第 5 部分 :架构与设计
Steven Franklin
软件设计师和过程专家
2004 年 4 月
当这个正在进行的应用 RUP 和其他的 Rational 工具的 J2EE 样例项目从用例转换成架构和设计时(包括数据建模和构建测试设计假想的原型),这个项目已经进入了更加技术的阶段了。
这个系列的第 5 部分首先检查了一下项目的时间进度,然后当我们进入了架构、设计、数据建模和创建原型时,我们已经在下一个阶段进行细化阶段中了。
| 第 5 部分快照 |
|
在第 5 部分演示的工具和技术:
产生或者被更新的产物:
|
在开始进行详细的架构和设计工作之前,让我们来检查一下 ASDI 项目的整体进度。就像你可以第 1 部分回想起来的,这个由多个部分组成的系列文章覆盖了项目的第 1 个阶段:以一系列需求、一个参考架构和代码(理想的可重用的)为结果的概念的验证。到目前为止,我们大概使用了整个第 1 阶段预算的三分之一,但我们已经接近了项目时间进度的一半了。这是在我们的预料之中的,因为我们有意的让进度稍微慢一点。分析和计划活动总是以较慢的步伐移动,团队应该在项目开始时逐步的将他们建立起来。
因为第 1 阶段要求一个相关的结构化的和正式的概念的证据,我们将它作为一个小的项目处理,通过在演进的产品上进行测试和 QA(同级审查)来完成它。RUP 有一些用于开发概念证据的机制,基本在分析和设计工作流的执行架构的合成的活动中。我们正在进一步的将概念的证据转化成可用的 beta 版产品。我们能够将更多的功能、风险的降低和产品的成熟放到这个阶段中,我们越多的将技能和知识用到系统的产品版本中,我们的客户就越高兴。
这个接下来的一系列的任务将比之前的活动更加具有技术性。我们正很好的向架构。设计、数据建模和原型前进。在第 4 部分中我们讨论了一些原型和评估如何进行我们的工具选择;现在我们的原型的关注点在测试我们设想的需求、系统说明和设计上。
架构和设计活动是在 ASDI 项目中最令人愉快和具有创造力的任务。我们为我们将系统计划的高效、安全和简单优雅而自豪。技术方案的远景在多次令人兴奋的会面、自由讨论和技术探索中最终形产生了。
简单的讲,架构意在捕获技术上灵活的方案,这个方案可以覆盖上个月我们定义出来的系统需求。不论是向前看(对于设计)还是向后看(对于需求),架构团队都将承受巨大的压力。 Rational Rose 的集成开发环境通过让我们能够做以下的事情简化了这个挑战:
- 使用 SoDA 产生文档以允许架构和设计元素的分发,简化了检查并保持每个人都有一致的当前远景。
- 从场景直接更新类的签名(方法和属性),以使我们不必回到类的说明中添加缺少的方法。
- 为自动化的任务比如产生类的骨架、检查模型的命名习惯和测试模型的完整性和有效性生成 RoseScripts (可以通过访问 Tools 菜单得到)。
- 使用 Rose 的 RUP 模板,提供一个附带 RUP 指南的模型框架。
- 在 Rose 中从提供的 J2EE 类框架中拖出类。
- 用 Rose 的”单元控制“特性将模型分解成为能够被团队进行版本控制和并行工作的片断。
注意,因为我们在过去的项目中创建的系统与目前这个系统类似,因此如果我们引用一些参考架构,我们的架构将会从中受益。然而,我们不能在已存在的包或者设计模式中找到任何可重用的机会,因此我们只是引用了已存在系统中可能会在将来用到的思想和类。
从用例到设计类的转化
从用例到设计类的转化过程是缓慢的,需要进行多次的迭代。这牵扯到分析人员和设计人员,因为我们有很少的既可以舒服的与客户讨论业务领域又可以使用特定的工具进行分析、细化设计产物的人员。
这个活动的目标
有时将需求直接的转换成代码是诱人的。实际上,我们在以前的项目中就是这样做的(因为我们有非常详细的需求说明),我们在我们对项目的理解上非常自信。这样就产生了一个错误。需求被遗漏,范围很难被跟踪,并且大量的工作和返工是无用的。使用设计模型来连接在需求和代码之间的鸿沟是重要的;设计模型可以在开发和测试之前很久捕获错误和有问题的假设。
在从用例向设计类转化的过程中,我们希望能够实现:
- 将分析小组的知识传授给工程团队。
- 识别能够满足所有需求的技术方案 ― 或者,什么地方不是可能的,识别与技术方案冲突的需求,并确定是否他们是重要的或者被改变或者被删除。
- 识别能够帮助确定团队结构、架构层次和对于购买软件的候选的接口。
- 指定技术方案的细节并开始计划如何在团队之中分配工作。
- 基于设计模型的细化时间进行计划和预算的预估。
- 分配类到平台、产品和私有代码。
- 为了反馈和同步的目的,生成软件架构文档,软件架构文档能够被分发到内部和外部的团队成员。
实现稳定的设计
从用例和分析类到设计和设计类的转化是不可避免的模糊的。在我们能够拥有我们感到满意的设计之前,我们需要做大量的工作。图 1 显示了我们以我们的方法定义一个稳定的设计的主要活动。
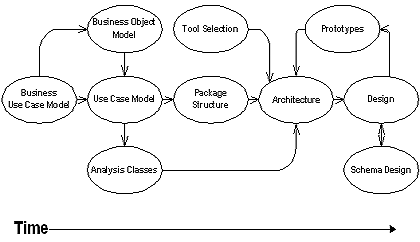 |
| 图 1: 从用例模型到设计模型的转化 |
前面的文章部分讨论了多数的在图 1 中作为”架构“准备的活动和产物(特别是 SOW 需求、用例、业务对象模型和分析类)。此外,这些其他的活动对设计工作也是重要的:
- 确定包的结构
- 建模数据(创建数据库计划)
- 创建原型和屏幕模拟
这些将在接下来的部分连同如何处理新的和改变的需求一起被讨论。
在开始考虑设计类之前,整个团队要对一个良好的包结构达成一致同意。不管我们最后的决定是什么,它都应该成为设计过程中的指导方针,所有团队成员都要遵守这个指导方针。
包结构的选择
我们一直在争论是按照子系统(图 2)来划分包还是按照架构的层次来划分(图 3)。表 1 列出了每种方法的有点和缺点。
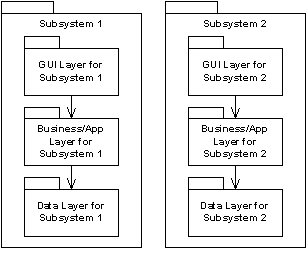 |
| 图 2: 按照子系统定义包 |
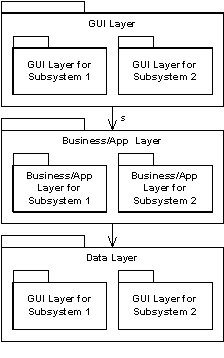 |
| 图 3 : 按照架构的层次进行包的划分 |
| 方法 | 优点 | 缺点 |
| 按照子系统定义包 |
|
|
| 按照架构层次划分包 |
|
|
| 表 1: 打包方法的比较 |
最终我们使用了第一种方法,按照子系统来划分设计模型。我们觉得系统是足够小的,我们可以保持好子系统之间的一致性。
子系统结构设计
我们的顶层的包结构的一个最初草稿就象图 4 。你可以从顶层的包中看到被识别的子系统(因此,原型 <
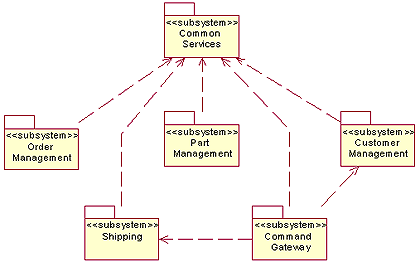 |
| 图 4: 顶层包的结构 |
在我们将这个早期的草稿变成最终稳定的包结构之前,我们进行了大量的讨论。下面是我们关注的一些问题:
- 我们如何组织通用的服务?
回答:公用服务被单独的放在一个子包中(日志服务;数据同步和备份服务;访问控制服务和登陆服务)。 - 我们应该在 shipping 和 part management 之间画线吗?
回答: 我们不需要连接他们两个。 - 我们根据领域还是架构来定义子系统?
回答:架构在大多数地方都能与领域结合。 - 我们允许包之间的双向依赖吗?
回答:不。这是违背我们内部设计指导方针的不好的设计实践。
作为一个例子,我们将着重关注在 command gateway 子系统上。虽然系统的很多地方都是以一个内部的和外部的 Web 接口为中心的,我们还是计划提供一个安全的、基于 XML 的命令网关(command gateway),这个命令网关允许 ASDI 的系统与它的大客户之间的形成一个 B2B(business-to-business)的接口。这个特性允许这些客户能够从他们已有的系统对 ASDI 查询、提交和更新信息。这是非常重要的,因为一些公司的需求是不能通过 Web 接口访问,相反他们需要的来自与公司的代号的批量的或者是幕后的提交。
在每一个包中,我们最初的类图都来自于我们的用例、业务对象模型、注释和访谈。图5 显示了 command gateway 子系统从早期的思想到详细的设计的演进过程。
 |
| 图 5: command gateway 的初始设计 |
在这个第一轮的设计中,我们简单的识别出 command gateway 子系统的主要部分,在这个层次上存在着必须被关注的问题:
- 我们使用 XML 吗?(问题包括宽带消费、稳定性和解释器的成熟性)。
- 我们要向客户发送和接收数据吗?
- 我们要提供命令的客户端软件或者仅仅为此发布命令的规范?
- 我们要通过 SSL(Secure Sockets Layer)、HTTP 或者私有的套接字通讯传输 XML 吗?
在后续的设计中(图 6 ),我们识别出了在系统中的更多依赖关系,并开始识别看起来象实现类的东西。我们仍然在争论高级别的概念,因此我们对文档和类的签名并不感兴趣(方法和属性)。文档和类的签名应该在我们觉得设计开始稳定时被填充进去。
 |
| 图 6: command gateway 的中期设计 |
就像图 7 显示的那样,我们后来细化了一些我们识别出的依赖关系、适当的方法和属性(被隐藏在图中以节省空间),并且添加了一些技术的细节。例如,通过建立原型我们识别出将 JSSE (Java Secure Socket Extension) 作为在客户和服务器之间的 SSL 连接的方案。JSSE 被直接集成到了 JDK 1.4 中,当对 JDK 1.4 以前的版本它只是一个附加的部分。
 |
| 图 7: 成熟的 command gateway 设计 |
这个设计还不是最终的。虽然设计已经通过众多的场景图被测试过了,但是在接下来的数周和数月的编码中将发现设计中不正确的地方或者或者遗漏的细节。
当我们进行架构和设计时,我们识别出了添加新的需求或者对已有系统需求进行细化的需要。忽略一些小的变更是诱人的,但是我们看到需要相当多的预算来完成变更。在预算上的小的缺口将增加需要的时间,并给客户一个不好的先例。我们发现跟踪所有的添加和变更将有助于我们用检查保持期望,并迫使我们问,“在将来我们真的需要这个吗?” 这是一个我们通常忽略的关键点:如果一个需求不是足够重要进入系统,那么这个需求就不值得去实现。
有时,需求的引入会对已有的进化和预算带来负面的影响。这就要求我们坐下来和客户讨论选择 ― 但是首先,我们应该在我们内部进行讨论,以便我们能可信的向客户提出备选方案,而不是简单的“即兴表演”。选择通常包括以下的方面:
- 推迟需求。 这通常发生在需求不是都重要的时候,或者是其他的需求没有目前正在构建的需求那么重要。
- 去掉需求。 这发生在需求更本不重要的时候。
- 用一个新的需求代替一个已有的需求。 如果已存在的需求不是重要的或者这至少不是特别紧急的,我们可以推迟或者去除这个需求来为新的需求在时间进度和预算上腾出空间。
- 添加需求到目前的工作中。 这种选择仅仅在不会引入不可接受的风险到已存在的需求和整个系统计划时才被考虑。添加任何重要的需求自然会要求额外的时间和预算。
对用例进行变更不是问题,因为我们对用例进行了严格的版本控制,并可以直接的在模型中更新他们。此外,Rational RequisitePro 的使用将编程集成回到 SOW 中也是容易的。然而,追溯我们所希望的,我们已经花费时间建立了 Rational ClearQuest 来管理需求的变更。有时变更是被内部识别出来的,但是更多的情况是有外部的请求产生的。我们的变更管理过程是非常笨拙的,包括每月的会议、硬拷贝的文件等等。更加无缝的变更请求过程几乎会为控制范围的增长、产生更好的系统和更高的和约价值带来的更多的机会。
当我们开始进行上面所描述的设计工作的同时,我们也开始建模数据了。在以前的项目中,我们使用 Rational Rose 进行设计,并发现在持久类和暂时类之间的分割有点笨拙:一旦我们识别出了一个用于持久存储的类,我们便设置它的持久属性并开始用其他的工具对他建模。在 ASDI 项目中,我们使用了集成在 Rational Rose Enterprise 中的 data modeler 进行数据建模,并且发现过度更加的成熟。
实际上,我们最初在使用老方法上范了一个错误 ― 将持久对象放到他们自己的文件夹中,并遗忘了他们 ― 但是,我们自己发觉了他们并使用 Rose 将这些对象转换成了数据模型。将所有收集到的持久类放入一个包中,我们可以通过鼠标右键点击包,并转换他们成为数据模型(通过从上下文菜单选择 Data Modeler > Transform to Data Model )。
数据建模器在 Rose 模型中创建了一个数据库计划。我们后来将这些计划从它的逻辑表示转化成了一个物理的 DB2 安装,并给工程团队访问表和测试数据。
作为架构和设计的基础,良好的分析是重要的,但是原型也是非常有价值的。很多的主意在纸上看起来很好,但我们的假设只有原型才能提供的证据。
工程团队非常喜欢原型活动。典型的对这些活动的时间计划是非常自信的,目标是模糊的,技术是新的,并且 QA 轻松的,因此原型通常是很有趣的 ― 金钱的大量浪费。我们发现如果原型没有清晰的、可测量的目标,它很快就会沦落到“我能做什么...”的境地,而不是降低风险的任务。
我们通常尽力与 RUP 的演进产品理论保持一致,RUP 可以指导我们将我们所有的原型演化成最终的产品。事实上,我们对快速的探索保留了术语“原型”。为了从原型中释放出最大的价值,我们经常忽略代码的标准、同级检查和类似的过程。原型的一些方面(类的说明、设计模式或者编码习惯)也许可以被重用,但是我们在重用这一点上给团队非常小的压力。相反,我们的原型的结果通常被总结成为技术注释或者成为可以被活来项目参考的样例应用。
马上,一个工作包必须被起草。对它的开发人员来说这个包能够概括特定原型的目标。我们为每个原型分配了预算和时间计划,这里包括了任务完成之前的中期检查。
我们不总是通过直接的编码来创建原型的。有时我们通过在写任何代码之前进行学习来执行工具的评估。当评估数据库时,比如,我们基于我们的经验、供应商提供的信息和第三方的检查从类表中去掉一些候选工具。
我们发现几种很好的构建原型和工具选择的方法:
- 审查 (读、反复查看、面谈)
- 编码 (深入的代码片断可以探察特定的接口、需求或者性能问题,并且明朗的、简洁的代码片断可以显示连接性、工作流和可用性)
- 原型的安装和演示
- 工具提供商的演示
良好运用原型的关键在于决定原型的实现的程度。很少有原型能够在推荐中被设计成为给人 100% 的信心。相反,原型必须演示足够的结果以减少风险到可以忍受的级别。
表 2 列出了一些我们在这个项目中采用的特定原型活动。
| 原型活动 | 结果 |
| 研究(覆盖特性、成本和性能) | Orion Application Server 的选择(更多信息,看 第 4 部分 ) |
| OOBD 的评估(覆盖特性和市场份额),以满足客户的偏爱 | 决定放弃使用 OODB(更多信息,看 第 4 部分 ) |
| 研究关系型数据库(覆盖特性、成本和性能) | 选择 DB2 (更多信息,看 第 4 部分 ) |
| JSSE 评估 (覆盖复杂性、稳定性和安全性) | 在 B2B 方案中包括 JSSE |
| 用户界面模拟(测试可用性、工作流和“外表感观”) | 对于“外表感观,用户界面指南和标准的开发” |
| 在 Rational Rose Enterprise 进行数据建模(使用 Rose 的 data modeler) | 熟悉使用 Rose data modeler;生成创建表、触发器等等用于早期原型的数据库教本 |
| XML 探索 (看 相关资源) 并且创建 B2B 接口原型 | 一致同意良好格式的 XML 比信任第三方的解释器带来的利益或者对丰富标记的 XML 更重要 |
| EJB 与 JSP 和 servlets 的对比 | 决定在 第 1 阶段使用 JSP 和 servlet |
| 表 2: 原型活动 |
我们对系统的架构和设计已经相当的成熟;我们的原型取得了巨大的成功,并且我们将很快开始实现的工作。这意味着跟踪项目的过程要比保持项目远景在规定的方向上和仔细的计划每一个迭代和增量更加的重要。
到现在为止,我们已经试验并选出了所有主要的技术和第三方的工具,并且我们非常满意工具提供商能够做他们的工作。我们通过被计划的原型做了这个决定,并且不只是希望或者相信银弹。原型也帮助我们的工程团队,给我们我们具有完成工作的知识和需要的技能。
计划未来
在不久的将来,我们将进入系统的实现中。我们计划实现以下目标:
- command gateway ,它造成了一些最大的技术风险
- 图形用户界面,它将为客户提供有用的检查产物
- 被众多子系统功能需要的一些通用服务
在做任何实现之前,我们必须在多个方面对项目的阶段做准备,包括更新我们团队的结构以满足我们的新需要,文档化代码和设计协定和交流有效的开发方法(包括单元测试和同级检查)。工程团队将需要完全的理解双向工程、调试、分析和其他更多的东西。
主要风险
JSSE 原型指出 JSSE 是一个比我们最初预期的更加复杂的 API 。尤其是,安全方面对项目范围的蔓延产生了巨大的机会,因此我们必须与 ASDI 密切的工作以准确的理解他们需要什么样的安全。来自于需求的工作不会涉及到密钥长度、加密机制和其他底层的细节。
最后,我们在 EJB 之上选择和 JSP 和 servlet ,我们知道我们架构可能需要在第 2 阶段进行一些返工。我们愿意将它作为那个阶段的风险保留,因为我们完全的提交了这个技术选择