| 适用于: 摘要:本文介绍托管代码执行时间的低级操作开销模型,该模型是通过测量操作时间得到的,开发人员可以据此做出更好的编码决策并编写更快的代码。 下载 CLR Profiler。(330KB) 目录简介(和誓言) 简介(和誓言)实现计算的方法有无数种,但这些方法良莠不齐,有些方法远胜于其他方法:更简单,更清晰,更容易维护。有些方法速度很快,有些却慢得出奇。 不要错用那些速度慢、内容臃肿的代码。难道您不讨厌这样的代码吗:不能连续运行的代码、不时将用户界面锁定几秒种的代码、顽固占用 CPU 或严重损害磁盘的代码? 千万不要用这样的代码。相反,请站起来,和我一起宣誓: “我保证,我不会向用户提供慢速代码。速度是我关注的特性。每天我都会注意代码的性能。我会经常地、系统地‘测量’代码的速度和大小。我将学习、构建或购买为此所需的工具。这是我的责任。” (我保证。)你是这样保证的吗?非常好。 那么,怎样才能在日常工作中编写出最快、最简洁的代码呢?这就要不断有意识地优先选择节俭的方法,而不要选择浪费、臃肿的方法,并且要深入思考。即使是任意指定的一段代码,都会需要许多这样的小决定。 但是,如果不知道开销的情况,就无法面对众多方案作出明智的选择:如果您不知道开销情况,也就无法编写高效的代码。 在过去的美好日子里,事情要容易一些,好的 C 程序员都知道。C 中的每个运算符和操作,不管是赋值、整数或浮点数学、解除引用,还是函数调用,都在不同程度上一一对应着单一的原始计算机操作。当然,有时会需要数条计算机指令来将正确的操作数放置在正确的寄存器中,而有时一条指令就可以完成几种
C 操作(比较著名的是 到了 20 世纪 90 年代,为了将数据抽象、面向对象编程和代码复用等技术更好地用于软件工程和生产,PC 软件业将 C 发展为 C++。 C++ 是 C 的超集,并且是“使用才需付出”,即如果不使用,新功能不会有任何开销。因此,C 的专用编程技术,包括其内在的开销模型,都可以直接应用。如果编写一段 C 代码并用 C++ 重新编译这段代码,则执行时间和空间的系统开销不会有太大变化。 另一方面,C++ 引入了许多新的语言功能,包括构造函数、析构函数、New、Delete、单继承、多继承、虚拟继承、数据类型转换、成员函数、虚函数、重载运算符、指向成员的指针、对象数组、异常处理和相同的复合,这些都会造成许多不易察觉但非常重要的开销。例如,每次调用虚函数时都要花费两次额外的定位,而且还会将隐藏的 vtable 指针字段添加到每个实例中。或者,考虑将这段看起来比较安全的代码: { complex a, b, c, d; ... a = b + c * d; }
编译为大约十三个隐式成员函数调用(但愿是内联的)。 九年前,在我的文章 C++:Under the Hood(英文)中曾探讨过这个主题,我写道: “了解编程语言的实现方式是非常重要的。这些知识可以让我们消除‘编译器到底在做些什么?’的恐惧和疑虑,让我们有信心使用新功能,并使我们在调试和学习其他的语言功能时更具洞察力。这些知识还能使我们认识到各种编码方案的相对开销,而这正是我们在日常工作中编写出最有效的代码所必需的。” 现在,我们将以同样的方式来了解托管代码。本文将探讨托管执行的“低级”时间和空间开销,以使我们能够在日常的编码工作中权衡利弊,做出明智的判断。 并遵守我们的承诺。 为什么是托管代码?对大多数本机代码的开发人员来说,托管代码为运行他们的软件提供了更好、更有效率的平台。它可以消除整类错误,如堆损坏和数组索引超出边界的错误,而这些错误常常使深夜的调试工作无功而返。它支持更为现代的要求,如安全移动代码(通过代码访问安全性实现)和 XML Web Service,而且与过去的 Win32/COM/ATL/MFC/VB 相比,.NET Framework 更加清楚明了,利用它可以做到事半功倍。 对软件用户来说,托管代码为他们提供了更丰富、更健壮的应用程序,让他们通过更优质的软件享受更好的生活。 编写更快的托管代码的秘诀是什么?尽管可以做到事半功倍,但还是不能放弃认真编码的责任。首先,您必须承认:“我是个新手。”您是个新手。我也是个新手。在托管代码领域中,我们都是新手。我们仍然在学习这方面的诀窍,包括开销的情况。 面对功能丰富、使用方便的 .NET Framework,我们就像糖果店里的孩子:“哇,不需要枯燥的
一切都是那么容易。真的是很容易。即使是从 XML 信息集中提出几个元素,也会轻易地投入几兆字节的 RAM 来分析 XML 信息集。使用 C 或 C++ 时,这件事是很令人头疼的,必须考虑再三,甚至您会想在某些类似 SAX 的 API 上创建一个状态机。而使用 .NET Framework 时,您可以在一口气加载整个信息集,甚至可以反复加载。这样一来,您的应用程序可能就不再那么快了。也许它的工作集达到了许多兆字节。也许您应该重新考虑一下那些简单方法的开销情况。 遗憾的是,在我看来,当前的 .NET Framework 文档并没有足够详细地介绍 Framework 的类型和方法的性能含义,甚至没有具体指明哪些方法会创建新对象。性能建模不是一个很容易阐述的主题,但是“不知道”会使我们更难做出恰当的决定。 既然在这方面我们都是新手,又不知道任何开销情况,而且也没有什么文档可以清楚说明开销情况,那我们应该做些什么呢? 测量,对开销进行测量。秘诀就是“对开销进行测量”并“保持警惕”。我们都应该养成测量开销的习惯。如果我们不怕麻烦去测量开销,就不会轻易调用比我们“假设”的开销高出十倍的新方法。 (顺便说一下,要更深入地了解 BCL [基类库] 的性能基础或 CLR,请查看 Shared Source CLI [英文],又称 Rotor。Rotor 代码与 .NET Framework 和 CLR 属于同一类别,但并不是完全相同的代码。不过即使是这样,我保证在认真学习 Rotor 之后,您会对 CLR 有更新、更深刻的理解。但一定保证首先要审核 SSCLI 许可证!) 知识如果您想成为伦敦的出租车司机,首先必须学习 The Knowledge(英文)。学生们通过几个月的学习,要记住伦敦城里上千条的小街道,还要了解到达各个地点的最佳路线。他们每天骑着踏板车四处查看,以巩固在书本上学到的知识。 同样,如果您想成为一名高性能托管代码的开发人员,您必须获得“托管代码知识”。您必须了解每项低级操作的开销,必须了解像委托 (Delegate) 和代码访问安全等这类功能的开销,还必须了解正在使用以及正在编写的类型和方法的开销。能够发现哪些方法的开销太大,对您的应用程序不会有什么损害,反倒因此可以避免使用这些方法。 这些知识不在任何书本中,也就是说,您必须骑上自己的踏板车进行探索:准备好 csc、ildasm、VS.NET 调试器、CLR 分析器、您的分析器、一些性能计时器等,了解代码的时间和空间开销。 关于托管代码的开销模型让我们开门见山地谈谈托管代码的开销模型。利用这种模型,您可以查看叶方法,能马上判断出开销较大的表达式或语句,而在您编写新代码时,就可以做出更明智的选择。 (有关调用您的方法或 .NET Framework 方法所需的可传递的开销,本文将不做介绍。这些内容以后会在另一篇文章中介绍。) 之前我曾经说过,大多数的 C 开销模型仍然适用于 C++ 方案。同样,许多 C/C++ 开销模型也适用于托管代码。 怎么会这样呢?您一定了解 CLR 执行模型。您使用几种语言中的一种来编写代码,并将其编译成 CIL(公用中间语言)格式,然后打包成程序集。当您运行主应用程序的程序集时,它开始执行 CIL。但是不是像旧的字节码解释器一样,速度会非常慢? 实时编译器不,它一点也不慢。CLR 使用 JIT(实时)编译器将 CIL 中的各种方法编译成本机 x86 代码,然后运行本机代码。尽管 JIT 在编译首次调用的方法时会稍有延迟,但所调用的各种方法在运行纯本机代码时都不需要解释性的系统开销。 与传统的脱机 C++ 编译过程不同,JIT 编译器花费的时间对用户来说都是“时钟时间”延迟,因此 JIT 编译器不具备占用大量时间的彻底优化过程。尽管如此,JIT 编译器所执行的一系列优化仍给人以深刻印象:
结果可以与传统的本机代码相媲美,至少是相近。 至于数据,可以混合使用值类型和引用类型。值类型(包括整型、浮点类型、枚举和结构)通常存储在栈中。这些数据类型就像 C/C++ 中的本地和结构一样又小又快。使用 C/C++ 时,应该避免将大的结构作为方法参数或返回值进行传送,因为复制的系统开销可能会大的惊人。 引用类型和装箱后的值类型存储在堆中。它们通过对象引用来寻址,这些对象引用只是计算机的指针,就像 C/C++ 中的对象指针一样。 因此实时编译的托管代码可以很快。下面我们将讨论一些例外,如果您深入了解了本机 C 代码中某些表达式的开销,您就不会像在托管代码中那样错误地为这些开销建模。 我还应该提一下 NGEN,这是一种“超前的”工具,可以将 CIL 编译为本机代码程序集。尽管利用
NGEN 编译程序集在当前并不会对执行时间造成什么实质性的影响(好的或坏的影响),却会使加载到许多应用程序域和进程中的共享程序集的总工作集减少。(操作系统可以跨所有客户端共享一份利用
NGEN 编译的代码,而实时编译的代码目前通常不会跨应用程序域或进程共享。请参阅 自动内存管理托管代码与本机代码的最大不同之处在于自动内存管理。您可以分配新的对象,但 CLR 垃圾回收器 (GC) 会在这些对象无法访问时自动释放它们。GC 不时地运行,通常不为人觉察,但一般会使应用程序停止一两毫秒,偶尔也会更长一些。 有一些文章探讨了垃圾回收器的性能含义,这里就不作介绍了。如果您的应用程序遵循这些文章中的建议,那么总的内存回收开销就不会很大,也就是百分之几的执行时间,与传统的
C++ 对象 但仍不能“免费”分配对象。对象会占用空间。无限制的对象分配将会导致更加频繁的内存回收。 更糟糕的是,不必要地持续引用无用的对象图 (Object Graph) 会使对象保持活动。有时,我们会发现有些不大的程序竟然有 100 MB 以上的工作集,可是这些程序的作者却拒绝承认自己的错误,反而认为性能不佳是由于托管代码本身存在一些神秘、无法确认(因此很难处理)的问题。这真令人遗憾。但是,只需使用 CLR 编译器花一个小时做一下研究,更改几行代码,就可以将这些程序用到的堆减少十倍或更多。如果您遇上大的工作集问题,第一步就应该查看真实的情况。 因此,不要创建不必要的对象。由于自动内存管理消除了许多对象分配和释放方面的复杂情况、问题和错误,并且用起来又快又方便,因此我们会很自然地想要创建越来越多的对象,最终形成错综复杂的对象群。如果您想编写真正的快速托管代码,创建对象时就需要深思熟虑,确保对象的数量合适。 这也适用于 API 的设计。由于可以设计类型及其方法,因此它们会要求客户端创建可以随便放弃的新对象。不要那样做。 托管代码的开销情况现在,让我们来研究一下各种低级托管代码操作的时间开销。 表 1 列出了各种低级托管代码操作的大致开销,单位是毫微秒。这些数据是在配备了 1.1 GHz Pentium-III、运行了 Windows XP 和 .NET Framework v1.1 (Everett) 的静止 PC 上通过一套简单的计时循环收集到的。 测试驱动程序调用各种测试方法,指定要执行的多个迭代,自动调整为迭代 218 到 230 次,并根据需要使每次测试的时间不少于 50 毫秒。一般情况下,这么长的时间足可以在一个进行密集对象分配的测试中观察几个 0 代内存回收周期。该表显示了 10 次实验的平均结果,对于每个测试主题,都列出了最好(最少时间)的实验结果。 根据需要,每个测试循环都展开 4 至 60 次,以减少测试循环的系统开销。我检查了每次测试生成的主机代码,以确保 JIT 编译器没有将测试彻底优化,例如,我修改了几个示例中的测试,以使中间结果在测试循环期间和测试循环之后都存在。同样,我还对几个测试进行了更改,以使通用子表达式消除不起作用。 表 1:原语时间(平均和最小)(ns)
免责声明:请不要照搬这些数据。时间测试会由于无法预料的二次影响而变得不准确。偶然事件可能会使实时编译的代码或某些关键数据跨过缓存行,影响其他的缓存或已有数据。这有点像不确定性原则:1 毫微秒左右的时间和时间差异是可观察到的范围限度。 另一项免责声明:这些数据只与完全适应缓存的小代码和数据方案有关。如果应用程序中最常用的部分不适应芯片缓存,您可能会遇到其他的性能问题。本文的结尾将详细介绍缓存。 还有一项免责声明:将组件和应用程序作为 CIL 的程序集的最大好处之一是,您的程序可以做到每秒都变快、每年都变快。“每秒都变快”是因为运行时(理论上)可以在程序运行时重新调整 JIT 编译的代码;“每年都变快”是因为新发布的运行时总能提供更好、更先进、更快的算法以将代码迅速优化。因此,如果 .NET 1.1 中的这几个计时不是最佳结果,请相信在以后发布的产品中它们会得到改善。而且在今后发布的 .NET Framework 中,本文中所列代码的本机代码序列可能会更改。 不考虑这些免责声明,这些数据确实让我们对各种原语的当前性能有了充分的认识。这些数字很有意义,并且证实了我的判断,即大多数实时编译的托管代码可以像编译过的本机代码一样,“接近计算机”运行。原始的整型和浮点操作很快,而各种方法调用却不太快,但(请相信我)仍可比得上本机 C/C++。同时我们还会发现,有些通常在本机代码中开销不太大的操作(如数据类型转换、数组和字段存储、函数指针 [委托])现在的开销却变大了。为什么是这样呢?让我们来看一下。 算术运算表 2:算术运算时间 (ns)
过去,浮点运算几乎比整数运算慢一个数量级。如表 2 所示,在使用现代的管道化的浮点单位之后,二者之间的差别变得很小或没有差别。而且令人惊奇的是,普通的笔记本 PC 现在已经可以在每秒内进行十亿次浮点运算(对于适应缓存的问题)。 让我们看一行从整数和浮点的加法运算测试中得到的实时编译代码: 反汇编 1:整数加法运算和浮点加法运算 int add a = a + b + c + d + e + f + g + h + i; 0000004c 8B 54 24 10 mov edx,dword ptr [esp+10h] 00000050 03 54 24 14 add edx,dword ptr [esp+14h] 00000054 03 54 24 18 add edx,dword ptr [esp+18h] 00000058 03 54 24 1C add edx,dword ptr [esp+1Ch] 0000005c 03 54 24 20 add edx,dword ptr [esp+20h] 00000060 03 D5 add edx,ebp 00000062 03 D6 add edx,esi 00000064 03 D3 add edx,ebx 00000066 03 D7 add edx,edi 00000068 89 54 24 10 mov dword ptr [esp+10h],edx float add i += a + b + c + d + e + f + g + h; 00000016 D9 05 38 61 3E 00 fld dword ptr ds:[003E6138h] 0000001c D8 05 3C 61 3E 00 fadd dword ptr ds:[003E613Ch] 00000022 D8 05 40 61 3E 00 fadd dword ptr ds:[003E6140h] 00000028 D8 05 44 61 3E 00 fadd dword ptr ds:[003E6144h] 0000002e D8 05 48 61 3E 00 fadd dword ptr ds:[003E6148h] 00000034 D8 05 4C 61 3E 00 fadd dword ptr ds:[003E614Ch] 0000003a D8 05 50 61 3E 00 fadd dword ptr ds:[003E6150h] 00000040 D8 05 54 61 3E 00 fadd dword ptr ds:[003E6154h] 00000046 D8 05 58 61 3E 00 fadd dword ptr ds:[003E6158h] 0000004c D9 1D 58 61 3E 00 fstp dword ptr ds:[003E6158h] 这里我们可以看到,实时编译的代码已接近最佳状态。在 方法调用本节将探讨方法调用的开销和实现。测试主题是实现接口 列表 1:方法调用的测试方法 interface I { void
请参阅表 3。首先可以判断出,表中的方法可以是内联的(抽象不需要任何开销),也可以不是内联的(抽象的开销是整型操作的 5 倍还多)。静态调用、实例调用、虚拟调用和接口调用的原始开销看起来并没有什么大的差别。 表 3:方法调用的时间 (ns)
但是,这些结果是不具代表性的“最好情况”,是连续上百万次运行计时循环的结果。在这些测试示例中,虚拟方法和接口方法的调用位置都是单态的(例如,对于每个调用位置,目标方法不因时间而改变),因此,缓存的虚拟方法和接口方法的调度机制(方法表、接口映射指针和输入)再加上非常有预测性的分支预测,使得处理器可以调用这些用其他方法难以预测并与数据相关的分支来完成这项不切实际但却富有成效的工作。实际上,任何调度机制数据的数据缓存不命中或分支预测错误(可能是强制性的容量不命中或多态的调用位置),都可以在多个循环之后使虚拟调用和接口调用的速度减慢。 让我们进一步看一下这些方法调用的时间。 在第一个 inlined static call 示例中,我们调用了 为了测量 static method call 的大致开销,我们将 我们甚至不得不使用一个显式假谓词变量 JIT 编译器将像以前那样把死调用 (Dead Call) 消除到 内联的实例调用和常规实例调用的计时使用了相同的方法。但是,由于 C# 语言规范规定,对 Null 对象引用的任何调用都会抛出 NullReferenceException,因此每个调用位置都必须确保实例不为空。这可以通过解除实例引用的引用来实现。如果该实例确实是 Null,则会生成一个故障,并转变为此异常。 在反汇编 2 中,我们使用静态变量 时,编译器会提起签出循环的 Null 实例。 反汇编 2:使用 Null 实例“检查”的实例方法调用位置 t.i1(); 00000012 8B 0D 30 21 A4 05 mov ecx,dword ptr ds:[05A42130h] 00000018 39 09 cmp dword ptr [ecx],ecx 0000001a E8 C1 DE FF FF call FFFFDEE0 inlined this instance call 和 this
instance call 相同,只是此实例是 反汇编 3:this 实例方法调用位置 this.i1(); 00000012 8B CE mov ecx,esi 00000014 E8 AF FE FF FF call FFFFFEC8 “虚拟方法调用”的运行情况与传统的 C++ 实现类似。每个新引入的虚拟方法的地址都存储在类型方法表的新插槽中。每个导出类型的方法表都与其基本类型的方法表一致并有所扩展,并且所有虚拟方法替代都会使用导出类型的虚拟方法地址(在导出的类型方法表的相应插槽中)来替换基本类型的虚拟方法地址。 在调用位置,与实例调用相比,虚拟方法调用要进行两次额外的加载,一次是获取方法表地址(随时可以在
反汇编 4:虚拟方法调用位置 this.v1(); 00000012 8B CE mov ecx,esi 00000014 8B 01 mov eax,dword ptr [ecx] ; 获取方法表地址 00000016 FF 50 38 call dword ptr [eax+38h] ; 获取/调用方法地址 最后,讨论一下“接口方法调用”(反汇编 5)。在 C++ 中,没有等效的接口方法调用。任何给定的类型都可以实现任意数量的接口,并且每个接口在逻辑上都需要自己的方法表。要对接口方法进行调度,就要查找方法表、方法的接口映射、该映射中接口的入口,然后通过方法表中接口部分适当的入口进行调用。 反汇编 5:接口方法调用位置 i.itf1(); 00000012 8B 0D 34 21 A4 05 mov ecx,dword ptr ds:[05A42134h]; 实例地址 00000018 8B 01 mov eax,dword ptr [ecx] ; 方法表地址 0000001a 8B 40 0C mov eax,dword ptr [eax+0Ch] ; 接口映射地址 0000001d 8B 40 7C mov eax,dword ptr [eax+7Ch] ; 接口方法表地址 00000020 FF 10 call dword ptr [eax] ; 获取/调用方法地址 其余的原语计时,inst itf instance call、this itf instance call、inst itf virtual call 和 this itf virtual call,充分印证了这样一个观点:不论何时,导出类型的方法在实现接口方法时,都可以通过实例方法调用位置来保持可调用性。 例如,在 this itf instance call 测试中,通过实例(不是接口)引用来调用接口方法实现,结果接口方法被成功内联并且开销为 0 ns。甚至当您将接口方法作为实例方法进行调用时,接口方法实现都有可能被内联。 尚未实时编译的方法调用对于静态方法调用和实例方法调用(不是虚拟方法调用和接口方法调用),JIT 编译器会根据在目标方法的调用位置被实时编译时,目标方法是否已经被实时编译,从而在当前生成不同的方法调用序列。 如果被调用者(目标方法)还未被实时编译,编译器将通过已经用“prejit stub”初始化的指针来发出调用。对目标方法的第一个调用到达 stub 时,将触发方法的 JIT 编译,同时生成本机代码,并对指针进行更新以寻址新的本机代码。 如果被调用者已经过实时编译,其本机代码地址已知,则编译器将直接向其发出调用。 创建新对象创建新对象包括两个阶段:对象分配和对象初始化。 对于引用类型,对象被分配在可以进行内存回收的堆上。对于值类型,不管是以栈形式驻留在另一个引用类型或值类型中,还是嵌入到另一个引用类型或值类型中,值类型对象都与封闭结构有一些固定的差异,即不需要进行任何分配。 对典型的引用类型的小对象来说,堆分配的速度非常快。每次内存回收之后,除了固定的对象之外,第 0 代堆的活对象都将被压缩并被提升到第 1 代,因此,内存分配程序可以使用一个相当大的连续可用内存空间。大多数的对象分配只会引起指针的递增和边界检查,这要比典型的 C/C++ 释放列表分配程序(malloc/操作符 new)节省很多开销。垃圾回收器甚至会考虑计算机的缓存大小,以设法将第 0 代对象保留在缓存/内存层次结构中快速有效的位置。 由于首选的托管代码风格要求大多数分配的对象生存期很短,并且快速回收这些对象,所以我们还包含了这些新对象的内存回收的分期开销(在时间开销中)。 请注意,垃圾回收器不会为死对象浪费时间。如果一个对象是死的,GC 不会处理它,也不会回收它,甚至是根本就不考虑它。GC 只关注那些存活的对象。 (例外:可终结的死对象属于特殊情况。GC 会跟踪这些对象,并且专门将可终结的死对象提升到下一代,等待终结。这会花费很大的开销,而且在最坏的情况下,还会可传递地提升大的死对象图。因此,若非确实需要,请不要使对象成为可终结的。如果必须这样做,请考虑使用“清理模式”[Dispose
Pattern],并在可能时调用 当然,生存期短的大对象的分期 GC 开销要大于生存期短的小对象的开销。每次对象分配都使我们更接近下一个内存回收周期;而较大的对象比较小的对象达到得更早。但无论早晚,“算帐”的时刻终会到来。GC 周期(尤其第 0 代回收)的速度非常快,但不是不需要开销的,即使绝大多数新对象是死的也是如此:因为要查找(标记)活对象,需要先暂停线程,然后查找栈和其他数据结构,以将根对象引用回收到堆中。 (也许更为重要的是,只有极少的大对象能够适应小对象所利用的缓存数量。缓存不命中的影响很容易超过代码路径长度的影响。) 一旦为对象分配了空间,空间就将保留下来以初始化对象(构造对象)。CLR 可以保证,所有的对象引用都预先初始化为 Null,所有的原始标量类型都初始化为 0、0.0、False 等。(因此没有必要在用户定义的构造函数中进行多余的初始化。当然,不必担心。但请注意,当前不必使用 JIT 编译器优化掉冗余的存储。) 除了消除实例字段外,CLR 还初始化(仅引用类型)对象的内部实现字段:方法表指针和对象标头词。而后者要优先于方法表指针。数组也获得一个 Length 字段,对象数组获得 Length 和元素类型字段。 然后,CLR 调用对象的构造函数(如果有的话)。每种类型的构造函数,不管是用户定义的还是编译器生成的,都是首先调用其基本类型的构造函数,然后运行用户定义的初始化操作(如果有的话)。 从理论上讲,这样做对于深度继承方案来说可能会花费比较大的开销。如果 E 扩展 D 扩展 C 扩展 B 扩展 A(扩展 System.Object),那么初始化 E 将导致五次方法调用。实际上,情况并没有这么糟糕,因为编译器会内联掉对空的基本类型构造函数的调用(使其不存在)。 参考表 4 的第一列时会发现,我们可以创建和初始化一个结构 表 4:值类型和引用类型对象的创建时间 (ns)
反汇编 6:值类型对象的构造 A a1 = new A(); ++a1.a;
00000020 C7 45 FC 00 00 00 00 mov dword ptr [ebp-4],0
00000027 FF 45 FC inc dword ptr [ebp-4]
C c1 = new C(); ++c1.c;
00000024 8D 7D F4 lea edi,[ebp-0Ch]
00000027 33 C0 xor eax,eax
00000029 AB stos dword ptr [edi]
0000002a AB stos dword ptr [edi]
0000002b AB stos dword ptr [edi]
0000002c FF 45 FC inc dword ptr [ebp-4]
E e1 = new E(); ++e1.e;
00000026 8D 7D EC lea edi,[ebp-14h]
00000029 33 C0 xor eax,eax
0000002b 8D 48 05 lea ecx,[eax+5]
0000002e F3 AB rep stos dword ptr [edi]
00000030 FF 45 FC inc dword ptr [ebp-4]
另外的五个计时(new reftype L1、……、new reftype L5)针对引用类型
public class A { int a; }
public class B : A { int b; }
public class C : B { int c; }
public class D : C { int d; }
public class E : D { int e; }
将引用类型的时间与值类型的时间进行比较,我们会发现,对于每个实例,其分配和释放的分期开销在测试计算机上大约为 20 ns(是整型加法运算时间的 20 倍)。这个速度非常快,也就是说,一秒钟可以分配、初始化和回收大约 5 千万个生存期很短的对象,而且这种速度可以保持不变。对于像五个字段一样小的对象,分配和回收的时间仅占对象创建时间的一半。请参阅反汇编 7。 反汇编 7:引用类型对象的构造 new A();
0000000f B9 D0 72 3E 00 mov ecx,3E72D0h
00000014 E8 9F CC 6C F9 call F96CCCB8
new C();
0000000f B9 B0 73 3E 00 mov ecx,3E73B0h
00000014 E8 A7 CB 6C F9 call F96CCBC0
new E();
0000000f B9 90 74 3E 00 mov ecx,3E7490h
00000014 E8 AF CA 6C F9 call F96CCAC8
最后三组五个计时说明了这种继承类构造方案的变化情况。
编译器将每组嵌套的基类构造函数调用内联到 反汇编 8:深度内联的继承构造函数 new A();
00000012 B9 A0 77 3E 00 mov ecx,3E77A0h
00000017 E8 C4 C7 6C F9 call F96CC7E0
0000001c C7 40 04 01 00 00 00 mov dword ptr [eax+4],1
new C();
00000012 B9 80 78 3E 00 mov ecx,3E7880h
00000017 E8 14 C6 6C F9 call F96CC630
0000001c C7 40 04 01 00 00 00 mov dword ptr [eax+4],1
00000023 C7 40 08 01 00 00 00 mov dword ptr [eax+8],1
0000002a C7 40 0C 01 00 00 00 mov dword ptr [eax+0Ch],1
new E();
00000012 B9 60 79 3E 00 mov ecx,3E7960h
00000017 E8 84 C3 6C F9 call F96CC3A0
0000001c C7 40 04 01 00 00 00 mov dword ptr [eax+4],1
00000023 C7 40 08 01 00 00 00 mov dword ptr [eax+8],1
0000002a C7 40 0C 01 00 00 00 mov dword ptr [eax+0Ch],1
00000031 C7 40 10 01 00 00 00 mov dword ptr [eax+10h],1
00000038 C7 40 14 01 00 00 00 mov dword ptr [eax+14h],1
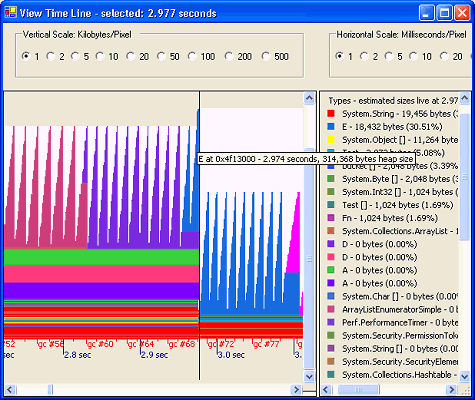
表 4 中的最后五个计时显示了调用嵌套的基本构造函数时所需的额外系统开销。 中间程序:CLR 分析器(CLR Profiler)演示现在来简单演示一下 CLR 分析器。CLR 分析器(旧称“分配分析器”)使用 CLR 分析 API 在应用程序运行时收集事件数据,特别是调用、返回以及对象分配和内存回收事件。(CLR 分析器是一种“侵害性”的分析器,即它会严重地减慢被分析的应用程序的运行速度。)收集事件之后,您可以使用 CLR 分析器来检查应用程序的内存分配和 GC 行为,包括分层调用图和内存分配模式之间的交互。 CLR 分析器之所以值得学习,是因为对许多“面临性能挑战的”托管代码应用程序来说,了解数据分配配置文件可以使您获得很关键的认知,从而减少工作集并由此而开发出快速、价廉的组件和应用程序。 CLR 分析器还可以揭示哪些方法分配的存储比您预期的多,并可以发现您不小心保留的对无用对象图的引用,而这些引用原本可能会由 GC 回收。(一种常见的问题设计模式是项目的软件缓存或查找表已不再需要,或者对以后的重建是安全的。当缓存使对象图的生存期超出其有用寿命时,情况将非常糟糕。因此,务必解除对不再需要的对象的引用。) 图 1 是在执行计时测试驱动程序时堆的时间线图。锯齿状图案表示对象
图 1:CLR 分析器时间线图 注意,对象越大(E 大于 D,D 大于 C),第 0 代堆充满的速度就越快,GC 周期就越频繁。 类型转换和实例类型检查要使托管代码安全、可靠、“可验证”,必须保证类型安全。如果可以将一个对象的类型转换为其他类型,就很容易危及 CLR 的完整性,并因此而使其被不可信的代码支配。 表 5:类型转换和 isinst 时间 (ns)
表 5 显示了这些强制性类型检查的系统开销。从导出类型转换到基本类型总是安全的,而且也是不需要开销的,而从基本类型转换到导出类型则必须经过类型检查。 (已检查的)类型转换将对象引用转换为目标类型,或者抛出 相反,
如果 列表 2 是一个类型转换的计时循环,反汇编 9 显示了向下转换为导出类型的生成代码。为执行类型转换,编译器直接调用 Helper 例程。 列表 2:测试类型转换计时的循环 public static void castUp2Down1(int n) {
A ac = c; B bd = d; C ce = e; D df = f;
B bac = null; C cbd = null; D dce = null; E edf = null;
for (n /= 8; --n >= 0; ) {
bac = (B)ac; cbd = ©bd; dce = (D)ce; edf = (E)df;
bac = (B)ac; cbd = ©bd; dce = (D)ce; edf = (E)df;
}
}
反汇编 9:向下类型转换 bac = (B)ac; 0000002e 8B D5 mov edx,ebp 00000030 B9 40 73 3E 00 mov ecx,3E7340h 00000035 E8 32 A7 4E 72 call 724EA76C 属性在托管代码中,属性是一对方法,即一个属性获取方法和一个属性设置方法,类似于对象的字段。get_ 方法获取属性,set_ 方法将属性更新为新的值。 除此之外,属性的行为和开销与常规的实例方法、虚拟方法的行为和开销非常相像。如果使用一个属性来获取或存储一个实例字段,通常是以内联方式进行,这与小方法相同。 表 6 显示了获取(和添加)并存储一组整数实例字段和属性所需的时间。获取或设置属性的开销实际上与直接访问基本字段相同,除非将属性声明为虚拟的。如果声明为虚拟的,则开销基本上就是虚拟方法调用的开销。这没什么可奇怪的。 表 6:字段和属性时间 (ns)
写屏障(Write Barrier)CLR 垃圾回收器充分利用“代假设”(即“多数新对象的生存期很短”)来最大限度地减少回收的系统开销。 堆在逻辑上被划分为几个代。最新的对象存储在第 0 代,这些对象尚未经过回收。在第 0 代回收期间,GC 确定从 GC 根集可以到达哪些第 0 代对象(如果有的话),这其中包括计算机寄存器中、栈上、类静态字段对象引用中的对象引用。能够以传递方式到达的对象是“存活的”,并被提升(复制)到第 1 代。 由于总的堆大小可能是数百 MB,而第 0 代堆大小可能只有 256 KB,因此限制 GC 对象图对第 0 代堆的跟踪范围是一项优化,对于实现 CLR 的非常短暂的回收暂停时间极为重要。 但是,可以将一个第 0 代对象的引用存储在第 1 代或第 2 代对象的对象引用字段中。因为我们不在第 0 代回收期间扫描第 1 代或第 2 代对象,所以如果此引用是对给定的第 0 代对象的唯一引用,则该对象可能会被 GC 误回收。我们不能允许发生这种情况! 相反,对堆中所有对象引用字段进行的所有存储都会导致“写屏障”(Write Barrier)。这是一种高效记录代码,可以记录新代对象引用到旧代对象的字段的存储情况。此类旧对象引用字段被添加到后续 GC 的 GC 根集中。 “各对象引用字段存储”写屏障的系统开销与简单的方法调用的开销基本相等(表 7)。这是一项新的开销,本机 C/C++ 代码中没有提供。但由于能够大幅提高对象分配和 GC 的速度,并充分利用自动内存管理来提高工作效率,因此这种开销通常还是很值得的。 表 7:写屏障时间 (ns)
在衔接紧密的内层循环中,写屏障的开销比较大。可以预见,在未来几年中,会出现可以减少写屏障数目和总分期开销的先进编译技术。 您可能会认为,写屏障只在存储引用类型的对象引用字段时才是必需的。但是,在一个值类型方法中,存储对象引用字段(如果有的话)同样会受到写屏障的保护。这是必需的,因为有时值类型本身可能会嵌入到驻留在堆中的引用类型中。 数组元素访问要诊断和排除数组超出边界的错误和堆的损坏,并保护 CLR 本身的完整性,必须在加载和存储数组元素时进行边界检查,以确保索引在间隔
[0,array.Length-1] 包含或抛出的 我们的测试测量了加载或存储 表 8:数组访问时间 (ns)
边界检查需要将数组索引与隐式的 array.Length 字段进行对比。如反汇编 10 所示,我们只利用两条指令来检查索引是否既不小于 0、也不大于或等于 array.Length。如果索引在此范围内,我们将转到一个抛出异常的行序列。这也适用于对象数组元素的加载,以及在 int 和其他简单值类型数组中的存储。(由于内层循环稍有不同,Load obj array elem 的速度稍有点缓慢。) 反汇编 10:加载 int 数组元素 ; i in ecx, a in edx, sum in edi
JIT 编译器通常通过对代码质量的优化,来消除冗余的边界检查。 回忆一下前面几节,我们可以认为“对象数组元素存储”的开销会大得多。要将对象引用存储到一个对象引用的数组中,运行时必须:
此代码序列相当长。编译器并未在各个对象的数组存储位置发出调用,而是对共享的 Helper 函数发出调用,如反汇编 11 所示。此调用(再加上这三项操作)说明了为何此示例中会出现附加时间。 反汇编 11:存储对象数组元素 ; objarray in edi
; obj in ebx
装箱 (Boxing) 和拆箱 (Unboxing)综合利用 .NET 编译器和 CLR,可以将值类型(包括原始类型,例如 int [System.Int32])作为引用类型使用,即作为对象引用进行寻址。这样一来,就可以将值类型作为对象传递到方法、作为对象存储在集合中,等等。 对值类型进行“装箱”就是创建一个包含其值类型的副本的引用类型对象。从概念上讲,这就相当于创建一个类,而这个类具有与值类型相同的未命名实例字段。 对已装箱的值类型进行“拆箱”就是将值从对象复制到值类型的新实例中。 如表 9 所示(与表 4 比较),装箱 int 以及以后对其进行内存回收所需的分期时间与实例化包含一个 int 字段的小型类所需的时间大致相同。 表 9:装箱和拆箱 int 的时间 (ns)
要对已装箱的 int 对象进行拆箱,需要将类型明确转换为 int。这将被编译为对象的类型(由其方法表地址表示)与装箱的 int 方法表地址的比较。如果它们相等,值就被从对象中复制出去。否则,就会抛出异常。请参阅反汇编 12。 反汇编 12:装箱和拆箱 int box object o = 0; 0000001a B9 08 07 B9 79 mov ecx,79B90708h 0000001f E8 E4 A5 6C F9 call F96CA608 00000024 8B D0 mov edx,eax 00000026 C7 42 04 00 00 00 00 mov dword ptr [edx+4],0 unbox sum += (int)o; 00000041 81 3E 08 07 B9 79 cmp dword ptr [esi],79B90708h ; "type == typeof(int)"? 00000047 74 0C je 00000055 00000049 8B D6 mov edx,esi 0000004b B9 08 07 B9 79 mov ecx,79B90708h 00000050 E8 A9 BB 4E 72 call 724EBBFE ; 否,抛出异常 00000055 8D 46 04 lea eax,[esi+4] 00000058 3B 08 cmp ecx,dword ptr [eax] 0000005a 03 38 add edi,dword ptr [eax] ; 是,获取 int 字段 委托 (Delegate)在 C 中,函数指针是一种逐字存储函数地址的原始数据类型。 C++ 中添加了成员函数的指针。成员函数的指针 (PMF) 代表一个延迟的成员函数调用。非虚拟成员函数的地址可以是一个简单的代码地址,而虚拟成员函数的地址则必须包含一个特殊的虚拟成员函数调用,对这样的 PMF 解除引用就是虚拟的函数调用。 要解除 C++ PMF 的引用,您必须提供一个实例: A* pa = new A;
void (A::*pmf)() = &A::af;
(
几年前,在 Visual C++ 编译器开发组工作的时候,我们常常问自己:表达式 返回到托管代码领域,委托对象与此(潜在的方法调用)类似。委托对象代表要调用的方法和要调用的实例,或者对于静态方法来说,就是要调用的静态方法。 (正如我们的文档所述:委托声明定义了一种使用特定签名来封装方法的引用类型。委托实例封装了静态或实例方法。委托大致与 C++ 中的函数指针类似,但是,委托是类型安全的和可靠的。) C# 中的委托类型是 MulticastDelegate 的导出类型。此类型提供了丰富的语义,包括可以构建在调用委托时要调用的 (object,method) 对的调用列表。 委托还提供一种进行异步方法调用的功能。定义委托类型并实例化委托类型之后(通过潜在的方法调用初始化),您可以通过
所有这些丰富的语义的开销都很大。比较表 10 和表 3,可以发现委托调用比方法调用大约慢八倍。希望以后会有所改进。 表 10:委托调用的时间 (ns)
关于缓存不命中、页面错误和计算机结构回顾“过去那些美好的日子”,大约是在 1983 年吧,处理器的速度很慢(大约 50 万条指令/秒),相对而言,RAM 的速度非常快但是较小(256 KB 的 DRAM 的访问时间大约为 300 ns),磁盘很慢而且很大(10 MB 的磁盘的访问时间大约为 25 ms)。PC 微处理器采用标量的 CISC,大多数的浮点运算都在软件中进行,而且没有缓存。 在“摩尔定律”提出二十年后,大约在 2003 年,处理器已经相当快了(3 GHz 的处理器每个周期可以发出最多三项操作),相对而言,RAM 则变得非常慢(512 MB 的 DRAM 的访问时间大约为 100 ns),磁盘已显得“极其”缓慢而“巨大”(100 GB 的磁盘的访问时间大约为 10 ms)。现在的 PC 微处理器采用无序数据流、超标量、超线程、跟踪缓存的 RISC(运行解码的 CISC 指令),而且有多级缓存,例如,某些服务器专用的微处理器有 32 KB 的一级数据缓存(可能是 2 次滞后时间周期)、512 KB 的二级数据缓存和 2 MB 的三级数据缓存(可能是 12 次滞后时间周期),所有这些缓存都在芯片上。 在过去的好日子里,您可以计算所编写的代码的字节数,计算代码运行所需的周期数。加载或存储需要的周期数大约与添加所需的周期数相等。现代处理器在多个功能单元中使用分支预测、推测和无序(数据流)执行来查找指令级的并行计算,因此可以同时进行多个计算过程。 现在,最快的 PC 每微秒可以发出多达 9000 项左右的操作,但同是在一微秒内,只能将大约 10 个缓存行加载或存储到 DRAM。在计算机结构领域,这被称为“撞内存墙”。缓存隐藏了内存滞后时间,但只隐藏到某个点。如果代码或数据不适应缓存,和/或显示出很差的引用位置,那么我们那架每微秒 9000 项操作的“超音速喷气机”就会退化为每微秒只有 10 次加载的“三轮车”。 而且,(请不要让这种情况发生在您身上),如果程序的工作集超出可用的物理 RAM,并且程序在一开始就出现硬页面错误,那么,在每个 10,000 微秒的页面错误服务(磁盘访问)中,我们就会丧失为用户提供多达“9000 万”项操作的机会。这实在太可怕了,因此我相信,从今天开始您会认真测量您的工作集 (vadump) 并使用像 CLR 分析器这样的工具,来消除不必要的分配和无意的对象图保持。 但是,所有这一切与了解托管代码原语的开销有什么关系呢?关系重大。 回忆一下表 1,即托管代码原语时间的综合列表,其中的数据是在 1.1 GHz P-III 上测量得到的。这些数据表明,每一个时间,甚至是使用五级显式构造函数调用分配、初始化和回收一个五字段对象的分期开销,都比访问一次 DRAM 要“快”。哪怕仅仅是一次未使用所有级别的芯片缓存的加载,都比一次托管代码的操作需要的时间长。 因此,如果您关心代码的速度,那么在设计和实现算法、数据结构时就必须考虑和测量缓存/内存的层次结构。 现在我们看一个简单的示例:是对一个 int 数组求和快,还是对一个等价的 int 链接列表求和快?哪种情况快、快多少、为何快? 您可以考虑一会儿。对于像 int 这样的小项目,每个数组元素所占用的内存空间是链接列表元素所占用空间的四分之一。(每个连接列表节点都有两个单词的对象系统开销和两个单词的字段 [下一个链接和 int 项目]。)这将危害缓存的利用。因此数组方法会更好一些。 但是,数组遍历可能会导致对每个项目进行数组边界检查。您前面已经看到,边界检查需要占用一点时间。也许这有利于链接列表? 反汇编 13:对 int 数组求和与对 int 链接列表求和 sum int array: sum += a[i];
00000024 3B 4A 04 cmp ecx,dword ptr [edx+4] ; 边界检查
00000027 73 19 jae 00000042
00000029 03 7C 8A 08 add edi,dword ptr [edx+ecx*4+8] ; 加载数组元素
for (int i = 0; i < m; i++)
0000002d 41 inc ecx
0000002e 3B CE cmp ecx,esi
00000030 7C F2 jl 00000024
sum int linked list: sum += l.item; l = l.next;
0000002a 03 70 08 add esi,dword ptr [eax+8]
0000002d 8B 40 04 mov eax,dword ptr [eax+4]
sum += l.item; l = l.next;
00000030 03 70 08 add esi,dword ptr [eax+8]
00000033 8B 40 04 mov eax,dword ptr [eax+4]
sum += l.item; l = l.next;
00000036 03 70 08 add esi,dword ptr [eax+8]
00000039 8B 40 04 mov eax,dword ptr [eax+4]
sum += l.item; l = l.next;
0000003c 03 70 08 add esi,dword ptr [eax+8]
0000003f 8B 40 04 mov eax,dword ptr [eax+4]
for (m /= 4; --m >= 0; ) {
00000042 49 dec ecx
00000043 85 C9 test ecx,ecx
00000045 79 E3 jns 0000002A
参阅反汇编 13 后,我开始支持链接列表遍历,并将该遍历展开四次,甚至删除了通常的 Null 指针列表结尾检查。数组循环中的每个项目需要六条指令,而链接列表循环中的每个项目只需要 11/4 = 2.75 条指令。现在,您认为哪个更快? 测试条件:首先,创建一个包含 100 万个 int 的数组和一个包含 100 万个 int(1 M 列表节点)的简单传统链接列表。然后,计算将前 1,000 个、10,000 个、100,000 个以及 1,000,000 个项目加起来所需的时间。每个重复循环多次,测量每个示例中最佳的缓存行为。 哪个更快?请您想一想,答案是:表 1 中的最后八个条目。 真有意思!随着引用数据的大小超过连续缓存大小,时间也变得相当慢。数组版本始终要比链接列表版本快,即使执行两倍指令也是如此,而在执行 100,000 个项目时,数组版本要快七倍! 为什么是这样?首先,只有很少的链接列表项目能够适应任何给定的缓存级。所有这些对象标头和链接都是在浪费空间。其次,现代的无序数据流处理器可以迅速提高速度,以同时处理数组中的多个项目。相比之下,对于链接列表,如果当前列表节点不在缓存中,处理器就无法开始获取指向当前节点之后的节点的链接。 在 100,000 个项目的示例中,处理器要花费全部时间的(平均)大约 (22-3.5)/22 = 84%,来等待从 DRAM 读取某个列表节点的缓存行。这听起来很糟糕,但实际情况可能会比这更糟糕。由于链接列表项目较小,因此其中的许多项目可以适应缓存行。由于我们按分配的顺序遍历列表,而且由于内存回收器即使在将死对象压在堆之外时也保持分配顺序,因此很可能在获取缓存行上的一个节点之后,接下来的多个节点可能也已在缓存中。如果节点更大,或者如果列表节点以随机地址顺序排列,则访问的每个节点可能刚好是完全缓存不命中。向每个列表节点添加 16 个字节会使每个项目的遍历时间增加一倍,达到 43 ns;添加 32 字节,达到 67 ns;添加 64 字节会再增加一倍,使每个项目的时间达到 146 ns,这很可能是测试计算机上的平均 DRAM 滞后时间。 那么应该从中吸取什么教训呢?是不是避免使用 100,000 个节点的链接列表?不是的。教训是,在考虑托管代码的低级效率时,缓存影响是比本机代码更为关键的因素。如果您编写的托管代码对性能的要求很高,尤其是管理大型数据结构的代码,请牢记缓存影响,认真考虑您的数据结构访问模式,努力减少数据占用的空间并实现良好的引用位置 (Locality of Reference)。 顺便说一句,存在这样的趋势:随着时间推移,内存墙、DRAM 访问时间与 CPU 操作时间的比率将继续恶化。 下面是一些“重视缓存设计”的经验法则:
DIY 时间实验在本文的计时测量实验中,我使用了 Win32 高分辨率性能计数器 通过 P/Invoke,可以容易地调用这些性能计数器: [System.Runtime.InteropServices.DllImport("KERNEL32")]
private static extern bool QueryPerformanceCounter(
ref long lpPerformanceCount);
[System.Runtime.InteropServices.DllImport("KERNEL32")]
private static extern bool QueryPerformanceFrequency(
ref long lpFrequency);
在计时循环之前和之后分别调用 由于空间和时间限制,我们没有涉及锁定、异常处理或代码访问安全系统。读者可以在自己的练习中考虑这些因素。 另外,我使用了 VS.NET 2003 中的“反汇编”(Disassembly) 窗口来得到文中的反汇编。但是,这其中也包含一个小技巧。如果在 VS.NET 调试程序中运行应用程序,即使是在“发布”(Release) 模式中构建的优化可执行程序,在“调试模式”下运行时,其中的优化如内联等也将被禁用。我找到的查看 JIT 编译器发出的优化本机代码的唯一方法,是在调试程序“外部”启动测试应用程序,然后再使用 Debug.Processes.Attach 将其附加到调试程序。 一个空间开销模型?篇幅有限,本文将不对空间问题做详细论述,只简单介绍一下。 基本考虑(有些是 C# [默认的 TypeAttributes.SequentialLayout] 和 x86 专用的):
宏观考虑:
反射 (Reflection)有这样一种说法:“如果您要知道‘反射’的开销是多少,您可能根本负担不起。”如果您深入阅读了本文,您就知道了解开销情况以及测量这些开销有多么重要。 反射很有用而且功能强大,但与实时编译的本机代码相比,它既不显得快,也不够精炼。我已经提醒过您了。请亲自测量。 小结现在,您(或多或少地)从最根本上了解了托管代码的开销情况。您也获得了一些基本知识,帮助您在权衡实现方案时做出更明智的决策,编写更快的托管代码。 我们已经了解到实时编译的托管代码可以像本机代码一样放心使用。您的挑战是,明智地编码,在 Framework 的众多丰富、易用的功能之间做出明智的选择。 性能在某些环境下无关紧要,而且另一些环境下却是产品的最重要特性。过早的优化是一切问题的根源。但是,不重视效率也会导致同样的结果。您是专业人士,是艺术家,是能工巧将。那么,您一定要知道事物的开销。如果您不知道或即使您认为自己知道,也要经常进行测量。 至于 CLR 工作组,我们将继续努力提供一个“比本机代码工作效率更高”且“比本机代码更快”的平台。希望情况会越来越好。请继续关注我们的工作。 记住您的诺言。 资源
|