| БрМЭЦМі: |
БОЮФЪЧДгММЪѕНЧЖШШыЪжЃЌНщЩмRTDPЕФММЪѕбЁаЭКЭЯрЙизщМўЃЌЬНЬжЪЪгУВЛЭЌгІгУГЁОАЕФЯрЙиФЃЪНЁЃRTDPЕФУєНнжЎТЗОЭДЫеЙПЊЃЌЯЃЭћЖдФњгаЫљАяжњ
БОЮФРДздгкcsdnЃЌгЩЛ№СњЙћШэМўDeloresБрМЁЂЭЦМіЁЃ |
|
вЛЁЂММЪѕбЁаЭНщЩм
дкЩшМЦЦЊжаЃЌЮвУЧИјГіСЫRTDPЕФвЛИіећЬхМмЙЙЩшМЦЃЈЭМ1ЃЉЁЃдкММЪѕЦЊРяЃЌЮвУЧдђЛсЭЦМіећЬхММЪѕзщМўбЁаЭЃЛЖдУПИіММЪѕзщМўзіГіМђЕЅНщЩмЃЌгШЦфЖдЮвУЧГщЯѓВЂЪЕЯжЕФЫФИіММЪѕЦНЬЈЃЈЭГвЛЪ§ОнВЩМЏЦНЬЈЁЂЭГвЛСїЪНДІРэЦНЬЈЁЂЭГвЛМЦЫуЗўЮёЦНЬЈЁЂЭГвЛЪ§ОнПЩЪгЛЏЦНЬЈЃЉзХжиНщЩмЩшМЦЫМТЗЃЛЖдPipelineЖЫЕНЖЫЧаУцЛАЬтНјааЬНЬжЃЌАќРЈЙІФмећКЯЁЂЪ§ОнЙмРэЁЂЪ§ОнАВШЋЕШЁЃ
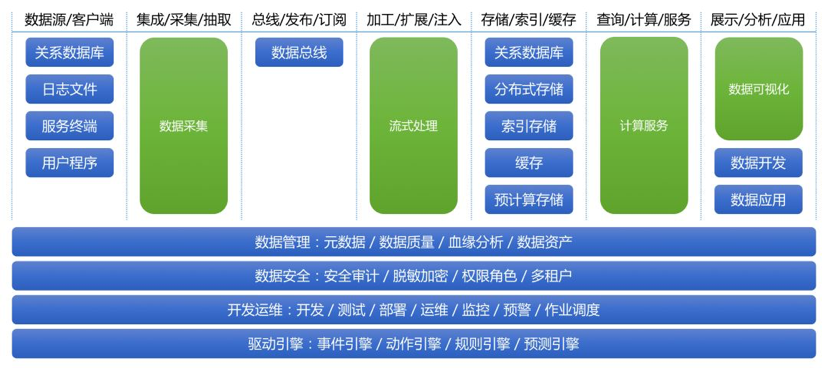
ЭМ1 RTDPМмЙЙ
1.1 ећЬхММЪѕбЁаЭ
ЭМ2 ећЬхММЪѕбЁаЭ
ЪзЯШЃЌЮвУЧМђвЊНтЖСвЛЯТЭМ2ЃК
Ъ§ОндДЁЂПЭЛЇЖЫЃЌСаОйСЫДѓЖрЪ§Ъ§ОнгІгУЯюФПЕФГЃгУЪ§ОндДРраЭЁЃ
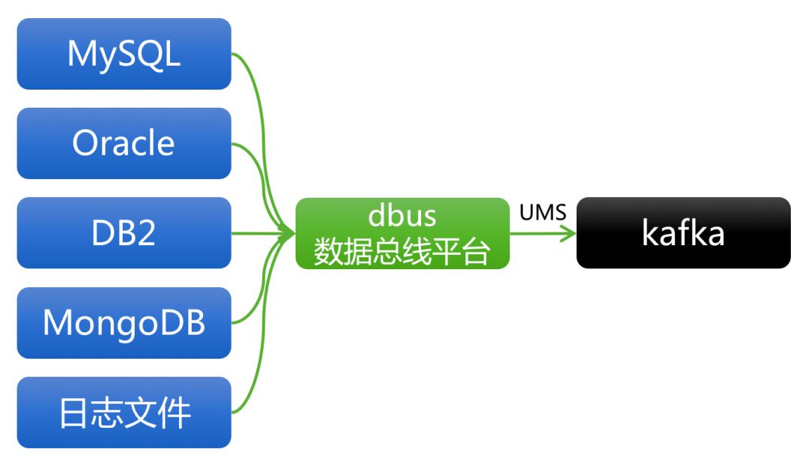
Ъ§ОнзмЯпЦНЬЈDBusЃЌзїЮЊЭГвЛЪ§ОнВЩМЏЦНЬЈЃЌИКд№ЖдНгИїжжЪ§ОндДЁЃDBusНЋЪ§ОнвддіСПЛђШЋСПЗНЪНГщШЁГіРДЃЌВЂНјаавЛаЉГЃЙцЪ§ОнДІРэЃЌзюКѓНЋДІРэКѓЕФЯћЯЂЗЂВМдкKafkaЩЯЁЃ
ЗжВМЪНЯћЯЂЯЕЭГKafkaЃЌвдЗжВМЪНЁЂИпПЩгУЁЂИпЭЬЭТЁЂПЩЗЂВМ-ЖЉдФЕШФмСІЃЌСЌНгЯћЯЂЕФЩњВњепКЭЯћЗбепЁЃ
СїЪНДІРэЦНЬЈWormholeЃЌзїЮЊЭГвЛСїЪНДІРэЦНЬЈЃЌИКд№СїЩЯДІРэКЭЖдНгИїжжЪ§ОнФПБъДцДЂЁЃWormholeДгKafkaЯћЗбЯћЯЂЃЌжЇГжСїЩЯХфжУSQLЗНЪНЪЕЯжСїЩЯЪ§ОнДІРэТпМЃЌВЂжЇГжХфжУЛЏЗНЪННЋЪ§ОнвдзюжевЛжТадЃЈУнЕШЃЉаЇЙћТфШыВЛЭЌЪ§ОнФПБъДцДЂЃЈSinkЃЉжаЁЃ
дкЪ§ОнМЦЫуДцДЂВуЃЌRTDPМмЙЙбЁдёПЊЗХММЪѕзщМўбЁаЭЃЌгУЛЇПЩвдИљОнЪЕМЪЪ§ОнЬиадЁЂМЦЫуФЃЪНЁЂЗУЮЪФЃЪНЁЂЪ§ОнСПЕШаХЯЂбЁдёКЯЪЪЕФДцДЂЃЌНтОіОпЬхЪ§ОнЯюФПЮЪЬтЁЃRTDPЛЙжЇГжЭЌЪБбЁдёЖрИіВЛЭЌЪ§ОнДцДЂЃЌДгЖјИќСщЛюЕФжЇГжВЛЭЌЯюФПашЧѓЁЃ
МЦЫуЗўЮёЦНЬЈMoonboxЃЌзїЮЊЭГвЛМЦЫуЗўЮёЦНЬЈЃЌЖдвьЙЙЪ§ОнДцДЂЖЫИКд№ећКЯЁЂМЦЫуЯТЭЦгХЛЏЁЂвьЙЙЪ§ОнДцДЂЛьЫуЕШЃЈЪ§ОнащФтЛЏММЪѕЃЉЃЌЖдЪ§ОнеЙЪОКЭНЛЛЅЖЫИКд№ЪеПкЭГвЛдЊЪ§ОнВщбЏЁЂЭГвЛЪ§ОнМЦЫуКЭЯТЗЂЁЂЭГвЛЪ§ОнВщбЏгябдЃЈSQLЃЉЁЂЭГвЛЪ§ОнЗўЮёНгПкЕШЁЃ
ПЩЪггІгУЦНЬЈDavinciЃЌзїЮЊЭГвЛЪ§ОнПЩЪгЛЏЦНЬЈЃЌвдХфжУЛЏЗНЪНжЇГжИїжжЪ§ОнПЩЪгЛЏКЭНЛЛЅашЧѓЃЌВЂПЩвдећКЯЦфЫћЪ§ОнгІгУвдЬсЙЉЪ§ОнПЩЪгЛЏВПЗжашЧѓНтОіЗНАИЃЌСэЭтЛЙжЇГжВЛЭЌЪ§ОнДгвЕШЫдБдкЦНЬЈЩЯазїЭъГЩИїЯюШеГЃЪ§ОнгІгУЁЃЦфЫћЪ§ОнжеЖЫЯћЗбЯЕЭГШчЪ§ОнПЊЗЂЦНЬЈZeppelinЁЂЪ§ОнЫуЗЈЦНЬЈJupyterЕШдкБОЮФВЛзіНщЩмЁЃ
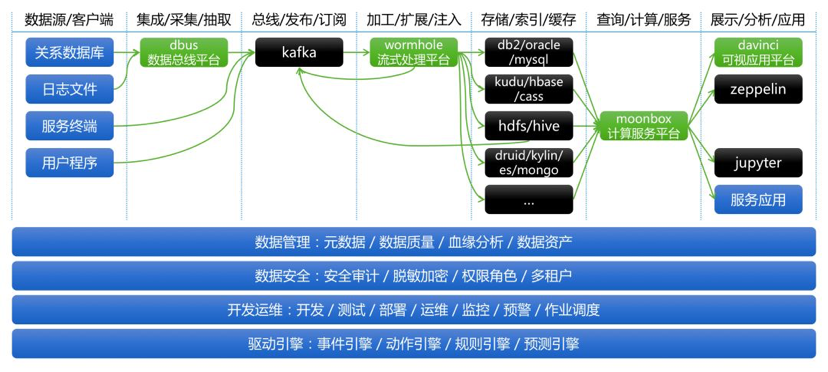
ЧаУцЛАЬтШчЪ§ОнЙмРэЁЂЪ§ОнАВШЋЁЂПЊЗЂдЫЮЌЁЂЧ§ЖЏв§ЧцЃЌПЩвдЭЈЙ§ЖдНгDBusЁЂWormholeЁЂMoonboxЁЂDavinciЕФЗўЮёНгПкНјааећКЯКЭЖўДЮПЊЗЂЃЌвджЇГжЖЫЕНЖЫЙмПиКЭжЮРэашЧѓЁЃ
ЯТУцЮвУЧЛсНјвЛВНЯИЛЏЩЯЭМЩцМАЕНЕФММЪѕзщМўКЭЧаУцЛАЬтЃЌНщЩмММЪѕзщМўЕФЙІФмЬиадЃЌзХжиНВНтЮвУЧздбаММЪѕзщМўЕФЩшМЦЫМЯыЃЌВЂЖдЧаУцЛАЬтеЙПЊЬжТлЁЃ
1.2 ММЪѕзщМўНщЩм
1.2.1 Ъ§ОнзмЯпЦНЬЈDBus
ЭМ3 RTDPМмЙЙжЎDBus
1.2.1.1 DBusЩшМЦЫМЯы
1ЃЉДгЭтВПНЧЖШПДД§ЩшМЦЫМЯы
ИКд№ЖдНгВЛЭЌЕФЪ§ОндДЃЌЪЕЪБГщШЁГідіСПЪ§ОнЃЌЖдгкЪ§ОнПтЛсВЩгУВйзїШежОГщШЁЗНЪНЃЌЖдгкШежОРраЭжЇГжгыЖржжAgentЖдНгЁЃ
НЋЫљгаЯћЯЂвдЭГвЛЕФUMSЯћЯЂИёЪНЗЂВМдкKafkaЩЯЃЌUMSЪЧвЛжжБъзМЛЏЕФздДјдЊЪ§ОнаХЯЂЕФJSONИёЪНЃЌЭЈЙ§ЭГвЛUMSЪЕЯжТпМЯћЯЂгыЮяРэKafka TopicНтёюЃЌЪЙЕУЭЌвЛTopicПЩвдСїзЊЖрИіUMSЯћЯЂБэЁЃ
жЇГжЪ§ОнПтЕФШЋСПЪ§ОнРШЁЃЌВЂЧвКЭдіСПЪ§ОнЭГвЛШкКЯГЩUMSЯћЯЂЃЌЖдЯТгЮЯћЗбЭИУїЮоИажЊЁЃ
2ЃЉДгФкВПНЧЖШПДД§ЩшМЦЫМЯы
ЛљгкStormМЦЫув§ЧцНјааЪ§ОнИёЪНЛЏЃЌШЗБЃЯћЯЂЖЫЕНЖЫбгГйзюЕЭЁЃ
ЖдВЛЭЌЪ§ОндДЪ§ОнНјааБъзМЛЏИёЪНЛЏЃЌЩњГЩUMSаХЯЂЃЌЦфжаАќРЈЃК
ЩњГЩУПЬѕЯћЯЂЕФЮЈвЛЕЅЕїЕндіidЃЌЖдгІЯЕЭГзжЖЮums_id_
ШЗШЯУПЬѕЯћЯЂЕФЪТМўЪБМфДСЃЈevent timestampЃЉЃЌЖдгІЯЕЭГзжЖЮums_ts_
ШЗШЯУПЬѕЯћЯЂЕФВйзїФЃЪНЃЈдіЩОИФЃЌЛђinsert onlyЃЉЃЌЖдгІЯЕЭГзжЖЮums_op_
ЖдЪ§ОнПтБэНсЙЙБфИќЪЕЪБИажЊВЂВЩгУАцБОКХНјааЙмРэЃЌШЗБЃЯТгЮЯћЗбЪБУїШЗЩЯгЮдЊЪ§ОнБфЛЏЁЃ
дкЭЖЗХKafkaЪБШЗБЃЯћЯЂЧПгаађЃЈЗЧОјЖдгаађЃЉКЭat least onceгявхЁЃ
ЭЈЙ§аФЬјБэЛњжЦШЗБЃЯћЯЂЖЫЕНЖЫЬНЛюИажЊЁЃ
1.2.1.2 DBusЙІФмЬиад
жЇГжХфжУЛЏШЋСПЪ§ОнРШЁ
жЇГжХфжУЛЏдіСПЪ§ОнРШЁ
жЇГжХфжУЛЏдкЯпИёЪНЛЏШежО
жЇГжПЩЪгЛЏМрПидЄОЏ
жЇГжХфжУЛЏЖрзтЛЇАВШЋЙмПи
жЇГжЗжБэЪ§ОнЛуМЏГЩЕЅТпМБэ
1.2.1.3 DBusММЪѕМмЙЙ
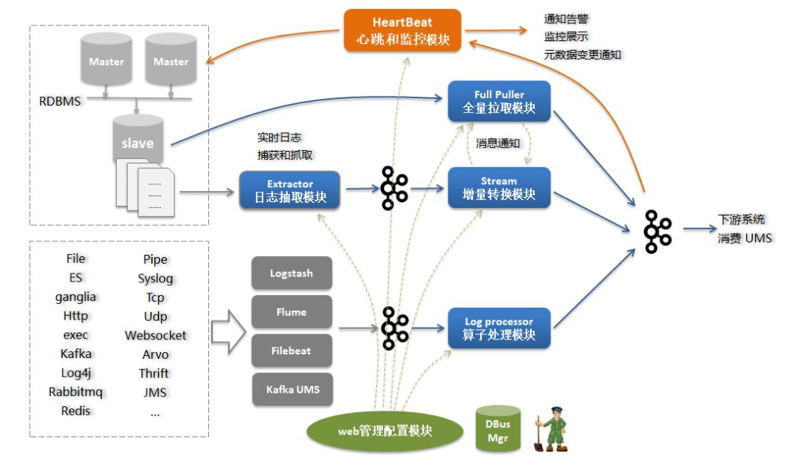
ЭМ4 DBusЪ§ОнСїзЊМмЙЙЭМ
ИќЖрDBusММЪѕЯИНкКЭгУЛЇНчУцЃЌПЩвдВЮПДЃК
GitHubЃК https://github.com/BriData
1.2.2 ЗжВМЪНЯћЯЂЯЕЭГKafka
KafkaвбОГЩЮЊЪТЪЕБъзМЕФДѓЪ§ОнСїЪНДІРэЗжВМЪНЯћЯЂЯЕЭГЃЌЕБШЛKafkaдкВЛЖЯЕФРЉеЙКЭЭъЩЦЃЌЯждквВОпБИСЫвЛЖЈЕФДцДЂФмСІКЭСїЪНДІРэФмСІЁЃЙигкKafkaБОЩэЕФЙІФмКЭММЪѕвбОгаКмЖрЮФеТаХЯЂПЩвдВщдФЃЌБОЮФВЛдйЯъЪіKafkaЕФздЩэФмСІЁЃ
етРяЮвУЧОпЬхЬНЬжKafkaЩЯЯћЯЂдЊЪ§ОнЙмРэЃЈMetadata ManagementЃЉКЭФЃЪНбнБфЃЈSchema EvolutionЃЉЕФЛАЬтЁЃ

ЭМ5
ЭМ5ЯдЪОЃЌдкKafkaБГКѓЕФConfluentЙЋЫОНтОіЗНАИжаЃЌв§ШыСЫвЛИідЊЪ§ОнЙмРэзщМўЃКSchema RegistryЁЃетИізщМўжївЊИКд№ЙмРэдкKafkaЩЯСїзЊЯћЯЂЕФ дЊЪ§ОнаХЯЂКЭTopicаХЯЂЃЌВЂЬсЙЉвЛЯЕСадЊЪ§ОнЙмРэЗўЮёЁЃжЎЫљвдвЊв§ШыетбљвЛИізщМўЃЌЪЧЮЊСЫKafkaЕФЯћЗбЗНФмЙЛСЫНтВЛЭЌTopicЩЯСїзЊЕФЪЧФФаЉЪ§ОнЃЌвдМАЪ§ОнЕФдЊЪ§ОнаХЯЂЃЌВЂНјаагааЇЕФНтЮіЯћЗбЁЃ
ШЮКЮЪ§ОнСїзЊСДТЗЃЌВЛЙмЪЧдкЪВУДЯЕЭГЩЯСїзЊЃЌЖМЛсДцдкетЖЮЪ§ОнСДТЗЕФдЊЪ§ОнЙмРэЮЪЬтЃЌKafkaвВВЛР§ЭтЁЃSchema RegistryЪЧвЛжжжааФЛЏЕФKafkaЪ§ОнСДТЗдЊЪ§ОнЙмРэНтОіЗНАИЃЌВЂЧвЛљгкSchema RegistryЃЌConfluentЬсЙЉСЫЯргІЕФKafkaЪ§ОнАВШЋЛњжЦКЭФЃЪНбнБфЛњжЦЁЃ
ФЧУДдкRTDPМмЙЙжаЃЌШчКЮНтОіKafkaЯћЯЂдЊЪ§ОнЙмРэКЭФЃЪНбнБфЮЪЬтФиЃП
1.2.2.1 дЊЪ§ОнЙмРэЃЈMetadata ManagementЃЉ
DBusЛсздЖЏНЋЪЕЪБИажЊЕФЪ§ОнПтдЊЪ§ОнБфЛЏМЧТМЯТРДВЂЬсЙЉЗўЮё
DBusЛсздЖЏНЋдкЯпИёЪНЛЏЕФШежОдЊЪ§ОнаХЯЂМЧТМЯТРДВЂЬсЙЉЗўЮё
DBusЛсЗЂВМдкKafkaЩЯЗЂВМЭГвЛUMSЯћЯЂЃЌUMSБОЩэздДјЯћЯЂдЊЪ§ОнаХЯЂЃЌвђДЫЯТгЮЯћЗбЪБЮоашЕїгУжааФЛЏдЊЪ§ОнЗўЮёЃЌПЩвджБНгДгUMSЯћЯЂРяФУЕНЪ§ОнЕФдЊЪ§ОнаХЯЂ
1.2.2.2 ФЃЪНбнБфЃЈSchema EvolutionЃЉ
UMSЯћЯЂЛсздДјSchemaЕФNamespaceаХЯЂЃЌNamespaceЪЧвЛИі7ВуЖЈЮЛзжЗћДЎЃЌПЩвдЮЈвЛЖЈЮЛШЮКЮБэЕФШЮКЮЩњУќжмЦкЃЌЯрЕБгкЪ§ОнБэЕФIPЕижЗЃЌаЮЪНШчЯТЃК
[Datastore].[Datastore Instance].[Database].[Table].[TableVersion].[Database Partition].[Table Partition]
Р§ЃКoracle.oracle01.db1.table1.v2.dbpar01.tablepar01
Цфжа[Table Version]ДњБэСЫетеХБэЕФФГИіSchemaЕФАцБОКХЃЌШчЙћЪ§ОндДЪЧЪ§ОнПтЃЌФЧУДетИіАцБОКХЪЧгЩDBusздЖЏЮЌЛЄЕФЁЃ
дкRTDPМмЙЙжаЃЌKafkaЕФЯТгЮЪЧгЩWormholeЯћЗбЕФЃЌWormholeдкЯћЗбUMSЪБЃЌЛсНЋ[TableVersion]зїЮЊ*ДІРэЃЌвтЮЖзХЕБФГБэЩЯгЮSchemaБфИќЪБЃЌVersionЛсздЖЏЩ§КХЃЌЕЋWormholeЛсЮоЪгетИіVersionБфЛЏЃЌНЋЛсЯћЗбДЫБэЫљгаАцБОЕФдіСП/ШЋСПЪ§ОнЃЌФЧУДWormholeШчКЮзіЕНМцШнадФЃЪНбнБфжЇГжФиЃПдкWormholeРяПЩвдХфжУСїЩЯДІРэSQLКЭЪфГізжЖЮЃЌЕБЩЯгЮSchemaБфИќЪЧвЛжжЁАМцШнадБфИќЁБЃЈжИдіМгзжЖЮЃЌЛђепаоИФРЉДѓзжЖЮРраЭЕШЃЉЪБЃЌЪЧВЛЛсгАЯьЕНWormhole SQLе§ШЗжДааЕФЁЃЕБЩЯгЮЗЂЩњЗЧМцШнадБфИќЪБЃЌWormholeЛсБЈДэЃЌетЪБОЭашвЊШЫЙЄНщШыЖдаТSchemaЕФТпМНјаааоИДЁЃ
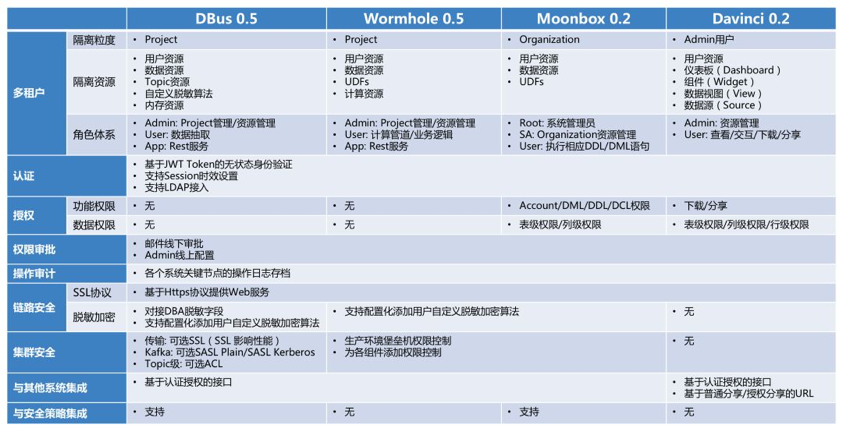
гЩЩЯЮФПЩвдПДГіЃЌSchema RegistryКЭDBus+UMSЪЧСНжжВЛЭЌЕФНтОідЊЪ§ОнЙмРэКЭФЃЪНбнБфЕФЩшМЦЫМТЗЃЌСНепИїгагХЪЦКЭСгЪЦЃЌПЩвдВЮПМБэ1ЕФМђЕЅБШНЯЁЃ
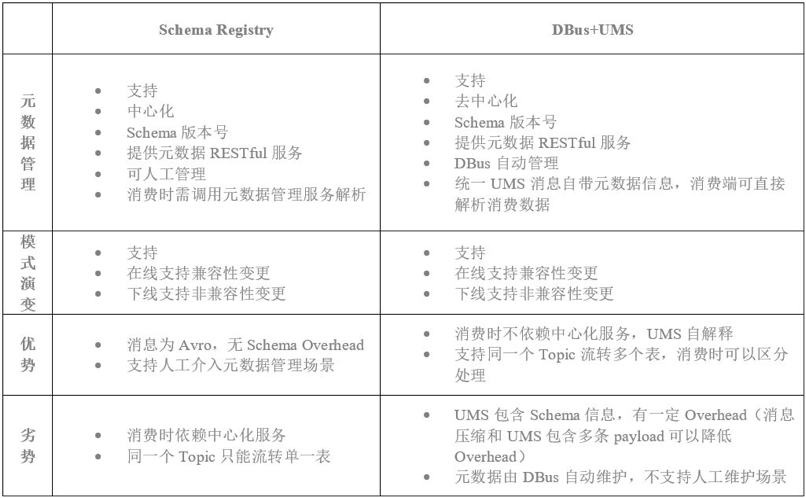
Бэ1 Schema Registry гы DBus+UMS ЖдБШ
етРяИјГівЛИіUMSЕФР§згЃК
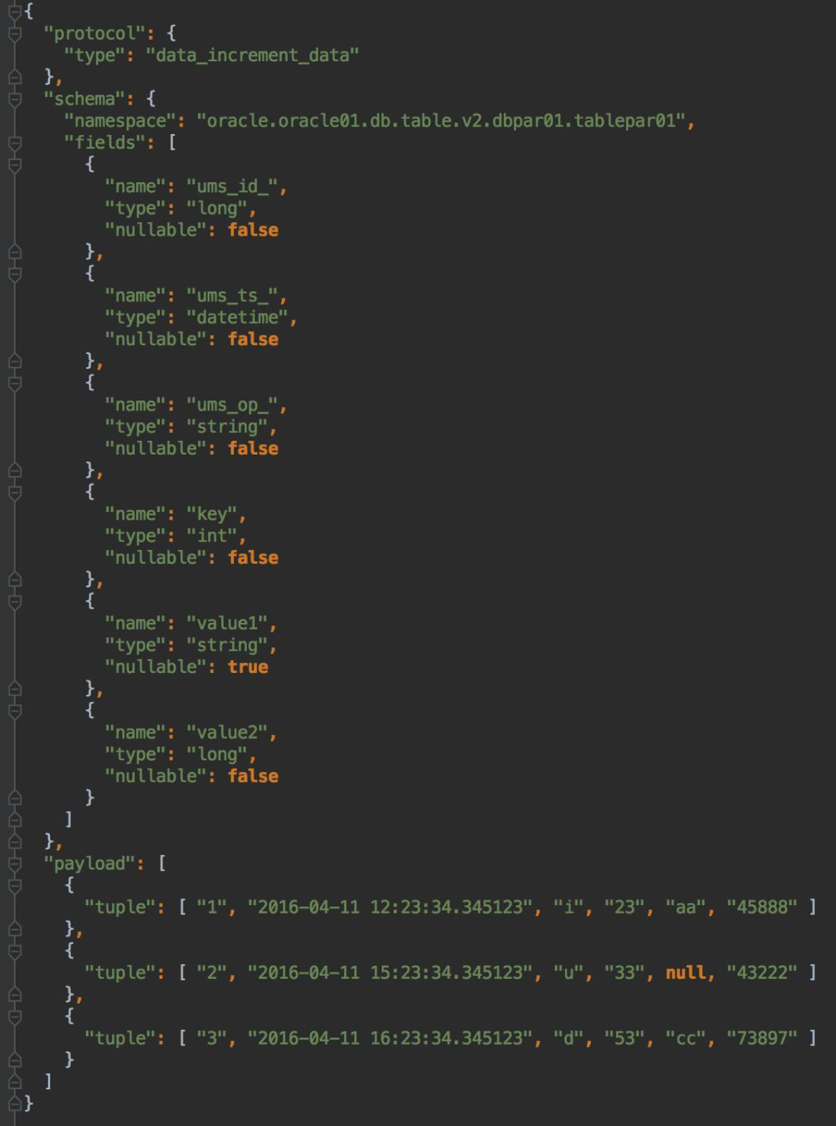
ЭМ6 UMSЯћЯЂОйР§
1.2.3 СїЪНДІРэЦНЬЈWormhole
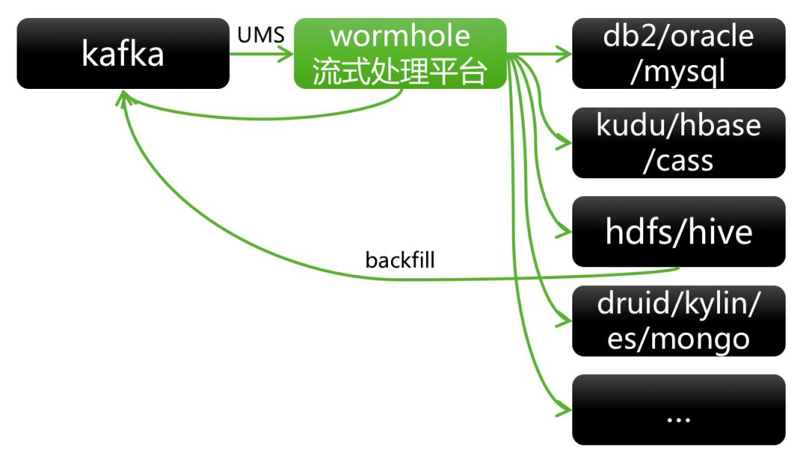
ЭМ7 RTDPМмЙЙжЎWormhole
1.2.3.1 WormholeЩшМЦЫМЯы
1)ДгЭтВПНЧЖШПДД§ЩшМЦЫМЯы
ЯћЗбРДздKafka ЕФUMSЯћЯЂКЭздЖЈвхJSONЯћЯЂ
ИКд№ЖдНгВЛЭЌЕФЪ§ОнФПБъДцДЂ (Sink)ЃЌВЂЭЈЙ§УнЕШТпМЪЕЯжSinkЕФзюжевЛжТад
жЇГжХфжУSQLЗНЪНЪЕЯжСїЩЯДІРэТпМ
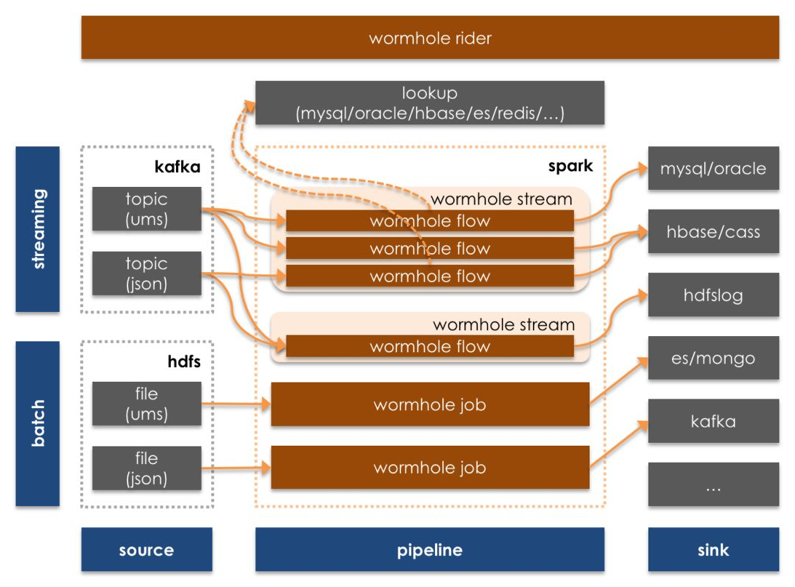
ЬсЙЉFlowГщЯѓЁЃFlowгЩвЛИіSource NamespaceКЭвЛИіSink NamespaceЖЈвхЃЌЧвОпБИЮЈвЛадЁЃFlowЩЯПЩвдЖЈвхДІРэТпМЃЌЪЧвЛжжСїЩЯДІРэЕФТпМГщЯѓЃЌЭЈЙ§гыЮяРэSpark StreamingЁЂFlink StreamingНтёюЃЌЪЙЕУЭЌвЛИіStreamПЩвдДІРэЖрИіFlowДІРэСїЃЌЧвFlowПЩвддкВЛЭЌStreamЩЯШЮвтЧаЛЛЁЃ
жЇГжЛљгкЛиЙрЃЈbackfillЃЉЕФKappaМмЙЙЃЛжЇГжЛљгкWormhole JobЕФLambdaМмЙЙ
2)ДгФкВПНЧЖШПДД§ЩшМЦЫМЯы
ЛљгкSpark StreamingЁЂFlinkМЦЫув§ЧцНјааЪ§ОнСїЩЯДІРэЁЃSpark StreamingПЩжЇГжИпЭЬЭТЁЂХњСПLookupЁЂХњСПаДSinkЕШГЁОАЃЛFlinkПЩжЇГжЕЭбгГйЁЂCEPЙцдђЕШГЁОАЁЃ
ЭЈЙ§ums_id_, ums_op_ЪЕЯжВЛЭЌSinkЕФУнЕШШыПтТпМ
ЭЈЙ§МЦЫуЯТЭЦЪЕЯжLookupТпМгХЛЏ
ГщЯѓМИИіЭГвЛвджЇГжЙІФмСщЛюадКЭЩшМЦвЛжТад
ЭГвЛDAGИпНзЗжаЮГщЯѓ
ЭГвЛЭЈгУСїЯћЯЂUMSавщГщЯѓ
ЭГвЛЪ§ОнТпМБэУќУћПеМфNamespaceГщЯѓ
ГщЯѓМИИіНгПквджЇГжПЩРЉеЙад
SinkProcessorЃКРЉеЙИќЖрSinkжЇГж
SwiftsInterfaceЃКздЖЈвхСїЩЯДІРэТпМжЇГж
UDFЃКИќЖрСїЩЯДІРэUDFжЇГж
ЭЈЙ§FeedbackЯћЯЂЪЕЪБЙщМЏСїЪНзївЕЖЏЬЌжИБъКЭЭГМЦ
1.2.3.2 WormholeЙІФмЬиад
жЇГжПЩЪгЛЏЃЌХфжУЛЏЃЌSQLЛЏПЊЗЂЪЕЪЉСїЪНЯюФП
жЇГжжИСюЪНЖЏЬЌСїЪНДІРэЕФЙмРэЁЂдЫЮЌЁЂеяЖЯКЭМрПи
жЇГжЭГвЛНсЙЙЛЏUMSЯћЯЂКЭздЖЈвхАыНсЙЙЛЏJSONЯћЯЂ
жЇГжДІРэдіЩОИФШ§ЬЌЪТМўЯћЯЂСї
жЇГжЕЅИіЮяРэСїЭЌЪБВЂааДІРэЖрИіТпМвЕЮёСї
жЇГжСїЩЯLookup AnywhereЃЌPushdown Anywhere
жЇГжЛљгквЕЮёВпТдЕФЪТМўЪБМфДССїЪНДІРэ
жЇГжUDFЕФзЂВсЙмРэКЭЖЏЬЌМгди
жЇГжЖрФПБъЪ§ОнЯЕЭГЕФВЂЗЂУнЕШШыПт
жЇГжЖрМЖЛљгкдіСПЯћЯЂЕФЪ§ОнжЪСПЙмРэ
жЇГжЛљгкдіСПЯћЯЂЕФСїЪНДІРэКЭХњСПДІРэ
жЇГжLambdaМмЙЙКЭKappaМмЙЙ
жЇГжгыШ§ЗНЯЕЭГЮоЗьМЏГЩЃЌПЩзїЮЊШ§ЗНЯЕЭГЕФСїПив§Чц
жЇГжЫНгадЦВПЪ№ЃЌАВШЋШЈЯоЙмПиКЭЖрзтЛЇзЪдДЙмРэ
1.2.3.3 WormholeММЪѕМмЙЙ
ЭМ8 WormholeЪ§ОнСїзЊМмЙЙЭМ
ИќЖрWormholeММЪѕЯИНкКЭгУЛЇНчУцЃЌПЩвдВЮПДЃК
GitHubЃКhttps://github.com/edp963/wormhole
1.2.4 ГЃгУЪ§ОнМЦЫуДцДЂбЁаЭ
RTDPМмЙЙЖдД§Ъ§ОнМЦЫуДцДЂбЁаЭЕФбЁдёВЩШЁПЊЗХећКЯЕФЬЌЖШЁЃВЛЭЌЪ§ОнЯЕЭГгаИїздЕФгХЪЦКЭЪЪКЯЕФГЁОАЃЌЕЋВЂУЛгавЛИіЪ§ОнЯЕЭГПЩвдЪЪКЯИїжжИїбљЕФДцДЂМЦЫуГЁОАЁЃвђДЫЕБгаКЯЪЪЕФЁЂГЩЪьЕФЁЂжїСїЕФЪ§ОнЯЕЭГГіЯжЃЌWormholeКЭMoonboxЛсАДееашвЊЯргІЕФРЉеЙећКЯжЇГжЁЃ
етРяДѓжТСаОйвЛаЉБШНЯЭЈгУЕФбЁаЭЃК
ЙиЯЕаЭЪ§ОнПтЃЈOracle/MySQLЕШЃЉЃКЪЪКЯаЁЪ§ОнСПЕФИДдгЙиЯЕМЦЫу
ЗжВМЪНСаДцДЂЯЕЭГ
KuduЃКScanгХЛЏЃЌЪЪКЯOLAPЗжЮіМЦЫуГЁОА
HBaseЃКЫцЛњЖСаДЃЌЪЪКЯЬсЙЉЪ§ОнЗўЮёГЁОА
CassandraЃКИпадФмаДЃЌЪЪКЯКЃСПЪ§ОнИпЦЕаДШыГЁОА
ClickHouseЃКИпадФмМЦЫуЃЌЪЪКЯжЛгаinsertаДШыГЁОАЃЈКѓЦкНЋжЇГжИќаТЩОГ§ВйзїЃЉ
ЗжВМЪНЮФМўЯЕЭГ
HDFS/Parquet/HiveЃКappend onlyЃЌЪЪКЯКЃСПЪ§ОнХњСПМЦЫуГЁОА
ЗжВМЪНЮФЕЕЯЕЭГ
MongoDBЃКЦНКтФмСІЃЌЪЪКЯДѓЪ§ОнСПжаЕШИДдгМЦЫу
ЗжВМЪНЫїв§ЯЕЭГ
ElasticSearchЃКЫїв§ФмСІЃЌЪЪКЯзіФЃК§ВщбЏКЭOLAPЗжЮіГЁОА
ЗжВМЪНдЄМЦЫуЯЕЭГ
Druid/KylinЃКдЄМЦЫуФмСІЃЌЪЪКЯИпадФмOLAPЗжЮіГЁОА
1.2.5 МЦЫуЗўЮёЦНЬЈMoonbox
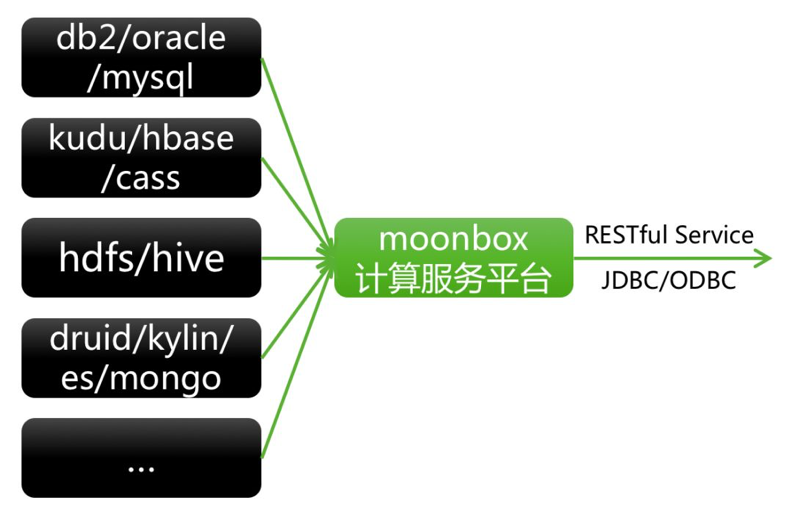
ЭМ9 RTDPМмЙЙжЎMoonbox
1.2.5.1 MoonboxЩшМЦЫМЯы
1)ДгЭтВПНЧЖШПДД§ЩшМЦЫМЯы
ИКд№ЖдНгВЛЭЌЕФЪ§ОнЯЕЭГЃЌжЇГжЭГвЛЗНЪНПчвьЙЙЪ§ОнЯЕЭГМДЯЏЛьЫу
ЬсЙЉШ§жжClientЕїгУЗНЪНЃКRESTfulЗўЮёЁЂJDBCСЌНгЁЂODBCСЌНг
ЭГвЛдЊЪ§ОнЪеПкЃЛЭГвЛВщбЏгябдSQLЪеПкЃЛЭГвЛШЈЯоПижЦЪеПк
ЬсЙЉСНжжВщбЏНсЙћаДГіФЃЪНЃКMergeЁЂReplace
ЬсЙЉСНжжНЛЛЅФЃЪНЃКBatchФЃЪНЁЂAdhocФЃЪН
Ъ§ОнащФтЛЏЪЕЯжЃЌЖрзтЛЇЪЕЯжЃЌПЩПДзїЪЧащФтЪ§ОнПт
2)ДгФкВПНЧЖШПДД§ЩшМЦЫМЯы
ЖдSQLНјааНтЮіЃЌОЙ§ГЃЙцCatalystДІРэНтЮіСїГЬЃЌзюжеЩњГЩПЩЯТЭЦЪ§ОнЯЕЭГЕФТпМжДаазгЪїНјааЯТЭЦМЦЫуЃЌШЛКѓНЋНсЙћРЛиНјааЛьЫуВЂЗЕЛи
жЇГжСНВуNamespaceЃКdatabase.tableЃЌвдЬсЙЉащФтЪ§ОнПтЬхбщ
ЬсЙЉЗжВМЪНЗўЮёФЃПщMoonbox GridЬсЙЉИпПЩгУИпВЂЗЂФмСІ
ЖдПЩШЋВПЯТЭЦТпМЃЈЮоЛьЫуЃЉЬсЙЉПьЫйжДааЭЈЕР
1.2.5.2 MoonboxЙІФмЬиад
жЇГжПчвьЙЙЯЕЭГЮоЗьЛьЫу
жЇГжЭГвЛSQLгяЗЈВщбЏМЦЫуКЭаДШы
жЇГжШ§жжЕїгУЗНЪНЃКRESTfulЗўЮёЁЂJDBCСЌНгЁЂODBCСЌНг
жЇГжСНжжНЛЛЅФЃЪНЃКBatchФЃЪНЁЂAdhocФЃЪН
жЇГжCli CommandЙЄОпКЭZeppelin
жЇГжЖрзтЛЇгУЛЇШЈЯоЬхЯЕ
жЇГжБэМЖШЈЯоЁЂСаМЖШЈЯоЁЂЖСШЈЯоЁЂаДШЈЯоЁЂUDFШЈЯо
жЇГжYARNЕїЖШЦїзЪдДЙмРэ
жЇГждЊЪ§ОнЗўЮё
жЇГжЖЈЪБШЮЮё
жЇГжАВШЋВпТд
1.2.5.3 MoonboxММЪѕМмЙЙ
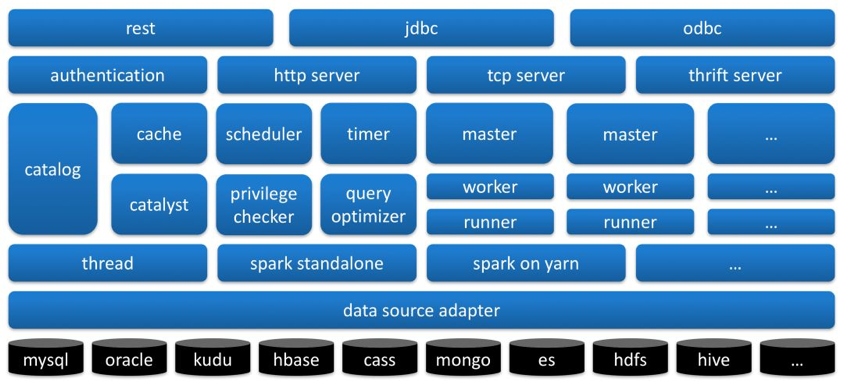
ЭМ10 MoonboxТпМФЃПщ
ИќЖрMoonboxММЪѕЯИНкКЭгУЛЇНчУцЃЌПЩвдВЮПДЃК
GitHubЃК https://github.com/edp963/moonbox
1.2.6 ПЩЪггІгУЦНЬЈDavinci
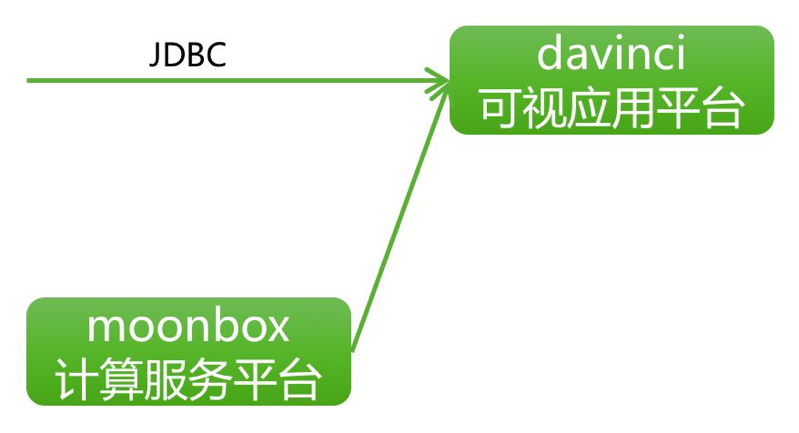
ЭМ11 RTDPМмЙЙжЎDavinci
1.2.6.1 DavinciЩшМЦЫМЯы
1)ДгЭтВПНЧЖШПДД§ЩшМЦЫМЯы
ИКд№ИїжжЪ§ОнПЩЪгЛЏеЙЪОЙІФм
жЇГжJDBCЪ§ОндД
ЬсЙЉЦНШЈгУЛЇЬхЯЕЃЌУПИігУЛЇПЩвдНЈСЂЪєгкздМКЕФOrgЁЂTeamКЭProject
жЇГжSQLБраДЪ§ОнДІРэТпМЃЌжЇГжЭЯзЇЪНБрМПЩЪгЛЏеЙЪОЃЌЬсЙЉЖргУЛЇЩчНЛЛЏЗжЙЄазїЛЗОГ
ЬсЙЉЖржжВЛЭЌЕФЭМБэНЛЛЅФмСІКЭЖЈжЦЛЏФмСІЃЌвдгІЖдВЛЭЌЪ§ОнПЩЪгЛЏашЧѓ
ЬсЙЉЧЖШыећКЯНјЦфЫћЪ§ОнгІгУЕФФмСІ
2)ДгФкВПНЧЖШПДД§ЩшМЦЫМЯы
ЮЇШЦViewКЭWidgetеЙПЊЁЃViewЪЧЪ§ОнЕФТпМЪгЭМЃЛWidgetЪЧЪ§ОнПЩЪгЛЏЪгЭМ
ЭЈЙ§гУЛЇздЖЈвхбЁдёЗжРрЪ§ОнЁЂгаађЪ§ОнКЭСПЛЏЪ§ОнЃЌАДееКЯРэЕФПЩЪгЛЏТпМздЖЏеЙЯжЪгЭМ
1.2.6.2 DavinciЙІФмЬиад
1)Ъ§ОндД
жЇГжJDBCЪ§ОндД
жЇГжCSVЮФМўЩЯДЋ
2)Ъ§ОнЪгЭМ
жЇГжЖЈвхSQLФЃАц
жЇГжSQLИпССЯдЪО
жЇГжSQLВтЪд
жЇГжЛиаДВйзї
3)ПЩЪгзщМў
жЇГждЄЖЈвхЭМБэ
жЇГжПижЦЦїзщМў
жЇГжздгЩбљЪН
4)НЛЛЅФмСІ
жЇГжПЩЪгзщМўШЋЦСЯдЪО
жЇГжПЩЪгзщМўБОЕиПижЦЦї
жЇГжПЩЪгзщМўМфЙ§ТЫСЊЖЏ
жЇГжШКПиПижЦЦїПЩЪгзщМў
жЇГжПЩЪгзщМўБОЕиИпМЖЙ§ТЫЦї
жЇГжДѓЪ§ОнСПеЙЪОЗжвГКЭЛЌПщ
5)МЏГЩФмСІ
жЇГжПЩЪгзщМўCSVЯТди
жЇГжПЩЪгзщМўЙЋЙВЗжЯэ
жЇГжПЩЪгзщМўЪкШЈЗжЯэ
жЇГжвЧБэАхЙЋЙВЗжЯэ
жЇГжвЧБэАхЪкШЈЗжЯэ
6)АВШЋШЈЯо
жЇГжЪ§ОнааСаШЈЯо
жЇГжLDAPЕЧТММЏГЩ
ИќЖрDavinciММЪѕЯИНкКЭгУЛЇНчУцЃЌПЩвдВЮПДЃК
GitHubЃКhttps://github.com/edp963/davinci
1.3 ЧаУцЛАЬтЬжТл
1.3.1 Ъ§ОнЙмРэ
1ЃЉдЊЪ§ОнЙмРэ
DBusПЩвдЪЕЪБФУЕНЪ§ОндДЕФдЊЪ§ОнВЂЬсЙЉЗўЮёВщбЏ
MoonboxПЩвдЪЕЪБФУЕНЪ§ОнЯЕЭГЕФдЊЪ§ОнВЂЬсЙЉЗўЮёВщбЏ
ЖдгкRTDPМмЙЙРДЫЕЃЌЪЕЪБЪ§ОндДКЭМДЯЏЪ§ОндДЕФдЊЪ§ОнаХЯЂПЩвдЭЈЙ§ЕїгУDBusКЭMoonboxЕФRESTfulЗўЮёЙщМЏЃЌПЩвдЛљгкДЫНЈЩшЦѓвЕМЖдЊЪ§ОнЙмРэЯЕЭГ
2ЃЉЪ§ОнжЪСП
WormholeПЩвдХфжУЯћЯЂЪЕЪБТфШыHDFSЃЈhdfslogЃЉЁЃЛљгкhdfslogЕФWormhole JobжЇГжLambdaМмЙЙЃЛЛљгкhdfslogЕФBackfillжЇГжKappaМмЙЙЁЃПЩвдЭЈЙ§ЩшжУЖЈЪБШЮЮёбЁдёLambdaМмЙЙЛђепKappaМмЙЙЖдSinkНјааЖЈЪБЫЂаТЃЌвдШЗБЃЪ§ОнЕФзюжевЛжТадЁЃWormholeЛЙжЇГжНЋСїЩЯДІРэвьГЃЛђSinkаДШывьГЃЕФЯћЯЂаХЯЂЪЕЪБFeedbackЕНWormholeЯЕЭГжаЃЌВЂЬсЙЉRESTfulЗўЮёЙЉШ§ЗНгІгУЕїгУДІРэЁЃ
MoonboxПЩвдЖдвьЙЙЯЕЭГНјааМДЯЏЛьЫуЃЌетИіФмСІИГгшMoonboxЁАШ№ЪПОќЕЖЁБАуЕФБуРћадЁЃПЩвдЭЈЙ§MoonboxБраДЖЈЪБSQLНХБОТпМЃЌЖдЙизЂЕФвьЙЙЯЕЭГЪ§ОнНјааБШЖдЃЌЛђЖдЙизЂЕФЪ§ОнБэзжЖЮНјааЭГМЦЕШЃЌПЩвдЛљгкMoonboxЕФФмСІЖўДЮПЊЗЂЪ§ОнжЪСПМьВтЯЕЭГЁЃ
3ЃЉбЊдЕЗжЮі
WormholeЕФСїЩЯДІРэТпМЭЈГЃSQLМДПЩТњзуЃЌетаЉSQLПЩвдЭЈЙ§RESTfulЗўЮёНјааЙщМЏЁЃ
MoonboxеЦЙмСЫЪ§ОнВщбЏЕФЭГвЛШыПкЃЌВЂЧвЫљгаТпМОљЮЊSQLЃЌетаЉSQLПЩвдЭЈЙ§MoonboxШежОНјааЙщМЏЁЃ
ЖдгкRTDPМмЙЙРДЫЕЃЌЪЕЪБДІРэТпМКЭМДЯЏДІРэТпМЕФSQLПЩвдЭЈЙ§ЕїгУWormholeЕФRESTfulЗўЮёКЭMoonboxЕФШежОЙщМЏЃЌПЩвдЛљгкДЫНЈЩшЦѓвЕМЖбЊдЕЗжЮіЯЕЭГЁЃ
1.3.2 Ъ§ОнАВШЋ
ЭМ12 RTDPЪ§ОнАВШЋ
ЩЯЭМИјГіСЫRTDPМмЙЙжаЃЌЫФИіПЊдДЦНЬЈИВИЧСЫЖЫЕНЖЫЪ§ОнСїзЊСДТЗЃЌВЂЧвдкУПИіНкЕуЩЯЖМгаЖдЪ§ОнАВШЋИїИіЗНУцЕФПМСПКЭжЇГжЃЌШЗБЃСЫЪЕЪБЪ§ОнЙмЕРЖЫЕНЖЫЕФЪ§ОнАВШЋадЁЃ
СэЭтЃЌгЩгкMoonboxГЩЮЊСЫУцЯђгІгУВуЪ§ОнЗУЮЪЕФЭГвЛШыПкЃЌвђДЫЛљгкMoonboxЕФВйзїЩѓМЦШежОПЩвдЛёЕУКмЖрАВШЋВуУцЕФаХЯЂЃЌПЩвдЮЇШЦВйзїЩѓМЦШежОНЈСЂЪ§ОнАВШЋдЄОЏЛњжЦЃЌНјЖјНЈЩшЦѓвЕМЖЪ§ОнАВШЋЯЕЭГЁЃ
1.3.3 ПЊЗЂдЫЮЌ
1ЃЉдЫЮЌЙмРэ
ЪЕЪБЪ§ОнДІРэЕФдЫЮЌЙмРэЯђРДЪЧИіЭДЕуЃЌDBusКЭWormholeЭЈЙ§ПЩЪгЛЏUIЬсЙЉСЫПЩЪгЛЏдЫЮЌЙмРэФмСІЃЌШУШЫЙЄдЫЮЌБфЕУМђЕЅЁЃ
DBusКЭWormholeЬсЙЉСЫНЁПЕМьВщЁЂВйзїЙмРэЁЂBackfillЁЂFlowЦЏвЦЕШRESTfulЗўЮёЃЌПЩвдЛљгкДЫбаЗЂздЖЏЛЏдЫЮЌЯЕЭГЁЃ
2ЃЉМрПидЄОЏ
DBusКЭWormholeОљЬсЙЉПЩЪгЛЏМрПиНчУцЃЌПЩвдЪЕЪБПДЕНТпМБэМЖЕФЭЬЭТКЭбгГйЕШаХЯЂЁЃ
DBusКЭWormholeЬсЙЉСЫаФЬјЁЂStatsЁЂзДЬЌЕШRESTfulЗўЮёЃЌПЩвдЛљгкДЫбаЗЂздЖЏЛЏдЄОЏЯЕЭГЁЃ
ЖўЁЂФЃЪНГЁОАЬНЬж
ЩЯвЛеТЮвУЧНщЩмСЫRTDPМмЙЙИїИіММЪѕзщМўЕФЩшМЦМмЙЙКЭЙІФмЬиадЃЌжСДЫЖСепвбОЖдRTDPМмЙЙШчКЮТфЕигаСЫОпЬхЕФШЯЪЖКЭСЫНтЁЃФЧУДRTDPМмЙЙПЩвдНтОіФФаЉГЃМћЪ§ОнгІгУГЁОАФиЃПЯТУцЮвУЧЛсЬНЬжМИжжЪЙгУФЃЪНЃЌвдМАВЛЭЌФЃЪНЪЪгІКЮжжашЧѓГЁОАЁЃ
2.1 ЭЌВНФЃЪН
2.1.1 ФЃЪНУшЪі
ЭЌВНФЃЪНЃЌЪЧжИжЛХфжУвьЙЙЪ§ОнЯЕЭГжЎМфЕФЪ§ОнЪЕЪБЭЌВНЃЌдкСїЩЯВЛзіШЮКЮДІРэТпМЕФЪЙгУФЃЪНЁЃ
ОпЬхЖјбдЃЌЭЈЙ§ХфжУDBusНЋЪ§ОнДгЪ§ОндДЪЕЪБГщШЁГіРДЭЖЗХдкKafkaЩЯЃЌШЛКѓЭЈЙ§ХфжУWormholeНЋKafkaЩЯЪ§ОнЪЕЪБаДШыЕНSinkДцДЂжаЁЃЭЌВНФЃЪНжївЊЬсЙЉСЫСНИіФмСІЃК
КѓајЪ§ОнДІРэТпМВЛдйжДаадквЕЮёБИПтЩЯЃЌМѕЩйСЫЖдвЕЮёБИПтЕФЪЙгУбЙСІ
ЬсЙЉСЫНЋВЛЭЌЮяРэвЕЮёБИПтЪ§ОнЪЕЪБЭЌВНЕНЭЌвЛЮяРэЪ§ОнДцДЂЕФПЩФмад
2.1.2 ММЪѕФбЕу
ОпЬхЪЕЪЉБШНЯМђЕЅЁЃ
ITЪЕЪЉШЫдБЮоашСЫНтЬЋЖрСїЪНДІРэЕФГЃМћЮЪЬтЃЌВЛашвЊПМТЧСїЩЯДІРэТпМЪЕЯжЕФЩшМЦКЭЪЕЪЉЃЌжЛашвЊСЫНтЛљБОЕФСїПиВЮЪ§ХфжУМДПЩЁЃ
2.1.3 дЫЮЌЙмРэ
дЫЮЌЙмРэБШНЯМђЕЅЁЃ
ашвЊШЫЙЄдЫЮЌЁЃЕЋгЩгкСїЩЯУЛгаДІРэТпМЃЌвђДЫШнвзАбПиСїЫйЃЌЮоашПМТЧСїЩЯДІРэТпМБОЩэЕФЙІКФЃЌПЩвдИјГівЛИіЯрЖдЮШЖЈЕФЭЌВНЙмЕРХфжУЁЃВЂЧввВКмШнвззіЕНЖЈЪБЖЫЕНЖЫЪ§ОнБШЖдРДШЗБЃЪ§ОнжЪСПЃЌвђЮЊдДЖЫКЭФПБъЖЫЕФЪ§ОнЪЧЭъШЋвЛжТЕФЁЃ
2.1.4 ЪЪгУГЁОА
ПчВПУХЪ§ОнЪЕЪБЭЌВНЙВЯэ
НЛвзЪ§ОнПтКЭЗжЮіЪ§ОнПтНтёю
жЇГжЪ§ВжЪЕЪБODSВуНЈЩш
гУЛЇзджњЪЕЪБМђЕЅБЈБэПЊЗЂ
ЕШЕШ
2.2 СїЫуФЃЪН
2.2.1 ФЃЪНУшЪі
СїЫуФЃЪНЃЌЪЧжИдкЭЌВНФЃЪНЕФЛљДЁЩЯЃЌдкСїЩЯХфжУДІРэТпМЕФЪЙгУФЃЪНЁЃ
дкRTDPМмЙЙжаЃЌСїЩЯДІРэТпМЕФХфжУКЭжЇГжжївЊдкWormholeЦНЬЈЩЯНјааЁЃдкЭЌВНФЃЪНЕФФмСІжЎЩЯЃЌСїЫуФЃЪНжївЊЬсЙЉСЫСНИіФмСІЃК
СїЩЯМЦЫуНЋХњСПМЦЫуМЏжаЙІКФЗжЩЂдкСїЩЯдіСПМЦЫуГжајЙІКФЃЌМЋДѓНЕЕЭСЫНсЙћПьееЕФЪБМфбгГй
СїЩЯМЦЫуЬсЙЉСЫПчвьЙЙЯЕЭГЛьЫуЕФаТЕФМЦЫуШыПкЃЈLookupЃЉ
2.2.2 ММЪѕФбЕу
ОпЬхЪЕЪЉЯрЖдНЯФбЁЃ
гУЛЇашвЊСЫНтСїЩЯДІРэФмзіФФаЉЪТЃЌЪЪКЯзіФФаЉЪТЃЌШчКЮзЊЛЏШЋСПМЦЫуТпМГЩЮЊдіСПМЦЫуТпМЕШЁЃЛЙвЊПМТЧСїЩЯДІРэТпМБОЩэЙІКФКЭвРРЕЕФЭтВПЪ§ОнЯЕЭГЕШвђЫиРДЕїНкХфжУИќЖрВЮЪ§ЁЃ
2.2.3 дЫЮЌЙмРэ
дЫЮЌЙмРэЯрЖдНЯФбЁЃ
ашвЊШЫЙЄдЫЮЌЁЃЕЋБШЭЌВНФЃЪНдЫЮЌЙмРэИќФбЃЌжївЊЬхЯждкСїПиВЮЪ§ХфжУПМТЧвђЫиНЯЖрЁЂЮоЗЈжЇГжЖЫЕНЖЫЪ§ОнБШЖдЁЂвЊбЁдёНсЙћПьеезюжевЛжТадЪЕЯжВпТдЁЂвЊПМТЧСїЩЯLookupЪБМфЖдЦыВпТдЕШЗНУцЮЪЬтЁЃ
2.2.4 ЪЪгУГЁОА
ЖдЕЭбгГйвЊЧѓНЯИпЕФЪ§ОнгІгУЯюФПЛђБЈБэ
ашвЊЕЭбгГйЕїгУЭтВПЗўЮёЃЈШчСїЩЯЕїгУЭтВПЙцдђв§ЧцЁЂдкЯпЫуЗЈФЃаЭЪЙгУЕШЃЉ
жЇГжЪ§ВжЪЕЪБЪТЪЕБэ+ЮЌЖШБэЕФПэБэНЈЩш
ЪЕЪБЖрБэШкКЯЁЂЗжВ№ЁЂЧхЯДЁЂБъзМЛЏMappingГЁОА
ЕШЕШ
2.3 ТжзЊФЃЪН
2.3.1 ФЃЪНУшЪі
ТжзЊФЃЪНЃЌЪЧжИдкСїЫуФЃЪНЕФЛљДЁЩЯЃЌдкЪ§ОнЪЕЪБТфПтжаЃЌЭЌЪБХмЖЬЪБЖЈЪБШЮЮёдкПтЩЯНјвЛВНМЦЫуКѓЃЌНЋНсЙћдйДЮЭЖЗХдкKafkaЩЯХмЯТвЛТжСїЩЯМЦЫуЃЌетбљСїЫузЊХњЫуЁЂХњЫузЊСїЫуЕФЪЙгУФЃЪНЁЃ
дкRTDPМмЙЙжаЃЌПЩвдРћгУKafka->Wormhole->Sink->Moonbox->KafkaЕФећКЯЗНЪНЪЕЯжШЮКЮТжДЮШЮКЮЦЕДЮЕФТжзЊМЦЫуЁЃдкСїЫуФЃЪНЕФФмСІжЎЩЯЃЌТжзЊФЃЪНЬсЙЉЕФжївЊФмСІЪЧЃКРэТлЩЯжЇГжЕЭбгГйЕФШЮКЮИДдгСїзЊМЦЫуТпМЁЃ
2.3.2 ММЪѕФбЕу
ОпЬхЪЕЪЉФбЁЃ
MoonboxзЊWormholeФмСІЕФв§ШыЃЌБШСїЫуФЃЪННјвЛВНдіМгСЫПМТЧЕФБфСПвђЫиЃЌШчЖрSinkЕФбЁдёЁЂMoonboxМЦЫуЕФЦЕТЪЩшЖЈЁЂШчКЮВ№ЗжWormholeКЭMoonboxЕФМЦЫуЗжЙЄЕШЗНУцЮЪЬтЁЃ
2.3.3 дЫЮЌЙмРэ
дЫЮЌЙмРэФбЁЃ
ашвЊШЫЙЄдЫЮЌЁЃКЭСїЫуФЃЪНБШЃЌашвЊИќЖрЪ§ОнЯЕЭГвђЫиЕФПМТЧЁЂИќЖрВЮЪ§ЕФХфжУЕїгХЁЂИќФбЕФЪ§ОнжЪСПЙмРэКЭеяЖЯМрПиЁЃ
2.3.4 ЪЪгУГЁОА
ЕЭбгГйЕФЖрВНжшЕФИДдгЪ§ОнДІРэТпМГЁОА
ЙЋЫОМЖЪЕЪБЪ§ОнСїзЊДІРэЭјТчНЈЩш
2.4 жЧФмФЃЪН
2.4.1 ФЃЪНУшЪі
жЧФмФЃЪНЃЌЪЧжИРћгУЙцдђЛђЫуЗЈФЃаЭРДНјаагХЛЏКЭдіаЇЕФЪЙгУФЃЪНЁЃ
ПЩвджЧФмЛЏЕФЕуЃК
Wormhole FlowЕФжЧФмЦЏвЦЃЈжЧФмЛЏздЖЏЛЏдЫЮЌЃЉ
MoonboxдЄМЦЫуЕФжЧФмгХЛЏЃЈжЧФмЛЏздЖЏЛЏЕїгХЃЉ
ШЋСПМЦЫуТпМжЧФмзЊЛЛГЩСїЪНМЦЫуТпМЃЌШЛКѓВПЪ№дкWormhole + MoonboxЃЈжЧФмЛЏздЖЏЛЏПЊЗЂВПЪ№ЃЉ
ЕШЕШ
2.4.2 ММЪѕФбЕу
ОпЬхЪЕЪЉдкРэТлЩЯзюМђЕЅЃЌЕЋгааЇЕФММЪѕЪЕЯжзюФбЁЃ
гУЛЇжЛашвЊЭъГЩРыЯпТпМПЊЗЂЃЌЪЃЯТНЛгЩжЧФмЛЏЙЄОпЭъГЩПЊЗЂЁЂВПЪ№ЁЂЕїгХЁЂдЫЮЌЁЃ
2.4.3 дЫЮЌЙмРэ
СудЫЮЌЁЃ
|






