| ժҪ���˽����ͨ����
ASP.NET 2.0 ��ʹ�õ����Ƶļ�����ʹ�� ASP.NET 1.1
�е����ݿ����Ч�����ơ�
����ȽϿ��ﻯ������������������Ȥ���Բ��ԣ�ASP.NET
�����ǵ�ĿǰΪֹ����ϲ���� ASP.NET
����֮һ��Ϊʲô�أ�������Ϊ��ͨ��ʹ�û��棬���Ի��һЩ��������ܺͿ������Խ��������Щ����������ɵؽ��к�����ת��ΪӦ�ó���ʵ�ʽ�ʡ���ʽ����ʹ����Ϊ
CTO
��ϲ���Ĵ�����ӣ���Ϊ��Ӱ����������Ҫ��Ӧ�ó���Ͷ�ʻر���
(ROI)�����仰˵������ȷʵ��ʡ���ʽ�
�ӽϸ�����˵���� ASP.NET 1.1
�У���������Ϊ֧���������ʹ�� (LRU)
�㷨����Ĺ�ϣ��ʵ�ֵģ��Ա�ȷ�������Ҫ�ڴ棬���Դӻ�����ɾ���һ�������ڻ����в�����Ƴ���ı�̽ӿڣ���������ʵ�������֧��ʱ�䡢�ļ��ؼ�������ȸ��
������ģ���ǻ����Ϊ��Ҫ�Ĺ���֮һ����Ϊ�������������³�����
| • |
��ʱ�˿̣������еĸ��������Ч������ʱ����������
|
| • |
����û�����Ŀ���ģ�������һ��������ĿҲ��Ч�����ڼ����������
|
| • |
������ļ����ģ����еĸ������Ч�������ļ����������
|
���û�����ʱ��Ӧ��ʼ����ʹ����֮ǰ�������Ƿ���ڡ���ˣ���ʹ�û���ʱ����ѭ�����ģʽ��һ���ܺõķ�����
' #1 �C Get a reference to the object
Dim myCachedArrayList As ArrayList = Cache("MyArrayList")
' #2 �C Check if the reference is null
If (myCachedArrayList) Is Nothing Then
' Add items to array list
myCachedArrayList = PopulateMyArrayList()
' Cache
Cache.Insert("MyArrayList", myCachedArrayList)
End If
' #3 �C Return the data
Return myCachedArrayList
�������������Dz��ǣ����Ǿ���һ�������ڿ���ijЩ��������Ч�����ڴ��д洢���ݵ����ģ�͡���ģ�ʹ���
ASP.NET
������Ա����Ҫ�����ļ���ȱ�㡣һ��ȱ�������ݿ����Ч��������ζ�ŵ����ݿ��е�ij���ݸ���ʱ���ӻ������Ƴ�����ڶ���ȱ�����ܹ������Լ��Ļ��������
����Ϣ�ǣ��� ASP.NET 2.0����ǰ�Ĵ���Ϊ��Whidbey�����У�������ȱ�ݶ����ˡ��������������ݿ��������ģ��
�� һ������ Microsoft SQL Server 7 �� 2000����һ������
SQL Server 2005����ǰ�Ĵ���Ϊ��Yukon�������ڶ���ϴ�ĸ�����
CacheDependency
��û���ܷ⣬���ұ����¹ܵ������Ա�������Ϊ�����д�Լ������������
����Ϣ�� ASP.NET 2.0
����������������;�����ǣ�Ŀǰ���ǿ���ͨ��
ASP.NET 1.1
���������Ƶ����ݿ����Ч��ϵͳ��ʵ���ϣ���
2002 ����Щʱ���һ��� ASP.NET
�Ŷ���ʱ���Ҿ���ʹ�øü�����������
Microsoft SQL Server 7 �� SQL Server 2000
�����ݿ����Ч�����ƽ���ԭ����Ƶġ�
ASP.NET 2.0
���ṩ���������ݿ����Ч��ѡ�Ϊ��ͬ������
SQL Server 2000 �� SQL Server 7.0
��ѡ����Ƶ�һ�ֳ�Ϊ��������֪ͨ���Ĺ����С�ֻ������
SQL ����ִ�еIJ�����֪ͨ�����磬���ϵ�
UPDATE��INSERT �� DELETE ������Ȼ���� SQL Server
2005 �У����ԴӶԶ�̬ SQL���洢���̡���ͼ�ͼ�������Ч���Ľ�����еĸ��Ľ���֪ͨ��
�ź����ǣ���ͨ�� ASP.NET 1.1 ���� SQL Server
2005
��ʹ�õ����ݿ��������ģ�ͣ���Ϊ���ݿ���ֱ���������µĹ��ܣ��Ա�֧������ǰ�汾��
SQL Server �в����õ�֪ͨ��
���ݿ����Ч��������Ҫ�˽������
Ŀǰ���ж�������ʵ�����ݿ����Ч���ļ��������е�һ�ּ��������ڴ�Լ����ǰ�ṩ�ģ���ʹ����չ�洢���̼��������ݿ��е����ݸ���ʱ֪ͨ
ASP.NET����ԭ���� ASP.NET �ŶӶ����ʵ�����ݿ����Ч���ĵ�һ��̽����
�ܶ����Ѿ�ʹ�ù�����һ�ּ����ǣ��� SQL
Server
�����ݿ��е����ݸ��IJ��һ�����Ҫ��Ч��ʱ�Ӵ��ⲿ�ļ����ļ��������
��Щ�����ı��ַdz��ã����Ǵ����������ɫ�����£����ҷdz��ʺ���С��Ӧ�ó����ǣ������Ҫ���ɸ��ӵĴ���Ӧ�ó�����ôǿ�ҽ���������ʹ����Щ�������ٸ�����˵�����Dz���ʹ����Щ�����������Լ���Ӧ�ó������磬��
www.asp.net/forums ���е���̳��������Ҫ���ɵ���Ϊ Community Server ����һ���汾
(www.communityserver.org)��
�������Ǽ�Ҫ����һ��Ϊʲô��Щ���м�������ȱ��
�� ���ȴ���չ�洢����ģ�Ϳ�ʼ��
��չ�洢���� HTTP ��ģ��
��չ�洢������ģ��ʹ��������ϵ�ṹ��
| • |
һ���������������ʹ����������ij�����ݿ�֪ͨ���Զ����ࡣ
|
| • |
һ�����Խ���֪ͨ��ʹ�����е�����Ч��
HttpHandler��
|
| • |
�������Ƿ������ĵ����ݿ��б��ϵĴ�������
|
| • |
���ݿ��е�һ���������ڶԱ������Ƿ������ĵı��Լ������ݸ���ʱҪ��֪ͨ��Ӧ�ó�����и��١�
|
| • |
һ����չ�洢���̣����ڵ���Ӧ�ó����
HttpHandler ��֪ͨ�䷢���ĸ��ġ�
|
��������ʱ������ʹ�ô洢���̻�������Ҫ���ĸ������������һ������֪ͨ�洢���̡��ø���֪ͨ���̼���Ҫ����֪ͨ���ĵ�
Web
Ӧ�ó����б���Ȼ���ÿ��Ӧ�ó������һ����չ�洢���̣��Ա�Ը�
Web Ӧ�ó������ HTTP
���ã���ָʾ���Ƴ��ض��Ļ�����Ŀ���Ӷ����������͵���Ӧ�ó���Web
Ӧ�ó���ֻ�ǽ���һ��������Ҫ�Ƴ��Ļ������
HTTP
�������ڲ�����Ӧ�ó���ֻ���÷��͵Ļ��������
Cache.Remove()��
���������ܺã��������ǵģ�������ʵ�����ܹ��ܺõع�������������һЩ�������棺
| • |
��չ�洢���̶Ի�����Ҫ��Ч���ķ���������
HTTP
�ص����洢������Ϊ�������ݿ��ڲ����ݵġ�ԭ�ӡ�������һ����ִ�С����ڱ�����ʱ�Ӵ������е��á�������Э�鲻ͬ��HTTP
�������������෴���κθ��������ڴ���Ӧ����ˣ���չ�洢��������
HTTP �������֮ǰ��ɡ���� Web
������λ�����������л�����Ҫ���ѽϳ���ʱ�������Ӧ������ӳٻ�������ݿ������ɡ��˷������һ������
SQL Server �����������
UPDATES/DELETE/INSERT�����߸������ǣ������߳���ɡ����ڣ��뽫��һ���س��Է��������з����������������ݿ������������
|
| • |
��� Web ������������ģʽ�����лᴴ�����������ģ������
Web
�������������У���û�а취ָʾ��ν����������������ض��Ľ��̡����仰˵��������ģʽ������ʱ����������ΪӦ�ó������кܶ������
Web
������������չ�洢���̻ص�����������֪ͨ�������Ѿ�����ʱ����û�а취ȷ����������
Web
���������ܻ��֪ͨ�����������ֻ������һ��Ӧ�ó�����������Ӧ�ó���ȴδ��ͬ����
|
��������е���С�ͷ������������벻Ҫ������ģʽ������
Web ������������ SQL Server
��Ӧ����ϵͳ�е�������Դ����չ�洢����
HTTP
��ģ���ܹ��ܺõع����������������Ӧ�ó���ͻȻ���������������ܻ��������ݿ⣬�������뻺�沢������ͬ���������
�ļ�����ģ��
�ڶ��ּ��������ɱ���һ�ּ������������ݸ���ʱ�����ļ�����������ͼʹ��
HTTP �ص���Ӧ�ó���ASP.NET
Ӧ�ó�����Աʹ�ñ��Ļ����ļ������������������ļ����ģ����ļ�����ʱ���������ᱻ�Ƴ���
�ü�������������չ�洢������ģ���йص��������⣬���������ںܶ�����չ�洢���̼����йص���ͬ�������⡣���⣬���������Լ������ԣ�
| • |
��ʹ�øü���ʱ���ļ����ó�Ϊһ�����⣬��Ϊ�������ġ��ļ�û�б�����IJ�������ʱ��SQL
Server
����ֻ���¸��ļ�����ˣ���Ҫ֪ͨ���ĵ����ݿ��е����и��Ķ������Э�����������ļ�������һЩֵ��Ȼ��ȡ���������ļ������仰˵�����ݿ�����л���Ը��ļ����еĹ������������ٵ�������Ȼ��
SQL Server
�Ͽ��ܷ��������л����������⡣
|
| • |
��ʹ�øü���ʱ���ļ�����֪ͨҲ���Ϊһ�����⣬��ΪҪ��
Web
����ʹ�ø����ļ������뽫��ŵ������У����ҽ���ȷ�İ�ȫȨ���������
Web
���������Ա���鿴�ù����������ļ����ġ�
|
�ļ�����ģ���ܹ��ܺõ�����С�ͷ�����������֧�������������ʺ���
SQL Server
����ϵͳ������Դ�������ʵ���ϣ���������һ�ָ��õ�ѡ����Ϊ������չ�洢���̽�������öࡣ���ǣ��ڽϴ�ķ��������������ݿ��Ѿ���ϵͳѡͨ��Դ�Ļ����У���ģ�ͻ������
�����������������������ּ��������������ԣ���������Ҫ�����Ƿ���Ի��ڷ�������С����ʹ����Щ�����������þ��ߡ�ÿ��������֪�������������뵽Ӧ�ó����е�ʱ��������DZ�ڵĿ������Ժ�����ƿ����
���ݿ����Ч����ASP.NET 2.0 ��ʽ
��չ�洢���̻�����Ч��ģ�͵�ԭʼĿ���ǣ���ʼ�����ݿ����Ч���������һЩ���ڵ�ԭ�ͻ�������ASP.NET
�Ŷ�֪�����ù���������ϣ���ڰ汾 2.0
�н����һ�����⣬����������Ҫ���õ��˽�����Կ������ķ�ʽ���ɸù��ܡ�
ʵ���ϣ���Ϊһ�ҹ�˾��Microsoft
֪�����ж�ô��Ҫ�������� ASP.NET��IIS��SQL
Server��ADO.NET �� ISA
���������ŶӵĻ����ϳ�����һ���µ��Ŷӣ���Ϊ
The Caching Taskforce��
ע�ҵ��й� Bill Gates ����IJ�������ר������ʹ���˽������� ASP.NET/Yukon
ʵ������ɵĹ������������� http://weblogs.asp.net/rhoward/archive/2003/04/28/6128.aspx
�Ķ������¡�
�û��湤����ijɼ��������µ����ݿ����Ч����ϵ�ṹ����һ������Ƶ�ϵͳ�У�����ֻ��
ASP.NET��ADO.NET �� SQL Server 2005
��һ���֡����ڳ����ȼ�����������֪ͨ�Ŀ�����ģ�͡����磬���ض��洢���̵��ض��������ʱ����֪ͨ�ҡ�������Ч����
SQL Server 2005 ʵ������ .NET Framework �汾 1.1
�о����ʵ�֡����ǽ����Ժ�����������۸�ϵͳ��ι����������ڶ��ּ�����Ŀ����֧��
SQL Server 7.0 �� SQL Server 2000
�����ݿ����Ч������Ȼ���������ݿ��������κζ�����������DZ����ڵ�������Լ����Χ�ڹ���������Ϣ�ǣ�Ŀǰ����ͨ��
ASP.NET 1.1 ʵ�������� SQL Server 7.0 �� SQL Server
2000 ֧�ֵ���ȫ��ͬ�ļ�����
���ǻ�û�е���
���Ƕ��ڵ����Ͽ�������������к��ӵĻ��������Ѿ����������������������������ǰ��ij�������Ѿõĵط�ʱ���ͣ��ѯ���Ƿ��Ѿ�����Ŀ�ĵء�����ʱ������Ҳ���ڲ�ͣ����ѯ��ֱ���յ��������ӦΪֹ��
���Ƶأ����� SQL Server 7.0 �� SQL Server 2000
�����ݿ����Ч����������ѯ���ݿ⣬�Լ���Ƿ����˸��ġ����������ʶ�ķ�Ӧͨ����������
��
�ѵ���ѯ����һ�����������𣿵��ǣ�һ�����˽��й����ڷ���������ĸ�����Ϣ������Ƶļ��ԺͿ������Ծͻ�����������������ǰ��
�����κ����ݿ����Ч��ϵͳ���ԣ�������˷������ϴ�����⣺
| • |
��ֹ���ݿⷢ�����������ݿ⾡���ܵؿ��ٺ�Ч�Ǽ�Ϊ��Ҫ�ģ���������ݸ����ڼ������ⷢ�����������л����Ӹ�����˵�������ݿ��Ŀ������Ч�ع��������ݵķ��ʲ������������ַ��ʡ�
|
| • |
ȷ������һ���ԣ����һ���������ֻ�ܱ�֤��֪ͨ���͵�������ģʽ�����е�
Web
�������еĵ����������������ý��������û���õġ�����Ӧ�ó������ܹ������ݸ���ʱ�յ�֪ͨ��
|
������ѯģ�͵�ǰ���ǣ���ѯ���ݿ�ijɱ�����������ִ��ԭʼ��ѯ�ijɱ������⣬��ѯ��Ӧ���������߳��Ϸ���������Ӧ����Ϊ��̨����������
���һ�����õķ����� Community Server��Community Server ��һ�����ӵ�Ӧ�ó�����ʹ�úܶ�����ı���������ݽ����һ������������һ�ֳ�����������ͨ���洢���̼�����ҳ�����ݼ����Ա���ʾ�ض���̳�е��̵߳ķ�ҳ��ͼ�������ҳ�߳���ͼ����Ĵ洢����ִ��һϵ�д�
3 �� 5 ���������ӵ�ѡ����䣬����һ����ʱ�����Ӹ���ʱ���н���ѡ��Ȼ��ִ����һ�����ӡ����仰˵�����뷢��������ij�����������ת����ȫ��һ��������
ͨ�� ASP.NET 2.0
��ʹ�õ����ݿ����Ч��ģ�ͣ������Ժ�ʵ�ָ�ģ�ͣ������������ݿ��д�����һ������֪ͨ���������������ݻ�����Ӧ�ó�����������Կ��ٵؼ������ݣ�����Ӧ�ó����ÿ�������Ӿͻ���ѯ���ݿ���ȷ�������Ƿ����˸��ġ���ԭʼ����ͬ����ѯ������������Ȳ��������ݿ��б��������ĵ���������ѯ�����Ӹø���֪ͨ���м������м�¼���ܿ��ܵ�����ǣ��ñ��dz�С�������ڿ��Խ�ȫ�������ҳ��
SQL �е��ڴ��в����ٵؽ��з��ʡ�
�����Ӧ�ó�����ڲ������ø���֪ͨ���Ľ��������������ݿ���ÿ�����ĸ���
ID ������������ ID
ֵ��ͬ�ڵ�ǰ����ĸ��� ID�������Ч����صĻ�����Ŀ������һ������ʹ����ȫ���Ҳ�������Ϊ���ݲ��ڻ����У�������������仺�棬֮��ý��̽�����������ͼ
1 ��ʾ�˸���ϵ�ṹ�Ĺ�����ʽ��
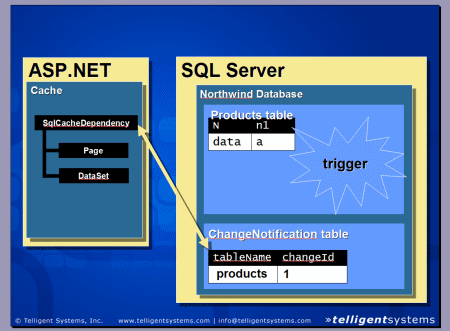
ͼ 1. ��ϵ�ṹ��ϵͼ
����ѯ�������õ�һ����Ϊ��Ҫ�ķ����ǣ���ѯ��������ִ��������̲߳�ͬ�ĺ�̨�߳��С���ˣ�������Դӻ������ṩ��������ڽ�������ʱ��������������ݿ⡣���ǣ�һ�������ģ���Ŀ���ӻ������Ƴ�����һ����������ִ�в�������仺�棬������������ϵͳ����ͼ
2 ��ʾ��
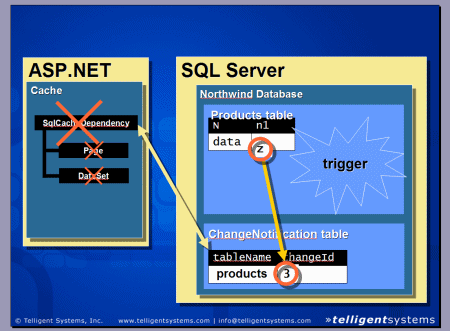
ͼ 2. ���ĺ����ϵ�ṹ��ϵͼ
Ϊ���ں�̨�߳��������ѯ�����ǽ�����
.NET Framework ������ϲ������Ϊ��֪��һ����
�� Timer��Timer ��� System.Threading
�����ռ��С�ͨ�� Timer
������ɵĹ����ǣ�����һ�������Ա�̷�ʽȷ����ʱ���������������¼�����
Timer
������ʱ������ӵ�ǰӦ�ó�������̳߳���ץȡһ���̣߳�������һ���¼������ǵĴ�������ڸ��¼��ڲ��������У�����֤���ݿ��еĸ��Ļ�ȱ�ٸ��ĵ������
��̨������
����ʹ�� Community Server
�е���һ��ͬ����������Ԥ�����õ�ʱ���������������ÿ�����������͵����ʼ����߱����������������Ѿ�Ϊ���ǽ�ʡ���������������������л��ѵĴ���ʱ�䣬��Ϊ����ǰ����������ÿ������������ʱִ�����������ġ�
�� Community Server �У�����ʹ�� Timer
��Ϊ HttpModule �ڲ��ľ�̬ʵ������ ASP.NET
Ӧ�ó����ʼ��ʱ����ʵ������̬��ʱ����ȷ����ѯ�ڲ����ڡ�����ѯ�¼�����ʱ������ִ�����в�����
| • |
ִ�б�Ҫ�� SQL
�Ա�����ݿ��н���һϵ�и��� ID��
|
| • |
�����ݿ��еĸ��� ID �� ASP.NET
�����д洢����Ӧֵ���бȽϡ������в�ƥ���ֵ�����£���Ὣ������ǿ�дӻ������Ƴ���
|
���ҵ� Microsoft Tech Ed 2004 ��ʾ�ĸ壨��λ�� http://www.rob-howard.net����
Blackbelt Slides and Demos �У��������������ݿ����Ч������ȫ��Чʾ����
���ض�ʾ������Ƭ�������� SQL Server �渽��
Northwind
ʾ�����ݿ⡣��ʹ����֮ǰ��������Ҫ�Ը����ݿ����һЩ���ġ�
���ȣ�����Ҫ���� ChangeNotification ����
CREATE TABLE [dbo].[ChangeNotification] (
[Table] [nvarchar] (256) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL ,
[ChangeID] [int] NOT NULL
)
��Σ�����Ҫ�� Products
��������һ����������
CREATE TRIGGER [ChangeNotificationTrigger] ON [dbo].[Products]
FOR INSERT, UPDATE, DELETE
AS
UPDATE
ChangeNotification
SET
ChangeID = ChangeID + 1
WHERE
[Table] = 'Products'
ÿ�� Products
������ʱ������Ӧ�øô��������Ӷ����� ChangeNotification
�����
��������һ����Ϊ��ʾ�����������ϣ��Ϊ�Լ���Ӧ�ó���ʵ���������ܣ����ʾ�������ṩһ�����õ���㡣��ʾ����δ�����һЩȱ�������
| • |
�����ڱ�������ģ�Ϊ��ͼ�����м����������һ�㲢��ʮ�����ѡ�
|
| • |
����������Ҫ���Ӹ��������Թ˼���
Products
�����еĴ����ġ����磬���� 100
�ֲ�Ʒ�ᵼ�¶� ChangeNotification
������ 100 �����ġ��� ASP.NET 2.0
�渽�İ汾���ƣ������ܻ�ϣ������һЩ�����Ա���õش��������¡�
|
��
ASP.NET �Ļ���ϵͳ������ ASP.NET
������Ա��Ӧ��Ŭ��ʹ�õ�һ��ܡ��뾡��ƻ�ʹ�û��棬���˽�Ӧ�ó������Щ������Դ���������ѵ�ʹ�û��档����
ASP.NET 1.1
���ƣ����磬���ݿ����Ч��������ͨ��ʹ��һЩ��
ASP.NET 2.0
��ʹ�õ���ͬ�ļ������Կ˷��������ж� Timer
���ʹ��˵����ʵ�ָ�Ŀ���һ�ֿ��ܷ�ʽ�����ң����ܻ����������ѡ��������Ȼ������ʹ�ø���ѯ����������Ϊ�����ᷢ�֣�Timer
�������������Ľ��Ҳ�����á�
|