|
|
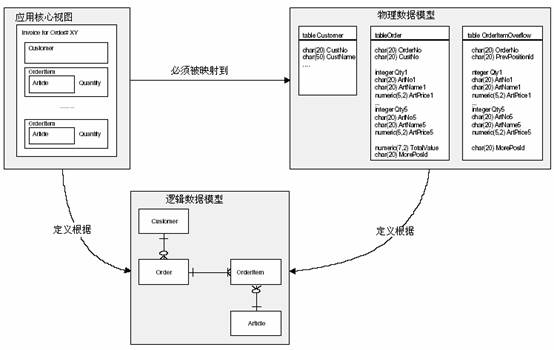
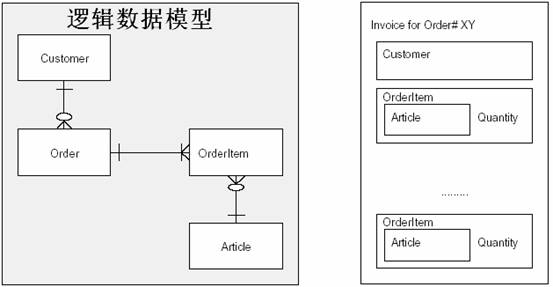
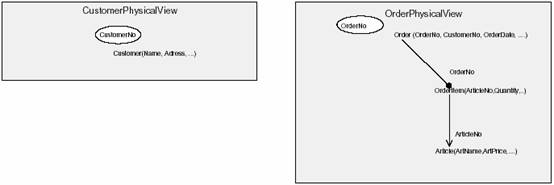
| ժҪ ��ϵ���ݿ������������������ʹ�ù�ϵ�����ݿ��Ӧ�ó�������ҵ�����ӳ��ϵ���㣬����Ӧ�ó���������������representational[Mar95]������ϵͳ������Ҫ���������ģ�����ȫ����ʹ�õ��������ԣ�3GL����ʵ�֣���ˣ����ĵ�ģʽ���Խ�����ӳ��̳кͶ�̬�����ԡ� ���İ������ģʽ�ͼ����ؼ���ʵ��ģʽ��PLoP ѧ��[Kel+96b]������������ģʽ���ԣ��������������Ż�ģʽ�� ��� �ܶ�ҵ����Ϣϵͳӵ��һ��������ģ�ͣ���ʹ���ǿ��ܻ���30�������ʵ��������Ǻ��ٷ��ּ̳л��߸��ӵĹ��������ڸ��ӵ������ͨ���Ƿ�װ��Ӧ�ó���ĺ��ġ��ù�ϵ������Ϊ��Щϵͳ��ģ��һ���ܺõ����⡣ ��������ͼ1����һ����������ϵͳ��ժ¼��Ƭ�ϣ������Ͻǣ��д�����������ʵ�壬���Ƭ����ѭ������ʽ��3NF�����������ֽ⼶�����ݷ����Ҿ�����ô����������ʹ������������ģ������������������ݿ����ϵͳ��Ȼ����������������������ȴ�Dz��ҹ�ά�� �������ϵͳ���㽫���ֺܶ��������ݿ������ͬʱ��Ҳ�ᷢ�����ݿ�������ڻ�����ԭ���Ǵ����ı����ӻ����Dz���Ҫ���ƶ��������ݡ�Ϊ��������ܣ����������������ģ���в���̫����ʽ���������ݿ����ݵ�ͳ�Ʒ�������90%�Ķ���ӵ�в�����5�������OrderItems������˿��Խ�ǰ5��OrderItems����Order���У�Ϊ����ʣ��10%�����Դ���һ��OrderItemOverflow������ͼ1���Ͻ���ʾ�����⣬�㻹���Խ���Ʒ������ArtPrice��ArtName���ɵ�Order���С��������������ݿ����ʹ�÷�����������һ��Order����һ��Customer�����Ϳ��Զ�ȡ90%�ķ������������������Ӷ�����ȥ���ˡ�
ͼ1����������ϵͳ�IJ��� ���ڼ�������Ӧ�ó���ĺ��Ĵ�����Ƕ����SQL��䣬Ϊ��Ӧ�µı��ṹ���㽫���ò���д���е�ij�����֣����⣬������Щ�����(OverflowTable)����ʹSQL���뱩¶����������ǣ��㻹���ò���ÿ�����ݿ�ṹ����ʱ�ظ���Щ���̡� ģʽ����ͼ ��ϵ���ݿ���ʲ���ģʽ���������IJ����Ľ�ɫ��ְ��ͬʱҲ�����������ؼ��������ͼ��������ͼ�Ͳ�ѯ������
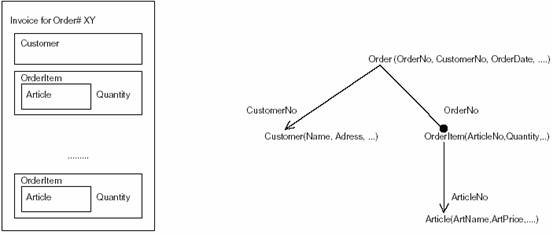
ͼ2����ģʽ���Ե�ӳ��ͼ�����е�ģʽ��ʾ�ڱ���������ģʽ���ҿ��е�ģʽֻ��PLoP ѧ��������[Kel+96b]�� ���ݿ���ʲ����ع��� ������Ϊ��Щ�����ݿ��Թ�ϵ�ͷ�ʽʹ�õ�Ӧ�ó����ṩ��һ�����ݿ���ͼ�ӿڣ������ij־û���ܺ�ģʽ���Զ��ǹ��ڶ���ij־û��������������ϵ�ķ��ʲ�[Bro+96, Col+96, Kel+96a]����ʹ��һ����ϵ�����ݿ⣻���ж�����ʲ㣬��ʹ��һ������������ݿ�[Col97]��ͼ3��ʾ����Щ��ͬ���ʲ������
ͼ3�����ֲ�ͬ�����ݿ���ʲ� ����Լ�� ����ʹ��OMT[Rum+91]����ʾ����ͼ�����»��ߵ�����ģʽ�ο�һ����ص�ģʽ�����һ��ģʽ�ο��������һ�����ã�����[GOF95]������Դ���Ӧ�ο��������ҵ����� ���ģʽ
ģʽ����ϵ���ݿ���ʲ�
���� ��������ڱ�дһ���������涩������ϵͳ��ҵ����Ϣϵͳ����ϵ������Ƚ��ʺ������������������ģ�ͷdz�������ʹ�ü̳У�������ϵģ��ӳ�䵽��������ʾ�Ĺ����ò���ʧ�� ���� ��η�����ϵ�����ݿ⣿ �Ⱦ�����
Ÿ
ҵ�������ɱ������ݿ��̺ܸ��ӣ�Ӧ����Ҳ����ˣ�����Ҫ�����Ľ�������������ǻ�������ĸ��ӳ̶�Ҫ�����������߸��Ӷȼ���ϡ������ķ����ǽ�Ӧ�ñ�̺����ݿ��̷��뿪�����߶�������ʵ�ֺͲ��ԡ���һ���棬�����µIJ㣬�����������������������ƺ�ʵ�ֵĹ�������Ҫ�������������ά���Ժ����ܵ����ϡ�
Ÿ
�������빦�ܣ���������Ҫ��װ���ݿ⣬���Ľӿڱ�������ʹ�á�����һ���棬���ݿ�ӿڵĸ��ӶȽ�Ӱ�����Ĺ��ܣ���ˣ��ӿڵķ�װ��Ҫ����ʹ�ã�����ҲҪ�㹻ǿ�������������Ŀ��
Ÿ
���ܣ�Ҫ��ҵ����Ϣϵͳ�ﵽһ���ɽ��ܵ����ܣ����ݿ��Ż��ǹؼ��ġ���Ϊ���ݿ��һ������������Ҫ�����������������ŵIJ��������������ݿ�����ϡ�������һ�������Ĺ��̣�Ϊ�Ż����ݿ���ʣ�����Ըı�洢�������������Լ����ķֲ���������ݿ��API��
Ÿ
������븴���ԣ���Ϊ���ݿ���ŷdz��ؼ�����Ҫ�����ݿ���һ���װ��������Ӧ�ú��IJ��������£�Ƶ���ı�ײ������ģ�͡���ˣ�ϵͳ�������Խ�ߣ������Ծ�Խ��
Ÿ
��ϵͳ���Ż���ƣ����ٴ��㿪ʼ���һ��ҵ����Ϣϵͳ��������Ҫ���ӵ�һ����ϵͳ�����Ҹ����Ͳ�����������ͨ���㲻����������е��������룬��Ϊ���ַ�ʽ�кܸߵķ��ղ����۲��ơ����ǣ��������ݵĽṹ���ٷ��������Ҫ�D�D������нṹ�Ļ�����Ҳ�����ò�����ͬ��������ݿ⼼���Ž�������Ϊ��֤Ӧ�õĿ�ά���ԣ��㲻�ò���װ�����ķ��ʽӿڣ������������ؽ���������һ��ǿ�ҵ��Ⱦ������� ������� ʹ��һ���ֲ�ļܹ����������㡣�����ʲ��ṩ�ȶ���Ӧ�ú��Ľӿڣ�������������������ݿ�ϵͳ�����߿�����Ӧ�����ܵ���Ҫ��������֮��ʹ��һ����ѯ�������������������
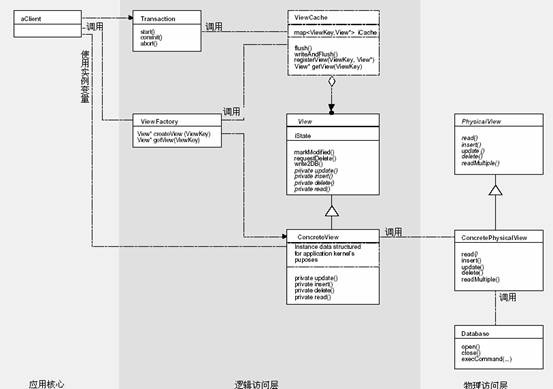
�ṹ ͼ4��ʾ�˹�ϵ���ݿ���ʲ���ࡣ�����ʲ��ṩ���������������࣬�������ʲ��ṩ�������ݿ�ϵͳ�Ľӿڡ�����ϸ���ɱ�ʾ���ݷ��ʵ�������ͼ��Database�࣬Database��������װ���ݿ�����ĵ��á����������ֱ��Ӳ���ӣ����ȡ���õķ�ʽ������һ����ѯ�������������������ʲ�֮�䡣
ͼ4����ϵ���ݿ���ʲ��ܵĽṹ���ͻ���ֻ���������ʲ㣬����������ʹ���������ʲ����ӵ����ݿ⡣ �����ɫ ������Transcation��
Ÿ
�ṩһ����������ʼ���ύ�ͻع����ӿڣ�
Ÿ
����ÿ������ʼǰ�����������ύ���ع������١������÷������ڶ�����[ODMG96, chapter2.8]�е�������� ��ͼ����(View Factory)
Ÿ
ת���ɼ�ֵ��ʶ�����ݡ����ṩcreateView()��getView()�������ֱ�����������ͼ�ͼ���������ͼ���ͻ���ֻ��ͨ���������������ܵõ���ͼ�����ã�
Ÿ
ʹ��һ����ͼ���壨View Cache��[Kel+96b]�����ⴴ���ڵ�ǰ�������Ѿ����ڵ���ͼ��
Ÿ
������ʶConcreteViews���ж�����һ���������ֵ��ViewKeyΪ���е����ṩ���ӿڣ�
Ÿ
����һ��Singleton����[GOF95]�� ��ͼ������ViewCache��
Ÿ
��������װ�����Σ�����һ����ֵ��������ͼ���������γɷ��ʲ�Ļ��壻
Ÿ
�ṩwriteAndFlush���������Խ������Ĺ�����ͼʹ��write2DB����д�����ݿ⡣����������ύʱ�������writeAndFlush������ֹ������flush()�����ViewCache�� ������ͼ��ConcreteView��
Ÿ
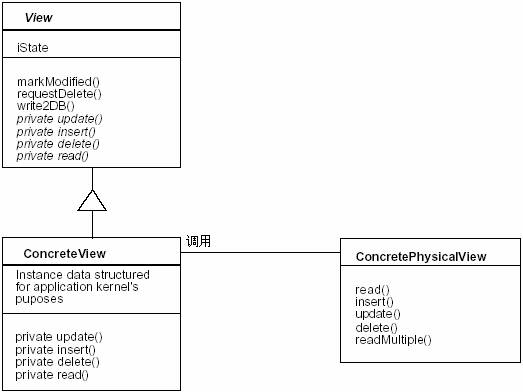
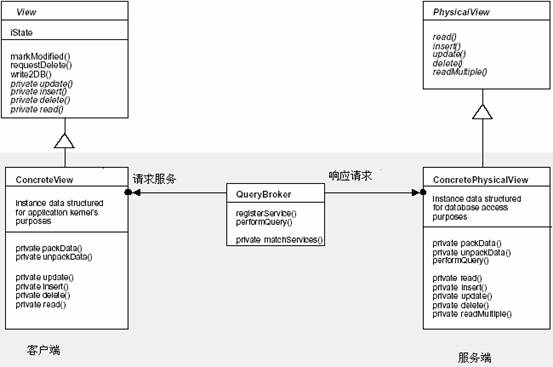
���������ݿ�ģ�͵������ͼ��Hierarchical View���������ɸ�������ͼ�ࡣÿ������Ӧ��Ӧ�ú���ij��������ConcreteView�ij�Ա��������Ӧ�ó����������ͣ��������ݿ����͡�
Ÿ
֪�����ͨ������������ͼ��ConcretePhysicalViews���������Լ�д�����ݿ⡣������ͼ�����������ڲ�״̬�����������ͼ������յ�һ��write2DB��Ϣ��������˽�е�update()��insert()��delete()��������Щ�����м�����ǿ�Ʊ������һ����Ӧ�ľ���������ͼ��Ҳ���Ե���һ����ѯ������Query Broker���� ��ͼ��View��
Ÿ
Ϊ������ͼ(ConcreteView)��������Э�飬�μ������ͼģʽ��
Ÿ
�ṩһ��markModified()�������ڵ�ǰ�����ύʱ�������ݿ���£�
Ÿ
�ṩrequestDelete()���������������ʱ�������ݿ�ɾ������Ҫ�������������������������������������ֻ�ǽ�������ڴ��������requestDelete()�������������������ݿ⣨ͬʱҲ���ڴ��У�ɾ����Ϊ�˱����������ã�requestDelete()����Ӧ����Ψһɾ�����ݿ��¼�ķ����� ������ͼ��PhysicalView��
Ÿ
Ϊ����������ͼ��ConcretePhysicalViews������ͳһ��Э�飻
Ÿ
�������ݿ���ʺ�������װ���ݿ���Ϊ�������ݿ������ת����Ӧ����������룻 ����������ͼ��ConcretePhysicalView��
Ÿ
��װһ���������ݱ�����Ҳ����װ���ݿ���ͼ��������ݿⲻ֧����ͼ��ֱ�Ӹ��£�����������ͼ��Ҫ�ṩ�ʵ���д���
Ÿ
��װ���ݿ��Ż������ʹ���Ƿ�ʽ�����ܿ����������������������£�����������ͼ����ӳ��������
Ÿ
���Դ�Ԫ������Ϣ���ɣ������ݿ�ı��ṹ�� ���ݿ���Database��
Ÿ
��װ���ݿ����ϵͳ���ṩ��ʼ���ݿ����ӵķ������Լ��������ݿ�������ս�����ȷ����� ��̬��Ϊ ���ǽ��������ģʽ�Ķ�̬��Ϊ��ʵ�ֿ�ܵIJ�ͬ���档 ʵ��
Ÿ
�Դ��������£�Mess Update������������������ʽ���硰update..where����ʹ��һ����ѯ����һ���¼�����ѽ���Щ��伯�ɵ���ͼ�����С��ϲ��������µ���˼�ǣ�����������ݵ���ͼ���壬�������ݼ�¼����д�����ݿ�ʱ��ÿ��дһ�������������ֱ�������ݿ��Ҫ���Ķࡣ
Ÿ
��������Ҫ�ر�Դ�����һЩģʽ������������ʽ�������ݿ⣬�������д��ھ�
Ÿ
���ز�ѯ�����Ǻ����˶��ز�ѯ������������ͼ��ShortView����խ��ͼ��Narrow View�����ҵ�������Ϣ��
Ÿ
�α��ȶ��ԣ����������ݶ�ȡ�����ύ��BFIM��ǰӳ��һ���Լ���Ǿ������ۿ����Եġ��⽫�ṩ��������һ���ԣ��α��ȶ���[Gra+93]��������һ�������һ���ԣ����������ݶ�ȡͨ����������б��μ�����ͼ�������Ǿ������硰select <fileds> from �� where������ʽ�����ύʱ������ǵ�һ������ζ���������У����¶�ȡ�����Ѷ���¼������������ǰ��ӳ���Ƚϡ������һ����¼��ͬ�������ò���ֹ�����ⲻ������������һ�����ص���в��ͬʱ��һ����Ҳû��ʲô��ֵ�����������£���������б���ļ�¼��������ƻ�����һ���ԵĽ�ɫ����ˣ��������У����ڲ������������ݣ�ͨ��ʹ�����һ���Ծ��㹻�ˡ�
Ÿ
����������ͼ�Ͷ�̬SQL��������ݿ�ϵͳ֧�ֶ�̬SQL��û��ʲô����ʱ�ĸ������������������������ͼ��ʹ�ò�ѯ������������Ӧ��SQL��䡣��̬��SQL�ɾ���������ͼ�ṩ��
Ÿ
���ݿ����Ӿ����ܳ�ʱ��ر�����Ϊÿ��������һ�������ӽ����²۸�����ܡ�
Ÿ
������ܹ��£�ǿ�ҽ��鲻ʹ�ô������Ͱ���ҵ�����Ĵ洢���̡�һ����ͼ����������֪ͨ�����ݿ������εı仯����˴洢���̿��ܻᵼ�»����һ�������⡣ͬ����������Ҳ���������⡣��Ϊ���ǹ�������������ģ�ͣ�����ת����Ӧ�ú��ĵ����㣬����Ҳ����Ϊ��������ݷ����ٶȣ���������ͼ��ʹ�����Ĵ洢���̡� ����
Ÿ
ҵ����룺���ʲ���������ݿ���ʡ������γ��˷�װ���õ���ϵͳ��Ӧ�ú���ʹ������ӿڣ���������ݿ�ķ������˽⡣
Ÿ
����ǿ�ȣ�ʵ��һ����ϵ���ݿ���ʲ���ݰ��������Բ�ͬ����Ҫ0.5��35�����꣬ʹ��������������Ӳ����ȹ���ά�����ߴ��ۺ���ѯ�����Ĵ���Ҫ�ͣ����������ͬ��ѡ��ǰ����ֿ���Ԥ�ڵı仯���г��ƹ���������������ڡ�
Ÿ
���ã�������ʲ㲢û�н���ϵģ��ת����һ�����������ͼ�����Ӧ�ú��ı��빤���ڹ�ϵ��ͼ�ϡ���Ӧ����ϸ�����Ƿ��������������ķ�ʽ�ʺ����Ӧ�����������Ƿ���Ĺ��̸��ʺ�ʹ�ö�������ϵ�ķ��ʲ㡣��Ӧ������ȷʵ��Ҫһ����ʽ��ӳ���ǣ������һ�������ӵķ��ʲ㲢����һ���õ��뷨��
Ÿ
����ԣ������ʹ��һ����ѯ�����������ͨ�������µľ���������ͼ��ά�����������ݿ⣬��������Ӧ�ú��Ĵ��롣�ڵײ��������ݿ�ı�ʱ��Ӧ�ô��뱣���ȶ���
Ÿ
�����ԣ�������ʲ��������ࡣ��ѯ�����dzɱ���ߵIJ��֣���Ϊ������һ�����ӵ���ƥ���㷨�����������Ե���һ�����������㣬��������Խ����ˡ�
Ÿ
���ܣ���ҪΪӳ�丶��һ������ʱ���ܵ��������������������ʹ�û������Ż������ڵ��ţ�����ʹ�ÿ��ٵĴ��������ڣ����������IO������
Ÿ
�������ݣ���Ҳ����ʹ�÷��ʲ�����������Ӧ�õ�������������ģ�ͼ����ϣ�����ع�����ϵͳ�dz����á����ȣ��ڴ����в���һ�����ݷ��ʲ㣬����һ�����пɿط��յĵ�һ���裬���ţ���ʼ�ڲ�ͬ����Ŀ����д���ݿ��Ӧ�ú��ġ� ����
Ÿ
��ȥ��ͼ���壺����㲻��Ҫ����������ȥ��ͼ���塣��ԼĶԻ���ϵͳ�ǿ��еģ�����ϵͳ��ÿ��������һ��֮����һ����¼���������Ӧ�ú�����һЩӰ�������¼������ʱ����Ӧ��ʹ����ͼ���塣
Ÿ
��������������֮��ʵ���û�����һ����������Ƿdz���Ȼ��ѡ������IMS��CICS��UTM�����û����������ಽ�Ի�������ɣ���������Ϊÿһ����ʼһ���µ�����ʹ����ͼ������������ռ���һ���û����������е�д���ݿ���������ţ����ǿ�����Ϊһ��������ʵ�ʵ�����ִ�У����Զ���Щ�ಽ���Ի��������������һ���ԡ�
Ÿ
ʹ�÷ǹ�ϵ�����ݿ⣺���������������װ�ǹ�ϵ�����ݿ���ļ���ʽ������IMS-DB��CODASYL��VSAM���������Խ�����д�����ɲ�ͬ�����ݿ⼼�������ض��������ݵķ��ʡ� ��֪Ӧ�� VAA���ݹ������淶ʹ�����ģʽ��������Ԫ���ݱ༭���ͶԲ�����ݿ�ϵͳ���ӵ�ӳ��[VAA95]��VAA���ݹ������Ǵ�W��rttembergische Versicherung[W��rt96]�����ݹ��������������ġ� Denert��[Den91,pp.230-239]�м����������ģʽ���Ե�һЩ����˼�룬sd&m��������Ŀ��ʹ�����ģʽ�ĸ��ֱ��֣�����Thyssen��Deutshche Bahn��HYPO����[Kel+96a]�� CORBA�־ö������POS��[Ses96]ָ���־ö���ʹ��һ���������־ö������������������д���������ݴ洢�У��־����ݷ��� ���ģʽ ���ģʽһ���ֲ㣨Layer����Ӧ��[Bus+96,pp.31]����ͼ����һ����������[Lan96]��Ӧ�á� [Bro+96]��[Col+96]�����������չ���ģʽ����Ӧ�ú����ṩ����������ͼ��Brown��Whitenack[Bro+96]ʹ��һ�����������Ͳ�֮�����ϣ���[Col+96]������һ��ֱ�����ӵķ����� һЩʵ��ģʽ
ģʽ�������ͼ
ʾ�� ����ͼ5�У���������ϵͳ��ϸ�ڡ����еķ��������ܾ�����ͼ�������������ע�������������������ӵIJ�νṹ��һ�������������Ǵ�һ�������ſ�ʼ����������ֶ���������ǵ���Ʒ��
ͼ5�����Ƕ�������ϵͳ����ģ����ϸ������õ�����ʽ��ʾ�� ERͼ���ұ��Ƿ������Ľṹ������Щʵ�幹�ɡ� ���� ���Ѿ�����ʹ�ù�ϵ���ݿ���ʲ��������������ݿ��Ӧ�ú��ĵ�������ģ��֮�����ϡ� ���� ���ݿ����ʲ���Ӧ�������ṩʲô�ӿڣ� �Ⱦ�����
Ÿ
���Ӷ��������ԺͿ����ɱ����ӿ�Ӧ�ü����ö���Ҫ���㹻�Ĺ����������Ҫ�����ݿ��������ΪӦ�ú��ķ�ӳ���������㲻���������ݿ��ض��Ĵ���������������������ӿ�Ӧ����ij�̶ֳ��Ϸ�ӳ�ʵ�������ݳ����ṩһ�������������ݿ�ܵĽӿ���ζ������ʵ�ִ����ݿ����ϵͳ���������̫���ˣ����ԣ�SQL���Ľӿڲ�����С�
Ÿ
������뿪���ٶȣ������ݿ����ʱ��ʹ��������ģ����Ϊָ�����ڶ��ڻ�������ʵ�ֿ�������Ľ�����������ǣ����ܵ��ź�ά����ʹ��Ҫ�����Ķ��������ݿ�IJ��֣�ͬʱ����Ҳ����ı�Ӧ�ú��ģ�����������Ҫһ�ֺ���������ģ���صĽӿڡ�
Ÿ
���ܣ������ϣ�������ʽ���ڹ�ϵ��������õģ�����������ģ�������������ºܲ�����ܡ�
Ÿ
�������⣺һ�����͵�����ģ�Ͱ����ϰ����������ʵ�壬�ֹ���Ϊ���ٸ�ʵ���д��װ������Ƕ���SQL������һ�����Ķ��ִ��۰����������Ĺ��������ǰ����������һ��Ľ�������������ݿ�����ʹ�úꡢ��������ģ�塣 ������� �����������ռ�����ʾ�ӿڣ��Ǿͳ�Ϊһ����ϵ����ģ�͡�������ģ�͵�һ�㣨��ʵ�壩��ʼ����ʹ��������ϵ�����ߵ���������Ȥ�ĵ㡣�����߹������γ��γ���һ��������ͼ��DAG����ÿ���ڵ�����ʵ������������Ժ�ѡ��ν�ʣ�ÿ���߱������ʹ�õ������Լ��������ȣ�һ��һ��һ�Զࣩ�� �ṹ
ͼ6��ʾ���൱����߷�������ͼ��ʾ Ҫ�����ͼת����һ�������ͼ����View����һ��ConcreteView�����ConcreteView��DAG�ĸ�����Ϊ�κ�һ���ڵ㶨��һ������࣬ʹ�þۼ���ʵ��ͼ��to one�Ĺ�ϵ��ʹ�ð�������ʵ��ͼ��to many�ıߡ�һ��ConcreteViewͨ�����ַ�ʽ�����������������ConcretePlysicalView�����ԣ��ʵ���ConcretePhysicalView����ʹ��Ӳ���뷽ʽ���û�ʹ�ò�ѯ������ ���ݿ������Ӧ���ܹ�������ConcreteViewsͳһ�Դ�����ˣ�View���������ǹ�ͨ�Ľӿ�ȥ���ʷ��ʲ����������ࡣ
ʵ�� �����ʹ���ı��ļ�����һ���ض��Ĺ���[Wurt96]������ConcreteViews�Ľṹ��������Ϊ��̬���������Զ�����ConcreteViews�࣬�����ڶ�̬�������Կ��Խ�������ʱ���塣 ����
Ÿ
�̳кͶ�̬�ԣ�������û����Ƕ�̳кͶ�̬�ԵĴ������������Ƿ��ʺ����������
Ÿ
�ӿڸ����ԣ�����ӿ�����С���ģ���Ϊ�����ṩӦ�ú�������Ļ������ԡ�Ȼ�����㲻�ò�����Ŭ������������ģ���ϣ����ڵ����ǻ���������ر�����ͬʱ������ﵽ����Ŀ��ǰ����Ҫ��������ά�����ڡ�һ�������������������ô�㶨���µ�ConcreteViews�����Ǽ����ӵ����顣
Ÿ
�ӿڷ��һ��ʹ�ò����ͼ��Ӧ�ó�������������ģ�͵Ľṹ��������ģ�;�����ʹ�����Ĵ���Ľṹ��������һ����������ϵ���ʲ��У�����ģ����������ڲ��ṹ��
Ÿ
�����Ժ�Ӧ�ú��ĵ��������ͼֻ��Ӧ�ض�����������������������ȷʵ֧�ֵģ���Ϊ�����ͼ��װ�����ݿ��ض����ܣ����Ե��÷��ʲ��Ƿdz��ġ�
Ÿ
���ܺ�����ԣ����ģ����ȫ������Ӧ�ú��ĺ���������ģ�͵���϶ȣ�������������������ݿ������Ӱ��Ӧ�ú��Ĵ��롣����������������Ҫ������������ͼ��һ��Ӳ��������ʧ��
Ÿ
�������⣺��������ÿ����������Ҫһ��������ConcreteView����ᵼ�´�������������������룬�������ű��ȵȡ�������ʹ��ģ�塢��������������ConcreteViews���㹻һ����ࡣ ʾ������ �����1��ʾ�˷�����ʾ���������������2���������������Ĵ��롣 struct
Customer { CustomerKeyType
iCustNumber; ...
// ������ģ���ֿͻ��������� }; struct
Article { ArticleNumberType
iArticleNumber; ...
// �������� }; struct
OrderItem { Article
iArticle; QuantityType
iQuantity; }; class
OrderInvoiceView : public View { public: OrderKeyType
iOrder; Customer
iCustomer; Vector<OrderItem> iItems; // ����������Ҳ���� Money
iSumOfInvoice; private: //
˽�з������Զ�ȡ��д������ //
��PhysicalView virtual
void update ( void ); virtual
void insert ( void ); virtual
void remove ( void ); virtual
void read ( void ); }; �����2�Ĵ�������ݿ��أ���������������ģ�͵ģ��Ƿ�ʽ������������ģ�Ͷ���Ӧ�ô����Dz��ɼ��ġ�����ֻ�����д����漰���־û���ViewFactory::getView()����ӷ�����õ����ݡ�pos->markModified()����ΪSumOfInvoice���ϱ�ǣ�������д�����ݿ⡣ void
Order::processInvoice ( OrderKeyType anOrder){ //
�����ݿ�õ����ݣ�����ָֻ��������ʣ�µ������ʲ�ȥ�� OrderInvoiceView * pInvoice
=
( OrderInvoiceView*)ViewFactory::getView( anOrder ); //
������������ ItemIterator itemIter = pInvoice->iItems.begin(); for(;
itemIter != iItems.end(); itemIter ++){
itemIter->iSumOfInvoice += (itemIter->iQuantity * itemIter->iArticle.iArticlePrice); } //
��ͼ�ı��ˣ������ pInvoice->markModified(); } �����2��processInvoice��ʵ�֡����������ʾ�˶����ж�����ı�����������ĿiSumOfInvoice���Ե���͡�ע�⣬���DZ�����������ģ���е�������Ӳ㡣Ϊ��������������ȥ��Χ��Order::processInvoice�������������һЩ���Ե����Ͷ��塣 ����
Ÿ
����Ӧ�ô����һЩ�������ļ��ϣ�����ֻ��Ҫ��һ����ļ�ӣ�����ʵ�����������ʵ�壩�����������ConcretePhysicalViews��װ�����ݿ���ʴ��벢��Ӧ���ṩ�㹻�ļ��ӿڣ�ʡ����ѯ�����������ͼ�����������Щ������Ƶ���10��ʵ��ĸ���������̫�ʺϣ����磬����Ӧ�õȡ�
Ÿ
һ�������ӵı�����������ȡ��ʷ���ݣ����㲻������һ����ͬ�ĵ�ǰ״̬����Ȥ�����Ҷ�����ijһ��ָ��ʱ���״̬����Ȥʱ����Ҫ���ֱ��֣�Ϊ�������ģ�ͣ��㲻�ò�Ϊ��ʾ����ʱ����������������������ߡ����չ�˾������Ҫ������ ��֪Ӧ�� VAA��Ӧ���ڵ¹����չ�˾��һ�������ܣ����ʱ�����ʹ�����ģʽ[VAA95]����Ӧ�����ݹ�������Ŀǰ�ڹ����У�W��rttembergische Versicherung[W��rt96]������һ��ʹ�ò����ͼ�����ݹ������Լ�һ���������ǵĹ��ߡ� ����sd&m����Ŀʹ�ò����ͼģʽ�ļ���(1:n views)��������Щ��ͼ[Den91]�� ���ģʽ �����ʹ��һ����ѯ���������������ͼ�͵ײ��������ݿ����϶ȡ�ʹ��һ����ͼ�����������ͬһ�������ݵ��ظ����ݿ���ʡ� ģʽ��������ͼ
���� ���Ѿ�����ʹ�ù�ϵ�����ݿ���ʲ㡣��ʹ�������ͼ��ΪӦ�ú��ĵĽӿڣ��������Ѿ������������ݿ�ķ��ʷ���ConcreteViews�� ���� ����ṩһ�����õķ����������ݿ���Ľӿڣ� �Ⱦ�����
Ÿ
�������ܣ�Ϊ�ﵽһ�����õ����ܣ��㲻�ò�ʹ���Ƿ�ʽ�����ɿ���������������Ż��������IJ��֡����ǣ�������Щ�������û�����Ƶ�ʹ�û���Ҵ����������ݽṹ���벢ʹ���ݿ���ʱ�ĸ��ӣ�����������������´��۸��ӵĴ��롣������Щ���ӵ��Ż����㻹����һ�����õĽӿں�һЩ��ά�����ࡣ
Ÿ
����ԣ�������ݿ������ṩ��ʹ�þ�̬���Ƕ�̬SQL��ѡ����Ϊ���ݿ�Ԥ���롢�Ż���̬SQL��ѯ����ͨ�����ٷ����������Եõ��Ϻ����ܡ�һЩ���ݿ����Աֻ�����ڷ�������ʹ�þ�̬SQL����һ���棬��̬SQL�������Ҹ���Ӧ���ݿ�ṹ�ı仯���������ڿ�����ʹ�á�Ϊ��������ܵ�������Ҳ����ʹ�õײ����ݿ�API�����ʲ�߲�APIӦ�ò�֪����Щϸ�ڡ�
Ÿ
��������Ϳ����ɱ�����Ϊ�������ݿ�������ϰٸ�������Ҳ������һ��������Щ�ӿڵ��Զ����̣��ꡢ��������ģ�嶼���Լ������������Ȼ����һ��ͨ�õĽӿڿ���Ҫ���Ѹ������Ŭ������Ϊ������Ҫ���ǵ���������� ������� ��һ��ConcretePhysicalView��װÿ��������ͼ��ͬ������Щ������װ�������Ϊ�ṩһ��ͳһ�Ľӿڣ���PhysicalViews������ConcretePhysicalViews����ʹ������PhysicalViews�ļ�¼�ṹ���洢���ǵ�ʵ�����ݣ���Ҫ�����Ƿ�װһ������������ͼ�����Ƿ�װ���������ͼ�� �ṹ
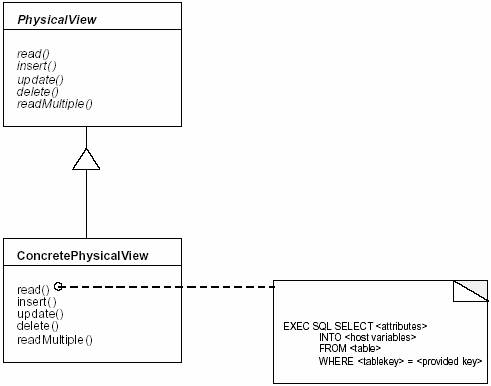
ʵ�� ��װʲô��ÿ��ConcretePhysicalViewӦ�÷�װһ����SQL��������Ӧ�����������Ϊ�����ͼָ����ConcretePhysicalView�������ѡ����ʹ��SQL���������ݿ���������������ڷ��ʲ��������ǡ�һ���ȽϺõ����ֵ���Ϊÿ����������������ͻ�������Ʒ��������һ��ConcretePhysicalView�������⣬Ϊÿ��������ʵ�塱����һ��ConcretePhysicalView������Ϊ���Ƕ��������ݿ���ͼ�����綩��/�������ϵ�������ʹ��һ����ѯ����������Է�����Щ���ߣ�Ѱ�����ĺ�ѡʵ�塣 ��װֻ����ͼ��Ϊ����������ͼ�����ܼ���Ӧ�ÿ�����ЩConcretePhysicalViews��Ȩ���������Ѷ�ȡ�����ݡ���ʾ���ݿ���ͼ��������ͼ���Լ���������ݿⶼ��֧��д��ͼ��������ˣ�����漰�����ű���һ��ֻ�����ʵ�������ͼҪ�ȶ�д�������ü�һ���õ���������ȫ��һ��������ͼӵ�ж�ij������дȨ�ޡ� ��̹��ߣ�ConcretePhysicalViews��һ���Ե��࣬ʹ��һ�����������꼼��ȥʵ�����ǣ���ȻҲ���Կ���ģ�塣 ʹ�ô洢���̺�����API����������ݿ��ṩ�洢�����Խ������ݿ�������ϵ����㡣��Ϊ������ͼ��ֱ�ӹ��������ݿ��ϵģ���˿���ʹ�ô洢���̻��������κη������ݿ�Ԫ���API��ʵ�֡�ʹ����������������д�������Ż���������������������ݿ������ʽ�ģ�����ij���������Լ���Ƕ��SQL�����ǣ��⽫�������ݿ�������ĸ��أ�������Ҫȷ�������е�Ӧ�ö�Ҫ��������ļܹ��� ����
Ÿ
���ԣ�������ͼ�������Ż������ݿ��̵ĸ����ԡ���Ϊ��û���������Σ�Ҳ������ʵ�֡�������ˣ����ӵ��������˸��ӵ��ࡣ�����ƻ���ȥ��ѯ��������ֱ��Ӳ���ӵ�ConcreteView�Ļ�����Ӧ�ÿ���������Ƿ�����һ��������������Ƿ�ConcreteView����Ӧ�÷������ݿ⡣���ߵ��½��ٵ��࣬������Ӧ�ģ������Ҳ�����ˡ�
Ÿ
����ԣ���Ϊ������ͼ��װ�����ݿ���룬ʹ�ú���APIȥ�������ݿ������ǵ�ѡ������Խ���ͬ���ݿ����API�ֳɼ����ࡣ�������������ʱ������ͬ�����ݿ���ʼ�������Ϳ���ʹ����(Bridge)[GOF95]����̬�л�����ģʽ��
Ÿ
��װ��������ͼʹ������Ӱ���ϲ���Ż��������ݿ�ṹ�����˵��Ź��������¸��ѵ����ܡ������ĸ��Ӽ�Ӽ����������������ġ�
Ÿ
�������⣺��������һ��������������һ�����汾��ConcretePhysicalView��ֻҪ�㲻ʹ�����������ֻ��Ҫ����Ӧ��SQL����װ�����������ӵ�������������Ҫ��������������⡣ ���� �����ѡ��ֱ������ConcreteViews��ConcretePhysicalViews������ܽ�ConcretePhysicalViews��ΪConcreteViews�ķ��������������������Խϵͣ���Ϊ�����ظ�ʹ��ͬһ��ConcretePhysicalView�� ��Ҳ����ʹ��������ͼ����װ��SQL���ݿ���ļ�ϵͳ������ADABAS��IMS-DB��CODASYL��VSAM�ȡ�����ǰ���ᵽ�ˣ������ʹ����Щ������������ϵͳ�Ϲ�����ϵ�͵�Ӧ�á� ʾ����� ͼ7��ʾ������������ͼ��DAG���壬�������ǵķ�������������ġ����Ƕ�Ӧ���������ݿ�ṹ����Ҳ�������������ͼ1����Ϊ�˼�OrderPhysicalView��Ӧ��ֻ��Order��OrderItem���ݸ��Ը��·���Ȩ�ޣ���������������ͼ�ı�Ariticle����
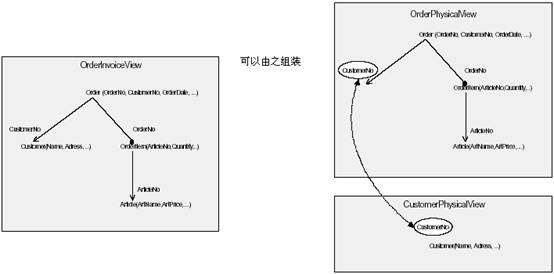
ͼ7������ConcretePhysicalViews��DAG���塣ע��OrderPhysicalView��װOrder�������������OrderItemOverflow����CustomerPhysicalViewֻ��װ��һ��Customer�����μ�ͼ1���������ṹ�� ���ģʽ ���Ż�����������ۣ�����[Kel+96b]�������ģʽ����ϸ��������β��ֺϲ������ܿص����������˹��ں�ʱ��дȨ�����ۡ�խ��ͼ����������ͼ����ѡ�����ݵ���ʾ�� ģʽ����ѯ����
ʾ�� ����ǰ�淢���������ӣ�OrderInvoiceView�����������ݽṹ����OrderPhysicalView��CustomerPhysicalView��������Ӧ����������
���� ���Ѿ�����ʹ����ϵ���ݿ����ʲ�����ʹ�������ͼ��ΪӦ�ú��ĵĽӿڣ���ʹ��������ͼ����װ���ݿ���ʡ� ���� ������Ӳ����ͼ��������ͼ�Խ��ж�ȡ��д�룿 �Ⱦ�����
Ÿ
�ɱ�������ԣ����ʡ�ɱ��ķ�ʽ��ͨ����������ֱ��Ӳ���ӣ�һ��ConcreteView֪������������ĸ�PhysicalViews�����ܹ�ʹ��Լ���ı�������������Ӧ�ĵ��ã��������еIJ㶼�dz��ȶ�������»Ṥ���úܺã����ǣ������һ�㲻�Ǻ��ȶ��������Ҫʹ��ij�ַ�ʽ��������ϡ��ڷ��ʲ��У������бȽ��ȶ��IJ����ͼ��λ�ڲ�̫�ȶ���������ͼ֮�ϡ����ϵͳ�㹻С�������ʹ��һ����������������������㡣���������ϵͳ���ڵ�ʱ�佫�кü��꣬���ַ�ʽ����Ϊ�����������������������ijɱ�������һ���㽫���ò���ÿ����������ģ�ͷ����仯ʱ�����������ݿ����������������ǧ���ͻ��ˡ�
Ÿ
�����ԣ���Ȼ������ͼ����Ѹ�ٸı䣬����ӳ���ݿ�������ṹ������п��������ɸ�Ӧ�ó���ʹ����ͬ��������ͼȴӵ�в�ͬ�IJ����ͼ��Ϊÿ��������Ӧ�ñ�дһ����������ϻ���ʹ�������������ͼ�еõ��ĺô������֡�
Ÿ
�����ԣ���ΪӲ����Ľ����������������Ҫһ�������ӵķ�����Ȼ�������ӵĸ�����ʹ���ϵͳ�ɱ����������Զ���ά���� ������� ʹ��һ������[Bus+96]�����������㣬�����ͼ�γɲ�ѯ�����Ŀͻ��ˣ�������ͼ��Ϊ�����ķ���ˡ�ʹ��DAG������������ʹ��һ����ƥ���㷨��Ѱ������ƥ�䡣�ò�ѯ����װ��������ͼ������������ڲ�ѯ������������С� �ṹ �����ǽ�����ϵ�һ�ֱ������������ı��ṹӦ�������ݿ���ʲ��ܣ�
Ÿ
��ѯ������һ������������Ҫ����������ͨ���ж�������������һ����������˵�ӳ�䲻��һ��һ����һ�Զ�Ĺ�ϵ��
ͼ8����ѯ������һ��Ӧ�õ����ݿ���ʲ��ܵĴ�����
Ÿ
����ͨ��ʹ�÷�����������ʶ�������������ڷ�������ͷ����֮����һ��1:n�Ĺ�ϵ���ⲻ���ʺϡ���ˣ���ѯ����ʹ������������DAGs��������������ͼ������ͼ9����߱�ʾOrderInvoiceView�������ұ߱�ʾ��Ӧ�ķ���Ϊ��װConcretePhysicalViews����ѯ����ƥ��ؼ��֣�����ڰ�ɫ��Բ�С�
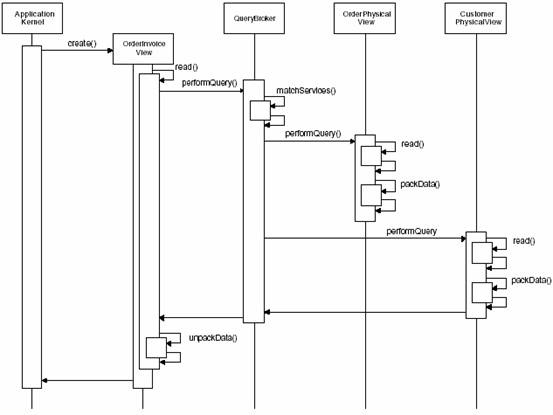
ͼ9����ƥ�������ѯ�����յ������������ʾ�����Ƕ�������ϵͳ��OrderInvoiceView���ұ���ʾ����Ӧ������������ͼ�������ѯ�����õ���߱�ʾ��������ô�ұߵ�������ͼ����������������ŷ�ʽ�� ��̬��Ϊ ������ij����У�һ��Ӧ�ú��Ķ���һ��OrderInvoiceView������һ�����ݿ����read()����ѯ��������read()������ͨ��һ��matchServices()�����������еķ���ƥ��һ����ͼ������QueryBroker���������ת����������ͬ��ConcretePhysicalViews��OrderPhysicalView��CustomerPhyscialView��������read()�����ݿ��ȡ���ݲ������ݴ����������������з�������������ϲ����������������OrderInvoiceView����һ�������OrderInvoiceView�ٽ����ݽ��������ʵ�������С�
ͼ10���ɲ�ѯ������ȡ���� ʵ��
Ÿ
�����ע����е�ConcretePhyscialViews�����ڵ�һ�����ݿ����ǰע�ᵽQueryBroker�У���ϵͳ��ʼ��ʱҪ�ر�ע����һ�㡣�����ʹ��һ������ʱ�ֵ䡢����һЩ��ʽ��ע��������������ض��ij�ʼ��������
Ÿ
ת���������͵�ְ��ԭʼ���ݿ����ͺ�Ӧ���������͵Ļ���ת��������ѡ�����磬�㲻�ò���һ��CHAR(20)����ת����һ��OrderKeyType���ͣ���֮��Ȼ�������ת��ConcreteViews��Ҳ����ת��PhysicalViews�������һ������ʱ�ֵ䣬������������ģ�ͺ���Щ����ת������ЩӦ���������͵���Ϣ���Ϳ���ͬʱ֧��������ѡ��
Ÿ
��ƥ�䣺ƥ��DAG�����ڱ������Ĵ������ɣ�������Ϊ����Ѱ��һ������Ļ���룬���ԣ������ʹ�����Ƶ��㷨[Aho+86,9.2��]��������������Ϊһ������Ѱ�����ɾ��в�ͬ�ٶȵIJ�ѯ�ƻ���ƥ���㷨���봦���������������Եõ�һ�����ķ������Ա������Ż�Ҳ���������⣬Ϊ�������ɵ�Ŀ�ģ������������
Ÿ
��ѯ�����ͽ������������������ҵ�һ�������DAG��ʾ��������������ѯ��һ���棬��ͼӦ���ܹ�������ָ�����ǵ�����ͷ�����һ���������ʾ��Ӧ��˳Ӧƥ���㷨����Ҫ��һ�����ڽ������ı���ʾ��һ���ܺõ�ѡ�� ����
Ÿ
����ԣ���ѯ������ȫ�����˲����ͼ��������ͼ����϶ȣ�������ʱ���µ�������ͼ���ܱ�ע�ᣬ���ҺͲ����ͼ�Ĺ���Ҳ�ᱻ�ı䡣
Ÿ
���Ӷȣ����ṹ�Ľ������������������������ƥ���㷨ʹ��ѯ����������ƣ����Ǵ�����װ�Ժܸߣ������˵�һ��ϵͳ�ĸ����ԡ�
Ÿ
�����ԣ���Ϊ��ѯ���������������ӵ���ͼ������Խ�����Ϊ��ܵ�һ���֣���Ƚ�������������ͼ�����������á�
Ÿ
�ɱ�����ѯ�����ĸ��Ӷ�ʹ֮ʵ�ֵĴ��ۺܸߣ�һ������ʱ�ֵ�������˳ɱ���������Ϊ��������ʵ�ֳ�һ�������õĿ�ܲ�Ӧ���ڶ��Ӧ�ó����С�Ӳ������ϵĹ��������ϵ͵���ʹ�Ż��������ҵ����뽫������������ǧ���ͻ���ʱ����ֱ�Ǹ������� ���� �����ֻʹ�ö�̬SQL����ѯ����������װSQL��������ʹ��������ͼ������ڸɾ������ݿ�ģ�����������������Ƕ���������Ĵ����ͺ��ѡ�������ڿ���������ʹ�����ַ�ʽ�����ţ�����Խ��Խ���ʹ�þ�̬SQL������API��������ͼ��������������Ӧ�ú�����������Щ�仯�������Ǹ���������ע�����Ѱ�����ķ��� ��֪Ӧ�� ��ѯ�����㼯�˶�����õ�ʵ��Ӧ�ã� VAA���ݹ�����[VAA95]����������ģ�Ͷ�����ͼ����ʹ��һ���Զ����ɵ�Ӳ������������㡣������HYPO-Bank�еľ�����������������Ķ���������ʹ�ö�̬��������sd&m��������Ŀʹ�������ַ�ʽ������Ҫ�IJ��֡� sd&m��LSM��Ŀʹ�ö�̬SQL����ֲ����̬SQL�������γ�һ��Ԫ��ӿڡ�����뷨���Թ�����һ�����������ݿ�������ϵ�ʵ�ʾ��飬�����Ŀ��ȫʹ��һ������ʱ�����ֵ����ŽӶ�̬��ѯ��Ԥ�����ѯ�� �¹����ֵ�Fall/OK��Ŀʹ����ƥ�䣬�������ͨ����һ����������ģ���ϵ�ʾ��������ѯ������ģ�͵ĸı�dz�Ƶ���� CORBA�־ö������[Ses96]Ҳʹ����һ��������Ӧ�ú��Ķ������ǵ�ʵ������д������Ȼ��һ���������־ö��������������ת����ij���־ö���������ݿ������ʲô�����־ö������������κ����ݿ⣬��������֪��������Ҳ��һ�ּ�����ͷ����֮��һ��һ������� ���ģʽ [Bus+96]������һ�����ڴ����ĸ��㷺�����ۡ� Brown��Whitenack������һ������ģʽ[Bro+96]�Ļ����࣬ע�⣬��ѯ�����Ǹ�һ�������� �ο�����
|