|
|
|
|
向Spark开炮:1.6版本问题总结与趟坑
|
| |
|
作者:岑玉海 来源:CSDN 发布于 2016-5-3 |

|
|
|
笔者使用Spark已超过一年,现在公司大部分的批处理任务和机器学习任务都运行在Spark平台之上,MapReduce已经成为历史。目前生产环境刚从Spark 1.4.1升级到最新版Spark 1.6.1,使用Yarn来调度和管理资源。本文将从升级到Spark 1.6过程当中遇到的若干问题和大家分享,我也会指出目前Spark存在的问题,希望引起重视。
内存问题
Spillable集合内存溢出
这个问题的具体错误信息:Unable to acquire 163 bytes of memory, got 0。这个Exception是Spark在申请不到运行内存的时候主动抛出来的,在处理大数据量的场景下很容易复现。在Spark 1.6,默认的Shuffle仍然是Sort方式,实际上是Tungsten-sort和sort合并之后的版本,为了详细阐述这个问题产生的根源,先回顾一下Tungsten-sort的流程(如图1所示)。
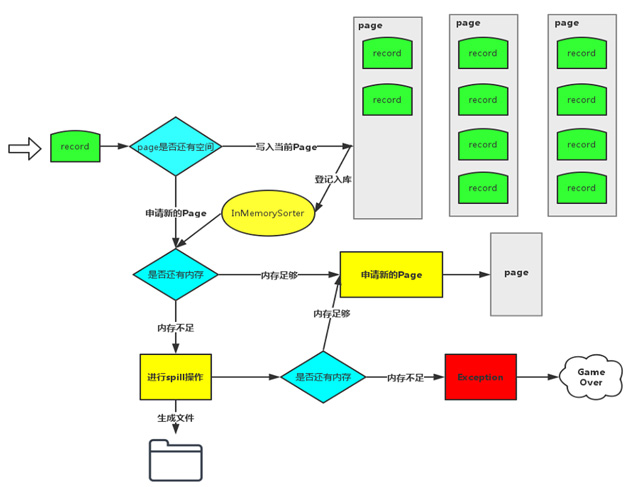
图1 Tungsten-sort的流程
Record的key和value会以二进制的格式存储写入到ByteArrayOutputStream当中,用二进制形式存储的好处是可以减少序列化和反序列化的时间。然后判断当前Page是否有足够的内存,如果有足够的空间就写入到当前Page(注:Page是一块连续的内存)。写入Page之后,会把内存地址address和partitionId编码成一个8字节的长整形记录在InMemorySorter当中。当前Page或者InMemorySorter内存不够的时候会去申请内存,如果内存不够就要把当前数据Spill到磁盘了,如果还是申请不到内存就会报该Exception。
为什么Spill都无法释放内存呢?通过添加日志信息的方式,发现了有一个Spillable对象申请了很多内存,但是却不登记姓名,属于黑户一般的存在。
于是在社区发现了这个issue:SPARK-11293。明明发现了问题却不解决,让人很无奈。
之前使用的Spark 1.4版本也存在该问题,只是没有主动抛错误,最后演变成ExecutorLost。Spillable的具体实现有ExternalAppendOnlyMap和ExternalSorter,它们主要负责做聚合和排序。虽然自身也有Spill机制,但它的Spill不是必须的,有非常大的概率会把所有的数据保存在内存当中,等遍历完集合里面的所有数据,才会释放内存。在不修改代码的情况下,有两种方式可以减少它发生的概率:
增加出错阶段的partition数,在数据分布比较均匀的情况下,可以减少每个Task处理的平均数据量。
设置spark.shuffle.spill.numElementsForceSpillThreshold,该参数主要用于测试,因为单元测试的时候可以明确知道写了几条测试数据。它的默认值是Long.MaxValue,当插入的数据条数超过了这个阈值之后,就会强行把数据写入到磁盘。
这两种方法都存在比较明显的缺陷,第一种方式不适用于数据倾斜的场景,第二种方式用户很难明确的知道自己设置多少才可以,调大了没作用,调小了会产生大量的磁盘I/O开销,需要反复不断尝试。如果第二种方式换成内存的大小就比较直观了,而且可以设置成默认的参数,这种修改方式最简单,修改的代码总共不超过10行。
修改方式如下:
修改Spillable接口,使它继承自MemoryConsumer对象,合法申请内存,绝不走后门。
增加系统参数spark.shuffle.spill.memoryForceSpillThreshold,默认值设置成640m,修改Spillable的maybeSpill方法,当currentMemory超过阈值时把数据spill到磁盘。
存储内存占用运行内存
在Spark 1.6之前,内存分为存储内存和运行内存,两者之间不能相互借用,在任务不进行缓存的情况下,存储内存等于是浪费了。Spark 1.6推出了统一内存管理(Unified Memory Management),默认情况下executor-memory的75%会拿出来供存储内存和运行内存使用(各占一半),存储内存和运行内存可以相互借用,避免了浪费的情况,有效的提高了内存的使用率。
听起来是挺好的,但是运行任务的时候发现了一个问题:存储内存把所有内存占完了,Shuffle的时候它再慢慢从内存中剔除,多浪费了一次加载和剔除的时间。
为什么会发生这种情况呢?因为Cache操作发生在Shuffle操作之前,这个时候运行内存是空闲的,它就顺势把运行内存给占完了,等进行Shuffle操作的时候,已无内存可用,只能要求存储内存归还。
为了避免这种状况,可对策略稍微做一下修改:存储内存不能借用运行内存,运行内存可以借用空闲的存储内存。
具体修改在类UnifiedMemoryManager当中:
设置参数spark.unifiedMemory.useStaticStorageRegion。
修改maxStorageMemory函数,该值会影响在Job UI上显示的最大内存。
override def maxStorageMemory:
Long = synchronized {
if (useStaticStorageMemory) {
storageRegionSize
} else {
maxMemory -
onHeapExecutionMemoryPool.memoryUsed
}
} |
3 . 修改acquireStorageMemory函数,增加以下的代码,修改maxBorrowMemory的值。
if (useStaticStorageMemory &&
(storageRegionSize - storageMemoryPool.poolSize)
<
onHeapExecutionMemoryPool.memoryFree)
{
maxBorrowMemory = storageRegionSize -
storageMemoryPool.poolSize } |
BlockManager死锁问题
该问题多发生在Cache数据比较多,存储内存不够用的场景下。用jstack命令打印线程信息直接显示出Deadlock来,具体的信息请看这个issue: SPARK-13566。
该问题的起因是缓存的数据块Block缺乏读写锁,当内存不够的时候,BlockManager清理Broadcast变量的线程和Executor Task的线程剔除Block同时选中了一个Block,并且相互锁定了对方需要的对象。BlockManager先锁定了MemoryManager,然后请求该BlockInfo,Executor Task先锁定了BlockInfo,然后要在内存中删除该Block的时候需要锁定MemoryManager,非常典型的死锁。
在JIRA开了一个issue之后,大神回复说在Spark 2.0会添加对Block的读写锁保护,但是该PR修改非常多,很难应用在Spark 1.6当中,可是该问题非常严重,需要cache的数据比内存大的时候很容易复现。临时的一种解决方法如下:
在BlockManager当中添加一个全局的ConcurrentHashMap[BlockId, Long]来记录锁定该Block的任务ID;在锁定BlockInfo之前记录,访问完MemoryManager删除记录。
锁定BlockInfo之前都要先判断是否在该ConcurrentHashMap当中已存在,如果已存在,函数退出。
考虑到任务可能失败的可能性,在任务结束之后释放跟该任务ID相关的所有锁。
详细的代码可以查看该issue当中的PR。
使用超额的内存被Yarn给Kill掉
相信在Yarn上跑过Spark程序的朋友都会碰到过这个问题:Current usage: 12.1 GB of 12 GB physical memory used; 13.9 GB of 48 GB virtual memory used. Killing container。
在同样的参数下,在Spark 1.4上正常运行的程序,在Spark 1.6上运行很容易出现这个问题。Spark在向Yarn申请内存的时候,一共申请了(execuor内存 + 额外内存),额外内存默认是executor内存的10%,最小是384M。在大多数情况下,10%的额外内存已经是不够的了,很容易被Yarn杀死。笔者尝试过把参数spark.shuffle.io.preferDirectBufs设置为false,禁止Netty使用堆外内存,也尝试过把参数spark.memory.fraction设置成0.6甚至更小,但是没有任何作用。
该问题出现频率非常高,通过设置参数spark.yarn.executor.memoryOverhead可以解决,但设置多少合适呢,让用户自己去设置?用户知道的参数应该越少越好,可以把精力放在业务代码的实现上。按照比例去设置更合理一些,毕竟不能保证所有人都不会去更改默认配置。于是修改代码,把该参数变成可通过比例去设置。当该比例设置成20%的时候,超过限制的情况减少,少数情况还是会超,但是不会导致整个任务失败。该问题也发生在Shuffle阶段,通过增加partition数的方法可以减少。
希望Spark的开发者能够重视这个问题,严格地控制堆外内存的使用。把内存的设置分成Executor内存+额外内存也是Spark的独创做法,就好比收完了房租,还要加收一笔垃圾处理费一样。这是一种对内存使用估计不准确的无奈举措,一直标榜自身是内存计算框架,却不能很好的限制内存的使用。期待Spark有一天可以像MapReduce、Samza这些框架设置了多少就是多少。
其他细节吐槽
UI的若干问题
在Spark 1.3以及之前版本Master的主页上,Workers列表都是显示的机器名,从Spark 1.4之后就改成显示IP列表了,让人非常无奈。偶尔有台机器挂了,如何从茫茫的IP海中搜索出来这台“失联的MH370”呢?如果它可以像Yarn一样显示Dead的节点也很好处理,可惜没有。
在Master主页Workers列表居然放在最上面,试想一下每次打开页面都要越过几百台Worker节点才能看到Running Applications的列表是一种什么样的感受。
执行了SQL之后,在Job UI会看到一个SQL的Tab页,可是有的程序执行之后看到了不只一个,SQL1、SQL2…… 而且这些界面什么数据都没有。查看了源代码,发现它有这个递增的机制。可以关注一下SPARK-11206,把这个issue的PR合并到1.6的分支可以解决多个SQL Tab页的问题,但是在某些程序上仍然没办法正确显示SQL Tab页的内容。
烦人的提示信息
Spark-sql启动的时候总会显示一堆set spark.hive.version=1.2.1的信息,重点还不仅仅是烦人,用spark-sql –e或者spark-sql –f 执行SQL完毕之后,它会把这些信息和结果输出在一起。通过查看源代码,这些信息输出到标准输出流。向Spark社区提过issue,直到现在都无人处理。该代码位于ClientWrapper文件的508行,只需要把state.out改成state.err就行。
Executor不让转正就罢工
偶尔Executor挂掉会引发个别的Task fail,该问题虽然不会杀死任务,但是总有人问这个错误怎么回事?Spark代码里面异常退出采用System.exit(1)的方式,因此从Driver端看到的信息是org.apache.hadoop.util.Shell$ExitCodeException。没人看懂这个提示,被用户问得实在没办法了,登陆到服务器上看container输出的错误信息,发现Received LaunchTask command but executor was null的错误提示信息。查了一下JIRA,发现有个类似的issue:SPARK-13112。报错在以下的位置:
case LaunchTask(data) =>
if (executor == null) {
logError("Received LaunchTask command but executor was null")
System.exit(1) |
原因是接收到Driver发过来的任务,但是Executor并没有完成初始化。
Executor是在什么时候完成初始化呢?它是在接收到Driver的Executor注册成功的消息之后才会。那这里就有个疑问了,为什么要等收到Driver的Executor注册成功消息了之后才去初始化呢?当Executor收到Driver的执行任务的消息,说明已经注册成功了。Driver发送消息是异步的,那就有可能先收到执行任务的消息再收到注册成功的消息。
在求助社区无果后,于是改了两行代码,先实例化好Executor再去Driver注册,该问题解决。
Spark SQL的喜与忧
先说喜吧,测试了一下用户提供的几组SQL语句,Spark 1.6比Spark 1.4有20%以上的性能提升!
忧的是在语法兼容性上没有大的改观,错误提示依旧难以看懂。很快就发现了一个类型转换的问题:SPARK-13772。测试的时候发现:if语句不能同时存在double和decimal两种不同类型,否则就会报错。该语句在Spark 1.4上是正常的。查看源代码之后发现它是在匹配的时候使用了错误的函数导致的,详细代码可查看issue里包含的PR。
结束语
从Spark 1.4升级到Spark 1.6,性能提升很明显,用户普遍反映任务运行速度变快了。碰到的问题也很多,尤其是内存方面,截止至最新发布的Spark 1.6.1,上述问题都没有解决,有类似问题的请参照我提供的方法或者issue里的PR自行解决。
Spark正在朝着精细化管理内存的方向发展,内存管理这个部分的代码改动非常大,从目前的情况来看,是处于失控的状态的,突出的两个问题表现为:
内存申请的逻辑存在明显缺陷,体现在内存不足时无法通过spill机制来释放,只能启动自杀的方式来结束任务。内存消费者A在内存不足时不能要求消费者B释放,只能通过把数据写到磁盘的方式来释放,原因是所有内存消费者的spill函数里都有一段检查代码,防止别的内存消费者触发自身的spill函数。即使内存消费者A释放了内存,它也不一定能申请到,它还需要受到任务可使用最大内存的限制(最大可使用内存=运行内存/运行的任务数)。
堆外内存的使用处于无监管状态,目前只能靠加内存的方式来避免问题。从代码上看,社区是有对通过ByteBuffer分配的堆外内存进行管理的计划,只是目前该部分工作还没有完成。
|
|
|
|
|





