| БрМЭЦМі: |
ЮФеТНщЩмСЫЪБМфађСаЪ§ОнПт(TSDB)ЃЌЙиМќЬиадЃЌЗўЮёЯрЙиЃЌSERIES,ГжајВщбЏЕШЯЃЭћЖдФњгаЫљАяжњЁЃ
БОЮФРДздsegmentfaultЃЌгЩЛ№СњЙћШэМўDeloresБрМЁЂЭЦМіЁЃ |
|
InfluxDB ЪЧвЛИіЪБМфађСаЪ§ОнПт(TSDB), БЛЩшМЦгУРДДІРэИпаДШыЁЂИпВщбЏИКдиЃЌЪЧ TICK ЕФвЛВПЗжЁЃ
TSDB ЪЧеыЖдЪБМфДСЛђЪБМфађСаЪ§ОнНјаагХЛЏЕФЪ§ОнПтЃЌзЈУХЮЊДІРэДјгаЪБМфДСЕФЖШСПКЭЪТМўЛђЖШСПЖјЙЙНЈЕФЁЃ
ЖјЪБМфађСаЪ§ОнПЩвдЪЧЫцЪБМфИњзйЁЂМрЪгЁЂЯТВЩбљКЭОлКЯЕФЖШСПЛђЪТМўЃЌШчЗўЮёЦїжИБъЁЂгІгУГЬађадФмЁЂЭјТчЪ§ОнЁЂДЋИаЦїЪ§ОнвдМАаэЖрЦфЫћРраЭЕФЗжЮіЪ§ОнЁЃ
ЙиМќЬиад
ФмЙЛИпЫйЖСШЁКЭбЙЫѕЪБМфађСаЪ§Он
ЪЙгУ Go БраДЃЌФмЙЛЕЋЮФМўдЫааЃЌУЛгавРРЕ
ЬсЙЉСЫМђЕЅЁЂИпаЇЕФ HTTP ЖСаДНгПк
ФмЙЛЪЙгУВхМўжЇГжЦфЫћЕФЪ§ОнавщЃЌШчЃК Graphite=ЃЌ =collectd КЭ OpenTSDB
ПЩЧсЫЩЪЙгУ SQL гябдВщбЏОлКЯЪ§Он
ФмЙЛЪЙгУ Tag НјааПьЫйИпаЇЕФВщбЏ
жЇГжБЃСєВпТд(Retention Policy), ФмЙЛздЖЏЧхРэОЩЪ§Он
жЇГжГжајВщбЏЃЌФмЙЛздЖЏЖЈЦкМЦЫуОлКЯЪ§ОнЃЌЬсИпСЫВщбЏЕФаЇТЪ
зЂвтЃК ПЊдДАцБОЕФ InfluxDB жЛдЫаадкЕЅИіНкЕуЩЯЃЌШчашИќКУЕФадФмЛђБмУтЕЅЕуЙЪеЯЃЌЧыЪЙгУЦѓвЕАцЁЃ
АВзА
deepin/Ubuntu/Debian
sudo apt install influxdb influxdb-cli
Archlinux
yaourt -S influxdb Лђ sudo pacman -S influxdb
ХфжУ
InfluxDB ЕФХфжУЮФМўЮЊЃК /etc/influxdb/influxdb.conf ЃЌбЁЯюЯъЧщЧыВЮМћЃКConfiguration SettingsЃЌетРяОЭВЛдкзИЪіЁЃ
ЛљБОВйзї
ЗўЮёЯрЙи
ЦєгУ/ЭЃжЙЗўЮё
systemctl start/stop influxdb.service
Ъ§ОнПт
СЌНгЪ§ОнПт
ЪЙгУ influx УќСюСЌНгЪ§ОнПтЃЌВЮПДЦфАязщЪжВсСЫНтЪЙгУЗНЗЈ
ДДНЈЪ§ОнПт
CREATE DATABASE < name >
ЩОГ§Ъ§ОнПт
DROP DATABASE < name >
СаГіЪ§ОнПт
SHOW DATABASES
бЁдёЪ§ОнПт
USE < name >
аДШыВщбЏ
InfluxDB жаЪЙгУ measurement БэЪОБэЃЌ tags БэЪОБэЕФдЊЪ§ОнЃЌ fields БэЪОЪ§ОнЁЃ
БэЕФ scheme ВЛгУЖЈвхЃЌ null жЕвВВЛЛсБЛДцДЂЁЃ
tag ПЩРэНтЮЊБэжаашвЊЫїв§ЕФСаЃЌ field ЪЧВЛашвЊЫїв§ЕФСаЃЌ point БэЪОвЛЬѕМЧТМЁЃ
tags жЎМфЛђ fields жЎМфЪЙгУ ',' ЗжИюЃЌ Жј tags гы fields жЎМфЪЙгУПеИёЗжИюЁЃ
ЩОГ§Бэ
DROP MEASUREMENTS < name >
СаГіБэ
SHOW MEASUREMENTS
аДШыЪ§Он
point аДШыЕФгяЗЈШчЯТЃК
<measurement>[,<tag-key>=<tag-value>...]
<field-key>=<field-value>
[,<field2-key>=<field2-value>...]
[unix-nano-timestamp] |
ВхШывЛЬѕ cpu load ЕФЪ§ОнЃК INSERT cpu_load,machine=001,region=ch value=0.56 ЃЌ
етОЭЯђУћЮЊ cpu_load ЕФ measurement жаЬэМгСЫ tags ЮЊ machine КЭ region ЃЌ fields ЮЊ value ЕФ point ЁЃ
ВЛжИЖЈ timestamp ЪБЃЌФЌШЯЛсЪЙгУ БОЕиЕФЕБЧАЪБМф зїЮЊ timestamp ЁЃ
ВщбЏЪ§Он
ВщбЏгяЗЈЃК
SELECT <field_key>
[,<field_key>,<tag_key>]
FROM
<measurement_name>[,<measurement_name>] |
ВщбЏгяОфжаБиаывЊга field Дцдк ЃЌВщбЏгяОфЛЙжЇГж Go ЗчИёЕФе§дђЃЌЯТУцИјГівЛаЉР§згЁЃ
SELECT * FROM cpu_load
ВщбЏ cpu_load жаЕФЫљга fields КЭ tags
SELECT *::field FROM cpu_load
ВщбЏ cpu_load жаЕФЫљга fields
SELECT value,machine FROM cpu_load
жЛВщбЏ value гы machine
SELECT value::field,machine::tag FROM cpu_load
жЛВщбЏ value гы machine ЃЌВЂЯоЖЈСЫРраЭЃЌШчЙћРраЭДэЮѓНЋЗЕЛи null ЃЌШчЙћЫљгаВщбЏзжЖЮЕФРраЭЖМДэЮѓНЋУЛга point ЗЕЛи
SELECT * FROM /.*/
ВщбЏЫљгаБэжаЕФЫљгазжЖЮ
`WHERE` гяОфКѓЕФжЕВЛЮЊЪ§зжЕФЃЌБиаыв§Ц№РДЁЃ
ИќЖргУЗЈВЮМћЃК [Data exploration using InfluxQL] |
ЩОГ§ Point
InfluxDB ВЛжЇГж Point ЕФЩОГ§ВйзїЃЌЕЋПЩвдЭЈЙ§ Retention Policy ЧхРэ Point ЁЃ
SERIES
SERIES ЪЧ measurement,< tag1 >,< tag2 >... ЕФМЏКЯЃЌШчжЎЧАЕФаДШыЕФ SERIES ОЭЪЧ cpu_load,machine,region
ВщПДгяЗЈЃК
| SHOW SERIES FROM
[measurement],[tag1],[tag2]... |
FROM ПЩвдВЛМгЃЌШчЃК
SHOW SERIES ЯдЪОЪ§ОнПтжаЫљгаЕФ series
SHOW SERIES FROM cpu_load ЯдЪОБэ cpu_load жаЕФЫљга series
ЩОГ§
DROP
DROP НЋЩОГ§ЫљгаЕФМЧТМЃЌВЂЩОГ§ЫљгаЕФЫїв§ЃЌгяЗЈЃК
| DROP SERIES FROM
<measurement> WHERE [condition] |
DELETE
DELETE НЋЩОГ§ЫљгаЕФМЧТМЃЌЕЋВЛЛсЩОГ§Ыїв§ЃЌВЂжЇГждк WHERE гяОфжаЪЙгУ =timestamp=ЃЌгяЗЈЃК
DELETE FROM <measurement_name>
WHERE [<tag_key>='<tag_value>'] |
[<time interval>]~ |
ГжајВщбЏ
СЌајВщбЏ(Continuous Queries МђГЦ CQ)ЪЧ InfluxQL ЖдЪЕЪБЪ§ОнздЖЏжмЦкдЫааЕФВщбЏЃЌШЛКѓАбВщбЏНсЙћаДШыЕНжИЖЈЕФ measurement жаЁЃ
гяЗЈШчЯТЃК
CREATE CONTINUOUS
QUERY <cq_name>
ON <database_name>
BEGIN
<cq_query>
END |
ЩОГ§гяЗЈЃК DROP CONTINUOUS QUERY < cq_name > ON < database_name >
cq_query ашвЊвЛИіКЏЪ§ЃЌвЛИі INTO згОфКЭвЛИі GROUP BY time() згОфЃК
SELECT <function[s]>
INTO
<destination_measurement> FROM
<measurement>
[WHERE <stuff>] GROUP BY
time(<interval>)[,<tag_key[s]>] |
зЂвтЃК дк WHERE згОфжаЃЌ cq_query ВЛашвЊЪБМфЗЖЮЇЁЃ InfluxDB дкжДаа CQ ЪБздЖЏЩњГЩ cq_query ЕФЪБМфЗЖЮЇЁЃ
cq_query ЕФ WHERE згОфжаЕФШЮКЮгУЛЇжИЖЈЕФЪБМфЗЖЮЇНЋБЛЯЕЭГКіТдЁЃ
ШчДДНЈвЛИівЛЗжжгВЩбљвЛДЮ cpu_load ВЂаДШы cpu_load_1min БэЕФСЌајВщбЏ:
CREATE CONTINUOUS
QUERY "cpu_load_1min"
ON "learn_test"
BEGIN
SELECT mean("value") INTO "cpu_load_1min"
FROM "cpu_load" GROUP BY time(1m)
END |
value НЋвд mean ЮЊУћБЃДцдк cpu_load_1min жаЁЃ
ИќЖрИпМЖгУЗЈВЮМгЃК InfluxQL Continuous Queries
БЃСєВпТд
InfluxDB ЪЧУЛгаЬсЙЉжБНгЩОГ§Ъ§ОнМЧТМЕФЗНЗЈЃЌЕЋЪЧЬсЙЉЪ§ОнБЃДцВпТдЃЌжївЊгУгкжИЖЈЪ§ОнБЃСєЪБМфЃЌГЌЙ§жИЖЈЪБМфЃЌОЭЩОГ§етВПЗжЪ§ОнЁЃ
ПЩвдгаЖрИі RP ВЂДцЃЌЕЋ default БэУїФЌШЯВпТдЁЃ
ИќЖргУЗЈВЮМћЃК Database management using InfluxQL ЁЃ
СаГі
SHOW RETENTION POLICY ON < database name >
ДДНЈ
ДДНЈгяЗЈЃК
CREATE RETENTION
POLICY
<retention_policy_name> ON <database_name>
DURATION <duration> REPLICATION <n>
[SHARD DURATION <duration>] [DEFAULT] |
REPLICATION згОфШЗЖЈУПИіЕудкМЏШКжаДцДЂЖрЩйИіЖРСЂИББОЃЌЦфжа n ЪЧЪ§ОнНкЕуЕФЪ§СПЃЌЖдЕЅНкЕуЪЕР§ЮоаЇЁЃ
ЫщЦЌГжајЪБМфзгОфШЗЖЈЫщЦЌзщИВИЧЕФЪБМфЗЖЮЇЃЌЪЧвЛИі duration ЮФзжЃЌВЛжЇГж INF (infinite) duration ЁЃетИіЩшжУЪЧПЩбЁЕФЁЃ
ФЌШЯЧщПіЯТЃЌЫщЦЌзщЕФГжајЪБМфгЩБЃСєВпТдЕФГжајЪБМфОіЖЈ:
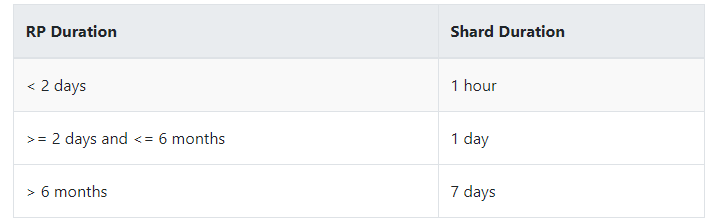
ШчЙћ RP Duration Дѓгк 0s аЁгк 1 hour ЃЌ Shard Duration ШдНЋЩшжУЮЊ 1 hour ЁЃ
ЩОГ§
DROP RETENTION POLICY < rp_name >
аоИФ
ALTER RETENTION POLICY < rp_name > ON
< database name > DURATION < duration >
REPLICATION < n > [SHARD DURATION
< duration >] DEFAULT |
HTTP НгПк
/query
Ъ§ОнжївЊЪЙгУ query НгПкВщбЏЃЌЯТУцИјГівЛаЉГЃМћгУЗЈЃЌЖјИќЖргУЗЈВЮМћЃК Querying data with the HTTP API ЁЃ
ДДНЈЪ§ОнПт
POST ЧыЧѓПЩгУгкДДНЈЪ§ОнПтЃЌШчЃК
curl -X POST
http://localhost:8086/query
--data-urlencode "q=CREATE
DATABASE
<database name>" |
ВщбЏ
curl -X GET http://localhost:8086/query?pretty
=true
--data-urlencode 'db=<database name>'
--data-urlencode
'q=SELECT "field1","tag1"...
FROM <measurement> WHERE <condition>' |
ЖрИіВщбЏ
ЖрИіВщбЏгяОфМфгУ ; ЗжИюЃЌШч:
curl -X GET http://localhost:8086/query?pretty
=true
--data-urlencode 'db=<database name>'
--data-urlencode
'q=SELECT "field1","tag1"...
FROM <measurement> WHERE <condition>;
SELECT
fields FROM <measurement>' |
зюДѓааЯожЦ(max-row-limit) дЪаэЪЙгУепЯожЦЗЕЛиНсЙћЕФЪ§ФПЃЌвдБЃЛЄInfluxDBВЛЛсдкОлКЯНсЙћЕФЪБКђЕМжТЕФФкДцКФОЁЁЃ
ЗжПщ(chunking) ПЩвдЩшжУВЮЪ§ chunked=true ПЊЦєЗжПщЃЌЪЙЗЕЛиЕФЪ§ОнЪЧСїЪНЕФ batch ЃЌЖјВЛЪЧЕЅИіЕФЗЕЛиЁЃЗЕЛиНсЙћПЩвдАД 100 Ъ§ОнЕуБЛЗжПщЃЌЮЊСЫИФБфетИіЗЕЛизюДѓЕФЗжПщЕФДѓаЁЃЌ
ПЩвддкВщбЏЕФЪБКђМгЩЯ chunk_size ВЮЪ§ЃЌР§ШчЗЕЛиЪ§ОнЕуЪЧУП 20000 ЮЊвЛИіХњДЮЁЃ
curl -X GET 'http://localhost:8086/query'
--data-urlencode "db=<name>" --data-urlencode
"chunked=true" --data-urlencode "chunk_size=100"
--data-urlencode "q=SELECT * FROM cpu_load" |
/write
ЗЂЫЭ POST ЧыЧѓЪЧаДШыЪ§ОнЕФжївЊЗНЪНЃЌЃЌЯТУцИјГівЛаЉГЃМћгУЗЈЃЌЖјИќЖргУЗЈВЮМћЃК Writing data with the HTTP API ЁЃ
ВхШывЛЬѕ Point
curl -X POST
http://localhost:8086/write?db
=<database name>
--data-binary
"cpu_load,machine=001,region=cn
value=0.56 1555164637838240795" |
БиаыжИЖЈ database name
ВхШыЖрЬѕ Point
ЖрЬѕ Point жЎМфгУааЗжИюЃЌШчЃК
curl -X POST
http://localhost:8086/write?db
=<database name>
--data-binary
"cpu_load,machine=001,
region=cn
value=0.56 1555164637838240795
cpu_load,machine=001,
region=cn value=0.65 1555164637838340795
cpu_load,machine=003,
region-cn value=0.6 1555164637839240795" |
ШчЙћашвЊаДШы Point Й§ЖрЃЌПЩвдНЋ Point ЗХШыЮФМўжаЃЌШЛКѓЭЈЙ§ POST ЧыЧѓЩЯДЋЁЃ
ЮФМў(cpu_data.txt)ФкШнШчЃК
cpu_load,machine=001,
region=cn
value=0.56 1555164637838240795
cpu_load,machine=001,
region=cn value=0.65 1555164637838340795
cpu_load,machine=003,
region-cn value=0.6 1555164637839240795 |
ШЛКѓЩЯДЋЃК
curl -X POST
http://localhost:8086/write?db
=<database name>
--data-binary @cpu_data.txt |
| 





