Modeling
Methodologies
From www.aisintl.com Many forms of symbolic notation have been developed to enable data models to represent various levels of abstraction. Some are lexical, others graphic; the better approaches are both.
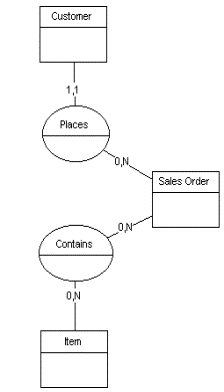
Chen's ER spawned a number of variations and improvements, some of which have been embodied in computer assisted software engineering (CASE) products employing ER methodology, e.g., CSA's Silverrun. Barker90 (p. 5-1) defines an entity as "... a thing or object of significance, whether real or imagined, about which information needs to be known or held." Martin90 (vol. II, p. 219) agrees that an entity "is something about which we store data." Chen's original E-R technique made a firm (if not clear) distinction between entities, as defined above, and relationships between them. To cope with inevitable complexities, Chen allowed relationships to have attributes of their own, making them look a lot like entities and giving rise to heated debate over just what is an entity versus a relationship. Given the lack of clarity in definitions, it is not surprising that Codd90 (p. 477) says "The major problem with the entity-relationship approach is that one person's entity is another person's relationship."Date95 (p.363) agrees , saying "[the ER approach] is seriously flawed because the very same object can quite legitimately be regarded as an entity by some users and a relationship by others." Thus Codd90 (p. 9) says emphatically that "... precisely the same structure is adopted for entities as for relationships between entities." Date95 (p.362) puts this in perspective with "[the ER approach] is essentially just a thin layer on top of the basic relational model."
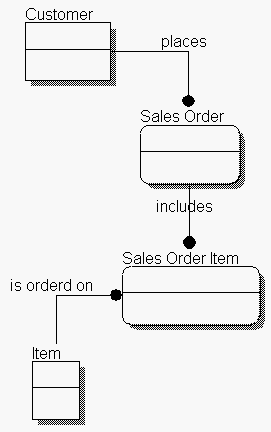
Entity-Relationship, IDEF1X, and Information Engineering all translate business requirements into formal symbols and statements which can eventually be transformed into database structural code. Thus the modeling process reduces undisciplined, non-mathematical narrative to algebraic regularity. Early practice (see DeMarco78) when data modeling techniques were not widely known, was built on a bottom-up approach. Analysts harvested an inventory of raw data elements or statements ("A customer order has a date of entry.") from the broad problem space. This examination was frequently conducted via data flow diagram (DFD) techniques, which were invented for the express purpose of discovering the pool of data items so that their structure could be considered. Expert analysis of this pool, including various forms of normalization, rendered aggregations of data elements into entities. Unfortunately, according to Teorey94, "The number of entities in a database is typically an order of magnitude less than the number of data elements ..." Conversely, the number of data items or attributes is one or two orders of magnitude greater than the number of entities. In approaching from discovery of the multitude of details, one has the discouraging experience of watching the work funnel into a black hole of diagrams and documents, seldom allowing the escape of an illuminating ray of understanding. Top-down, entity-based approachs (ER, IE, etc.) are more concise, more understandable and far easier to visualize than those which build up from a multitude of details. Top-down techniques rapidly fan out through the power of abstraction to generate the multitude of implementation details. Current practice therefore leans toward modeling entites (e.g., "customer", "order") first, since most information systems professionals now understand the concept of entities or tables in a relational database. Entities are later related amongst each other and fleshed out with attributes; during these processes the modeler may choose to rearrange data items into different entity structures. While this delays the analysts' inevitable agony of populating the model's details, it has the corollary shortcoming of placing responsibility for critical structural decisions on the designers. We do not mean to suggest that professional data analysts are incapable of making such decisions but rather that their time could be better spent if the CASE tool can make those decisions - swiftly, reliably, consistently - for them.
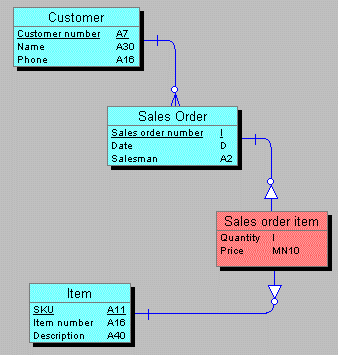
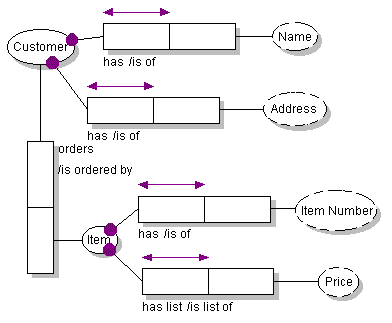
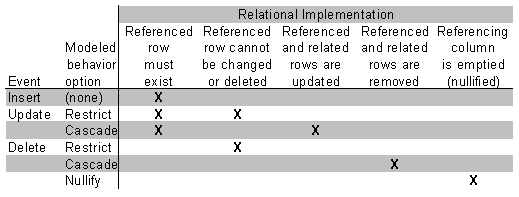
Accidents of history rather than relative deficiencies seem to have kept ORM in the shadows of ER for many years. Contrary to a frequent misconception, the academic foundations of ORM date back twenty years, to the same period which gave birth to ER. Over the years several CASE tools have employed this methodology yet there has seldom been even one commercial product available. For a comprehensive display of the current art of ORM, see Asynetrix's InfoModeler. The modeling methodologies discussed above deal with conceptual and logical understanding of data but not necessarily the physical details of its storage. Additional techniques from the area of relational schema design are generally employed to represent tables, columns, indexes, constraints and other storage structures which implement a data design. For example, the table below illustrates some design choices which must be implemented in declarative or procedural integrity constraints to implement a model.
The conceptual, logical, and physical models together comprise a complete data model which can represent a given database design from its highest abstraction through its most detailed level of column data type and index expression.
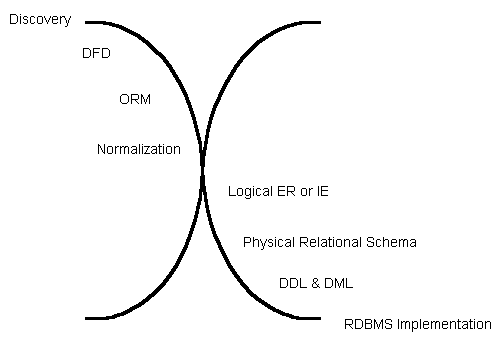
In our limited experience no single methodology, method, or tool covers the full scope of data modeling from raw discovery to instantiated database, as sketched above. Notice that in the upper half the techniques funnel downward toward coalescence and conceptual clarity (or into the black hole of bloated, aborted projects); in the lower half the process fans rapidly out as automated algorithms replicate abstract patterns to implement details (e.g., a simple foreign key reference propagates a lengthy SQL trigger). If you are in search of the appropriate methods, skills, and tools for a large scale data design effort, keep your eyes and options open. Contact AIS for consulting assistance in evaluating, selecting, and implementing CASE techniques.
|