Introduction
Some may wonder why one should ever bother
writing a compiler, when there are already dozens of great
compilers out there. The answer is simple, you may never
need to write a compiler, but most likely you will find
yourself in a situation where you could apply many of the
ideas and algorithms that come together to create a compiler.
Besides, it's kind of cool to write programs in your own
language (Job security).
Programming languages are called languages
for a reason, that being, that they are in fact languages.
A programming language is defined by a set of tokens (words
in the English language) and productions (grammar rules).
The main difference between a programming language and a
natural language is that while the natural language can
have multiple interpretations a programming language cannot.
It wouldn't be much fun to have our programs compile differently
ever time we build them. A language that can have multiple
interpretations is called ambiguous, and is not useful to
us.
Warning
Entire books are written on this stuff,
and I cannot explain all of the 5000+ lines of this project
in this article, and frankly I don't want to. It is strongly
recommended that you have some background on grammars and
bottom up parsing techniques as well as a little MSIL knowledge.
What I am especially proud of is the code in Scanner.cs
and Parser.cs this contains the heart of the entire project,
the rest is just the grunt work that needs to be done. Don't
bother looking at the Generator.cs file, that's where I
got sloppy and tired of this school project.
A simple language
A set of tokens and a set of rules define
a language. Some text is said to be grammatical if there
is a way to derive it using the language's tokens and rules.
A language that describes all binary numbers may be described
as follows:
L = {Tokens(0,1),Rules(Any number of 0s
or 1s)}
We can now ask ourselves if the following
text is grammatical "1200011". The answer should
be no, since we see a "2", which is not a token
that is part of our language.
The topic of languages deserves a large
discussion which I am not prepared to make, or know fully
well to explain, so I invite you to strap on your favorite
search engine.
Regular Expressions
Regular Expressions are used to describe
simple languages, generally the tokens themselves, or things
like phone numbers or social security numbers. The regular
expression "A*BC", translates into a more verbose
language definition L {Tokens(A,B,C),Rules(Zero or more
As, followed by a B then a C)}. This is all great, but how
do we write a program that uses a regular expression to
identify whether a stream of characters is grammatical or
not. The general solution to the problem described is to
create a Non Deterministic Finite State Automaton (NFA)
from the given regular expression and then convert this
NFA to a Deterministic Finite State Automaton (DFA). If
you have never heard of these things before, don't worry,
you won't have to deal with them in the rest of the article.
A DFA is simply a state machine, the fact that it's deterministic
means that, from any one state you can only have one other
state to go to based on an input character. Consider the
following regular expression;
R = int|char|ch
This regular expression has the following
DFA
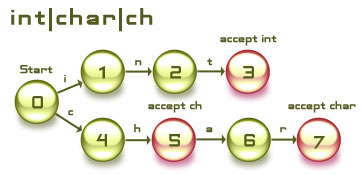
Once we have a DFA we can easily write
an algorithm to that checks whether a string of characters
is grammatical. Consider the following strings;
interop
We start out in state 0 (the start state), we read
the first character which is "i", this takes us
to state 1. We then read the next character "n",
this takes us to state 2, the next character "t"
takes us to state 3, which is an accepting state, however
we have not yet read the entire string. The next character
"e" takes us nowhere, actually it take us to an
error state, which tells us the string is not grammatical.
char
The first character "c" takes us to state 4, the
next takes us to state 5, then "a" takes us to
state 6 and finally "r" takes us to state 7. We
have finished reading the entire string so we check if the
current state (state 7) is an accepting state, and in this
particular case it is, it accepts char. Thus this string
is grammatical.
cin
The first character "c" takes us to state 4. The
next character "i" doesn't take us anywhere, except
to the error state. This string is not grammatical.
Grammars
Grammars, like Regular Expressions, are
used to describe languages. However grammars are much more
powerful then Regular Expressions. I will not go into depth
about Grammars simply because it is too much to cover. Briefly,
a Grammar is a set of Productions (Rules), composed of terminals
and non-terminals. A terminal is a token. A non-terminal
is a grammar element that is composed of terminals and non-terminals.
A typical example of a grammar that defines
a language that describes the set of all enclosed parentheses
is as follows:
1 : S -> (S)
2 : S ->
In this case "(" and ")"
are the tokens of the language and S is the only non-terminal.
Production 1 tells us that S can be a "(" followed
by S and followed by a ")". Production 2 tells
us that S can be null. To better visualize this, lets take
for example the string "((()))". We can replace
the most inner null space with S using production 2, we
now have (((S))). Using production 1 we can replace the
most inner (S) with S to get ((S)), repeating this step
we get (S) and finally S. The difficulty arises in trying
to determine what production to use and when. There is a
lot of theoretical stuff that deals with this, which I don't
fully understand hence I don't want to get into.
The reason I am glancing over all the hard
stuff is that there are compiler tools that create the DFA
and LALR tables. So we don't need to concern ourselves too
much with how this is done. Most compiler tools actually
generate C++/Java/C# code, the tool that is used in this
project generates a file that contains the tables. This
tool is called Gold Parser. Don't feel like you are cheating
either, it is practically impossible to write an bottom
up parser without using a tool such as this.
Sharp Compiler
Honestly, since I don't want to spend days
writing this article I will base the rest of the discussion
on my school project, which I have named Sharp. Sharp is
a very easy language that contains a few essential features;
integer primitives, integer arrays, if for do while statements,
complex expressions, functions, passing values by reference
or value to functions, functions inside functions, a function
for input and one for output and a few other neat things.
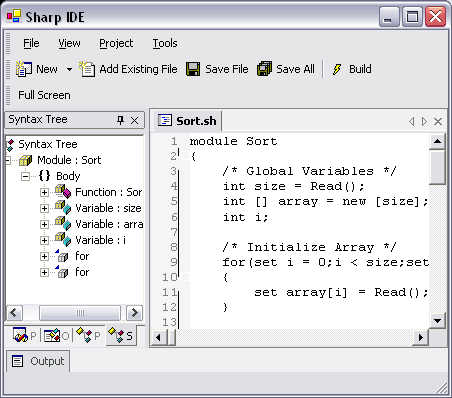
Bellow is a glimpse of what the language looks like.
Bubble Sort implemented in Sharp
module Bubble_Sort
{
/* Global Variables */
int size = Read();
int [] array = new [size];
int i;
/* Initialize Array */
for(set i = 0;i < size;set i = i + 1)
{
set array[i] = Read();
}
Sort();
/* Display sorted array */
for(set i = 0;i < size;set i = i + 1)
{
Write(array[i]);
}
Read();
return;
/* Simple bubble sort routine */
void Sort()
{
int sorting = 1;
int temp;
while(sorting)
{
set sorting = 0;
for(set i = 0; i < (size - 1); set i = i + 1)
{
if(array[i] > array[i+1])
{
set temp = array[i];
set array[i] = array[i+1];
set array[i+1] = temp;
set sorting = 1;
}
}
}
return;
}
}
Originally when I designed the grammar
for the language I took a larger bite then I could chew.
Not everything that appears in the grammar is implemented.
Things such as structs or other primitive types are not
implemented, array passing is also not implemented.
Organization
In the above source code download you will
notice two projects. Magic IDE and Core. Magic IDE is a
simple IDE that provides project management, although the
compiler can only build one file. Magic IDE uses two components
which were not created by me, the IC#Code TextEditor and
the wonderful Magic Library. Core contains the compiler
source code, it provides 5 main classes. Language, Scanner,
Parser, Semantics, Generator.
The language class is a wrapper around
the file produced by the Gold Parser, it reads this file
and makes its content more accessible. The Scanner class
is responsible for tokenizing source code. The Parser class
parses the source file using the Scanner class. The Semantics
class defines the semantic actions to be taken every time
a production is applied. Lastly the Generator class is responsible
for building the actual executable. The generator uses the
.NET namespace System.Reflection.Emit to produce
IL code. Ildasm framework SDK tool can be used to see the
contents of the generated executable.
Dissecting the Sharp Compiler Architecture
Every compiler has at least 3 parts to
it. The scanner, the parser and code generator.
The Scanner
The scanner performs a very remedial job
compared to the other sections, however it is crucial to
the simplicity of the overall design. The scanner's job
is to break up the source code into tokens. The Sharp statement
int [] array = new [size]; will be broken up
by the scanner into "int,[,],identifier,=,new,[,identifier,],;".
The code for the scanner can be written in numerous ways,
however the most elegant way is to base it on a DFA generated
by some tool, in our case the Gold Parser. Using this approach
it makes the code much much slimmer and elegant. The following
C# method is responsible for getting the next token from
the source file.
public Token GetNextToken()
{
State currentState = m_Language.StartState;
State lastAcceptingState = null;
int tokenStart = m_Cursor + 1;
int tokenEnd = tokenStart;
int tokenStartColumn = m_Column;
int tokenStartLine = m_Line;
Token result = null;
//
// Retrieve one character at a time from the source input and walk through the DFA.
// when we enter an accepting state save it as the lastAcceptingState and keep walking.
// If we enter an error state (nextState == null) then return the lastAcceptingState, or
// a null token if the lastAcceptingState is never set.
//
while(true)
{
// Don't advance the cursor.
char nextChar = PeekNextChar();
// Return an EOF token.
if(nextChar == (char)0 && (lastAcceptingState == null))
{
result = new Token(m_Language.Symbols[0]);
result.Column = tokenStartColumn;
result.Line = tokenStartLine;
break;
}
// Get next state from current state on the next character.
State nextState = currentState.Move(nextChar);
// If the next state is not an error state move to the next state.
if(nextState != null)
{
// Save accepting state if its accepting.
if(nextState.IsAccepting)
{
lastAcceptingState = nextState;
tokenEnd = m_Cursor + 2;
}
// Move to the next state.
currentState = nextState;
// Advance cursor.
nextChar = GetNextChar();
}
else
{
// We have entered an error state. Thus either return the lastAcceptingState or
// a null token.
if(lastAcceptingState == null)
{
result = new Token(null);
result.Column = tokenStartColumn;
result.Line = tokenStartLine;
result.Text = new string(m_Buffer,tokenStart,tokenEnd - tokenStart);
}
else
{
result = new Token(lastAcceptingState.Accepts);
result.Column = tokenStartColumn;
result.Line = tokenStartLine;
result.Text = new string(m_Buffer,tokenStart,tokenEnd - tokenStart);
}
break;
}
}
return result;
}
The Parser
The parser is the heart of the entire compiler.
Since this parser uses a pre calculated table generated
by Gold Parser, the only task left to do is write the algorithm
that uses this table. The following C# method uses the parse
table to parse the source file tokens constructed by the
scanner. This is the classic algorithm for a table driven
LR parser.
public Module CreateSyntaxTree()
{
// Are we currently in a comment block.
bool inCommentBlock = false;
// Parser stack.
Stack stack = new Stack();
// Syntax stack.
SyntaxStack syntaxStack = new SyntaxStack();
m_Scanner.Reset();
ParserState currentState = m_Language.ParserStartState;
// m_Language.ParserStartState is our parser start state.
// Push start state.
stack.Push(currentState);
while(true)
{
// Get next token.
Token nextToken = m_Scanner.PeekNextToken();
Symbol nextSymbol = nextToken.Symbol;
// Ignore whitespace.
if(nextSymbol.Type == SymbolType.Whitespace)
{
m_Scanner.GetNextToken();
continue;
}
// Ignore comment blocks
if(nextSymbol.Type == SymbolType.CommentStart)
{
m_Scanner.GetNextToken();
inCommentBlock = true;
continue;
}
// Ignore comment blocks
if(nextSymbol.Type == SymbolType.CommentEnd)
{
m_Scanner.GetNextToken();
inCommentBlock = false;
continue;
}
// Ignore stuff inside comments
if(inCommentBlock)
{
m_Scanner.GetNextToken();
continue;
}
// Print(stack); //Uncomment this to see the parse stack.
// PrintSyntax(syntaxStack.Stack); // Uncomment this to see the syntax stack.
// Lookup action out of current state.
Action action = currentState.Find(nextSymbol);
// Do we have a parser error ? (Entered an invalid state.)
if(action == null)
{
StringBuilder message = new StringBuilder("Token Unexpected, expecting [ ");
for(int x = 0; x < currentState.Actions.Length; x++)
{
if(currentState.Actions[x].Symbol.Type == SymbolType.Terminal)
message.Append(currentState.Actions[x].Symbol.Name + " ");
}
message.Append("]");
if(Error != null)
Error(nextToken,message.ToString());
return null;
}
// Should we shift token and the next state on the stack.
else if(action.Type == ActionType.Shift)
{
Token token = m_Scanner.GetNextToken();
stack.Push(token.Symbol);
syntaxStack.Push(token.Text);
stack.Push(action.ParserState);
}
// Should we reduce ?
else if(action.Type == ActionType.Reduce)
{
// Pop off the stack however many state-symbol pairs as the Production
// has Right Terminals,Nonterminals.
int rightItems = action.Production.Right.Length;
for(int i = 0;i < rightItems;i++)
{
stack.Pop();
stack.Pop();
}
// Find the top of the stack.
ParserState topState = (ParserState)stack.Peek();
// Push left hand side of the production.
stack.Push(action.Production.Left);
// Find next state by looking up the action for the top of the stack
// on the Left hand side symbol of the production.
stack.Push(topState.Find(action.Production.Left).ParserState);
// Apply semantic rule. Applies the semantic rule associated
// with the production used. This ultimately creates the
// syntax tree.
Semantics.Apply(action.Production,syntaxStack);
}
else if(action.Type == ActionType.Accept)
{
Debug.WriteLine("Accept");
return (Module)syntaxStack.Pop();
}
currentState = (ParserState)stack.Peek();
}
return null;
}
The Parse & Syntax Stacks
The parser uses a parse stack to push terminals
and non terminals, once it figures out that it should use
a production it pops the top elements that make up the right
hand side of the production and it pushes the new non-terminal
on the stack. A successfull parse is obtained if at the
end of the parse there is only one non-terminal on the stack
and that being the start non-terminal itself. The syntax
stack is used for semantic operations, which give the real
meaning to the source code. The following list is a print
out of the contents of the parse and syntax stack after
each token.
Source Code
module Test
{
int x;
void Foo(int x, int y)
{
return;
}
return;
}
Syntax and Parse Stacks
Stack : 0
Syntax :
Stack : 0 module 1
Syntax : module
Stack : 0 module 1 identifier 2
Syntax : module Test
Stack : 0 module 1 identifier 2 { 3
Syntax : module Test {
Stack : 0 module 1 identifier 2 { 3 int 96
Syntax : module Test { int
Stack : 0 module 1 identifier 2 { 3 Primitive_Type 109
Syntax : module Test { Core.Type
Stack : 0 module 1 identifier 2 { 3 Type 157
Syntax : module Test { Core.Type
Stack : 0 module 1 identifier 2 { 3 Type 157 identifier 158
Syntax : module Test { Core.Type x
Stack : 0 module 1 identifier 2 { 3 Type 157 identifier 158 ; 117
Syntax : module Test { Core.Type x ;
Stack : 0 module 1 identifier 2 { 3 Variable_Declaration 173
Syntax : module Test { Core.Variable
Stack : 0 module 1 identifier 2 { 3 Statement 152
Syntax : module Test { Core.Variable
Stack : 0 module 1 identifier 2 { 3 Statements 153
Syntax : module Test { Core.StatementCollection
Stack : 0 module 1 identifier 2 { 3 Statements 153 void 107
Syntax : module Test { Core.StatementCollection void
Stack : 0 module 1 identifier 2 { 3 Statements 153 Primitive_Type 109
Syntax : module Test { Core.StatementCollection Core.Type
Stack : 0 module 1 identifier 2 { 3 Statements 153 Type 157
Syntax : module Test { Core.StatementCollection Core.Type
Stack : 0 module 1 identifier 2 { 3 Statements 153 Type 157 identifier 158
Syntax : module Test { Core.StatementCollection Core.Type Foo
Stack : 0 module 1 identifier 2 { 3 Statements 153 Type 157 identifier 158 ...
( 159
Syntax : module Test { Core.StatementCollection Core.Type Foo (
Stack : 0 module 1 identifier 2 { 3 Statements 153 Type 157 identifier 158 ...
( 159 int 96
Syntax : module Test { Core.StatementCollection Core.Type Foo ( int
Stack : 0 module 1 identifier 2 { 3 Statements 153 Type 157 identifier 158 ...
( 159 Primitive_Type 109
Syntax : module Test { Core.StatementCollection Core.Type Foo ( Core.Type
Stack : 0 module 1 identifier 2 { 3 Statements 153 Type 157 identifier 158 ...
( 159 Type 171
Syntax : module Test { Core.StatementCollection Core.Type Foo ( Core.Type
Stack : 0 module 1 identifier 2 { 3 Statements 153 Type 157 identifier 158 ...
( 159 Type 171 identifier 172
Syntax : module Test { Core.StatementCollection Core.Type Foo ( Core.Type x
Stack : 0 module 1 identifier 2 { 3 Statements 153 Type 157 identifier 158 ...
( 159 Parameter 165
Syntax : module Test { Core.StatementCollection Core.Type Foo ( ...
Core.Parameter
Stack : 0 module 1 identifier 2 { 3 Statements 153 Type 157 identifier 158 ...
( 159 Parameters 166
Syntax : module Test { Core.StatementCollection Core.Type Foo ( ...
Core.ParameterCollection
Stack : 0 module 1 identifier 2 { 3 Statements 153 Type 157 identifier 158 ...
( 159 Parameters 166 , 169
Syntax : module Test { Core.StatementCollection Core.Type Foo ( ...
Core.ParameterCollection ,
Stack : 0 module 1 identifier 2 { 3 Statements 153 Type 157 identifier 158 ...
( 159 Parameters 166 , 169 int 96
Syntax : module Test { Core.StatementCollection Core.Type Foo ( ...
Core.ParameterCollection , int
Stack : 0 module 1 identifier 2 { 3 Statements 153 Type 157 identifier 158 ...
( 159 Parameters 166 , 169 Primitive_Type 109
Syntax : module Test { Core.StatementCollection Core.Type Foo ( ...
Core.ParameterCollection , Core.Type
Stack : 0 module 1 identifier 2 { 3 Statements 153 Type 157 identifier 158 ...
( 159 Parameters 166 , 169 Type 171
Syntax : module Test { Core.StatementCollection Core.Type Foo ( ...
Core.ParameterCollection , Core.Type
Stack : 0 module 1 identifier 2 { 3 Statements 153 Type 157 identifier 158 ...
( 159 Parameters 166 , 169 Type 171 identifier 172
Syntax : module Test { Core.StatementCollection Core.Type Foo ( ...
Core.ParameterCollection , Core.Type y
Stack : 0 module 1 identifier 2 { 3 Statements 153 Type 157 identifier 158 ...
( 159 Parameters 166 , 169 Parameter 170
Syntax : module Test { Core.StatementCollection Core.Type Foo ( ...
Core.ParameterCollection , Core.Parameter
Stack : 0 module 1 identifier 2 { 3 Statements 153 Type 157 identifier 158 ...
( 159 Parameters 166
Syntax : module Test { Core.StatementCollection Core.Type Foo ( ...
Core.ParameterCollection
Stack : 0 module 1 identifier 2 { 3 Statements 153 Type 157 identifier 158 ...
( 159 Parameters 166 ) 167
Syntax : module Test { Core.StatementCollection Core.Type Foo ( ...
Core.ParameterCollection )
Stack : 0 module 1 identifier 2 { 3 Statements 153 Type 157 identifier 158 ...
( 159 Parameters 166 ) 167 { 3
Syntax : module Test { Core.StatementCollection Core.Type Foo ( ...
Core.ParameterCollection ) {
Stack : 0 module 1 identifier 2 { 3 Statements 153 Type 157 identifier 158 ...
( 159 Parameters 166 ) 167 { 3 return 98
Syntax : module Test { Core.StatementCollection Core.Type Foo ( ...
Core.ParameterCollection ) { return
Stack : 0 module 1 identifier 2 { 3 Statements 153 Type 157 identifier 158 ...
( 159 Parameters 166 ) 167 { 3 return 98 ; 99
Syntax : module Test { Core.StatementCollection Core.Type Foo ( ...
Core.ParameterCollection ) { return ;
Stack : 0 module 1 identifier 2 { 3 Statements 153 Type 157 identifier 158 ...
( 159 Parameters 166 ) 167 { 3 Statement 152
Syntax : module Test { Core.StatementCollection Core.Type Foo ( ...
Core.ParameterCollection ) { Core.Return
Stack : 0 module 1 identifier 2 { 3 Statements 153 Type 157 identifier 158 ...
( 159 Parameters 166 ) 167 { 3 Statements 153
Syntax : module Test { Core.StatementCollection Core.Type Foo ( ...
Core.ParameterCollection ) { Core.StatementCollection
Stack : 0 module 1 identifier 2 { 3 Statements 153 Type 157 identifier 158 ...
( 159 Parameters 166 ) 167 { 3 Statements 153 } 154
Syntax : module Test { Core.StatementCollection Core.Type Foo ( ...
Core.ParameterCollection ) { Core.StatementCollection }
Stack : 0 module 1 identifier 2 { 3 Statements 153 Type 157 identifier 158 ...
( 159 Parameters 166 ) 167 Body 168
Syntax : module Test { Core.StatementCollection Core.Type Foo ( ...
Core.ParameterCollection ) Core.Body
Stack : 0 module 1 identifier 2 { 3 Statements 153 Function_Declaration 150
Syntax : module Test { Core.StatementCollection Core.Function
Stack : 0 module 1 identifier 2 { 3 Statements 153 Statement 155
Syntax : module Test { Core.StatementCollection Core.Function
Stack : 0 module 1 identifier 2 { 3 Statements 153
Syntax : module Test { Core.StatementCollection
Stack : 0 module 1 identifier 2 { 3 Statements 153 return 98
Syntax : module Test { Core.StatementCollection return
Stack : 0 module 1 identifier 2 { 3 Statements 153 return 98 ; 99
Syntax : module Test { Core.StatementCollection return ;
Stack : 0 module 1 identifier 2 { 3 Statements 153 Statement 155
Syntax : module Test { Core.StatementCollection Core.Return
Stack : 0 module 1 identifier 2 { 3 Statements 153
Syntax : module Test { Core.StatementCollection
Stack : 0 module 1 identifier 2 { 3 Statements 153 } 154
Syntax : module Test { Core.StatementCollection }
Stack : 0 module 1 identifier 2 Body 183
Syntax : module Test Core.Body
Stack : 0 Module 184
Syntax : Core.Module
Accept
Visual Representation of Syntax
and Parse Trees
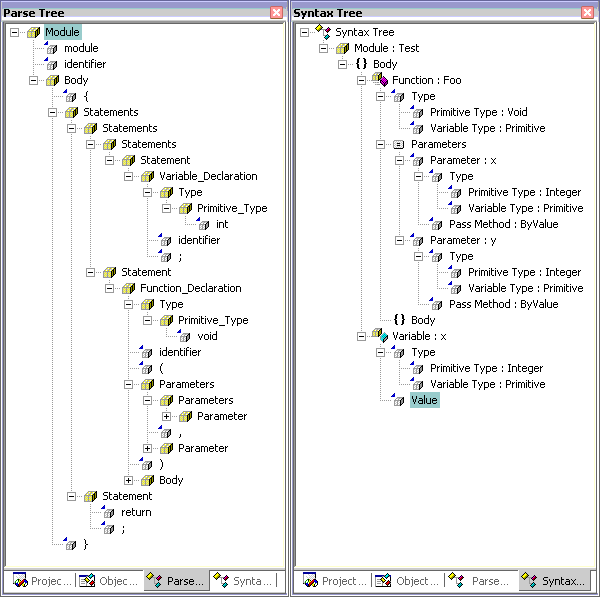
Code Generator
Once we have a syntax tree in place the
code generation is pretty straight forward. Since MSIL is
a stack based instruction set the code generation ties in
pretty easily. All the code for emitting a .NET assembly
from a Module class resides inside of the Generator.cs source
file.
Gold Parser - Grammar Source File
The following text file is the source file
that Gold Parser uses to build the DFA and LALR state tables.
The compiled grammar file this generates is used by the
Language class.
"Name" = Sharp Grammar
"Version" = 1.0
"Author" = Michael Bebenita
"Start Symbol" = <Module>
"Case Sensitive" = True
! Scanner Rules
{LETTER} = {Letter}
{DIGIT} = {Digit}
{ALPHA_NUMERIC} = {DIGIT} + {LETTER}
{HEX_DIGIT} = {DIGIT} + [a-fA-F]
{String Char} = {Printable} - ["]
! Identifiers must start with a letter followed any amount of letters, digits or underscores.
identifier = {LETTER}({ALPHA_NUMERIC} | _)*
! Literals may be either true or false, integers, real numbers, or characters.
boolean_literal = (true)|(false)
integer_literal = ({DIGIT}+) | (0x{HEX_DIGIT}+)
real_literal = {DIGIT}*.{DIGIT}+f
character_literal = ''{LETTER}''
string_literal = '"'{String Char}*'"'
<Literal> ::= boolean_literal
| integer_literal
| real_literal
| character_literal
| string_literal
!! Types
<Type> ::= <Structure_Type>
| <Primitive_Type>
| <Array_Type>
<Structure_Type> ::= identifier
<Primitive_Type> ::= bool
| int
| real
| char
| void
<Array_Type> ::= <Structure_Type> '[' ']'
| <Primitive_Type> '[' ']'
!!
!! Global stuff. Module and body declaration.
!!
<Module> ::= module identifier <Body>
<Body> ::= '{' <Statements> '}'
| '{' '}'
<Name> ::= identifier
| <Name> . identifier
!!
!! Variable stuff.
!!
<Variable_Declarations> ::= <Variable_Declaration>
| <Variable_Declarations> <Variable_Declaration>
<Variable_Declaration> ::= <Type> identifier ;
| <Type> identifier = <Expression> ;
| <Type> identifier = new '[' <Expression> ']' ;
| <Type> identifier = '{' <Elements> '}' ;
<Elements> ::= <Element>
| <Elements> , <Element>
<Element> ::= <Expression>
| '{' <Elements> '}'
!!
!! Function stuff.
!!
<Function_Declaration> ::= <Type> identifier '(' ')' <Body>
| <Type> identifier '(' <Parameters> ')' <Body>
<Parameters> ::= <Parameter>
| <Parameters> , <Parameter>
<Parameter> ::= <Type> identifier
| ref <Type> identifier
<Function_Call> ::= <Name> '(' ')'
| <Name> '(' <Arguments> ')'
<Arguments> ::= <Argument>
| <Arguments> , <Argument>
<Argument> ::= <Expression>
| ref <Expression>
!!
!! Structure stuff.
!!
<Structure_Declaration> ::= struct identifier '{' <Variable_Declarations> '}'
| struct identifier '{' '}'
!!
!! Statements
!!
<Statements> ::= <Statement>
| <Statements> <Statement>
<Statement> ::= <Variable_Declaration>
| <Function_Declaration>
| <Structure_Declaration>
| <Function_Call> ;
| <Assignment> ;
| return <Expression> ;
| return ;
| if '(' <Expression> ')' <Body>
| if '(' <Expression> ')' <Body> else <Body>
| while '(' <Expression> ')' <Body>
| do <Body> while '(' <Expression> ')'
| for '(' <Assignment> ; <Expression> ; <Assignment> ')' <Body>
!
! Expressions
!
<Assignment> ::= set <Name> = <Expression>
| set <Name> '[' <Expression> ']' = <Expression>
| set <Name> ++
| set <Name> --
<Expression> ::= <Expression_Term>
| <Expression> + <Expression_Term>
| <Expression> - <Expression_Term>
<Expression_Term> ::= <Expression_Factor>
| <Expression_Term> * <Expression_Factor>
| <Expression_Term> / <Expression_Factor>
<Expression_Factor> ::= <Expression_Binary>
| <Expression_Factor> % <Expression_Binary>
| <Expression_Factor> '>' <Expression_Binary>
| <Expression_Factor> '<' <Expression_Binary>
| <Expression_Factor> '>=' <Expression_Binary>
| <Expression_Factor> '<=' <Expression_Binary>
| <Expression_Factor> '==' <Expression_Binary>
| <Expression_Factor> '!=' <Expression_Binary>
<Expression_Binary> ::= <Expression_Unary>
| <Expression_Binary> && <Expression_Unary>
| <Expression_Binary> || <Expression_Unary>
<Expression_Unary> ::= + <Expression_Primary>
| - <Expression_Primary>
| ! <Expression_Primary>
| <Expression_Primary>
| <Expression_Primary> '[' <Expression> ']'
<Expression_Primary> ::= <Name>
| <Function_Call>
| <Literal>
| '(' <Expression> ')'
|