|
表映射是控制数据适配器如何将数据表和数据列从一个物理数据源复制到 ADO.NET 内存中对象的过程。数据适配器对象利用 “填充” 方法将 “选择” 命令检索的数据填充到 “数据集” 或 “数据表” 对象。在内部,“填充” 方法使用数据读取器来读取描述源表的结构和内容的数据和元数据。然后,读取的数据被复制到临时的内存容器(即数据表)中。表映射机制是一组规则和参数,通过它们,您可以控制 SQL 结果集如何映射到内存中对象。 下面的代码显示了使用数据适配器从数据源收集数据的典型方式。 SqlDataAdapter da; DataSet ds; da = new SqlDataAdapter(m_selectCommand, m_connectionString); ds = new DataSet(); da.Fill(ds); 必须承认,此代码并没有什么高深复杂的地方,我猜想您已经对它非常熟悉,并且可能不止一次地成功运行过。但是,您是否了解在上述代码的背后究竟发生了什么?信不信由你,在代码中运行着一个小有名气的对象,它的性质和行为对最后的结果有很大的影响。 当您运行上述代码时,对于 “选择” 语句的执行可能生成的每个结果集,都有一个新的 “数据表” 对象添加到数据集(最初是空的)中。如果您将一个非空的数据集传递到 “填充” 方法,只要发现数据表的名称与之相匹配,结果集和现有的 “数据表” 对象的内容就会进行合并。同样,在开始将数据行从结果集复制到一个给定的数据表时,匹配列的内容将进行合并。相反,如果未发现列名相匹配,则会新建一个 DataColumn 对象(使用默认设置),并且会添加到内存中的数据表中。 我们要提出的问题是,适配器如何将结果集的内容映射到数据集构成项中?数据适配器怎样才能知道哪些表和列的名称相匹配呢?数据适配器的 TableMappings 属性正是这个幕后的对象,它决定了结果集中的表如何映射到数据集中的对象。 映射机制 一旦 “选择” 命令终止,且数据适配器返回一个或多个结果集之后,映射机制就开始起作用了。适配器获取对内部数据读取器对象的引用,然后开始处理提取的数据。默认情况下,数据读取器定位在第一个结果集上。下面的伪代码描述了这一过程: int Fill(DataSet ds)
{
// Execute the SELECT command and gets a reader
IDataReader dr = SelectCommand.ExecuteReader();
// Map the first result set to the DataSet and return the table
bool bMoreToRead, bMoreResults;
DataTable dt = MapCurrentResultSet(ds);
// Copy rows from the result set to the specified DataTable
while(true)
{
// Move to the next data row
bMoreToRead = dr.Read();
if (!bMoreToRead)
{
// No more rows in this result set. More result sets?
bMoreResults = dr.NextResult()
if (!bMoreResults)
break;
else
// Map this new result set and continue the loop
dt = MapCurrentResultSet(ds);
}
else
AddRowToDataTable(dt)
}
}
“填充” 方法将第一个结果集映射到给定数据集的 “数据表” 对象。接下来,它对结果集进行从头到尾的循环,并将数据行添加到该数据表。到达结果集的结尾时,该方法就会寻找新的结果集,然后重复该操作。 将结果集映射到数据集的过程包括两个阶段:
在表映射过程中,数据适配器必须为将要包含所处理结果集中的行的数据表找到一个名称。 每个结果集都有一个默认名称,您可以随意更改该名称。结果集的默认名称取决于已用于调用的 “填充” 方法的签名。例如,我们来看下面的两个重载: Fill(ds); Fill(ds, "MyTable"); 在前一种情况下,第一个结果集的名称默认为 表。其他结果集的名称分别为 Table1、Table2 等。在后一种情况下,第一个结果集名称为 MyTable,其他结果集也随之命名为 MyTable1、MyTable2 等。 适配器检查其 TableMappings 集合,看是否存在匹配结果集默认名称的条目。如果发现匹配的条目,适配器则会尝试在数据集中找到具有映射中所指定名称的 DataTable 对象。如果不存在这样的 DataTable 对象,则创建该对象,然后进行填充。如果数据集中存在这样的数据表,其内容则会与结果集的内容进行合并。 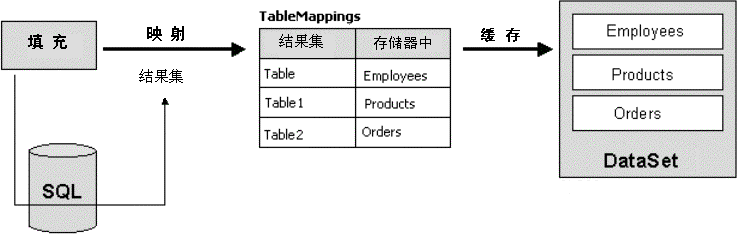 图 1. 将结果集映射到 DataSet 对象 在图 1 中,我假定查询至少会产生三个结果集。TableMappings 集合包含三个默认名称和相应的映射名称。如果 “选择” 命令创建了采用默认名称 表 的结果集,其内容则会合并到一个名称为 “雇员” 的新的或现有的 “数据表” 对象。如何从代码的角度来控制这个过程呢?请看下面的代码片断: SqlDataAdapter da = new SqlDataAdapter(...);
DataSet ds = new DataSet();
DataTableMapping dtm1, dtm2, dtm3;
dtm1 = da.TableMappings.Add("Table", "Employees");
dtm2 = da.TableMappings.Add("Table1", "Products");
dtm3 = da.TableMappings.Add("Table2", "Orders");
da.Fill(ds);
当然,您映射到自己名称上的默认名称必须与调用 “填充” 方法生成的默认名称一致。也就是说,如果您将最后一行更改为 da.Fill(ds, "MyTable");,代码则无法成功运行,因为默认名称现在变成了 MyTable、MyTable1 和 MyTable2,而对于这些名称,前面的 TableMappings 集合中并没有相匹配的条目。 您可以有任意数量的表映射,不一定与预期的结果集数量相关。例如,您可以只映射命令返回的第二个结果集 Table1。这种情况下,目标结果集包含三个表,分别名为 Table、Products 和 Table2。 DataTableMapping 对象描述了结果集与数据集中的 “数据表” 对象之间的映射关系。SourceTable 属性返回默认的结果集名称,而 DataSetTable 则包含映射名称。 如果您使用 Visual Studio® .NET,则可以通过运行 Data Adapter Configuration Wizard,用一种可视的方式配置表映射。 列映射 如果就这样完成表映射,也没有什么特别之处。实际上,如果您的目的是为数据集表起一个好记的名称,则可以使用下面的代码: SqlDataAdapter da = new SqlDataAdapter(...); DataSet ds = new DataSet(); da.Fill(ds); ds.Tables["Table"].TableName = "Employees"; ds.Tables["Table1"].TableName = "Products"; 最后的效果完全一样。不过,这种映射机制的另一方面却十分有趣,这就是列映射。下图扩展了前面的图,包括详细的列映射过程。 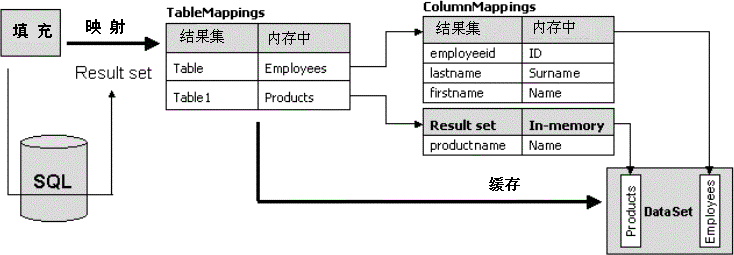 图 2. 表映射和列映射 DataTableMapping 对象有一个名为 ColumnMappings 的属性,它其实就是一个 DataColumnMapping 对象集合。列映射表示结果集中的列的名称与 “数据表” 对象中相应列名称之间的映射。基本上,DataColumnMapping 对象的最终目标是,使您在数据表中使用的列名能够区别于数据源中的列名。 SqlDataAdapter da = new SqlDataAdapter(...);
DataSet ds = new DataSet();
DataTableMapping dtm1;
dtm1 = da.TableMappings.Add("Table", "Employees");
dtm1.ColumnMappings.Add("employeeid", "ID");
dtm1.ColumnMappings.Add("firstname", "Name");
dtm1.ColumnMappings.Add("lastname", "Surname");
da.Fill(ds);
在上面的代码中,我假定提取的结果集包含名为 employeeid、firstname 和 lastname 的列。这些列必须复制到数据集的内存中数据表子集中。默认情况下,目标 DataColumn 的名称与源列相同。不过,利用列映射机制,您可以更改内存中列的名称。例如,将列 employeeid 复制到内存时,它被重命名为 ID,并放在名为 Employees 的数据表中。 该列的名称是您在此级别唯一可以更改的参数。请记住,整个映射是在 “填充” 方法内自动进行的。当 Fill 终止时,源结果集中的每一列已转换到为 DataColumn 对象中时,您可以加入和应用进一步的更改 - 关系、约束、主键、只读、自动递增种子和步长、对空值的支持等。 总之,“填充” 方法会完成两个主要操作。首先,它将源结果集映射到内存中的表。其次,它使用从物理数据源提取的数据来填充表。在完成其中任何一个任务的时候,“填充” 方法都可能产生某些特殊的异常。从概念上来说,异常是需要从代码角度专门进行解决的反常情况。当适配器没有找到表映射或列映射时,并且在目标数据集中没有找到所需的数据表或数据列时,适配器就会引发一种轻量型的异常。 与必须在代码中解决的真正异常不同的是,这种特殊的适配器异常必须通过从为数不多的一组可行选项中选择一个操作,用声明的方式来解决。适配器会引发下面两种轻量型异常:
缺少映射操作 当适配器正收集用来填充数据集的数据时,有两种情况需要缺少映射操作。如果在 TableMappings 中没有找到默认名称,或者,如果表的 ColumnMappings 集合中没有列名,则需要缺少映射操作。您必须自定义适配器的 MissingMappingAction 属性的行为,以便处理这样的异常。该属性的可取值属于 MissingMappingAction 枚举类型,如下表所示。
表 1. MissingMappingAction 枚举 除非您在填充适配器之前明确设置了 MissingMappingAction 属性,否则它会采用默认值 Passthrough。因此,会使用默认名称将表或列添加到数据集中。例如,如果尚未为名称为 Table 的结果集指定表映射,目标数据表则会采用与之相同的名称。实际上,下面的语句最后会将新的数据表分别添加到名称为 Table 和 MyTable 的数据集。 da.Fill(ds); da.Fill(ds, "MyTable"); 如果将 MissingMappingAction 属性设置为 Ignore,则只是忽略任何未映射的表或列。此时,不会检测任何错误,但目标数据集中也不会存在有关所涉及结果集的任何内容(或它的一列)。 如果 MissingMappingAction 属性设置为 Error,那么,适配器就会限制为每次检测到缺少映射时都引发 SystemException 异常。 一旦适配器完成映射阶段,就开始用所选结果集的内容填充目标数据集。如果目标数据集中不存在任何必需的 “数据表” 或 DataColumn 对象,就会触发另外一个轻量型的异常,此时需要另一个声明的操作:缺少架构操作。 缺少架构操作 如果数据集不包含其名称已经在表映射步骤中确定的表,则需要缺少架构操作。同样,如果数据集表不包含具有预期映射名称的列,也需要同样的操作。MissingSchemaAction 是为了在缺少表架构的情况下指示您希望执行操作而设置的属性。该属性的可取值属于 MissingSchemaAction 枚举类型,如下表所示。
表 2. MissingSchemaAction 枚举 默认情况下,MissingSchemaAction 属性设置为 Add。因此,会通过添加任何缺少的构成项 - “数据表” 或 DataColumn 形成完整的数据集。不过,要记住,用这种方式添加的架构信息非常有限。其中只包括名称和类型。如果您需要额外的信息 - 如主键、自动递增、只读和空设置 - 请使用 AddWithKey 选项。注意,即使使用 AddWithKey 选项,也并非关于列的所有可用信息都加载到 DataColumn 中。例如,AddWithKey 将某个列标记为自动递增,但不设置相关的种子和步长属性。而且,源列的默认值(如果有的话)也不会自动复制。主键会被导入,但并非您可能已经设置的任何额外索引都会导入。 另外两个选项,Ignore 和 Error,其运行方式与处理 MissingMappingAction 属性的方式完全一样。 对代码的影响 虽然我反复提到(轻量型)异常方面的操作,但您在缺少对象的情况下声明要执行的操作不像真正的异常那么难以处理。另一方面,这并不意味着,您的代码完全不受此类操作的影响。更具体地说,填充一个已包含所有所需架构信息的数据集是一种代码优化形式。当代码的构成方式是使用固定的架构重复填充空数据集的时候,尤其是这样。这种情况下,使用预加载了架构信息的全局 “数据集” 对象有助于阻止所有那些对恢复操作的请求。 如何使用属于一组结果集的架构信息填充数据集呢?您猜怎样,原来,数据适配器对象有一个自定义的方法 - FillSchema。 DataTable[] FillSchema(DataSet ds, SchemaType mappingMode); FillSchema 首先获得一个数据集,然后通过与适配器相关联的 SELECT 命令根据需要向其添加任意数量的表。该方法会在一个数组中返回所创建的各个 “数据表” 对象(只有架构,没有数据)。映射模式参数可以是 SchemaType 枚举中定义的一个值。
表 3. SchemaType 枚举 可取的选项从字面上就能看出其含义。Mapped 说明定义了映射时的进行什么操作。而 Source 则有意忽略您可能已经设置的任何映射。数据集中的表会保留其默认名称,所有列也都会保留它们在源表中具有的原始名称。 管理用户配置文件 为了圆满完成这次关于表映射的讨论,我们来看一个您可能要考虑使用表映射的真实情况。假设您必须管理不同的用户配置文件。每个配置文件都需要您访问相同的一些表,但返回不同的列集合。您可以用许多方式解决这个问题,但 ADO.NET 表映射机制可能是最好的方法。 其理念是,您始终使用一个查询 - 针对权限最高的的配置文件的查询 - 然后映射到只包含特定于当前用户配置文件的列的结果数据集。下面的一些 Visual Basic® 代码说明了这个要点: Dim da As SqlDataAdapter
da = New SqlDataAdapter(m_selectCommand, m_connectionString)
Dim dtm As DataTableMapping
dtm = da.TableMappings.Add(da.DefaultSourceTableName, "Employees")
If bUserProfileAdmin Then
dtm.ColumnMappings.Add("EmployeeID", "ID")
dtm.ColumnMappings.Add("LastName", "Last Name")
dtm.ColumnMappings.Add("FirstName", "Name")
dtm.ColumnMappings.Add("Title", "Position")
dtm.ColumnMappings.Add("HireDate", "Hired")
Else
dtm.ColumnMappings.Add("LastName", "Last Name")
dtm.ColumnMappings.Add("FirstName", "Name")
End If
Dim ds As DataSet = New DataSet()
da.MissingMappingAction = MissingMappingAction.Ignore
da.MissingSchemaAction = MissingSchemaAction.Add
da.Fill(ds)
在这个简单的示例中,查询只返回一个结果集,我决定使用其默认名称 Table 识别该结果集。注意,为了实现通用性,您应该使用数据适配器对象的 DefaultSourceTableName 属性,而不是文字的名称 (Table)。表映射根据用户的角色定义不同的列映射。如果用户是管理员,数据集则会包括更多的列。当然,诸如角色和权限这些概念的真正实现完全取决于您。使整个过程按预期工作的关键语句是已设置为 Ignore 的 MissingMappingAction 属性值。结果是,未映射的列只是被忽略。最后,您要牢记的是,对于列名来说,区分大小写这一点非常重要,列映射名称的大小写必须与源列名的大小写相匹配。 小结 在这篇专栏文章中,我讨论了 ADO.NET 中提供的表映射机制。表映射是管理行从数据源到内存中数据集的传递过程的规则和行为集合。映射由两个步骤构成 - 表映射和列映射 - 它只是一个范围更广的操作的第一个阶段,该操作涉及到由数据适配器对象控制的数据集填充。第二个阶段在目标数据集实际被填充后开始。映射阶段和填充阶段中的任何逻辑异常都可以得到控制,方法是:声明当表或列没有显式绑定到数据集表时或数据集中没有所需的表或列时要执行哪些操作。 对话栏:区别 @Register 和 @Import 之间有什么区别呢?什么地方最适合由 ASP.NET 应用程序使用的非系统程序集 DLL? 首先,ASP.NET 应用程序是 .NET 应用程序。因而,它们需要链接到包含计划使用的对象的任何程序集。@Register 指令就是用于解决这个问题的。您在页面注册的任何程序集稍后将作为引用传递到所选择的编译器。@Import 指令的作用不是很重要,因为它的功能是简化编码。利用 @Import,您可以导入命名空间,而不是程序集。程序集可以包含更多命名空间。例如,程序集 system.data.dll 包含 System.Data、System.Data.OleDb、System.Data.SqlClient 等等。 通过导入命名空间,您可以编写更简单的代码,因而无需指定到给定对象的完整路径。通过导入 System.Data,您可以通过类 DataSet 而不是 System.Data.DataSet 使用数据集。要使用数据集,您不必使用 @Import 指令,但不能缺少对 system.data.dll 的引用。 具体地说,对于 ASP.NET 应用程序,您无需显式注册 Global Assembly Cache (GAC) 中提供的任何程序集。使用 @Register 只是为了引用已向系统 GAC 注册的自定义程序集。 这些程序集驻留在哪里呢?它们必须放在应用程序的虚拟目录下的 BIN 目录中。如果此目录不存在,则应该创建该目录。如果您的 ASP.NET 应用程序不使用虚拟目录,则会从 Web 服务器的根目录隐式运行。因此,BIN 目录在 Web 服务器的根目录下。例如,c:\inetpub\wwwroot\bin。 |