请求-响应
基于 Web 的用户和应用程序服务器之间的交互遵循使用 HTTP 协议的原始 Web 模型。这意味着我们要受上面简要描述过的请求-响应模型的约束。
为了便于进行该通信,引入了新的 Java 类。用于处理该通信的主类就是 HttpServlet 类。该类包含了一组与
HTTP 协议相匹配的方法,其中获得请求内容的方法是 doGet() 和 doPost()。
HTTP 协议要么通过在 URL 中放置参数来向 Web 服务器传递信息,要么独立于 URL 传递信息。第一种称作
GET 命令,而第二种称作 POST 命令。GET 命令的优点是,URL 包含了检索请求信息所需的所有信息。因此,可将其加入书签以便将来重新调用。而
POST 命令独立于 URL 发送附加信息,提供了更好的安全性。当需要发送比较大量的信息时,该方法也更为合适。其缺点就是不能被加入书签。
doGet() 和 doPost() 接收两个参数:HttpServletRequest 请求和 HttpServletResponse
响应。这些附加类为您提供了需要从请求中获得的所有信息。您将使用响应参数来编写应答。已提供的方法可以满足您完成该应答所需的所有功能。
浏览器和应用程序服务器之间的一切交互都是通过 HttpServlet 类完成的。您得花些时间去学习上述类中所包含的字段和方法。
模型-视图-控制器
J2EE 建议使用 MVC 开发模型。该模型背后的思想是:尽可能地将与用户的交互、处理以及数据访问分离开。该模型已经活跃了很长一段时间。我记得它最早出现在
20 世纪 80 年代的 Smalltalk 语言中。
图 3 说明了该模型与 J2EE 组件的使用。应用程序首先发出一个 JSP(视图)请求,而 JSP 稍后将返回一个在浏览器中显示的页面。接着,用户选择一个动作,向
servlet(控制器)发送信息。再由 servlet 来决定必须完成什么操作,它可能需要检索一个 Java bean(模型)或
EJB 来提供数据访问。然后,servlet 可以向 JSP 传递一个对 Java bean 的引用,以便访问要格式化和显示的数据。
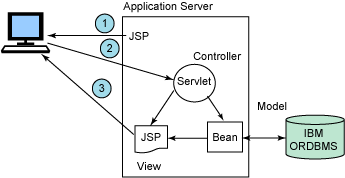
图 3. MVC 模型
Enterprise Java Beans(EJB) EJB 体系结构提供了开发分布式应用程序的标准模型。一个
EJB 包含两个接口:Home 和 Remote。home 接口用于创建或查找指定类型的对象。remote 接口是通过
home 接口检索得到的,为您提供了对远程对象的公共方法的访问。
EJB 有三种类型:会话(session)、消息(message)和实体(entity)。会话 bean 提供对业务过程的访问。它们分为两种类型:有状态的和无状态的。有状态会话
bean 保存特定客户机调用之间的信息。无状态会话 bean 可以被多个客户机共享,因为它不保存调用之间的任何特定信息。
消息 bean 是一种无状态的 bean,提供了用于操纵 JMS 异步消息的业务过程。实体 bean 代表业务数据及其相关的操纵逻辑。该业务数据必须保存在持久性存储器(例如,一个数据库)中。EJB
是通过部署描述符进行分布的,部署描述符包括事务属性、安全性授权和持久性等信息。
面向对象方法(OOA)面向对象(Object Orientation)改进了软件的开发,它也是 J2EE 环境中的关键部分。OO
的关键包括数据封装和继承的概念。
面向对象支持层次结构方法。我们可以看到对象继承层次结构和对象组合层次结构。图 4 通过部分医学数字图像和通信(Digital
Imaging and Communications in Medicine,DICOM)标准,说明了这两种类型的层次结构。
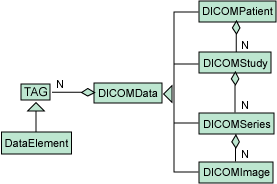
图 4. DICOM 层次结构
一个 Data 对象(DICOMData)可以特殊化为以下四种对象中的一种:patient、study、series
或 image。而在图 4 所展示的另一层次结构中,则可以将 TAG 对象特殊化为 DataElement。这些类型的继承在
OO 分析、设计和编程中极为普遍。仅仅查看 Java 类就可以看到一组精巧的对象继承层次结构。
图 4 还展示了聚集/组合示例,包括组合层次结构中的多个层次:我们看到,一个 Patient 可以包含多个 study,而一个
study 可以包含多个 series,而一个 series 又可以包含多个 image。我们还看到所有这些对象都可以包含多个
TAG/DataElement,因为该组合是在对象继承层次结构的父类(DICOMData)中表示的。
聚集/组合模型使对象之间不太明显的区别变得有意义。阅读 OO 文献时会发现,在多数商业应用程序中,具有频繁搜索并直接操纵的“第一级”对象,以及仅通过第一级对象来访问“第二级”对象
―― 如果您不检索第一级对象,就永远无法获得第二级对象。30 年前,这种典型的层次结构模型主导了数据库模型。我们将在后面的小节中进一步讨论它所带来的优点和缺点。
OO 中另一个有趣的主题就是对象持久性。实际上,OO 文献整个都在讨论对象,以及它作为内存中的对象与其他对象的交互。另一方面,持久性似乎是个很麻烦的问题。主要问题就是“持久保存对象”。数据库服务器除了在必要时恢复对象之外,不会添加值。这就是为何“阻抗失谐”问题对于许多
OO 人员来说显得如此重要的部分原因。
J2EE 持久性模型
在谈论 J2EE 环境中的持久性时,我们很可能要涉及实体 bean。J2EE 环境为实体 bean 提供了两种持久性模式:bean
管理和容器管理。Bean 管理的持久性将所有的工作交给 EJB 开发人员,让他们确定如何存储和检索特定的对象类型。
容器管理的持久性从 EJB 的实现中去除了持久性的细节。部署描述符中包含的抽象模式定义了实体 bean 的持久性字段,以及它与其他
bean 之间的关系。这一工作是通过 EJB QL 语言完成的,该语言是 SQL 92 标准的一个子集。
在创建一个实体 bean 时,容器管理的持久性会将其信息保存在数据库中。每当一个方法调用修改该 bean 的内容时,这些修改就必须在数据库中加以反映。当然,这也要考虑目标实体
bean 的事务属性。
J2EE 试图让对象持久性尽可能地简单、透明和自动。在此过程中,它希望使持久性尽量独立于所有的数据库产品,而无需考虑使用何种类型的数据库或持久存储器。因此,数据库被降级为简单的持久性存储设备。
IBM 的对象-关系数据库
IBM 提供了两种最新型的对象-关系数据库:DB2? Universal Database(UDB)和 Informix
Dynamic Server(IDS)。这两种都是关系型的数据库,因而包含了关系模型及其集合处理的长处。它们还包含了对象的概念,并且可以扩展数据库服务器的功能,更好地配合您的业务模型。而数据库服务器则是一个用于处理业务数据的可扩展性的架构。这些可扩展性特性与
J2EE 环境中的概念一致,因为 J2EE 确实是一个可扩展的应用架构。
这些数据库产品在数据库市场中处于领导地位。要了解这些产品是如何崛起的,我们必须先看一看关系数据库为何成为了该行业的主导。在关系数据库出现之前,占主导地位的各种数据库都是按照层次结构来组织的。这应用了“分而治之”的概念。
从层次结构的顶层开始,您要选择一个指定节点来表示一个容器对象,如区域或部门,其中包含的是您数据库中所有数据的一个子集。该对象有可能包含成员。然后,您可以通过该节点的成员指针来选择另一个子集。该过程可以一直进行到您找到了需要操作的指定元素为止。除了可以添加、删除或修改元素之外,您还可以通过操纵指向元素或节点的指针,将元素移动到该层次结构中的另一位置上。
层次型数据库具有两大优点:
它们是系统开销最小的轻量级数据库,因为它们仅仅返回应用程序所请求的节点和成员指针。它们快速地将数据分成较小部分以获得所需的记录。另外,它们还具有一些可改善性能的特点:
针对单个问题的优化:本质上,层次数据库就通过一条指定的路径来优化数据访问。例如,一家大型银行可能按区域、部门和帐户来划分单元。那么,就可以极其高效地找到属于已知部门和区域的指定帐户,或者按区域和部门制作报表或进行分析。但是,要为某个指定客户找到所有帐户就比较困难了,因为该客户可能有多个过去创建的帐户。而且,该客户可能经历过多次职位和住所的改动,从而会拥有多个部门和多个区域中的帐户。
大多数公司都要通过他们的数据来解决多重问题。如果遵循层次模型,他们可以很好地解决某一个问题。而其他问题的解决则可能比较糟糕。为了取得相当好的性能,可能需要在多个层次中复制数据,从而可能极大地增加数据管理的复杂性。
对于物理记录的处理:层次数据库中所存储的记录是由应用程序来直接操纵的。应用程序必须知道每个字段的次序和类型,因为它必须计算该字段在记录中的偏移量。修改了记录结构就需要修改访问这些记录的应用程序。以编程方式实现对象的重定位:该指针操纵为复制和悬空指针(dangling
pointer)等问题的发生制造了机会。
总的来说,层次模型在某些特定的应用程序中是一种极为可行的模型,IBM IMS 产品的长久生命力就证明了这一点。关系型数据库已经超越了持久性存储设备的角色,它们还解决了上述层次数据库的两个缺点。关系型数据库的主要特点有:
扁平的层次结构(Flattened hierarchy):关系数据库以表的形式来表示数据。所有的表都处于同一层次。这意味着所有的数据都可以直接进行访问。再回过头来看上文中的银行示例,我们可以直接访问所有帐户,并且找到属于指定客户的记录,而不必管其帐户属于哪个部门或区域。
逻辑记录:表中的列是通过列名而非记录偏移量来访问的。操作中只会使用指定的列。这样一来,应用程序可以独立于数据库中的列号以及各列次序。可以对表进行修改以添加新的列,且无需修改任何应用程序。这一概念随着视图(VIEW)的使用得到了深化,视图是一种由一个或多个表的子集所构建的虚表(virtual
table)。您可以将视图的概念与对象接口等同起来。只要接口保持不变,使用该接口的应用程序就不需要进行修改。 集合操作:不是简单地检索特定记录并返回给应用程序,关系型数据库具有操作数据的功能。这些功能包括排序、分组、聚集以及一个操作不同数据类型的大型函数集。
非过程化的查询语言:关系型数据库包括一种称作结构化查询语言(Structured Query Language,SQL)的数据操作语言。这将允许用户或应用程序开发人员描述需要操作哪些数据,而不是描述如何获得该数据。然后,数据库系统必须确定如何实现该请求。优化器使用表大小、索引可用性以及数据分布等信息来确定响应该查询的最佳路径。
关系数据库还包括事务 ACID 属性(原子性、一致性、独立性、持久性)。关系数据库中陆续添加了约束、存储过程、备份/恢复、复制等功能。
IBM 在继续改进它的 ORDBMS。总的方向包括性能、可用性、可伸缩性、可管理性、开发生产率、集成信息以及商业智能。通过数据联邦和自主计算(autonomic
computing),在信息集成和随需应变计算方面取得了较大突破。IBM 的产品中已经包含了其中的某些功能,不久,还会出现更多功能来简化数据管理。
ORDBMS 的“OR”部分是什么呢?它是关系数据库的可扩展性部分。我们一旦在概念上完成这一飞跃,就会了解数据库的可扩展性是关系数据库的自然演变的一部分。
很早以前,关系数据库就包含了有限的可扩展功能。诸如约束、存储过程等功能都是可扩展性的一种形式。DB2 UDB 还包含了允许系统和数据库管理员设计部分处理的“用户出口”。存储过程难道还不足够吗?不。它们是为了在数据库返回数据之后应用过程化处理而设计的。其好处在于限制数据库与应用程序之间的数据传送。存储过程并未集成在数据库引擎中,因为它们被设计为以过程化的方式一次处理一条记录。我们还必须区别存储过程和存储过程语言。
DB2 支持用户用 SQL、Cobol、“C”和 Java 等语言编写存储过程。IBM-IDS 包含了一种存储过程语言,同时也支持用“C”和
Java 编写的存储过程。这些语言的使用已经扩展到了关系模型中。除了通过编写过程,在数据库服务器完成其处理之后操作数据,我们还可以将该处理包含在数据库系统的集合处理中。其结果就是将集合处理交给数据库引擎的简化函数。还可以将其执行更好地集成起来,从而更早地应用在处理中,以减少集合处理以及并行执行查询过程中的函数集成等后续步骤中的数据处理。这就支持多线程地执行这些函数,而不必通过复杂的代码来显式地利用它。
DB2 UDB 和 IDS 允许您编写多个具有相同名称的函数,但必须带有不同数目或不同类型的参数。这类似于适用于
integer、decimal、float、double 或其混合类型的加法运算符(“+”),也类似于面向对象中的多态性。除了函数,这两种数据库还允许您创建新的类型,以及通过使用表层次结构创建对象层次结构。所有这些功能共同允许您通过调整数据库来配合业务环境,而不是牺牲您的设计来适应数据库。深入探讨您通过充分使用
IBM 数据库的功能所获得的所有商业优势我们将在下一连载中继续为您讲述。
|
|
|