| БрМЭЦМі: |
БОЮФРДздгкcsdnЃЌБОЮФжївЊНщЩмСЫdoublewriteММЪѕНјааНтЮіЃЌШУДѓМвГфЗжРэНтdouble
writeЪЧШчКЮзіЕНБЃеЯЪ§ОнвГЕФПЩППадЁЃ
|
|
вЛЁЂОЕфPartial page writeЮЪЬтЃП
НщЩмdouble writeжЎЧАЮвУЧгаБивЊСЫНтpartial page writeЃЈВПЗжвГЪЇаЇЃЉЮЪЬтЁЃ
InnoDBЕФPage SizeвЛАуЪЧ16KBЃЌЦфЪ§ОнаЃбщвВЪЧеыЖдет16KBРДМЦЫуЕФЃЌНЋЪ§ОнаДШыЕНДХХЬЪЧвдPageЮЊЕЅЮЛНјааВйзїЕФЁЃЮвУЧжЊЕРЃЌгЩгкЮФМўЯЕЭГЖдвЛДЮДѓЪ§ОнвГЃЈР§ШчInnoDBЕФ16KBЃЉДѓЖрЪ§ЧщПіЯТВЛЪЧдзгВйзїЃЌетвтЮЖзХШчЙћЗўЮёЦїхДЛњСЫЃЌПЩФмжЛзіСЫВПЗжаДШыЁЃ16KЕФЪ§ОнЃЌаДШы4KЪБЃЌЗЂЩњСЫЯЕЭГЖЯЕч/os
crash ЃЌжЛгавЛВПЗжаДЪЧГЩЙІЕФЃЌетжжЧщПіЯТОЭЪЧpartial page writeЮЪЬтЁЃ
гаОбщЕФDBAПЩФмЛсЯыЕНЃЌШчЙћЗЂЩњаДЪЇаЇЃЌMySQLПЩвдИљОнredo logНјааЛжИДЁЃетЪЧвЛИіАьЗЈЃЌЕЋЪЧБиаыЧхГўЕиШЯЪЖЕНЃЌredo
logжаМЧТМЕФЪЧЖдвГЕФЮяРэаоИФЃЌШчЦЋвЦСП800ЃЌаДЁЏaaaaЁЏМЧТМЁЃШчЙћетИівГБОЩэвбОЗЂЩњСЫЫ№ЛЕЃЌдйЖдЦфНјаажизіЪЧУЛгавтвхЕФЁЃMySQLдкЛжИДЕФЙ§ГЬжаМьВщpageЕФchecksumЃЌchecksumОЭЪЧМьВщpageЕФзюКѓЪТЮёКХЃЌЗЂЩњpartial
page writeЮЪЬтЪБЃЌpageвбОЫ№ЛЕЃЌевВЛЕНИУpageжаЕФЪТЮёКХЁЃдкInnoDBПДРДЃЌетбљЕФЪ§ОнвГЪЧЮоЗЈЭЈЙ§checksumбщжЄЕФЃЌОЭЮоЗЈЛжИДЁЃМДЪБЮвУЧЧПжЦШУЦфЭЈЙ§бщжЄЃЌвВЮоЗЈДгБРРЃжаЛжИДЃЌвђЮЊЕБЧАInnoDBДцдкЕФвЛаЉШежОРраЭЃЌгааЉЪЧТпМВйзїЃЌВЂВЛФмзіЕНУнЕШЁЃ
ЮЊСЫНтОіетИіЮЪЬтЃЌInnoDBЪЕЯжСЫdouble write bufferЃЌМђЕЅРДЫЕЃЌОЭЪЧдкаДЪ§ОнвГжЎЧАЃЌЯШАбетИіЪ§ОнвГаДЕНвЛПщЖРСЂЕФЮяРэЮФМўЮЛжУЃЈibdataЃЉЃЌШЛКѓдйаДЕНЪ§ОнвГЁЃетбљдкхДЛњжиЦєЪБЃЌШчЙћГіЯжЪ§ОнвГЫ№ЛЕЃЌФЧУДдкгІгУredo
logжЎЧАЃЌашвЊЭЈЙ§ИУвГЕФИББОРДЛЙдИУвГЃЌШЛКѓдйНјааredo logжизіЃЌетОЭЪЧdouble writeЁЃdouble
writeММЪѕДјИјinnodbДцДЂв§ЧцЕФЪЧЪ§ОнвГЕФПЩППадЁЃ
ЖўЁЂdouble writeЬхЯЕНсЙЙМАЙЄзїСїГЬЃП
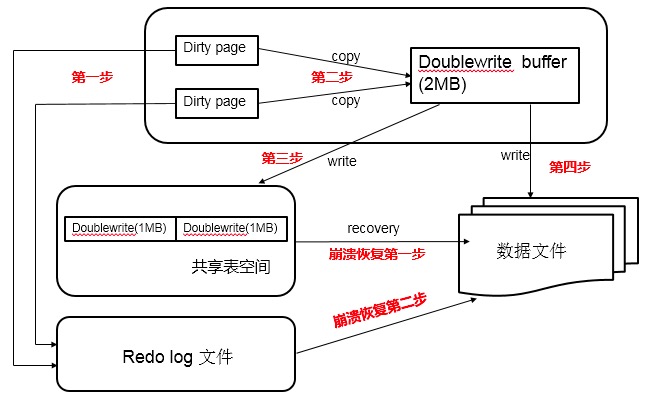
double writeгЩСНВПЗжзщГЩЃЌвЛВПЗжЪЧInnoDBФкДцжаЕФdouble write bufferЃЌДѓаЁЮЊ2MЃЌСэвЛВПЗжЪЧЮяРэДХХЬЩЯibdataЯЕЭГБэПеМфжаДѓаЁЮЊ2MBЃЌЙВ128ИіСЌајЕФPageЃЌМШ2ИіЗжЧјЁЃЦфжа120ИігУгкХњСПаДдрЃЌСэЭт8ИігУгкSingle
Page FlushЁЃзіЧјЗжЕФдвђЪЧХњСПЫЂдрЪЧКѓЬЈЯпГЬзіЕФЃЌВЛгАЯьЧАЬЈЯпГЬЁЃЖјSingle page
flushЪЧгУЛЇЯпГЬЗЂЦ№ЕФЃЌашвЊОЁПьЕФЫЂдрВЂЬцЛЛГівЛИіПеЯавГГіРДЁЃ
ЖдгкХњСПЫЂдрЃЌУПДЮевЕНвЛИіПЩзіflushЕФpageЃЌЖдЦфГжгаS lockЃЌШЛКѓНЋИУpageПНБДЕНdblwrжаЃЌЕБdblwrТњКѓепвЛДЮХњСПЫЂдрНсЪјЪБЃЌНЋdblwrжаЕФpageШЋВПЫЂЕНibdataжаЃЌзЂвтетЪЧЭЌВНаДВйзїЃЛШЛКѓдйЛНабКѓЬЈIOЯпГЬШЅаДЪ§ОнвГЁЃЕБКѓЬЈIOЯпГЬЭъГЩаДВйзїКѓЃЌЛсШЅИќаТdblwrжаЕФМЦЪ§вдЬкГіПеМфЃЌЪЭЗХblockЩЯЕФSЫјЃЌЭъГЩаДШыЁЃ
ЖдгкSingle Page FlushЃЌдђзіЕФЪЧЭЌВНаДВйзїЃЌдкЬєГівЛИіПЩвдЫЂдрЕФpageКѓЃЌЯШМгШыЕНdblwrжаЃЌЫЂЕНibdataЃЌШЛКѓаДЕНгУЛЇБэПеМфЃЌЭъГЩКѓЃЌЛсЖдИУгУЛЇБэПеМфзівЛДЮfsyncВйзїЁЃ
Single Page Flushдкbuffer poolжаfree pageВЛЙЛЪБДЅЗЂЃЌЭЈГЃгЩЧАЬЈЯпГЬЗЂЦ№ЃЌгЩгкУПДЮsingle
page flushЖМЛсЕМжТвЛДЮfsyncВйзїЃЌдкДѓВЂЗЂИКдиЯТЃЌШчЙћДѓСПЯпГЬШЅзіflushЃЌКмЯдШЛЛсВњЩњбЯжиЕФадФмЯТНЕЁЃPerconaдк5.6АцБОжазіСЫгХЛЏЃЌПЩвдбЁдёгЩКѓЬЈЯпГЬlru
managerРДзідЄЫЂЃЌБмУтгУЛЇЯпГЬЯнШыЦфжаЁЃ
ШчЙћЗЂЩњСЫМЋЖЫЧщПіЃЈЖЯЕчЃЉЃЌInnoDBдйДЮЦєЖЏКѓЃЌЗЂЯжСЫвЛИіPageЪ§ОнвбОЫ№ЛЕЃЌФЧУДДЫЪБОЭПЩвдДгdouble
write bufferжаНјааЪ§ОнЛжИДСЫЁЃ
double writeЙЄзїСїГЬШчЯТЃК
ЕБвЛЯЕСаЛњжЦЃЈmainКЏЪ§ДЅЗЂЁЂcheckpointЕШЃЉДЅЗЂЪ§ОнЛКГхГижаЕФдрвГНјааЫЂаТЕНdata
fileЕФЪБКђЃЌВЂВЛжБНгаДДХХЬЃЌЖјЪЧЛсЭЈЙ§memcpyКЏЪ§НЋдрвГЯШИДжЦЕНФкДцжаЕФdouble write
bufferЃЌжЎКѓЭЈЙ§double write bufferдйЗжСНДЮЁЂУПДЮ1MBЫГађаДШыЙВЯэБэПеМфЕФЮяРэДХХЬЩЯЁЃШЛКѓТэЩЯЕїгУfsyncКЏЪ§ЃЌЭЌВНдрвГНјДХХЬЩЯЁЃгЩгкдкетИіЙ§ГЬжаЃЌdouble
writeвГЕФДцДЂЪБСЌајЕФЃЌвђДЫаДШыДХХЬЮЊЫГађаДЃЌадФмКмИпЃЛЭъГЩdouble writeКѓЃЌдйНЋдрвГаДШыЪЕМЪЕФИїИіБэПеМфЮФМўЃЌетЪБаДШыОЭЪЧРыЩЂЕФСЫЁЃИїФЃПщазїЧщПіШчЯТЭМЃЈЕквЛВНгІЮЊдрвГВњЩњЕФredoМЧТМlog
bufferЃЌШЛКѓlog bufferаДШыredo log fileЃЌЮЊМђЛЏДЮвЊВНжшжБНгСЌЯпБэЪОЃЉЃК
ВщПДdoublewriteЙЄзїЧщПіЃЌПЩвджДааУќСюЃК
mysql> show
status like "%InnoDB_dblwr%";
+----------------------------+------------+
| Variable_name | Value |
+----------------------------+------------+
| Innodb_dblwr_pages_written |61932183 |
| Innodb_dblwr_writes |15237891 |
+----------------------------+------------+
2 rows in set (0.01 sec) |
вдЩЯЪ§ОнЯдЪОЃЌdouble writeвЛЙВаДСЫ 61932183ИівГЃЌвЛЙВаДСЫ15237891ДЮЃЌДгетзщЪ§ОнЮвУЧПЩвдЗжЮіЃЌжЎЧАНВЙ§дкПЊЦєdouble
writeКѓЃЌУПДЮдрвГЫЂаТБиаывЊЯШаДdouble writeЃЌЖјdouble writeДцдкгкДХХЬЩЯЕФЪЧСНИіСЌајЕФЧјЃЌУПИіЧјгЩСЌајЕФвГзщГЩЃЌвЛАуЧщПіЯТвЛИіЧјзюЖрга64ИівГЃЌЫљвдвЛДЮIOаДШыгІИУПЩвдзюЖраД64ИівГЁЃЖјИљОнвдЩЯЮветИіЯЕЭГInnodb_dblwr_pages_writtenгыInnodb_dblwr_writesЕФБШР§РДПДЃЌвЛДЮДѓИХдк4ИівГзѓгвЃЌдЖдЖЛЙУЛЕН64ЃЌЫљвдДгетИіНЧЖШвВПЩвдПДГіЃЌЯЕЭГаДШыбЙСІВЂВЛИпЁЃ
ШчЙћВйзїЯЕЭГдкНЋвГаДШыДХХЬЕФЙ§ГЬжаЗЂЫЭСЫБРРЃЃЌдкЛжИДЙ§ГЬжаЃЌInnoDBДцДЂв§ЧцПЩвдДгЙЄађБэПеМфжаЕФdouble
writeжаевЕНИУвГЕФИББОЃЌНЋЦфИДжЦЕНБэПеМфЮФМўЃЌдйгІгУredo logЁЃЯТУцЯдЪОСЫвЛИігЩdouble
writeНјааЛжИДЕФЙ§ГЬЃК
090924 11:36:32
mysqld restarted
090924 11:26:33 InnoDB: Database was not shut
down normally!
InnoDB: Starting crash recovery.
InnoDB: Reading tablespace information from the
.ibd files...
InnoDB: Crash recovery may have faild for some
.ibd files!
InnoDB: Restoring possible half-written data pages
from the doublewrite.
InnoDB: buffer... |
Ш§ЁЂdouble writeЕФШБЕу?
dblwrЮЛгкЙВЯэБэПеМфЩЯЕФdouble write bufferЪЕМЪЩЯвВЪЧвЛИіЮФМўЃЌв§ШыСЫвЛДЮЖюЭтаДЕФПЊЯњЃЌУПИіЪ§ОнвГЖМБЛвЊЧѓаДСНДЮЁЃгЩгкашвЊДѓСПЕФfsyncВйзїЃЌЫљвдЫќЛсНЕЕЭMySQLЕФећЬхадФмЃЌЕЋЪЧВЂВЛЛсНЕЕЭЕНдРДЕФ50%ЁЃетжївЊЪЧвђЮЊЃК
1) double writeЪЧвЛИіСЌНгЕФДцДЂПеМфЃЌЫљвдгВХЬдкаДЪ§ОнЕФЪБКђЪЧЫГађаДЃЌЖјВЛЪЧЫцЛњаДЃЌетбљадФмИќИпЁЃ
2) НЋЪ§ОнДгdouble write bufferаДЕНеце§ЕФsegmentжаЕФЪБКђЃЌЯЕЭГЛсздЖЏКЯВЂСЌНгПеМфЫЂаТЕФЗНЪНЃЌУПДЮПЩвдЫЂаТЖрИіpagesЁЃ
double writeФЌШЯПЊЦєЃЌВЮЪ§skip_innodb_doublewriteЫфШЛПЩвдНћжЙЪЙгУdouble
writeЙІФмЃЌЕЋЛЙЪЧЧПСвНЈвщДѓМвЪЙгУdouble writeЁЃБмУтВПЗжаДЪЇаЇЮЪЬтЃЌЕБШЛЃЌШчЙћФуЕФЪ§ОнБэПеМфЗХдкБОЩэОЭЬсЙЉСЫВПЗжаДЪЇаЇЗРЗЖЛњжЦЕФЮФМўЯЕЭГЩЯЃЌШчZFS/FusionIO/DirectFSЮФМўЯЕЭГЃЌдкетжжЧщПіЯТЃЌОЭПЩвдВЛПЊЦєdoublewriteСЫЁЃ
ЫФЁЂdouble writeдкЛжИДЕФЪБКђЪЧШчКЮЙЄзїЕФЃП
ШчЙћЪЧаДdouble write bufferБОЩэЪЇАмЃЌФЧУДетаЉЪ§ОнВЛЛсБЛаДЕНДХХЬЃЌInnoDBДЫЪБЛсДгДХХЬдиШыдЪМЕФЪ§ОнЃЌШЛКѓЭЈЙ§InnoDBЕФЪТЮёШежОРДМЦЫуГіе§ШЗЕФЪ§ОнЃЌжиаТаДШыЕНdouble
write bufferЁЃ
ШчЙћdouble write bufferаДГЩЙІЕФЛАЃЌЕЋЪЧаДДХХЬЪЇАмЃЌInnoDBОЭВЛгУЭЈЙ§ЪТЮёШежОРДМЦЫуСЫЃЌЖјЪЧжБНггУbufferЕФЪ§ОндйаДвЛБщЁЃШчЩЯЭМжаЯдЪОЃЌдкЛжИДЕФЪБКђЃЌInnoDBжБНгБШНЯвГУцЕФchecksumЃЌШчЙћВЛЖдЕФЛАЃЌInnodbДцДЂв§ЧцПЩвдДгЙВЯэБэПеМфЕФdouble
writeжаевЕНИУвГЕФвЛИізюНќЕФИББОЃЌНЋЦфИДжЦЕНБэПеМфЮФМўЃЌдйгІгУredo logЃЌОЭЭъГЩСЫЛжИДЙ§ГЬЁЃвђЮЊгаИББОЫљвдвВВЛЕЃаФБэПеМфжаЪ§ОнвГЪЧЗёЫ№ЛЕЃЌЕЋInnoDBЕФЛжИДЭЈГЃашвЊНЯГЄЕФЪБМфЁЃ
ЮхЁЂMariaDB/MySQL/Facebook/Percona 5.7ЕФИФНј
MariaDB/MySQLИФНј
MariaDBЪЙгУВЮЪ§innodb_use_atomic_writesРДПижЦдзгаДааЮЊЃЌЕБДђПЊИУбЁЯюЪБЃЌЛсЪЙгУO_DIRECTФЃЪНДђБэПеМфЃЌЭЈЙ§posix_fallocateРДРЉеЙЮФМўЃЈЖјВЛЪЧаД0РЉеЙЃЉЃЌЕБдкЦєЖЏЪБМьВщЕНжЇГжatomic
writeЪБЃЌМДЪЙПЊЦєСЫinnodb_doublewriteЃЌвВЛсЙиБеЕєЁЃ
Oracle MySQLЭЌбљжЇГжFusionIOЕФAtomic WriteЬиадЃЈFusion-io
Non-Volatile Memory (NVM) file systemЃЉЃЌЖдгкжЇГждзгаДЕФЮФМўЯЕЭГЃЌвВЛсздЖЏЙиБеdouble
write bufferЁЃ
FacebookИФНј
ЪЕМЪЩЯетВЛФмЫуЪЧИФНјЃЌжЛЪЧЬсЙЉСЫвЛИіаТЕФбЁЯюЁЃдкЯжЪЕГЁОАжаЃЌхДЛњЪЧЗЧГЃЕЭИХТЪЕФЪТМўЁЃДѓВПЗжЧщПіЯТdblwrЖМЪЧгУВЛЩЯЕФЁЃЕЋШчЙћЮвУЧжБНгЙиБеdblwrЃЌШчЙћецЕФЗЂЩњР§ШчЕєЕчхДЛњСЫЃЌЮвУЧашвЊжЊЕРФФаЉpageПЩФмЫ№ЛЕСЫЁЃ
вђДЫFacebook MySQLЬсЙЉСЫвЛИібЁЯюЃЌПЩвдаДpageжЎЧАЃЌжЛНЋЖдгІЕФpage numberаДЕНdblwrжаЃЈЖјВЛЪЧаДШЋpageЃЉЃЌдкБРРЃЛжИДЪБЃЌЯШЖСГіМЧТМдкdblwrжаЕФpageКХЃЌМьВщЖдгІЕФЪ§ОнвГЪЧЗёЫ№ЛЕЃЌШчЙћЫ№ЛЕСЫЃЌФЧОЭашвЊДгБИПтжиаТЛжИДИУЪЕР§ЁЃ
Percona 5.7ИФНј
Percona ServerЕФУПИіАцБОЖМЖдInnoDBЕФЫЂдрТпМзіСЫВЛЩйЕФгХЛЏЃЌНјШы5.7АцБОвВВЛР§ЭтЁЃдкЙйЗН5.7жавбОЪЕЯжСЫЖрИіPage
CleanerЃЌЮвУЧПЩвдАбPage CleanerХфжУГЩКЭbuffer pool instanceЕФИіЪ§ЯрЭЌЃЌПЩвдИќКУЕФЪЕЯжВЂааЫЂдрЁЃ
ЕЋЪЧЙйЗНАцБОжаЃЌPage cleanerМШвЊИКд№ЫЂFLUSH LISTЃЌЭЌЪБвВвЊзіLRU FLUSH(ЕЋУПИіbp
instanceВЛГЌЙ§innodb_lru_scan_depth)ЁЃЖјетСНВПЗжШЮЮёЪЧПЩвдЖРСЂНјааЕФЁЃ
вђДЫPercona ServerдіМгСЫЖрИіLRU FLUSHЯпГЬЃЌПЩвдИќИпаЇЕФНјааlru flushЃЌБмУтгУЛЇЯпГЬЯнШыsingle
page flushзДЬЌЁЃУПИіbuffer pool instanceгЕгаздМКЕФlru flushЯпГЬКЭpage
cleanerЯпГЬЁЃlru flushЛљгкЕБЧАfree listЕФГЄЖШНјааздЪЪгІМЦЫуЁЃ УПИіlruЯпГЬИКд№здМКЕФФЧИіBuffer
poolЁЃвђДЫВЛЭЌlru flushЯпГЬЕФЗБУІГЬЖШПЩФмЪЧВЛвЛбљЕФЁЃ
дкНтОіЩЯЪіЮЪЬтКѓЃЌbp flushЕФВЂаааЇТЪДѓДѓЕФЬсЩ§СЫЁЃЕЋЪЧЖдгкЫљгаЕФЫЂдрВйзїЃЌЖМашвЊзпЕНdouble
write bufferЁЃетвтЮЖзХdblwrГЩЮЊСЫаТЕФЦПОБЁЃЮЊСЫНтОіетИіЮЪЬтЃЌdblwrНјааСЫВ№ЗжЃЌУПИіbp
instanceЖМгаздМКЕФdblwrЧјгђЁЃетбљИїИіLru flushЯпГЬМАPage cleanerЯпГЬдкзіpage
flushЪБОЭВЛЛсЯрЛЅМфВњЩњЫјГхЭЛЃЌДгЖјЬсЩ§СЫЯЕЭГЕФРЉеЙадЁЃ
ФуПЩвдЭЈЙ§ВЮЪ§РДХфжУвЛИіЖРСЂгкibdataжЎЭтЕФЮФМўРДДцДЂdblwrЃЌЮФМўБЛЛЎЗжГЩЖрИіЧјгђЃЌЗжЧјЪ§ЮЊbp
instanceЕФИіЪ§ЃЌУПИіЗжЧјЕФДѓаЁЮЊ2 * srv_doublewrite_batch_sizeЃЌУПИіbatch
sizeФЌШЯХфжУЮЊ120ИіpageЃЌЦфжавЛИігУгкЫЂFLUSH LISTЃЌвЛИігУгкЫЂLRUЁЃ
ШчЙћfast shutdownЩшжУЮЊ2ЃЌdblwrЮФМўдке§ГЃshutdownЪБЛсБЛЩОГ§ЕєЃЌВЂдкжиЦєКѓжиНЈЁЃ | 





