| 本文讨论以下内容: ・对象类型如何对内存使用的影响 ・对象池机制如何影响垃圾收集 ・访问大规模数据时的数据流 ・内存使用率分析 本文使用到以下技术:.NET Framework, C# 内存是一个所有程序都需要的资源,但是合理的内存使用正在成为一种失传的技术。因为用Microsoft®.NET Framework所写的托管应用程序依靠垃圾收集来分配和清扫内存。对许多应用程序来说,用百分之三到五的CPU时间进行垃圾收集(GC)之于不用操心内存管理是一个相当公平的交易。 但对于应用程序来说CPU时间和内存都是宝贵的资源,最小化垃圾收集消耗时间可能较大提升应用程序的性能和健壮性。如果一个应用程序可以更加有效的使用可用内存,这时它表示垃圾收集器运行频次将更少并将花费更少的时间。因此与其考虑垃圾收集器在你的应用程序里这样做或那样做,倒不如直接看看内存使用。 大多成品机器都有一个容量巨大的RAM,并且在大多数情况下,比如使用短整数代替常用的优化可能被视为是微不足道的。在本文中我将让你改变这个看法。我将着眼于类型大小,各种设计技巧,以及如何分析一个程序的内存使用。我的例子将集中于C#,但是这个讨论同样适用于Visual Basic®.NET,managed C++,和任何你能想到的.NET目标语言(.NET-targeted languages) 我假定你理解垃圾收集工作的基本原理,包括相关概念如:代(generations),释放模式(the disposal pattern),和弱引用(weak references)。如果你不熟悉这些概念,Jeffrey Richter有一篇很好的关于垃圾收集的文章在Garbage Collection: Automatic Memory Management in the Microsoft .NET Framework。 类型大小 内存使用最终依赖于你的程序中程序集的已定义和使用的类型,因此让我们先从探究系统中各种类型的大小开始。 图 1展示了在System命名空间中定义的核心. NET值类型的字节大小,以及他们对应的C#类型。我使用了非安全代码和C# sizeof操作符来查验这些值类型在托管内存中的大小。对这些类型中的一部分来说,用Marshal.SizeOf方法代替sizeof操作符将导致不同的值,包括bool和char,既然Marshal.SizeOf计算了一个已封送类型的非托管大小,并且这些类型是non-blittable(意思是在托管和非托管代码之间传递时他们可能需要转换)。更多内容很快就要谈到。 结构(一种值类型)的大小是其各字段的大小的和,加上所有用来对齐字段的自然边界的附加系统开销。引用类型的大小是其字段上舍入到下一个4字节边界,加上8字节系统开销。(为了解到底你的引用类型用了多少空间,你可以在分配他们时测算一下堆大小的变化,或者你可以使用后面讨论的CLR Profiler工具。)这意味着所有引用类型占用至少12个字节,因此在C#中任何小于16个字节长的对象可能用一个结构会更加有效率些。当然,如果你需要储存一个引用到这个类型时用结构是会有问题的,因为频繁装箱可以耗尽内存和CPU周期。此时,小心使用结构是很重要的。 既然字段对齐可以影响一个类型的大小,一个类型内部的字段组织在它最终的大小方面扮演了重要角色。一个类型设计和用那个设计的字段组织受到应用到类型上StructLayoutAttribute的影响。一般情况下,C#,Visual Basic .NET,和C++编译器都应用一个StructLayoutAttribute到结构,指定一个Sequential(顺序的)布局。这意味着这个字段依照它们在源文件中的顺序来布局。然而,在.NET Framework 1.x中,一个Sequential设计请求是不能受到即时编译器(JIT)响应的,尽管它是由封送拆分器提出的。在.NET Framework 2.0中,JIT为值类型的托管布局增强了Sequential 布局(如果指定),虽然只有当它们都是非引用类型字段成员时。因此,类型的大小在下一个版本Framework中可能会更加重要。在所有的版本中,对于一个显式布局(你作为一个开发者指定每个字段偏移量和每个字段的地方)的请求都被JIT 和封送拆分器共同响应。 我做此区别是因为一个类型的已封送布局是和该类型的栈或GC堆布局明显地不同。一个已封送类型的布局必须和它的非托管副本一致。然而托管布局只由JIT编译的托管代码使用。因此JIT可以在没有外部依赖下在现有平台上优化托管布局。 请看以下的C#结构(为了简单,我已经避免为这些成员指定任何访问修饰符): struct BadValueType
{
char c1;
int i;
char c2;
}
对于在非托管C++缺省打包,整数被布局在四个字节边界上,因此当第一个字节使用两个字节(在托管代码里的字符是一个Unicode字符,因此占据两个字节),整数被提到下一个4字节边界,并且第二个字符使用了随后2字节。当用Marshal.SizeOf度量的结构大小结果是12个字节(在我的32位机上用.NET
Framework 2.0的sizeof度量的结果也是12个字节)。如果我按我的喜好像下面一样改造这些对齐操作,结果将是一个8字节结构: struct GoodValueType
{
int i;
char c1;
char c2;
}
另一个值得注意的一点是越小的类型使用越少的内存。这可能看起来很明显,但是一些项目即使当它们不必要时仍使用标准整数或十进制数值。在我的GoodValueType例子中,假定整数值不会大于32767或小于-32768,我可能会使用短整数更多地砍掉这个类型的大小,如下所示:
struct GoodValueType2
{
short i;
char c1;
char c2;
}
适当地对齐和确定类型的大小将其从12字节减小到6字节。(Marshal.SizeOf将报告GoodValueType2有4字节,但是这是由于缺省封送一个字符为一个字节值。)如果你注意一点就可以使你的结构和类减少那么多的大小,你将会为此感到惊讶。正如前面提到的,了解结构的托管布局可以和非托管布局有很大不同是非常重要的,特别在.NET Framework 1.x上。已封送布局可能与内部布局不同,因此它是可能的(并且,实际上,大概):我已提到的类型在使用sizeof操作符时将报告不同的结果。正如一个适用的情况,所有我已展示的三个结构迄今为止在.NET Framework 1.x上有一个8字节的托管大小。你可以通过JIT使用非安全代码和指针计算检查其中一个类型的布局: unsafe
{
BadValueType t = new BadValueType();
Console.WriteLine("Size of t: {0}", sizeof(BadValueType));
Console.WriteLine("Offset of i: {0}", (byte*)&t.i - (byte*)&t);
Console.WriteLine("Offset of c1: {0}", (byte*)&t.c1 - (byte*)&t);
Console.WriteLine("Offset of c2: {0}", (byte*)&t.c2 - (byte*)&t);
}
在.NET Framework 1.x上,运行这个代码结果输出如下: Size of BadValueType: 8
Offset of i: 0
Offset of c1: 4
Offset of c2: 6
然而在.NET Framework 2.0上,相同的代码将有以下结果输出:Size of BadValueType: 12
Offset of i: 4
Offset of c1: 0
Offset of c2: 8
乍一看好像是退步了,因为新版的Framework增加了类型的大小,它实际上是被预期的行为且是一个好事情:JIT现在响应指定布局。如果你更愿意让JIT自动确定最好的布局(产生如用1.x
JIT当前生成的相同结果),你可以用StructLayoutAttribute来明确标记你的结构,确定LayoutKind.Auto。只要紧记由于.NET
Framework 1.x上运行的纯托管应用程序不会做任何与非托管代码的互操作,你努力通过手工排序字段来得到更好的对齐以获得节约内存可能会难以捉摸。图 2图解了一些附加考虑。Address类代表了一个美国地址。这个类型有36个字节长:每个成员4字节,另外8个字节是给它的引用类型系统开销的(注意C#中的sizeof操作符只能用于值类型,因此我又要依靠Marshal.SizeOf报告的数值了)。一个管理医生工资及医院的大型医疗应用软件可能需要同时处理成千的地址。在这个例子中,最小化这个类的大小可能就重要了。类型内部排序过了,但是要考虑AddressType(看图 2)。 当枚举被默认存储为整数时,你可以指定使用整数基类型。图 3定义AddressType枚举为short类型。同样通过改变IsPayTo字段到byte类型,我已将每个Address实例的非托管大小减少了超过10%,从36个字节到32个字节,并减少了托管大小至少2个字节。 最后,string类型是一个引用类型,因此每个字符串实例引用了一个附加内存块来装入实际的字符串数据。在Address类型中,如果我忽略各种美国行政区划的不同,因此state字段将有50个可能的值。也许在这里枚举类型值得考虑既然它可以去除一个引用类型的需要并直接在类中存储数值。因为枚举类型可以是一个字节而胜于缺省的int,因而字段需要1个字节而不是4个。虽然这是一个可行的选择,它使得数据显示和存储复杂化因为整数值在每次访问或存储时将不得不转换成用户或存储机制能理解的某个东西。这种情况揭示了计算中的更加一般的交易之一:对内存提速。它常可能以一些CPU周期为代价优化内存使用,并且反之亦然。 这里有一个可行选择是使用内部字符串。CLR保持一个称为拘留池(intern pool)的表,它包含一个程序的字母字符串。这确保在你的代码中重复使用相同内容的字符串将利用相同的字符串引用。System.String类提供一个Intern方法确保一个字符串是在拘留池并返回对它的引用。如图 3所示。 在我结束讨论类型大小之前,我也想谈谈基类。一个继承类的大小是基类大小加上由继承实例定义的附加成员的大小(及任何为对齐而需要的额外空间,正如之前讨论的)。作为一个结果,任何在继承类型中不再使用的基字段对内存的浪费很大。一个基类因为定义公共功能性而强大,但是你必须确保每个数据元素定义得确有必要。 下面,我将讨论一些为了获得有效内存管理的设计及实现上的技术。一个程序集需要的内存很大程度上依赖程序集做什么,但是由一个程序集实际使用的内存是受到一个应用程序如何实现它的各种任务的影响。这是一个重要的特点在设计和实现一个应用软件时需要紧记。我将分析单态(singleton),内存池机制(memory pooling),和数据流(data streaming)的思想。 单态(Singletons) 一个应用程序的工作区是在RAM中当前可用的一组内存页。初始工作区是应用程序在启动时消耗的内存页。在应用程序启动时越多的任务在执行和分配内存,一个应用程序准备(时间)就越长并且初始工作区就越大。这对于桌面应用程序是特别重要的,因为一个用户经常注视着闪屏(the splash screen)以等待应用程序就绪。 单态模式可以尽可能地延迟一个对象的初始化。下面的代码展示了在C#中实现这种模式的方法。一个static字段装有由GetInstance 方法返回的单态实例。这个static构造器(由C#编译器为执行所有static字段初始化而暗中生成)。被确保在第一次访问类的一个成员和初始化static实例之前执行,如下面代码所示: public class Singleton
{
private static Singleton _instance = new Singleton();
public static Singleton GetInstance()
{
return _instance;
}
}
单态模式确保一个应用程序通常使用仅仅单个类的实例,但是仍然允许在需要时创建替代实例。这节省了内存因为应用程序可以使用一个共享实例,而不是不同的组件分配他们自己的私有实例。static构造器的使用确保了直到应用程序的某些部分需要它时才分配给共享实例内存。在支持许多不同功能性类型的大型应用软件中这可能就很重要了,因为对象的内存只在类实际使用的情况下才分配。 这个模式和类似技术有时称为懒惰初始化,因为初始化要直到实际需要时才进行。懒惰初始化在很多情况下是相当有用的,作为对象的第一次请求部分初始化时可以触发。在用static方法就足够的情况下不应该使用(单态)。换句话说,如果你创建一个单态以访问单态类的一组实例成员,应考虑是否通过static成员可以更好地实现相同的功能性,因为它不需要你例示单态。 池机制 当一个应用程序启动并运行时,内存使用就受到系统需要的对象数量和大小的影响。对象池机制减少了由一个应用程序所需要分配的内存数量,同时也减少了垃圾收集的数量。池机制是相当简单的:重用一个对象而不是让它被垃圾收集器回收。对象被存储于一些列表或数组的类型称为池,并应客户的要求分发。当一个对象的实例是重复使用时这是特别有用的,或者如果对象的构建有一个消耗甚多的初始化,那么重用一个已经存在的实例将比扔掉一个已有实例而白手起家创建一个全新的实例更好。 让我们看一个对象池机制会有所作为的场景。假定你在为一个大型保险公司写针对客户档案信息的一个系统。医生在白天收集信息并在每天晚上将其传到一个中心站。这个 代码可能包含一个循环,做某事如下: while (IsRecordAvailable())
{
PatientRecord record = GetNextRecord();
... // process record
}
在这个循环中,每次这个循环执行时返回一个新的PatientRecord对象。非常明显:GetNextRecord方法的执行将在它每次被调用时将创建一个新对象,并要求对象被配置,初始化,甚至垃圾收集,和析构如果这个对象有一个完成器(finalizer)。当使用一个对象池,配置,初始化,收集和析构只发生一次,既减少了内存使用又减少所需的运行时间。 在某些情况下,代码会被重写以在类型上使用一个Clear方法如下: PatientRecord record = new PatientRecord();
while (IsRecordAvailable())
{
record.Clear();
FillNextRecord(record);
... // process record
}
在这段程序中,单个PatientRecord对象被创建并且一个Clear方法使内容复位以使其可以在循环内重复使用。FillNextRecord方法使用了一个现有对象,避免重复配置新的对象。当然,你仍要在每次这个代码段执行时为单个分配、初始化、收集而消耗资源(尽管这仍比每次循环的消耗要好得多)。如果初始化消耗甚多,或同时有多个线程调用代码,重复创建的效果可能仍是个问题。对象池机制的基本模式看起来就像这样: while (IsRecordAvailable())
{
PatientRecord record = Pool.GetObject();
record.Clear();
FillNextRecord(record);
... // process record
Pool.ReleaseObject(record);
}
一个PatientRecord实例,或实例池,在应用程序的开始被创建。代码从池中重新得到一个实例,避免了内存分配,构建,和最后的垃圾收集。这个过程是节省了大量的时间和内存,虽然它需要程序员明确地管理池中的对象。.NET Framework为COM+程序集最为它企业服务(Enterprise Services)支持的一部分提供对象池机制。该功能性的访问由System.EnterpriseServices.ObjectPoolingAttribute类提供。关于这个特性Rocky Lhotka有一篇很好的文章:Everyone Into the Pool。COM +自动提供池机制支持,因此你不必明确地记住重新得到和返回对象。另一方面,你的程序集必须在COM+内部运行。 为了池机制化任何.NET对象,我想为本文写一个一般用途的对象池将是有趣的。我为这个类写的接口如图 4所示。ObjectPool类为任何.NET类型提供了池机制。 在一个类型可以被装入池中之前,它必须首先被注册。当需要一个对象的新实例时注册标识一个创建委托以供调用。 这个委托只返回最近实例化的对象并丢掉构建逻辑上直到客户应用该委托。像Enterprise Services 的ObjectPooling属性,它也接受了最少的对象数以在池中保持活动,允许的最大的对象数,及为等到一个可用对象所用的多长的一个超时值。如果超时值为零,这时一个调用者将一直等待直到一个空闲对象可用。一个非零超时值在实时下或当一个对象不易成为可用的可能需要一个替代动作的地方是有用的。在注册调用返回,在池中需要的最少数量的对象是可用的。一个给定类型的池机制可以用UnregisterType方法予以终止。 在注册后,GetObject和ReleaseObject方法从池中重新得到和返回对象。ExecuteFromPool方法接受一个委托和附加到目的类型参数。执行方法用池中的一个对象调用给定的委托,并确保重新得到的对象在委托完成后返回到池中。这增加了委托调用的系统开销,但是将你从不得不手工管理池的工作中解放出来。 在内部,类保持了一个存放所有已入池对象的哈希表。它定义了一个ObjectData类用以存放每个类型相关的内部数据。这个类没有在这里显示,但是为这个类型保留了这个注册信息和记录用信息并保持一个已入池对象的队列。 ReleaseObject方法内部使用一个私有ReturnToPool方法来将给定对象再存储到池中,如图 5所示。这个Monitor类锁定了操作。如果少于最小可用对象数量,这时对对象的引用将被放在队列中。如果最少数量的对象已经被分配,这时一个对对象的弱引用入队。如果需要,一个等待线程被通知获取新的入队对象。 这里使用一个弱引用要尽可能地保持高于最小数量对象,而且要使它们可供GC使用。ObjectData 的inUse字段跟踪给定应用程序的对象,同时inPool字段跟踪在池中有多少实际引用。inPool字段忽略了任何弱引用。 在创建一个池时需要做的最重要的一件事就是适当的对象生存时间策略。弱引用构成了这个策略的基础之一,但是这里有其它一些,以及基于环境使用的策略。 对GetObject方法来说,内部RetrieveFromPool方法如图 6所示。 Monitor.TryEnter方法用来确保应用程序不会为锁定而等待太长时间。如果在超时期间锁定不能获得,将返回给调用者null。 如果锁定被载入,DequeueFromPool方法被调用以从池中重新得到一个对象。注意该方法是如何用do-while循环解决可能的弱引用。 回到RetrieveFromPool代码,如果在队列中没有找到一个入口, 只要小于最大可用对象数,就通过AllocateObject方法分配一个新对象,。一旦达到最大值,WaitForObject方法等待一个对象直到创建超时已到达。注意在调用WaitForObject以计算在获得锁上花费的时间之前等待的时间如何被调整。WaitForObject代码没有在这里列出,但是可以从本文代码下载中得到它。 当检索超时发生时,这里有两个选项应发生:返回null或抛出一个异常。返回null的缺点是它迫使一个调用者每次都要对从池中获得的对象检查null。抛出一个异常避免了检查,但是使得超时值更大。如果超时是非预期的,这时抛出一个异常可能是个更好的选择。我决定返回null,因为当超期是非预期的,这个检查可以被跳过。当超期是预期的,检查null的代价比捕捉一个异常的代价要低。 图 7显示的是ExecuteFromPool方法的代码,它去掉了错误检查和注释。这个代码使用私有方法从池中重新获得对象并调用已提供的委托。最后的代码块确保对象返回到池中即时一个异常发生。 对象池机制帮助水平化堆上对象的数量分配,既然在应用程序中大多数普通对象可以被装入池中。这可以在基于.net的应用程序的托管堆大小中消除不良模式,并减少了应用程序用于执行垃圾收集的时间。我后面将用ObjectPool类看一个简单的程序。 注意托管堆在分配新对象上是非常高效的,并且垃圾收集器在收集大量小且短命的对象上也是非常高效的。如果你的对象没有高频率使用或没有极大的建构或析构消耗,这时对象池机制可能就不是适当的策略了。当用到任何性能决策时,分析一个应用程序的最好办法是在代码的真正瓶颈处得到一个句柄。 数据流 当管理大块数据时,有时一个应用程序只需要大量内存。对象池机制只帮助减少类配置所需的内存和对象建构和析构所需的时间。它并未真的致力于解决这样的事实:一些程序必须处理大量数据以完成他们的工作的。 当不断需要大量数据时,你所做的最多的就是尽可能的管理好内存,或可能压缩或其它措施使其尽可能地紧凑。(此外,内存和速度之间的典型交易,正如压缩减少了内存消耗但同时压缩需要cpu周期。)当临时需要数据时,你也许可以利用数据流减少大量内存。通过在一段时间上只有部分数据起作用的方法以获得数据流,而不是一下使用全部或大部分数据。比较System.Data 命名空间中的DataSet及DataReader类。当你可能将一个查询的结果装入一个DataSet对象时,一个巨大的查询结果将消耗大量的内存。一个DataSet也需要两次访问内存:一次填写快表,还有一次是稍后的读快表。DataReader类可以增量装入相同查询的结果并一次给一行结果给应用程序。在并不实际需要全部结果时这是理想的,因为它更有效地使用了可用内存。 String类提供了无意中造成许多消耗大量内存的机会。最简单的例子是连接字符串。连接四个字符串增量(一次增加一个字符串到新的字符串)内部将产生七个字符串对象,因为每次增加将产生一个新的字符串。在System.Text中的StringBuilder类连接字符串到一起而没有每次分配一个新的字符串实例;这有效地提高了内存利用率。C#编译器也支持这一点因为它将在相同代码语句里的一系列字符串连接转换到调用String.Concat。 String.Replace方法提供了另一个例子。考虑一个从外部资源接受许多输入文件并对其进行读和处理的系统。这些文件可能需要预处理以使其适当格式化。从讨论目的出发,假定我有一个系统,它不得不一看到单词“nation” 就替换为“country”,并且一看到单词“liberty”就替换为“freedom”。 用下面的代码片段可以很容易地做到它: using(StreamReader sr = new StreamReader(inPath))
{
string contents = sr.ReadToEnd();
string result = contents.Replace("nation", "country");
result = result.Replace("liberty", "freedom");
using(StreamWriter sw = new StreamWriter(outPath))
{
sw.Write(result)
}
}
它效果很好,创建了三个字符串的代价就是文件的长度。Gettysburg
Address大概是2400个字节的Unicode文本。U.S.宪法超过50,000个字节的Unicode文本。你知道后果将会如何。现在假定每个文件大概是1MB的字符串数据并且我不得不并行处理10个文件。在我们的简单例子里,读和处理这10个文件将消耗大约10MB的字符串数据。这需要相当巨大的内存以供垃圾收集器不断分配和清扫。流机制化该文件将允许我们每次看到一小部分数据。无论何时我找到一个N或一个L,我寻找这些单词并按需要替换它们。例子的代码如图 8 所示。我在这个代码中用FileStream类以在字节层面上展示数据操作。你可以根据自己的需要用StreamReader 和StreamWriter类修改这些。 在这个代码中,ProcessFile方法一次接收两个流并读一个字节,寻找N 或L。当找到一个,CheckForWordAndWrite方法将检查是否流的随后字符与目标单词是否相符。如果找到一个相符的,替代单词被写入到输出流。否则,原字符被放入输出流中,并且输入流被重新设置为原位置。这个方法依赖于FileStream类适当地缓冲输入和输出文件,所以这个代码可以一个字节一个字节地执行必需处理。每个FileStream使用一个8KB缓冲区,因此这个实现使用了比前面读和处理整个文件的代码更少的内存。尽管如此,这个进程为输入流中的大部分字符做了一个函数调用到FileStream.ReadByte及一个函数调用到FileStream.WriteByte。你可能会发现一个更恰当的方法:通过一次读一系列字节到一个缓冲区找到,如此省掉方法调用。另外,分析器是你的朋友。 在.NET中流机制的类被构造以允许多个流在一个共同的基流上同时工作。来源于Stream的一些类包括一个构造器获得一个已有的Stream对象,允许一串Stream对象操作输入数据并产生一个对流修改或变换的继承。举个例子,看一下.NET Framework关于CryptoStream类的文档,它说明了如何加密来自一个引入的FileStream对象的字节数组。 现在我已分析了一些关于内存利用率的设计和实现问题,关于测试和调整一个应用程序的主要论述是有序。几乎任何应用程序一定都有各种性能和内存问题。发现它们的最好办法是明确地度量这些项目并在问题暴露的同时追踪到它。Windows®执行计数器和.NET CLR分析器(CLR Profiler)或其它分析器是达到最终目的的两个杀手锏。 性能监视 Windows性能监视器并不会解决性能问题,但是它可以帮助你确定应从哪里找到它们。 这是一个详尽的关于内存利用率和其它性能指标的性能计数列表在Chapter 15 ― Measuring .NET Application Performance。 性能调整观念上是一个重复的任务。一旦一系列性能指标被确定且一个测试环境在这些指标可以应用的地方创建,应用程序将在测试环境下运行。使用性能监视器收集性能信息。基于这些建议修改应用程序或配置,并再次开始这个过程。 测试、收集、分析和修改一个系统应用的过程同样对所有性能包括内存使用率都有好处。系统的修改应该包括重写一部分代码,在系统内部改变应用程序的配置或分配,或其它改变。 CLR分析器(Profiler) CLR 分析器工具对于内存利用率分析极为有用。它分析了一个应用程序在它运行时的行为并提供类型分配的详细报告,它们被分配了多长字节,每次垃圾收集的细节,及附加内存相关信息。你可以从Tools & Utilities 处下载该免费工具。 这个分析工具是完全侵入式的,因此不适于一般性能分析。然而对于分析托管堆,它给人以深刻印象。为了看看一个它应用的小例子,我用先前讨论的ObjectPool类写了一个小的PoolingDemo程序。为避免你认为池机制只用于大的或长时间消耗的对象,该demo程序定义了一个MyClass对象如下: class MyClass {
Random r = new Random();
public void DoWork() {
int x = r.Next(0, 100);
}
}
这个程序允许你在非池机制和池机制间选择。非池机制代码如下: public static void BasicNoPooling()
{
for (int i = 0; i < Iterations; i++)
{
MyClass c = new MyClass();
c.DoWork();
}
}
在我的台式机上,完成一百万次迭代用了12秒。池机制代码避免了在循环内部分配MyClass对象:
public static void BasicPooling()
{
// Register the MyClass type
Pool.RegisterType(typeof(MyClass), ...);
for (int i = 0; i < Iterations; i++)
{
MyClass c = (MyClass)Pool.GetObject(typeof(MyClass));
c.DoWork();
Pool.ReleaseObject(c);
}
Pool.UnregisterType(typeof(MyClass));
}
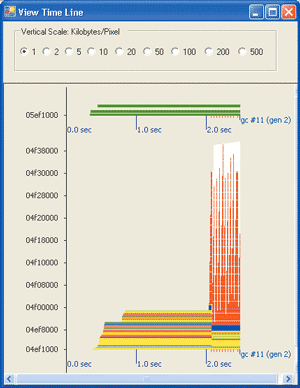
这个代码,我用了一个静态Pool属性以避免ObjectPool.GetInstance。在一百万次迭代,池机制测试大概花了1.2秒完成,比非池机制大约快了10倍。当然,我的例子是人为着重于考虑获得和释放对象的实例的耗费。MyClass.DoWork是几乎一定由JIT编译器内联,并且预迭代节省的时间(百万次上10秒)是相当少的。尽管如此这个例子说明了对象池机制如何能去除一个确定数量的系统开销。在系统开销非常重要的场合下或创建或完成一个对象需要很长时间时,对象池机制被证明是有益的。
|