| ±ύΦ≠ΆΤΦω: |
±ΨΈΡ÷ς“ΣΫ≤Ϋβ ≤Ο¥ «LinuxΡΎΚΥΘ§“‘ΦΑΆ®ΙΐΕύ’≈ΆΦΤ§’Ι ΨLinuxΡΎΚΥΒΡΉς”Ο”κΙΠΡήΘ§“‘±ψ”ΎΕΝ’ΏΡήΩλΥΌάμΫβ ≤Ο¥ «LinuxΡΎΚΥΘ§ΡήΩ¥Ε°LinuxΡΎΚΥΓΘ
±ΨΈΡά¥Ή‘”Ύ
ΆΖΧθΚ≈@Linux―ßœΑΫΧ≥Χ
Θ§”…ΜπΝζΙϊ»μΦΰAlice±ύΦ≠ΓΔΆΤΦωΓΘ |
|
1. «Α―‘
±ΨΈΡ÷ς“ΣΫ≤Ϋβ ≤Ο¥ «LinuxΡΎΚΥΘ§“‘ΦΑΆ®ΙΐΕύ’≈ΆΦΤ§’Ι ΨLinuxΡΎΚΥΒΡΉς”Ο”κΙΠΡήΘ§“‘±ψ”ΎΕΝ’ΏΡήΩλΥΌάμΫβ ≤Ο¥ «LinuxΡΎΚΥΘ§ΡήΩ¥Ε°LinuxΡΎΚΥΓΘ ”Β”–≥§Ιΐ1300Άρ––ΒΡ¥ζ¬κΘ§LinuxΡΎΚΥ « άΫγ…œΉν¥σΒΡΩΣ‘¥œνΡΩ÷°“ΜΘ§ΒΪ «ΡΎΚΥ « ≤Ο¥Θ§Υϋ”Ο”Ύ ≤Ο¥?
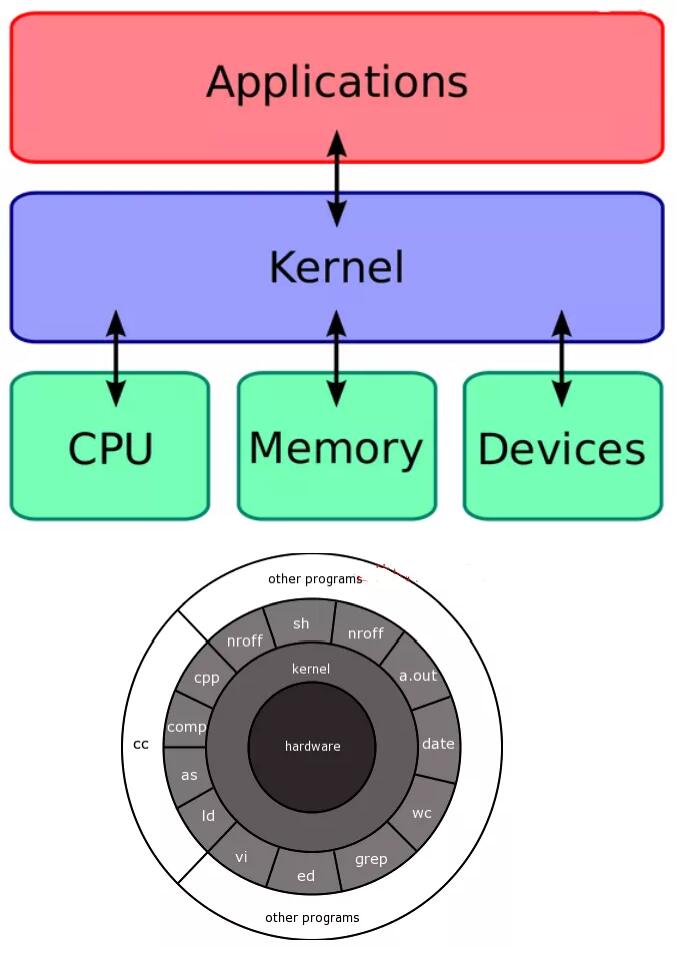
2. ≤Ο¥ «ΡΎΚΥ
ΡΎΚΥ «”κΦΤΥψΜζ”≤ΦΰΫ”ΩΎΒΡ“ΉΧφΜΜ»μΦΰΒΡΉνΒΆΦΕ±πΓΘΥϋΗΚ‘πΫΪΥυ”–“‘ΓΑ”ΟΜßΡΘ ΫΓ±‘Υ––ΒΡ”Π”Ο≥Χ–ρΝ§Ϋ”ΒΫΈοάμ”≤ΦΰΘ§≤Δ‘ –μ≥ΤΈΣΖΰΈώΤςΒΡΫχ≥Χ Ι”ΟΫχ≥ΧΦδΆ®–≈(IPC)±Υ¥ΥΜώ»Γ–≈œΔΓΘ
3. ΡΎΚΥΜΙ“ΣΖ÷÷÷άύΘΩ «ΒΡΘ§ΟΜ¥μΓΘ
3.1 ΈΔΡΎΚΥ
ΈΔΡΎΚΥ÷ΜΙήάμΥϋ±Ί–κΙήάμΒΡΕΪΈς:CPUΓΔΡΎ¥φΚΆIPCΓΘΦΤΥψΜζ÷–ΦΗΚθΥυ”–ΒΡΕΪΈςΕΦΩ…“‘±ΜΩ¥Ής «“ΜΗωΗΫΦΰΘ§≤Δ«“Ω…“‘‘Ύ”ΟΜßΡΘ Ϋœ¬¥ΠάμΓΘΈΔΡΎΚΥΨΏ”–Ω…“Τ÷≤–‘ΒΡ”≈ ΤΘ§“ρΈΣ÷Μ“Σ≤ΌΉςœΒΆ≥»‘»Μ ‘ΆΦ“‘œύΆ§ΒΡΖΫ ΫΖΟΈ ”≤ΦΰΘ§ΨΆ≤Μ±ΊΒΘ–ΡΡζ «ΖώΗϋΗΡΝΥ ”ΤΒΩ®Θ§…θ÷Ν «≤ΌΉςœΒΆ≥ΓΘΈΔΡΎΚΥΕ‘ΡΎ¥φΚΆΑ≤ΉΑΩ’ΦδΒΡ’Φ”Ο“≤Ζ«≥Θ–ΓΘ§Εχ«“ΥϋΟ«ΆυΆυΗϋΑ≤»ΪΘ§“ρΈΣ÷Μ”–ΧΊΕ®ΒΡΫχ≥Χ‘Ύ”ΟΜßΡΘ Ϋœ¬‘Υ––Θ§Εχ”ΟΜßΡΘ Ϋ≤ΜΨΏ”–Ιήάμ‘±ΡΘ ΫΒΡΗΏ»®œόΓΘ
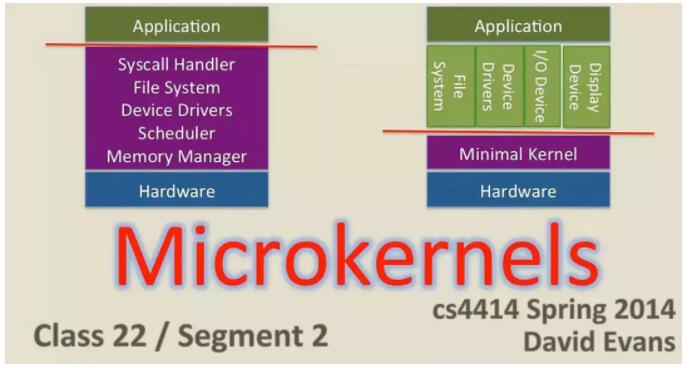
3.1.1 Pros
- Ω…“Τ÷≤–‘
- Α≤ΉΑ’Φ”ΟΩ’Φδ–Γ
- –ΓΡΎ¥φ’Φ”Ο
- Α≤»Ϊ
3.1.2 Cons
- Ά®Ιΐ«ΐΕ·≥Χ–ρΘ§”≤ΦΰΗϋΦ”≥ιœσ
- ”≤ΦΰΩ…ΡήΖ¥”ΠΫœ¬ΐΘ§“ρΈΣ«ΐΕ·≥Χ–ρ¥Π”Ύ”ΟΜßΡΘ Ϋ
- Ϋχ≥Χ±Ί–κ‘ΎΕ”Ν–÷–Β»¥ΐ≤≈ΡήΜώΒΟ–≈œΔ
- Ϋχ≥Χ≤ΜΡή‘Ύ≤ΜΒ»¥ΐΒΡ«ιΩωœ¬ΖΟΈ ΤδΥϊΫχ≥Χ
3.2 ΒΞΡΎΚΥ
ΒΞΡΎΚΥ”κΈΔΡΎΚΥœύΖ¥Θ§“ρΈΣΥϋΟ«≤ΜΫωΑϋΚ§CPUΓΔΡΎ¥φΚΆIPCΘ§Εχ«“ΜΙΑϋΚ§…η±Η«ΐΕ·≥Χ–ρΓΔΈΡΦΰœΒΆ≥ΙήάμΚΆœΒΆ≥ΖΰΈώΤςΒς”ΟΒ»ΡΎ»ίΓΘΒΞΡΎΚΥΗϋ…Ο≥Λ”ΎΖΟΈ ”≤ΦΰΚΆΕύ»ΈΈώ¥ΠάμΘ§“ρΈΣ»γΙϊ“ΜΗω≥Χ–ρ–η“Σ¥”ΡΎ¥φΜρ‘Υ––÷–ΒΡΤδΥϊΫχ≥Χ÷–Μώ»Γ–≈œΔΘ§Ρ«Ο¥ΥϋΨΆ”–“ΜΧθΗϋ÷±Ϋ”ΒΡœΏ¬Ζά¥ΖΟΈ –≈œΔΘ§Εχ≤Μ–η“Σ‘ΎΕ”Ν–÷–Β»¥ΐά¥Άξ≥…»ΈΈώΓΘΒΪ «Θ§’βΩ…ΡήΜαΒΦ÷¬Έ ΧβΘ§“ρΈΣ‘ΎΙήάμΡΘ Ϋœ¬‘Υ––ΒΡΕΪΈς‘ΫΕύΘ§»γΙϊ––ΈΣ≤Μ’ΐ≥ΘΘ§ΨΆΜα”–‘ΫΕύΒΡΕΪΈςΒΦ÷¬œΒΆ≥±άάΘΓΘ
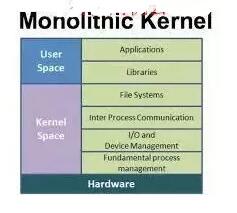
3.2.1 Pros
- Ηϋ÷±Ϋ”ΒΊΖΟΈ ≥Χ–ρΒΡ”≤Φΰ
- Νς≥Χ÷°ΦδΗϋ»ί“ΉΆ®–≈
- »γΙϊ÷ß≥÷ΡζΒΡ…η±ΗΘ§Υϋ”ΠΗΟ≤Μ–η“ΣΕνΆβΑ≤ΉΑΨΆΩ…“‘ΙΛΉς
- Ϋχ≥ΧΖ¥”ΠΗϋΩλΘ§“ρΈΣΟΜ”–Β»¥ΐ¥ΠάμΤς ±ΦδΒΡΕ”Ν–
3.2.2 Cons
- Ϋœ¥σΑ≤ΉΑΧεΜΐ
- Ϋœ¥σΡΎ¥φ’Φ”Ο
- ≤ΜΧΪΑ≤»ΪΘ§“ρΈΣΥυ”–≤ΌΉςΕΦ‘ΎΙήάμΡΘ Ϋœ¬‘Υ––

4. ΜλΚœΒΡΡΎΚΥ
ΜλΚœΡΎΚΥΡήΙΜ―Γ‘ώ‘Ύ”ΟΜßΡΘ Ϋœ¬‘Υ–– ≤Ο¥Θ§“‘ΦΑ‘ΎΙήάμΡΘ Ϋœ¬‘Υ–– ≤Ο¥ΓΘΆ®≥Θ«ιΩωœ¬Θ§…η±Η«ΐΕ·≥Χ–ρΚΆΈΡΦΰœΒΆ≥I/OΫΪ‘Ύ”ΟΜßΡΘ Ϋœ¬‘Υ––Θ§ΕχIPCΚΆΖΰΈώΤςΒς”ΟΫΪ±Θ≥÷‘ΎΙήάμΤςΡΘ Ϋœ¬ΓΘ’β «ΝΫ»ΪΤδΟάΘ§ΒΪΆ®≥Θ–η“Σ”≤Φΰ÷Τ‘λ…ΧΉωΗϋΕύΒΡΙΛΉςΘ§“ρΈΣΥυ”–«ΐΕ·≥Χ–ρΒΡ‘π»ΈΕΦ”…ΥϊΟ«ά¥≥–ΒΘΓΘΥϋΜΙΩ…Ρή¥φ‘Ύ“Μ–©”κΈΔΡΎΚΥΙΧ”–ΒΡ―”≥ΌΈ ΧβΓΘ
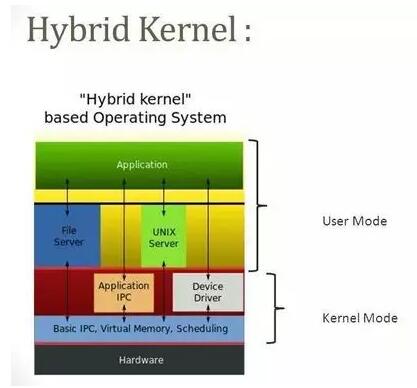
4.1 Pros
- ΩΣΖΔ»Υ‘±Ω…“‘―Γ‘ώ ≤Ο¥‘Ύ”ΟΜßΡΘ Ϋœ¬‘Υ––Θ§ ≤Ο¥‘ΎΙήάμΡΘ Ϋœ¬‘Υ––
- ±»ΒΞΤ§ΡΎΚΥΗϋ–ΓΒΡΑ≤ΉΑ’Φ”ΟΩ’Φδ
- ±»ΤδΥϊ–ΆΚ≈ΗϋΝιΜν
4.2 Cons
- Μα‘β ή”κΈΔΡΎΚΥœύΆ§ΒΡΫχ≥Χ―”≥Ό
- …η±Η«ΐΕ·≥Χ–ρ–η“Σ”…”ΟΜßΙήάμ(Ά®≥Θ)
5. LinuxΡΎΚΥΈΡΦΰ‘ΎΡΡάο
Ubuntu÷–ΒΡΡΎΚΥΈΡΦΰ¥φ¥Δ‘Ύ/bootΈΡΦΰΦ–÷–Θ§≥ΤΈΣvmlinux -versionΓΘvmlinuz’βΗωΟϊΉ÷ά¥Ή‘”Ύunix άΫγΘ§‘γ‘Ύ60Ρξ¥ζΘ§ΥϊΟ«ΨΆΑ―ΡΎΚΥΦρΒΞΒΊ≥ΤΈΣΓΑunixΓ±Θ§Υυ“‘Β±ΡΎΚΥ‘Ύ90Ρξ¥ζ Ή¥ΈΩΣΖΔ ±Θ§LinuxΨΆΩΣ ΦΑ―ΡΎΚΥ≥ΤΈΣΓΑLinuxΓ±ΓΘ

Β±ΩΣΖΔ–ιΡβΡΎ¥φ“‘±ψΗϋ»ί“ΉΒΊΫχ––Εύ»ΈΈώ¥Πάμ ±Θ§ΫΪΓΑvmΓ±Ζ≈‘ΎΈΡΦΰΒΡ«ΑΟφΘ§“‘œ‘ ΨΡΎΚΥ÷ß≥÷–ιΡβΡΎ¥φΓΘ”–“ΜΕΈ ±ΦδΘ§LinuxΡΎΚΥ±Μ≥ΤΈΣvmlinuxΘ§ΒΪ «ΡΎΚΥ±δΒΟΧΪ¥σΘ§ΈόΖ®ΉΑ»κΩ…”ΟΒΡ“ΐΒΦΡΎ¥φΘ§“ρ¥Υ―ΙΥθΝΥΡΎΚΥ”≥œώΘ§≤ΔΫΪΡ©Έ≤ΒΡxΗϋΗΡΈΣzΘ§“‘œ‘ ΨΥϋ «”Οzlib―ΙΥθΒΡΓΘ≤Δ≤ΜΉή « Ι”ΟœύΆ§ΒΡ―ΙΥθΘ§Ά®≥Θ”ΟLZMAΜρBZIP2ΧφΜΜΘ§“Μ–©ΡΎΚΥΦρΒΞΒΊ≥ΤΈΣzImageΓΘ
Αφ±ΨΚ≈ΫΪ≤…”ΟA.B.C.Ηώ ΫD‘ΎΓΘBΩ…Ρή «2.6,C «ΡζΒΡΑφ±ΨΘ§D±μ ΨΡζΒΡ≤ΙΕΓΜρ≤ΙΕΓΓΘ
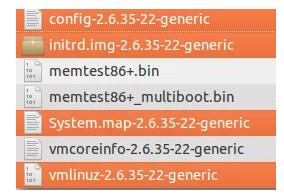
‘Ύ/bootΈΡΦΰΦ–÷–ΜΙ”–ΤδΥϊΖ«≥Θ÷Ί“ΣΒΡΈΡΦΰΘ§≥ΤΈΣinitrd.img-versionΓΔsystem.map-version, config-versionΓΘinitrdΈΡΦΰ”ΟΉς“ΜΗω–ΓRAM¥≈≈ΧΘ§”Ο”ΎΧα»ΓΚΆ÷¥–– ΒΦ ΒΡΡΎΚΥΈΡΦΰΓΘ’βΗωœΒΆ≥ΓΘmapΈΡΦΰ”Ο”ΎΡΎΚΥΆξ»ΪΦ”‘Ί÷°«ΑΒΡΡΎ¥φΙήάμΘ§≈δ÷ΟΈΡΦΰΗφΥΏΡΎΚΥ‘Ύ±ύ“κΡΎΚΥ”≥œώ ±“ΣΦ”‘ΊΡΡ–©―ΓœνΚΆΡΘΩιΓΘ
6. LinuxΡΎΚΥΧεœΒΫαΙΙ
“ρΈΣLinuxΡΎΚΥ «ΒΞΤ§ΒΡΘ§Υυ“‘Υϋ±»ΤδΥϊάύ–ΆΒΡΡΎΚΥ’Φ”ΟΩ’ΦδΉν¥σΘ§Η¥‘”Ε»“≤ΉνΗΏΓΘ’β «“ΜΗω…ηΦΤΧΊ–‘Θ§‘ΎLinux‘γΤΎ“ΐΤπΝΥœύΒ±ΕύΒΡ’υ¬έΘ§≤Δ«“»‘»Μ¥χ”–“Μ–©”κΒΞΡΎΚΥΙΧ”–ΒΡœύΆ§ΒΡ…ηΦΤ»±œίΓΘ
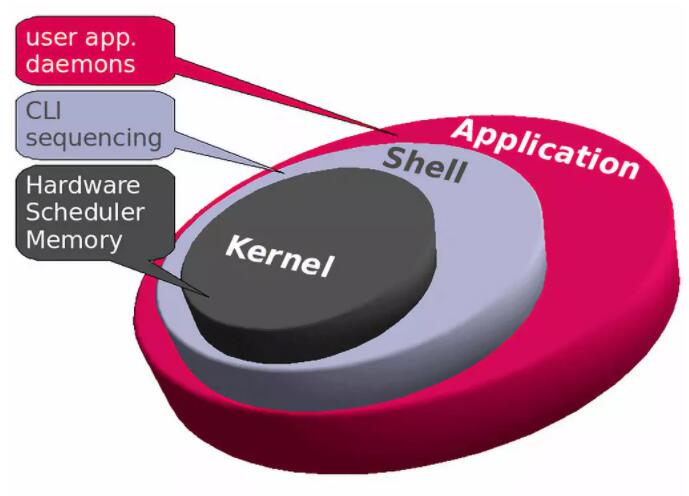
ΈΣΝΥΫβΨω’β–©»±œίΘ§LinuxΡΎΚΥΩΣΖΔ»Υ‘±ΥυΉωΒΡ“ΜΦΰ ¬ΨΆ « ΙΡΎΚΥΡΘΩιΩ…“‘‘Ύ‘Υ–– ±Φ”‘ΊΚΆ–Ε‘ΊΘ§’β“βΈΕΉ≈ΡζΩ…“‘Ε·Χ§ΒΊΧμΦ”Μρ…Ψ≥ΐΡΎΚΥΒΡΧΊ–‘ΓΘ’β≤ΜΫωΩ…“‘œρΡΎΚΥΧμΦ””≤ΦΰΙΠΡήΘ§ΜΙΩ…“‘Αϋά®‘Υ––ΖΰΈώΤςΫχ≥ΧΒΡΡΘΩιΘ§±»»γΒΆΦΕ±π–ιΡβΜ·Θ§ΒΪ“≤Ω…“‘ΧφΜΜ’ϊΗωΡΎΚΥΘ§Εχ≤Μ–η“Σ‘ΎΡ≥–©«ιΩωœ¬÷ΊΤτΦΤΥψΜζΓΘ
œκœσ“Μœ¬Θ§»γΙϊΡζΩ…“‘…ΐΦΕΒΫWindowsΖΰΈώΑϋΘ§Εχ≤Μ–η“Σ÷Ί–¬ΤτΕ·Γ≠Γ≠
7. ΡΎΚΥΡΘΩι
»γΙϊWindows“―Ψ≠Α≤ΉΑΝΥΥυ”–Ω…”ΟΒΡ«ΐΕ·≥Χ–ρΘ§ΕχΡζ÷Μ–η“Σ¥ρΩΣΥυ–ηΒΡ«ΐΕ·≥Χ–ρ‘θΟ¥Αλ?’β±Ψ÷ …œΨΆ «ΡΎΚΥΡΘΩιΈΣLinuxΥυΉωΒΡΓΘΡΎΚΥΡΘΩιΘ§“≤≥ΤΈΣΩ…Φ”‘ΊΡΎΚΥΡΘΩι(LKM)Θ§Ε‘”Ύ±Θ≥÷ΡΎΚΥ‘Ύ≤ΜœϊΚΡΥυ”–Ω…”ΟΡΎ¥φΒΡ«ιΩωœ¬”κΥυ”–”≤Φΰ“ΜΤπΙΛΉς «±Ί≤ΜΩ……ΌΒΡΓΘ
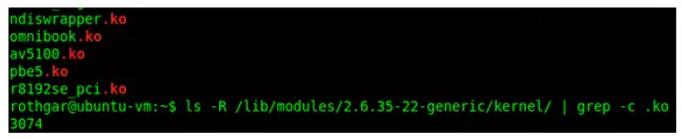
ΡΘΩιΆ®≥ΘœρΜυ±ΨΡΎΚΥΧμΦ”…η±ΗΓΔΈΡΦΰœΒΆ≥ΚΆœΒΆ≥Βς”ΟΒ»ΙΠΡήΓΘlkmΒΡΈΡΦΰά©’ΙΟϊ «.koΘ§Ά®≥Θ¥φ¥Δ‘Ύ/lib/modulesΡΩ¬Φ÷–ΓΘ”…”ΎΡΘΩιΒΡΧΊ–‘Θ§ΡζΩ…“‘Ά®Ιΐ‘ΎΤτΕ· ± Ι”ΟmenuconfigΟϋΝνΫΪΡΘΩι…η÷ΟΈΣloadΜρnot loadΘ§Μρ’ΏΆ®Ιΐ±ύΦ≠/boot/configΈΡΦΰΘ§Μρ’Ώ Ι”ΟmodprobeΟϋΝνΕ·Χ§ΒΊΦ”‘ΊΚΆ–Ε‘ΊΡΘΩιΘ§«αΥ…Ε®÷ΤΡΎΚΥΓΘ
ΒΎ»ΐΖΫΚΆΖβ±’‘¥¬κΡΘΩι‘Ύ“Μ–©ΖΔ––Αφ÷– «Ω…”ΟΒΡΘ§±»»γUbuntuΘ§Ρ§»œ«ιΩωœ¬Ω…ΡήΈόΖ®Α≤ΉΑΘ§“ρΈΣ’β–©ΡΘΩιΒΡ‘¥¥ζ¬κ «≤ΜΩ…”ΟΒΡΓΘΗΟ»μΦΰΒΡΩΣΖΔ»Υ‘±(Φ¥nVidiaΓΔATIΒ»)≤ΜΧαΙ©‘¥¥ζ¬κΘ§Εχ «ΙΙΫ®Ή‘ΦΚΒΡΡΘΩι≤Δ±ύ“κΥυ–ηΒΡ.koΈΡΦΰ“‘±ψΖ÷ΖΔΓΘΥδ»Μ’β–©ΡΘΩιœώbeer“Μ―υ «ΟβΖ―ΒΡΘ§ΒΪΥϋΟ«≤ΜœώspeechΡ«―υ «ΟβΖ―ΒΡΘ§“ρ¥Υ≤ΜΑϋά®‘Ύ“Μ–©ΖΔ––Αφ÷–Θ§“ρΈΣΈ§ΜΛ»Υ‘±»œΈΣΥϋΆ®ΙΐΧαΙ©Ζ«ΟβΖ―»μΦΰΓΑΈέ»ΨΓ±ΝΥΡΎΚΥΓΘ
ΡΎΚΥ≤Δ≤Μ…ώΤφΘ§ΒΪΕ‘”Ύ»ΈΚΈ’ΐ≥Θ‘Υ––ΒΡΦΤΥψΜζά¥ΥΒΘ§ΥϋΕΦ «±Ί≤ΜΩ……ΌΒΡΓΘLinuxΡΎΚΥ≤ΜΆ§”ΎOS XΚΆWindowsΘ§“ρΈΣΥϋΑϋΚ§ΡΎΚΥΦΕ±πΒΡ«ΐΕ·≥Χ–ρΘ§≤Δ Ι–μΕύΕΪΈςΓΑΩΣœδΦ¥”ΟΓ±ΓΘœΘΆϊΡζΡήΕ‘»μΦΰΚΆ”≤Φΰ»γΚΈ–≠Ά§ΙΛΉς“‘ΦΑΤτΕ·ΦΤΥψΜζΥυ–ηΒΡΈΡΦΰ”–ΗϋΕύΒΡΝΥΫβΓΘ
8. Linux ΡΎΚΥ―ßœΑΨ≠―ιΉήΫα
ΩΣΤΣ
―ßœΑΡΎΚΥΘ§ΟΩΗω»ΥΕΦ”–Ή‘ΦΚΒΡ―ßœΑΖΫΖ®Θ§» ’ΏΦϊ» ÷«’ΏΦϊ÷«ΓΘ“‘œ¬ «Έ“‘Ύ―ßœΑΙΐ≥Χ÷–ΉήΫα≥ωά¥ΒΡΕΪΈςΘ§Ε‘Ή‘…μά¥ΥΒΘ§Έ“»œΈΣ±»Ϋœ”––߬ Θ§ΡΟ≥ωά¥Ηζ¥σΦ“ΫΜΝς“Μœ¬ΓΘ
ΡΎΚΥ―ßœΑΘ§“ΜΤΪ÷°ΦϊΘΜ η¬©Ρ―ΟβΘ§Ω“«κ÷Η’ΐΓΘ
ΈΣ ≤Ο¥–¥’βΤΣ≤©ΩΆ
Η’ΩΣ Φ―ßΡΎΚΥΒΡ ±ΚρΘ§≤Μ“Σ÷¥Ή≈”Ύ“ΜΗωΖΫΟφΘ§≤Μ“ΣΉ®ΉΔ”Ύ“ΜΗωΉ”œΒΆ≥ΨΆ“ΜΆΖ‘ζΒΫ ΒΦ ΒΡ¥ζ¬κ––÷–»ΞΘ§“ρΈΣ’β―υΒΡΜΑΘ§«Θ…φΒΡΟφΜαΚήΙψΘ§Μα≈ωΒΫΚήΕύάßΡ―Θ§»ί“Ή≤ζ…ζ¥λΑήΗ–Θ§“ΜΗωΚ· ΐΧε÷–Θ®ΦΌ…ηΗ’ΩΣ ΦΒΡ ±Κρ’ΐ‘Ύ―ßœΑΡ≥ΗωΖΫΟφΒΡΡ≥ΗωΨΏΧεΒΡΙΠΡήΚ· ΐΘ©ΚήΩ…Ρή≤τ‘”Ή≈ΤδΥϊΗςΗωΉ”œΒΆ≥ΖΫΟφ…ηΦΤάμΡνΘ®Εύ «¥σΝΩœύΙΊΒΡ ΐΨίΫαΙΙΜρ’Ώ»ΪΨ÷±δΝΩΘ§”Ο”Ύ÷ß≥≈ΗΟΉ”œΒΆ≥ΒΡΙήάμΙΛΉςΘ©œ¬œύ”ΠΒΡ¥ζ¬κ Βœ÷Θ§’βΗω ±ΚρΩ¥ΒΫ’β–©ΕΪΈςΘ§ΖΉΖ±ΈΏ‘”Θ§ «ΟΜ”–ΆΖ–ςΕχ«“Κή≤ΜάμΫβΒΡΘ§Μα≤ζ…ζΚήΕύΚήΕύΒΡ“…Έ Θ§Θ®’βΗω ±Κρ»γΙϊΕ‘’β–©“…Έ Ψά≤χ≤Μ«εΘ§≈ΌΗυΈ ΒΉΘ§Ρ«Ο¥ ¬ Β…œΨΆ «‘Ύ―ßœΑΒ±«ΑΉ”œΒΆ≥ΒΡΙΐ≥Χ÷–ΤΒΖ±ΒΡ»Ξ…φΉψΤδΥϊΉ”œΒΆ≥Θ§’β ±ΚρΉΔ“βΝΠΨΆΖ÷…ΔΝΥΘ©Θ§Εχ ¬ Β…œΒ»ΝΥΫβΝΥΗςΗωΉ”œΒΆ≥Κσ‘ΌΜΊΆΖΩ¥’β–©ΕΪΈςΒΡΜΑΘ§ΨΆΦρΒΞΕύΝΥΘ§Εχ«“ΥΦ¬Ζ“≤Μα±»Ϋœ«εΈζΓΘΥυ“‘Θ§“Σ±ήΟβ ΓΑ÷ΜΦϊ ςΡΨΘ§≤ΜΦϊ…≠Ν÷Γ±Θ§≤Μ“ΣΦ±”Ύ…ν»κΒΫΒΉ≤ψ¥ζ¬κ÷–»ΞΘ§≤Μ“ΣΙΐ‘γ―–ΨΩΒΉ≤ψ¥ζ¬κΓΘ
Έ“‘Ύ¥σΕΰΒΡ ±ΚρΗ’ΩΣ ΦΫ”¥ΞΡΎΚΥΘ§ΨΆΖΗΝΥ’βΗω¥μΈσΘ§“ΜΆΖ‘ζΒΫΡΎ¥φΙήάμάοΆΖΘ§»ΞΩ¥Ζ«≥ΘΒΉ≤ψΒΡ Βœ÷¥ζ¬κΘ§Υδ»Μ“≤ «Ϋ®ΝΔ‘ΎΡΎ¥φΙήάμΒΡ…ηΦΤΥΦœκΒΡΜυ¥Γ…œΘ§ΒΪ «œύΕ‘ά¥ΥΒΘ§±»ΫœΙ¬ΝΔΘ§“ρΈΣ¥Υ ±≤ΔΟΜ”–―ßœΑΤδΥϋΉ”œΒΆ≥Θ§”ΠΗΟΥΒΈό¬έ « ”“ΑΜΙ «ΥΦœκΘ§ΕΦ±»ΫœœΝΑ·Θ§Υυ“‘¥ζ¬κ÷–«Θ…φΒΫΒΡΤδΥϋΉ”œΒΆ≥ΒΡ Βœ÷Έ“ΕΦ÷±Ϋ”ΧχΙΐΝΥΘ§’β“ΜΒψΜΙΥψ¥œΟςΘ§Β±»Μ“≤ «Τ»≤ΜΒΟ“―ΒΡΓΘ
Έ“ΒΡ―ßœΑΖΫΖ®
Η’ΩΣ ΦΘ§Έ“»œΈΣ÷ς“ΣΒΡΈ Χβ‘Ύ”ΎΡψ÷ΣΒά≤Μ÷ΣΒάΘ§Εχ≤Μ «άμΫβ≤ΜάμΫβΘ§Ρ≥ΗωΉ”œΒΆ≥ΒΡ Βœ÷≤…”ΟΝΥΡ≥÷÷≤Ώ¬‘ΓΔΖΫΖ®Θ§ΕχΡψ‘Ύ―ßœΑ÷––η“ΣΉωΒΡΨΆ «÷ΣΒά”–’βΟ¥“ΜΜΊ ¬ΕυΘ§»ΜΚσ≤≈ «άμΫβΥυΟη ωΒΡ≤Ώ¬‘Μρ’ΏΖΫΖ®ΓΘ
ΗυΨίΉ‘ΦΚΒΡ―ßœΑΨ≠―ιΘ§Η’ΩΣ Φ―ßœΑΡΎΚΥΒΡ ±ΚρΘ§Έ“»œΈΣ“ΣΉωΒΡ «‘ΎΉ‘ΦΚΒΡΡ‘ΚΘ÷–Ϋ®ΝΔΤπΡΎΚΥΒΡ¥σΧεΩρΦήΘ§άμΫβΗςΗωΉ”œΒΆ≥ΒΡ…ηΦΤάμΡνΚΆΙΙΫ®ΥΦœκΘ§’β–©άμΡνΚΆΥΦœκΜα¥”ΚξΙέ…œ≥ œΉΗχΡψ«εΈζΒΡ¬ω¬γΘ§ΨΆœώ“ΜΗω»Ξ≥ΐΝΥ÷Π÷Π“Ε“ΕΒΡ¥σ ςΒΡ÷ςΗ…Θ§“ΜΡΩΝΥ»ΜΘΜΒ±»ΜΘ§ΩœΕ®ΜΙΜα…φΦΑΒΫΨΏΧεΒΡ Βœ÷ΖΫΖ®ΓΔΚ· ΐΘ§ΒΪ «¥Υ ±Ϋ”¥ΞΒΫΒΡΚ· ΐΜρ’ΏΖΫΖ®ΈΜ”ΎΡΎΚΥ Βœ÷ΒΡΫœΗΏΒΡ≤ψ¥ΈΘ§ «÷ςΘ®“ΣΘ©Κ· ΐΘ§“―Ψ≠ΝΥΫβΒΫ’β–©Κ· ΐΘ§’κΕ‘ΒΡ «ΡΡ–©…ηΦΤΥΦœκΘ§ Βœ÷ΝΥ ≤Ο¥―υΒΡΙΠΡήΘ§¥ο≥…ΝΥ ≤Ο¥―υΒΡΡΩΒΡΘ§ΜλΗωΝ≥ λΒΡΥΒΖ®‘Ύ’βΕυ“≤ «≥…ΝΔΒΡΓΘ÷Ν”ΎΗΟ÷ςΚ· ΐΥυΒς”ΟΒΡΤδΥϋΒΡΗ®÷ζ–‘Κ· ΐΨΆΒ»Ά§”Ύ÷Π÷Π“Ε“ΕΝΥΘ§≤Μ±ΊΧΪ‘γΨΆ»Ξ…νΨΩΓΘ¥Υ ±Θ§“≤ΨΆ≥θ≤ΫΫ®ΝΔΤπΝΥΡΎΚΥΉ”œΒΆ≥ΩρΦήΚΆ¥ζ¬κ Βœ÷÷°ΦδΒΡΙΊΝΣΘ§ΙΊΝΣΤδ ΒΚήΦρΒΞΘ§±»»γ“ΜΩ¥ΒΫΡ≥ΗωΚ· ΐΟϊΉ÷Θ§ΨΆœκΤπ’βΗωΚ· ΐ «’κΕ‘ΡΡΗωΉ”œΒΆ≥ΒΡΘ§ Βœ÷ΝΥ ≤Ο¥ΙΠΡήΓΘ
Έ“»œΈΣ¥Υ ±“ΣΩ¥ΒΡΨΆ «LKD3Θ§’β±Ψ ιΥψ «ΖΚΖΚΕχΧΗΘ§÷ς“ΣΨΆ «¥”Η≈ΡνΘ§…ηΦΤΘ§¥σΒΡ Βœ÷ΖΫΖ®…œΟη ωΗςΗωΉ”œΒΆ≥Θ§ΕχΕ‘”ΎΨΏΧεΒΡœύΙΊΒΡΚ· ΐ Βœ÷ΒΡ¥ζ¬κΫ≤ΫβΚή…Ό…φΦΑ(Ε‘±»”ΎULK3Θ§¥Υ ι÷ς“ΣΨΆ «ΙΊ”ΎΨΏΧεΚ· ΐ¥ζ¬κΒΡΨΏΧε Βœ÷ΒΡ…ν»κΖ÷ΈωΘ§Β±»ΜΘ§Ρψ“≤Ω…“‘Ω¥Θ§ΒΪ «Ιΐ‘γΩ¥’β±Ψ ιΘ§ΜαΗ–ΨθΚήΆ¥ΩύΘ§ΚήΩί‘οΈόΈΕΘ§Μυ±Ψ…œΕΦ «Κ· ΐΒΡ Βœ÷)Θ§Κή…ΌΘ§ΒΪ≤Μ «ΟΜ”–Θ§’βΨΆΚήΚΟΘ§¬ζΉψΈ“ϫ±«ΑΒΡ–η«σΘ§ΜΙ±ήΟβΈ“Ο«Ιΐ‘γ…ν»κΒΫ ΒΦ ΒΡ¥ζ¬κ÷–»ΞΓΘΕχ«“±Ψ ι‘Ύ“Μ–©÷Ί“ΣΒΡΒψ…œΜΙΗχ≥ωΝΥ–¥≥Χ–ρ ±ΒΡΉΔ“β ¬œνΘ§Υψ «÷ΗΒΦ–‘Ϋ®“ιΓΘ÷ς“ΣΒΡΉ”œΒΆ≥Αϋά®ΘΚΡΎ¥φΙήάμΘ§Ϋχ≥ΧΙήάμΚΆΒςΕ»Θ§œΒΆ≥Βς”ΟΘ§÷–ΕœΚΆ“λ≥ΘΘ§ΡΎΚΥΆ§≤ΫΘ§ ±ΦδΚΆΕ® ±ΤςΙήάμΘ§–ιΡβΈΡΦΰœΒΆ≥Θ§ΩιI/O≤ψΘ§…η±ΗΚΆΡΘΩιΓΘΘ®’βάοΒΡœ»ΚσΥ≥–ρΤδ ΒΨΆ «LKD3ΒΡΡΩ¬ΦΒΡΥ≥–ρΘ©ΓΘ
Έ“―ßœΑΒΡ ±Κρ «»ΐ±Ψ ιΫΜ≤φΉ≈Ω¥ΒΡΘ§œ»Ω¥LKD3Θ§Ή®”Ύ“ΜΗωΉ”œΒΆ≥Θ§÷ς“ΣΨΆ «ΝΥΫβ…ηΦΤΒΡ‘≠άμΚΆΥΦœκΘ§Β±»Μ“≤Μα≈ωΒΫΕ‘“Μ–©÷ς“ΣΚ· ΐΒΡΫι…ήΘ§ΒΪ¥σΕύΨΆ «ΗΟΚ· ΐΜυ”Ύ«ΑΟφΫι…ήΒΡΥΦœκΚΆ‘≠άμΆξ≥…ΝΥ ≤Ο¥―υΒΡΙΠΡήΘ§ΗΟ ι≤ΔΟΜ”–ΨΆΚ· ΐ±Ψ…μΒΡ Βœ÷Ϋχ––…ν»κΤ ΈωΓΘ»ΜΚσ‘ΌΩ¥ULK3ΚΆPLKA…œΩ¥Ά§―υΒΡΉ”œΒΆ≥Θ§ΒΪ «≤Δ≤ΜΉ–œΗΖ÷ΈωΒΉ≤ψΨΏΧεΚ· ΐΒΡ¥ζ¬κΘ§÷Μ «¥÷¬‘ΒΊΓΔ≤Μ«σ…θΫβΒΊΩ¥Θ§…θ÷Ν≤ΜΩ¥ΓΘ“ρΈΣΘ§”––© ±ΚρΘ§‘ΎΤδ÷–“Μ±Ψ ιΒΡΡ≥ΗωΒψ…œΘ§Ω®Ω«ΝΥΘ§≤Μ «ΚήάμΫβΝΥΘ§‘ΎΝμΆβΒΡ ι…œΡψΩ…ΡήΨΆ≈ωΒΫΕ‘Ά§“ΜΗωΈ ΧβΒΡ≤ΜΆ§Ϋ«Ε»ΒΡΟη ωΘ§ΥΒ≤ΜΉΦΡΡΨδΜΑΨΆΡή»ΟΡψΜμ»ΜΩΣά Θ§»γθ°θ≠ΙύΕΞΓΘΈ“Ψ≠≥Θ≈ωΒΫ’β÷÷«ιΩωΓΘ
≤Δ≤Μ «ΥΒ―ßœΑΙΐ≥Χ÷–Ε‘“Μ–©Κ· ΐΧεΒΡ Βœ÷Άξ»ΪΨΆΚω¬‘ΒτΘ§÷Μ“ΣΉ‘ΦΚœκ≥ΙΒΉΝΥΫβΤδ¥ζ¬κ Βœ÷Θ§ΟΜ”–Υ≠ΜαΉη÷ΙΡψΓΘΈ“ «‘ΎΖ¥Η¥‘ΡΕΝΙΐ≥Χ÷–¬ΐ¬ΐ…ν»κΒΡΓΘ±»»γVFS÷–ΈΡΦΰ¥ρΩΣ–η“ΣΕ‘¬ΖΨΕΫχ––Ζ÷ΈωΘ§–η“ΣΩΦ¬«ΒΡœΗΫΎ≤Μ…Ό(.././÷°άύΒΡ)Θ§ΒΪ «Τδ¥ζ¬κ Βœ÷ «ΚήΚΟάμΫβΒΡΓΘ‘Ό±»»γΘ§CFSΒςΕ»÷–ΗυΨίshedule latencyΓΔΕ”Ν–÷–Ϋχ≥ΧΗω ΐΦΑΤδnice÷Β( Ι”ΟΒΡ «Ε·Χ§”≈œ»ΦΕ)ΦΤΥψ≥ωΖ÷≈δΗχΫχ≥ΧΒΡ ±ΦδΤ§Θ§ΟΜάμ”…≤ΜΩ¥ΒΡΘ§’βΗωΧΪ÷Ί“ΣΝΥΘ§Εχ«““≤Κή”–“βΥΦΓΘ
ULK3“≤Μα”–…ηΦΤ‘≠άμ”κΥΦœκ÷°άύΒΡΗ≈ά®–‘Ϋι…ήΘ§Μυ±Ψ…œΕΦΈΜ”ΎΡ≥Ηω÷ςΧβΒΡΩΣΤΣΕΈ¬δΓΘΒΪ «ΗϋΕύΒΡ «Ε‘÷ß≥÷ΗΟ‘≠άμΚΆΥΦœκΒΡ÷ς“ΣΚ· ΐ Βœ÷ΒΡΨΏΧεΖ÷ΈωΘ§Ά§―υ‘Ύ ΉΕΈΘ§“ΜΨδΜΑΉέ ωΚ· ΐΒΡΙΠΡήΘ§»ΜΚσΕ‘Κ· ΐΒΡ Βœ÷“‘1ΓΔ2ΓΔ3Θ§Μρ’ΏaΓΔbΓΔc≤Ϋ÷ηΒΡ–Έ ΫΫχ––Ϋ≤ΫβΓΘΈ“÷Μ «”–―Γ‘ώ–‘ΒΡΩ¥Θ§”– ±ΚρΕ‘’’Ή≈”Οsource insight¥ρΩΣΒΡ‘¥¬κΘ§»Ζ»œ“Μœ¬¥ζ¬κ¥σΧε…œ»Ζ Β «Α¥ ι÷–ΥυΟη ωΒΡ≤Ϋ÷η Βœ÷ΒΡΘ§ΨΆΒ± «‘ωΦ”Η––‘»œ ΕΓΘ”…”Ύ≤Ϋ÷η÷–≤τ‘”Ή≈Ης÷÷’κΕ‘≤ΜΆ§ Βœ÷ΡΩΒΡΑ≤»Ϊ–‘ΓΔ”––ß–‘Φλ≤ιΘ§»γΙϊ≤ΜάμΫβΨΆœ»ΧχΙΐΓΘ’β≤Δ≤ΜΖΝΑ≠ΡψΕ‘Κ· ΐΧεΙΠΡή Βœ÷ΒΡ’ϊΧεΑ―Έ’ΓΘ
PLKAΫι”ΎLKD3ΚΆULK3÷°ΦδΓΘΈ“ΨθΒΟPLKAΒΡΉς’ΏΘ®Ω¥’’Τ§Θ§’φ“ΜΒ¬ΙζΥß–ΓΜοΘ§ΦΦ θ»γ¥ΥΝΥΒΟΘ©ΩœΕ®Ω¥ΙΐULKΘ§Έό¬έΥϊΒΡ±Ψ“βΜΙ «”–“βΘ§Ήή÷°PLKAΜΙ «ΗζULK”–Υυ≤ΜΆ§Θ§Ε‘Κ· ΐΒΡΉ–œΗΫ≤ΫβΕΦΉω≤Ι≥δΥΒΟςΘ§»ΞΒτΚ· ΐΧε÷–±Ώ±ΏΫ«Ϋ«ΒΡ«ιΩωΘ§±»»γ“Μ–©ΧΊ β«ιΩωΒΡ¥ΠάμΘ§”––ß–‘Φλ≤ιΒ»Θ§Εχ≤ΜΖΝΑ≠Ε‘’ϊΗωΚ· ΐΧεΙΠΡήΒΡάμΫβΘ§’β–©ΥϊΕΦ”–ΥυΫΜ¥ζΘ§ΉωΝΥ…υΟςΘΜΕχ«“Θ§ΨΆœώLKD3“Μ―υΘ§‘ΎΡ≥–©Βψ…œ“≤Ηχ≥ωΝΥ÷ΗΒΦ–‘±ύ≥ΧΫ®“ιΓΘΉς’ΏΟ«…θ÷ΝΕ‘Ά§“ΜΗω÷ς“ΣΚ· ΐΒΡΫ≤ΫβΒΡΉ≈÷ΊΒψΕΦ≤Μ“Μ―υΓΘ’β―υΒΡΜΑΘ§Ε‘Έ“Ο«―ßœΑΒΡ»ΥΕχ―‘Θ§”–÷ζ”ΎΦ”…νάμΫβΓΘΝμΆβΘ§Έ“»œΈΣΚή÷Ί“ΣΒΡ“ΜΒψΨΆ «PLKA’κΕ‘ΒΡ2.6.24ΒΡΡΎΚΥΑφ±ΨΘ§ΕχULK «2.6.11Θ§LKD3 «2.6.34ΓΘ‘ΎΡ≥–©ΖΫΟφPLKA±»ΫœΫ”Ϋϋœ÷¥ζΒΡ Βœ÷ΓΘΤδ ΒΉς’ΏΟ«÷°Υυ“‘Ζ÷±π―Γ‘ώ11Μρ’Ώ24Θ§ΕΦ «“ρΈΣ‘ΎΑφ±ΨΖΔ–– ς÷–Θ§’βΝΫΗωΑφ±Ψ‘ΎΡ≥–©ΖΫΟφΕΦΉωΝΥ≤Μ–ΓΒΡ±δΕ·Θ§Μρ’ΏΥΒ «ΨΏ”–±ξ÷Ψ–‘ΒΡΉΣ’έΒψΘ®’β–©–≈œΔ¥σΕύ «‘Ύ ι÷–ΒΡ“ΐ―‘≤ΩΖ÷Ϋι…ήΒΡΘ§ΨΏΧεΒΡœΗΫΎΈ“œκ≤ΜΤπά¥ΝΥΘ©ΓΘ
Intel V3Θ§’κΕ‘X86ΒΡCPUΘ§±Ψ ιΉ‘»Μ «œΒΆ≥±ύ≥ΧΒΡ»®ΆΰΓΘΡΎΚΥ≤ΩΖ÷ Βœ÷ΕΦΩ…“‘‘Ύ±Ψ ι’“ΒΫΤδΗυ‘¥ΓΘΥυ“‘Θ§‘ΎΕΝ“‘…œ»ΐ±Ψ ιΡ≥ΗωΉ”œΒΆ≥ΒΡ ±ΚρΘ§≤Μ“ΣΆϋΦ«Ω…“‘‘ΎV3÷–œύ”Π’¬ΫΎ’“ΒΫ“Μ–©Μυ¥Γ–‘÷ß≥≈–≈œΔΓΘ
‘ΎΕΝ ιΙΐ≥Χ÷–Θ§Μα≤ζ…ζœύΒ±ΕύΒΡ“…Έ Θ§’β“ΜΒψ «»Ζ–≈Έό“…ΒΡΓΘ¥σΒΫΗψ≤ΜΟςΑΉ“ΜΗω…ηΦΤΥΦœκΘ§–ΓΒΫ≤ΜάμΫβΡ≥––¥ζ¬κΒΡ”ΟΆΨΓΘΗςΗωΖΫΟφΘ§Ης÷÷“…Έ Θ§ΡψΆξ»ΪΩ…“‘Α―≤ΜάμΫβΒΡΒΊΖΫΕΦΦ«¬Φœ¬ά¥(≤ΜΙΐΘ§Έ“≤ΔΟΜ”–’βΟ¥ΉωΘ§ΟΜ”–Α―“…Έ »Ϊ≤ΩΦ«œ¬ά¥Θ§÷Μ±ξΦ«ΝΥΚή…Ό“Μ≤ΩΖ÷Έ“»œΈΣΚήΙΊΦϋΒΡΦΗΗωΈ Χβ)Θ§Ή®Ο≈–¥ΒΫ“Μ’≈÷Ϋ…œΘ§≤ΜΕ‘Θ§“ΜΗω±Ψ…œΘ§Έ“»Ζ–≈Μα≤ζ…ζ’βΟ¥ΕύΒΡ“…Έ Θ§≤Μ»ΜΡΎΚΥœύΙΊΒΡ¬έΧ≥‘γΨΆΩ…“‘ΙΊ±’ΝΥΓΘΤδ ΒΘ§¥σ≤ΩΖ÷ΒΡΈ ΧβΘ®Τδ÷–ΚήΕύΈ ΧβΕΦ «Ρψ÷ΣΒά≤Μ÷ΣΒά”–’βΟ¥“ΜΜΊ ¬ΒΡΈ ΧβΘ©ΕΦΩ…“‘”≠»–ΕχΫβΘ§÷Μ“ΣΡψΩœΜΊΆΖ‘ΌΩ¥Θ§ ιΕΝΑΌ±ιΘ§Τδ“εΉ‘œ÷ΓΘΕύΩ¥ΦΗ±ιΘ§«Α«ΑΚσΚσΒΡΝΣœΒΟςΑΉΗωΤΏΤΏΑΥΑΥ «ΟΜ”–Έ ΧβΒΡΓΘΈ““≤’βΟ¥ΉωΝΥΘ§’κΕ‘Ρ≥–©Ή”œΒΆ≥“≤Ω¥ΝΥΚΟΦΗ±ιΘ§«–…μΧεΜαΓΘ
Β±ΡψΑ¥Υ≥–ρ―ßœΑ’β–©Ή”œΒΆ≥ΒΡ ±ΚρΘ§«ΑΟφΒΡ’¬ΫΎΚήΩ…ΡήΜα“ΐ”ΟΚσΟφΒΡ’¬ΫΎΘ§ΨΆœώPLKAΒΡΉς’ΏΥΒΒΡΡ«―υΘ§Άξ»ΪΟΜ”–œρΚσ“ΐ”Ο «≤ΜΩ…ΡήΒΡΘ§ΥϊΡήΉωΒΡ÷Μ «ΨΓΝΩΦθ…Ό’β÷÷“ΐ”ΟΕχ”÷≤ΜΥπΚΠΡψΕ‘Β±«ΑΈ ΧβΒΡάμΫβΓΘ≤ΜάμΫβΘ§ΟΜΙΊœΒΘ§ΧχΙΐΨΆ––ΝΥΓΘΚσΟφΒΡ’¬ΫΎΆ§―υΜα”–œρ«Α’¬ΫΎΒΡ“ΐ”ΟΘ§≤ΜΙΐ’βΗωΈ ΧβΨΆΦρΒΞ“Μ–©ΝΥ Θ§ΡψΩ…“‘‘ΌΜΊΆΖ»ΞΩ¥œύ”ΠΒΡΫι…ήΘ§Β± ±Ρψ≤ΜΧΪάμΫβΒΡΕΪΈςΘ§ΚήΩ…Ρή’βΗω ±ΚρΨΆ÷ΣΒάΝΥΥϋΒΡ…ηΦΤΒΡΡΩΒΡ“‘ΦΑΨΏΧεΒΡ”Π”ΟΓΘ≤Μ«σ…θΫβ÷Μ «‘ί ±ΒΡΓΘ±»»γΥΒΘ§ΡΎΚΥΗςΗωΉ”œΒΆ≥÷°ΦδΒΡΫΜΜΞΚΆ“ΐ”Ο‘Ύ¥ζ¬κ÷–ΒΡΧεœ÷ΨΆ « Βœ÷Κ· ΐ¥©≤εΒς”ΟΘ§±»»γΡψ‘ΎΡΎ¥φΙήάμ’¬ΫΎ―ßœΑΝΥΒΡΡΎ¥φΖ÷≈δΚΆ ΆΖ≈ΒΡΚ· ΐΘ§ΕχΡψ «ΝΥΫβΡΎ¥φ‘Ύœ»ΒΡΘ§‘Ύ―ßœΑ«ΐΕ·Μρ’ΏΡΘΩιΒΡ ±ΚρΨΆΜα≈ωΒΫ’β–©Κ· ΐΒΡΒς”ΟΘ§’β―υ“≤ΨΆ±»Ϋœ»ί“ΉΫ” ήΘ§≤Μ÷Ν”ΎΧΪΙΐΟΘ»ΜΘΜ‘Ό±»»γΘ§ΡψΝΥΫβΝΥœΒΆ≥ ±ΦδΚΆΕ® ±ΤςΒΡΙήάμΘ§‘ΌΜΊΆΖΩ¥÷–ΕœΚΆ“λ≥Θ÷–bottom halfΒΡΒςΕ» Βœ÷Θ§ΡψΕ‘ΥϋΒΡάμΫβΨΆΜαΦ”…ν“Μ≤ψΓΘ
Ή”œΒΆ≥Ϋχ––ΙήάμΙΛΉς–η“Σ¥σΝΩΒΡ ΐΨίΫαΙΙΓΘ
Ή”œΒΆ≥÷°ΦδΫΜΜΞΒΡ“Μ÷÷ΖΫ ΫΨΆ «ΗςΗωΉ”œΒΆ≥ΗςΉ‘ΒΡ÷ς“Σ ΐΨίΫαΙΙΆ®Ιΐ÷Η’κ≥…‘±œύΜΞ“ΐ”ΟΓΘ―ßœΑΙΐ≥Χ÷–Θ§≤ΈΩΦ ι…œ‘ΎΫ≤ΫβΡ≥ΗωΉ”œΒΆ≥ΒΡ ±ΚρΜαΕ‘ ΐΨίΫαΙΙ÷–÷ς“Σ≥…‘±ΒΡ”ΟΆΨΫβ Ά“Μœ¬Θ§ΒΪΩœΕ®≤ΜΜαΗ≤Η«»Ϊ≤ΩΘ®≥…‘±±»ΫœΕύΒΡ«ιΩωΘ§άΐ»γtask_structΘ©Θ§Ε‘ΤδΥϋΉ”œΒΆ≥Μυ”ΎΡ≥ΗωΙΠΡή Βœ÷ΒΡ“ΐ”ΟΩ…ΡήΫβ ΆΝΥΘ§“≤Ω…ΡήΟΜΉωΫβ ΆΘ§ΜΙΩ…ΡήΥΒ’βΗω±δΝΩ‘ΎΚΈ¥ΠΜαΉωΫχ“Μ≤ΫΥΒΟςΓΘΥυ“‘Θ§≤Μ“ΣΨάΫα”Ύ“ΜΗω≤ΜάμΫβΒΡΒψ…œΘ§‘ί«“Ζ≈ΙΐΘ§ΜΊΆΖΜΙΩ…“‘Ω¥ΒΡΓΘ÷°ΦδΒΡΝΣœΒΩ…“‘‘ΎΕ‘ΗςΗωΉ”œΒΆ≥ΕΦ”–ΥυΝΥΫβ÷°Κσ‘ΌΫ®ΝΔΤπά¥ΓΘΤδ ΒΘ§Έ“»‘»Μ‘Ύ«ΩΒςœ»άμΫβΗ≈ΡνΚΆΩρΦήΒΡ÷Ί“Σ–‘ΓΘ
Β»Έ“Ο«Άξ≥…ΝΥΫ®ΝΔΩρΦή’β“Μ≤ΫΘ§ΨΆΩ…“‘―Γ‘ώ“ΜΗω±»ΫœΗ––Υ»ΛΒΡΉ”œΒΆ≥Θ§±»»γ«ΐΕ·ΓΔΆχ¬γΘ§Μρ’ΏΈΡΦΰœΒΆ≥÷°άύΒΡΓΘ’βΗω ±ΚρΡψ‘Ό»Ξ…ν»κΝΥΫβΒΉ≤ψ¥ζ¬κ Βœ÷Θ§œύΫœ”Ύ“ΜΩΣ ΦΨΆΉξ―–¥ζ¬κΘ§Ηϋ»ί“Ή“Μ–©Θ§Εχ«“≈ωΒΫΝΥ≤ΜΫβ÷°¥ΠΘ§Μρ’ΏΆϋΦ«ΝΥΡ≥ΗωΖΫΟφΒΡ Βœ÷Θ§¥Υ ±ΡψΆξ»ΪΩ…“‘’“ΒΫœύ”ΠΒΡΉ”œΒΆ≥Θ§“ρΈΣΡψ÷ΣΒά‘ΎΡΡ»Ξ’“Θ§≤鬩≤Ι»±Θ§≤ΜΫωΆξ≥…ΝΥΕ‘Β±«ΑΚ· ΐΒΡΉξ―–Θ§Εχ«“Ω…“‘ΜΊΙΥΓΔΈ¬œΑ“‘«ΑΒΡΡΎ»ίΘ§»ΎΜαΙαΆ®ΒΡ ±ΜζΨΆ‘Ύ’βάοΝΥΓΘ
ΓΕ…ν»κάμΫβlinux–ιΡβΡΎ¥φΓΖ(2.4ΡΎΚΥΑφ±Ψ)Θ§LDD3Θ§ΓΕ…ν»κάμΫβlinuxΆχ¬γΦΦ θΡΎΡΜΓΖΘ§ΦΗΚθΟΩ“ΜΗωΉ”œΒΆ≥ΕΦ–η“Σ“Μ±Ψ ιΒΡ»ίΝΩ»ΞΫ≤ΫβΘ§Υυ“‘ΥΒΘ§Η’ΩΣ Φ―ßœΑ≤Μ“ΥΕ‘Ρ≥ΗωΡΘΩιΧΪΙΐ…ν»κΘ§Β»Ε‘ΗςΗωΉ”œΒΆ≥ΕΦ”–ΥυΝΥΫβΝΥΘ§‘Ό”–’κΕ‘–‘ΒΡ»Ξ―ßœΑ“ΜΗωΧΊΕ®ΒΡΉ”œΒΆ≥ΓΘ’β ±ΚρΕ‘ΤδΥϋœΒΆ≥ΒΡ‘°“ΐΕΦΩ…“‘»ΟΈ“Ο«≤Μ‘ΌΗ–ΒΫΟΘ»ΜΓΔΗ¥‘”Θ§≤Μ÷ΣΥυ‘ΤΓΘ
±»»γΘ§LDD3÷–ΒΡ“‘œ¬ΥυΝ–’¬ΫΎΘΚΙΙ‘λΚΆ‘Υ––ΡΘΩιΘ§≤ΔΖΔΚΆΨΚΧ§Θ§ ±ΦδΓΔ―”≥ΌΦΑ―”ΜΚ≤ΌΉς,Ζ÷≈δΡΎ¥φΘ§÷–Εœ¥ΠάμΒ»Θ§ΕΦ τ”Ύ«ΐΕ·ΩΣΖΔΒΡ÷ß≥≈–‘Ή”œΒΆ≥Θ§ΥδΥΒ±Ψ ιΕ‘’β–©Ή”œΒΆ≥ΕΦΉ®Ο≈ΩΣ±Ό“ΜΗω’¬ΫΎΫχ––Ϋ≤ΫβΘ§ΒΪ «œξœΗ≥ΧΕ»‘θΟ¥Ρή±»ΒΟ…œPLKAΘ§ULK3Θ§LKD3’β»ΐ±Ψ ιΘ§Ω¥Άξ’β»ΐ±Ψ ιΘ§ΡψΜαΖΔœ÷ΕΝLDD3’β–©’¬ΫΎΒΡ ±ΚρΦρ÷±ΗζΚ»ΑΉΩΣΥ°“Μ―υΘ§ΧΪΥφ“βΝΥΘ§“ρΈΣLDD3ΒΡΫ≤Ϋβ±»÷°LKD3Ηϋ¥÷¬‘ΓΘ¥ρΚΟΝΥΜυ¥ΓΘ§PCIΓΔUSBΓΔTTY«ΐΕ·Θ§Ωι…η±Η«ΐΕ·Θ§ΆχΩ®«ΐΕ·Θ§–η“ΣΝΥΫβΚΆ―ßœΑΒΡΕΪΈςΨΆ±»Ϋœ”–’κΕ‘–‘ΝΥΓΘ’β–©Ή”œΒΆ≥ΨΆ τ”ΎΆ®”ΟΉ”œΒΆ≥Θ§ΝΥΫβ÷°ΚσΘ§Μυ”Ύ’β–©Ή”œΒΆ≥ΒΡΉ”œΒΆ≥ΒΡΩΣΖΔΓΣ«ΐΕ·(–ηΫχ“Μ≤Ϋ’κΕ‘”≤ΦΰΧΊ–‘)ΚΆΆχ¬γ(–ηΫχ“Μ≤ΫάμΫβΗς÷÷–≠“ι)ΓΣœύΕ‘Εχ―‘Θ§Τδ―ßœΑΡ―Ε»¥σ¥σΫΒΒΆΘ§―ßœΑΫχΕ»¥σ¥σΦ”ΩλΘ§―ßœΑ–߬ ¥σ¥σΧα…ΐΓΘΥΒΉ≈»ί“ΉΉωά¥Ρ―ΓΘ¥οΒΫ’β―υ“Μ÷÷–ßΙϊΒΡ«ΑΧαΨΆ «ΘΚ±Ί–κΒΟΨ≤œ¬–Ρά¥Θ§»œ’φΕΝ ιΘ§“ΣΩ¥ΒΟΫχ»ΞΘ§PLKAΘ§ULK3ΚώΒΟΕΦΗζΉ©ΆΖΩιΕυ“Μ―υΘ§Νν»ΥΆϊ÷°…ζΈΖΘ§»γΙϊΟΜ”––Υ»ΛΘ§ΟΜ”–»»«ιΘ§ΟΜ”–“ψΝΠΘ§Έό¬έ»γΚΈΕΦ «≤Μ––Θ§“ρΈΣ–η“Σ ±ΦδΘ§–η“ΣΚή≥Λ ±ΦδΓΘΈ“≤Δ≤Μ «ΥΒ±Ί–κ¥ρΚΟΝΥΜυ¥Γ≤≈Ω…“‘Ϋχ––«ΐΕ·ΩΣΖΔΘ§÷Μ «ΥΒ¥ρΚΟΝΥΜυ¥ΓΒΡ«ιΩωœ¬Ϋχ––ΩΣΖΔΜαΗϋ«αΥ…Θ§Ηϋ”––߬ Θ§Εχ«“Ή‘ΦΚΕ‘ΡΎΚΥ¥ζ¬κΒΡΦί‘ΠΡήΝΠΜαΗϋ«Ω¥σΓΘ’β÷Μ «Έ“Ηω»ΥΦϊΫβΘ§Έ“Ή‘ΦΚΒΡ―ßœΑΖΫ ΫΘ§ΫωΙ©≤ΈΩΦΓΘ
”ο―‘
PLKA «ΗωΒ¬Ιζ»Υ”ΟΒ¬”ο–¥ΒΡΘ§Κσά¥Ζ≠“κ≥…”ΔΈΡΘ§”÷¥””ΔΈΡΖ≠“κ≥…÷–ΈΡΘ§Έ“‘ΎΆχ…œ ιΒξάοΟΜ”–’“ΒΫΥϋΒΡ÷Ϋ÷ ”ΔΈΡΑφΘ§Υυ“‘ΨΆ¬ρΝΥ÷–ΈΡΑφΒΡΓΘULK3ΚΆLKD3ΕΦ «”ΔΈΡΑφΒΡΓΘ¥σ≈ΘΟ«–¥ΒΡ ιΘ§«≤¥ ‘λΨδ’φΒΡ «ΦρΫύΘ§“ΉΕ°Θ§Ω¥‘≠ΑφΕ‘Έ“Ο«―ßœΑΦΤΥψΜζ±ύ≥ΧΒΡ≥Χ–ρ‘±ά¥ΥΒΆξ»Ϊ≤Μ≥…Έ ΧβΘ§ΉνΚΟ‘≠÷≠‘≠ΈΕΓΘ»γΙϊ“Μ±Ψ ι»Ζ ΒΖ≠“κΒΊΚήΚΟΘ§Έ“ϫ±»ΜΩ…“‘Ω¥÷–ΈΡΑφΒΡΘ§”ΟΡΗ”οΫχ––―ßœΑΘ§άμΫβΥΌΕ»ΚΆ―ßœΑΫχΕ»Β±»Μ «ΚήΩλΒΡΘ§≤ΜΉςΥϊœκΓΘΩ¥”ΔΈΡΒΡ ±Κρ≤Μ“ΣΡ‘Ή”άοœκΉ≈Α―ΥϊΖ≠“κ≥…÷–ΈΡΘ§ΟΜ±Ί“ΣΓΘ
APIΗ–œκ
ΓΑ±»Τπ÷ΣΒάΡψΥυ”ΟΦΦ θΒΡ÷Ί“Σ–‘Θ§≥…ΈΣΡ≥“ΜΗωΧΊ±πΝλ”ρΒΡΉ®Φ“ «≤Μ÷Ί“ΣΒΡΓΘ÷ΣΒάΡ≥“ΜΗωΨΏΧεAPIΒς”Ο“ΜΒψΚΟ¥ΠΕΦΟΜ”–Θ§Β±Ρψ–η“ΣΥϊΒΡ ±Κρ÷Μ“Σ≤ι―·œ¬ΨΆΚΟΝΥΓΘΓ±’βΨδΜΑ‘¥”ΎΈ“Ω¥ΒΫΒΡ“ΜΤΣΖ≠“κΙΐά¥ΒΡ≤©ΩΆΓΘΈ“œκ«ΩΒςΒΡΨΆ «Θ§’βΨδΜΑ’κ”Π”Ο–Ά±ύ≥Χ‘ΌΚœ ≤ΜΙΐΘ§ΒΪ «ΡΎΚΥAPIΨΆ≤ΜΆξ»Ϊ»γ¥ΥΓΘ
ΡΎΚΥœύΒ±Η¥‘”Θ§―ßœΑΤπά¥Κή≤Μ»ί“ΉΘ§ΒΪ «Β±Ρψ―ßœΑΒΫ“ΜΕ®≥ΧΕ»Θ§ΡψΜαΖΔœ÷Θ§»γΙϊΉ‘ΦΚ¥ρΥψ–¥ΡΎΚΥ¥ζ¬κΘ§ΒΫΉνΚσ“ΣΙΊΉΔΒΡ»‘»Μ «APIΫ”ΩΎΘ§÷Μ≤ΜΙΐ’β–©APIΨχ¥σ≤ΩΖ÷ «ΩγΤΫΧ®ΒΡΘ§¬ζΉψΩ…“Τ÷≤–‘ΓΘΡΎΚΥΚΎΩΆΜυ±Ψ…œ“―Ψ≠±ξΉΦΜ·ΓΔΈΡΒΒΜ·ΝΥ’β–©Ϋ”ΩΎΘ§ΡψΥυ“ΣΉωΒΡ÷Μ «Βς”ΟΕχ“―ΓΘΒ±»ΜΘ§‘Ύ Ι”ΟΒΡ ±ΚρΘ§ΉνΚΟΕ‘Ω…“Τ÷≤–‘’β“ΜΜΑΧβ‘ΎΡΎΚΥ÷–ΒΡ±ύ¬κ‘ΦΕ®άΟ λ”Ύ–ΡΘ§’β―υ≤≈Μα–¥≥ωΩ…“Τ÷≤–‘ΒΡ¥ζ¬κΓΘΨΆœώ”Π”Ο≥Χ–ρ“Μ―υΘ§Ω…“‘ Ι”ΟΩΣΖΔ…ΧΧαΙ©ΒΡΕ·Χ§ΩβAPIΘ§Μρ’Ώ Ι”ΟΩΣ‘¥APIΓΘΆ§―υ «Βς”ΟAPIΘ§≤ΜΆ§Βψ‘Ύ”Ύ Ι”ΟΡΎΚΥAPI“Σ±» Ι”Ο”Π”ΟAPIΝΥΫβΒΡΕΪΈς“ΣΕύ≥ω–μΕύΓΘ
Β±ΡψΝΥΫβΝΥ≤ΌΉςœΒΆ≥ΒΡ Βœ÷ΓΣ’β–© Βœ÷Ω…ΕΦ «Ε‘”Π”Ο≥Χ–ρΒΡΜυ¥Γ–‘÷ß≥≈ΑΓΓΣΡψ‘Ό»Ξ–¥”Π”Ο≥Χ–ρΒΡ ±ΚρΘ§”Π”Ο≥Χ–ρ÷–”ΟΒΫΒΡΕύœΏ≥ΧΘ§Ε® ±ΤςΘ§Ά§≤ΫΥχΜζ÷Τ»»»»ȧ Ι”ΟΙ≤œμΩβAPIΒΡ ±ΚρΘ§ΝΣœΒΒΫ≤ΌΉςœΒΆ≥Θ§¥”ΕχΑ―Ε‘ΗΟAPIΒΡΈΡΒΒΟη ωΆ§Ή‘ΦΚΥυΝΥΫβΒΫΒΡ’β–©ΖΫΟφ‘ΎΡΎΚΥ÷–ΒΡœύ”Π÷ß≥≈–‘ Βœ÷ΫαΚœΤπά¥Ϋχ––ΩΦ¬«Θ§’βΜα÷ΗΒΦΡψ―Γ‘ώ Ι”ΟΡΡ“ΜΗωAPIΫ”ΩΎΘ§―Γ≥ω–߬ ΉνΗΏΒΡ Βœ÷ΖΫ ΫΓΘΕ‘œΒΆ≥±ύ≥ΧΤΡ”–ΝΥΫβΒΡΜΑΘ§Ε‘”Π”Ο±ύ≥Χ≤ΜΈό“φ¥ΠΘ§…θ÷ΝΩ…“‘ΥΒ «¥σ”–ΚΟ¥ΠΓΘ
…ηΦΤ Βœ÷ΒΡ±Ψ÷ Θ§÷ΣΒάΜΙ «άμΫβ
≤ΌΉςœΒΆ≥ «Ϋι”ΎΒΉ≤ψ”≤ΦΰΚΆ”Π”Ο»μΦΰ÷°ΦδΒΡΫ”ΩΎΘ§ΤδΗςΗωΉ”œΒΆ≥ΒΡ Βœ÷Κή¥σ≥ΧΕ»…œ“άάΒ”Ύ”≤ΦΰΧΊ–‘ΓΘ ι…œΫι…ή’β–©Ή”œΒΆ≥ΒΡ…ηΦΤΚΆ Βœ÷ΒΡ ±ΚρΘ§Έ“Ο«ΕΝΙΐΝΥΘ§“≤ΨΆ÷ΣΒάΝΥΘ§»γΙϊ‘Ό…ν»κΩΦ¬«“Μœ¬Θ§ΈΣ ≤Ο¥’ϊΧεΦήΙΙ“ΣΑ¥’’’β÷÷ΖΫ ΫΉι÷·Θ§ΈΣ ≤Ο¥Ψ÷≤ΩΚ· ΐ“ΣΉώ―≠’β―υΒΡ≤Ϋ÷η¥ΠάμΘ§÷ΣΤδ»ΜΘ§÷ΣΤδΥυ“‘»ΜΘ§»γΙϊΡψ÷ΣΒάΝΥΡ≥ΗωΙΠΡήΒΡ Βœ÷ «“ρΈΣ–ΨΤ§ΨΆ «’βΟ¥…ηΦΤΒΡΘ§CPUΨΆ «’βΟ¥ΉωΒΡΘ§Ρ«Ο¥ΡψΒΡ“…Έ “≤ΨΆΜυ±Ψ…œΒΫ¥ΥΈΣ÷ΙΝΥΓΘ‘Ό…νΨΩΘ§ΨΆ «–ΨΤ§ΦήΙΙΖΫΟφΒΡ…ηΦΤ”κ Βœ÷Θ§Ε‘”Ύ≥Χ–ρ‘±ά¥Ϋ≤Θ§Έό¬έ «œΒΆ≥ΜΙ «”Π”Ο≥Χ–ρ‘±Θ§ΉψΦΘΧΫΨΩΒΫ’βάοΘ§“―Ψ≠ΫβΨωΝΥΚήΕύ“…Έ Θ§“ρΈΣΈ“Ο«ΒΡΙΛΉς–‘÷ ΤΪ»μΘ§Εχ’β–©ΕΪΈς Β‘Ύ «ΙΜ”≤ΓΘ
±»»γΘ§ULK3÷–Ϋ≤ΫβΒΡ÷–ΕœΚΆ“λ≥ΘΒΡ Βœ÷Θ§ΨΩΤδΗυ‘¥Θ§Ρ« «“ρΈΣIntel x86œΒΝ–ΨΆ «’βΟ¥…ηΦΤΒΡΘ§»ΞΩ¥Ω¥Intel V3 ÷≤α÷–œύ”Π’¬ΫΎΫι…ήΘ§ΕΦΩ…“‘ΈΣULK3÷–Οη ωΒΡ¥ζ¬κ Βœ÷ΖΫ Ϋ’“ΒΫΉΔΫβΓΘΜΙ”– ±ΦδΚΆΕ® ±ΤςΙήάμΘ§Ά§―υΩ…“‘‘ΎIntel V3 Ε‘APICΒΡΫι…ή÷–Μώ»ΓΉψΙΜΒΡ–≈œΔΘ§≤ΌΉςœΒΆ≥ΨΆ «“άΨί’β–©”≤ΦΰΧΊ–‘ά¥ Βœ÷»μΦΰΖΫΖ®Ε®“εΒΡΓΘ
”÷ «Ρ«ΨδΜΑΘ§≤Μ «άμΫβ≤ΜάμΫβΒΡΈ ΧβΘ§Εχ «÷ΣΒά≤Μ÷ΣΒάΒΡΈ ΧβΓΘ”– ±ΚρΘ§÷ΣΒάΝΥΘ§ΨΆάμΫβΝΥΓΘ‘Ύ’ϊΗω―ßœΑΙΐ≥Χ÷–Θ§÷ΣΒάΘ§άμΫβΘ§÷ΣΒάΘ§άμΫβΘ§÷ΣΒάΓ≠Γ≠Θ§ΫΜ≤φΖ¥Η¥ΓΘΈΣ ≤Ο¥ΩΣ ΦΚΆΫαΈ≤ΕΦ «÷ΣΒάΘ§ΕχάμΫβ÷Μ «÷–Φδ≤Ϋ÷ηΡΊΘΩ άΫγ…œΆρ ¬ΆρΈοΉ‘”–ΤδΙφ¬…Θ§»Υάύ÷Μ «ΖΔœ÷Εχ“―Θ§ ΒΦυ «ΒΎ“ΜΈΜΒΡΘ§ ΒΦυΨΆ «÷ΣΒάΒΡΙΐ≥ΧΘ§ ΒΦυ≤ζ…ζΨ≠―ιΘ§Ψ≠―ιΒΡΉήΫαΨΆ «άμ¬έΘ§άμ¬έ‘¥”Ύ ΒΦυΘ§άμ¬έ≤≈–η“ΣάμΫβΓΘΈ“Ο«―ßœΑΡΎΚΥΘ§…ν»κ―–ΨΩΘ§Ηψά¥Ηψ»ΞΘ§”÷ΜΊΒΫΝΥ–ΨΤ§…œΘ§–ΨΤ§ «Έο÷ ΒΡΘ§–ΨΤ§ΒΡΙΠ”ΟΜυ”ΎΉ‘»ΜΫγ÷–Έο÷ ±Ψ”–ΒΡΈοάμΚΆΒγΉ”ΧΊ–‘ΓΘΉΖ±ΨΥί‘¥Θ§¥Υ÷°ΈΫ“≤ΓΘ
Ε· ÷–¥¥ζ¬κ
÷Ϋ…œΒΟά¥÷’Ψθ«≥Θ§Ψχ÷Σ¥Υ ¬“ΣΙΣ––ΓΘ÷ΜΩ¥ ι «ΨχΕ‘≤Μ––ΒΡΘ§“ΜΕ®“ΣΫαΚœΩΈ±ΨΗχ≥ωΒΡ±ύ≥ΧΫ®“ιΉ‘ΦΚ«Ο¥ζ¬κΓΘΗ’ΩΣ ΦΨΆ“‘ΡΘΩι–Έ Ϋ≤β ‘ΚΟΝΥΘ§Μρ’ΏΉ‘ΦΚ±ύ“κ“ΜΗωΩΣΖΔΑφ±ΨΒΡΡΎΚΥΓΘ
“ΜΧ®ΜζΤςΒΡΜΑΘ§ Ι”ΟUMLΖΫ ΫΒς ‘Θ§ΡΎΚΥΩΊ÷Τ¬ΖΉΏΒΫΡΡ“Μ≤ΫΘ§ΒΞ≤ΫΒς ‘Ω¥Ω¥≥Χ–ρ÷¥––Ιΐ≥ΧΘ§±» ι…œΒΡΫ≤ΫβΗϋ÷±ΙέΟςΝΥΓΘ“ΜΕ®“ΣΕ· ÷ ΒΦ ≤ΌΉςΓΘ
|






