| 简介 基础知识 另一个 SQL 特性是它不仅仅是一种查询语言。您还可以使用它来定义数据结构;控制对数据的访问;以及插入、修改和删除数据的发生。通过提供一种公共语言,SQL 简化了 DBA、系统程序员、应用程序员、系统分析员和最终用户之间的通信。当项目的所有参与者都使用同一种语言时,他们之间所建立起来的协作就可以减少整体系统开发时间。 历史证明,保证 SQL 成功的最重要的一个特性就是它使用类似英语的语法轻松地检索数据的能力。理解这种语言比理解数据页面的结构和程序源代码要容易得多:
想想看:当访问文件中的数据时,程序员必须编码指令来打开文件、开始一个循环、读取记录、检查 EMPNO 字段是否等于适当的值、检查文件结尾、回到循环的开头等。 SQL 本来就是非常灵活的。它使用自由格式的结构,该结构可以让用户开发 SQL 语句来适合他们的需要。DBMS 在执行之前会分析每个 SQL 请求,以检查语法是否正确和优化该请求。SQL 语句不需要从任何给定的列中开始,您可以将它们串在一行中,或者把它们拆成几行。例如,以下这条单行的 SQL 语句与我前面使用的三行示例等价:
SQL 的另一个灵活特性是您可以用许多形式不同但功能等价的方法来制定一个请求。例如:SQL 可以连接表或嵌套查询。您始终可以将嵌套查询转换成等价的连接。您可以在大量的函数和谓词中看到这一灵活性的其它示例。具有等价功能的特性的示例包括:
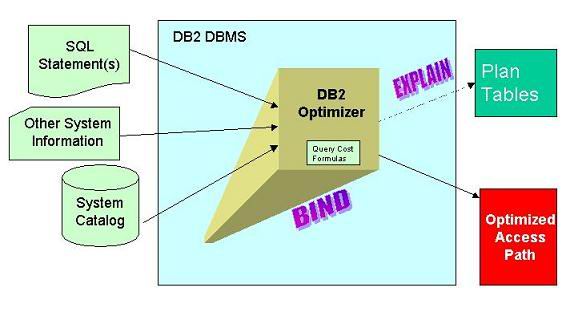
SQL 展示的这一灵活性并不总是称心的,因为形式不同但功能等价的 SQL 公式可以提供非常不同的性能。我将在本文的以后部分讨论该灵活性所造成的结果,并提供开发有效的 SQL 的准则。 如我所说的,SQL 指定了要检索或操作什么数据,但没有指定数据库如何完成这些任务。这就使 SQL 本身变得很简单。如果您能够记得关系数据库的一次处理一个集合(set-at-a-time)的特点,您就开始掌握 SQL 的本质和性质了。一条 SQL 语句可以作用于多行。作用于一组数据而不需要建立如何检索和操作数据的能力将 SQL 定义成非过程化语言 因为 SQL 是一种非过程化语言,所以一条语句可以代替一系列过程。同样,由于 SQL 使用集合级别的处理以及 DB2 优化查询来确定数据导航逻辑,所以这是可能的。有时,如果不使用 SQL 语句,一条或两条 SQL 语句可以完成的任务就需要完整的过程化程序来完成。 优化器 优化器在功能上等价于一个专家系统。专家系统是一个标准规则集合,当与情境数据组合时,它返回一个“专家”意见。例如,医学专家系统采用一个规则集合,用来确定哪些药可以用于哪些疾病,将规则集与描述疾病症状的数据组合,并将知识库应用于输入症状的列表。DB2 优化器会根据存储在 DB2 系统目录中的情境数据和 SQL 格式的查询输入来生成对数据检索方法的专家意见。 在 DBMS 中优化数据访问的概念是 DB2 最强大的能力之一。请记住,您访问 DB2 数据时应告诉 DB2 要检索什么,而不是如何检索。无论数据实际上是如何存储和操作的,DB2 和 SQL 都可以访问该数据。从物理存储特征中分离出访问标准叫作物理数据独立性。DB2 的优化器是完成该物理数据独立性的组件。 如果您不要索引,DB2 仍然能够访问数据(尽管效率会降低)。如果将一列添加到正在被访问的表中,DB2 仍然可以在不更改程序代码的情况下操作数据。因为到 DB2 数据的物理存取路径并不是由程序员在应用程序中编码的,而是由 DB2 生成的,所以这种情况是完全有可能发生的。 这个特点与非 DBMS 系统非常不同,在那种系统中,程序员必须知道数据的物理结构。如果有索引,程序员就必须编写适当的代码来使用该索引。如果某人删除了索引,程序就不能工作,除非程序员进行更改。而使用 DB2 和 SQL 就不必如此。这一灵活性完全归功于 DB2 自动优化数据操作请求的能力。 优化器根据许多信息执行复杂的计算。要使优化器的工作方式直观化,可以将优化器想象成执行一个四步骤的过程:
这个过程的第二步是最有趣的。优化器怎样决定如何以它的方式执行您可以发送的大量 SQL 语句? 优化器有许多类型的优化 SQL 的策略。它如何选择在优化存取路径中使用这些策略中的哪一个?IBM 并没有发布优化器如何确定最佳存取路径的真正和深入的详细信息,但优化器是一个 基于成本的优化器。这意味着优化器将始终尝试为每个查询制定减少总体成本的存取路径。要实现这个目标,DB2 优化器会应用查询成本公式,该公式对每条可能的存取路径的四个因素进行评估和权衡:CPU 成本、I/O 成本、DB2 系统目录中的统计信息和实际的 SQL 语句。 性能准则 1) 使 DB2 统计信息保持最新 :如果没有存储在 DB2 系统目录中的统计信息,优化器在优化任何事物时都会遇到困难。这些统计信息向优化器提供了与正在被优化的 SQL 语句将要访问的表状态相关的信息。存储在系统目录中的统计信息的类型包括:
当执行 RUNSTATS 或 RUN STATISTICS 实用程序时,统计信息就会填充 DB2 系统目录。您可以从控制中心(Control Center)、批处理作业或通过使用命令行处理器来调用该实用程序。一定要与您的 DBA 一起工作以确保在适当的时候积累统计信息,尤其是在生产环境中。 2) 构建适当的索引 :也许您为保证最佳 DB2 应用程序性能而可以做的最重要的事就是根据应用程序使用的查询为您的表创建正确的索引。当然,说总比做更容易。但我们可以从一些基础开始。例如,考虑以下这条 SQL 语句:
什么索引会对这个简单查询有作用?首先,考虑您可以创建的所有可能的索引。您的第一个简短列表可能看起来如下:
这是一个好的开始,Index3 可能是最好的。它让 DB2 使用索引来立即查找满足 WHERE 子句中的两个简单谓词的行。当然,如果您已经有许多关于 EMP 表的索引,您也许应该检查再创建另一个关于表的索引所带来的影响。要考虑的因素包括:
索引设计涉及的内容比到目前为止我所讨论的要多得多。例如,您也许要考虑索引重载以实现仅索引访问(index-only access)。如果 SQL 查询要寻找的所有数据都包含在索引中,那么 DB2 也许只使用索引就可以满足该请求。请考虑我们前面的 SQL 语句。给定了关于 EMPNO 和 DEPTNO 的信息,我们要寻找 LASTNAME 和 SALARY。我们还从创建关于 EMPNO 和 DEPTNO 列的索引开始。如果我们在索引中还包含了 LASTNAME 和 SALARY,我们就不再需要访问 EMP 表,因为我们需要的所有数据都已经在索引中。该技术可以大大提高性能,因为它减少了 I/O 请求的数量。 请记住:使每个查询成为仅索引访问是不谨慎,甚至也是不可能的。您应该谨慎使用该技术以便用于特别棘手或重要的 SQL 语句。 SQL 编码准则
但是,这些规则并不是 SQL 性能调优的最终和最高目标 - 决不是。您可能需要附加的、深入的调优。但遵循前面的规则将确保您不会犯降低应用程序性能的“新手”错误。 特定数据库应用程序开发技巧 要确保在您的应用程序中经常发出 COMMIT 语句。COMMIT 语句控制工作单元。发出 COMMIT 会将自上一个 COMMIT 语句之后的所有工作“永远”记录到数据库中。在发出 COMMIT 之前,可以使用 ROLLBACK 语句回滚工作。当修改数据(使用 INSERT、UPDATE 和 DELETE)但没有发出 COMMIT 时,DB2 将在数据上加一把锁并保持该锁 - 这把锁会使其它应用程序在等待检索被锁住的数据时超时。通过在工作完成时发出 COMMIT 语句,并且确保数据是正确的,就释放了该数据以供其它应用程序使用。 另外,构建应用程序时要考虑使用情况。例如,当某个特定查询返回几千行给最终用户时,要慎重处理。对于在程序和最终用户之间的在线交互,很少会用到几百行以上的数据。您可以在 SQL 语句上使用 FETCH FIRST nROWS ONLY 子句来限制返回到查询的数据量。例如,考虑以下查询:
该查询将只返回 200 行。如果有超过 200 行符合条件也没有关系;如果您尝试从查询中 FETCH(访存)超过 200 行,DB2 将用 +100 SQLCODE 表明数据结束。当您想要限制返回给程序的数据量时,这种方法很有用。 DB2 支持另一个名为 OPTIMIZE FOR nROWS 的子句,该子句不限制要返回给游标的行数,但从性能角度看可能是有帮助的。使用 OPTIMIZE FOR nROWS 子句告诉 DB2 如何处理 SQL 语句。例如:
这告诉 DB2 尝试尽快访存前 20 行。如果您的 Delphi 应用程序在显示从数据库检索出来的数据行时每次显示 20 行,那么这将非常有用。 对于只读游标,使用 FOR READ ONLY 子句确保游标无歧义。Delphi 不能在 DB2 游标中执行位置更新,因此将 FOR READ ONLY 附加到每条 SELECT 语句后面可以使游标成为无歧义的只读游标,从而对 DB2 有所帮助。例如:
|