|
・ 概念和结构 ----数据仓库的经典概念由W.H.Inmon于1992年最早提出: “数据仓库是20世纪90年代信息技术构架的新焦点,它提供集成化和历史化的数据,集成种类不同的应用系统,数据仓库从事物发展和历史的角度来组织和存储数据,以供信息化和分析处理之用。” ----数据仓库具有以下四个基本特点:
----数据仓库应用是一个典型的C/S结构。其客户端的工作包括客户交互、格式化查询及报表生成等。服务器端完成各种辅助决策的SQL查询、复杂的计算和各类综合功能等。现在,普遍采用三层结构的形式,即在客户与服务器之间增加一个应用服务器,它能加强和规范决策支持的服务工作,集中和简化客户端和DW服务器的部分工作,降低系统数据传输量,因此工作效率更高。 ----・ 异构特性 ----由于实际的企业应用环境非常复杂,它们可能分布在不同的地理位置上,使用着不同的数据组织形式和操作系统平台,加上应用不同所造成的数据不一致性问题,因此,在普通的应用环境中很难将这些高度分布的数据集中起来充分利用。在构建数据仓库进行数据转移的过程中,则可以通过数据转移工具将位于不同操作系统平台、不同数据组织形式中的数据按照一定的规则,集中在一个数据仓库中,从而保证数据仓库中数据的完全一致,达到充分利用各种数据源的目的。因此,数据转移工具必须支持异构数据源。 ----由于数据仓库系统存储的数据量大,对查询速度要求快,因此它往往采用分布式的客户/服务器体系结构,并支持并行处理的硬件平台。数据仓库系统可运行于不同操作系统的机器上,数据也分布在不同的机器上,整体上构成一个系统,再通过适当的粒度划分和数据分割,可提高数据抽取和查询响应的并行度。数据仓库也支持广泛的硬件平台,从单 CPU到 SMP (对称多处理 )、 NUMA (非均匀存储存取 ) SMP簇或者 MMP (大规模并行处理 )体系,利用并行处理器将单个查询分为多个子任务并将它们分布到多个处理器上执行,从而提高查询的响应速度。因此,从数据仓库的运行环境来看,它是运行在一个异构平台上。 ----・ 异构技术 ----实现数据源中的数据向数据仓库的集成需要解决两个问题:提取和格式转换。对于从异构数据库中提取数据大多采用开放式数据库互连(ODBC), ODBC是一种用来在数据库系统之间存取数据的标准应用程序接口,目前流行的数据库管理系统都提供了相应的ODBC驱动程序,它使数据库系统具有很好的开放性,数据格式转换也很方便。另一种提取数据的方法是针对不同的数据库系统编写专用的嵌C接口程序,这样可提高数据的提取速度。例如,Stanford大学的WHIPS数据仓库原型系统提出在每个数据源上建立一个捆绑器,数据库上的捆绑器用嵌C编写,以实现数据的提取和格式转换。对于从 Web服务器提取数据可采用标准的JDBC接口,对于从不同的文件系统中提取数据则需要分别编写相应的接口程序。 ----为了从异构数据源中集成数据,这些数据源包括关系数据库、文件系统、主机上的DB2、IMS数据库及Web服务器等,各数据库厂商和其他软件开发商提供了很多中间件工具来提取和转换数据,如Informix的InfoMover、Microsoft SQL Server 7的DTS和Oracle的Open Gateway等,这些工具在一定范围内解决了数据的提取和转换。目前,这些工具还不能自动完成数据的抽取,用户还需利用这些工具编写适当的转换程序,而且数据往往是批量加载,数据源被假设为不工作状态。 ----数据仓库还可运行在多种硬件环境和操作系统上,充分发挥分布式数据库和并行处理器的能力,提高查询响应速度。例如Sybase提供了应用大型并行处理器的Sybase MPP作为SQL Server的可选扩充;Microsoft的SQL Server 7查询处理器引入了一个允许查询间并行处理的并行操作器,建立在现有的并行I/O和查询间处理能力基础之上。 基于数据仓库的数据开采
----・ 数据开采 ----数据开采(DM)又称数据挖掘,是应用特定的发现算法,从大量数据中搜索或产生一个感兴趣的模式或数据集。 ----数据开采过程分为三个步骤:数据准备、开采和表述。在解决实际问题时,经常要同时使用多种模式。一个数据开采系统或仅仅一个数据开采查询就可能生成成千上万的模式,但是并非所有的模式都令人感兴趣。一个重要的概念,兴趣度 (Interestingness),通常被用来衡量模式的总体价值,它包括正确性(Validity)、新奇性(Novelty)、可用性(Usefulness)和简洁性(Simplicity)。 ----数据开采工具还要求具有开放性,它的开放性体现在两个方面:能与各种数据源集成,分析结果是通用的或易于转化的。数据开采工具相互差别很大,这不仅体现在关键技术上,还体现在运行平台、数据存取和价格等方面。从运行平台来看,简单的工具可运行在PC的DOS或Windows上,复杂的工具要求运行在Unix工作站或并行处理平台上;从数据存取来看,简单工具处理的数据以文件形式输入,复杂工具要求大型的数据库环境。 ----・数据仓库与数据开采的结合 ----数据仓库和数据开采是作为两种独立的信息技术出现的。数据仓库是不同于数据库的数据组织和存储技术,它从数据库技术发展而来并为决策服务,通过OLAP工具验证用户的假设;数据开采是通过对文件系统和数据库中的数据进行分析,获得具有一定可信度知识的算法和技术。它们从不同侧面完成对决策过程的支持,相互间有一定的内在联系。因此,将它们集成到一个系统中,形成基于数据开采的OLAP工具,可以更加有效地提高决策支持能力。 ----数据开采与数据库报表工具的区别在于后者是将数据库中的某些数据抽取出来,经过一些数学运算,最终以特定的格式呈现给用户,而前者则是对数据背后隐藏的特征和趋势进行分析,最终给出关于数据的总体特征和发展趋势。 ----数据开采不一定需要建立在数据仓库基础上,但以数据仓库为基础,对于数据开采来说源数据的预处理将简化许多;另外,为了保证结果的正确性,数据开采对基础数据量的需求是巨大的,数据仓库可以很好地满足这个要求。 实例: DM3_DW
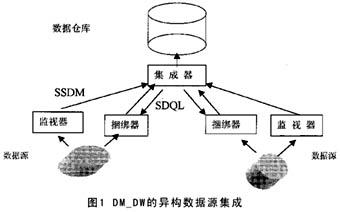
----数据仓库系统DM3_DW是在国产数据库管理系统 DM3的基础上,研制的一个具有自主版权的数据仓库系统,包括数据仓库管理系统和联机分析处理工具(OLAP)。 ----・ DM3_DW的异构数据源集成技术 ----1 利用面向对象的思想设计了一种针对异构数据源的通用数据模型――半结构化数据自描述的数据模型SSDM(SemiStructured Data Model),来表示所有的数据,数据源和数据仓库之间按SSDM格式传送数据,并在此基础上构造了查询语言SDQL(SemiStructured Data Query Language)。 ----DM3_DW通过在数据源上运行监视器和捆绑器来实现数据的集成,如图1所示。监视器定时检测数据源上的数据变化,并按SSDM 格式向集成器报告;捆绑器执行集成器SDQL格式的查询语句,完成实化视图的初始化和增量式维护。
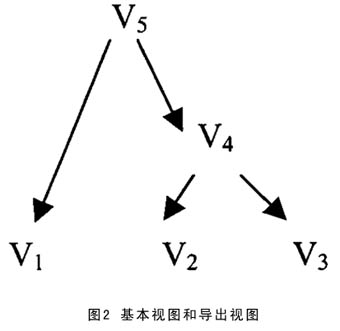
----2 实现了实化视图和对实化视图的增量式维护,使数据仓库和数据源7×24小时工作。扩充SQL语言功能,满足实化视图的需要。 ----实化视图的定义分两类:基本视图和导出视图。基本视图只涉及选择-投影-连接SPJ三种关系操作,不包含子查询和聚集操作;导出视图只能由基本视图产生,可以包含子查询和聚集操作。如图2所示,V1、V2、V3是基本视图,V4、 V5是导出视图。实化视图的增量式维护只维护基本视图,导出视图由数据仓库统一维护,这样做的优点是减轻了视图维护复杂度。
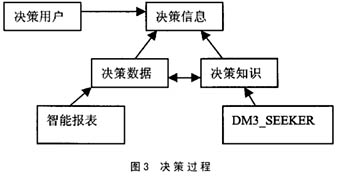
----・ DM3_Seeker数据开采工具 ----DM3_DW的数据开采工具DM3_Seeker采用基于关联规则的开采算法,包括顺序算法、并行和分布式开采算法以及增量式更新和维护算法,是一个集成的关联规则开采工具。DM3_Seeker可运行在Windows、Unix等操作系统上,通过 ODBC接口可与不同厂商的数据库集成,它的数据输入平台为数据库和数据仓库。 ----在创建数据仓库时,必须将数据的粒度定义在数据仓库的元数据中,粒度是数据仓库所维护的数据概要级别,数据仓库通常包含不同层次的粒度。通过元数据的粒度机制,在数据仓库中形成基本数据、历史数据和综合数据,这样,决策所需要的数据源就准备好了。在决策分析时,通过基于假设驱动的OLAP工具智能报表产生决策数据,通过DM3_Seeker产生决策知识,决策数据与决策知识相互作用,合起来成为决策信息,进一步提高了决策支持能力。决策过程如图3所示。
|