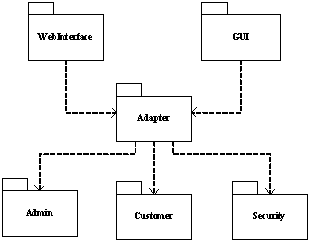
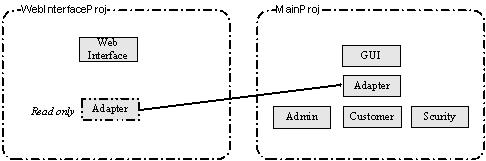
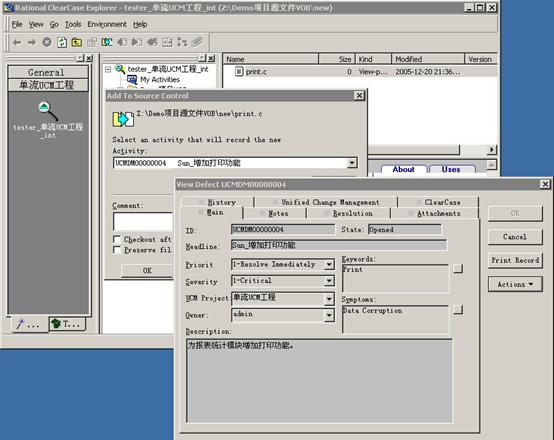
| �������ĸ���UCM����Ҫ�ص㣬��Ͼ����Ӧ�ó��������漰��UCM���̽����ļ�����Ҫ�������֣���������ΰ���ʵ��������ƹ滮һ�������UCM���̣��Ա�֤�������ԡ� ���ڹ��̾��������ù�����Ա��˵��UCM���̣�Project���ṩ��һ�����ù����Ļ�����ܣ������˶�������洢�ṹ�Ĺ�������������������Stream���ͻ��ߣ�Baseline���Ĺ��������ҿ���ͨ��UCM����������ͬ����ٹ���ClearQuest�ļ��ɡ�ͨ����UCM���̵Ķ��ƺ滮��������Ч�������ù�������������Ҫ���⡣ һ ���ù�������������� ��ʵʩ���ù���֮ǰ�����б�Ҫ������˽����ù������������ݹ��̵�ʵ����Ҫ��ȷ�����ù�����ʼ����㡣 ��ν���ù����������ǽ�ʲô���������������ɵĹ������ڰ汾�����У�ʹ��ʲô�����ֶζ�����й�����������������������з�����Ч�ض�����д�ȡ�����ȣ�������Ҫȷ�ϻ���Ԥ�����������������У����������Ŷӻ����ʲô�������Ŷ��еĵ��θ��ֽ�ɫ�ij�Ա��ζ������ʹ�á�һ������£���Ƶ���ĵ�����Դ�����Լ���Ӧ��Ŀ¼�ṹ���ڰ汾����֮�£����Ⲣ�������ù�����ȫ�������ù����������������ܹ���¼����������������ʷ�����ܹ���ʱ������ִ�ʱ��������������״̬��Ϊ�˴ﵽ���Ŀ�ģ�����������Դ�������Ӧ��Ŀ¼�ṹ��Ҫ���ڰ汾����֮�����⣬��������Ҫ���������������������в����Ĺ����������ù����ķ��룺 ����ϵͳ�������ĵ�����������˵���飬����ģ�͵ȵȣ� UCM�������ļ���Ŀ¼����Ϊ���߲�εĶ���UCM�����component������ʾ�����ܹ���ͨ��������activity�������ƶ�������ĸ��ģ������̻ͬ���в���Ԥ��ı仯�����Ե��������������������ṩ���ڽϸ߲�ι�������������������������ʵ��Ӧ���У�ͨ��ʹ��UCM����������һ����Ʒ������һ���Ʒ�Ŀ����������������ô��ʱ��ʼ����һ��UCM���̿�ʼ�������������ù����أ� ͨ������£�һ��UCM���̵�����Ӧ��������ϵͳ��ϵ�ṹ��Ƶ����Ϊǰ�ᡣ��ϵ�ṹ��һ������ϵͳ�������л����µĸ߲����������������ϵͳ�ĸ߲�νṹ����ƺ�ʵʩ����������������֯Ԫ�ء�����ӿڼ���֮����ΪԪ�ء�ͨ��������ϵ�ṹ��ʵ����ͼ��Implementation View�������ǿ��Ի���ڿ��������������ľ�̬��֯�ṹ���Դ�Ϊ��㣬��UCM�����н����������ļܹ�ӳ��ΪUCM�������֯�ṹ���Ӷ����������ù���ϵͳ�������ܡ� ��ҳ�� �����ù���ϵͳ�ڣ������ܰ汾���Ƶ��ļ�����Ŀ¼����Ϊ�������������Ԫ�أ�element�����й�������UCMͨ������Ӧ��������ۼ���һ��UCM����ڣ��Ա��ڶԴ����������������й�������ˣ�����Ӧ�ý���������֯Ϊ�ṹ������UCM�����Ȼ��ʹ��UCM���̶��������ͳһ������ ������������ϵ�ṹ��4+1��ͼ�У�ʵ����ͼ����ָ��������ʵ������ϵͳ�������������ģ����ļ������Ŀ¼����������ù���ϵͳ�������˵�dz���Ҫ������ʵ����ͼ������Ϊ��������������ϵͳ����UCM���ù��������ʹ����ЩUCM�������ص�Ŀ¼���ļ���֯�����������Ժ�Ŀ����������뷢����������˵����һ������ϵͳ�п��ܰ������û�Ȩ����ģ�飬��ô��ʵ����ͼ�оͻ�ָ������Щ�ļ���Ŀ¼����������û�Ȩ����ģ�飬��ô���ǾͿ��Խ������Զ�����ģ��ӳ��Ϊһ��UCM���������ģ���Ӧ���ļ���Ŀ¼�ۼ���������½��й�������ʵ��Ӧ���У��ȿ��Խ�һ������ģ��������ӳ��Ϊһ��UCM�����Ҳ���Խ�һ����ϵͳ����������ϵͳӳ��ΪUCM��������ǿ��Ը��ݾ��������ȷ��UCM��������ȡ� ���ʹ��IBMͳһ�������̣�RUP����ָ�������Ŀ���������RUP�Ƽ�ʹ���������ϳ�һ��ϵͳ������������ھ��Լ���Զ����ԣ���ʹ�ý�����ϵͳӳ��ΪUCM������ṹ��Ϊ������ ͼ1��ʾ����һ������ϵͳ��ϵ�ṹʵ����ͼ�İ�ͼ������ϵͳ������Ϊ�����Զ�����ģ�飬ʹ�ð���package������ʾ������ƪ�������Dz�����ϸչʾ���ڲ����ļ���Ŀ¼��֯�ṹ�����ڰ��ڲ����ھ����Լ������֮�����Զ����ԣ���һ������£�����ֱ�ӽ�һ����ӳ��Ϊһ��UCM�������˿��Խ������������Ӧ��UCM����У�������ʵ����ͼ����֯UCM������ļ���Ŀ¼����֯�ṹ�� ϵͳ�����ϵͳ����ڲ������Ҫ��ϵͳ�����ļ����������̼ƻ��������ĵ�������ĵ��Լ�����ϵͳ�ܹ��ĵ��ȵȣ� ��ʶ������ù���ϵͳ�����е�UCM���֮����������UCM���̶�����й�������ʱ��Ҫ����ʹ�õ���UCM���̻��Ƕ�UCM���̡�UCM���������������Ϊһ��Ⱥ���ṩһ�����������ɡ������Լ�����Ļ������ﵽ��ͬ����һ������ϵͳ��Ŀ�ġ����һ������ϵͳ����ģ��Ĺ����Ƚϸߣ�������Ա��Ҫ���ܵؽ��й��������ҵ�ǰֻ����һ���汾�Ŀ�����������ͬһ�����̵Ķ�汾���п�������ô�ù��̵����ù���ֻ��Ҫʹ��һ��UCM���̼���������еĹ�����Ȼ�������Щ��ģ�ϴ��ϵͳ��˵�����������ϵͳ����ģ����϶Ƚϵͣ��ڿ��������л���Ӱ�첻��Ϊ�˱��ڹ���������ʹ�ö��UCM���̶�����й�������ijһ���������ɸ�ģ�����ϵͳʹ��һ��������UCM���̽��й�����������ϵͳ���������ٶ�����ϵͳ���м��ɡ����⣬���һ������ϵͳ��Ҫ����汾�IJ��п��������磬ͬʱ��Ҫ�°汾�Ŀ����;ɰ汾����������ʱ��Ҳ��Ҫʹ�ò�ͬ��UCM���̷ֱ���������й����� ������UCM���̽�����һ�����̶���⣨PVOB���У���ô��Щ��ͬ��UCM��������Թ���һ��PVOB�ڵ�UCM������ڽ���UCM����ʱָ��������ЩUCM�����ѡ����Ҫʹ�õ�UCM������ߣ�ȷ���Ƿ���ж�UCM��������ĵ�Ȩ�ޡ����������������У������Ը�����Ҫ���Ӻ�ȥ����Ӧ��UCM��������ɸ��Ĵ�UCM����ʹ�õĸ���UCM��������û��ߣ��Ա����ܹ�ʹ�ú��ʵİ汾�����м��ɿ�����Ϊ�˱����ͻ�������ܹ���֤����������һ���ԣ������UCM���̹���һ�����ʱ��������Ը�UCM����Ĺ��̣�����ʹ�ø�����Ĺ���ֻ���ж�ȡȨ�ޡ����ʵ����Ҫ������̶�ijһ��UCM������и�дȨ�ޣ���Ҫ���ڽ����ĸ�����������Ļ������deliver����ͳһ�����ϣ���������Ӧ�Ĺ鲢��merge���ͻ��߸��¡���ͼ��ʾ���ù���ϵͳʹ��������UCM���̡� ��ҳ�� ClearCase UCMʹ������stream��Ϊ����ṩһ��������Զ�������VOB���ֶΣ�һ������һ�������Ϊ������ͨ�����������ϵ�UCM��ͼ��ѡȡ��������з��ʡ�һ�����뽨�������ϵ�UCM��ͼ���γ���һ����Ը���Ĺ����ռ䣨workplace�������������ռ��ʹ���߲�������������������Ա��һ�������е�������Ա���������Ա��ϵͳ������Ա�ȵ�Ҳ����ʹ��UCM�����ʺ������ǵĹ����ɹ��� ��һ��UCM�����У�һ�㽫����Ϊ���ࣺ������(Integration stream)�Ϳ�����(Development stream)����һ���������ڣ�һ��ʹ�ù�������������ʾ���̳�Ա�����ձ���������������Ա�ڿ������ϵijɹ��ύ(deliver)���������ϣ���������п������ϵı����ͨ������������ָ�����ʵ���̱���Ȼ���ڿ�������ͨ����ԭ����(rebase)���������ϵĻ����뼯�����ϵ��Ƽ����߱���ͬ���� ��ʵ��Ӧ���У�һ��UCM���̼ȿ���ֻʹ��һ������������UCM���̣�Ҳ����ʹ�ö������������UCM���̣��û������ڴ���UCM����ʱ����ѡ����ͼ3��ʾ����
�ڴ���UCM����ʱ�����Ⱦ���Ҫ�ڵ����Ͷ�����ѡ��ʹ�����ֽṹ��������������һ�������ֽṹ���ص㼰ʹ�ó����������ṹ��ζ�����г�Աʹ��һ�������������й��������̳�Ա�Ĺ����ռ佨����һ������һ�µ�����֮�ϣ��κ�һ����Ա�ı������ύ��ClearCase�������Ժ��ܹ���������Ա�Ĺ����ռ��ڵõ���ӳ����ˣ������ṹ��UCM���̽����ṩһ�ּ��п���ģ�ͣ���ͬ���û�ʹ�üļ��/������������ĺ��ύ�����һ����˵������������»�ʹ�õ����ṹ��UCM���̣� 1. ���̵Ŀ����������ݿ�������(Agile development)��������Ա��Ҫ���쿴�����������ı���� 2. �ڹ��̿������ڽΣ����ɸ�������Ա��Ҫ��ʱ�������롣 3. ������������Ա��1��3����ɵ�С�鼯���������е�С��ģ��������Ա����Ҫ���ܿ�������Ա֮��ı����Ҫ��ʱ�ɼ��� 4. ʹ��UCM����������ClearCase���ṩͼ�λ��ϲ�(Merge)���ʲ�������ͼ���ļ����������ļ��ȵȡ� ��ͼ��ʾ���Dz��õ���UCM���̵Ĺ������̣�
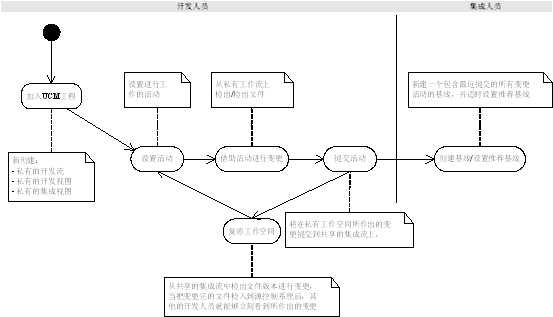
����ͼ�п��Կ�������UCM���̵ļ�����Ϊ"UCM�������̣�����"�������ŶӰ���������������λ������Ա���ڿ�����У�������Աͨ������������Լ��Ļֱ�ӴӼ������м��������ļ��汾���б��������ɱ����������뵽Դ����֮������������Ա���ܿ��������������ı�������������������Ϊ���п�����������Աʼ�շ��ʵ��Ǽ������е����ݣ�����ڿ���������ʹ�õ����ݶ������µġ����ڴˣ���������Ա��ɱ����Ҫ�����������뵽Դ����ʱ����Ҫ��������IJ��ԣ���֤�������Ч�ԣ�����Ӱ�쵽������Ա�Ĺ�������Ϊ������Ա������Ҫ��ʱ��ؿ�����Ա����Ŀ�����ı���������ݱ���������Ļ������Ŀ���ߣ����ڸ�����Ŀ��չ�ij̶Ⱦ����Ƽ����ߡ� ����ڵ����ṹ���ԣ������ṹ��UCM������ζ�Ų�ͬ�Ŀ�����Աʹ��һ��������˽�й�������������Ա֮��Ĺ����ռ䱣��һ���ĸ����ԣ�ͬʱ����ͬ�Ŀ�����Ա��ʹ��һ�������ļ���������������Ա������ɶ�Ӧ�ı�����������ɹ��ύ��������֮�����еij�Ա�ſ��Կ������µı仯��������Ա�ڼ���������ʱ�ش������ߣ���������Ŀ�Ľ�չ״�������Ƽ����ߣ�����˽�п�����ͨ����ԭ(Rebase)������ʹ�ø����������Ļ���ͬ�������Ƽ����߱���һ�£��Ӷ�ʹ����������Ա��ͬһ�����Ͻ��б����� ��UCM�����У����������������Ķ����Ը���Ŀ�����ʹ�ò��п�������˳������ʵ�֣����Ƕ����ṹ��ʹ�����ù���ϵͳ�ĸ����Դ�����ӣ���������UCM������ô���ڹ�����ά����ͨ�������������������ʹ�ö�����UCM���̣� 1. ������Ա��Ҫһ����Ը����˽�й����ռ䣬�ڽ���ɹ�������������Ա֮ǰ����Ҫ����˽�й����ռ��ڶ�����ĵ�Դ�ļ����е��ʣ�ȷ�����������ƻ�ϵͳ���ȶ��ԡ� 2. ��Ҫ�Է����İ汾������Ŀ�Ļ��߽��о�ȷ�Ŀ��ơ� 3. ����Ŀ���й����У��������г�������ֱ�����������£���Ҫʹ�ö���UCM���̱�֤��˽�пռ���ʹ��һ��������������Ļ����汾�� 4. ʹ��UCM����������ClearCase�ܹ��ṩͼ�λ��ϲ�(Merge)���ʲ��������ı��ļ���Rational Roseģ���ļ��Լ�Word�ĵ��ȵȡ� ������ʹ�ö����ṹUCM���̵Ĺ������̣�
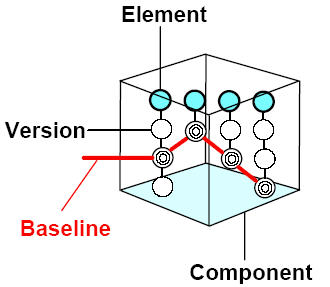
��ҳ�� ��ͼ8��ʾ��������һ��UCM �����ijһ�ض�ʱ��һ��Ԫ�صļ��ϣ����������ڸ�ʱ����ѡȡ����Ԫ�ذ汾�ļ��ϣ�������¼��������Ŀ������������ɵĹ�������ʶ����ָ���������̱������ɸ�����Ҫ��ʹ�û���������ij���ض�ʱ�̵����á��붯̬������Stream����ͬ�����ߵľ�̬�ģ�����ġ�
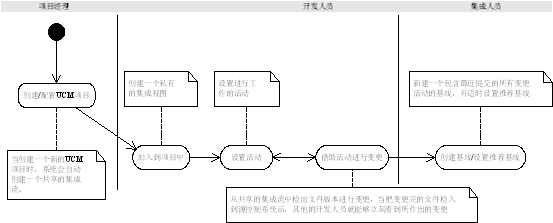
�����UCM�������֯��滮����Ӧ�أ���Ҫ������Щ����Ļ��ߴ�����ά�����ԡ������������ ��θ���UCM�����ָ��һ��UCM���̵Ļ��ߡ� ��һ����Ŀ�ij�ʼ�Σ�������Ա����Ŀ������Ҫȷ��ʹ����Щ������Դ��Ϊ��Ŀ��ʼ����㣬֮��ʹ��һ��������һ�������������б�ʾ�����ʹ�����е�UCM�������ôʹ����������еĻ�����Ϊ�½����̵ij�ʼ���ߡ����ʹ�����еĻ���VOB(Base ClearCase VOB)����ô��Ҫ�����ѱ�ʶ��labled���İ汾ת��Ϊ���ߣ������½�������Ϊ����ij�ʼ���ߡ����������������У�Ҳ��Ҫ�����ԣ�ÿ�����ÿ�ܣ����ڼ������ϴ������ߣ����������Դﵽ����Ŀ�꣺ 1. ������Ա֮�����ͬ���˴˵Ĺ�����ͨ�������ԵĽ������½����ߣ������Ƽ����߸�ԭ��������Ա���Թ����˴˵ijɹ��� 2. ���Դ����ٺϲ���merge����ʱ�����������������ԵĽ��н����븴ԭʱ����Ҫ���˽�й����ռ��빲�����ɿռ�İ汾��ͻ���Ӷ��������ύ�����ɹ����ٺϲ��Ĺ������� 3. ���Լ��緢�������ļ������⡣������һ���µĻ��ߺ���Ҫ���������б��롢������ִ�г���ͨ�������ԵĴ�����������Լ�ʱ�����ڿ��������ж�Ӱ���������ɵ����⡣ 4. ���Ա�ʶ��������������������Ҫ����̱�������ÿ�ε��������հ汾���²��汾�������汾�ȵȡ� ���ڵ���UCM������˵�����ڲ����ڿ�����Ա˽�пռ�����ͬ���ɹ�������֮������⣬���û�б�Ҫ�����Եش����µĻ��ߡ����������ߵ�Ŀ������Ϊ�˱�ʶ�洢�������������о�����Ҫָ���������̱��� ÿ�����߶���һ����Ӧ�ļ�����ν�ļ�����DZ�ʶһ�������������ȶ��Ե����ԣ�ͨ�����֣����Դ����˽�һ�����ߵĴ���״����ȱʡ����£�ClearCaseʹ�����¼��� Rejected��δͨ�����ԣ�������ʹ�� ���½�һ�����߲���Ҫ������в���ʱ��������Ҫ�������������Է�ֹ������Ա�����ύ�����Ӱ�켯�������ݵ��ȶ��ԣ�������Ŀ���ڵ�ȷ���Բ��Բ���Ҫ����̫��ʱ�䣬���Ҳ���᳤ʱ��������������������Ŀ���������в�����ɴ��Ӱ�졣���Ҫ���г�ʱ��ĸ��Ӳ��ԣ�����ԴӼ������½�һ�������������ڼ������½����ߺ����������������������ڲ�����ִ�и�ԭ������ָ���½�����Ϊ��ԭĿ����ߣ�������Լ��������н������ڲ��������о���IJ��ԣ������Ͳ��᳤ʱ������������������������Ŀ������Ӱ�졣 ��ͨ��һϵ�еIJ���֮�Ϳ���������Ӧ���ߵĵȼ������ɸ��ݾ���������趨�Ƽ����ߣ�ͨ����ԭ���������µļ��ɽ��ͬ���������������ϡ� ��ҳ�� ��UCM�����У�����ϵͳ�ı��ͨ�����Activity������ɣ��Ӽ����Ƕ����������ǿ��ѻ������������������壬����������Ŀ���������Ϊ��ĽǶ�����������Ҳ���Խ�UCM�еĻ��Activity��ͬ��ʵ�е�ʵ�ʻһһ���������������Ϳ���ͨ���ֱ�۵���ȷ�����Ŀ���������ǣ�ClearCase�Ļ�����ܹ����ػ�������Լ���ص�ע�ͣ����Ҳû���κε����̿��ƺ���ʷ��¼������С�͵�UCM������˵�����������������ӡ����Ƕ�����Ҫͨ��������������֤����˳���ݽ��Ĵ���������Ŀ��˵�����ӿ��ƺ����ı�������������Ŀ�������Ѷȣ���������ķ��ա�����������£�����Ҫ��UCM����ͬ�������ϵͳClearQuest�༯���������һ���⡣ ���ɺ��UCM�����еĻ��Activity��ͬClearQuest�еı���������������ͼ9��ʾ����ͨ��ClearQuest�Ա�����������������ڵĹ������٣��ﵽ������������������̵�Ŀ�ġ�
��ҳ�� ���ĸ������������½�һ��UCM����ʱ��Ҫ���ǵļ������⣬ͨ�����ϵ����ۣ�ϣ���ܹ�ʹ�����˽��ڴ���UCM����֮ǰ����������������Ӧ�ƻ������Եȵȡ����������в�ά��һ��UCM������һ��ӵĹ����������������۵��������⣬�����UCM����ʹ���и�����Ҫ������Ӧ�ĵ�����ά�����������UCM����ϵͳ�Ĺ����Ϳ��ƣ�Ҳ��һ��dz���Ҫ�Ĺ�����ϣ�������ܸ����Ľ�һ��ѧϰ�춨һ���ʯ�� �������� ��־ǿ��IBM�й���������������������ʦ��Ŀǰ����IBM Rational ClearCase�IJ��Թ�������Ϥ���ù�����������ʵ�����Լ�������Ʒ��ȫ���ԡ� |