第一节 DAO的特点
-
易用
- 支持大字段
- 支持分页(包括多表“串联”分页)
- 单表查询所得到的结果是与该表对应的Bean的列表,操作方便
- 多表联查所得到的结果是与各表对应的Bean的对象数组的列表(对象数组中的Bean的顺序与查询时所指定的表名的顺序一致),操作方便
- 插入记录时,可直接插入Bean,不需要写SQL――insert(Bean
obj)
- 支持事务处理
- 支持批处理
- 提供直接执行SQL的API,增加了灵活性
- 每秒插入500条记录
详见第三节
第二节 使用DAO的步骤
1、 使用DAOTool生成与数据库表对应的BEAN和一个配置文件(如下图所示)
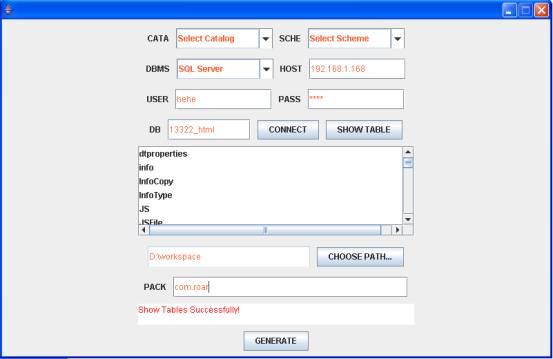
2,创建DAOFactory(参数表示上一步中由DAOTool生成的属性文件的全限定名)
DAOFactory factory=DAOFactory.getInstance("com.huahai.sdk.framework.user.DBConf");
3,创建DAO(可以使用下面的四种方式)
DAO dao=factory.createDAO(String jndi);
DAO dao=factory.createDAO(String driver,String url ,String
user,String pass);
DAO dao=factory.createDAO(String driver,String url);
DAO dao=factory.createDAO(Connection conn);
第三节 简单的示例代码
一,单表查询
List results=dao.query(String tblName,String condition);//不翻页
List results=dao.query(String tblName,String condition,int
每页记录,int 第几页);//翻页
例如:dao.query(“USER”,”USER_ID =’xiaojiong’”);
例如:dao.query(“USER”,”USER_ID =’xiaojiong’”,10,3);
返回结果results中的每一个元素为与数据库表对应的Bean的对象
二,多表查询
List results=dao.query(String[] tblNames,String condition);//不翻页
List results=dao.query(String[] tblNames,String condition,int
每页记录,int 第几页);//翻页
返回结果results中的每一个元素为Object[],对象数组中元素为与数据库表对应的Bean的对象,其顺序与参数tblNames中指定的表名的顺序一致
三,直接写SQL查询,返回ResultSet
ResultSet rs=dao.find(“select * from user”);
四,插入一条记录
User user=new User();
User.setUSER_ID(“XIAO”);
……
dao.insert(user);
五,插入多条记录
List users=new LinkedList();
User user=new User();
User.setUSER_ID(“XIAO”);
……
User user1=new User();
User1.setUSER_ID(“jiong”);
……
users.add(user);
users.add(user1);
dao.insert(users);
六,插入多条记录,并指定每次commit的记录条数
List users=new LinkedList();
User user=new User();
User.setUSER_ID(“XIAO”);
……
User user1=new User();
User1.setUSER_ID(“jiong”);
……
users.add(user);
users.add(user1);
dao.insert(users,2);
七,更新记录
//更新User的USER_NAME,USER_DESC
Map columnsBeUpated=new HashMap();
dolumnsBeUpated.put(“USER_NAME”,”xiaojiong”);
dolumnsBeUpated.put(“USER_DESC”,”超人”);
dao.update(“USER”,columnsBeUpated,”user_id= ‘xiao’”);
八,删除记录
dao.delete(“USER”,”USER_NAME = ‘xiaojiong’”);
九,多表“串联”分页
List results=dao.query(String[] tblNames,String[] conditions,int
每页记录,int 第几页);
当把多个表的记录“串联”在一起进行分页处理时,按照tblNames中申明的表的顺序读取每页记录,其中conditions为与tblNames中表按顺序一一对应的查询条件
十,事务操作
dao.setAutoCommit(false);
//……
dao.commit();//如果成功,则提交
//dao.rollback();//如果失败,则回滚
十一,其它方法
a, dao.getRecordCnt(“user”,”user_name like ‘jordan’”);//得到符合条件的记录数
dao.getRecordCnt(“user”,””);//得到全部记录数
b, dao.executeSQL(String sql);//执行SQL语句
c, dao.executeBatch(List sqlList, int commitCount);//批量执行sql,commitCount
为每次commit的条数
d, dao.getMaxValue(String tblName,String colName,String
condition);
得到指定表、指定列的符合条件的记录中的最大值
e, dao.getMinValue(String tblName,String colName,String
condition);
得到指定表、指定列的符合条件的记录中的最小值
十二,执行完操作后,一定要调用下面的函数,释放数据库连接:dao.close();
|