| �༭�Ƽ�: |
���±������ݼ�¼libco
��飬Э���л�, ����ջ,Э�̿���,epoll ��·���� IO ģ�͵ȵ�ϣ����������������
����������Infoq���ɻ�����Delores�༭�Ƽ��� |
|
libco ���
libco ���ź�̨���ģʹ�õ� c/c++ Э�̿⣬2013 �������ȶ��������ź�̨������̨�����ϣ�ʹ���ź�˷�����ͬʱ hold ����������Ϊ�ŷ������ȶ��ԵĻ�ʯ��libco �� 2013 ���ʱ����Ϊ��Ѷ����Դ��Ŀ�״ο�Դ�� libco Դ���ַ��
libco �����ܽ�� CPU �������� IO �����ʲ�ƽ�⣬���ö��߳̽�� IO ���� CPU �������Ч����Ϊ�û�̬Э���л����߳��л����ܸߣ��߳��л�����ָ������ݸ��࣬��Ҫ�û�̬���ں�̬�л������ libco �ֱ������첽���úͻص����뵼�µĴ���ṹ���顣
libco ���� epoll ��·����ʹ��һ���̴߳������ socket ���ӣ����ù��Ӻ��� hook ס socket �庯��������ʱ�����̴����ȴ���ʱ�¼�������Э��ջ���桢�ָ�ÿ��Э�������Ļ�����
Ϊ���ô�Ҹ������Ķ� libco Դ�룬������Դ��Ϊ������ libco������ƫ�ײ�ϸ�ڡ�����������£���ӭ��ע���߲��͡�
���˼��
1. Э���л�
1.1 ����ջ
���ȸ�ϰ�½��̵ĵ�ַ�ռ䣬��ͼ 1 ��ʾ���뱾����ص��д���Ρ��ѡ�ջ������ΰ���Ӧ�ó���Ļ����룬ָ��Ĵ��� eip ����Ǵ������ijһ�����ָ���ַ��cpu �� eip ��ȡ�����ָ��ĵ�ַ�����ڴ�������ҵ���Ӧ���ָ�ʼִ�С�CPU ִ��ָ��ʱ��ջ���������ֲ����������ݡ�����ͨ�� malloc��new �ڶ��������ڴ�ռ䡣

ͼ 1
ͼ 2 ��ʾ C ���룬ͨ�� gcc -m32 test.c -o test.o �� i386 �±��룬Ȼ��ִ�� gdb test.o��disas main �ɿ���ͼ 3 ��ʾ�� main ��������룬disas sum �ɿ���ͼ 4 ��ʾ sum �����Ļ����롣���� sum ʱ��main �� sum �ĺ���ջ��ͼ 5 ��ʾ��ͼ 5 �ı��������У���һ��Ϊ�ڴ��ַ���ڶ���Ϊ�õ�ַ������ݣ������á�����ʡ�Ե��ڴ��ַ������ÿһ�о�����һ�е� 4byte����Ϊջ��ַ�Ӹߵ���������
��ͼ 5 ���Կ�����һ��ÿ��������ջ�� ebp ջ��ָ��� esp ջ��ָ��֮�䣻�������ڵ��ù�ϵ������������ջ�ڴ��ַ�����ڵģ�����ebp ָ��ָ��λ�ô洢�����ϼ������� ebp ��ַ������ sum �� ebp 0xffffd598 λ�ô���� main �� ebp0xffffd5c8��Ŀ���� sum ִ�к�ɻָ� main �� ebp���� main �� esp ��ͨ�� sum �� ebp + 4 �ָ����ģ�sum �� ebp + 4 λ�ã��� main �� esp λ�ô���� sum ִ�к�ķ��ص�ַ 0x08048415���õ�ַ����ͼ 1 �е�ջ��Stack�������ͼ 1 �еĴ�����sum ִ�к�leave ָ��ָ� ebp��esp��ret ָ� esp �������� 0x08048415 �ŵ��Ĵ��� eip��cpu �� eip ��ȡ����һ����ִ�е�ָ���ַ��������ָ���ַ�Ӵ�������ȡָ��ִ�У��壬sum �IJ��� y��x ���ߵ�ַ���͵�ַ�����δ��� sum �� ebp + 12��ebp + 8 λ�ô���
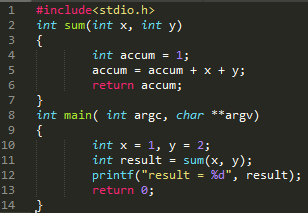
ͼ 2
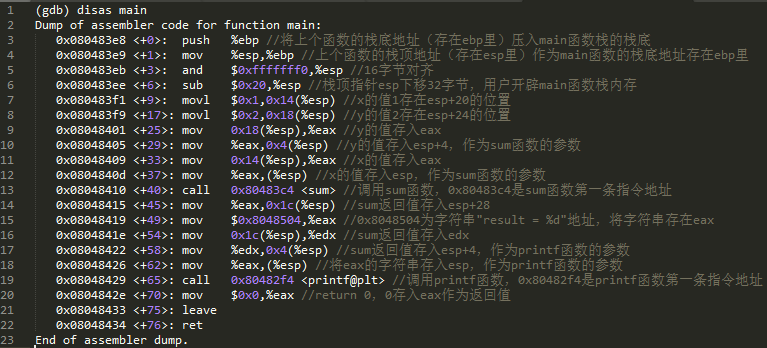
ͼ 3 main ���������

ͼ 4 sum ���������
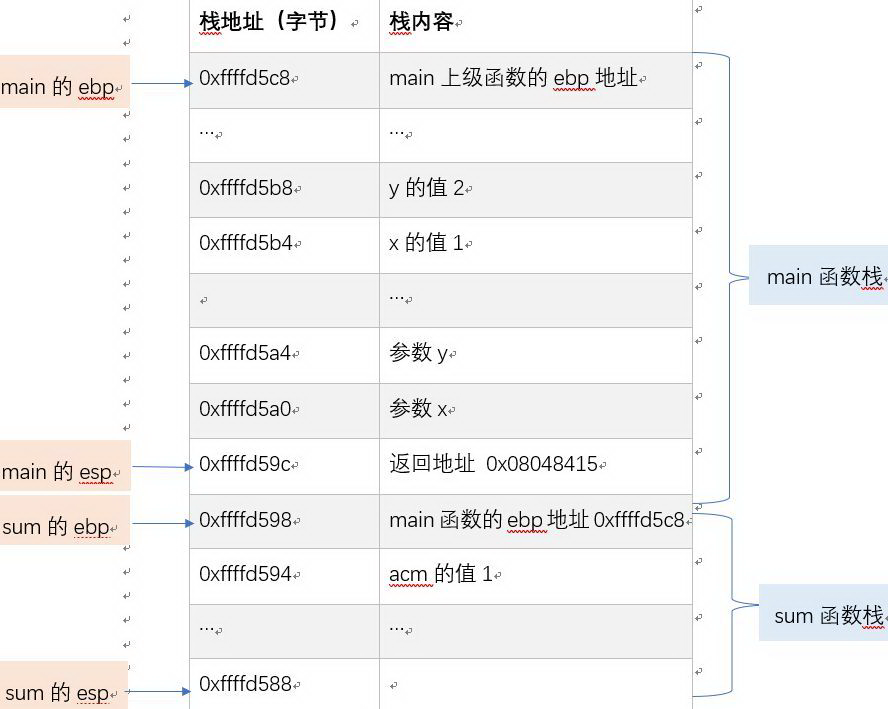
ͼ 5 32 λϵͳ����ջ
1.2 Э��ջ
����ջ���Ľ��ܣ��˴����ܷǹ���ջ���ڷǹ���ջģʽ�£�ÿ������Э�����Լ���ջ������ջ���ڶ��Ϸ���ģ�������ϵͳջ������Э�̵�ջ��Ȼ��ϵͳջ��ÿ����Э�̵�ջ��ַ�����ڡ�Э��ջ�л���Ϊ�� 1 �Ρ��� k �� (k>=2) ����Ŀ��Э�� TargetCoroutine��
��Ϊ��Э�̼���ǰ�̵߳ĵ� 1 ��������ϵͳ���ȵģ����������û����ȣ�������Э��ÿ�ζ����û����ȡ�����ÿ����Э���лص���Ϊ��һ�����Һͷ���Э�̵� k �� (k>=2) ���л���Ϊһ�¡�
�� 1 ���е� TargetCoroutine ֮ǰ�� coctx_make��ͼ 6����������ַ pfn д��Э�̱��� regs[ kEIP ]��pfn ��Ϊ CoRoutineFunc ��ָ�롣CoRoutineFunc ������ͼ 7���ڵ� 448 �е����û��Զ����Э�̺��� UserCoRoutineFunc��ͼ 8����ͼ 6 �� ss_sp Ϊ 128K Э��ջ�͵�ַ,ss_size Ϊ 128K �� ss_sp+ss_size �C sizeof(coctx_param_t)�Csizeof(void*) ��Ϊ esp ��ʼλ�ã���¼�� regs[kESP]����Ϊջ�Ӹߵ�������������������ջ�ռ�Ӹߵ�ַ ss_sp + ss_size �C sizeof(void*) �C sizeof(coctx_param_t) �������͵�ַ ss_sp���ⲿ�ֿռ���Ȼ��Э��ջ����ʵ����ͨ�� stack_mem->stack_buffer= (char*)malloc(stack_size) ����Ķѿռ䡣CoRoutineFunc������õĺ���������õĺ����ٵ��õĺ������ĺ���ջ���ڸ� 128K �Ķѿռ��

ͼ 6
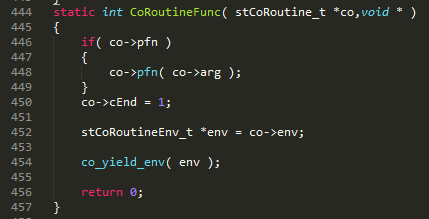
ͼ 7
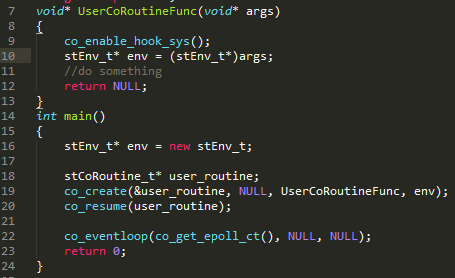
ͼ 8
�� 1 ���л��� TargetCoroutine ʱ��ͼ 9 �� 50 �н� esp ָ�� TargetCoroutine.coctx_t.regs����ʱ esp ָ��ĵ�ַ��ͼ 10 ��ʾ���� 54 �д� regs[0] �������ص�ַ���� CoRoutineFunc ������ַ 0x08043212���� 65 �е��� esp ��ַ�� ss_sp+ss_size�Csizeof(coctx_param_t)�Csizeof(void*)���� 67 �� pushl %eax ���������飺
һ���� esp ��ַ�� 4���� esp = ss_sp + ss_size �C sizeof(coctx_param_t) �C sizeof(void*) �C 4��
������ esp ��λ��ѹ�� CoRoutineFunc ������ַ���� 71 �� ret �� esp ȡ�� CoRoutineFunc ������ַ���� eip �Ĵ�����cpu �� eip �Ĵ���ȡ�� CoRoutineFunc ������һ��ָ���ַ��ʼִ��ָ�CoRoutineFunc ������һ��ָ��ĵ�ַ���� CoRoutineFunc ������ַ��
ͼ 6 ��û�ж� regs[kEBP] ����ֵ������е� TargetCoroutine ʱ������ ebp �� 0������ CoRoutineFunc ����ջ����ϼ������� ebp �� 0����û��Ӱ�졣CoRoutineFunc��ͼ 7��ֻ��ִ�е��� 454 �У�co_yield_env(env)��Ȼ���е�����Э�̣�����ִ�е� 456 �С��ϼ������� ebp ���� CoRoutineFunc ִ�к����ڻָ��ϼ������� esp���������� CoRoutineFunc ������ return 0 ֮ǰ�Ѿ��е�����Э�̣�����ϼ������� ebp �� 0 ���ᵼ�´���
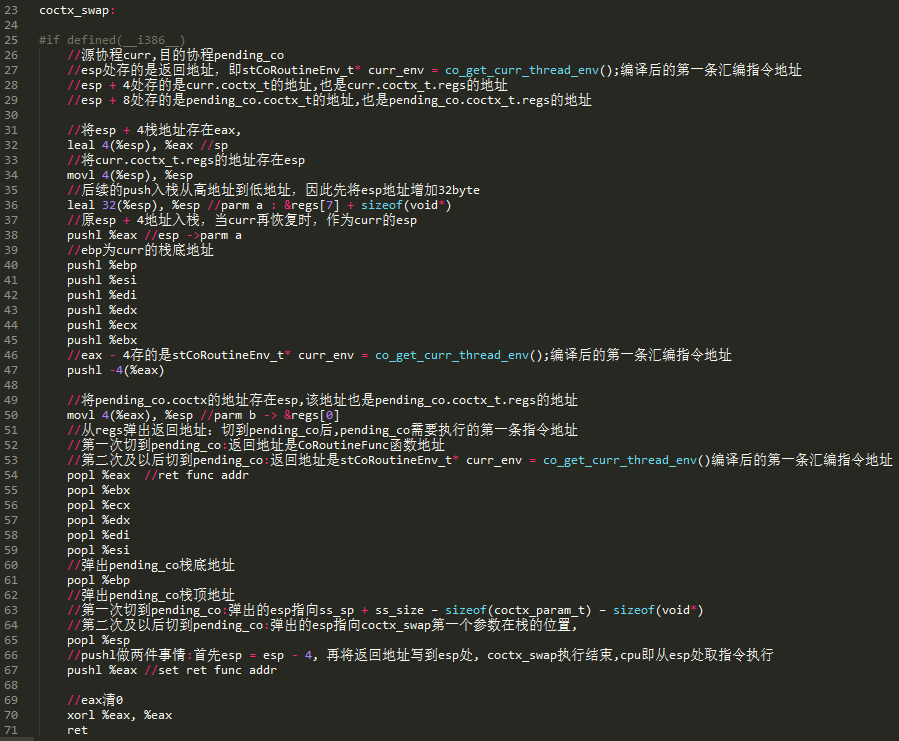
ͼ 9
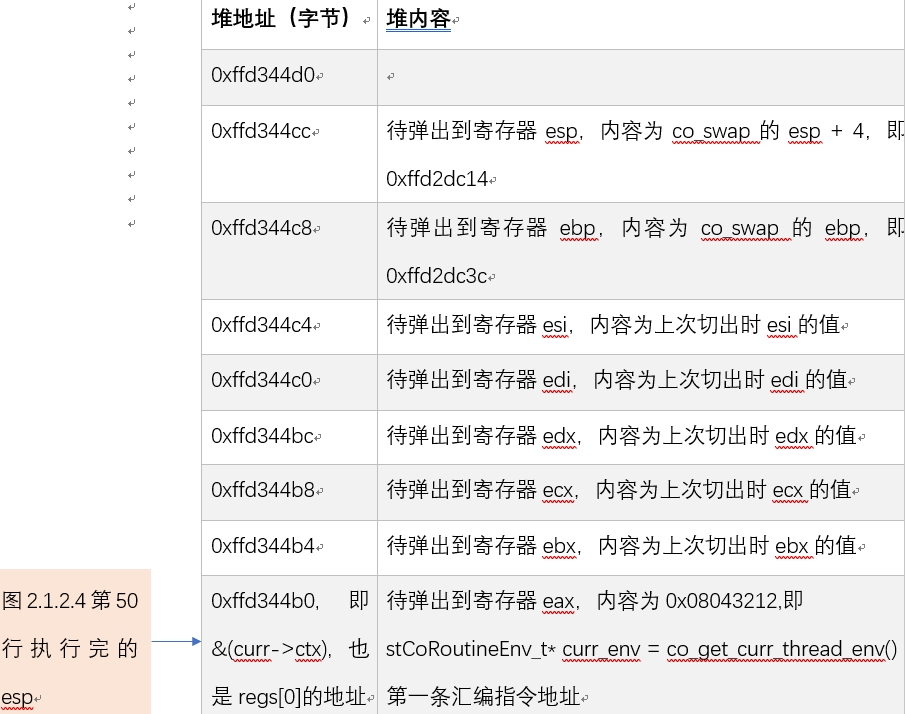
ͼ 10 �� 1 ���е� TargetCoroutine
TargetCoroutine �ڵ� k-1 �α� coctx_swap �г�ʱ��TargetCoroutine ��ͼ 2.3.2.4 ��ԴЭ�� curr���г� TargetCoroutine ʱ����� coctx_swap����ִ��ͼ 9 �� 34 ��֮ǰ������ջ��ͼ 11 ��ʾ��Ȼ�� co_swap��ע�ⲻ�� coctx_swap����Ϊ����û����ͼ 4 �ĵ� 3��4��5 ���� ebp �� esp��ջ����ַ +4 �� 0xffd2dc14 ͨ���� 38 ��д�뵽 regs[kESP]���� co_swap������ coctx_swap��ԭ��ͬ�ϣ�ջ��ַ ebp �� 0xffd2dc3c ͨ���� 40 ��д�� regs[kEBP]���� stCoRoutineEnv_t* curr_env = co_get_curr_thread_env() �ĵ�һ�����ָ���ַ 0x08043212 ͨ���� 47 ��д�� regs[ kEIP ]����ʱ regs ����������ͼ 12 ��ʾ���ڴ��ڼ� esp �ı仯��ͼ 12 �����ʾ��
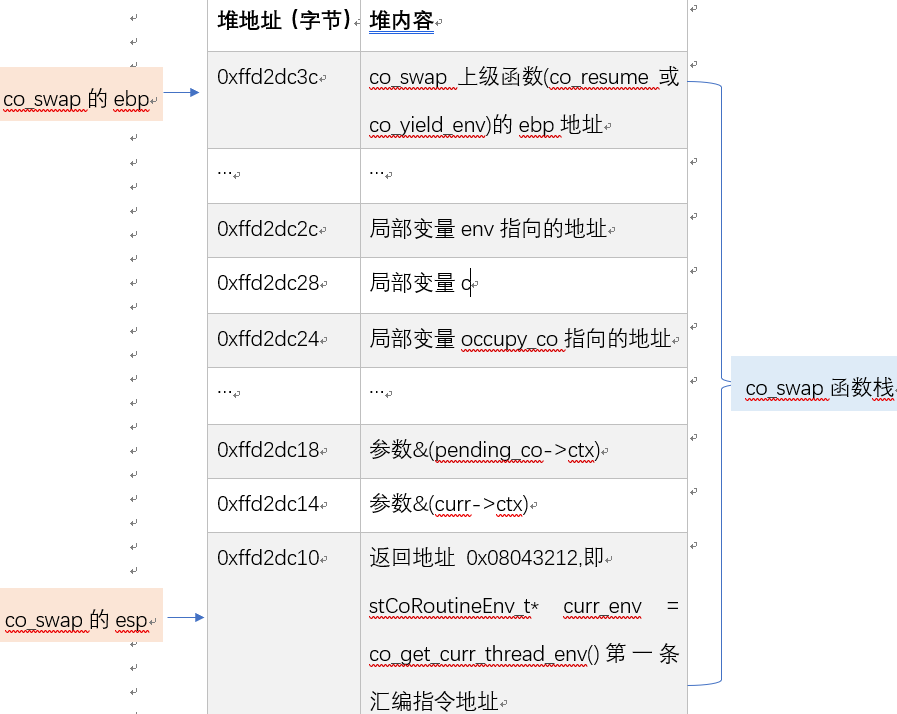
ͼ 11 co_swap ����ջ

ͼ 12 �� k(k>=2) ���е� TargetCoroutine
�� k(k>=2) ���л� TargetCoroutine ʱ��ͼ 9 �� 54 �е��� eax���� stCoRoutineEnv_t* curr_env = co_get_curr_thread_env() �ĵ�һ�����ָ���ַ 0x08043212���� 61 �е��� ebp ��ͼ 2.3.2.6 ��ʾ�� 0xffd2dc3c��ͼ 2.3.2.4 �� 65 �е��� esp����ͼ 11 ��ʾ�� 0xffd2dc14(���� 0xffd2dc10����Ϊͼ 2.3.2.4 �� 38 �е�ѹ��� eax �� 0xffd2dc10 + 4)���� 67 �����������飬���� esp �� 4 �õ��г�ʱ��ջ��ַ 0xffd2dc10���ٽ� eax ��Ļ��ָ���ַ 0x08043212 д�� esp �� 0xffd2dc10 ������� ret �� esp ȡ�����ָ���ַ 0x08043212 ���� eip �Ĵ�����cpu �� eip �Ĵ���ȡ��ָ���ַ��ʼִ��ָ���Ϊ TargetCoroutine �л�ʱ������ִ�� stCoRoutineEnv_t* curr_env=co_get_curr_thread_env()���� TargetCoroutine ��֮ǰ�г�ʱ�����ִ�еĴ����� coctx_swap(&(curr->ctx),&(pending_co->ctx) )�����Э�����лغ��ܽ���֮ǰ�г�ʱ�Ĵ������ִ�С�
�Ա�ͼ 10 �� 12 ���֣��� 1 ���е� TargetCoroutine ʱ ebp��esp�����ص�ַ���Լ������Ĵ����͵� k(k>=2) �ξ���ͬ��
libco �� stCoRoutineEnv_t ������ pCallStack ���飬��СΪ 128���������ÿ��Ԫ�ؾ�ΪЭ�̡�pCallStack ���ڻ�ȡ��ǰЭ�� pCallStack[iCallStackSize - 1]����ȡ��ǰЭ�̹������е���Э�� pCallStack[iCallStackSize - 2]��pCallStack ����ǵݹ���ã����ҳ�֮Ϊ�ݹ飬�����ǵݹ飩��Э�̣�pCallStack[0] һ������Э�̡�������Э�̵���Э�� 1��Э�� 1 ����Э�� 2��Э�� k-1 ����Э�� k�����ֵݹ��ϵ�� k ���Ϊ 127������Э�� 127 ʱ����ʱ pCallStack[0] ����Э�̣�pCallStack[1] ��Э�� 1��pCallStack[k] ��Э�� k��pCallStack[127] ��Э�� 127�����ݹ����֮���Э��ʵ���в�������������ij���Ӧ������Э�̵���Э�� 1��Э�� 1 �����л���Э�̣���Э���ٵ���Э�� 2��Э�� 2 �����л���Э�̣���Э���ٵ���Э�� 3�������Э�̵���Э�� k ʱ��pCallStack[0] ����Э�̣�pCallStack[1] ��Э�� k������Ԫ��Ϊ�գ�Э�� k �����л���Э��ʱ��pCallStack[0] ����Э�̣�����Ԫ��Ϊ�ա���� 128 ��С�� pCallStack �㹻������������Э��ʹ�á�
1.3 ����
��Э�̼�Ϊ��ǰ�̣߳��� stCoRoutine_t. cIsMain ��ǡ���Э�̵�ջ��ͼ 1 ��ʾ��ջ (Stack) ����������Э�̵�ջ��ͼ 1 ��ʾ�Ķ� (Heap) ����ͼ 9 ���г���Э��ʱ 38-47 �мĴ������� regs ��������� 128K ��Э��ջ���������Ķѿռ䣩���л���Э��ʱ���� 61��65 �е����� ebp��esp ָ�����ϵͳջ����ڴ棬�����Э�̵�ջʼ����ϵͳջ�ϣ��ò��� 128K ��Э��ջ��
���Ƿ��б�Ҫ����ǰЭ�̱��Ϊ��Э�̣�ͼ 2.1.3.1 �ĵ� 1024��1033 ���Ǵ�����е�������Ҫ�ж���Э�̡����������Э��˽�б�������û�д�������Э��ʱ��co Ϊ NULL����ʱͨ�� 1026 �л�ȡ��Э��˽�б��������ڳ������е�ij�δ���ʱ��ʼ����Э�̣�����������Э�̣���Ϊ co ��Ϊ NULL�������ͨ���� 1028 �л�ȡ��Э��˽�б�������ʱ��Ϊ�ò�����ǰ���õ���Э��˽�б��������´�����������ͼ 2.1.3.1 �� 1024��1033 �е� co->cIsMain ����ɾ����ͼ 2.1.3.2 �� 24 ���������Э��˽�б���Ϊ 11������ 30 ����� 0��

ͼ 13
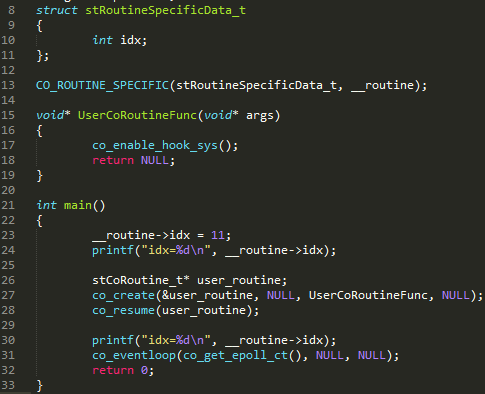
ͼ 14
1.4 ����ջ
ÿ��Э������һ���̶� 128K ��ջ����Э�������ܴ�ʱ�������ڴ�ѹ������� libco ���빲��ջģʽ��ʾ������ɲο� example_copystack.cpp������ջ����Э��û��Ӱ�죬����ջ��Ȼ���ڶ��ϣ�����Э�̵�ջ��ϵͳջ�ϡ�
���ù���ջʱ��ÿ��Э�̵�ջ�ӹ���ջ����ʱ����Ҫ����ռ�洢�����������ռ䡣��Ϊ����Э�̵�ջ�ռ䶼Զ���� 128K����˿���ʱֻ������С�Ŀռ䣬���˽��ջ�ܽ�ʡ�����ڴ档����ջ����ֻ��һ������Ϊ�˱���Ƶ�����뻻����һ�㿪�������ջ��ÿ������ջ���������ռ䣬����ջ����ķ��ա�
���迪 10 ������ջ��ÿ��Э��ģ 10 ӳ�䵽��Ӧ�Ĺ���ջ������Э�̵���˳��Ϊ��Э�̡�Э�� 2��Э�� 3��Э�� 12��Э�� 2 �е�Э�� 3 ʱ����ΪЭ�� 2��3 ʹ�õĹ���ջ�ֱ��ǵ� 2��3 ������ջ��û�г�ͻ������Э�� 2 ��ջ������Ȼ�����ڵ� 2 ������ջ����������������Э�� 2 �ļĴ����ᱻ coctx_swap ������ regs ���顣���õ�Э�� 12 ʱ��Э�� 12 ��Э�� 2 ��ӳ�䵽�� 2 ������ջ�������Ҫ��Э�� 2 ��ջ���ݿ���������Э�� 12 ��ջ���ݿ������� 2 ������ջ�С����Թ���ջ���˿���Э�� 2 ��ջ������Э�� 12 ��ջ�������������ÿ�������ջ��ʱ�任ȡÿ��Э��ջ�Ŀռ䡣
ͼ 15 �� 609 �н� curr �� stack_sp ָ�� c �ĵ�ַ����¼��ǰЭ��ջ�ĵ�λ�ã���ǰЭ��ջ�ĸ�λ���� ss_sp + ss_size �C sizeof(coctx_param_t) �C sizeof(void*)������� CoRoutineFunc ������һ�����ָ�curr Э�̿���Э��ʱ����Ҫ������ curr->stack_sp(�� &c) �� ss_sp + ss_size �C sizeof(void*) �C sizeof(coctx_param_t) ��ջ���ݡ��Ժ������Э�����л��� curr Э��ʱ���������ջ���� curr Э�̣���ֻͨ�� coctx_swap �ָ��Ĵ������ɣ�������ͼ 15 �� 657 ����ʾ����Ҫ�� curr ������ curr->save_buffer ��Э��ջ���Ƶ��� curr->stack_sp �� ss_sp + ss_size �C sizeof(void*) �C sizeof(coctx_param_t) ���ڴ�ռ䡣
ͼ 15 �� curr Э���е� pending_co Э��ʱ������ǹ���ջģʽ�����õ� pending_co �Ĺ���ջ stack_mem �����е�Э�� occupy_co����� occupy_co �ǿ��Ҳ��� pending_co�������е�Э�� save_stack_buffer(occupy_co)���� stack_mem ָ���Э�̻�Ϊ pending_co������ pending_co �� occupy_co �������� env ������þֲ�������¼����Ϊ�ֲ������� coctx_swap ֮ǰ���� curr Э�̣��� coctx_swap ��Э��ջ�Ѿ����л���curr �����оֲ��������� pending_co ���ʡ���� occupy_co �� pending_co ����ͬһ��Э�̣���Ҫ�� occupy_co �ڹ���ջ������ݿ����� occupy_co->save_buffer��Э�̵����ݳ�����ջ�ﻹ�ֲ��ڼĴ�������� occupy_co ���� curr������ occupy_co ֮ǰ���л�������Э��ʱ�Ĵ����Ѿ��� coctx_swap ���棻��������Ĵ����ڱ���ִ�� coctx_swap �����档
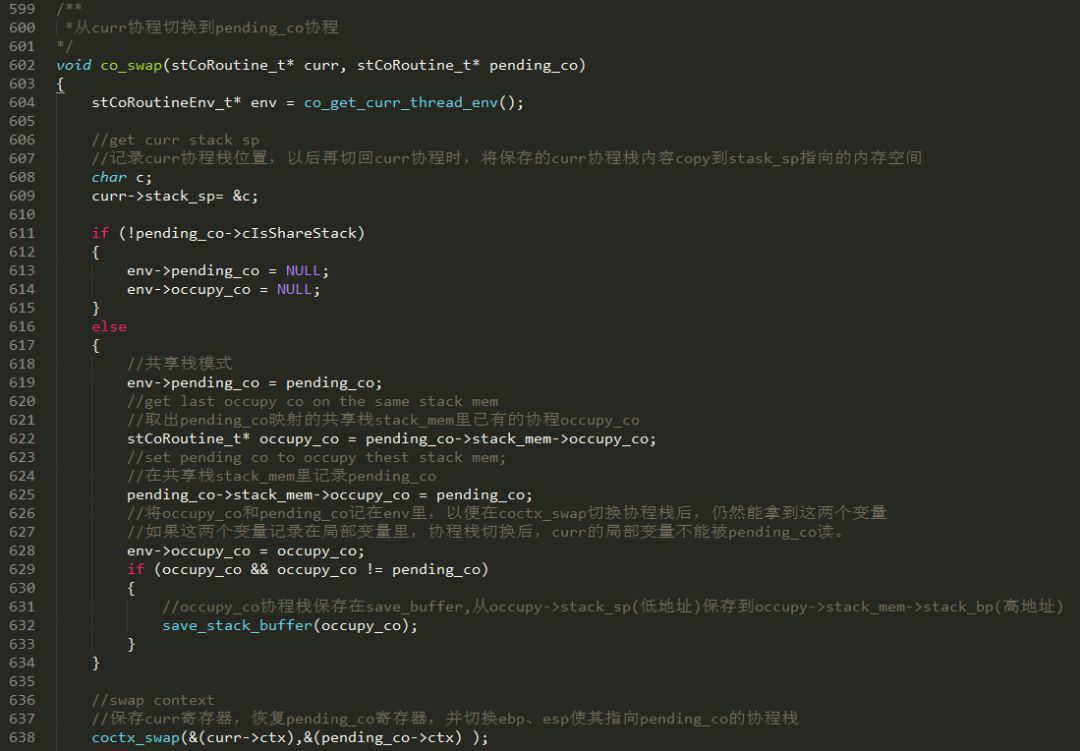
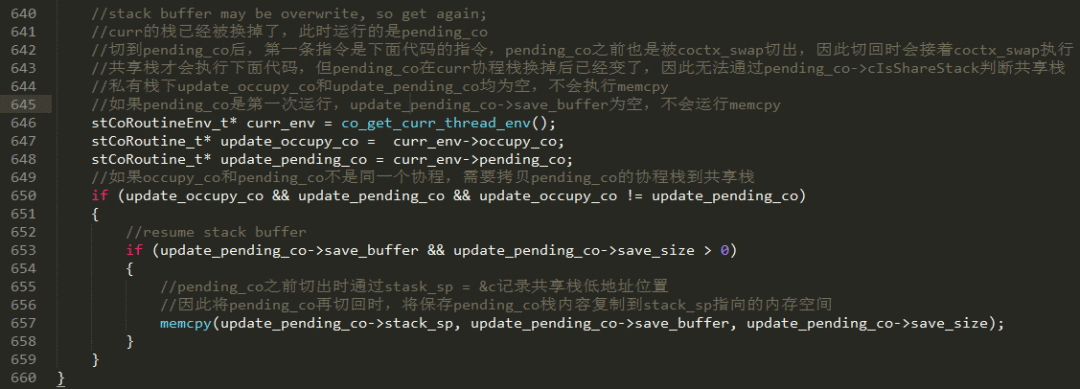
ͼ 15
1.5 �߳��л� VS Э���л�
IO �ܼ�ʱҲ����ʹ�ö���̡߳����߳����������㣺һ���л����۴���ָ������ġ��̵߳��ȣ�������ռ����Դ�ࡣ
�߳�������Ҫ�Թ������ݼ��������ᵼ���̵߳��ȡ���Ϊ�û����߳������û�ִ̬�У����̵߳��Ⱥ��������ں�̬ʵ�֣������̵߳�����Ҫ���û�̬ת���ں�̬���ٴ��ں�̬ת���û�̬���е��ں�̬ʱ��Ҫ�����û�̬�����ģ����е��û�̬ʱ����Ҫ�ָ��û�̬�����ģ����̵߳��û�̬�����ı�Э�������Ĵ�öࡣ�����̵߳���Ҳ��Ҫ��ʱ��
�߳�ջĬ��Ϊ 1M ����Э��ջ 128K�������̻߳���Ҫ���� struct ��һЩ״̬��ʵ��ÿ�� pthread_create �������̴߳�Լռ 8M �����ڴ棬����߳�ռ����ԴҲԶ��Э�̶ࡣ
2. Э�̿���
2.1 epoll ��·���� IO ģ��
Э��ʹ�� epoll ��·���� IO ģ�͡�������ͬ��������ͬ������ģ�ͣ��첽�������첽 IO ģ�͡��� read Ϊ��˵���������� IO ģ�͵�����read ��Ϊ�����Σ�һ���ȴ����ݣ����������ݴ� kernel �������û��̡߳�
ͬ������ read ʹ��ͬ������ IO��kernel �ȴ����ݵ���ٽ����ݿ������û��̣߳����������û��̶߳����������첽���� read ʹ���첽 IO ģ�ͣ��û��̵߳��� read �����̿���ȥ�������£� kernel �ȴ���������ɣ�Ȼ�����ݿ������û��ڴ棬����ɺ�kernel ֪ͨ�û� read ��ɣ�Ȼ���û��߳�ֱ��ʹ�����ݣ��������û��̶߳�������������Э�̵��� read ʹ�ö�·���� IO ģ�ͣ��û��̵߳��� read ��һ��Ҳ���ᱻ���������ڶ����λᱻ������epoll ��·���� IO ģ�Ϳ�����һ���̹߳������ socket��
ͬ�������������ζ��������û��̣߳����Ч�ʵ͡���Ȼ����Ϊÿ�����ӿ����̣߳�����������ʱ���߳�̫�ർ������ѹ����Ҳ���Կ��̶���Ŀ���̳߳أ���������ڴ��������ӣ��߳���Դ�����ͷţ����������ӵò����������첽����ʱ����Ϊ�����ζ��������û��̣߳����Ч����ߣ����첽�ĵ������ͻص�����Ҫ�ֿ������첽���ö�ʱ������ṹ����������Э�̵� epoll ��·���� IO ģ�ͣ���Ȼ�������ڶ����Σ�����Ϊ�ڶ��ζ����ݺ�ʱ���٣����Ч���Ե����첽���á�Э�������ŵ����ڽӽ��첽Ч�ʵ�ͬʱ������ʹ��ͬ����д����������ͬ����д��������ͬ�����ã������� read �����ĵ��ô�������ſ���д�������ݵ����������ٶ���ص����������� read ��Э�̹�������Э�̱����ã����ݾ������� read ���洦�����ݡ�
ϵͳ select/poll��epoll �������ṩ��· IO ���÷�����Э��ʹ�õ��� epoll��select��poll ���ƣ����� writefds��readfds��exceptfds �ļ������� (fd)������ select/poll ��������ֱ���� fd �������ɶ�����д���� except������ʱ��select/poll ���غ�ͨ������ fd ���ϣ��ҵ������� fs������ʼ��д��poll �������洢 fd���� select �� fd ���λ�洢����� poll û��������������ƣ��� select ����Ϊ 1024��select/poll ���е�ȱ���ǣ�һ�����غ���Ҫ���� fd �����ҵ������� fd���� fd ���Ͼ��������������٣�����select/poll ���轫 fd �������û�̬���ں�̬֮�����ؿ�����epoll ��������Ϊ�˽�� select/poll ��������ȱ�㣬epoll �ṩ�������� epoll_create��epoll_ctl��epoll_wait��epoll_create ���ں˵ĸ��� cache �н�һ�ú�����Լ��������� (activeList)��epoll_ctl �� add �ں���������� fd ��㣬����ע�� fd �Ļص��������ں��ڼ�ij fd ����ʱ����ûص������� fd ���ӵ� activeList��epoll_wait �� activeList �е� fd ���ء�epoll_ctl ÿ��ֻ���ں����Ӻ�����ڵ㣬������ select/poll �������� fd ���ںˣ�epoll_wait ͨ�������ڴ���ں˴��ݾ��� fd ���û��������� select/poll ���������� fd ���������� fd �ҵ������ġ�
2.2 ������ IO
Э��ʹ�� epoll ��·���� IO ģ�͡�������ͬ��������ͬ������ģ�ͣ��첽�������첽 IO ģ�͡��� read Ϊ��˵���������� IO ģ�͵�����read ��Ϊ�����Σ�һ���ȴ����ݣ����������ݴ� kernel �������û��̡߳�
ͬ������ read ʹ��ͬ������ IO��kernel �ȴ����ݵ���ٽ����ݿ������û��̣߳����������û��̶߳����������첽���� read ʹ���첽 IO ģ�ͣ��û��̵߳��� read �����̿���ȥ�������£� kernel �ȴ���������ɣ�Ȼ�����ݿ������û��ڴ棬����ɺ�kernel ֪ͨ�û� read ��ɣ�Ȼ���û��߳�ֱ��ʹ�����ݣ��������û��̶߳�������������Э�̵��� read ʹ�ö�·���� IO ģ�ͣ��û��̵߳��� read ��һ��Ҳ���ᱻ���������ڶ����λᱻ������epoll ��·���� IO ģ�Ϳ�����һ���̹߳������ socket��
ͬ�������������ζ��������û��̣߳����Ч�ʵ͡���Ȼ����Ϊÿ�����ӿ����̣߳�����������ʱ���߳�̫�ർ������ѹ����Ҳ���Կ��̶���Ŀ���̳߳أ���������ڴ��������ӣ��߳���Դ�����ͷţ����������ӵò����������첽����ʱ����Ϊ�����ζ��������û��̣߳����Ч����ߣ����첽�ĵ������ͻص�����Ҫ�ֿ������첽���ö�ʱ������ṹ����������Э�̵� epoll ��·���� IO ģ�ͣ���Ȼ�������ڶ����Σ�����Ϊ�ڶ��ζ����ݺ�ʱ���٣����Ч���Ե����첽���á�Э�������ŵ����ڽӽ��첽Ч�ʵ�ͬʱ������ʹ��ͬ����д����������ͬ����д��������ͬ�����ã������� read �����ĵ��ô�������ſ���д�������ݵ����������ٶ���ص����������� read ��Э�̹�������Э�̱����ã����ݾ������� read ���洦�����ݡ�
ϵͳ select/poll��epoll �������ṩ��· IO ���÷�����Э��ʹ�õ��� epoll��select��poll ���ƣ����� writefds��readfds��exceptfds �ļ������� (fd)������ select/poll ��������ֱ���� fd �������ɶ�����д���� except������ʱ��select/poll ���غ�ͨ������ fd ���ϣ��ҵ������� fs������ʼ��д��poll �������洢 fd���� select �� fd ���λ�洢����� poll û��������������ƣ��� select ����Ϊ 1024��select/poll ���е�ȱ���ǣ�һ�����غ���Ҫ���� fd �����ҵ������� fd���� fd ���Ͼ��������������٣�����select/poll ���轫 fd �������û�̬���ں�̬֮�����ؿ�����epoll ��������Ϊ�˽�� select/poll ��������ȱ�㣬epoll �ṩ�������� epoll_create��epoll_ctl��epoll_wait��epoll_create ���ں˵ĸ��� cache �н�һ�ú�����Լ��������� (activeList)��epoll_ctl �� add �ں���������� fd ��㣬����ע�� fd �Ļص��������ں��ڼ�ij fd ����ʱ����ûص������� fd ���ӵ� activeList��epoll_wait �� activeList �е� fd ���ء�epoll_ctl ÿ��ֻ���ں����Ӻ�����ڵ㣬������ select/poll �������� fd ���ںˣ�epoll_wait ͨ�������ڴ���ں˴��ݾ��� fd ���û��������� select/poll ���������� fd ���������� fd �ҵ������ġ�
2.2 ������ IO
Э�̵� epoll ��·���� IO ģ��ʹ�õ��Ƿ����� IO������ read ��������������Э�̣�����������Э�̡������� IO ��ͨ�� fcntl �������� O_NONBLOCK��Ӱ�� socket �� read��write��connect��sendto��recvfrom��send��recv ��������Ϊ read��recv��recvfrom ʵ�����ƣ�write��send ʵ�����ơ���˽��������� read��write��connect ����������
2.2.1 ���Ӻ��� read
��ͼ 16 ��ʾ���û��Զ���� read ���� hook סϵͳ read ������Read ʱ�����������һ���û�δ���� hook��ֱ���� 337 �е���ϵͳ read����������û�ָ���� O_NONBLOCK��Ҳֱ���� 343 �е���ϵͳ read����ʱ�Ƿ������ģ���������û��ȿ����� hook����û��ָ�� O_NONBLOCK����� libco �����κδ�������ʹͨ�� 353 �� poll �ˣ������Э���dz�ʱ���أ��� 355 �л��ǻᱻ����������ֻҪ�û����� hook��socket ������ͼ 17������ 234 �е��� fcntl ���������յ���ͼ 18 �ĵ� 696 �У����ĵ����� O_NONBLOCK���� user_flag ��û�м�¼ O_NONBLOCK���������ɺ͵ڶ���������֡�Ȼ��ͼ 16 �� 353 �е��� poll ����ǰЭ�̹���ֱ�������ݿɶ����߳�ʱ��Э�̲Ż����µ��ȡ��ڵڶ�������£������Ƚ�Э�̹��𣬵ȴ����������лأ���Ϊ�û���ʾ������ O_NONBLOCK ��Ϊ���������أ�������𣬾�����ʱ�����лأ����û���Ҫ������÷��ؽ���ij���Υ����
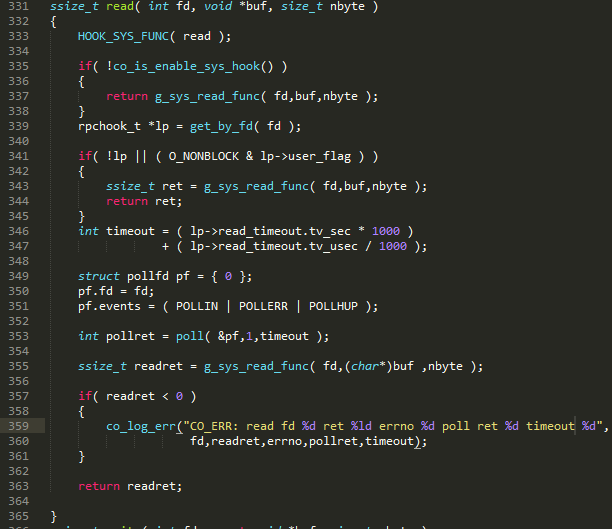
ͼ 16
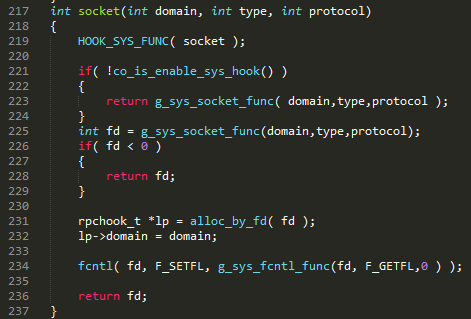
ͼ 17
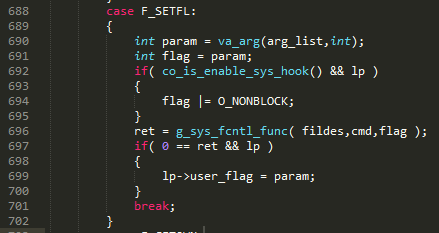
ͼ 18
2.2.2 ���Ӻ��� write
������ write �ڷ��ͻ�����û�пռ�ʱֱ�ӷ��أ����ͻ������пռ�ʱ����ȫ���֣��ռ䲻�������ݣ�����ʵ�ʿ������ֽ�����
��ͼ 19 ��ʾ�������������һ���û�δ���� hook���� 372 �е���ϵͳ write����������û�ָ���� O_NONBLOCK���� 378 �е���ϵͳ write����ʱ�Ƿ������ģ���������������������ֵ�ԭ��� 2.2.2.1����������û��ȿ����� hook����û��ָ�� O_NONBLOCK���� 2.2.2.1 ��֪��libco ���������� O_NONBLOCK��ֻҪ����û����ȫд�뻺��������ͨ���� 402 �� poll ��Э�̹��𣬵ȴ��п���ռ份��Э�̻��߳�ʱ���ѡ�writeret ��¼���ε���д����ֽ���,wrotelen ��¼�ܹ�д����ֽ������������д��û�пռ���������ֱ�ӷ��ء���Ϊ write ��ȷ֪��Ҫд�����ݵij��� nbyte����һ�ο�����д��ȫ�����ݣ����� write �� while ѭ���ﲻ��д���ݣ�ֱ������д�ꡢд�������Ż�ֹͣд���ݡ��� 2.2.2.1 �� read ��֪Ҫ���������ݣ���˶�һ�ξͷ��ء�
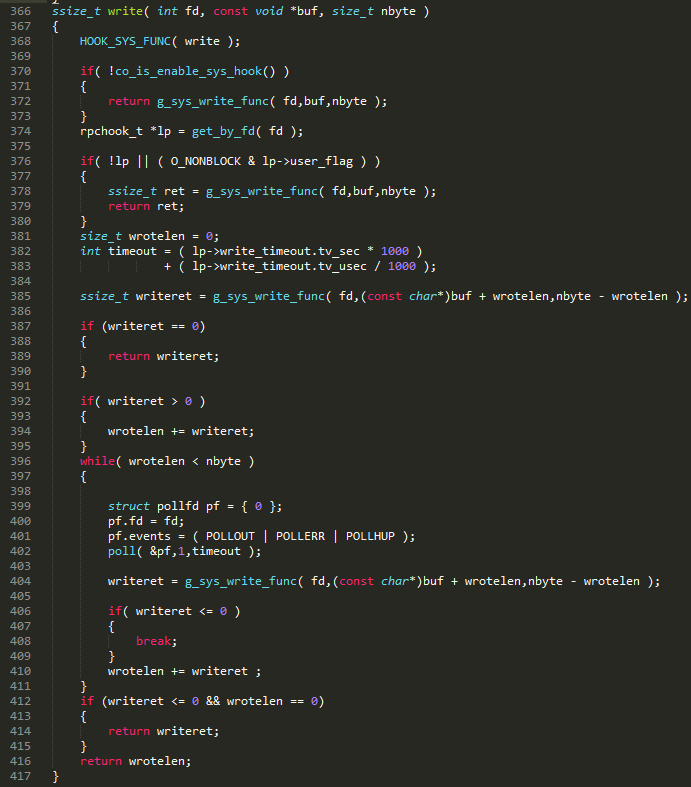
ͼ 19
2.2.3 ���Ӻ��� connect
ͼ 20 ��ʾΪ libco �Զ��� connect ����Ƭ�Ρ�����û����� hook����δ���� O_NONBLOCK��libco ���İ��û������� O_NONBLOCK�������� connect �����������أ���Ϊ connect ���������ֵĹ��̣��ں��ж��������ֵij�ʱ������ 75 �룬��ʱ���ʧ�ܡ�libco ���� O_NONBLOCK ����������ϵͳ connect ���ܻ�ʧ�ܣ������ͼ 20 ��ѭ�����Σ�ÿ�����ó�ʱʱ�� 25 �룬Ȼ�����Э�̣��ȴ� connect �ɹ���ʱ��
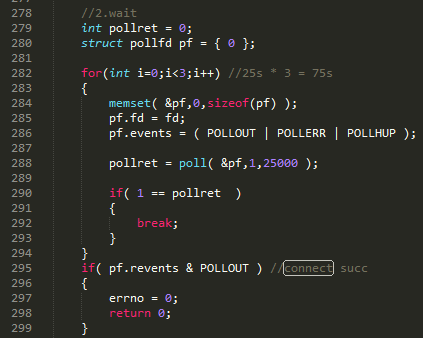
ͼ 20
2.3 epoll ������
Э�� hook ס�˵ײ� socket �庯���������� O_NONBLOCK������ socket �庯������ poll ע�� epoll �¼�������Э�̣�������Э��ִ�У�����Э�̶������ͨ�� epoll������Э������ע��� IO �¼�����������ʱ���е���ӦЭ�̡�
poll ���ջ���� co_poll_inner��ͼ 21��ͼ 22 �ֱ�Ϊ co_poll_inner �����ϡ��²��֡��ú����IJ��� ctx Ϊ epoll �Ļ���������������epoll ������ iEpollFd����ʱ���� pTimeOut���ѳ�ʱ���� pstTimeoutList���������� pstActiveList��epoll_wait �����¼����� result��������� fds Ϊ socket �ļ����������ϣ�nfds Ϊ socket �ļ���������Ŀ��timeout ��ʱʱ�䣬pollfunc Ϊϵͳ poll ������
�� 908 �� epfd �� epoll_create ������ epoll ���������൱�ں���������������ı�ʶ������ͨ�� epfd �������� fd��919 �� 927 ������ nfds ���� 3 ��ʱֱ����ջ�Ϸ���ռ䣨���죩�������ڶ��Ϸ��䡣�� 930 �м�¼���� fd �Ļص����� OnPollProcessEvent���ûص��������лض�Ӧ��Э�̡��� 940 �м�¼�л�Э��֮ǰ��Ԥ�������� OnPollPreparePfn���� 948 �н�ÿ�� fd ͨ�� epoll_ctl ������������ 968 �н� arg ���볬ʱ���� pTimeOut���� 980 �й���Э�̡��ȵ�����Э�̾�������Э�̿�ʼ���С�

ͼ 21
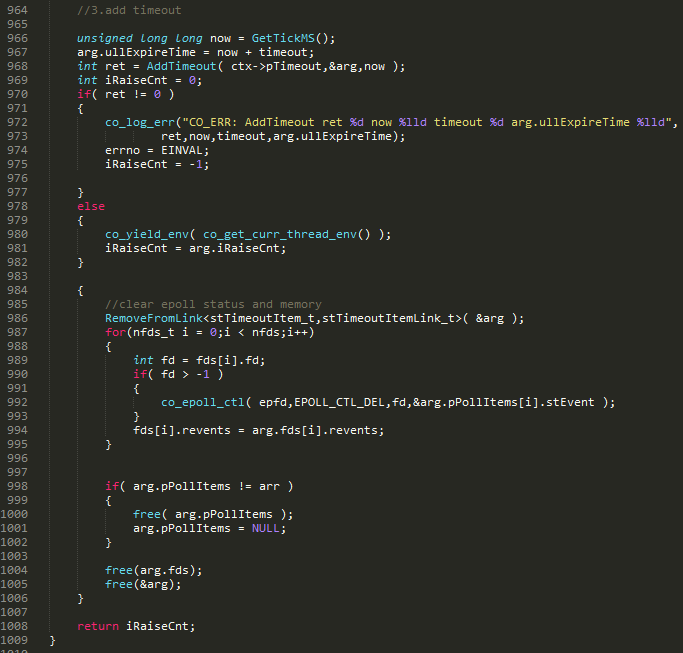
ͼ 22
ͼ 23 Ϊ��Э�̵��õ� co_eventloop ����Ƭ�Ρ�co_epoll_wait �ҳ����о��� fd������ pfnPrepare �� OnPollPreparePfn�������� fd �ӳ�ʱ���� pTimeOut �Ƴ���������������� pstActiveList��801 ���ò�����TakeAllTimeout �ó���ʱ���������г�ʱԪ�أ����ڵ� 817 �м��� pstActiveList��824 �е� 833 �н� 807 ��ȡ����δ��ʱ�¼��ټӻس�ʱ���У���Ϊ TakeAllTimeout �ó��IJ�һ�����dz�ʱ�¼�����ʱ���еײ�ʵ���� 60000 ��С��ѭ�����飬���ÿ���루�� 60000 ���룩�ij�ʱ�¼���ÿ�������Ԫ�ؾ���һ��������ѭ�������Ŀ���DZ���ͨ���±��ҵ����г�ʱ���������糬ʱʱ���� 10 ����������¼�����¼�������±�Ϊ 9����ѭ������ʵ�ʵ��±���ܲ��� 9�����ٸ����ӣ�����������г�ʱʱ����� 60000 ������¼�����¼�������±�Ϊ 59999 ����������ȡ����ʱʱ���� 60000 ������¼���TakeAllTimeout ��ѳ�ʱʱ����� 60000 �����Ҳȡ�����������Ҫ�ٰѳ�ʱʱ����� 60000 ��������¼ӻس�ʱ���С��ڵ� 836 ������Э�̳�ʱ�� fd ����ʱ���� pfnProcess �� OnPollProcessEvent �л�Э�̡�Э���лغ������� 2.1.2 ��֪��Э�̽��� co_yield_env �� co_swap ��� stCoRoutineEnv_t* curr_env = co_get_curr_thread_env() ����ִ�У�co_yield_env ִ������ͼ 22 �ĵ� 981 �м���ִ�С��� 986 ��Ӧ���Ƕ���ģ���Ϊ pfnPrepare �Ѿ��ӳ�ʱ����ɾ���¼���992 �е��� epoll ɾ����ǰЭ�̵ľ��� fd��
ע� co_poll_inner ����� fd ���飬�� arg ֻ�������е�һ��Ԫ�ء����� co_poll_inner ���� 10 ���ļ������������ֻ�� 1 �� fd ������OnPollPreparePfn �� pTimeOut ɾ�� arg���� 10 ���ļ� fd ���ӳ�ʱ����ɾ������ͼ 22 �л�Э��ʱ�ڵ� 987 �� 995 �н� 10 �����������Ӻ����ɾ����Ȼ��Ӧ�ò���Ҫ�� 9 ��δ������ fd ���µ��� co_poll_inner �ټ������������ÿ��ֻ����һ�� fd����������Ҫ����������10 + 9+ 8 +�� +1 �Σ�Ч�ʵ��� 10 �� poll��ÿ��ֻ poll һ�� fd��co_poll_inner �ṩ���� fd �����ԭ���ǣ�co_poll_inner �� poll ���õģ��� poll �� hook ��ϵͳ���������ܸı�ϵͳ�����塣ϵͳ poll ֧�������ԭ���ǣ�����ϵͳ poll һ�Σ��ɼ���� fd���ȵ���ϵͳ poll ��Σ�ÿ�μ��һ�� fd��Ч�ʸ��ߡ����ϵͳ poll �ʺ�һ�� poll ��� fd���� libco �Զ���Ĺ��Ӻ��� poll ���ʺ�һ�� poll ��� fd������ libco ʹ�� poll ʱ�����һ�� poll ��� fd��
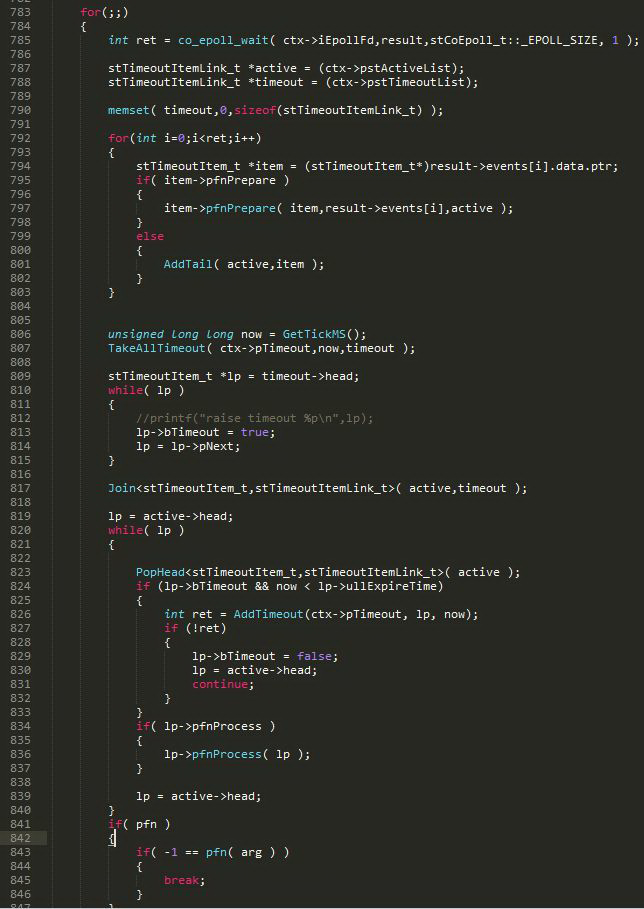
ͼ 23
2.4 �ź�������Э��
libco �ṩ�ź������ƣ����� golang �� channel��example_cond.cpp ���������ߺ������ߵ����ӣ�һ��Э���������ߣ���һ���������ߣ������߲������ݺ��������ߡ�
��Э�����ȴ���������Э�̣���ͨ�� co_resume �л���������Э�̺��� Consumer��co_resume ����õ� coctx_swap ������Э�̵�ջ���ݣ�����������Э�̳�ʼ���� regs ��� esp��ebp�����ص�ַ�����ݵ����Ĵ�����������Э��ջ���ʱ��ʼ����������Э�̡�Consumer �ڼ�鵽 task_queue Ϊ��ʱ����������Э��ͨ�� co_cond_timedwait�����볬ʱ���� pTimeout���������ź������� env->cond��Ȼ��ͨ�� co_yield_ct �л�����Э�̣�co_yield_ct ���õ� coctx_swap ����������������Э�̣����ָ���Э�̡���Э�̽��Ŵ���������Э�̣�ͨ�� co_resume �л���������Э�̡�������Э�̺��� Producer �� task_queue ���������ݺ�ͨ�� co_cond_signal �� pTimeOut��env->cond ��ɾ��������Э�̣�������������� pstActiveList��Ȼ��ͨ�� poll ����������Э�̼��볬ʱ���� pTimeout������ co_poll_inner ͨ�� co_yield_env �лص���Э�̡���Э���� co_eventloop ������������ pstActiveList������������Э������ task_queue �����ݡ�
2.5 ��ʱ����Э��
��ǰЭ��ͨ����� poll(NULL, 0, duration)��������Э�̵ij�ʱʱ���� duration��poll �DZ� hook ס�ĺ�����ִ�� poll ֮��ǰЭ�̻ᱻ�ӵ���ʱ���� pTimeOut�������л�������Э�̣�����Э�̹������Э��ɨ�賬ʱ���У��ҵ���ʱ��Э�̣����л�����˿��� poll ʵ��Э�̵�˯�ߡ�ע�ⲻ���� sleep����Ϊ sleep ��˯���̣߳��߳�˯���ˣ�Э���������ȣ����е�Э��Ҳ������ִ���ˡ�
2.6 �ص�����Э��
ʹ�� libco ��Ҫ hook ס socket �庯������ҵ�����һ��ʹ���ֳɵķ� libco ����⣬����ĸ������ʹ�� hook ס socket �庯����������̫�����ҵ������Э�����첽���ã��첽���ú����Э�̣����е��첽�ص�ʹ��ͬһ��������ͬһ�ص�����������첽����ʱ�ı�Ǿ��������ĸ�Э�̡��÷���Ҳ�������������첽���úʹ����첽���÷��ص����ݡ�����Ҫҵ�������һ��ͳһ���첽�ص����������ڸú�������ݱ�ʶ����Э�̡�
3. Э�̳�
Э�̳صĺô��Dz���ÿ��ʹ��Э��ʱ�������µ�Э�̡�������Э����Ҫ������������һ����Ҫ malloc Э�̻��� stCoRoutine_t��stCoRoutine_t �� 4K ��С��Э��˽�б������飻����Э��ջ 128K��ÿ�δ����µ�Э��Ҫ������ô��Ŀռ���Ҫ��ʱ�俪��������Ƶ�����롢���ٻᵼ���ڴ���Ƭ�IJ�������ʹ�ڹ���ջģʽ�²���Ϊÿ��Э������Э��ջ��Ҳ���е�һ���� stCoRoutine_t �Ŀ�����ÿ�δ�Э�̳�ȡ��Э�̺� stCoRoutine_t.pfn ���³�ʼ��Ϊ�û��Զ����Э�̺������ɡ�
4. Э��˽�б���
Э��˽�б���Ϊÿ��Э�̶��������ᱻ����Э���ģ��ɲο� example_specific.cpp��Э��˽�б���ͨ���� CO_ROUTINE_SPECIFIC ���壬Ȼ�����ز����� -> ʵ�� set/get���ú����ȶ����߳�˽�б��������� pthread_key_t ���͵ı�������ͨ�� pthread_once_t ��֤ pthread_key_t ���ͱ���ֻ�� create һ�Ρ������ǰû�д�����Э�̣����ߵ�ǰЭ������Э�̣���ͨ�� co_pthread_setspecific/pthread_getspecific �� set/get �߳�˽�б����������ڵ�ǰЭ�̵� aSpec ������ set/get Э��˽�б�����pthread_key_t ���͵ı�����Ϊ�����±ꡣ
pthread_once ���� pthread_key_create �ڶ��̻߳�����ֻ��ִ��һ�Ρ�routine_init##name ����һ���̵߳Ķ��Э��ֻ����� pthread_once һ�Σ�����ÿ�� set��get ����ʱ������ pthread_once��
��ΪЭ��˽�б�����Ҫ���ز����� ->����� CO_ROUTINE_SPECIFIC ��һ����������Ϊ�ṹ����ࡣ��Ȼ aSpec �� 1024 ����������ͨ�� pthread_key_create ������ key �Ǵ� 1 ��ʼ�����Э��˽�б���ʵ�ʿ����� 1023 ��Ԫ�ء�
ע������
1. ����ջ�����ݴ۸�
ͼ 24 ��ʾ���룬Э�� RoutineFuncA��RoutineFuncB ����һ������ջ�����д��룬�� 7 ����� 1���� 14 ����� 2�����ڵ� 14 ��֮ǰֻ�� RoutineFuncA �ォ global_ptr ָ�����������Ϊ 1��ԭ������ RoutineFuncA �� global_ptr ָ�� routineidA �ĵ�ַ������ RoutineFuncB ���Ϊ�ǹ���ջ������ routineidB �� routineidA �ĵ�ַһ�������õ�ַ����ֵ���� 13 ����Ϊ 2����˵� 14 �д�ӡ���� 2�����Թ���ջģʽ�£������Э��֮ǰ���ݵ�ַ����Ϊ��ַ�����ݻᱻ�۸ġ�
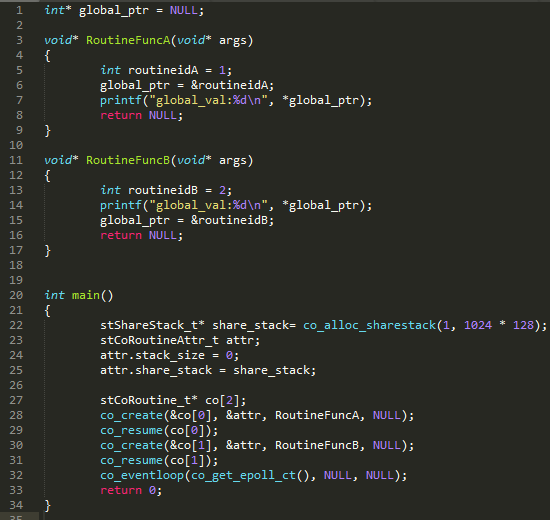
ͼ 24
2. poll ��
libco �Զ���Ĺ��Ӻ��� poll����Ȼ֧�ִ��� fd ���飬��һ�� poll ��� fd ��Ч�ʣ������� poll ÿ�� poll һ�� fd ��Ч�ʣ�ԭ���2.3 epoll ����Э�̡�
3. ջ���
ÿ��Э��ջʹ�� 128K �Ķ��ڴ棬128K �� malloc ʹ�� brk �� mmap ������ڴ�ķֽ��ߡ��� 128K �Ŀռ���ܲ���һ��Э��ʹ�ã�����Э��ջ�����Э��ջ������⣬���������ֽ��������
3.1 ���ڴ�
���ڴ治��Э��ջ�Ϸ��䣬ͨ�� malloc��new �ڶ��Ϸ��䣬����ʹ�ñ������ -Wstack-usage ���ʹ�ýϴ�ջ�ռ�ı���������ջ����ռ�ķǷ���д��һ���� Crash������� 128K Э��ջ�������ӱ���ҳ����ͨ�� mprotect ���ñ���ҳȨ�ޣ��Ƿ���д����ҳʱ����������� Crash���Ƽ�ʹ�ø÷�����
3.2 �Զ�����Э��ջ
��Э�̵��õ����к�����ڼ��ջʹ���ʣ����ջʹ���ʳ�����ֵ�����Զ�����Э��ջ���ڽ��뺯��ʱ������һ����ʱ��������ȡ�ñ����ĵ�ַ varaddr����ΪЭ��ջ�ռ�ߵ�ַΪ stack_mem->stack_bp���͵�ַΪ stack_mem->stack_buffer�����ʹ����Ϊ (stack_mem->stack_bp -varaddr) / (stack_mem->stack_bp - stack_mem->stack_buffer)�����ʹ���ʳ�����ֵ�����������ռ����Э��ջ��������Э��ջ��������Э��ջ��
�����Э�̺�����ʹ����ָ�룬����ָ�� ptr ָ���Э��ջ�ڴ��ַ 0xffd344c0��ջ�������� ptr ��������Ȼ�Ƿ��ʾ�Э��ջ 0xffd344c0�����·Ƿ����ʡ���Э�̺�����ʹ��ָ��ĸ��ʺܴ����������飬��˸÷������սϴ�
golang ֧��Э��ջ���Զ����ݣ�1.3 ֮ǰ�Ƿֶ�ջ������ջ�����������ٿ�����ջ����ջ��ջһ��ʹ�ã�������ջ����������ջ���档ʹ�÷ֶ�ջ���� hot split ���⣬���� 1.3 ��֮���������ջ����ջ������ʱ�������ռ����ջ��������ջ���ݿ�������ջ��������ջ����ջʱ��golang Ҳ����ָ��ʧЧ�����⣬ԭ�IJο����� golang �ı����������ÿ��ָ���λ�ã�ԭ�IJο���ֻҪ֪��ÿ��ָ������ջ��λ�ã�������Э��ջ��ƫ���������ɽ�ָ��Ǩ�Ƶ���ջ��λ�á�
3.3 �����ڴ�
��Ϊ malloc ʹ�õ��������ڴ棬�������ڴ水����䣬Э��ռ�õ��ڴ沢���� malloc ���ڴ��С������ʵ��ʹ�õ����ڴ��С����˿ɽ� malloc(128K) ��Ϊ malloc(8M)�����ڷ�Э�̳�ģʽ�£�Ƶ�� mmap 8M �Ķ��ڴ�ᵼ�´���ȱҳ�жϡ���Э�̳�ģʽ�£���������� 10 ��Э�̣�10 ��Э����������ͬһ���û��Զ����Э�̺��������ú��������ջ�ʹ�� 8M �������ڴ棬���յ���Э�̳��������Э��ʵ��ʹ���ڴ涼Ϊ 8M����Э�̳ش������£���Ѹ�ٺľ��ڴ档����ڻ���Э�̳����Э��ʱ����Ҫ��������ڴ�ʵ��ʹ����������ͬ 3.2.2�������� 128K ʱ����Ҫ����Э�̣��ؽ� 128K ��Э�̼���Э�̳�
|