| 前 言
关系型数据库是一种常用的数据库结构。1971年E.F.Codd博士首先提出了关系数据库的规范化理论,之后,此理论不断深化、完善。规范化理论不仅仅是设计关系模式的理论指导和强有力的工具,对其它数据模型数据库的逻辑设计也同样有理论意义,在基于网络的数据库开发过程中也应该对数据库进行规范化处理。 系统中逻辑数据库的范式设计 未经规范化的数据库一般都有下述缺点:较大的数据冗余,数据一致性差,数据修改复杂,对表进行插入删除时会产生异常。规范化的作用就在于尽量去除冗余,使数据保持一致,使数据修改简单,除去在表中进行插入删除时产生的异常。规范化后的表一般都较小,而在Sybase中数据页的大小是2k,小的表意味着一个数据页中可以包含较多的记录,这样客户端用户就可在同样的时间内获得所需的更多数据记录,从而减少客户端与服务器端的物理I/O,减轻网络的负担。 以下讲述中用到以下术语及表示(限于篇幅,不作详解,请参阅文献[1]): Y函数依赖于X记作:X→Y;Y函数完全依赖于X记作: Y函数部分依赖于X记作: 关系R具有连接依赖记作:JD*(X1,X2,…,XN)(JD:Join Dependentcy);Y多值依赖于X记作:X→→Y 第一范式(1NF) 定义:如果关系R 中所有属性的值域都是单纯域,那么关系模式R是第一范式的,记作R∈1NF。 这一限制是关系的基本性质,所以任何关系都必须满足第一范式。在仅满足1NF的表中,数据冗余大、修改量大、插入删除时会有异常,由此我们引入2NF。 第二范式(2NF) 定义:如果关系模式R是第一范式的,而且关系中每一个非主属性不部分依赖于主键,称R是第二范式的,记作:R∈2NF。 不满足2NF的关系会产生前面讲的插入异常、删除异常、修改复杂,解决办法是用投影分解。 数据库的1NF与2NF较易取得,在此不再举例赘述。 第三范式(3NF) 定义:如果关系模式R是2NF的,且每一个非主属性都不传递依赖于主键,称R是第三范式的,记作R∈3NF。 反例:下表表示关系R3(sbbh,czmc,czdz,sbxh),其中sbbh构成主键。
分析上表的函数依赖,由sbbh→czmc,czmc→sbbh,czmc→czdz,得sbbh→czdz,所以 3NF去除了非主属性对主键的部分函数依赖和传递函数依赖。一般满足3NF的关系模式已能消除冗余和各种异常现象,获得较满意的效果,但无论2NF还是3NF都没有涉及主属性间的函数依赖,所以有时仍会引起一些问题。由此我们引入BC范式(BCNF,Boyeet和Codd提出),通常认为BCNF是第三范式的改进。 BC范式的定义:如果关系模式R∈1NF,且R中每一个决定因素都是候选键,则R是满足BC范式的关系,记作R∈BCNF。 当一个关系模式R∈BCNF,则在函数依赖范畴里,已实现了分离,消除了插入、删除的异常。 第四范式(4NF) 第四范式是BC范式的推广,是针对有多值依赖的关系模式所定义的规范化形式。 定义:关系模式R<U,F>∈1NF,X、Y是U的非空子集, 反例:下表表示关系R4(sbm,cz#,sccj)。
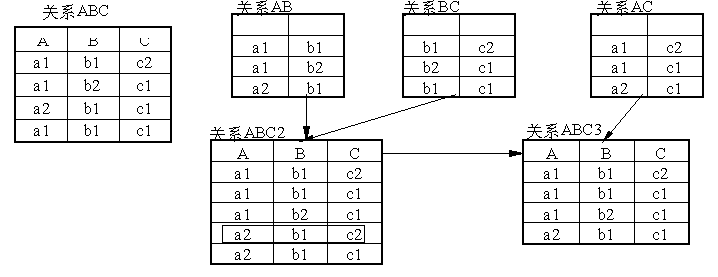
分析上表,对sbm的一个值,不论sccj取什么值,总有一组确定的cz#与之对应,所以有:sbm→→cz#,同样分析有sbm→→sccj。这说明R4不满足4NF,此种关系模式有数据冗余和修改量大等弊端。可用分解法消除不满足4NF的非平凡多值依赖。解决办法:把R4分解为R41(sbm,cz#),R42(sbm,sccj)。 第五范式(5NF) 前面我们提高范式等级的办法是分解,把一个关系用投影来代替,这些投影一般都能通过连接得到原来的关系。但有一种关系不能无损分解成两个投影,而能分解成三个以上的投影。如图1中,关系ABC可分解成两个投影AB和BC(或AC和BC)。AB与BC在上连接得ABC2;ABC2与AC再连接得ABC3。显然关系ABC2中比关系ABC多出一元组(a2,b1,c2),称之为寄生元组。ABC2与AC连接,得关系ABC3,和原关系相同。所以关系ABC具有连接依赖JD*(A,B,C)。在省电力GIS系统中我们也遇到了类似的问题,并做了相应的处理。
图1 定义: 如果关系模式R中的每一个连接依赖, 都是由R的候选键所蕴含, 称R是第五范式的,记作:R∈5NF 基于网络的考虑 数据库的规范化提高了系统性能,但不是单纯为了规范化而规范化,高范式等级的数据库在网络中不一定有高性能。因为使数据库规范化的方法是把表拆分成相关列最少的表,这样查询时就需要用复杂的联结,占用较多的CPU资源和I/O操作,才能查到客户端所需的数据。这样的开销是我们所不希望的,因为这会导致复杂度的增加和性能的下降。所以在网络环境下有必要对规范化进行必要的平衡,使系统有最优的性能。提高数据库的网络性能,在系统中我们采用了下面的方法。 适量增加冗余 非网络的集中式数据库中要尽可能减少数据的冗余度,以节省存贮空间,使数据易于保持一致性。冗余数据虽易造成不一致性,且系统为了维护冗余数据要付出一定的代价,但在网络数据库中适当增加数据的冗余是有好处的。增加冗余分两个层次:一是数据库层,二是表层。 数据库层数据冗余:系统建模无论采用何种体系结构,冗余数据可以数据副本的方式出现,副本的存在使许多应用可以“本地性”,大大减少了网络通信,提高了系统的性能;再有当某一结点出现故障时,由于拷贝副本的存在,系统仍可对此副本操作,而不至于因一处故障而使系统无法使用。 表层数据冗余:数据库的规范化其实质是概念的单一化,所以规范后的数据库中的表一般都较小,使表中相关列最少,这虽然增强了数据库的可维护性,但在系统要完成一些检索时,可能要用复杂的联结才能实现。这种操作有时需要网络I/O上的较大开销,这将导致性能的下降。对这一问题的解决方案,一是建立临时表或定义视图以减少频繁出现的多表联结,二是在数据库的设计时仅采用恰当的范式等级。 增加标识列 当一个表需要多个列的组合才能组成主键时,可以在表中合理的增加一列作为主键,唯一标识此表,一般这一列用的值是一个编号或是时间戳(timestamp)等。在这种情况下增加列虽然多占了存贮空间,但是在索引中以此列代替大的组合键,从而获得了性能的提高。 大表横向分割 在执行查询时如果只涉及一大表的一个子集,可以把这个大表分成多个表,也即对表进行了分割,可提高在网络环境下的查询速度。 结束语 在基于网络的数据库设计过程中,既要考虑其范式要求,也要考虑其网络要求。当在这两者之间有冲突时,要在两者之间作一个平衡,根据实际应用进行具体的系统分析,权衡各方面的因素后,选择最优设计方案
|