Abstract
Belief network is a very powerful tool
for probabilistic reasoning. In this article I will demonstrate
a C# implementation of bucket elimination algorithm for
making inference in belief networks.
Introduction
Belief network, also known as Bayesian
network or graphical model, is a graph in which nodes with
conditional probability table (CPT) represent random variables,
and links or arrows that connect nodes represent influence.
See Fig.1 for example
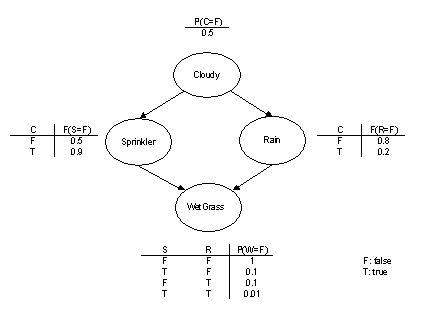
Fig.1 WetGrass belief network. P(X=T)
can be obtained by 1-P(X=F)
Mathematically belief network is equivalent
to the joint probability distribution. It provides us a
natural way to model probabilistic relationships among a
set of variables of interests. Because of its probabilistic
nature, belief network is very useful in encoding uncertain
knowledge. Once we have the network in hand, we can make
inference from it, no matter if it is diagnostic (from effects
to causes), or if it is causal (from causes to effects),
or mixed. We can then make decisions or recommendations
based on the results of inference. That is how the belief
network finds its way in artificial intelligence.
Belief network is a very rich field to
explore both in theory and application. However, I will
not discuss any detail in this article because of limited
space. Instead, I will walk you through a simple example
without providing proofs. Hopefully this article can give
you a feeling of how the belief network works. If you are
interested, you may pick up a textbook like [1], or search
for tutorials in the Internet.
Inference
Conditional probability, written as, say,
P(A|B,C), tells us the probability of the event A
given the event B and C. A joint probability such as P(A,
B) indicates the probability of both event A and B. According
to product rule of probability calculus, a joint probability
can be separated into product of prior probability and conditional
probability,
P(A, B) = P(A|B)P(B), (1)
where P(B) is called prior or unconditional
probability.
The task of inference is to compute conditional
probability P (query | evidence ) for
a set of query variables with some evidence variables given.
Consider the belief network given in Fig.1, if we want to
know the chance of not cloudy when grass is wet, we would
calculate P( cloudy=0 | wetGrass=1 ). By rearranging
eq.(1), we have:
P(c=0 | w=1) = P(c=0, w=1)/P(w=1). (2)
To calculate P(w=1), we must include influence
from W node’s parent, which is represented as arrows in
the belief network. The W node has two parents S and R.
W’s parents are also influenced by their parents. Repeating
this process until reach prior probability, it gives us
P(w=1) = ∑s,rP(s,r)P(w=1|s,r) = ∑c,s,rP(c)P(s|c)P(r|c)P(w=1|s,r). (3)
Calculate P(c=0, w=1) in similar way, we
have
P(c=0 | w=1) = P(c=0)∑s,rP(s|c=0)P(r|c=0)P(w=1|s,r)/P(w=1). (4)
Now all right side probability is explicitly
defined in the CPT of the belief network.
Bucket elimination algorithm
From example above we can see that making
an inference is about calculating joint probability (P(w=1)
can be viewed as a special case of joint). If we
have an algorithm that computes joint probability P(c,s,r,w),
we can make any inference in the belief network.
Let us rewrite (3) as
P(w=1) = ∑cP(c)∑sP(s|c)∑rP(r|c)P(w=1|s,r). (5)
The idea for bucket elimination algorithm
[2], or in general, variable elimination algorithm, is distributing
sums over products. Start from the innermost (the rightmost)
of (5),
P(w=1) = ∑cP(c)∑sP(s|c)∑rP(r|c)λw(s,r) where λw(s,r)=P(w=1|s,r)
= ∑cP(c)∑sP(s|c)λr(c,s) where λr(c,s)=∑rP(r|c)λw(s,r)
= ∑cP(c)λs(c) where λs(c)=∑sP(s|c)λr(c,s)
= λc, (6)
Now the node is replaced by bucket λ, which
contains corresponding node’s CPT and child buckets. Calculating
process works in reverse order. It starts from outmost node,
i.e. root node. If a node is evidence or query, we use the
supplied value, otherwise we sum over all possible values.
The process can then be implemented recursively.
Implementation
The implementation has a static structure
shown in Fig.2. The source code for download is a simplified
version. It only works for binary node, i.e. the node only
takes two values of 0 and 1. I also removed all exception
controls such as try-catches and asserts, and removed all
optimizations though some of them are are obvious and straightforward.
The purpose is to make the code easier to read. It should
not be difficult for you to tweak the code once you understand
it.
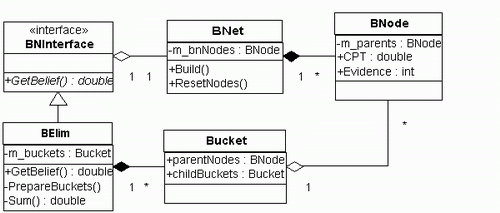
Fig.2 Static structure of belief
network classes
The nodes are defined in XML file. There
are two files, BN_WetGrass.xml and BN_Alarm.xml,
included in the download, both are taken from [1]. They
have completely different topologic structure. You may design
your own nodes. Just keep in mind that the order of nodes
is important, any parent node of a node must be defined
before the node. The method BNet::Build("nodes.xml")
loads nodes from XML file and then creates a belief network
with these nodes.
To make an inference, you may do the following
BNet net = new BNet();
net.Build(“bn_wetGrass.xml”);
BNInference infer = new BElim(net)
double pr = infer.GetBelief(“sprinkler=1; cloudy=0”, “WetGrass=0; Rain=1”);
The bucket is initialized in BElim::PrepareBucket().
After reading example eq. (6) carefully, you will see that
each bucket needs input not only from the parent nodes of
its corresponding node but also from the nodes asked by
its child bucket.
The core of the algorithm is in BElim::Sum(int
id, int para), as explained in the following fragment:
protected double Sum(int node_id, int para)
{
// skipped ...
double pr = 0.0;
foreach(int value in theNode.Range)
{
if( theNode.IsEvidence && theNode.Evidence != value )
continue;
double tmpPr = theNode.CPT;
foreach(Bucket nxtBuck in theBuck.childBuckets)
{
int next_para = 0;
foreach(BNode node in nxtBuck.parentNodes)
{
//calculate next_para;
}
tmpPr *= Sum(nxtBuck.id, next_para);
}
pr += tmpPr;
}
return pr;
}
Here we have taken advantage of binary
node. The integer para is used as
a bit array of size 32. It allows us to play bit operation
on it and so make the code more efficient and compact. The
sum goes through all possible values unless the node has
a supplied value. Then it takes into account the contributions
from its child buckets. To call the child’s contribution,
the sum must provide parameters and let the next bucket
know which node has what value, etc. I will not go any further,
because these things are better explained by code than by
words.
Use Belief Network
The WetGrass network is pretty simple,
however it already shows some subtlety. For instance, we
may calculate the probability of the sprinkler working given
the grass is wet. We have P( sprinkler=1 | wetGrass=1 )
= 0.43. This inference is diagnostic, because it tells us
the cause from the effect. On the other hand, if we know
it is raining or not raining, then P( sprinkler=1 | wetGrass=1;
rain=1 ) = 0.19, or P(sprinkler=1 | wetGrass=1; rain=0 )
= 1.0. You see the extra information of raining changes
the probability of sprinkler=1, although sprinkler and rain
does not directly influence each other. This effect is known
as explaining away. That is the existence of one
makes the other less likely, even though they are independent.
You can play with the code and try different
inference with both WetGrass and Alarm network. You may
or may not have surprise. The reasoning is not always straightforward.
Your common sense may not always be correct.
Coding notes
The reason of using C# is because I want
to learn it. I have used C# as a better C++, but not a better
better C :). As a long time C++ programmer it took me a
while to get used to use new without thinking where to put
delete. The only thing that bothers me is the ArrayList.
It seems to me that there is no way to specify type in declaration;
the type is decided on the fly when you add an item to it.
This can be a nice feature. However it may cause a problem
if we want to separate design from implementation, we must
rely on a comment to remind implementer the item type the
list contains. Maybe I missed something here.
The code is edited with Emacs editor and
complied by csc.exe from C# SDK downloaded from Microsoft
site. The Emacs editor restricts me to write a better UI.
|