这一章的内容基于学习笔记的观察和测量模式,所以,请首先阅读观察和测量的内容。 在大规模的企业中,高层的问题很容易被发现,但是要发现这些问题的根源却比较困难,因为这样的企业会产生大量的信息,以至于很容易分析人员就被淹没在这些信息当中了。 例如,一个企业最主要的财务表现是它的最终财政收入,如果财政收入有问题,就必须找出引起问题的原因。在ACM(Aroma Coffee Makers)的财政收入中表明他们的设备销售收入减少了,尽管花费还同样可观。这个问题在ACM的东北区域最为严重;继续深入追究发现他们的11-10单元低于计划收入,尤其是面向政府的部门,到这里为止,这些分析的大部分仍然是数据的形式;进一步分析可能给出定性的结果:可能是由于无力的销售补偿计划,或政府预算缩减,或炎热的夏季,或出现了强劲的竞争对手,等等。 这样的分析过程非常类似于医生对病人症状的分析:根据显著的外在症状,用专业知识跟踪可能的病因,然后对症下药。这种类似性让我们意识到,噢,也许观察和测量模式可以应用到金融分析中来。让人高兴的是,确实如此,那些模式非常适用,只需要做一些适当的调整,而且调整基本上是对已有模型的扩展,而不是改变。 下面我们就来看这些模式和它们新的应用。 1.1
企业部门单元(Enterprise
Segment[1])
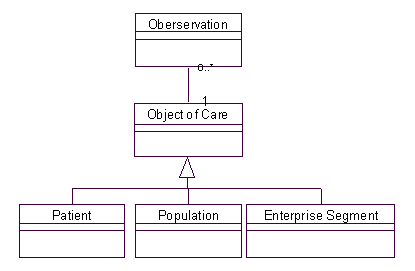
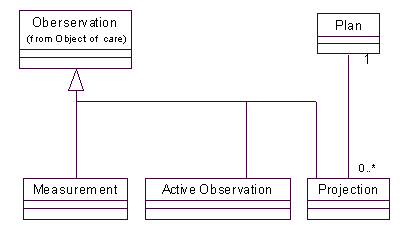
首先我们要做的小小补充是引入Object of Care来表示被观察和测量的对象,在前一章中,观测的对象是Patient,而我们现在关心的对象是企业的部门,所以增加一个抽象层次,让Patient和Enterprise Segment都成为它的子类;我们顺便介绍一个Population类(人口)来代表“人”的群体,我们知道,对于人口而言,也有很多有意义的观测工作,这是题外的话。引入的抽象关系请看下图所示:
图1
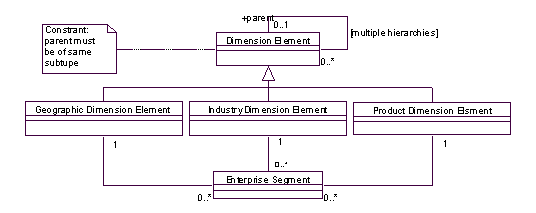
Object of Care和它的子类 在这里还要提一下Enterprise Segment(企业部门单元)的来历,当我们面对一个企业时,总是可以根据一些原则来把它划分成不同的单元/部门,根据地理位置,根据产品,根据产品销售的目标行业,等等。例如一家国际性的公司可以首先根据市场划分(例如美国),然后根据区域(Region)划分(例如东北地区),然后根据地区(Area)划分(例如新汉普)。这些独立的层次中每一个方面都是一个维数(Dimension,即市场,区域,等);而新汉普和东北地区是“地理位置”维数中不同层次的两个元素;一个Enterprise Segment(企业部门单元)是各维数元素的结合,即取每个维数的一个元素构成,例如ACM的一个部门可以这样描述:东北,11-10,政府部门;东北是地理位置,11-10是产品型号,政府部门是销售对象。 通过这样定义Enterprise Segment(企业部门单元),我们得到一个企业结构的描述模型,如图所示(见下页):
图2
用维数元素定义企业部门单元 这个模型基本解决问题,可以方便定义层次,以及反映了三个不同的维数元素,也反映了企业部门单元和维数元素的关系,但是很快可以看到,在这里,维数被局限在三个:也就是说,如果维数需要改变,那么整个模型都需要更改,那是我们不希望看到的。因此稍作改进之后,得到以下一个模型:
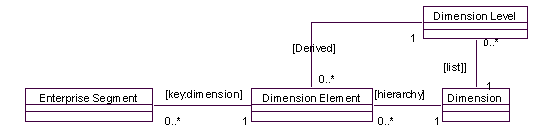
在这个模型里,增加维数变得容易了,而且,用关键字映射(keyed mapping)以及数量上的约束来保证Enterprise Segment在每个维数上仅对应一个Dimension Element。 每一个层次都需要一个顶层元素,可以定义为“all”,或者“空(nil)”。 如果考虑到维数级别(Level),可以修改上面的模型如下:
在这里,可以定义每一个维数元素的级别,而级别由这个元素在维数层次中的位置决定的,例如,在维数层次中,元素新汉普的上级是东北地区,再上级是美国,往上是all,所以它的级别为3,得到维数级别在list中对应的结果是地区(Area)。 1.1.1
定义维数(Defining
the Dimensions)
要得到比较合理的Enterprise Segment(企业部门单元)定义,维数(Dimension)的定义也是很重要的一个环节。最简单的方法是遵循某种显而易见的组织结构,但是不同的分析会有不同的侧重点,所以这样也并不是每次都可行。 一个更好的办法是观察层次最底层的部分,然后看在那里的是怎么分类的,例如在ACM的例子里,可以看到重点是咖啡机的出售和出租,因此可以得到咖啡机类别,出售出租地区和销售目标行业这三个维数,用一个名词焦点事件(focal event)来表示这种分类的依据。 分类可能会很复杂而出现交叉,但是,在现实的情况中,很少出现维数(Dimension)会大于6的情况,导致实际分析中可能需要对上一节的模型稍作修改:尽量考虑一下有没有这样的必要。 维数(Dimension)通常不必细分到最末端的一层,例如在ACM的例子里不值得,或者甚至可能一直往下分析到每个销售人员的销售范围甚至细到每个具体的顾客,这样的层次对理解整个系统结构是有帮助的,由于复杂度以及具体细节暂时不进行深入讨论。 维数可以由系统分析人员显式定义;否则,就得由企业数据库决定,如果是这样,每个维数就得定义一个builder操作从数据库查询所要的数据,这也允许系统随着时间的推进增加维数的节点(add nodes to the dimension over time)。 1.1.2
维数和企业部门单元的属性(Properties)
对于维数(Dimension)而言,一条非常重要的规则是维数层次中,上面级别的测量可以由底下级别的测量得到,例如我们想得到东北地区的销售收入,就可以累计东北地区下属地区所有的销售收入。每一个维数都必须支持这一规则,具体运算通常是累加,但也有例外(参见本文第2.5节)。 维数的定义经常跟企业结构有关,不过还有一个非常重要的通用维数是时间(time),也满足上一规则。 企业部门单元(Enterprise Segment)还有一个有趣的属性,那就是:它们是概念存在的,就像许多基础的数据类型一样,哪怕它们并没有创建成为软件对象。我们仍然把它当作非基础数据类型,创建时是一种查找/创建形式,即首先查看要求的实例是否存在,如存在,返回它作为结果,如不存在,创建它。 1.2
测量协议(Mesurement
Protocol)
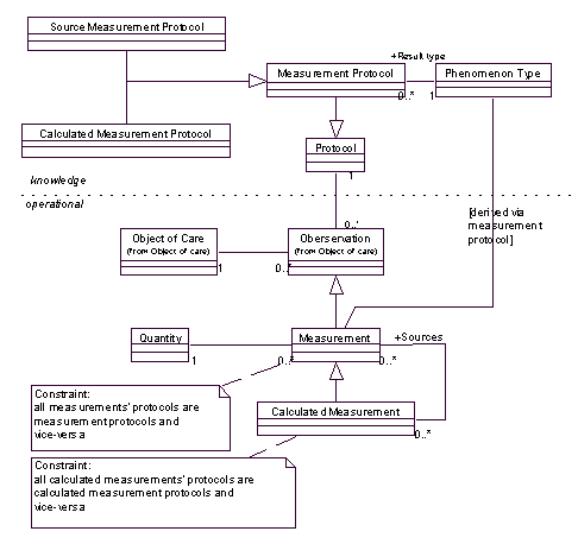
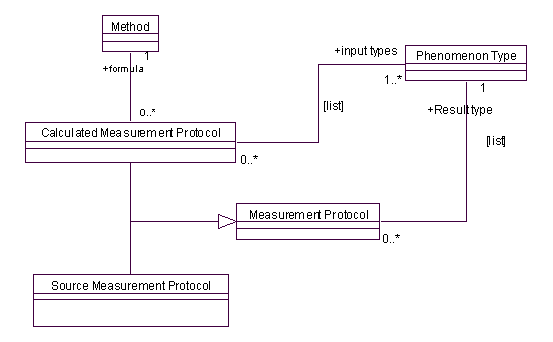
在企业金融分析中要用到许许多多的测量(measurements),这些测量不是用手工输入的,它们通常来自数据库,或者从其他的measurements计算而来,也就是说,获得这些测量的途径很重要,下面的模型给出了关于测量协议(Mesurement Protocol)的一个大体框架,跟第三章中的模型很类似:
在上述模型中,给出了两种测量协议:Source Measurement Protocol和Calculated Measurement Protocol,其中Source Measurement Protocol指的是从企业数据库查询,一般来说一个对象知道去哪里取数据,哪怕实际的代码可能在另外的层次中(用户应该决定)。而Calculated Measurement Protocol代表测量由系统中已有的测量对象计算而来。 需要指出的是,在这个模型中,一种类型(Phenomenon Type)可能对应几种测量协议,例如,同一个Phenomenon Type可能同时拥有源/计算协议。一般来说应该由用户确定到底采用哪个具体的协议,但也可以从Phenomenon Type到Measurement Protocol形成一个映射表,并从前到后表明各个Measurement Protocol的优先级,以供系统选用。 还有要注意的是Calculated Measurement,连接到它的源(Sources)测量对象,这是基于计算结果的通用原则:当结果作为对象时,它应该知道哪种计算方式给出结果(协议),还有对这个协议的输入(Sources)。 1.2.1 保存计算结果(Holding the Calculations)Calculated Measurement Protocols包括计算的公式(formulas),这些公式一般非常简单,所以用简单的解释器(interpreter[2]),并在解释器中把公式用一般电子表格格式来保存。由下图可以看到:
注意图中参数的表示方法,每个Calculated Measurement Protocol有一个参数列表,该列表同公式中提到的类型相结合,由于这些类型对象必须可识别,所以用列表是合适的;也可以用字符串关键字表示。 1.2.2 比较关系和因果关系的测量协议在企业金融分析中,测量(Measurements)并不都是数值(value),例如收入多少多少美元,人们可能对比较实际收入和计划收入,或是对目前数值和历史数值对比更感兴趣。考虑到这些比较性的测量,我们需要在模型中加入它们,鉴于一般的比较都是在历史数据和现实数据,或者计划数据之间发生,而历史数据可以由计算某个时间段得到,那么计划数据稍有不同,在上一章中提到过Projected Observation,在这里,Projected Observation还要和相应的计划结合在一起,如图所示:
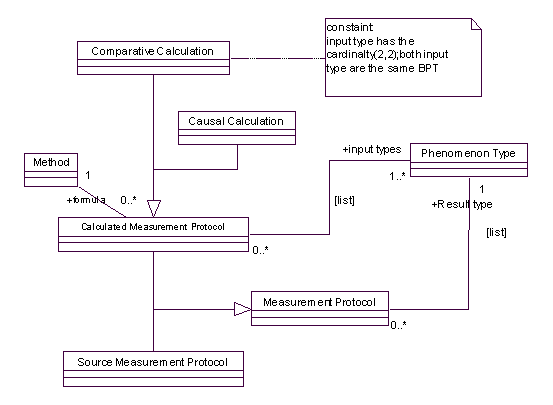
需要注意的是,计算测量(Calculated Measurement)可以分为两大类,一类是因果关系的测量(Causal Measurement),因为这类测量的结果来自其他的测量(计算之后),因果测量可以有不受限制的输入参数,输入之间任意的关系,而且计算公式也可以是任意的形式。 另一类就是刚才说的,比较关系的测量,相比而言,这类测量要有规律得多,一般是两个输入参数,必须是同一种类型(Phenomenon Type),比较结果要不是两者之间的差值,要不是差值对于输入的百分比,即:(x-y)或((x-y)/y *100%)。 这两种不同的测量协议可以由以下的模型来描述:
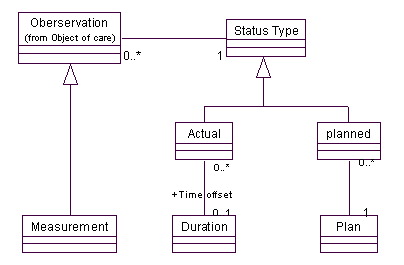
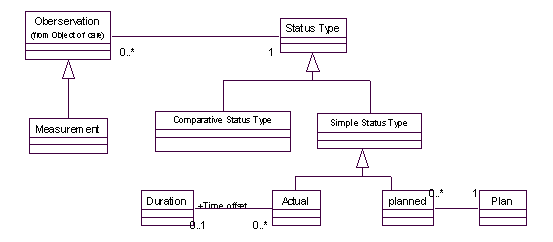
可以看到,在Comparative Calculation中,有对输入参数类型和数量上的限制。 1.2.3 状态类型(Status Type):定义计划(Planned)状态和实际(Actual)状态由数据源或计算所得的测量(Measurement)通常通过他们的测量协议得到结果,测量协议(Measurement Protocol)可以为测量(Measurement)提供一个工厂(Factory[3])方法(来创建测量对象),当客户需要创建测量对象时,需要提供测量的对象(Object of Care),需要说明是实际测量还是计划测量,如果是计划测量,则需要给出相关的计划,如果是实际测量,则需要制定实际测量的日期。 想想,是不是可以把测量的状态信息提取出来到Status Type类,单独表示?如下图:
在这个模型中,把观察的状态从Observation当中抽取出来,放到一个单独的类中间,这样还可以方便扩展到其他可能的状态。而且,客户创建测量时只需指定测量状态就可以了,如果是比较性的测量,则需要两个状态,给予两个参数。如果对这种情况更进一步明确表述,还可以得到下面的模型: 疑问:原文中Actual和Planned是两个Status
Type的子类,而笔者认为,作为Simple
Status Type的子类就可以了。
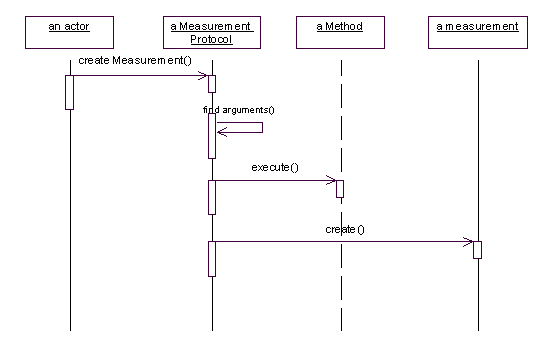
1.2.4 创建测量实例(Create a Mesurement)从上一节基本了解到了创建Measurement对象的大致方法,下面我们来看具体的创建过程,创建过程分为三个步骤:首先找到参数(arguments),然后执行一个公式(formula),然后用所得的结果创建一个新的Measurement对象,在这个过程中,参数查找是一个多态的操作,取决于我们要创建因果关系还是比较关系的测量对象。创建过程的序列图如下所示:
活动图如下所示:
细化因果关系测量的参数查找过程,可以知道,首先要得到所有同一状态类型的测量和测量针对的对象(Object of Care),这些测量目标对象的类型和协议的输入匹配;而比较关系的测量计算公式,则需要查找两个同输入类型匹配的测量实例(同样的针对对象),这两个实例的状态类型分别是比较和被比较的对象。 |