| БрМЭЦМі: |
БОЮФРДздгкcsdnЃЌЮФеТНВНтRDDЕФЬиЕуЃЌRDDВйзїКЏЪ§ЯрЙиЃЌДЉВхАИР§РБНДЕУЖЮзгЃЌДјДѓМвРэНтMapReduceЃЌЭЈЙ§ЙўФЗРзЬиЕЅДЪЗжЮіАИР§НјааЩюЖШЦЪЮіЁЃ
|
|
RDDЃЈResilient Distributed DatasetsЕЏадЗжВМЪНЪ§ОнМЏЃЉЃЌЪЧsparkжазюживЊЕФИХФюЃЌПЩвдМђЕЅЕФАбRDDРэНтГЩвЛИіЬсЙЉСЫаэЖрВйзїНгПкЕФЪ§ОнМЏКЯЃЌКЭвЛАуЪ§ОнМЏВЛЭЌЕФЪЧЃЌЦфЪЕМЪЪ§ОнЗжВМДцДЂгквЛХњЛњЦїжаЃЈФкДцЛђДХХЬжаЃЉЃЌRDDЛьКЯСЫИїжжМЦЫуФЃаЭЃЌЪЙЕУSparkПЩвдгІгУгкИїжжДѓЪ§ОнДІРэГЁОАЕБШЛЃЌRDDПЯЖЈВЛЛсетУДМђЕЅЃЌЫќЕФЙІФмЛЙАќРЈШнДэЁЂМЏКЯФкЕФЪ§ОнПЩвдВЂааДІРэЕШЁЃRDDПЩвдcacheЕНФкДцжаЃЌУПДЮЖдRDDЪ§ОнМЏЕФВйзїжЎКѓЕФНсЙћЃЌЖМПЩвдДцЗХЕНФкДцжаЃЌЯТвЛИіВйзїПЩвджБНгДгФкДцжаЪфШыЃЌЪЁШЅСЫMapReduceДѓСПЕФДХХЬIOВйзїЁЃ
RDDЕФЬиЕу
ДДНЈЃКжЛФмЭЈЙ§зЊЛЛ ( transformation ЃЌШчmap/filter/groupBy/join
ЕШЃЌЧјБ№гкЖЏзї action) ДгСНжжЪ§ОндДжаДДНЈ RDD
жЛЖСЃКзДЬЌВЛПЩБфЃЌВЛФмаоИФЁЃ
ЗжЧјЃКжЇГжЪЙ RDD жаЕФдЊЫиИљОнФЧИі key РДЗжЧј ( partitioning ) ЃЌБЃДцЕНЖрИіНсЕуЩЯЁЃЛЙдЪБжЛЛсжиаТМЦЫуЖЊЪЇЗжЧјЕФЪ§ОнЃЌЖјВЛЛсгАЯьећИіЯЕЭГЁЃ
ТЗОЖЃКМД RDD гаГфзуЕФаХЯЂЙигкЫќЪЧШчКЮДгЦфЫћ RDD ВњЩњЖјРДЕФЁЃ
ГжОУЛЏЃКжЇГжНЋЛсБЛжигУЕФ RDD ЛКДц ( Шч in-memory ЛђвчГіЕНДХХЬ )ЁЃ
бгГйМЦЫуЃК Spark вВЛсбгГйМЦЫу RDD ЃЌЪЙЦфФмЙЛНЋзЊЛЛЙмЕРЛЏ (pipeline transformation)ЁЃ
ВйзїЃКЗсИЛЕФзЊЛЛЃЈtransformationЃЉКЭЖЏзї ( action ) ЃЌ count/reduce/collect/save
ЕШЁЃжДааСЫЖрЩйДЮtransformationВйзїЃЌRDDЖМВЛЛсеце§жДаадЫЫуЃЈМЧТМlineageЃЉЃЌжЛгаЕБactionВйзїБЛжДааЪБЃЌдЫЫуВХЛсДЅЗЂЁЃ
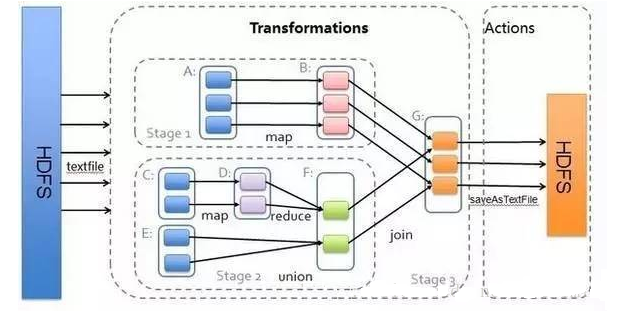
RDD ЗжЮЊЖўРрЃКtransformation КЭ actionЁЃ
transformation ЪЧДгвЛИі RDD зЊЛЛЮЊвЛИіаТЕФ RDD ЛђепДгЪ§ОндДЩњГЩвЛИіаТЕФ RDDЃЛ
action ЪЧДЅЗЂ job ЕФжДааЃЌжЛгадк action БЛЬсНЛЕФЪБКђВХДЅЗЂЧАУцећИіRDDЕФжДааЭМ
RDDдЫааТпМ
2.1вЛИіЖЮзгРэНтMapReduce?

РюЖњЮвгаШ§МўБІБДЃЌГжгаЖјефжиЫќЁЃЕквЛМўНаДШАЎЃЌЕкЖўМўНаНкМѓЃЌЕкШ§МўНаВЛИвДІдкжкШЫжЎЯШ
НКўДЋЫЕгРСїДЋЃКЙШИшММЪѕга"Ш§БІ"ЃЌGFSЁЂMapReduceКЭДѓБэЃЈBigTableЃЉЃЁ
РБНДЖЮзг
зђЬьЃЌЮвдкXebiaгЁЖШАьЙЋЪвЗЂБэСЫвЛИіЙигкMapReduceЕФбнЫЕЁЃбнЫЕНјааЕУКмЫГРћЃЌЬ§жкУЧЖМФмЙЛРэНтMapReduceЕФИХФюЃЈИљОнЫћУЧЕФЗДРЁЃЉЁЃЮвГЩЙІЕиЯђММЪѕЬ§жкУЧЃЈНтЪЭСЫMapReduceЕФИХФюЃЌетШУЮвИаЕНаЫЗмЁЃдкЫљгааСЧкЕФЙЄзїжЎКѓЃЌЮвУЧдкXebiaгЁЖШАьЙЋЪвЯэгУСЫЗсЪЂЕФЭэВЭЃЌШЛКѓЮвОЖжБЛиСЫМвЁЃ
ЁЁЛиМвКѓЃЌЮвЕФЦозгЃЈSupriyaЃЉЮЪЕРЃКЁАФуЕФЛсПЊЕУдѕУДбљЃПЁБЮвЫЕЛЙВЛДэЁЃ НгзХЫ§гжЮЪЮвЛсвщЪЧЕФФкШнЪЧЪВУД(Ы§ВЛЪЧДгЪТШэМўЛђБрГЬСьгђЕФЙЄзїЕФ)ЁЃЮвИцЫпЫ§ЫЕMapReduceЁЃЁАMapduceЃЌФЧЪЧЪВУДЭцвтЖљЃПЁБЫ§ЮЪЕРЃК
ЁАИњЕиаЮЭМгаЙиТ№ЃПЁБЮвЫЕВЛЃЌВЛЪЧЕФЃЌЫќКЭЕиаЮЭМвЛЕуЙиЯЕвВУЛгаЁЃЁАФЧУДЃЌЫќЕНЕзЪЧЪВУДЭцвтЖљЃПЁБЦозгЮЪЕРЁЃ
ЁАпэЁШУЮвУЧШЅDominos(ХћШјСЌЫј)АЩЃЌЮвЛсдкВЭзРЩЯИњФуКУКУНтЪЭЁЃЁБ ЦозгЫЕЃКЁАКУЕФЁЃЁБ ШЛКѓЮвУЧОЭШЅСЫХћШјЕъЁЃ
ЮвУЧдкDomionsЕуВЭжЎКѓЃЌЙёЬЈЕФаЁЛязгИцЫпЮвУЧЫЕХћШјашвЊ15ЗжжгВХФмзМБИКУЁЃгкЪЧЃЌЮвЮЪЦозгЃКЁАФуецЕФЯывЊХЊЖЎЪВУДЪЧMapReduceЃПЁБ
Ы§КмМсЖЈЕФЛиД№ЫЕЁАЪЧЕФЁБЁЃ вђДЫЮвЮЪЕРЃК
ЁЁЁЁЮвЃК ФуЪЧШчКЮзМБИбѓДаРБНЗНДЕФЃПЃЈвдЯТВЂЗЧзМШЗЪГЦзЃЌЧыЮ№дкМвГЂЪдЃЉ
ЁЁЁЁЦозгЃК ЮвЛсШЁвЛИібѓДаЃЌАбЫќЧаЫщЃЌШЛКѓАшШыбЮКЭЫЎЃЌзюКѓЗХНјЛьКЯбаФЅЛњРябаФЅЁЃетбљОЭФмЕУЕНбѓДаРБНЗНДСЫЁЃ
ЁЁЁЁЦозгЃК ЕЋетКЭMapReduceгаЪВУДЙиЯЕЃП
ЁЁЁЁЮвЃК ФуЕШвЛЯТЁЃШУЮвРДБрвЛИіЭъећЕФЧщНкЃЌетбљФуПЯЖЈПЩвддк15ЗжжгФкХЊЖЎMapReduce.
ЁЁЁЁЦозгЃК КУАЩЁЃ
ЁЁЁЁЮвЃКЯждкЃЌМйЩшФуЯыгУБЁКЩЁЂбѓДаЁЂЗЌЧбЁЂРБНЗЁЂДѓЫтХЊвЛЦПЛьКЯРБНЗНДЁЃФуЛсдѕУДзіФиЃП
ЁЁЁЁЦозгЃК ЮвЛсШЁБЁКЩвЖвЛДщЃЌбѓДавЛИіЃЌЗЌЧбвЛИіЃЌРБНЗвЛИљЃЌДѓЫтвЛИљЃЌЧаЫщКѓМгШыЪЪСПЕФбЮКЭЫЎЃЌдйЗХШыЛьКЯбаФЅЛњРябаФЅЃЌетбљФуОЭПЩвдЕУЕНвЛЦПЛьКЯРБНЗНДСЫЁЃ
ЁЁЁЁЮвЃК УЛДэЃЌШУЮвУЧАбMapReduceЕФИХФюгІгУЕНЪГЦзЩЯЁЃMapКЭReduceЦфЪЕЪЧСНжжВйзїЃЌЮвРДИјФуЯъЯИНВНтЯТЁЃMapЃЈгГЩфЃЉ:
АббѓДаЁЂЗЌЧбЁЂРБНЗКЭДѓЫтЧаЫщЃЌЪЧИїздзїгУдкетаЉЮяЬхЩЯЕФвЛИіMapВйзїЁЃЫљвдФуИјMapвЛИібѓДаЃЌMapОЭЛсАббѓДаЧаЫщЁЃ
ЭЌбљЕФЃЌФуАбРБНЗЃЌДѓЫтКЭЗЌЧбвЛвЛЕиФУИјMapЃЌФувВЛсЕУЕНИїжжЫщПщЁЃ ЫљвдЃЌЕБФудкЧаЯёбѓДаетбљЕФЪпВЫЪБЃЌФужДааОЭЪЧвЛИіMapВйзїЁЃ
MapВйзїЪЪгУгкУПвЛжжЪпВЫЃЌЫќЛсЯргІЕиЩњВњГівЛжжЛђЖржжЫщПщЃЌдкЮвУЧЕФР§згжаЩњВњЕФЪЧЪпВЫПщЁЃдкMapВйзїжаПЩФмЛсГіЯжгаИібѓДаЛЕЕєСЫЕФЧщПіЃЌФужЛвЊАбЛЕбѓДаЖЊСЫОЭааСЫЁЃЫљвдЃЌШчЙћГіЯжЛЕбѓДаСЫЃЌMapВйзїОЭЛсЙ§ТЫЕєЛЕбѓДаЖјВЛЛсЩњВњГіШЮКЮЕФЛЕбѓДаПщЁЃ
ЁЁЁЁReduceЃЈЛЏМђЃЉ:дкетвЛНзЖЮЃЌФуНЋИїжжЪпВЫЫщЖМЗХШыбаФЅЛњРяНјаабаФЅЃЌФуОЭПЩвдЕУЕНвЛЦПРБНЗНДСЫЁЃетвтЮЖвЊжЦГЩвЛЦПРБНЗНДЃЌФуЕУбаФЅЫљгаЕФдСЯЁЃвђДЫЃЌбаФЅЛњЭЈГЃНЋmapВйзїЕФЪпВЫЫщОлМЏдкСЫвЛЦ№ЁЃ
ЁЁЁЁЦозгЃК ЫљвдЃЌетОЭЪЧMapReduce?
ЁЁЁЁЮвЃК ФуПЩвдЫЕЪЧЃЌвВПЩвдЫЕВЛЪЧЁЃ ЦфЪЕетжЛЪЧMapReduceЕФвЛВПЗжЃЌMapReduceЕФЧПДѓдкгкЗжВМЪНМЦЫуЁЃ
ЁЁЁЁЦозгЃК ЗжВМЪНМЦЫуЃП ФЧЪЧЪВУДЃПЧыИјЮвНтЪЭЯТАЩЁЃ
ЁЁЁЁЮвЃК УЛЮЪЬтЁЃ
ЁЁЁЁЮвЃК МйЩшФуВЮМгСЫвЛИіРБНЗНДБШШќВЂЧвФуЕФЪГЦзгЎЕУСЫзюМбРБНЗНДНБЁЃЕУНБжЎКѓЃЌРБНЗНДЪГЦзДѓЪмЛЖгЃЌгкЪЧФуЯывЊПЊЪМГіЪлзджЦЦЗХЦЕФРБНЗНДЁЃМйЩшФуУПЬьашвЊЩњВњ10000ЦПРБНЗНДЃЌФуЛсдѕУДАьФиЃП
ЁЁЁЁЦозгЃК ЮвЛсеввЛИіФмЮЊЮвДѓСПЬсЙЉдСЯЕФЙЉгІЩЬЁЃ
ЁЁЁЁЮвЃКЪЧЕФ..ОЭЪЧФЧбљЕФЁЃФЧФуФмЗёЖРздЭъГЩжЦзїФиЃПвВОЭЪЧЫЕЃЌЖРздНЋдСЯЖМЧаЫщЃП НіНівЛВПбаФЅЛњгжЪЧЗёФмТњзуашвЊЃПЖјЧвЯждкЃЌЮвУЧЛЙашвЊЙЉгІВЛЭЌжжРрЕФРБНЗНДЃЌЯёбѓДаРБНЗНДЁЂЧрНЗРБНЗНДЁЂЗЌЧбРБНЗНДЕШЕШЁЃ
ЁЁЁЁЦозгЃК ЕБШЛВЛФмСЫЃЌЮвЛсЙЭгЖИќЖрЕФЙЄШЫРДЧаЪпВЫЁЃЮвЛЙашвЊИќЖрЕФбаФЅЛњЃЌетбљЮвОЭПЩвдИќПьЕиЩњВњРБНЗНДСЫЁЃ
ЁЁЁЁЮвЃКУЛДэЃЌЫљвдЯждкФуОЭВЛЕУВЛЗжХфЙЄзїСЫЃЌФуНЋашвЊМИИіШЫвЛЦ№ЧаЪпВЫЁЃУПИіШЫЖМвЊДІРэТњТњвЛДќЕФЪпВЫЃЌЖјУПвЛИіШЫЖМЯрЕБгкдкжДаавЛИіМђЕЅЕФMapВйзїЁЃУПвЛИіШЫЖМНЋВЛЖЯЕФДгДќзгРяФУГіЪпВЫРДЃЌВЂЧвУПДЮжЛЖдвЛжжЪпВЫНјааДІРэЃЌвВОЭЪЧНЋЫќУЧЧаЫщЃЌжБЕНДќзгПеСЫЮЊжЙЁЃ
ЁЁЁЁетбљЃЌЕБЫљгаЕФЙЄШЫЖМЧаЭъвдКѓЃЌЙЄзїЬЈЃЈУПИіШЫЙЄзїЕФЕиЗНЃЉЩЯОЭгаСЫбѓДаПщЁЂЗЌЧбПщЁЂКЭЫтШиЕШЕШЁЃ ЁЁЁЁЦозгЃКЕЋЪЧЮвдѕУДЛсжЦдьГіВЛЭЌжжРрЕФЗЌЧбНДФиЃП
ЁЁЁЁЮвЃКЯждкФуЛсПДЕНMapReduceвХТЉЕФНзЖЮЁЊНСАшНзЖЮЁЃMapReduceНЋЫљгаЪфГіЕФЪпВЫЫщЖМНСАшдкСЫвЛЦ№ЃЌетаЉЪпВЫЫщЖМЪЧдквдkeyЮЊЛљДЁЕФmapВйзїЯТВњЩњЕФЁЃНСАшНЋздЖЏЭъГЩЃЌФуПЩвдМйЩшkeyЪЧвЛжждСЯЕФУћзжЃЌОЭЯёбѓДавЛбљЁЃ
ЫљвдШЋВПЕФбѓДаkeysЖМЛсНСАшдквЛЦ№ЃЌВЂзЊвЦЕНбаФЅбѓДаЕФбаФЅЦїРяЁЃетбљЃЌФуОЭФмЕУЕНбѓДаРБНЗНДСЫЁЃЭЌбљЕиЃЌЫљгаЕФЗЌЧбвВЛсБЛзЊвЦЕНБъМЧзХЗЌЧбЕФбаФЅЦїРяЃЌВЂжЦдьГіЗЌЧбРБНЗНДЁЃ
ЁЁЁЁХћШјжегкзіКУСЫЃЌЫ§ЕуЕуЭЗЫЕЫ§вбОХЊЖЎЪВУДЪЧMapReduceСЫЁЃЮвжЛЯЃЭћЯТДЮЫ§Ь§ЕНMapReduceЪБЃЌФмИќКУЕФРэНтЮвЕНЕздкзіаЉЪВУДЁЃ
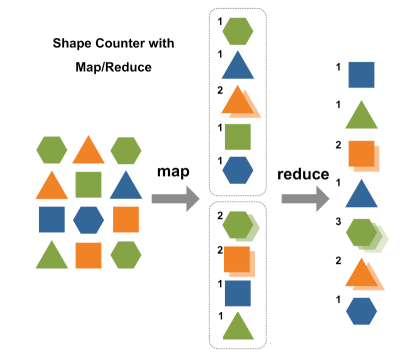
ЭјЩЯЦфЫћШЫгУзюМђЖЬЕФгябдНтЪЭMapReduceЃК
We want to count all the books in the library. You
count up shelf #1, I count up shelf #2. ThatЁЏs map.
The more people we get, the faster it goes.
ЁЁЁЁЮвУЧвЊЪ§ЭМЪщЙнжаЕФЫљгаЪщЁЃФуЪ§1КХЪщМмЃЌЮвЪ§2КХЪщМмЁЃетОЭЪЧЁАMapЁБЁЃЮвУЧШЫдНЖрЃЌЪ§ЪщОЭИќПьЁЃ
ЁЁЁЁNow we get together and add our individual counts.
ThatЁЏs reduce.
ЁЁЁЁЯждкЮвУЧЕНвЛЦ№ЃЌАбЫљгаШЫЕФЭГМЦЪ§МгдквЛЦ№ЁЃетОЭЪЧЁАReduceЁБ
2.2RDDВйзїКЏЪ§
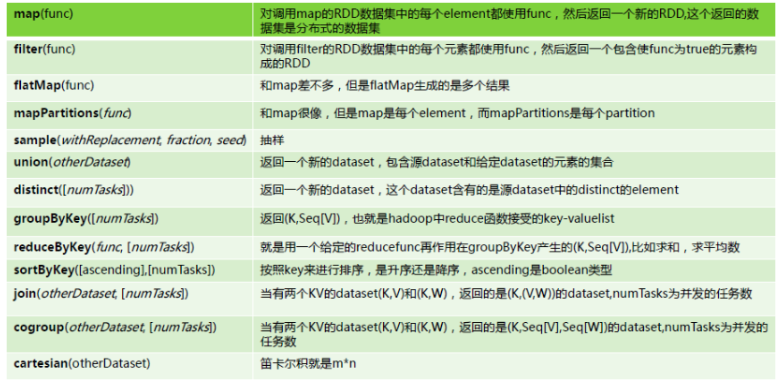
transformation
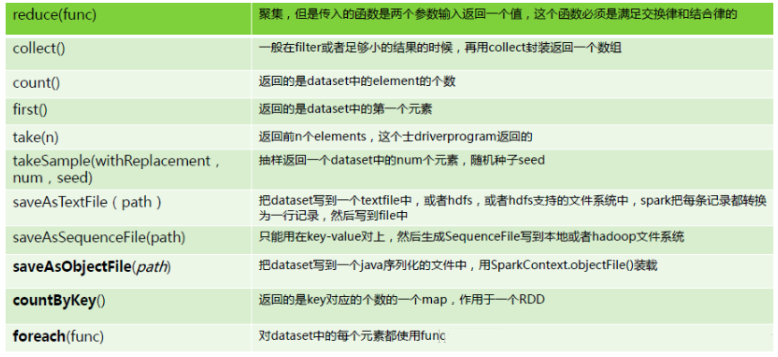
action
КЏЪ§ОпЬхЙІФмНщЩм
<1>НЋвЛИіRDDжаЕФУПИіЪ§ОнЯюЃЌЭЈЙ§mapжаЕФКЏЪ§гГЩфБфЮЊвЛИіаТЕФдЊЫи,
ЪфШыЗжЧјгыЪфГіЗжЧјвЛЖдвЛЃЌМДЃКгаЖрЩйИіЪфШыЗжЧјЃЌОЭгаЖрЩйИіЪфГіЗжЧј.
data = sc.textFile("/tmp/hive/tmp/1.txt")
data: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[1]
at textFile at :21
//ЪЙгУmapЫузг
mapresult = data.map()
mapresult: org.apache.spark.rdd.RDD[Array[String]]
= MapPartitionsRDD[2] at map at :23
|
<2>flatMap,ЪєгкTransformationЫузгЃЌЕквЛВНКЭmapвЛбљЃЌзюКѓНЋЫљгаЕФЪфГіЗжЧјКЯВЂГЩвЛИі
<3>countЗЕЛиRDDжаЕФдЊЫиЪ§СП
<4>reduce,ИљОнгГЩфКЏЪ§ЖдRDDРяЕФдЊЫиНјааЖўдЊМЦЫуНсЙћЃЌЗЕЛиМЦЫуНсЙћ
| rdd.reduce(lambda
x,y:x.a+y.a,x.b+y.b) |
<5>collectгУгкНЋвЛИіRDDзЊЛЛГЩЪ§зщ
<6>countByKey(),countByKeyгУгкЭГМЦRDD[K,V]жаУПИіKЕФЪ§СП
<7>foreach(),foreachгУгкБщРњRDD,НЋКЏЪ§fгІгУгкУПвЛИідЊЫи?<8>saveAsTextFileгУгкНЋRDDвдЮФБОЮФМўЕФИёЪНДцДЂЕНЮФМўЯЕЭГжа
| rdd.saveAsTextFile("/tmp/hive/itcast/python-bigdata.txt") |
2.3ЙўФЗРзЬиЕЅДЪЗжЮіАИР§
hdfsЮФМўВйзї
<1>НЋБОЕиЕФHamlet.txtЩЯДЋЕНhdfsЩЯ
| hadoop fs -put
Hamlet.txt /tmp/hive/itcast/ |
ЦфЫћВйзї
ЛёШЁhdfsЮФМўЕНБОЕи
| hadoop fs -get
/tmp/hive/itcast/python.txt ./ |
СаГіhdfsЮФМўЯЕЭГИљФПТМЯТЕФФПТМКЭЮФМў
rmВйзї
hadoop fs -rm
< hdfs file > ...
hadoop fs -rm -r < hdfs dir>...
УПДЮПЩвдЩОГ§ЖрИіЮФМўЛђФПТМ |
sparkдЫаадРэГЬађЗжЮі
SparkгІгУзїЮЊЖРСЂЕФНјГЬдЫааЃЌгЩЧ§ЖЏГЬађжаЕФSparkContextаЕїЁЃетИіcontextНЋЛсСЌНгЕНвЛаЉМЏШКЙмРэепЃЈШчYARNЃЉЃЌетаЉЙмРэепЗжХфЯЕЭГзЪдДЁЃМЏШКЩЯЕФУПИіworkerгЩжДааепЃЈexecutorЃЉЙмРэЃЌжДааепЗДЙ§РДгЩSparkContextЙмРэЁЃжДааепЙмРэМЦЫуЁЂДцДЂЃЌЛЙгаУПЬЈЛњЦїЩЯЕФЛКДцЁЃ
sc
ПЊЦєsparkКѓЃЌSparkContextМђТдаДЗЈsc,ЖдгкscПЩвдНјааЮФМўЕФЖСШЁвдМАНкЕужЎМфЕФаЕї
<1>ЖСШЁЮФМўВЂзЊЛЛГЩвЛИіRDDЪ§ОнМЏ
| sc.textFile("itcast-python.txt") |
<2>НЋЪ§ОнДгвЛИіНкЕуЗЂЫЭЕНЦфЫќНкЕуЩЯ
#ЖСШЁRDDРраЭЕФЪ§ОнМЏЃЌВЂЧвЗЕЛивЛИіbroadcastРраЭЕФЪ§Он
#ЖСШЁRDDРраЭЕФЪ§ОнМЏЃЌВЂЧвЗЕЛивЛИіbroadcastРраЭЕФЪ§Он
bdata = sc.broadcast(data) |
from operator
import add
text = sc.textFile("/tmp/hive/itcast/Hamlet.txt")
def tokenize(text):
return text.split()
words = text.flatMap(tokenize)
wc = words.map(lambda x: (x,1))
counts = wc.reduceByKey(add)
counts.saveAsTextFile("/tmp/hive/itcast/hm")
|
|






