| БрМЭЦМі: |
| БОЮФРДздsohu
ЃЌЮФеТжївЊНщЩмСЫЪ§ОнЗжЮіБиаывЊеЦЮеЕФММФмЃКЪ§ОнНЈФЃЕФЯъЯИВНжшЃЌЯЃЭћФмЖдФњгаЫљАяжњЁЃ |
|
ЧАвЛеѓзгЃЌФГЭјТчЙЋЫОЗЂЦ№СЫвЛИіЪВУДНЈФЃДѓШќЃЌгаШЫЮЪЃЌЪ§ОнНЈФЃдѕУДИуЃП
ЮЊСЫТњзуЫћЕФКУбЇОЋЩёЃЌЮвОіЖЈаДетвЛЦЊЮФеТЃЌРДУшЪівЛЯТЪ§ОнЗжЮіБиаывЊеЦЮеЕФММФмЃКЪ§ОнНЈФЃЁЃ
БОЮФНЋГЂЪдРДЪсРэвЛЯТЪ§ОнНЈФЃЕФВНжшЃЌвдМАУПвЛВНашвЊзіЕФЙЄзїЁЃ
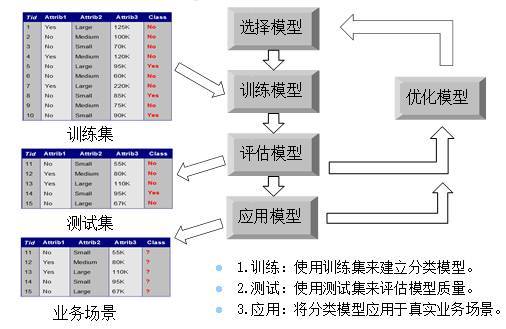
ЕквЛВНЃКбЁдёФЃаЭЛђздЖЈвхФЃЪН
етЪЧНЈФЃЕФЕквЛВНЃЌЮвУЧашвЊЛљгквЕЮёЮЪЬтЃЌРДОіЖЈПЩвдбЁдёФФаЉПЩгУЕФФЃаЭЁЃ
БШШчЃЌШчЙћвЊдЄВтВњЦЗЯњСПЃЌдђПЩвдбЁдёЪ§жЕдЄВтФЃаЭЃЈБШШчЛиЙщФЃаЭЃЌЪБађдЄВтЁЁЃЉЃЛШчЙћвЊдЄВтдБЙЄЪЧЗёРыжАЃЌдђПЩвдбЁдёЗжРрФЃаЭЃЈБШШчОіВпЪїЁЂЩёОЭјТчЁЁЃЉЁЃ
ШчЙћУЛгаЯжГЩЕФФЃаЭПЩгУЃЌФЧУДЙЇЯВФуЃЌФуПЩвдздЖЈвхФЃаЭСЫЁЃВЛЙ§ЃЌвЛАуЧщПіЯТЃЌздМКЖЈвхФЃаЭВЛЪЧФЧУДШнвзЕФЪТЧщЃЌУЛгаЩюКёЕФЪ§бЇЛљДЁКЭбаОПОЋЩёЃЌздМКЫМПМГівЛИіНтОіЬиЖЈЮЪЬтЕФЪ§бЇФЃаЭЛљБОЩЯЪЧЛУЯыЁЃЫљвдЃЌздЖЈвхФЃаЭЕФЪТЧщЛЙЪЧСєИјбЇаЃЕФНЬЪкУЧШЅбаОПКЭПЊЗЂАЩЁЃЕБЧАОјДѓЖрЪ§ШЫЫљЮНЕФНЈФЃЃЌЖМжЛЪЧбЁдёвЛИівбгаЕФЪ§бЇФЃаЭРДЙЄзїЖјвбЁЃ
вЛАуЧщПіЃЌФЃаЭЖМгавЛИіЙЬЖЈЕФФЃбљКЭаЮЪНЁЃЕЋЪЧЃЌгааЉФЃаЭАќКЌЕФЗЖЮЇНЯЙуЃЌБШШчЛиЙщФЃаЭЃЌЦфЪЕВЛЪЧФГвЛИіЬиЖЈЕФФЃаЭЃЌЖјЪЧвЛРрФЃаЭЁЃЮвУЧжЊЕРЃЌЫљЮНЕФЛиЙщФЃаЭЃЌЦфЪЕОЭЪЧздБфСПКЭвђБфСПЕФвЛИіКЏЪ§ЙиЯЕЪНЖјвбЃЌШчЯТБэЫљЪОЁЃвђДЫЃЌЛиЙщФЃаЭЕФбЁдёЃЌвВОЭгаСЫЮоЯоЕФПЩФмадЃЌЛиЙщФЃаЭЕФбљзгЃЈЛђНаЗНГЬЃЉПЩвдЪЧФуФмЙЛЯыЕНЕФШЮКЮаЮЪНЕФЛиЙщЗНГЬЁЃЫљвдЃЌДгФГжжвтвхЩЯПДЃЌФуздМКЯыГівЛИіКмЩйШЫМћЙ§ЕФЛиЙщЗНГЬЃЌвВПЩвдУуЧПЫуЪЧздЖЈвхФЃаЭСЫЙўЃЁ
ФЧУДЃЌетУДЖрПЩбЁЕФФЃаЭЃЌЕНЕзбЁдёФФИіФЃаЭВХКУФиЃП
ЮвЕФД№ИДЪЧЃКЬьжЊЕРЃЁ
ЬьжЊЕРгІИУбЁдёФФИіФЃаЭЛсКУвЛаЉЃЁФуЮЪЮвЃЌЮвЮЪЫАЁЃПШчЙћдкетИіЪБКђгаШЫИцЫпФуЃЌФуЕФвЕЮёгІИУбЁдёФФИіЛиЙщЗНГЬЛсИќКУвЛаЉЃЌФЧУДЃЌЮвИвПЯЖЈЃЌФугіЩЯЕФПЯЖЈЪЧЁАзЉМвЁБЖјВЛЪЧЁАзЈМвЁБЁЃФЃаЭЕФКУЛЕЪЧВЛФмЙЛЕЅЖРРДЦРТлЕФЃЈФуЭљЯТПДОЭжЊЕРСЫЃЉЃЁОЭШчаЁКЂзгЬжТлЕФФуАжАжКУЛЙЪЧЮвАжАжКУвЛбљЃЌФуЫЕЫКУЃП
ФЧУДЃЌЪЧВЛЪЧЮвУЧдкбЁдёФЃаЭЪБОЭЕУППдЫЦјСЫЃПЦфЪЕецгаФЧУДвЛЕуППдЫЦјЕФГЩЗнЃЌВЛЙ§КУдкКѓајЪ§бЇМвУЧИјЮвУЧЬсЙЉСЫЦРЙРФЃаЭКУЛЕЕФвРОнЁЃ
ЯждкЃЌЮвУЧжЛФмППдЫЦјРДбЁдёФГвЛИіФЃаЭСЫLЁЃ
ЛиЙщФЃаЭ ЛиЙщЗНГЬ
вЛдЊЯпад y=ІТ0+ІТ1x
ЖрдЊЯпад y=ІТ0+ІТ1x1+Ё+ ІТkxk
ЖўДЮЧњЯп y=ІТ0+ІТ1x+ІТ2x2
ИДКЯЧњЯп y=ІТ0ІТx
діГЄЧњЯп y=eІТ0+ІТ1x
ЖдЪ§ЧњЯп y=ІТ0+ІТ1ln(x)
Ш§ДЮЧњЯп y=ІТ0+ІТ1x+ІТ2x2+ІТ3x3
SЧњЯп y=eІТ0+ІТ1/x
жИЪ§ЧњЯп y=ІТ0eІТ1x
ФцКЏЪ§ y=ІТ0+ІТ1/x
УнКЏЪ§ y=ІТ0xІТ1
ЕкЖўВНЃКбЕСЗФЃаЭ
ЕБФЃаЭбЁдёКУСЫвдКѓЃЌОЭЕНСЫбЕСЗФЃаЭетвЛВНЁЃ
ЮвУЧжЊЕРЃЌжЎЫљвдНаФЃаЭЃЌетИіФЃаЭДѓжТЕФаЮзДЛђФЃЪНЪЧЙЬЖЈЕФЃЌЕЋФЃаЭжаЛЙЛсгавЛаЉВЛШЗЖЈЕФЖЋЖЋдкРяУцЃЌетбљФЃаЭВХЛсгаЭЈгУадЃЌШчЙћФЃаЭжаЫљгаЕФЖЋЮїЖМЙЬЖЈЫРСЫЃЌФЃаЭЕФЭЈгУадОЭУЛгаСЫЁЃФЃаЭжаПЩвдЪЪЕББфЛЏЕФВПЗжЃЌвЛАуНазіВЮЪ§ЃЌОЭБШШчЧАУцЛиЙщФЃаЭжаЕФІСЁЂІТЕШВЮЪ§ЁЃ
ЫљЮНбЕСЗФЃаЭЃЌЦфЪЕОЭЪЧвЊЛљгкецЪЕЕФвЕЮёЪ§ОнРДШЗЖЈзюКЯЪЪЕФФЃаЭВЮЪ§ЖјвбЁЃФЃаЭбЕСЗКУСЫЃЌвВОЭЪЧвтЮЖзХевЕНСЫзюКЯЪЪЕФВЮЪ§ЁЃвЛЕЉевЕНзюгХВЮЪ§ЃЌФЃаЭОЭЛљБОПЩгУСЫЁЃ
ЕБШЛЃЌвЊевЕНзюгХЕФФЃаЭВЮЪ§вЛАуЪЧБШНЯРЇФбЕФЃЌдѕбљевЃПШчКЮевЃПетОЭЩцМАЕНЫуЗЈСЫЁЃХЖЃЌвЛЯыЕНЫуЗЈЃЌЮвЕФЭЗОЭПЊЪМЭДСЫЃЌЖМЙжЕБФъЪ§бЇУЛгабЇКУбНЃЁ
ЕБШЛЃЌзюБПЕФАьЗЈЃЌЮвУЧПЩвдВЛЖЯЕФГЂЪдВЮЪ§ЃЌРДевЕНвЛИізюКУЕФВЮЪ§жЕЁЃвЛИівЛИіЪдЃПетВЛЪЧвЊЪдЕНЩњУќНсЪјЃППЊЭцаІРВЃЌВЛПЩФмШЅвЛИівЛИіЪдЕФРВЁЃЗДе§гаЙЄОпЛсАяФуевЕНзюгХВЮЪ§ЕФЃЌЪВУДзюгХЛЏЫуЗЈжаЕФЪВУДЬнЖШЩЯЩ§бНЬнЖШЯТНЕбНЃЌФуОЭВЛгУВйаФСЫбНЃЌетаЉСєИјЗжЮіЙЄОпРДЪЕЯжОЭПЩвдСЫЃЁ
ЕБШЛЃЌвЛИіКУЕФЫуЗЈвЊдЫааЫйЖШПьЧвИДдгЖШЕЭЃЌетбљВХФмЙЛЪЕЯжПьЫйЕФЪеСВЃЌЖјЧвФмЙЛевЕНШЋОжзюгХЕФВЮЪ§ЃЌЗёдђбЕСЗЫљЛЈЕФЪБМфЙ§ГЄаЇТЪЕЭЃЌЛЙжЛевЕНОжВПзюгХВЮЪ§ЃЌОЭШУШЫФбвдШЬЪмСЫЁЃ
ЕкШ§ВНЃКЦРЙРФЃаЭ
ФЃаЭбЕСЗКУвдКѓЃЌНгЯТРДОЭЪЧЦРЙРФЃаЭЁЃ
ЫљЮНЦРЙРФЃаЭЃЌОЭЪЧОіЖЈвЛЯТФЃаЭЕФжЪСПЃЌХаЖЯФЃаЭЪЧЗёгагУЁЃ
ЧАУцЫЕЙ§ЃЌФЃаЭЕФКУЛЕЪЧВЛФмЙЛЕЅЖРЦРЙРЕФЃЌвЛИіФЃаЭЕФКУЛЕЪЧашвЊЗХдкЬиЖЈЕФвЕЮёГЁОАЯТРДЦРЙРЕФЃЌвВОЭЪЧЛљгкЬиЖЈЕФЪ§ОнМЏЯТВХФмжЊЕРФФИіФЃаЭКУгыЛЕЁЃ
МШШЛвЊЦРЙРвЛИіФЃаЭЕФКУЛЕЃЌОЭгІИУгавЛаЉЦРМлжИБъЁЃБШШчЃЌЪ§жЕдЄВтФЃаЭжаЃЌЦРМлФЃаЭжЪСПЕФГЃгУжИБъгаЃКЦНОљЮѓВюТЪЁЂХаЖЈЯЕЪ§R2ЃЌЕШЕШЃЛЦРЙРЗжРрдЄВтФЃаЭжЪСПЕФГЃгУжИБъЃЈШчЯТЭМЫљЪОЃЉгаЃКе§ШЗТЪЁЂВщШЋТЪЁЂВщзМТЪЁЂROCЧњЯпКЭAUCжЕЕШЕШЁЃ
ЖдгкЗжРрдЄВтФЃаЭЃЌвЛАувЊЧѓе§ШЗТЪКЭВщШЋТЪЕШдНДѓдНКУЃЌзюКУЖМНгНќ100%ЃЌБэЪОФЃаЭжЪСПКУЃЌЮоЮѓХаЁЃ

дкецЪЕЕФвЕЮёГЁОАжаЃЌЦРЙРжИБъЪЧЛљгкВтЪдМЏЕФЃЌЖјВЛЪЧбЕСЗМЏЁЃЫљвдЃЌдкНЈФЃЪБЃЌвЛАувЊНЋдЪМЪ§ОнМЏЗжГЩСНВПЗжЃЌвЛВПЗжгУгкбЕСЗФЃаЭЃЌНабЕСЗМЏЃЛСэвЛВПЗжгУгкЦРЙРФЃаЭЃЌНаВтЪдМЏЛђбщжЄМЏЁЃ
гаЕФШЫПЩФмЛсЯыЃЌЮЊЪВУДЦРЙРФЃаЭвЊгУСНИіВЛЭЌЕФЪ§ОнМЏЃЌжБНггУвЛИібЕСЗМЏВЛОЭПЩвдСЫЃПРэТлЩЯЪЧВЛааЕФЃЌвђЮЊФЃаЭЪЧЛљгкбЕСЗМЏЙЙНЈЦ№РДЕФЃЌЫљвддкРэТлЩЯФЃаЭдкбЕСЗМЏЩЯПЯЖЈгаНЯКУЕФаЇЙћЁЃЕЋЪЧЃЌКѓРДЪ§бЇМвУЧЗЂЯжЃЌдкбЕСЗМЏЩЯгаНЯКУдЄВтаЇЙћЕФФЃаЭЃЌдкецЪЕЕФвЕЮёгІгУГЁОАЯТЦфдЄВтаЇЙћВЛвЛЖЈКУЃЈетжжЯжЯѓГЦжЎЮЊЙ§ФтКЯЃЉЁЃЫљвдЃЌНЋбЕСЗМЏКЭВтЪдМЏЗжПЊРДЃЌвЛИігУгкбЕСЗФЃаЭЃЌвЛИігУгкЦРЙРФЃаЭЃЌетбљПЩвдЬсЧАЗЂЯжФЃаЭЪЧВЛЪЧДцдкЙ§ФтКЯЁЃ
ШчЙћЗЂЯждкбЕСЗМЏКЭВтЪдМЏЩЯЕФдЄВтаЇЙћВюВЛЖрЃЌОЭБэЪОФЃаЭжЪСПЩаКУЃЌгІИУПЩвджБНгЪЙгУСЫЁЃШчЙћЗЂЯжбЕСЗМЏКЭВтЪдМЏЩЯЕФдЄВтаЇЙћЯрВюЬЋдЖЃЌОЭЫЕУїФЃаЭЛЙгагХЛЏЕФгрЕиЁЃ
ЕБШЛЃЌШчЙћжЛЯыбщжЄвЛДЮОЭЯызМШЗЦРЙРГіФЃаЭЕФКУЛЕЃЌКУЯёЪЧВЛКЯЪЪЕФЁЃЫљвдЃЌНЈвщВЩгУНЛВцбщжЄЕФЗНЪНРДНјааЖрДЮЦРЙРЃЌвдевЕНзМШЗЕФФЃаЭЮѓВюЁЃ
ЦфЪЕЃЌФЃаЭЕФЦРЙРЪЧЗжПЊдкСНИівЕЮёГЁОАжаЕФЃК
вЛЪЧЛљгкЙ§ШЅЗЂЩњЕФвЕЮёЪ§ОнНјаабщжЄЃЌМДВтЪдМЏЁЃБОРДЃЌФЃаЭЕФЙЙНЈОЭЪЧЛљгкЙ§ШЅЕФЪ§ОнМЏЕФЙЙНЈЕФЁЃ
ЖўЪЧЛљгкецЪЕЕФвЕЮёГЁОАЪ§ОнНјаабщжЄЁЃМДЃЌдкгІгУФЃаЭВНжшжаМьбщФЃаЭЕФецЪЕгІгУНсЙћЁЃ
ЕкЫФВНЃКгІгУФЃаЭ
ШчЙћЦРЙРФЃаЭжЪСПдкПЩНгЪмЕФЗЖЮЇФкЃЌЖјЧвУЛгаГіЯжЙ§ФтКЯЃЌгкЪЧОЭПЩвдПЊЪМгІгУФЃаЭСЫЁЃ
етвЛВНЃЌОЭашвЊНЋПЩгУЕФФЃаЭПЊЗЂГіРДЃЌВЂВПЪ№дкЪ§ОнЗжЮіЯЕЭГжаЃЌШЛКѓПЩвдаЮГЩЪ§ОнЗжЮіЕФФЃАхКЭПЩЪгЛЏЕФЗжЮіНсЙћЃЌвдБуЪЕЯжздЖЏЛЏЕФЪ§ОнЗжЮіБЈИцЁЃ
гІгУФЃаЭЃЌОЭЪЧНЋФЃаЭгІгУгкецЪЕЕФвЕЮёГЁОАЁЃЙЙНЈФЃаЭЕФФПЕФЃЌОЭЪЧвЊгУгкНтОіЙЄзїжаЕФвЕЮёЮЪЬтЕФЃЌБШШчдЄВтПЭЛЇааЮЊЃЌБШШчЛЎЗжПЭЛЇШКЃЌЕШЕШЁЃ
ЕБШЛЃЌгІгУФЃаЭЙ§ГЬжаЃЌЛЙашвЊЪеМЏвЕЮёдЄВтНсЙћгыецЪЕЕФвЕЮёНсЙћЃЌвдМьбщФЃаЭдкецЪЕЕФвЕЮёГЁОАжаЕФаЇЙћЃЌЭЌЪБгУгкКѓајФЃаЭЕФгХЛЏЁЃ
ЕкЮхВНЃКгХЛЏФЃаЭ
гХЛЏФЃаЭЃЌвЛАуЗЂЩњдкСНжжЧщПіЯТЃК
вЛЪЧдкЦРЙРФЃаЭжаЃЌШчЙћЗЂЯжФЃаЭЧЗФтКЯЃЌЛђепЙ§ФтКЯЃЌЫЕУїетИіФЃаЭД§гХЛЏЁЃ
ЖўЪЧдкецЪЕгІгУГЁОАжаЃЌЖЈЦкНјаагХЛЏЃЌЛђепЕБЗЂЯжФЃаЭдкецЪЕЕФвЕЮёГЁОАжааЇЙћВЛКУЪБЃЌвВвЊЦєЖЏгХЛЏЁЃ
ШчЙћдкЦРЙРФЃаЭЪБЃЌЗЂЯжФЃаЭЧЗФтКЯЃЈМДаЇЙћВЛМбЃЉЛђепЙ§ФтКЯЃЌдђФЃаЭВЛПЩгУЃЌашвЊгХЛЏФЃаЭЁЃЫљЮНЕФФЃаЭгХЛЏЃЌПЩвдгавдЯТМИжжЧщПіЃК
1ЃЉжиаТбЁдёвЛИіаТЕФФЃаЭЃЛ
2ЃЉФЃаЭжадіМгаТЕФПМТЧвђЫиЃЛ
3ЃЉГЂЪдЕїећФЃаЭжаЕФуажЕЕНзюгХЃЛ
4ЃЉГЂЪдЖддЪМЪ§ОнНјааИќЖрЕФдЄДІРэЃЌБШШчХЩЩњаТБфСПЁЃ
ВЛЭЌЕФФЃаЭЃЌЦфФЃаЭгХЛЏЕФОпЬхзіЗЈвВВЛвЛбљЁЃБШШчЛиЙщФЃаЭЕФгХЛЏЃЌФуПЩФмвЊПМТЧвьГЃЪ§ОнЖдФЃаЭЕФгАЯьЃЌвВвЊНјааЗЧЯпадКЭЙВЯпадЕФМьбщЃЛдйБШШчЫЕЗжРрФЃаЭЕФгХЛЏЃЌжївЊЪЧвЛаЉуажЕЕФЕїећЃЌвдЪЕЯжОЋзМадгыЭЈгУадЕФОљКтЁЃ
ЕБШЛЃЌвВПЩвдВЩгУдЊЫуЗЈРДгХЛЏФЃаЭЃЌОЭЪЧЭЈЙ§бЕСЗЖрИіШѕФЃаЭЃЌРДЙЙНЈвЛИіЧПФЃаЭЃЈМДШ§ИіГєЦЄНГЃЌЖЅЩЯвЛИіжюИ№ССЃЉРДЪЕЯжФЃаЭЕФзюМбаЇЙћЁЃ
ЪЕМЪЩЯЃЌФЃаЭгХЛЏВЛНіНіАќКЌСЫЖдФЃаЭБОЩэЕФгХЛЏЃЌЛЙАќКЌСЫЖддЪМЪ§ОнЕФДІРэгХЛЏЃЌШчЙћЪ§ОнФмЙЛЕУЕНгааЇЕФдЄДІРэЃЌПЩвддкФГжжГЬЖШЩЯНЕЕЭЖдФЃаЭЕФвЊЧѓЁЃЫљвдЃЌЕБФуЗЂЯжФуГЂЪдЕФЫљгаФЃаЭаЇЙћЖМВЛЬЋКУЕФЪБКђЃЌБ№ЭќМЧСЫЃЌетгаПЩФмЪЧФуЕФЪ§ОнМЏУЛгаЕУЕНгааЇЕФдЄДІРэЃЌУЛгаевЕНКЯЪЪЕФЙиМќвђЫиЃЈздБфСПЃЉЁЃ
ВЛПЩФмгавЛИіФЃаЭЪЪгУгкЫљгавЕЮёГЁОАЃЌвВВЛЬЋПЩФмгавЛИіЙЬгаЕФФЃаЭОЭЪЪгУгкФуЕФвЕЮёГЁОАЁЃКУФЃаЭЖМЪЧгХЛЏГіРДЕФЃЁ
зюКѓгя
е§ШчЪ§ОнЭкОђБъзМСїГЬвЛбљЃЌЙЙНЈФЃаЭЕФетЮхИіВНжшЃЌВЂВЛЪЧЕЅЯђЕФЃЌЖјЪЧвЛИібЛЗЕФЙ§ГЬЁЃЕБЗЂЯжФЃаЭВЛМбЪБЃЌОЭашвЊгХЛЏЃЌОЭгаПЩФмЛиЕНзюПЊЪМЕФЕиЗНжиаТПЊЪМЫМПМЁЃМДЪЙФЃаЭПЩгУСЫЃЌвВашвЊЖЈЦкЖдФЃаЭНјааЮЌЛЄКЭгХЛЏЃЌвдБуШУФЃаЭФмЙЛМЬајЪЪгУаТЕФвЕЮёГЁОАЁЃ
|






