|
梗概禁止改变对象的状态,从而增加共享对象的坚固性、减少对象访问的错误,同时还避免了在多线程共享时进行同步的需要。 实现方法:在对象构造完成以后就完全禁止改变任何状态信息。如果需要改变状态,则生成一个状态与原对象不同的新对象。 场景假设你正在为一家游戏公司开发一个和外太空、宇宙飞船有关的游戏,当然你有必要用某种方式来表示一艘宇宙飞船(不管它是属于地球人的还是属于外星人的)所处的位置。很自然的,你决定编写一个Position类。从一个Position对象应该可以查询到当前位置的x坐标和y坐标(我们的游戏比较简单,二维地图,呵呵),还应该可以根据输入的偏移量得到新的位置。很正确的设计,不是吗?(见例1) 例1:Position的设计 class Position{
private:
int x, y; //简单点,用整型数来表示坐标
public:
Position(int x, int y){ //ctor需要两个参数。
this->x = x;
this->y = y;
}
int getX( ){ return x; }
int getY( ){ return y; }
void Offset(int offX, int offY){ //根据偏移量得到新的位置
x+=offX;
y+=offY;
}
}
但是,如果我们的Position需要在多线程环境下使用,它能保证线程安全吗?答案是很明显的No!如果两条线程同时调用同一个Position对象的Offset函数,你就无法保证得到的结果是什么了。所以,为了保证线程安全,也许你还会想给Offset函数加上同步机制――麻烦了!
换个角度想想怎么样?假如我们根本不让Offset函数修改Position的内容?假如我们让Offset函数生成一个新的Position对象?如果是这样,Position对象就已经是线程安全的了――它没有任何“写”操作,而没有写操作的类是不需要同步的。于是我们这样做了,并且很轻松的得到了一个线程安全的Position类。(见例2) 例2:线程安全的Position类(这里只展示Offset函数) Position Position::Offset(int offX, int offY){ //根据偏移量得到新的位置
return Position(x+offX, y+offY);
}
约束
解决方案为了避免状态改变带来的诸多麻烦,不允许对实例的状态做任何修改。具体的做法就是:不在类的公开接口中出现任何可以修改对象状态的方法,只出现状态读取方法。如果client需要不同的状态,就生成一个新的对象。(见图1)
效果
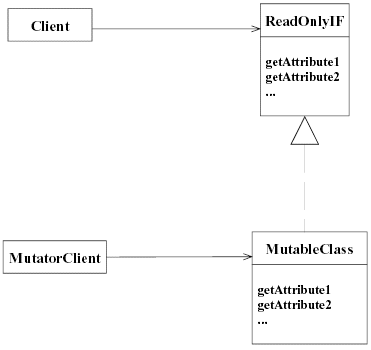
Immutable模式的实现主要有以下两个要点: 1.除了构造函数之外,不应该有其它任何函数(至少是任何public函数)修改任何成员变量。 在“效果”中我已经讲到:Immutable模式会大大提高对象生成和销毁的频率。因此,在C++中实现Immutable模式时,还必须特别注意对象的生存周期。你可以尝试用智能指针[Meyers96, Item28]来帮助你处理对象的销毁问题,但是无论如何你都必须仔细检查以确保没有内存泄漏――如果每艘飞船的每次移动都会造成内存泄漏,你的游戏该是多么糟糕! 此外,Immutable模式还有一种变体:Read Only Object模式。它的做法是:当一个类的对象对于某些client可写、某些client不可写时,让这个类实现一个ReadOnly接口。然后让可写的client直接访问对象,而让不可写的client通过ReadOnly接口访问该对象,从而实现了不同的读写权限控制。(如图2所示)
Immutable模式与string类的实现策略如果你也读过[Meyers96],我想你一定对那个应用在String类上的COW(Copy-On-Write)策略[Meyers96, Item29]印象深刻。COW策略是“lazy evaluation”的发展形式。如果对String类的写操作数量很少,那么COW策略将大大提高整个String类的效率,并大大降低空间开销。 可是你知道吗?在STL中的string类并没有采用COW策略,从例3就可以看出这一点。为什么?为什么这么好的策略没有得到采用?相信你从[Meyers96]中便可发现:实际在String类上实现COW策略是如此复杂。更何况我们还必须考虑线程安全的问题。我完全有理由认为:正是因为考虑到这些复杂的情况,STL的实现者们才最终决定用一个比较低效但是安全的实现方案。 例3:STL中的string::operator=和string::operator[] //下面代码出自SGI STL 2000年6月8日版本
//为了帮助读者理解,我做了些微改动,并在关键位置加上注释
//如果使用COW策略,operator=应该不做内容复制,而是进行引用计数
string& string::operator=(const string& s) {
if (&s != this)
assign(s.begin(),s.end()); // 这里的operator=只是简单的内容复制而已
return *this;
}
//如果使用COW策略,const的operator[]和非const的operator[]应该不同
//但是这里两个operator[]完全相同
const char & string::operator[](int n) const
{ return *(_M_start + n); } //_M_start是字符数组的起始位置
char & string::operator[](int n)
{ return *(_M_start + n); }
看到这些,我不能不开始猜想:为什么STL的设计者们一定要保留这些给他们造成麻烦的“修改函数”(即可以修改string内容的函数)?我想,这是因为他们希望让string的行为方式尽量接近于C语言的char *型字符串。不然,我真的想不出其他任何保留operator[]的理由。 那么,如果不必非要让string类的行为方式接近char *型字符串,如果string类的读操作应用频率远远大于写操作(在实际应用中这是很常见的),你会考虑如何实现一个string类?啊,也许你已经想到了:Immutable模式。你可以很舒服的使用[Meyers96]教你的引用计数方法来节约存储空间,你不必再担心写操作的同步问题或别的什么,因为已经没有写操作。任何改变字符串内容的操作都将得到一个新的string对象。而对象生存期管理和存储空间管理这两个大问题也因为Immutable模式的引入而大大简化,你完全可以参照[Meyers96]第183页到第189页的内容自己来解决它们。 代码示例我用了一天的时间,做了一个简单的ImmutableString实现。其中实现细节用了Proxy类[Meyers96],并参考了COM的引用计数规则[Pan99]。在这个例子中,读者可以感觉到:Immutable模式大大简化了共享空间的字符串类型的实现,并为其中的一些方法(比如subString)的实现提供了非常大的便利。本来我想把代码放在文章里面,但是时间和空间受限,最后决定放弃。 在该代码中,我做了一个简单的效率测试:反复进行字符串对象的赋值(operator=)操作。结果表明:ImmutableString的效率比std::string高出了一倍左右。假如你的业务就是不断的读取数据库、不断的赋值、不断的输出,而不对字符串进行修改,那么ImmutableString的效率提升是非常可观的。 该示例代码在VC .NET下编译通过。 相关模式经常会使用Abstract Factory模式[GOF95]来创建新的对象。 大量的对象经常通过Flyweight模式[GOF95]被共享。 参考书目[Meyers96] Scott Meyers, More Effective C++, Addison-Wesley, 1996. [GOF95] Erich Gamma etc., Design Patterns: Elements of Reusable Object-Oriented Software, Addison-Wesley, 1995. 中译本:《设计模式:可复用面向对象软件的基础》,李英军等译,机械工业出版社,2000 年9月。 [PAN99] 潘爱民,《COM原理与应用》,清华大学出版社,1999年11月。 |