��йص���Դ��
�ر��α�ĸ�ʽΪ��
EXEC SQL CLOSE �����
���磺
EXEC SQL CLOSE C1��
ORACLE V5.0��֧��SQL��ʽ��CURRENT OF CURSOR����������佫ָ��һ���α�������ȡ�����У�
�������ĺ�ɾ������������������ȡ����֮��ʹ�ã�����ͬ�洢һ��ROWID����ʹ������
(4)������
EXEC SQL DECLARE SALESPEOPLE CURSOR FOR
SELECT SSNO�� NAME�� SALARY
FROM EMPLOYEE
WHERE DNAME=��Sales����
EXEC SQL OPEN SALESPEOPLE��
EXEC SQL FETCH SALESPEOPLE
INTO ��SS����NAME����SAL��
EXEC SQL CLOSE SALESPEOPLE��
��5��SQLǶ�ķ�����Ӧ��
Ƕ��SQL�뽻��ʽSQL����ʽ�������²��
��SQL���ǰ����ǰ��EXEC SQL���� ��һСС�IJ����Ŀ��������Ԥ����ʱ����ʶ������� �Ա��ÿһ��SQL��Ϊһ����������������
ÿһSQL����Ϊ˵�������Ϳ�ִ����������ࡣ��ִ������ַ�Ϊ���ݶ��塢���ݿ��ơ����ݲ��ݡ����ݼ����Ĵ��ࡣ
��ִ����SQL���д�ڸ����ԵĿ�ִ�д���˵����SQL���д�ڸ����Ե�˵���Եĵط���
���磺��PRO*C�����н���һ����ΪBOOK�ı��ṹ���������£�
#include��stdio.h��
EXEC SQL BEGIN DECLARE SECTION��
VARCHAR uid[20]�� pwd[20]��
EXEC SQL END DECLARE SECTION��
EXEC SQL INCLUDE SQLCA��
Main����
{
/*login database*/
strcpy(uid.arr,��wu��);
uid.len=strlen(uid,arr);
strcpy(pwd.arr,��wu��);
pwd.len=strlen(pwd.arr);
EXEC SQL CONNECT:uid IDENTIFEED BY:pwd;
EXEC SQL CREATE TABLE book
( acqnum number, copies number , price number);
EXEC SQL COMMIT WORK RELEASE;
EXIT;
PRO*C�ɷdz�������ط���ORCLE���ݿ��е����ݣ�ͬʱ�־���C���Ը��ٵ��ص㣬��������һЩORACLE��Ʒ������ɵ�������������һ���̶��������ʽ��������
SQLǶ��Դ����ʾ��
#unclude<stdio.h>
typedef char asciz[20];
EXEC SQL BEGIN DECLARE SECTION;
EXEC SQL TYPE asciz IS STRING (20) REFERENCE;
asciz username;
asciz password;
asciz emp_name(5);
int emp_number(5a);
float salary[5];
EXEC SQL END DECLARE SECTION;
EXEC SQL INCLUDE sqlca;
Void print_rows();
Void sqlerror();
Main()
{
int num_ret;
strcpy(username,��SCOTT��);
strcpy(password, ��TYGER��);
EXEC SQL WHENEVER SQLERROR DO sqlerror();
EXEC SQL CONNECT:username IDENTIFIED BY:password;
Print (��\nConnected to ORACLE as user:%s\n��, username);
EXEC SQL DECLARE c1 CURSOR FOR
SELECT EMPNO , ENAME , SAL FROM EMP;
EXEC SQL OPEN c1;
Num_ret = 0;
For(;;)
{
EXEC SQL WHENEVER NOT FOUND DO break;
EXEC SQL FETCH c1 INTO : emp_number , :emp_name , :salary;
Print_rows (sqlca.sqlerrd[2] �C num_ret);
Num_ret=sqlca.sqlerrd[2];
}
if ((sqlca.sqlerrd[2] �C num_ret)>0);
print _rows(sqlca.sqlerrd[2] �Cnum_ret);
EXEC SQL CLOSE c1;
Printf(��\Have a good day.\n��);
EXEC SQL COMMIT WORK RELEASE;
}
void print_rows(n);
int n;
{
int i;
printf(��\nNumber Employee Salary\n��);
printf(��------------------------------\n��);
for (i=0;i<n; i++ )
printf(��% - 9d%- 8s%9.2f\n��,emp-number[i], emp---name[i],salary[i];
}
void sqlerror()
{
EXEC SQL WHENEVER SQLERROR CONTINUE;
Printf(��\noracle error detected:\n��);
Printf(��\n%.70s\n��, sqlca.sqlerrm.sqlerrmc);
EXEC SQL ROLLBACK WORK RELEASE;
Exit(1);
}
(6) ������ͻָ�
��ʹ��SQL����PRO*C�����ݿ���в���ʱ���������ֶο�ֵ��������ɾ�������з��أ���������ͽضϵ����������������������SQLCA��ָʾ����������⡣
1 SQLCA�Ľṹ
��PRO*C������SQLCA�ṹ���£�
STRUCT SQLCA{
Char sqlcaid[8];
Long sqlabc;
Long sqlcode;
STRUCT{
Unsigned sqlerrm1;
Char sqlerrmc[10];
}sqlerrm;
Char sqlerrp[8];
Long sqlerrd[6];
Char sqlwarn[8];
Char sqlext[8];
}
����
SQLCA.sqlerrm.sqlerrmc������SQLCA��SQLCODE�Ĵ������ġ�
SQLCA.sqlerrd:��ǰORACLE��״̬��ֻ��SQLCA.SQLERRD[2]�����壬��ʾDML��䴦����������
SQLCA.sqlwarn:�ṩ����������������Ϣ��
��ÿִ��һ��SQL����ORACLE�Ͱѷ��ؽ������SQLCA�У���˵�������⡣
��SQLCA���Բ鿴SQL����ִ�н�������������ֽ����
=0��ִ�гɹ���
SQLCA.SQLCODE= >0��ִ�гɹ���״ֵ̬��
<0��ʧ�ܣ�����������ִ�С�
2 ָʾ������
ָʾ��������ʱҲ��ָʾ����.ָʾ������һ�������������,ָ���������ķ������.
=0������ֵ��Ϊ��, δ���ض�,ֵ������������;
����ֵ= >0������ֵΪ��, ������������ֵ;
<0�����������Ȳ����ͱ��ضϡ�
ʹ��ָʾ����Ҫע�⣺
��WHERE�Ӿ��в�����ָʾ��������NULL���������Կ�ֵ��
���������Ӿ䣺
SELECT��
FROM��
WHERE ENAME IS NULL��
����ȷ�ģ���
WHERE ENAME=��PEME��PEME1
�Ǵ���ġ�
ָʾ�����ڲ����ֵ֮ǰΪ��1
�������ֵ��
3 WHENEVER���
WHENEVER��˵����䣬������SQLCODE�� ֻ�Ǹ���SQLCA�еķ�����ָ����صĴ�ʩ����ʽΪ
EXEC SQL WHENEVER [SQLERROR|SQLWARNING|NOTFORUND]
[STOP|CONTINUE|GOTO<���>];
����
��1��[STOP|CONTINUE|GOT<���>]��ȱʡֵΪCONTINUE��
��2��SQLERROR��SQLCA.SQLCODE<0;
��3��SQLWARNIGN��SQLCA.SQLWARN[0]=��W����
��4��NOTFOUND��SQLCA.SQLCODE=1403��
�������һ�γ�����˵��WHENEVER���÷���
EXEC SQL BEGIN DEELARE SECTION��
VARCHAR UID[20]��
VARCHAR PASW[20]��
����
EXEC SQL END DECLARE SECTION��
EXEC SQL INCLUDE SQLCA��
Main����
{
����
EXEC SQL WHENEVER SQLERROR GOTO ERR��
EXEC SQL CONNECT��UID/��PWD��
����
EXEC SQL DECLARE CSOR1 CURSOR FOR
SELECT ���ֶΡ�
FORM������
EXEC SQL OPEN CSOR1��
SQL
����
EXEC SQL WHENEVER NOT FOUND GOTO good��
For��������
EXEC SQL FETCH CSOR�� INTO����
Good��
����
printf����\n��ѯ����\n����;
EXEC SQL CLOSE C1;
EXEC SQL WHENEVER SQLERROR CONTINUE.
EXEC SQL COMMIT WORK RELEASE:
Exit();
Printf(��\n%70s|n��, sqlca.sqlerrm.sqlerrmc);
EXEC SQL ROLLBACK WORK RELEASE:
Exit(1);
}
(7) ��̬�������
SQL���ֶ�̬�������;�̬����������֣�
��̬������䣺SQL������ȱ���PRO*C�У��ھ���Ԥ����������֮���γ�Ŀ�����*��BOJ��Ȼ��ִ��Ŀ�����Ԥ���ɡ�
��̬������䣺��Щ��䲻������Ƕ�뵽PRO*C�����У�Ҫ���ݳ�������������û��Լ��������豸�ϣ����ն��ϣ�ʵʱ���뼴��ִ�е�SQL��䡣
��̬��������У�
EXECUTE IMMEDIATE��
PREPARE ��EXECUTE��
PREPARE��FETCH �� OPEN ��
BIND��DEFINE DESCRIPTOR��
EXECUTE IMMEDIATE���
������ʾ����ִ�У� ����ֻ��SQLCA����ִ�н������������Ϣ�����磺
EXEC SQL BEGIN DECLARE SECTION��
VARCHAR abcd[89];
VARCHAR deay[20];
EXEC SQL END DECLARE SECTION;
/** ����ַ�����abcd **/
EXEC SQL EXECUTE IMMEDIATE :abcd;
ע�⣺
EXECUTE IMMEDIATEֻ�����д�һ�������Ķ�̬��䡣���У�abcd�Dz��������ǹؼ��֡�
EXECUTE IMMEDIATEʹ�õ��Ⱦ������ǣ�SQL��䲻�ܰ�����������SQL��䲻���Dz�ѯ��䡣
�����κ���������ΪEXECUTE IMMEDIATE�IJ�����Ҳ�����ַ�����Ϊ��������
PREPARE��EXECUTE���
������ʾ��Ԥ����/ִ�С���������ܹ�Ԥ����һ�ζ�ִ�ж�Ρ��Ϊ��
EXEC SQL PREPARE ���������FROM����������
EXEC SQL EXECUTE���������[USING���滻������]��
PREPARE����������£�
Ԥ����SQL��䣻
����SQL�����������
ע�⣺
SQL��䲻���Dz�ѯ��䣻
PREPARE��EXECUTE�ɰ�����������
PREPARE���ܶ��ִ�С�
���磺<example.pc>
#define USERNAME ��SCOTT��
#define PASSWORD ��TIGER��
#include <stdio.h>
EXEC SQL INCLUDE sqlca;
EXEC SQL BEGIN DECLARE SECTION;
Char * username=USERNAME;
Char * password=PASSWORD;
VARCHAR sqlstmt[80];
Int emp_number;
VARCHAR emp_name[15];
VARCHAR job[50];
EXEC SQL END DECLARE SECTION;
Main()
{
EXEC SQL WHENEVER SQLERROR GOTO :sqlerror;
EXEC SQL CONNECT :username IDENTIFIED BY :password;
Sqlstmt.len=sprintf(sqlstmt.arr,��INSERT INTO EMP (EMPNO,ENAME,JOB,SAL)
VALUES(:V1,:V2,:V3,:V4)��);
Puts(sqlstmt.arr);
EXEC SQL PREPARE S FROM :sqlstmt;
For(;;)
{
printf(��\nenter employee number:��);
scanf(��%d��,&emp_number);
if (emp_number==0) break;
printf(��\nenter employee name:��);
scanf(��%s��,&emp_name.arr);
emp_name.len=strlen(emp_name.arr);
printf(��\nenter employee job:��);
scanf(��%s��,job.arr);
job.len=strlen(job.arr);
printf(��\nenter employee salary:��);
scanf(��%f��,&salary);
}
EXEC SQL EXECUTE S USING :emp_number,:emp_name,:job,:salary;
}
FETCH����OPEN���
FETCH����OPEN������鶯̬����Ƕ��α���в����ģ���ִ�й������£�
PREPARE���������FROM ���������ַ�������
DECLARE�������FOR�����������
OPEN ���α�����[USING���滻����1[�����滻�����䡭]]
FETCH�������INTO�� ������1[����������2��]
CLOSE�������
ע�⣺
SQL�������ʹ�ò�ѯ��䣻
SELECT�Ӿ��е��������ܶ�̬�ı䣬ֻ��Ԥ�ã�
WHERE��ORDER BY �Ӿ���Զ�̬�ı�������
Pro*C�ı��������
����ORACLEԤ������PROC��PRO*C�������Ԥ�������ñ�������Դ������Ƕ���SQL���Է����C���ԣ�����һ��C���Ա�������ֱ�ӱ�����ļ��������ļ�����չ��Ϊ
.C
��C���Ա�����CC ����չ��Ϊ .c���ļ�����,����Ŀ�����ļ�,����չ��Ϊ .o
ʹ��MAKE����,����Ŀ�����ļ�,���ɿ������ļ�
����: �������example.pc���������
PROC iname=example.pc
CC example.c
MAKE EXE=example OBJS=��example.o��
example
SQL���Լ��
һ. SQL����
SQL��һ���������ݿ��ͨ�����ݴ������Թ淶����������¼���ܣ���ȡ��ѯ���ݣ�������ɾ�����ݣ������ĺ�ɾ�����ݿ�������ݿⰲȫ���ƣ����ݿ������Լ����ݱ������ơ�
���ݿ�������������ͼ��������ͬ��ʡ��ء������������������̡��������ݿ��������յȣ����ռ䡢�ع��Ρ���ɫ���û��������ݿ�ͨ���Ա��IJ����������洢�����е����ݡ�
1) SQL*PLUS���棺
��¼������SQLPLUS�س���������ȷ��ORACLE�û������س��������û�����س�����ʾ��ʾ����SQL>
�˳�������EXIT���ɡ�
2������ı༭�����У�
? ��������ʾ��������SQL������У��ԷֺŽ������룻��б�ܽ������룻�Կ��н������룻
? ����SQL����������PL/SQL��ı༭�����У�
? ���������ļ�����PL/SQL��ı༭�����С�
1�� ���ݿ��ѯ
1�� ��SELECT���ӱ�����ȡ��ѯ���ݡ��Ϊ
SELECT [DISTINCT] {column1,column2,��} FROM tablename WHERE
{conditions} GROUP BY {conditions} ORDER BY {expressions}
[ASC/DESC];
˵����SELECT�Ӿ�����ָ���������ݿ������Щ�У�FROM�Ӿ�����ָ������һ��������ͼ�м������ݡ�
2�� SELECT�еIJ������������ѯWHERE�Ӿ䡣(LIKE,IS,��)
WHERE�Ӿ��е�����������һ�������ȺŻȺŵ���������ʽ��Ҳ������һ������IN��NOT IN��BETWEEN��LIKE��IS
NOT NULL�ȱȽ������������ʽ�����������ɵ�һ����������ͨ�����������ϳɸ���������
3�� ORDER BY �Ӿ�
ORDER BY �Ӿ�ʹ��SQL����ʾ��ѯ���ʱ���������а�˳�����У������е�����˳����ORDER BY �Ӿ�ָ���ı���ʽ��ֵȷ����
4�� ���Ӳ�ѯ
����SELECT���������ݿ��ѯʱ�����Ѷ��������ͼ�����ݽ��������ʹ�ò�ѯ�����ÿһ���а������Զ������ʽ����ͼ�����ݣ����ֲ�������Ϊ���Ӳ�ѯ��
���Ӳ�ѯ�ķ�������SELECT�����FROM�Ӿ���ָ�����������������Ӳ�ѯ�ı�����ͼ��������WHERE�Ӿ����ORACLE��ΰѶ���������ݽ��кϲ�������WHERE�Ӿ��е���������ʽ�ǵȻ��Dz���ʽ���������Ӳ�ѯ��Ϊ��ʽ���ӺͲ���ʽ���ӡ�
5�� �Ӳ�ѯ
���ijһ��SELECT�����ѯ1����������һ��SQL�����ѯ2����һ���Ӿ��У���Ʋ�ѯ1�Dz�ѯ2���Ӳ�ѯ��
2�� �����������ͣ�NUMBER,VARCHAR2,DATE�� O
RACEL֧�������ڲ��������ͣ�
��VARCHAR2 �䳤�ַ������Ϊ2000�ַ���
��NUMBER ��ֵ�͡�
��LONG �䳤�ַ����ݣ��Ϊ2G�ֽڡ�
��DATE �����͡�
��RAW ���������ݣ��Ϊ255�ֽڡ�
�� LONG RAW �䳤���������ݣ��Ϊ2G�ֽڡ�
��ROWID �������ƴ�����ʾ�����е�Ψһ��ַ��
��CHAR �����ַ����ݣ��Ϊ255��
3�� ���ú����÷���
һ������������һ����������������������һ������������ڸ�ʽ�ϲ�ͬ��������������б�Ԫ���ɲ���0����һ��������������Ԫ����ʽΪ��
����������Ԫ����Ԫ������
������������һ�����Σ�
�� �����
����麯��
1�� ���к����Բ�ѯ�ı�����ͼ��ÿһ�з���һ������С�������ֵ�������ַ����������ں�����ת�������ȡ�
2�� ���麯�����صĽ���ǻ�����������ǵ��У����Է��麯����ͬ�ڵ��к�������������麯���п�������ѡ�
�� DISTRNCT ��ѡ��ʹ���麯��ֻ���DZ�Ԫ����ʽ�еIJ�ֵͬ��
�� ALL��ѡ��ʹ���麯������ȫ��ֵ������ȫ���ظ���
ȫ�����麯������COUNT��*���⣩���Կ�ֵ��������з��麯���IJ�ѯ��û�з����л�ֻ�п�ֵ�����麯���ı�Ԫȡֵ���У�������麯�����ؿ�ֵ��
5�� ���ݲ����������
���ݿ�������ԣ�DML���������ڲ�ѯ�Ͳ���ģʽ�����е����ݣ�������ʽ���ύ��ǰ����������UPDATE��INSERT��DELETE��EXPLAIN
PLAN��SELECT��LOCK TABLE ������������һ�£�
1) UPDATE tablename SET {column1=expression1,column2=expression2,��}
WHERE {conditions};
���磺S QL>UPDATE EMP
SET JOB =��MANAGER��
WHERE ENAME=��MAPTIN��;
SQL >SELECT * FROM EMP;
UPDATE�Ӿ�ָ����Ҫ�ĵ����ݿ���EMP,����WHERE�Ӿ�������ֻ������(ENAME)Ϊ��MARTIN����ְ�������ݽ�����,SET�Ӿ���˵���ĵķ�ʽ,���ѡ�MARTION���Ĺ�������(JOB)��Ϊ��MARAGER��.
2) INSERT INTO tablename {column1,column2,��} VALUES {expression1,expression2,��};
���磺SQL>SELECT INTO DEPT��DNAME�� DEPTNO��
VALUES ����ACCOUNTING����10��
3) DELETE FROM tablename WHERE {conditions};
���磺SQL>DELETE FROM EMP
WHERE EMPNO = 7654;
DELETE����ɾ��һ����¼,����DELETE����ֻ��ɾ������,������ɾ��ij���еIJ�������.
4�� �����������
�ύ����(COMMIT):����ʹ���ݿ�������û�.����AUTOCOMMITΪ����״̬:SQL >SET AUTOCOMMIT
ON;
�ع�����(ROLLBACK):������һ��COMMIT������������ȫ����,ʹ�����ݿ�����ݻָ�����һ��COMMITִ�к��״̬.ʹ�÷�����:
SQL>ROLLBACK;
4�� ����������ͼ��������ͬ��ʡ��û���
1�� �����Ǵ洢�û����ݵĻ����ṹ��
��������Ҫָ����������Ϣ��
�����
��������Լ��
������ڱ��ռ�
��洢����
���ѡ��ľۼ�
���һ��ѯ�������
����£�CREATE TABLE tablename
(column1 datatype [DEFAULT expression] [constraint],
column1 datatype [DEFAULT expression] [constraint],
������
[STORAGE�Ӿ�]
[�����Ӿ䡭]��
���磺
SQL>CREATE TABLE NEW_DEPT
(DPTNO NUMBER(2),
DNAME CHAR(6),
LOC CHAR(13);
���ı����ã�
�� ������
������������Լ��
�����¶����У��������͡����ȡ�ȱʡֵ��
���Ĵ洢��������������
��ʹ�ܡ�ʹ���ܻ�ɾ��һ������Լ������
����ʽ�ط���һ����Χ
2������ͼ
��ͼ��һ�������������������ߴ�����������ͼ��ȡ���ݣ���ͼ�������������ݡ���ͼ�����ڵı���Ϊ������
������ͼ���������ã�
���ṩ���ӵı���ȫ�������ƴ�ȡ�������л�/���м��ϡ�
�� �������ݸ����ԡ�
��Ϊ�����ṩ��һ�ֹ۵㡣
���ʹORACLE��ijЩ�����ڰ�����ͼ�����ݿ���ִ�У���������һ�����ݿ���ִ�С�
3��������
�����������ݿ�������ڱ���ۼ����������ϵ�ÿһֵ������һ�Ϊ���ṩֱ�ӵĿ��ٴ�ȡ�����������ORACLE�����������Ľ����ܣ�
��ָ���������е�ֵ�����С�
�������е�˳���ȡ����
���������� CREATE [UNIQUE] INDEX indexname ON tablename(column
,������)��
���磺SQL>CREAT INDEX IC_EMP
ON CLUSTER EMPLOYEE
4����ͬ���
ͬ��ʣ�Ϊ������ͼ�����С��洢�������������ջ�����ͬ��ʵ���һ�����֡�ʹ��ͬ���Ϊ�˰�ȫ�ͷ��㡣��һ������ͬ��ʿ������кô���
�����ö�����ָ������ij����ߡ�
�����ö�����ָ������λ�ڵ����ݿ⡣
��Ϊ�����ṩ��һ�����֡�
����ͬ��ʣ�
CREATE SYNONYM symnon_name FOR [username.]tablename;
���磺CREAT PUBLIC SYNONYM EMP
FOR SCOTT.EMP @SALES
5�����û�
CREATE USER username IDENTIFIED BY password;
���磺SQL>CREATE USER SIDNEY
IDENTIFIED BY CARTON ;
��. Oracle��չPL/SQL���
1�� PL/SQL������
PL/SQL��Oracle��SQL�淶����չ����һ�ֿ�ṹ���ԣ�������һ��PL/SQL����Ļ�����λ�����̡������������飩�����飬�ɰ����κ���Ŀ��Ƕ���˿졣���ֳ���ṹ֧��������������⡣һ���飨���ӿ飩��������ص�˵������������һ������ʽΪ��
DECLARE
---˵��
BEGIN
---�������
EXCEPTION
---���������
END��
���������ŵ�:
��֧��SQL;
�������ʸ�;
�����ܺ�;
��ɳ�ֲ��;
����ORACLE����.
2�� PL/SQL��ϵ�ṹ
PL/SQL����ϵͳ���ּ���������һ�ֶ�����Ʒ������Ϊ���ּ�����PL/SQL����ӳ����һ�ֻ������ɽ����κ���Ч��PL/SQL����ӳ�����ͼ��ʾ��
PL/SQL����ִ�й�������䣬����SQL��䷢�͵�ORACLE�������ϵ�SQL���ִ��������ORACLEԤ��������OCI�����п�Ƕ��������PL/SQL�顣���ORACLE����PROCEDURALѡ����������PL/SQL�飨�ӳ��ɵ������룬���õش洢�����ݿ��У���ִ�С�
3�� PL/SQL������
PL/SQL��һ�ַ����������֡���㡢�������͡�������ȣ�����SQL����ͬ��ʾ�����ص���ܡ�
1�����������ͣ����±���ʾ
�������� ������
�������� ��ֵ BINARY_INTEGER NATURAL,POSITIVE
NUMBER DEC,DECIMAL,DOUBLE PRECISION,PLOAT,INTEGER,INT,NUMERIC,REAL,SMALLINT
�ַ� CHAR CHARACTER,STRING
VARCHAR2 VARCHAR
LONG
LONG RAW
RAW
RAWID
�� BOOLEAN
���� DATE
���
���� ��¼ RECORD
�� TABLE
2���������ͳ���
��PL/SQL�����пɽ�ֵ�洢�ڱ����ͳ����У�������ִ��ʱ��������ֵ���Ըı䣬��������ֵ���ܸı䡣
3���������ʽ�ṹ��
DECLARE
����˵�����֣�
BEGIN
ִ����䲿�֣�
[EXCEPTION
��������֣�]
END;
4�� ������䣺
��֧��䣺
IF condition THEN
Sequence_of_statements;
END IF;
IF condition THEN
Sequence_of_statement1;
ELSE
Sequence_of_statement2;
END IF;
IF condition1 THEN
Sequence_of_statement1;
ELSIF condition2 THEN
Sequence_of_statement2;
ELSIF condition3 THEN
Sequence_of_statement3;
END IF;
5�� ѭ����䣺
LOOP
Sequence_of_statements;
IF condition THEN
EXIT;
END IF;
END LOOP;
WHILE condition LOOP
Sequence_of_statements;
END LOOP;
FOR counter IN lower_bound..higher_bound LOOP
Sequence_of_statements;
END LOOP;
6�� �ӳ���
�洢���̣�
CREATE PROCEDURE ������ (����˵��1������˵��2�� ������) IS
[�ֲ�˵��]
BEGIN
ִ����䣻
END ��������
�洢������
CREATE FUNCTION ������ (����˵��1������˵��2�� ������)
RETURN ���� IS
[�ֲ�˵��]
BEGIN
ִ����䣻
END ��������
|