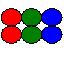
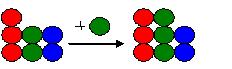
| 序 两个程序员同时修改某个文件的内容,如何合并?程序员在自己的工作空间完成了若干修改,如何将这些修改提交到公共的工作空间,而不覆盖别人的工作成果?程序员如何拿到公共的工作空间里最新的代码,更新自己的工作空间,同时又保证自己刚刚改过的内容不丢失?在产品发布1.0版本后,同时在开发1.1修正版和2.0升级版,如何将1.1版里的缺陷修正带到2.0版里?这些话题都涉及到版本合并(merge)。版本合并(merge)是软件版本控制(version control)和软件配置管理(software configuration management)的基础。 本文给出版本合并的基本模型:矩形模型。在实践中遇到的版本合并情景总可以归结到矩形模型上。本文给出基于矩形模型的版本合并的基本算法。这些基本算法既适用于文件的合并,也可以适用于项目/产品的合并。 不论是否采用工具软件,采用什么样的工具软件,软件开发团队都有必要掌握版本合并的基本概念和方法。版本合并的正确和灵活的运用,可以有效的避免混乱,显著的节约开发成本,缩短开发时间,并使团队成员集中精力于更有价值,更体现创造力的工作上。 抽象 让我们用几个不同颜色的小球的集合来代表要合并的内容。要合并的内容可以是文件,可以是目录,可以是一个包括某个产品的所有的源代码的工作空间。 首先,我们有一个初始的版本,两个红球,两个绿球,两个蓝球:
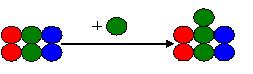
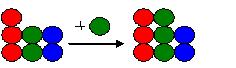
假定Tony拿到了这个初始版本,并在其上工作,添加了一个绿球:
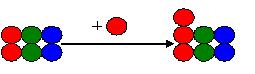
而另一个程序员,比如Grace,也拿到了这个初始版本,并在其上工作,添加了一个红球:
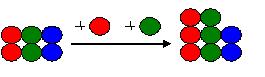
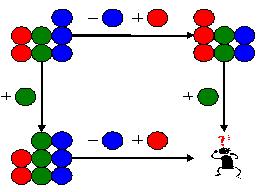
并且,她已经把她的新版本提交到了公共区域。那么,当Tony提交他的修改的时候,就需要进行合并。见下图:
合并应该是把两个人的改动都拿进来。其结果是:三个红球,三个绿球,两个蓝球。
看来我们已经发现了版本合并的基本模型:找到两个不同版本的共同祖先版本,然后进行合并。是这样的吗? 让我们来看下一个例子:
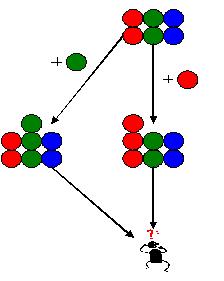
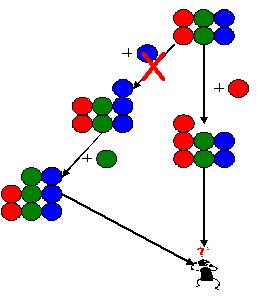
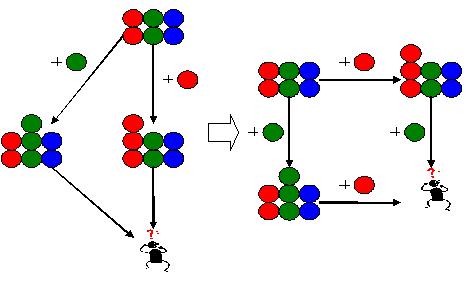
在这个例子里,Tony先添加了一个蓝球,形成一个版本。接着又添加了一个绿球,形成另一个版本。与此同时,Grace添加了一个红球,并把修改提交到了公共区域。下面,该Tony提交他的工作了。但是要注意到,这时Tony不想把添加蓝球那个修改带进来。只想把添加绿球那个修改带进来。可能是因为,添加蓝球那个修改只是个尝试,可能是因为添加蓝球那个修改还没有到该提交的时候,无论如何,现在不想把添加蓝球那个修改带到进来,可又要把添加绿球那个修改带进来。 如果我们使用共同祖先法进行合并,那么就会把添加蓝球的那个修改带进来。这不是我们想要的。
可能你会想到一个改进:基于共同祖先法,但是在合并时把添加蓝球那个修改减去:
哦,这回是对的了。但是,这看起来有点复杂了。或许我们有更简单的模型? 来看看下面这个模型。这个模型不是树状的,而是矩形的。
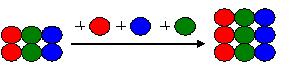
矩形的左上角是Tony添加蓝球之后,添加绿球之前的版本。左下角是Tony添加绿球之后的版本。右上角是Grace添加红球并提交到公共区域的版本。我们要根据这三个版本及三个版本之间的差异,来求出合并后的版本。 有不止一种方法来求解。其中最简单的一种是:把右上角的版本(三红两绿两蓝)加上右边的变化(加一个绿球),得到合并后的版本(三红三绿两蓝):
特别简单,是不是? 还有两种方法能解,其一跟这个方法很类似,是同一类解法。其二从另一个角度入手,属于另一类解法。你现在可以停下来想一想,争取把它们想出来。当然,也可以立即往下阅读,到下面的章节里看这两类解法的详细描述。 而对于我们给出的第一个例子,就是那个引入了共同祖先法的例子,我们给出矩形模型下的描述。
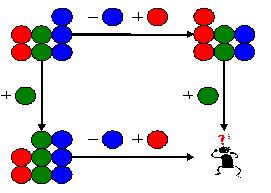
对于适用于共同祖先模型的情形,总是可以使用矩形模型。共同祖先模型反映的是一类特殊的情况,而矩形模型是更一般的情况。 下面则是一个比较复杂的例子:
它也可以使用矩形模型:
反正,无论如何,合并是关于四个角和四条边的问题,关于一个矩形的问题。这是版本合并的本质。这跟它们的共同祖先无关,跟它们在版本树上的位置和复杂关系无关。就好像,如果你想找邻居串门,你不需要先拿到一张城市地图来研究。 解法1:分解角 当我们遇到一个大问题的时候,就会考虑如何把它分解为小问题,然后逐一解决。当我们要把一大块内容做版本合并的时候,我们就会考虑把它分成小块,逐一合并。例如,在下面的例子里,我们根据颜色把矩形的角分解,分别考虑:
我们考察红色球:左下角两个,左上角两个,右上角三个。右上角起了变化,所以,右下角应该和右上角一样,是三个。考察绿色球:左下角三个,左上角两个,右上角两个。左下角起了变化,所以,右下角应该和左下角一样,是三个。考虑蓝色球:左下角三个,左上角三个,右上角两个。右上角与众不同,所以,右下角应该和右上角一样,是两个。合在一起,右下角是三个红球,三个绿球,两个蓝球。 那么,在软件配置管理中,是什么样的情形呢?
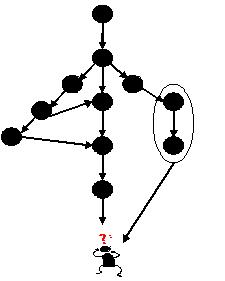
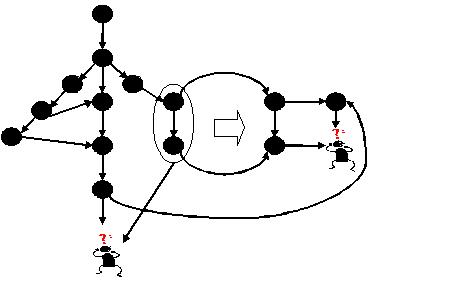
李如,假定有个任务单元,包含目录A、文件B和目录C的变更。任务单元记录着A、B、C各自的变更前版本和变更后版本,如果它们存在的话。我们现在要把这个任务单元合并到工作空间。我们分头考虑A、B和C。
可以看到,当我们把一大块内容进行分解后,我们会考察分解后的这些小块是否已经能够一眼看出该如何合并了。如果能,就合并。如果不能,就继续分解。已知分解到能够一眼看出该如何合并为止。当然,也有可能直到最后还是不能‘自动’合并。 在什么情况下能够一眼看出该如何合并呢?什么情况下不能一眼看出呢?什么情况下不能‘自动’合并呢?
以上是合并和冲突的基本类型。关于冲突,这里再多说一些:
解法2:分解边 在解法1中,我们把矩形的每个顶点拆分,再拆分,直到我们能一眼看出来该如何合并。这样,这个矩形被拆分成了很多小矩形,而最后,我们会把这些小矩形再叠加起来,得到右下角,问题的答案。 在解法2中,我们不再拆分矩形的顶点,而去拆分矩形的边。矩形的顶点代表着一个版本的内容,而矩形的边则代表着版本间的变化。我们把变化拆分,让变化一点一点的发生,让我们能够看清楚,然后一步一步的处理。最后得到答案。 在解法1中,我们需要的输入信息是矩形的三个角,然后得到第四个角,即右下角。在解法2中,我们需要的输入信息是矩形的一个角(左下角或者右上角),再加上一条边(下边或者右边),然后得到答案,也就是右下角。
我们还用这张熟悉的图。右上角加右边就是右下角。右上角是三红两绿两蓝,右边是加一个绿球,所以右下角是三红三绿两蓝。或者,左下角加下边就是右下角。左下角是两红三绿三蓝,下边是减一个蓝球,加一个红球,所以右下角是三红三绿两蓝。 细心的读者可能会问,为什么右边是加一个绿球呢?为什么下边是减一个蓝球,加一个红球呢?这是因为,一般来说,下边等于上边,右边等于左边。而上边和左边代表着两个已知版本间的差异,这是我们可以知道的。 我们回到关于把变更拆分的话题上。拆分是为了把问题缩小到可处理。如果问题本来就不大的话,那就直接解决它!比如,在上图中,如果我们沿右上角加右边求解,那就不用拆分,直接加上一个绿球就好了。而如果我们沿左下角加下边求解,那就拆分,先减去一个蓝球,再加上一个红球。 那么这种拆分的本质是什么呢?把边拆分,实际是在边上加了若干对中间点。这些中间点,把矩形拆分成了若干并排的小矩形。然后我们对于每个小矩形进行版本合并。例如:
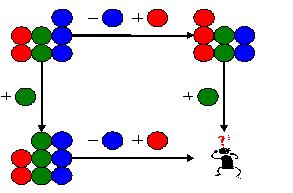
那么,根据什么原则来拆分边,也就是拆分变更呢?变更总是有逻辑意义的,比如,修复了一个缺陷,对已有功能实现了一个小的改进,或者新添加了一个功能。总体的变更是由若干这样有逻辑意义的小变更组成的。那么我们就根据逻辑意义来拆分变更。并且。我们把每个逻辑意义的小变更叫做一个任务单元(Task)。它可能包括了对若干个文件/目录的修改。在这个任务单元里,我们既记录相关文件/目录的变更前版本,也记录变更后版本。这样,对于每个任务单元,我们就知道如何合并了。而对于任务单元的集合,也就是总体的变更,我们也就知道如何处理了。 综合应用 假定,你面临着如下挑战:假定你所在的团队在开发一个这个软件产品,该产品是由若干子产品组成的,就好像汽车是由发动机,轮子,主体框架等等组成的。在产品发布1.0版本后,同时在开发1.1版和1.0_A用户专版。所谓1.0_A用户专版,其实和1.0版差不多,换了些图标,还应客户要求添加了一个特殊功能,接收该用户另一个软件系统的输入。现在,要生成1.1_A用户专版,因为1.1版跟1.0版相比,修正了很多缺陷,还做了一些小的改进。
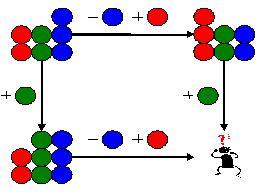
上面是一个特别复杂的情况。如果情况没有这么复杂,那么,我们是可以把步骤简略的。比如,还记得前面出现过的这张图吗:
特别简单,是不是? 重要的是,我们要理解版本合并的基本模型和基本方法,然后,灵活运用。找到具体问题的有效解决之道。 工具 合适的工具会给版本合并带来便利。不同的版本合并工具、版本控制工具、配置管理工具对版本合并的矩形模型提供不同程度和不同角度的支持,尽管工具不一定明确指出支持矩形模型。 Flooda是一个开源免费的配置管理工具。它从底层结构设计上支持版本合并的矩形模型。你可以通过它来研究矩形模型,也可以在实际工作中运用它。 |