| БрМЭЦМі: |
| БОЮФРДздгкcsdnЃЌНщЩмСЫOpenMPжДааФЃЪНЃЌБрвыЦїжИСюЃЌAPIКЏЪ§ЃЌЛЗОГБфСПЃЌOpenMPжаЕФШЮЮёЕїЖШЕШЁЃ |
|
OpenMPЛљБОИХФю
OpenMPЪЧвЛжжгУгкЙВЯэФкДцВЂааЯЕЭГЕФЖрЯпГЬГЬађЩшМЦЗНАИЃЌжЇГжЕФБрГЬгябдАќРЈCЁЂC++КЭFortranЁЃOpenMPЬсЙЉСЫЖдВЂааЫуЗЈЕФИпВуГщЯѓУшЪіЃЌЬиБ№ЪЪКЯдкЖрКЫCPUЛњЦїЩЯЕФВЂааГЬађЩшМЦЁЃБрвыЦїИљОнГЬађжаЬэМгЕФpragmaжИСюЃЌздЖЏНЋГЬађВЂааДІРэЃЌЪЙгУOpenMPНЕЕЭСЫВЂааБрГЬЕФФбЖШКЭИДдгЖШЁЃЕББрвыЦїВЛжЇГжOpenMPЪБЃЌГЬађЛсЭЫЛЏГЩЦеЭЈЃЈДЎааЃЉГЬађЁЃГЬађжавбгаЕФOpenMPжИСюВЛЛсгАЯьГЬађЕФе§ГЃБрвыдЫааЁЃдкVSжаЦєгУOpenMPКмМђЕЅЃЌКмЖржїСїЕФБрвыЛЗОГЖМФкжУСЫOpenMPЁЃдкЯюФПЩЯгвМќ->Ъєад->ХфжУЪєад->C/C++->гябд->OpenMPжЇГжЃЌбЁдёЁАЪЧЁБМДПЩЁЃ
OpenMPжДааФЃЪН
OpenMPВЩгУfork-joinЕФжДааФЃЪНЁЃПЊЪМЕФЪБКђжЛДцдквЛИіжїЯпГЬЃЌЕБашвЊНјааВЂааМЦЫуЕФЪБКђЃЌХЩЩњГіШєИЩИіЗжжЇЯпГЬРДжДааВЂааШЮЮёЁЃЕБВЂааДњТыжДааЭъГЩжЎКѓЃЌЗжжЇЯпГЬЛсКЯЃЌВЂАбПижЦСїГЬНЛИјЕЅЖРЕФжїЯпГЬЁЃ
вЛИіЕфаЭЕФfork-joinжДааФЃаЭЕФЪОвтЭМШчЯТЃК
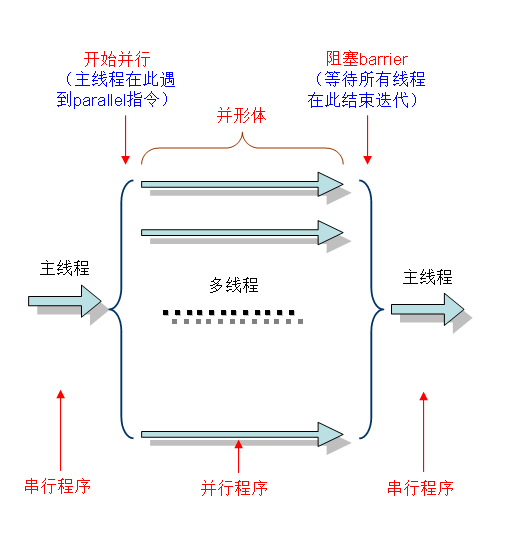
OpenMPБрГЬФЃаЭвдЯпГЬЮЊЛљДЁЃЌЭЈЙ§БрвыжЦЕМжИСюжЦЕМВЂааЛЏЃЌгаШ§жжБрГЬвЊЫиПЩвдЪЕЯжВЂааЛЏПижЦЃЌЫћУЧЗжБ№ЪЧБрвыжЦЕМЁЂAPIКЏЪ§МЏКЭЛЗОГБфСПЁЃ
БрвыЦїжИСю
OpenMPЕФБрвыЦїжИСюЕФФПБъжївЊгаЃК1ЃЉВњЩњвЛИіВЂааЧјгђЃЛ2ЃЉЛЎЗжЯпГЬжаЕФДњТыПщЃЛ3ЃЉдкЯпГЬжЎМфЗжХфбЛЗЕќДњЃЛ4ЃЉађСаЛЏДњТыЖЮЃЛ5ЃЉЭЌВНЯпГЬМфЕФЙЄзїЁЃБрвыжЦЕМжИСювд#pragma
omp ПЊЪМЃЌКѓБпИњОпЬхЕФЙІФмжИСюЃЌИёЪНШчЃК#pragma omp жИСю[згОф],[згОф] Ё]ЁЃГЃгУЕФЙІФмжИСюШчЯТЃК
parallel ЃКгУдквЛИіНсЙЙПщжЎЧАЃЌБэЪОетЖЮДњТыНЋБЛЖрИіЯпГЬВЂаажДааЃЛ
forЃКгУгкforбЛЗгяОфжЎЧАЃЌБэЪОНЋбЛЗМЦЫуШЮЮёЗжХфЕНЖрИіЯпГЬжаВЂаажДааЃЌвдЪЕЯжШЮЮёЗжЕЃЃЌБиаыгЩБрГЬШЫдБздМКБЃжЄУПДЮбЛЗжЎМфЮоЪ§ОнЯрЙиадЃЛ
parallel for ЃКparallelКЭforжИСюЕФНсКЯЃЌвВЪЧгУдкforбЛЗгяОфжЎЧАЃЌБэЪОforбЛЗЬхЕФДњТыНЋБЛЖрИіЯпГЬВЂаажДааЃЌЫќЭЌЪБОпгаВЂаагђЕФВњЩњКЭШЮЮёЗжЕЃСНИіЙІФмЃЛ
sections ЃКгУдкПЩБЛВЂаажДааЕФДњТыЖЮжЎЧАЃЌгУгкЪЕЯжЖрИіНсЙЙПщгяОфЕФШЮЮёЗжЕЃЃЌПЩВЂаажДааЕФДњТыЖЮИїздгУsectionжИСюБъГіЃЈзЂвтЧјЗжsectionsКЭsectionЃЉЃЛ
parallel sectionsЃКparallelКЭsectionsСНИігяОфЕФНсКЯЃЌРрЫЦгкparallel
forЃЛ
singleЃКгУдкВЂаагђФкЃЌБэЪОвЛЖЮжЛБЛЕЅИіЯпГЬжДааЕФДњТыЃЛ
criticalЃКгУдквЛЖЮДњТыСйНчЧјжЎЧАЃЌБЃжЄУПДЮжЛгавЛИіOpenMPЯпГЬНјШыЃЛ
flushЃКБЃжЄИїИіOpenMPЯпГЬЕФЪ§ОнгАЯёЕФвЛжТадЃЛ
barrierЃКгУгкВЂаагђФкДњТыЕФЯпГЬЭЌВНЃЌЯпГЬжДааЕНbarrierЪБвЊЭЃЯТЕШД§ЃЌжБЕНЫљгаЯпГЬЖМжДааЕНbarrierЪБВХМЬајЭљЯТжДааЃЛ
atomicЃКгУгкжИЖЈвЛИіЪ§ОнВйзїашвЊдзгадЕиЭъГЩЃЛ
masterЃКгУгкжИЖЈвЛЖЮДњТыгЩжїЯпГЬжДааЃЛ
threadprivateЃКгУгкжИЖЈвЛИіЛђЖрИіБфСПЪЧЯпГЬзЈгУЃЌКѓУцЛсНтЪЭЯпГЬзЈгаКЭЫНгаЕФЧјБ№ЁЃ
ЯргІЕФOpenMPзгОфЮЊЃК
privateЃКжИЖЈвЛИіЛђЖрИіБфСПдкУПИіЯпГЬжаЖМгаЫќздМКЕФЫНгаИББОЃЛ
firstprivateЃКжИЖЈвЛИіЛђЖрИіБфСПдкУПИіЯпГЬЖМгаЫќздМКЕФЫНгаИББОЃЌВЂЧвЫНгаБфСПвЊдкНјШыВЂаагђЛђШЮЮёЗжЕЃгђЪБЃЌМЬГажїЯпГЬжаЕФЭЌУћБфСПЕФжЕзїЮЊГѕжЕЃЛ
lastprivateЃКЪЧгУРДжИЖЈНЋЯпГЬжаЕФвЛИіЛђЖрИіЫНгаБфСПЕФжЕдкВЂааДІРэНсЪјКѓИДжЦЕНжїЯпГЬжаЕФЭЌУћБфСПжаЃЌИКд№ПНБДЕФЯпГЬЪЧforЛђsectionsШЮЮёЗжЕЃжаЕФзюКѓвЛИіЯпГЬЃЛ
reductionЃКгУРДжИЖЈвЛИіЛђЖрИіБфСПЪЧЫНгаЕФЃЌВЂЧвдкВЂааДІРэНсЪјКѓетаЉБфСПвЊжДаажИЖЈЕФЙщдМдЫЫуЃЌВЂНЋНсЙћЗЕЛиИјжїЯпГЬЭЌУћБфСПЃЛ
nowaitЃКжИГіВЂЗЂЯпГЬПЩвдКіТдЦфЫћжЦЕМжИСюАЕКЌЕФТЗеЯЭЌВНЃЛ
num_threadsЃКжИЖЈВЂаагђФкЕФЯпГЬЕФЪ§ФПЃЛ
scheduleЃКжИЖЈforШЮЮёЗжЕЃжаЕФШЮЮёЗжХфЕїЖШРраЭЃЛ
sharedЃКжИЖЈвЛИіЛђЖрИіБфСПЮЊЖрИіЯпГЬМфЕФЙВЯэБфСПЃЛ
orderedЃКгУРДжИЖЈforШЮЮёЗжЕЃгђФкжИЖЈДњТыЖЮашвЊАДееДЎаабЛЗДЮађжДааЃЛ
copyprivateЃКХфКЯsingleжИСюЃЌНЋжИЖЈЯпГЬЕФзЈгаБфСПЙуВЅЕНВЂаагђФкЦфЫћЯпГЬЕФЭЌУћБфСПжаЃЛ
copyin nЃКгУРДжИЖЈвЛИіthreadprivateРраЭЕФБфСПашвЊгУжїЯпГЬЭЌУћБфСПНјааГѕЪМЛЏЃЛ
defaultЃКгУРДжИЖЈВЂаагђФкЕФБфСПЕФЪЙгУЗНЪНЃЌШБЪЁЪЧsharedЁЃ
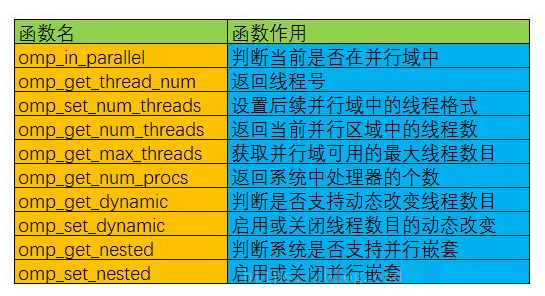
APIКЏЪ§
Г§ЩЯЪіБрвыжЦЕМжИСюжЎЭтЃЌOpenMPЛЙЬсЙЉСЫвЛзщAPIКЏЪ§гУгкПижЦВЂЗЂЯпГЬЕФФГаЉааЮЊЃЌЯТУцЪЧвЛаЉГЃгУЕФOpenMP
APIКЏЪ§вдМАЫЕУїЃК
ЛЗОГБфСП
OpenMPЬсЙЉСЫвЛаЉЛЗОГБфСПЃЌгУРДдкдЫааЪБЖдВЂааДњТыЕФжДааНјааПижЦЁЃетаЉЛЗОГБфСППЩвдПижЦЃК1ЃЉЩшжУЯпГЬЪ§ЃЛ2ЃЉжИЖЈбЛЗШчКЮЛЎЗжЃЛ3ЃЉНЋЯпГЬАѓЖЈЕНДІРэЦїЃЛ4ЃЉЦєгУ/НћгУЧЖЬзВЂааЃЌЩшжУзюДѓЕФЧЖЬзВЂааМЖБ№ЃЛ5ЃЉЦєгУ/НћгУЖЏЬЌЯпГЬЃЛ6ЃЉЩшжУЯпГЬЖбеЛДѓаЁЃЛ7ЃЉЩшжУЯпГЬЕШД§ВпТдЁЃГЃгУЕФЛЗОГБфСПЃК
OMP_SCHEDULEЃКгУгкforбЛЗВЂааЛЏКѓЕФЕїЖШЃЌЫќЕФжЕОЭЪЧбЛЗЕїЖШЕФРраЭЃЛ
OMP_NUM_THREADSЃКгУгкЩшжУВЂаагђжаЕФЯпГЬЪ§ЃЛ
OMP_DYNAMICЃКЭЈЙ§ЩшЖЈБфСПжЕЃЌРДШЗЖЈЪЧЗёдЪаэЖЏЬЌЩшЖЈВЂаагђФкЕФЯпГЬЪ§ЃЛ
OMP_NESTEDЃКжИГіЪЧЗёПЩвдВЂааЧЖЬзЁЃ
1.OpenMPжИСюМАзгОфгУЗЈ
2.parallel
parallel ЪЧгУРДЙЙдьвЛИіВЂааПщЕФЃЌвВПЩвдЪЙгУЦфЫћжИСюШчforЁЂsectionsЕШКЭЫќХфКЯЪЙгУЁЃparallelжИСюЪЧгУРДЮЊвЛЖЮДњТыДДНЈЖрИіЯпГЬРДжДааЫќЕФЁЃparallelПщжаЕФУПааДњТыЖМБЛЖрИіЯпГЬжиИДжДааЁЃКЭДЋЭГЕФДДНЈЯпГЬКЏЪ§БШЦ№РДЃЌЯрЕБгкЮЊвЛИіЯпГЬШыПкКЏЪ§жиИДЕїгУДДНЈЯпГЬКЏЪ§РДДДНЈЯпГЬВЂЕШД§ЯпГЬжДааЭъЁЃГЬађЪОР§ШчЯТЃК
void fun1()
{
#pragma omp parallel num_ threads(6) //ЖЈвх6ИіЯпГЬЃЌУПИіЯпГЬЖМНЋдЫаа{}ФкДњТыЃЌдЫааНсЙћЃКЪфГі6ДЮTest
{
cout < < "Test" << endl;
}
system("pause");
}
|
for
forжИСюдђЪЧгУРДНЋвЛИіforбЛЗЗжХфЕНЖрИіЯпГЬжажДааЁЃforжИСювЛАуПЩвдКЭparallelжИСюКЯЦ№РДаЮГЩparallel
forжИСюЪЙгУЃЌвВПЩвдЕЅЖРгУдкparallelгяОфЕФВЂааПщжаЁЃparallel forгУгкЩњГЩвЛИіВЂаагђЃЌВЂНЋМЦЫуШЮЮёдкЖрИіЯпГЬжЎМфЗжХфЃЌгУгкЗжЕЃШЮЮёЁЃГЬађЪОР§ШчЯТЃК
void fun2()
{
#pragma omp parallel for num_threads (6) {
printf (" OpenMP Test, ЯпГЬБрКХЮЊ: %d\n",
omp_ get_ thread _ num());
} //жИЖЈСЫ6ИіЯпГЬЃЌЕќДњСПЮЊ12ЃЌУПИіЯпГЬЖМЗжЕНСЫ12 /6= 2ДЮЕФЕќДњСПЁЃ
system ("pause");
} |
sections & section
sectionгяОфЪЧгУдкsectionsгяОфРягУРДНЋsectionsгяОфРяЕФДњТыЛЎЗжГЩМИИіВЛЭЌЕФЖЮЃЌУПЖЮЖМВЂаажДааЁЃгяЗЈИёЪНШчЯТЃК
#pragma omp
[parallel] sections [згОф]
{
#pragma omp section
{
ДњТыПщ
}
#pragma omp section
{
ДњТыПщ
}
} |
ЫЕУїИїИіsectionРяЕФДњТыЖМЪЧВЂаажДааЕФЃЌВЂЧвИїИіsectionБЛЗжХфЕНВЛЭЌЕФЯпГЬжДааЁЃ
ЪЙгУsectionгяОфЪБЃЌашвЊзЂвтЕФЪЧетжжЗНЪНашвЊБЃжЄИїИіsectionРяЕФДњТыжДааЪБМфЯрВюВЛДѓЃЌЗёдђФГИіsectionжДааЪБМфБШЦфЫћsectionЙ§ГЄОЭДяВЛЕНВЂаажДааЕФаЇЙћСЫЁЃгУforгяОфРДЗжЬЏЪЧгЩЯЕЭГздЖЏНјааЃЌжЛвЊУПДЮбЛЗМфУЛгаЪБМфЩЯЕФВюОрЃЌФЧУДЗжЬЏЪЧКмОљдШЕФЃЌЪЙгУsectionРДЛЎЗжЯпГЬЪЧвЛжжЪжЙЄЛЎЗжЯпГЬЕФЗНЪНЁЃ
private
privateзгОфгУгкНЋвЛИіЛђЖрИіБфСПЩљУїГЩЯпГЬЫНгаЕФБфСПЃЌБфСПЩљУїГЩЫНгаБфСПКѓЃЌжИЖЈУПИіЯпГЬЖМгаЫќздМКЕФБфСПЫНгаИББОЃЌЦфЫћЯпГЬЮоЗЈЗУЮЪЫНгаИББОЁЃМДЪЙдкВЂааЧјгђЭтгаЭЌУћЕФЙВЯэБфСПЃЌЙВЯэБфСПдкВЂааЧјгђФкВЛЦ№ШЮКЮзїгУЃЌВЂЧвВЂааЧјгђФкВЛЛсВйзїЕНЭтУцЕФЙВЯэБфСПЁЃГЬађЪОР§ШчЯТЃК
int k = 100;
#pragma omp parallel for private(k)
for ( k=0; k < 3; k++)
{
printf("k=%d/n", k);
}
printf("last k=%d/n", k); |
ЩЯУцГЬађжДааКѓДђгЁЕФНсЙћШчЯТЃК
k=0
k=1
k=2
k=3
last k=100
ДгДђгЁНсЙћПЩвдПДГіЃЌforбЛЗЧАЕФБфСПkКЭбЛЗЧјгђФкЕФБфСПkЦфЪЕЪЧСНИіВЛЭЌЕФБфСПЁЃгУprivateзгОфЩљУїЕФЫНгаБфСПЕФГѕЪМжЕдкВЂааЧјгђЕФШыПкДІЪЧЮДЖЈвхЕФЃЌЫќВЂВЛЛсМЬГаЭЌУћЙВЯэБфСПЕФжЕЁЃ
privateЩљУїЕФЫНгаБфСПВЛФмМЬГаЭЌУћБфСПЕФжЕЃЌЕЋЪЕМЪЧщПіжагаЪБашвЊМЬГадгаЙВЯэБфСПЕФжЕЃЌOpenMPЬсЙЉСЫfirstprivateзгОфРДЪЕЯжетИіЙІФмЁЃШєЩЯЪіГЬађЪЙгУfirstprivate(k)ЃЌдђВЂааЧјгђФкЕФЫНгаБфСПkМЬГаСЫЭтУцЙВЯэБфСПkЕФжЕ100зїЮЊГѕЪМжЕЃЌВЂЧвдкЭЫГіВЂааЧјгђКѓЃЌЙВЯэБфСПkЕФжЕБЃГжЮЊ100ЮДБфЁЃ
гаЪБдкВЂааЧјгђФкЕФЫНгаБфСПЕФжЕОЙ§МЦЫуКѓЃЌдкЭЫГіВЂааЧјгђЪБЃЌашвЊНЋЫќЕФжЕИГИјЭЌУћЕФЙВЯэБфСПЃЌЧАУцЕФprivate
КЭ firstprivateзгОфдкЭЫГіВЂааЧјгђЪБЖМУЛгаНЋЫНгаБфСПЕФзюКѓШЁжЕИГИјЖдгІЕФЙВЯэБфСПЃЌlastprivate
згОфОЭЪЧгУРДЪЕЯждкЭЫГіВЂааЧјгђЪБНЋЫНгаБфСПЕФжЕИГИјЙВЯэБфСПЁЃГЬађЪОР§ШчЯТЃК
int k = 100;
#pragma omp parallel for firstprivate(k),lastprivate(k)
for ( i=0; i < 4; i++)
{
k+=i;
printf("k=%d/n",k);
} printf("last k= %d/n", k) |
ЩЯУцДњТыжДааКѓЕФДђгЁНсЙћШчЯТЃК
k=100
k=101
k=103
k=102
last k=103
ДгДђгЁНсЙћПЩвдПДГіЃЌЭЫГіforбЛЗЕФВЂааЧјгђКѓЃЌЙВЯэБфСПkЕФжЕБфГЩСЫ103ЃЌЖјВЛЪЧБЃГждРДЕФ100ВЛБфЁЃOpenMPЙцЗЖжажИГіЃЌШчЙћЪЧбЛЗЕќДњЃЌФЧУДЪЧНЋзюКѓвЛДЮбЛЗЕќДњжаЕФжЕИГИјЖдгІЕФЙВЯэБфСПЃЛШчЙћЪЧsectionЙЙдьЃЌФЧУДЪЧзюКѓвЛИіsectionгяОфжаЕФжЕИГИјЖдгІЕФЙВЯэБфСПЁЃзЂвтетРяЫЕЕФзюКѓвЛИіsectionЪЧжИГЬађгяЗЈЩЯЕФзюКѓвЛИіЃЌЖјВЛЪЧЪЕМЪдЫааЪБЕФзюКѓвЛИідЫааЭъЕФЁЃШчЙћЪЧРрЃЈclassЃЉРраЭЕФБфСПЪЙгУдкlastprivateВЮЪ§жаЃЌФЧУДЪЙгУЪБгааЉЯожЦЃЌашвЊвЛИіПЩЗУЮЪЕФЃЌУїШЗЕФШБЪЁЙЙдьКЏЪ§ЃЌГ§ЗЧБфСПвВБЛЪЙгУзїЮЊfirstprivateзгОфЕФВЮЪ§ЃЛЛЙашвЊвЛИіПНБДИГжЕВйзїЗћЃЌВЂЧветИіПНБДИГжЕВйзїЗћЖдгкВЛЭЌЖдЯѓЕФВйзїЫГађЪЧЮДжИЖЈЕФЃЌвРРЕгкБрвыЦїЕФЖЈвхЁЃ
threadprivate
threadprivateжИСюгУРДжИЖЈШЋОжЕФЖдЯѓБЛИїИіЯпГЬИїздИДжЦСЫвЛИіЫНгаЕФПНБДЃЌМДИїИіЯпГЬОпгаИїздЫНгаЕФШЋОжЖдЯѓЁЃthreadprivateКЭprivateЕФЧјБ№дкгкthreadprivateЩљУїЕФБфСПЭЈГЃЪЧШЋОжЗЖЮЇФкгааЇЕФЃЌЖјprivateЩљУїЕФБфСПжЛдкЫќЫљЪєЕФВЂааЙЙдьжагааЇЁЃгУзїthreadprivateЕФБфСПЕФЕижЗВЛФмЪЧГЃЪ§ЁЃЖдгкC++ЕФРрЃЈclassЃЉРраЭБфСПЃЌгУзїthreadprivateЕФВЮЪ§ЪБгааЉЯожЦЃЌЕБЖЈвхЪБДјгаЭтВПГѕЪМЛЏЪБЃЌБиаыОпгаУїШЗЕФПНБДЙЙдьКЏЪ§ЁЃГЬађЪОР§ШчЯТЃК
int g;
#pragma omp threadprivate(g) //вЛЖЈвЊЯШЩљУї
int main(int argc, char *argv[])
{
/* Explicitly turn off dynamic threads */
omp_set_dynamic(0);
#pragma omp parallel
{
g = omp_get_thread_num();
printf("tid: %d\n",g); //ЫцЛњвРДЮЪфГі0~3
} // End of parallel region
#pragma omp parallel
{
int temp = g*g;
printf("tid : %d, tid*tid: %d\n",g,
temp); //ВЛЭЌЯпГЬжаШЋОжБфСПжЕВЛЭЌ
} // End of parallel region
} |
зЂвтЃКдкЪЙгУthreadprivateЕФЪБКђЃЌвЊгУomp_set_dynamic(0)ЙиБеЖЏЬЌЯпГЬЕФЪєадЃЌВХФмБЃжЄНсЙће§ШЗЁЃ
Share
sharedзгОфПЩвдгУгкЩљУївЛИіЛђЖрИіБфСПЮЊЙВЯэБфСПЁЃЫљЮНЕФЙВЯэБфСПЃЌЪЧжЕдквЛИіВЂааЧјгђЕФteamФкЕФЫљгаЯпГЬжЛгЕгаБфСПЕФвЛИіФкДцЕижЗЃЌЫљгаЯпГЬЗУЮЪЭЌвЛЕижЗЁЃЫљвдЃЌЖдгкВЂааЧјгђФкЕФЙВЯэБфСПЃЌашвЊПМТЧЪ§ОнОКељЬѕМўЃЌвЊЗРжЙОКељЃЌашвЊдіМгЖдгІЕФБЃЛЄЁЃГЬађЪОР§ШчЯТЃК
#define COUNT
10000
int main(int argc, _TCHAR* argv[])
{
int sum = 0;
#pragma omp parallel for shared(sum)
for(int i = 0; i < COUNT;i++)
{
sum = sum + i;
}
printf("%d\n",sum);
return 0;
} > |
ЖрДЮдЫааЃЌНсЙћПЩФмВЛвЛбљЁЃашвЊзЂвтЕФЪЧЃКбЛЗЕќДњБфСПдкбЛЗЙЙдьЧјгђРяЪЧЫНгаЕФЃЌЩљУїдкбЛЗЙЙдьЧјгђФкЕФздЖЏБфСПЖМЪЧЫНгаЕФЁЃШчЙћбЛЗЕќДњБфСПвВЪЧЙВгаЕФЃЌOpenMPИУШчКЮШЅжДааЃЌЫљвдвВжЛФмЪЧЫНгаЕФСЫЁЃМДЪЙЪЙгУsharedРДаоЪЮбЛЗЕќДњБфСПЃЌвВВЛЛсИФБфбЛЗЕќДњБфСПдкбЛЗЙЙдьЧјгђжаЪЧЫНгаЕФетвЛЬиЕуЁЃГЬађЪОР§ШчЯТЃК
#define COUNT 10
int main(int argc, _TCHAR* argv[])
{
int sum = 0;
int i = 0;
#pragma omp parallel for shared(sum, i)
for(i = 0; i < COUNT;i++)
{
sum = sum + i;
}
printf("%d\n",i);
printf("%d\n",sum);
return 0;
} |
ЩЯЪіГЬађжаЃЌбЛЗЕќДњБфСПiЕФЪфГіжЕЮЊ0ЃЌОЁЙметРяЪЙгУsharedаоЪЮБфСПiЁЃзЂвтЃЌетРяЕФЙцдђжЛЪЧеыЖдбЛЗВЂааЧјгђЃЌЖдгкЦфЫћЕФВЂааЧјгђУЛгаетбљЕФвЊЧѓЁЃЭЌЪБдкбЛЗВЂааЧјгђФкЃЌбЛЗЕќДњБфСПЪЧВЛПЩаоИФЕФЁЃМДдкЩЯЪіГЬађжаЃЌВЛФмдйforбЛЗЬхФкЖдбЛЗЕќДњБфСПiНјаааоИФЁЃ
Default
defaultжИЖЈВЂааЧјгђФкБфСПЕФЪєадЃЌC++ЕФOpenMPжаdefaultЕФВЮЪ§жЛФмЮЊsharedЛђnoneЁЃdefault(shared)
ЃКБэЪОВЂааЧјгђФкЕФЙВЯэБфСПдкВЛжИЖЈЕФЧщПіЯТЖМЪЧsharedЪєад
default(none)ЃКБэЪОБиаыЯдЪНжИЖЈЫљгаЙВЯэБфСПЕФЪ§ОнЪєадЃЌЗёдђЛсБЈДэЃЌГ§ЗЧБфСПгаУїШЗЕФЪєадЖЈвхЃЈБШШчбЛЗВЂааЧјгђЕФбЛЗЕќДњБфСПжЛФмЪЧЫНгаЕФЃЉШчЙћвЛИіВЂааЧјгђЃЌУЛгаЪЙгУdefaultзгОфЃЌФЧУДЦфФЌШЯааЮЊЮЊdefault(shared)ЁЃ
Copyin
copyinзгОфгУгкНЋжїЯпГЬжаthreadprivateБфСПЕФжЕПНБДЕНжДааВЂааЧјгђЕФИїИіЯпГЬЕФthreadprivateБфСПжаЃЌДгЖјЪЙЕУteamФкЕФзгЯпГЬЖМгЕгаКЭжїЯпГЬЭЌбљЕФГѕЪМжЕЁЃГЬађЪОР§ШчЯТЃК
#include <omp.h>
int A =
100;
#pragma omp threadprivate(A)
int main (int argc, _TCHAR* argv[])
{
#pragma omp parallel for
for(int i = 0; i<10;i++)
{
A++;
printf ("Thread ID: %d, %d: %d\n",omp_get_
thread_num(), i, A); // #1
} |
printf("Global A: %d\n",A);
// ВЂааЧјгђЭтЕФДђгЁЕФЁАGloba AЁБЕФжЕзмЪЧКЭЧАУцЕФthread 0ЕФНсЙћЯрЕШЃЌвђЮЊЭЫГіВЂааЧјгђКѓЃЌжЛгаmasterЯпГЬМД0КХЯпГЬдЫааЁЃ
#pragma omp parallel for copyin(A)
for(int i = 0; i<10;i++)
{
A++;
printf("Thread ID: %d, %d: %d\n",omp_get_thread_num(),
i, A); // #1
}
printf("Global A: %d\n",A); // #2
return 0;
} |
ВЛЪЙгУcopyinЕФЧщПіЯТЃЌНјШыЕкЖўИіВЂааЧјгђЕФЪБКђЃЌВЛЭЌЯпГЬЕФЫНгаИББОAЕФГѕЪМжЕЪЧВЛвЛбљЕФЃЌетРяЪЙгУСЫcopyinжЎКѓЃЌЗЂЯжЫљгаЕФЯпГЬЕФГѕЪМжЕЖМЪЙгУжїЯпГЬЕФжЕГѕЪМЛЏЃЌШЛКѓМЬајдЫЫуЃЌЪфГіЕФжЕМДЮЊБОДЮthread
0ЕФНсЙћЁЃМђЕЅРэНтЃЌдкЪЙгУСЫcopyinКѓЃЌЫљгаЕФЯпГЬЕФthreadprivateРраЭЕФИББОБфСПЖМЛсгыжїЯпГЬЕФИББОБфСПНјаавЛДЮЁАЭЌВНЁБЁЃ
СэЭтcopyinжаЕФВЮЪ§БиаыБЛЩљУїГЩthreadprivateЕФЃЌЖдгкРрРраЭЕФБфСПЃЌБиаыДјгаУїШЗЕФПНБДИГжЕВйзїЗћЁЃ
Copyprivate
copyprivateзгОфгУгкНЋЯпГЬЫНгаИББОБфСПЕФжЕДгвЛИіЯпГЬЙуВЅЕНжДааЭЌвЛВЂааЧјгђЕФЦфЫћЯпГЬЕФЭЌвЛБфСПЁЃcopyprivateжЛФмгУгкsingleжИСюЃЈsingleжИСю:гУдквЛЖЮжЛБЛЕЅИіЯпГЬжДааЕФДњТыЖЮжЎЧА,БэЪОКѓУцЕФДњТыЖЮНЋБЛЕЅЯпГЬжДааЃЉЕФзгОфжаЃЌдквЛИіsingleПщЕФНсЮВДІЭъГЩЙуВЅВйзїЁЃcopyprivate
жЛФмгУгкprivate / firstprivateЛђthreadprivateаоЪЮЕФБфСПЁЃГЬађЪОР§ШчЯТЃК
int counter
= 0;
#pragma omp threadprivate(counter)
int increment_counter()
{
counter++;
return(counter);
}
#pragma omp parallel
{
int count;
#pragma omp single copyprivate(counter)
{
counter = 50;
}
count = increment_counter();
printf("ThreadId: %ld, count = %ld/n",
omp_ get_ thread_ num( ), count);
} |
ДђгЁНсЙћЮЊЃК
ThreadId: 2, count = 51
ThreadId: 0, count = 51
ThreadId: 3, count = 51
ThreadId: 1, count = 51
ШчЙћУЛгаЪЙгУcopyprivateзгОфЃЌФЧУДДђгЁНсЙћЮЊЃК
ThreadId: 2, count = 1
ThreadId: 1, count = 1
ThreadId: 0, count = 51
ThreadId: 3, count = 1
ПЩвдПДГіЃЌЪЙгУcopyprivateзгОфКѓЃЌsingleЙЙдьФкИјcounterИГЕФжЕБЛЙуВЅЕНСЫЦфЫћЯпГЬРяЃЌЕЋУЛгаЪЙгУcopyprivateзгОфЪБЃЌжЛгавЛИіЯпГЬЛёЕУСЫsingleЙЙдьФкЕФИГжЕЃЌЦфЫћЯпГЬУЛгаЛёШЁsingleЙЙдьФкЕФИГжЕЁЃ
OpenMPжаЕФШЮЮёЕїЖШ
OpenMPжаЃЌШЮЮёЕїЖШжївЊгУгкВЂааЕФforбЛЗжаЃЌЕБбЛЗжаУПДЮЕќДњЕФМЦЫуСПВЛЯрЕШЪБЃЌШчЙћМђЕЅЕиИјИїИіЯпГЬЗжХфЯрЭЌДЮЪ§ЕФЕќДњЕФЛАЃЌЛсдьГЩИїИіЯпГЬМЦЫуИКдиВЛОљКтЃЌетЛсЪЙЕУгааЉЯпГЬЯШжДааЭъЃЌгааЉКѓжДааЭъЃЌдьГЩФГаЉCPUКЫПеЯаЃЌгАЯьГЬађадФмЁЃOpenMPЬсЙЉСЫscheduleзгОфРДЪЕЯжШЮЮёЕФЕїЖШЁЃscheduleзгОфИёЪНЃКschedule(type,[size])ЁЃ
ВЮЪ§typeЪЧжИЕїЖШЕФРраЭЃЌПЩвдШЁжЕЮЊstaticЃЌdynamicЃЌguidedЃЌruntimeЫФжжжЕЁЃЦфжаruntimeдЪаэдкдЫааЪБШЗЖЈЕїЖШРраЭЃЌвђДЫЪЕМЪЕїЖШВпТджЛгаЧАУцШ§жжЁЃ
ВЮЪ§sizeБэЪОУПДЮЕїЖШЕФЕќДњЪ§СПЃЌБиаыЪЧећЪ§ЁЃИУВЮЪ§ЪЧПЩбЁЕФЁЃЕБtypeЕФжЕЪЧruntimeЪБЃЌВЛФмЙЛЪЙгУИУВЮЪ§ЁЃ
ОВЬЌЕїЖШstatic
ДѓВПЗжБрвыЦїдкУЛгаЪЙгУscheduleзгОфЕФЪБКђЃЌФЌШЯЪЧstaticЕїЖШЁЃstaticдкБрвыЕФЪБКђОЭвбОШЗЖЈСЫЃЌФЧаЉбЛЗгЩФФаЉЯпГЬжДааЁЃМйЩшгаnДЮбЛЗЕќДњЃЌtИіЯпГЬЃЌФЧУДИјУПИіЯпГЬОВЬЌЗжХфДѓдМn/tДЮЕќДњМЦЫуЁЃn/tВЛвЛЖЈЪЧећЪ§ЃЌвђДЫЪЕМЪЗжХфЕФЕќДњДЮЪ§ПЩФмДцдкВю1ЕФЧщПіЁЃ
дкВЛЪЙгУsizeВЮЪ§ЪБЃЌЗжХфИјУПИіЯпГЬЕФЪЧn/tДЮСЌајЕФЕќДњЃЌШєбЛЗДЮЪ§ЮЊ10ЃЌЯпГЬЪ§ЮЊ2ЃЌдђЯпГЬ0ЕУЕНСЫ0ЁЋ4ДЮСЌајЕќДњЃЌЯпГЬ1ЕУЕН5ЁЋ9ДЮСЌајЕќДњЁЃ
ЕБЪЙгУsizeЪБЃЌНЋУПДЮИјЯпГЬЗжХфsizeДЮЕќДњЁЃШєбЛЗДЮЪ§ЮЊ10ЃЌЯпГЬЪ§ЮЊ2ЃЌжИЖЈsizeЮЊ2дђ0ЁЂ1ДЮЕќДњЗжХфИјЯпГЬ0ЃЌ2ЁЂ3ДЮЕќДњЗжХфИјЯпГЬ1ЃЌвдДЫРрЭЦЁЃ
ЖЏЬЌЕїЖШdynamic
ЖЏЬЌЕїЖШвРРЕгкдЫааЪБЕФзДЬЌЖЏЬЌШЗЖЈЯпГЬЫљжДааЕФЕќДњЃЌвВОЭЪЧЯпГЬжДааЭъвбОЗжХфЕФШЮЮёКѓЃЌЛсШЅСьШЁЛЙгаЕФШЮЮёЃЈгыОВЬЌЕїЖШзюДѓЕФВЛЭЌЃЌУПИіЯпГЬЭъГЩЕФШЮЮёЪ§СППЩФмВЛвЛбљЃЉЁЃгЩгкЯпГЬЦєЖЏКЭжДааЭъЕФЪБМфВЛШЗЖЈЃЌЫљвдЕќДњБЛЗжХфЕНФФИіЯпГЬЪЧЮоЗЈЪТЯШжЊЕРЕФЁЃ
ЕБВЛЪЙгУsize ЪБЃЌЪЧНЋЕќДњж№ИіЕиЗжХфЕНИїИіЯпГЬЁЃЕБЪЙгУsize
ЪБЃЌж№ИіЗжХфsizeИіЕќДњИјИїИіЯпГЬЃЌетИігУЗЈРрЫЦОВЬЌЕїЖШЁЃ
ЦєЗЂЪНЕїЖШguided
ВЩгУЦєЗЂЪНЕїЖШЗНЗЈНјааЕїЖШЃЌУПДЮЗжХфИјЯпГЬЕќДњДЮЪ§ВЛЭЌЃЌПЊЪМБШНЯДѓЃЌвдКѓж№НЅМѕаЁЁЃПЊЪМЪБУПИіЯпГЬЛсЗжХфЕННЯДѓЕФЕќДњПщЃЌжЎКѓЗжХфЕНЕФЕќДњПщЛсж№НЅЕнМѕЁЃЕќДњПщЕФДѓаЁЛсАДжИЪ§МЖЯТНЕЕНжИЖЈЕФsizeДѓаЁЃЌШчЙћУЛгажИЖЈsizeВЮЪ§ЃЌФЧУДЕќДњПщДѓаЁзюаЁЛсНЕЕН1ЁЃ
sizeБэЪОУПДЮЗжХфЕФЕќДњДЮЪ§ЕФзюаЁжЕЃЌгЩгкУПДЮЗжХфЕФЕќДњДЮЪ§Лсж№НЅМѕЩйЃЌЩйЕНsizeЪБЃЌНЋВЛдйМѕЩйЁЃОпЬхВЩгУФФвЛжжЦєЗЂЪНЫуЗЈЃЌашвЊВЮПМОпЬхЕФБрвыЦїКЭЯрЙиЪжВсЕФаХЯЂЁЃ
ЕїЖШЗНЪНзмНс
ОВЬЌЕїЖШstaticЃКУПДЮФФаЉбЛЗгЩФЧИіЯпГЬжДааЪБЙЬЖЈЕФЃЌБрвыЕїЪдЁЃгЩгкУПИіЯпГЬЕФШЮЮёЪЧЙЬЖЈЕФЃЌЕЋЪЧПЩФмгаЕФбЛЗШЮЮёжДааПьЃЌгаЕФТ§ЃЌВЛФмДяЕНзюгХЁЃ
ЖЏЬЌЕїЖШdynamicЃКИљОнЯпГЬЕФжДааПьТ§ЃЌвбОЭъГЩШЮЮёЕФЯпГЬЛсздЖЏЧыЧѓаТЕФШЮЮёЛђепШЮЮёПщЃЌУПДЮСьШЁЕФШЮЮёПщЪЧЙЬЖЈЕФЁЃ
ЦєЗЂЪНЕїЖШguidedЃКУПИіШЮЮёЗжХфЕФШЮЮёЪЧЯШДѓКѓаЁЃЌжИЪ§ЯТНЕЁЃЕБгаДѓСПШЮЮёашвЊбЛЗЪБЃЌИеПЊЪМЮЊЯпГЬЗжХфДѓСПШЮЮёЃЌзюКѓШЮЮёВЛЖрЪБЃЌИјУПИіЯпГЬЩйСПШЮЮёЃЌПЩвдДяЕНЯпГЬШЮЮёОљКтЁЃ
OpenMPГЬађЩшМЦММЧЩзмНс
1.ЕБбЛЗДЮЪ§НЯЩйЪБЃЌШчЙћЗжГЩЙ§ЖрЕФЯпГЬРДжДааЕФЛАЃЌПЩФмЛсЪЙЕУзмЕФдЫааЪБМфИпгкНЯЩйЯпГЬЛђвЛИіЯпГЬЕФжДааЧщПіЃЌВЂЧвЛсдіМгФмКФЃЛ
2.ШчЙћЩшжУЕФЯпГЬЪ§СПдЖДѓгкCPUЕФКЫЪ§ЕФЛАЃЌФЧУДДцдкзХДѓСПЕФШЮЮёЧаЛЛКЭЕїЖШЕФПЊЯњЃЌвВЛсНЕЕЭећЬхЕФаЇТЪЁЃ
3.дкЧЖЬзбЛЗжаЃЌШчЙћЭтВубЛЗЕќДњДЮЪ§НЯЩйЪБЃЌШчЙћНЋРДCPUКЫЪ§діМгЕНвЛЖЈГЬЖШЪБЃЌДДНЈЕФЯпГЬЪ§НЋПЩФмаЁгкCPUКЫЪ§ЁЃСэЭтШчЙћФкВубЛЗДцдкИКдиЦНКтЕФЧщПіЯТЃЌКмФбЕїЖШЭтВубЛЗЪЙжЎДяЕНИКдиЦНКтЁЃ
|






