| ЮяСЊЭјСьгђНќЦкШчЛ№ШчнБЃЌЛЅСЊЭјКЭДЋЭГЙЋЫОељЯрВМОжЮяСЊЭјЁЃзїЮЊЮяСЊЭјСьгђЪ§ОнДцДЂЕФЪзбЁЃЌЪБађЪ§ОнПтвВдНРДдНЖрНјШыШЫУЧЕФЪгвАЃЌЖјдчдк2016Фъ7дТЃЌАйЖШдЦдкЦфЬьЙЄЮяСЊЭјЦНЬЈЩЯЗЂВМСЫЙњФкЪзИіЖрзтЛЇЕФЗжВМЪНЪБађЪ§ОнПтВњЦЗTSDBЃЌГЩЮЊжЇГжЦфЗЂеЙжЦдьЃЌНЛЭЈЃЌФмдДЃЌжЧЛлГЧЪаЕШВњвЕСьгђЕФКЫаФВњЦЗЃЌЭЌЪБвВГЩЮЊАйЖШеНТдЗЂеЙВњвЕЮяСЊЭјЕФБъжОадЪТМўЁЃ
ЧАЮФЬсЕНЕЭГЩБОЕФДцДЂЪЧЪБађЪ§ОнПташвЊНтОіЕФвЛИіжївЊЮЪЬтЃЌЖјЩЯвЛЦЊЮФеТНщЩмСЫЭЈЙ§еыЖдЪБађЪ§ОнЕФбЙЫѕЗНЗЈЃЌДгРћгУЪ§ОнБОЩэЬиеїЕФЗНУцЃЌНЕЕЭЪБађЪ§ОнЕФДцДЂГЩБОЁЃ
БОЮФНЋНщЩмЭЈЙ§ЖдЪ§ОнНјааЗжМЖДцДЂЃЌДгЪЙгУВЛЭЌДцДЂНщжЪЃЌвдМАМѕЩйЪ§ОнЕФИББОЪ§ЕФЗНУцЃЌНщЩмШчКЮдкБЃжЄЪБађЪ§ОнЕФВщбЏадФмЕФЧАЬсЯТЃЌНЕЕЭЪБађЪ§ОнЕФДцДЂГЩБОЁЃ
1. ЗжМЖДцДЂ
ЗжМЖДцДЂЃЌОЭЪЧАДФГвЛЬиеїЃЌНЋЪ§ОнЛЎЗжЮЊВЛЭЌЕФМЖБ№ЃЌУПИіМЖБ№ЕФЪ§ОнДцДЂдкВЛЭЌГЩБОЕФДцДЂНщжЪЩЯЁЃЮЊЪВУДашвЊЖдЪ§ОнНјааЗжМЖДцДЂЃПЮЊЪВУДВЛАбЫљгаЕФЪ§ОнЖМДцДЂдкзюБувЫЕФДцДЂНщжЪЩЯЃПетЪЧвђЮЊдкНЕЕЭДцДЂГЩБОЕФЭЌЪБЃЌЛЙашвЊБЃжЄЪ§ОнЗУЮЪЕФадФмЃЈЮвУЧжЊЕРЃЌДцДЂНщжЪЕФЖСаДадФмгыГЩБОвЛАуГЩе§БШЃЉЃЌЗжМЖДцДЂЪЧЖдСНепБШНЯКУЕФЦНКтЗНЗЈЁЃЗжМЖДцДЂЕФетвЛЫМЯывВЬхЯждкМЦЫуЛњЕФЬхЯЕНсЙЙРяЃЈМФДцЦїЁЂL1/L2
CacheЁЂФкДцЁЂгВХЬЃЉЁЃ
2. ЪБађЪ§ОнЕФЗжМЖДцДЂ
ЪБађЪ§ОнгІИУАДЪВУДЬиеїНјааЗжМЖФиЃПЪБађЪ§ОнЕФЪБМфДСЪЧвЛжжЗЧГЃКЯЪЪЕФЗжМЖвРОнЃЌдННќЦкЕФЪ§ОнВщбЏЕУдНЖрЃЌЪЧШШЪ§ОнЃЛдНОУвдЧАЕФЪ§ОнВщбЏЕУдНЩйЃЌЪЧРфЪ§ОнЁЃР§ШчЃЌгУЛЇЛсОГЃВщбЏвЛИіЩшБИЕФзюаТЮТЖШЃЌЛђепВщПДетИіЩшБИзюНќ1аЁЪБЛђепзюНќ1ЬьЕФЮТЖШЧњЯпЃЛКмФбЯыЯѓгУЛЇЛсОГЃВщбЏвЛИіЩшБИ1ФъЧАЕФЮТЖШЃЌетаЉ1ФъЧАЕФЪ§ОнвЛАуЛсгУгкДѓЪ§ОнЗжЮіЛђепЛњЦїбЇЯАжаЃЌЖјетаЉХњДІРэЕФГЁОАвЛАуЖдВщбЏЕФбгЪБВЛЛсЯёНЛЛЅЪНГЁОАФЧУДУєИаЁЃ
ШчЭМ1ЫљЪОЃЌвЛАуПЩвдНЋЪБађЪ§ОнЗжЮЊ3МЖЃЌЕквЛМЖЪЧзюНќ1ЬьЕФЪ§ОнБЃДцдкФкДцЛКДцCacheжаЃЌЕкЖўМЖЪЧзюНќ1ФъЕФЪ§ОнДцДЂдкЙЬЬЌгВХЬSSDжаЃЌЕкШ§МЖЪЧ1ФъвдЩЯЕФЪ§ОнДцДЂдкЛњаЕгВХЬHDDжаЁЃCacheжаЕФЪ§ОнПЩвдЪЙгУаДЛиЃЈwrite
backЃЉЛђепаДЭЈЃЈwrite throughЃЉЕФВпТдаДШыSSDЃЌЖјSSDжаЕФЪ§ОнПЩвдЭЈЙ§КѓЬЈГЬађЖЈЦкХњСПЕФЧЈвЦЕНHDDЁЃЮЊСЫБЃжЄЪ§ОнГжОУадЃЌвЛАуЛсЮЊЪ§ОнБЃДц2ИіЛђеп3ИіИББОЃЌЭЈЙ§ECБрТыПЩвдНЋИББОЪ§НЕЕЭЕН1.5ЩѕжСИќЕЭЃЌЕЋШДВЛгАЯьЪ§ОнЕФГжОУадЁЃВЛЙ§ECБрТыЛсЯћКФИќЖрЕФCPUКЭЭјТчДјПэЃЌНјЖјгАЯьВщбЏадФмЃЌвђДЫвЛАужЛгІгУдкДцДЂРфЪ§ОнЕФHDDЩЯЁЃ
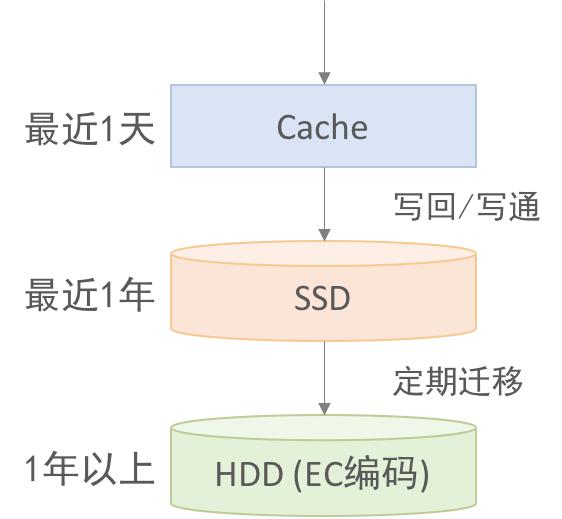
ЭМ1 ЪБађЪ§ОнЕФЗжМЖДцДЂ
3. ФкДцЛКДц
ЪБађЪ§ОнПтДѓВПЗжЧыЧѓЕФЪ§ОнЖММЏжадкзюНќ1ЬьЃЌНЋетаЉЪ§ОнБЃДцдкФкДцжаЃЌПЩвдБЃжЄетаЉЪ§ОнФмБЛПьЫйЕФЖСШЁЁЃЫфШЛФкДцЕФЗУЮЪЫйЖШПьЃЌЕЋЪЧГЩБОКмИпЃЈМлИёДѓдМБШSSDИпвЛИіЪ§СПМЖЃЉЃЌВЂЧвШнСПгаЯоЁЃвђДЫашвЊЖдЪ§ОнНјаабЙЫѕЃЌвдМѕЩйУПИіЪ§ОнЕФФкДцеМгУЃЌбЙЫѕЯрЙиЕФФкШнвбОдкЩЯвЛЦЊЮФеТжаНјааСЫНщЩмЃЌдкетРяВЛдйзИЪіЁЃСэвЛЗНУцЃЌгЩгкФкДцжаЕФЪ§ОнЪЧвзЪЇЕФЁЂЗЧГжОУЛЏЕФЃЌвЛЕЉжиЦєНјГЬЛђепжиЦєЛњЦїКѓОЭЛсЖЊЪЇЃЌШчЙћВЛЛжИДЪ§ОнЃЌЫљгаЧыЧѓНЋТфЕНЯТвЛМЖЕФДцДЂЩЯЃЌЖдЯТвЛМЖДцДЂдьГЩОоДѓЕФбЙСІЁЃвђДЫвЛАуЛсдкаДШыФкДцЕФЭЌЪБаДШыБОЕигВХЬЃЌдкжиЦєКѓжиаТМгдиЕНФкДцжаЁЃ
BeringeiЪЧFacebookПЊдДЕФвЛПюФкДцЪБађЪ§ОнПтЃЌЪЧFacebookЗЂБэЕФGorillaТлЮФЕФПЊдДЪЕЯжЁЃBeringeiЪЙгУвЛжжШ§МЖЕФФкДцЪ§ОнНсЙЙЃЌШчЭМ2ЫљЪОЃЌЦфжаЕквЛМЖЮЊЗжЦЌЫїв§ЃЌЕкЖўМЖЮЊЪБМфађСаЫїв§ЃЌЕкШ§МЖЮЊЪБађЪ§ОнЃЌЭЈЙ§ИУЪ§ОнНсЙЙПЩвджЇГжПьЫйЕФЪ§ОнЖСаДЃЛBeringeiЪЕЯжСЫвЛжжИпаЇЕФСїЪНЕФбЙЫѕЫуЗЈЃЌДгЖјЪЙФкДцеМгУзюаЁЛЏЃЛBeringeiжЇГжаДШыФкДцЕФЭЌЪБаДШыгВХЬЃЌВЂдкжиЦєКѓЛжИДЪ§ОнЁЃШЛЖјBeringeiвВгавЛаЉЯожЦЃЌЦЉШчжЛжЇГжИЁЕуаЭЪ§жЕЁЂЪБМфОЋЖШжЛЕНУыЁЂжЛФмАДЪБМфДСЫГађЕФаДШыЪ§ОнЁЃ
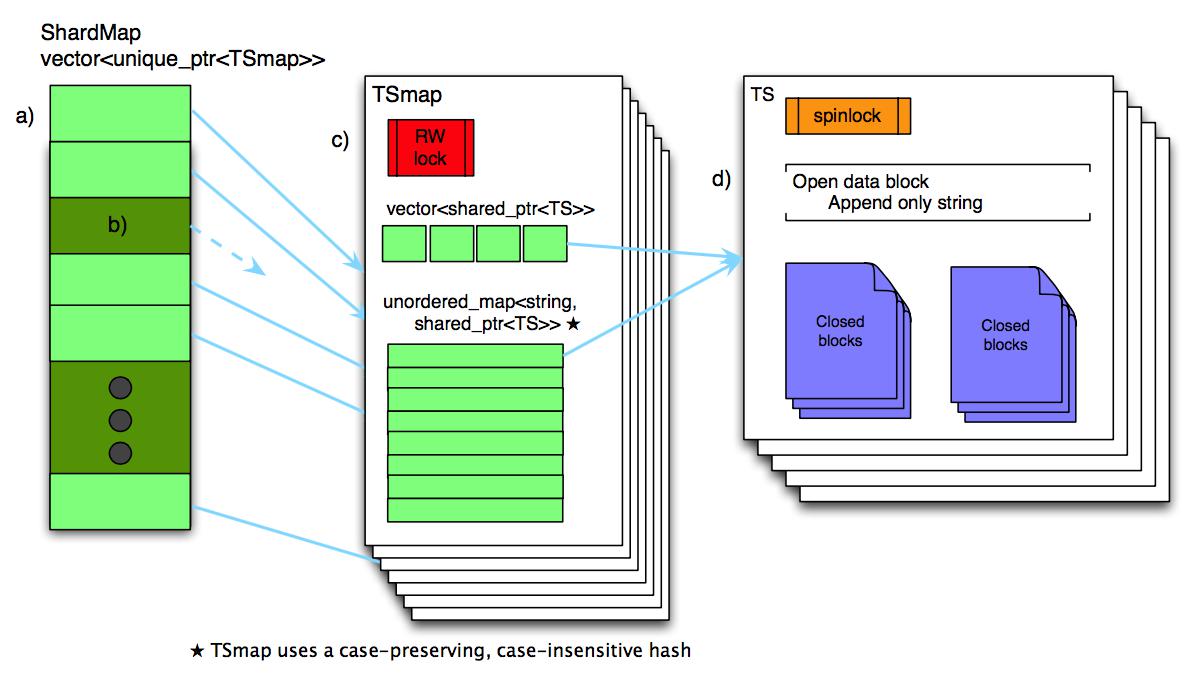
ЭМ2 BeringeiЕФФкДцЪ§ОнНсЙЙ
4. SSDгыHDD
гУЛЇгаЪБЛсЙизЂЪБађЪ§ОндкЙ§ШЅ1жмЁЂЙ§ШЅ1ИідТЁЂЙ§ШЅ1ФъЕФЧїЪЦЃЌАбзюНќ1ФъЕФЪ§ОнДцДЂдкЙЬЬЌгВХЬSSDЩЯЃЌПЩвдЪЕЯждкУыМЖЩѕжСбЧУыМЖЖСШЁЙ§ШЅ1ФъЕФЪ§ОнЁЃЖј1ФъвдЩЯЕФЪБађЪ§ОндђКмЩйгУгкНЛЛЅЪНВщбЏЃЌетаЉЪ§ОнЭљЭљЛсгУгкДѓЪ§ОнЗжЮіЛђепЛњЦїбЇЯАЃЌетаЉХњДІРэГЁОАЖдВщбЏЕФбгЪБВЛЛсЯёНЛЛЅЪНГЁОАФЧУДУєИаЃЌвђДЫПЩвдАбетаЉ1ФъвдЩЯЕФЪ§ОнДцДЂдкЛњаЕгВХЬHDDЩЯЁЃ
SSDЕФМлИёДѓдМЪЧHDDЕФМИБЖЃЌЕЋЪЧSSDЕФадФмвЊдЖдЖИпгкHDDЁЃдкЧАЮФжаЮвУЧНщЩмЙ§ЃЌЪБађЪ§ОнПтЛсЖдЪБађЪ§ОнНјааЗжЦЌЃЌвЛИіЗжЦЌЕФЪ§ОнЛсСЌајЕФДцЗХдквЛЬЈЛњЦїЕФгВХЬЩЯЃЌвђДЫЖСШЁвЛИіЗжЦЌЕФЪ§ОнЪЧЫГађЖСШЁЕФЁЃЖдгкЫГађЖСШЁРДЫЕЃЌSSDКЭHDDЕФадФмЪЧВюВЛЖрЕФЃЌвђДЫетжжДцДЂЗНЪНЖдгкSSDКЭHDDРДЫЕЖМЪЧКЯЪЪЕФЁЃЕЋЪЧЃЌвЛЬЈЛњЦїЩЯЛсДцДЂДѓСПЕФЗжЦЌЃЌЕБЭЌЪБЖСШЁЖрИіЗжЦЌЪБЃЌгВХЬЕФЗУЮЪОЭБфГЩСЫЫцЛњЖСШЁЁЃЖдгкЫцЛњЖСШЁРДЫЕЃЌHDDгЩгкашвЊЦНОљ10КСУыЕФбАЕРЪБМфЃЌвђДЫжЛФмзіЕНАйетИіСПМЖЕФIOPSЃЌЖјSSDФмзіЕНЭђМЖЩѕжСЪЎЭђМЖЕФIOPSЃЌБШHDDИп2ЕН3ИіЪ§СПМЖЃЈзЂ3ЃЉЁЃгЩДЫПЩМћЃЌHDDжЛФмгІИЖХњДІРэетжжВЂЗЂСПНЯЕЭЁЂЫГађЖСШЁДѓСПЪ§ОнЕФГЁОАЃЌЖјжЛгаSSDФмжЇГжИпВЂЗЂЁЂЕЭбгЪБЕФНЛЛЅЪНВщбЏГЁОАЁЃ
5. ECБрТы
ЮЊСЫБЃжЄЪБађЪ§ОндкЛњЦїхДЛњЁЂгВХЬЙЪеЯЕФЪБКђЛЙФме§ГЃЕФЗУЮЪЁЂВЛЛсЖЊЪЇЃЌвВОЭЪЧЮЊСЫБЃжЄЪ§ОнЕФПЩгУадКЭГжОУадЃЌЛсЮЊЪ§ОнБЃДцЖрИіБИЗнЃЈвВГЦЮЊИББОЃЉЃЌИљОнПЩгУадКЭГжОУадЕФашЧѓвЛАуЪЧБЃДц2ЕН3ИіИББОЃЌетбљЕБЦфжаЕФ1ИіЛђеп2ИіЛњЦїхДЛњЁЂгВХЬЙЪеЯЕФЪБКђвВФмБЃжЄЪ§ОнЕФе§ГЃЗУЮЪвдМАВЛЛсЖЊЪЇЁЃЕЋЪЧетвВДѓДѓдіМгСЫДцДЂЕФГЩБОЃЌ3ИіИББООЭЪЧ3БЖЕФДцДЂГЩБОЁЃЭЈЙ§ECБрТыЃЌПЩвдНЋДцДЂГЩБОНЕЕН1.5БЖЃЌЭЌЪБВЛЛсНЕЕЭЪ§ОнЕФПЩгУадКЭГжОУадЁЃ
ECБрТыШЋГЦЪЧErasure CodingОРЩОТыЃЌЪЧвЛжжЪ§ОнБЃЛЄММЪѕЃЌзюдчгІгУгкЭЈаХаавЕЕФЪ§ОнДЋЪфЕФЪ§ОнЛжИДжаЃЌЭЌЪБвВгУгкRAID-5КЭRAID-6ДцДЂеѓСаММЪѕжаЁЃECБрТыжївЊЪЧРћгУЫуЗЈЖддЪМЪ§ОнПщНјааБрТыЕУЕНаЃбщПщЃЌВЂНЋдЪМЪ§ОнПщКЭаЃбщПщЖМДцДЂЦ№РДЁЃЕБдЪМЪ§ОнПщЖЊЪЇЪБЃЌЭЈЙ§ЦфЫћдЪМЪ§ОнПщвдМАаЃбщПщФмжиаТМЦЫуГіЖЊЪЇЕФЪ§ОнПщЃЛЕБаЃбщПщЖЊЪЇЪБЃЌжиаТМЦЫуМДПЩЕУЕНаЃбщПщЁЃетбљОЭФмЖдЖЊЪЇЕФЪ§ОнНјааЛжИДЃЌДгЖјДяЕНШнДэЕФФПЕФЁЃЖдгкkИідЪМЪ§ОнПщКЭmИіаЃбщПщЃЌЫуЗЈФмБЃжЄдкЖЊЪЇШЮвтmИіПщКѓЃЌЖМПЩвдЭЈЙ§ЫуЗЈЛжИДГідРДЕФkИідЪМЪ§ОнПщЁЃШчЭМ3ЫљЪОЃЌвЛИіЩњГЩОиеѓGTГЫвдkИідЪМЪ§ОнПщзщГЩЕФЯђСПЃЌПЩвдЕУЕНгЩkИідЪМЪ§ОнПщКЭmИіаЃбщПщзщГЩЕФЯђСПЁЃ
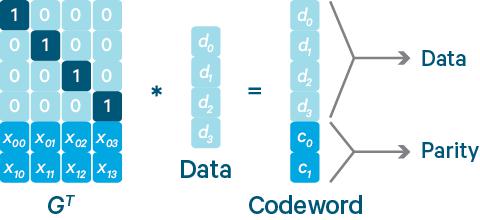
ЭМ3 ECБрТыЙ§ГЬЃЈзЂ4ЃЉ
НЋECБрТыгІгУгкЪБађЪ§ОнЃЌЙиМќЮЪЬтдкгкШчКЮЖЈвхЪВУДЪЧЪ§ОнПщЁЃвЛжжжБЙлЕФЗНЗЈЪЧвЛИіЗжЦЌзїЮЊвЛИіЪ§ОнПщЃЈзЂвтЃЌвЛИіЗжЦЌЪЧДцДЂдквЛИіЛњЦїЩЯЕФЃЌВЛЭЌЕФЪ§ОнПщЪЧДцДЂдкВЛЭЌЛњЦїЩЯЕФЃЌвђДЫВЛгІИУАбвЛИіЗжЦЌдйЛЎЗжЮЊЖрИіЪ§ОнПщЃЉЁЃЕЋЪЧгЩгкЗжЦЌЕФЪ§ОнСПВЛвЛжТЃЌашвЊНЋЪ§ОнПщЖМЖдЦыЕНзюДѓЕФЪ§ОнПщЃЌЖјЧвЕУЕНЕФаЃбщПщвВЪЧИњзюДѓЕФЪ§ОнПщвЛбљДѓЃЌетЛсЕМжТДцДЂПеМфКЭМЦЫузЪдДЕФРЫЗбЁЃОйИіМЋЖЫЕФР§згЃЌЦЉШч1ИіЗжЦЌЕФДѓаЁЪЧ1MЃЌЦфЫћk-1ИіЗжЦЌЕФДѓаЁЖМЪЧ1KЃЌФЧУДОЭашвЊНЋетk-1ИіЗжЦЌЖМЖдЦыЃЈПЩвдЭЈЙ§ВЙ0ЃЉЕН1MдйМЦЫуECБрТыЃЌЕУЕНЕФmИіаЃбщПщЖМЪЧ1MЕФЁЃИќКУЕФЗНЗЈЪЧРћгУЕзВуДцДЂЕФЪ§ОнПщзїЮЊECБрТыЕФЪ§ОнПщЃЌЦЉШчЪЙгУHbaseДцДЂЪБађЪ§ОнЕФЛАЃЌОЭПЩвдРћгУЕзВуHDFSЬсЙЉЕФECБрТыЙІФмЁЃ
6. змНс
ИљОнЪБађЪ§ОнЬьШЛЕФЪБађЩЯЕФРфШШЛЎЗжЃЌПЩвдЖдЪБађЪ§ОнНјааЗжМЖДцДЂЃЌНЋзюНќЕФзюШШЕФЪ§ОнБЃДцдкФкДцжаЃЌНЋжаЦкЕФДЮШШЪ§ОнДцДЂдкSSDЩЯЃЌНЋдЖЦкЕФРфЪ§ОнДцДЂдкHDDЩЯЃЌФмдкБЃжЄВщбЏадФмЕФЧАЬсЯТЃЌНЕЕЭДцДЂГЩБОЁЃСэЭтЃЌЭЈЙ§ECБрТыММЪѕЃЌФмМѕЩйЪ§ОнЕФИББОЪ§ЃЌДгЖјЪЙДцДЂГЩБОФмНЕжСИќЕЭЕФЫЎЦНЁЃ |






