| БрМЭЦМі: |
| БОЮФРДздгкЭјТчЃЌБОЮФЯъЯИУшЪіKafkaЕФЛљБОдРэЁЂKafkaдіЧПзщМўвдМАЛљгкKafkaЕФLambdaМмЙЙЕФОпЬхгІгУГЁОАвдМАЯргІЕФбаЗЂГЩЙћЁЃ |
|
вЛЁЂЧАбд
БОАИР§зїЮЊДѓЪ§ОнПђМмдкЙЋЙВАВШЋСьгђгІгУЪЕМљЕФПЊЦЊжЎзїЃЌНЋДгзюЛљДЁЕФЪ§ОнМмЙЙЬхЯЕгХЛЏНВЦ№ЁЃдкНгЯТРДЕФеТНкРяНЋЯъЯИУшЪіKafkaЕФЛљБОдРэЁЂKafkaдіЧПзщМўвдМАЛљгкKafkaЕФLambdaМмЙЙЕФОпЬхгІгУГЁОАвдМАЯргІЕФбаЗЂГЩЙћЁЃ
LambdaМмЙЙгЩStormЕФзїепNathan MarzЬсГіЁЃжМдкЩшМЦГівЛИіФмТњзуЁЃЪЕЪБДѓЪ§ОнЯЕЭГЙиМќЬиадЕФМмЙЙЃЌОпгаИпШнДэЁЂЕЭбгЪБКЭПЩРЉеЙЕШЬиЁЃ
LambdaМмЙЙећКЯРыЯпМЦЫуКЭЪЕЪБМЦЫуЃЌШкКЯВЛПЩБфЃЈImmutabilityЃЌЖСаДЗжРыКЭИєРы
вЛЯЕСаЙЙддђЃЌПЩМЏГЩHadoopЃЌKafkaЃЌStormЃЌSpark,HBaseЕШИїРрДѓЪ§ОнзщМўЁЃ
ДѓЪ§ОнЯЕЭГЕФЙиМќЮЪЬтЃКШчКЮЪЕЪБЕидкШЮвтДѓЪ§ОнМЏЩЯНјааВщбЏЃПДѓЪ§ОндйМгЩЯЪЕЪБМЦЫуЃЌЮЪЬтЕФФбЖШБШНЯДѓЁЃLambdaМмЙЙЭЈЙ§ЗжНтЕФШ§ВуМмЙЙРДНтОіИУЮЪЬтЃКBatch
LayerЃЌSpeed LayerКЭServing LayerЁЃШчЯТЭМЫљЪОвтЁЃ
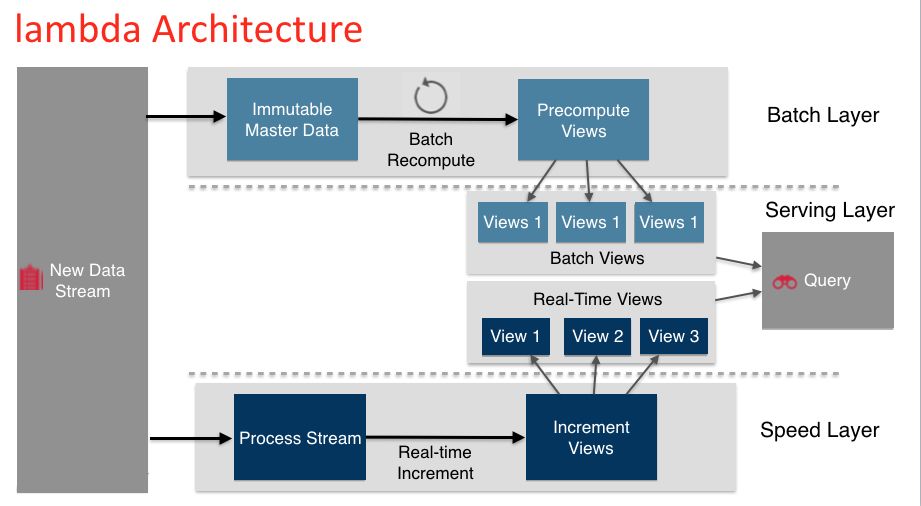
ЭМ1.1 LambdaМмЙЙЭМ
Ъ§ОнСїНјШыЯЕЭГКѓЃЌЭЌЪБЗЂЭљBatch LayerКЭSpeed LayerДІРэЁЃBatch
LayerвдВЛПЩБфФЃаЭРыЯпДцДЂЫљгаЪ§ОнМЏЃЌЭЈЙ§дкШЋЬхЪ§ОнМЏЩЯВЛЖЯжиаТМЦЫуЙЙНЈВщбЏЫљЖдгІЕФBatch
ViewsЁЃSpeed LayerДІРэдіСПЕФЪЕЪБЪ§ОнСїЃЌВЛЖЯИќаТВщбЏЫљЖдгІЕФReal time ViewsЁЃServing
LayerЯьгІгУЛЇЕФВщбЏЧыЧѓЃЌКЯВЂBatch ViewКЭReal time ViewжаЕФНсЙћЪ§ОнМЏЕНзюжеЕФЪ§ОнМЏЁЃ
ЖўЁЂЛљгкKafkaЕФLambdaМмЙЙ
2.1 ФГЪЁДѓЪ§ОнЦНЬЈЪЕМљАИР§
вдФГЪЁЬќДѓЪ§ОнНЈЩшЗНАИЮЊР§ЃЌНЋKafkaзїЮЊЭГвЛЕФЪ§ОнСїЭЈЕРЃЈdata pipelineЃЉЁЃKafkaЗжЮЊЕиЪаКЭЪЁЬќСНМЖЃЌЕиЪаЪ§ОнЪзЯШОЙ§СїЪНЛЏДІРэЗЂЫЭЕНЕиЪаЕФKafkaЃЌОЙ§БъзМЛЏКѓЃЌЕиЪаKafkaЕФдйЛуМЏЕНЪЁЬќKafkaЁЃ
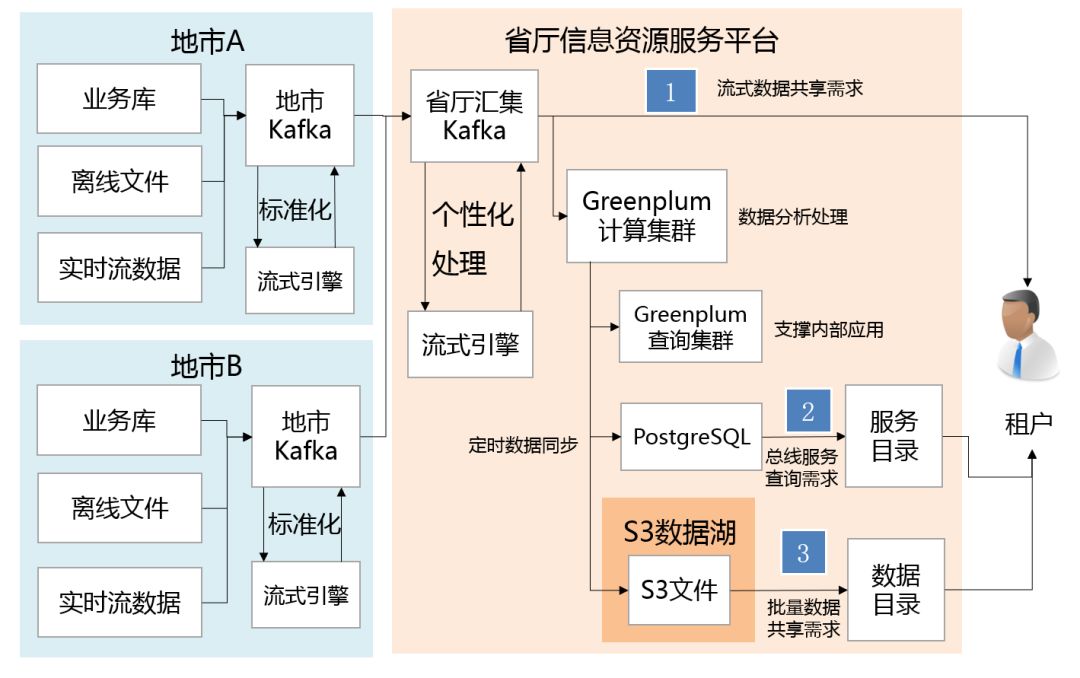
ФГЪЁДѓЪ§ОнЦНЬЈЪЕМљ
2.2 в§ШыKafkaЕФБивЊад
дкДѓЪ§ОнЯЕЭГжаЃЌГЃГЃЛсХіЕНвЛИіЮЪЬтЃЌећИіДѓЪ§ОнЪЧгЩИїИізгЯЕЭГзщГЩЃЌЪ§ОнашвЊдкИїИізгЯЕЭГжаИпадФмЁЂЕЭбгГйЕФВЛЭЃСїзЊЁЃДЋЭГЕФЦѓвЕЯћЯЂЯЕЭГВЂВЛЪЧЗЧГЃЪЪКЯДѓЙцФЃЕФЪ§ОнДІРэЁЃШнвздьГЩШежОЪ§ОнФбвдЪеМЏЃЌШнвзЖЊЪЇаХЯЂЃЌOracleЪЕР§жЎМфЕФЙмЕРЮоЗЈЙЉЦфЫќЯЕЭГЪЙгУЃЌЪ§ОнМмЙЙвзДДНЈФбРЉеЙЃЌЪ§ОнжЪСПВюЕШЮЪЬтЁЃЮЊСЫЭЌЪБИуЖЈдкЯпгІгУЃЈЯћЯЂЃЉКЭРыЯпгІгУЃЈЪ§ОнЮФМўЃЌШежОЃЉЃЌKafkaОЭГіЯжСЫЁЃKafkaПЩвдЦ№ЕНСНИізїгУЃК
1.НЕЕЭЯЕЭГзщЭјИДдгЖШЁЃ
2.НЕЕЭБрГЬИДдгЖШЃЌИїИізгЯЕЭГВЛдйЪЧЯрЛЅаЩЬНгПкЃЌИїИізгЯЕЭГРрЫЦВхПкВхдкВхзљЩЯЃЌKafkaГаЕЃИпЫйЪ§ОнзмЯпЕФзїгУЁЃ
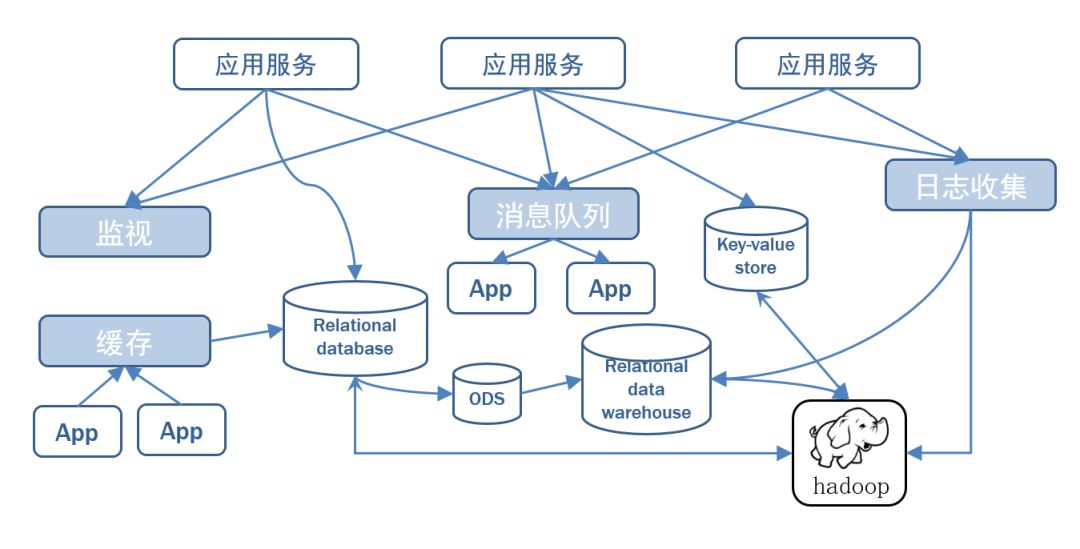
ДЋЭГЪ§ОнМмЙЙ
в§ШыKafkaКѓЃЌПЩвдЙЙНЈвдСїЮЊжааФЪ§ОнМмЙЙЁЃKafkaЪЧзїЮЊвЛИіШЋОжЪ§ОнЙмЕРЁЃУПИіЯЕЭГЖМЯђетИіжааФЙмЕРЗЂЫЭЪ§ОнЛђепДгжаЛёШЁЪ§ОнЁЃгІгУГЬађЛђСїДІРэГЬађПЩвдНгШыЙмЕРВЂДДНЈаТЕФХЩЩњСїЁЃетаЉХЩЩњСїгжПЩвдЙЉЦфЫќИїжжЯЕЭГЪЙгУЁЃ
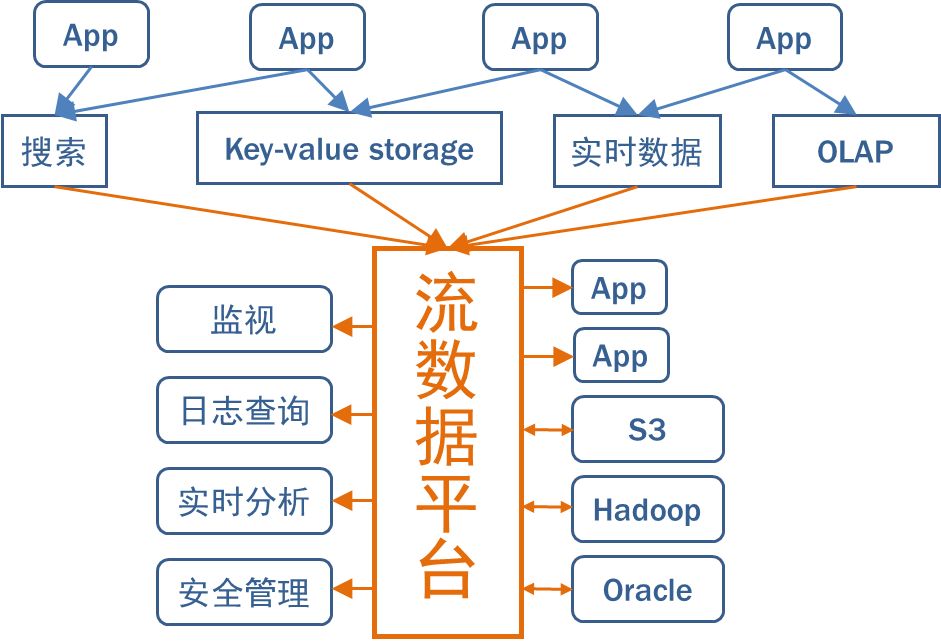
вдСїЮЊжааФЕФЪ§ОнМмЙЙ
Ш§ЁЂKafkaММЪѕЗжЮі
3.1 KafkaЕФЬиЕу
KafkaПЩвдШУКЯЪЪЕФЪ§ОнвдКЯЪЪЕФаЮЪНГіЯждкКЯЪЪЕФЕиЗНЁЃKafkaЕФзіЗЈЪЧЬсЙЉЯћЯЂЖгСаЃЌШУЩњВњепЕЅЭљЖгСаЕФФЉЮВЬэМгЪ§ОнЃЌШУЖрИіЯћЗбепДгЖгСаРяУцвРДЮЖСШЁЪ§ОнШЛКѓздааДІРэЁЃ
KafkaЯћЯЂЖгСа
ЗжВМЪНЯЕЭГЃЌвзгкЯђЭтРЉеЙЁЃЫљгаЕФproducerЁЂbrokerКЭconsumerЖМЛсгаЖрИіЃЌОљЮЊЗжВМЪНЕФЁЃЮоашЭЃЛњМДПЩРЉеЙЛњЦїЁЃ
ЬсЙЉPub/SubЗНЪНЕФКЃСПЯћЯЂДІРэЁЃ ОнСЫНтЃЌKafkaУПУыПЩвдЩњВњдМ25ЭђЯћЯЂЃЈ50 MBЃЉЃЌУПУыДІРэ55ЭђЯћЯЂЃЈ110
MBЃЉЁЃ
вдИпШнДэЕФЗНЪНДцДЂКЃСПЪ§ОнСїЁЃ
БЃжЄЪ§ОнСїЕФЫГађЃЌДІРэЙиМќИќаТЁЃ
ЬсЙЉЯћЯЂЕФГЄЪБМфДцДЂЃЌНЋЯћЯЂГжОУЛЏЕНДХХЬЃЌвђДЫПЩгУгкХњСПЯћЗбЃЌР§ШчETLЃЌвдМАЪЕЪБгІгУГЬађЁЃЭЈЙ§НЋЪ§ОнГжОУЛЏЕНгВХЬвдМАreplicationЗРжЙЪ§ОнЖЊЪЇЁЃ
ФмЙЛЛКДцЛђГжОУЛЏЪ§ОнЃЌжЇГжгыХњДІРэЯЕЭГЃЈШчHadoopЃЉЕФМЏГЩЁЃ
ЮЊЪЕЪБгІгУГЬађЬсЙЉЕЭбгЪБЪ§ОнДЋЪфКЭДІРэЁЃ
жЇГжonlineКЭofflineЕФГЁОАЁЃ
ЯћЯЂБЛДІРэЕФзДЬЌЪЧдкconsumerЖЫЮЌЛЄЃЌЖјВЛЪЧгЩserverЖЫЮЌЛЄЁЃЕБЪЇАмЪБФмздЖЏЦНКтЁЃ
3.2 KafkaдРэЗжЮі
3.2.1 KafkaзмЬхМмЙЙ
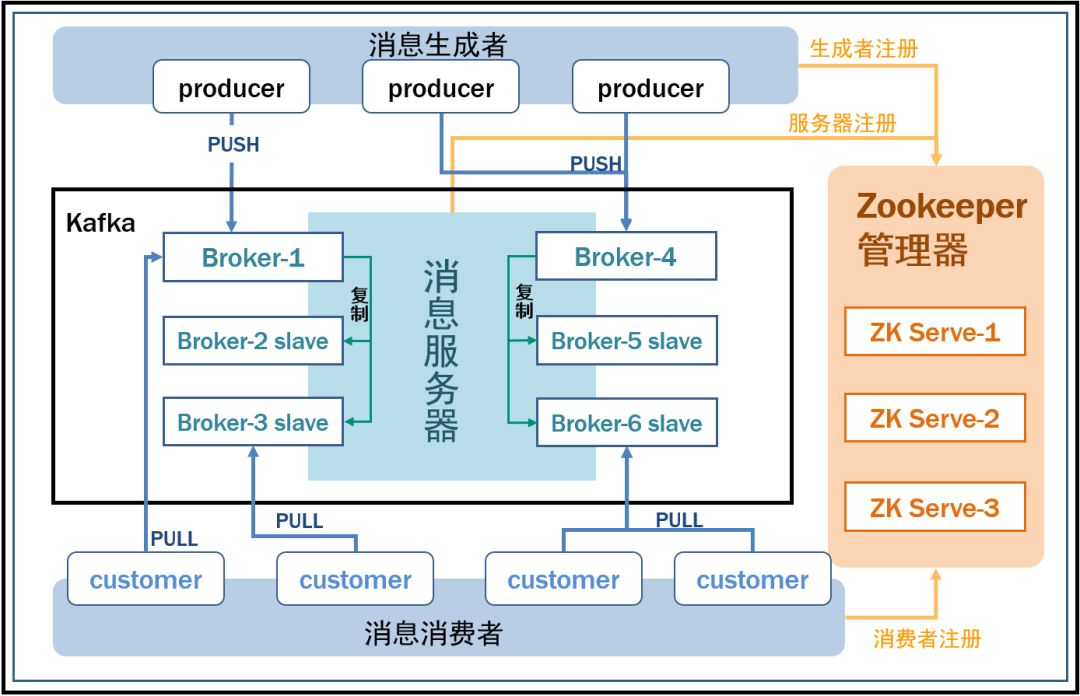
KafkaзмЬхМмЙЙ
KafkaЕФећЬхМмЙЙЗЧГЃМђЕЅЃЌЪЧЯдЪНЗжВМЪНМмЙЙЃЌproducerЁЂbrokerЃЈkafkaЃЉКЭconsumerЖМПЩвдгаЖрИіЁЃProducerЃЌconsumerЪЕЯжKafkaзЂВсЕФНгПкЃЌЪ§ОнДгproducerЗЂЫЭЕНbrokerЃЌbrokerГаЕЃвЛИіжаМфЛКДцКЭЗжЗЂЕФзїгУЁЃbrokerЗжЗЂзЂВсЕНЯЕЭГжаЕФconsumerЁЃbrokerЕФзїгУРрЫЦгкЛКДцЃЌМДЛюдОЕФЪ§ОнКЭРыЯпДІРэЯЕЭГжЎМфЕФЛКДцЁЃПЭЛЇЖЫКЭЗўЮёЦїЖЫЕФЭЈаХЃЌЪЧЛљгкМђЕЅЁЂИпадФмЧвгыБрГЬгябдЮоЙиЕФTCPавщЁЃ
ЛљБОИХФюЃК
1.TopicЃКЬижИKafkaДІРэЕФЯћЯЂдДЃЈfeeds of messagesЃЉЕФВЛЭЌЗжРрЁЃ
2.PartitionЃКTopicЮяРэЩЯЕФЗжзщЃЌвЛИіtopicПЩвдЗжЮЊЖрИіpartitionЃЌУПИіpartitionЪЧвЛИігаађЕФЖгСаЁЃpartitionжаЕФУПЬѕЯћЯЂЖМЛсБЛЗжХфвЛИігаађЕФidЃЈoffsetЃЉЁЃ
3.MessageЃКЯћЯЂЃЌЪЧЭЈаХЕФЛљБОЕЅЮЛЃЌУПИіproducerПЩвдЯђвЛИіtopicЃЈжїЬтЃЉЗЂВМвЛаЉЯћЯЂЁЃ
4.ProducersЃКЯћЯЂКЭЪ§ОнЩњВњепЃЌЯђKafkaЕФвЛИіtopicЗЂВМЯћЯЂЕФЙ§ГЬНазіproducersЁЃ
5.ConsumersЃКЯћЯЂКЭЪ§ОнЯћЗбепЃЌЖЉдФtopicsВЂДІРэЦфЗЂВМЕФЯћЯЂЕФЙ§ГЬНазіconsumersЁЃ
6.BrokerЃКЛКДцДњРэЃЌKafkaМЏШКжаЕФвЛЬЈЛђЖрЬЈЗўЮёЦїЭГГЦЮЊbrokerЁЃ
3.2.2 KafkaЙиМќММЪѕЕу
3.2.2.1 zero-copy
дкKafkaЩЯЃЌгаСНИідвђПЩФмЕМжТЕЭаЇЃКвЛЪЧЬЋЖрЕФЭјТчЧыЧѓЃЌЖўЪЧЙ§ЖрЕФзжНкПНБДЁЃЮЊСЫЬсИпаЇТЪЃЌKafkaАбmessageЗжГЩвЛзщвЛзщЕФЃЌУПДЮЧыЧѓЛсАбвЛзщmessageЗЂИјЯргІЕФconsumerЁЃ
ДЫЭтЃЌЮЊСЫМѕЩйзжНкПНБДЃЌВЩгУСЫsendfileЯЕЭГЕїгУЁЃ
3.2.2.2 Exactly once message transfer
дкKafkaжаНіБЃДцСЫУПИіconsumerвбОДІРэЪ§ОнЕФoffsetЁЃетбљгаСНИіКУДІЃКвЛЪЧБЃДцЕФЪ§ОнСПЩйЃЛЖўЪЧЕБconsumerГіДэЪБЃЌжиаТЦєЖЏconsumerДІРэЪ§ОнЪБЃЌжЛашДгзюНќЕФoffsetПЊЪМДІРэЪ§ОнМДПЩЁЃ
3.2.2.3 Push/pull
Producer ЯђKafkaЭЦЃЈpushЃЉЪ§ОнЃЌconsumer
Дгkafka РЃЈpullЃЉЪ§ОнЁЃ
3.2.2.4 ИКдиОљКтКЭШнДэ
ProducerКЭbrokerжЎМфУЛгаИКдиОљКтЛњжЦЁЃbrokerКЭconsumerжЎМфРћгУzookeeperНјааИКдиОљКтЁЃЫљгаbrokerКЭconsumerЖМЛсдкzookeeperжаНјаазЂВсЃЌЧвzookeeperЛсБЃДцЫћУЧЕФвЛаЉдЊЪ§ОнаХЯЂЁЃШчЙћФГИіbrokerКЭconsumerЗЂЩњСЫБфЛЏЃЌЫљгаЦфЫћЕФbrokerКЭconsumerЖМЛсЕУЕНЭЈжЊЁЃ
3.2.2.5 ЗжЧј
KafkaПЩвдНЋжїЬтЛЎЗжЮЊЖрИіЗжЧјЃЈPartitionЃЉЃЌЛсИљОнЗжЧјЙцдђбЁдёАбЯћЯЂОљдШЕФЗжВМЕНВЛЭЌЕФЗжЧјжаЃЌетбљОЭЪЕЯжСЫИКдиОљКтКЭЫЎЦНРЉеЙЁЃЖрИіЖЉдФепПЩвдДгвЛИіЛђепЖрИіЗжЧјжаЭЌЪБЯћЗбЪ§ОнЃЌвджЇГХКЃСПЪ§ОнДІРэФмСІЁЃгЩгкЯћЯЂЪЧвдзЗМгЕНЗжЧјжаЕФЃЌЖрИіЗжЧјЫГађаДДХХЬЕФзмаЇТЪвЊБШЫцЛњаДФкДцЛЙвЊИпЃЌЪЧKafkaИпЭЬЭТТЪЕФживЊБЃжЄжЎвЛЁЃ
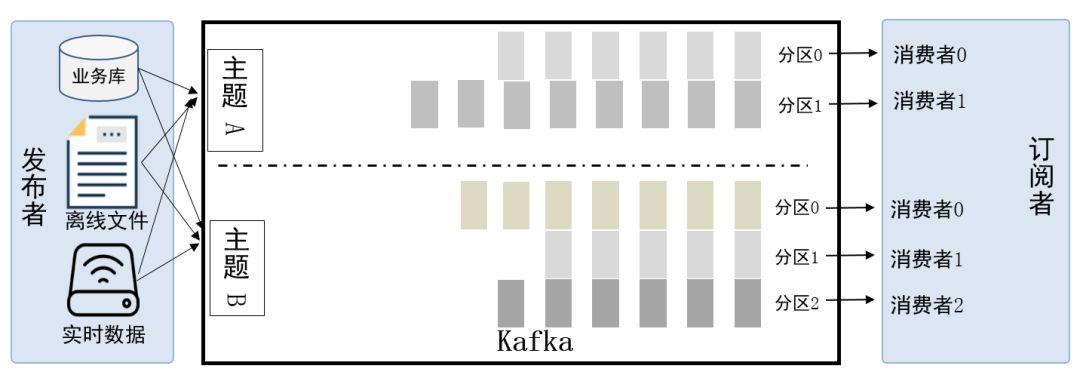
KafkaЗжЧјЪЕЯжИКдиОљКтЃЌЫЎЦНЭиеЙЃЌИпЭЬЭТТЪ
ЮЊСЫБЃжЄЪ§ОнЕФПЩППадЃЌУПИіЗжЧјНкЕуЖМЛсЩшжУвЛИіLeaderЃЌвдМАШєИЩНкЕуЕБFollowerЁЃЪ§ОнаДШыЗжЧјЪБЃЌLeaderГ§СЫздМКИДжЦвЛЗнЃЌЛЙЛсНЋЪ§ОнИДжЦЕНУПИіFollowerЩЯЁЃШєШЮвЛfollowerЙвСЫЃЌKafkaЛсдйеввЛИіfollowerДгleaderЛёШЁЪ§ОнЁЃШєLeaderЙвСЫЃЌдђДгFollowerжаГщШЁвЛИіЕБLeaderЁЃ
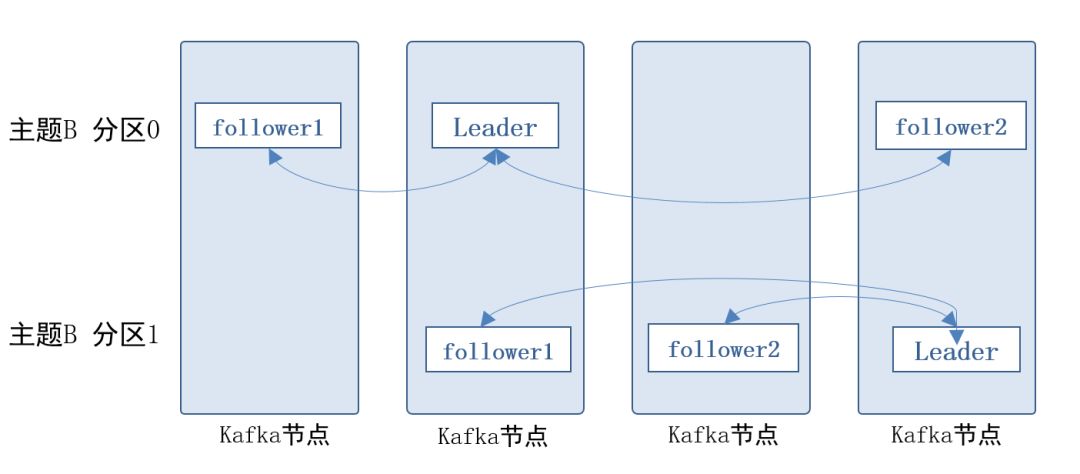
KafkaЗжЧјЪЕЯжЪ§ОнЕФПЩППад
3.3 KafkaЕФММЪѕбЁаЭ
3.3.1 Confluent PlatformИХЪі
Confluent Platform ЪЧвЛИіСїЪ§ОнЦНЬЈЃЌФмЙЛзщжЏЙмРэРДздВЛЭЌЪ§ОндДЕФЪ§ОнЃЌгЕгаЮШЖЈИпаЇЕФЯЕЭГЁЃConfluent
Platform КмШнвзЕФНЈСЂЪЕЪБЪ§ОнЙмЕРКЭСїгІгУЁЃЭЈЙ§НЋЖрИіРДдДКЭЮЛжУЕФЪ§ОнМЏГЩЕНвЛИіжабыЪ§ОнСїЦНЬЈЁЃConfluent
PlatformМђЛЏСЫСЌНгЪ§ОндДЕНKafkaЁЂKafkaЙЙНЈгІгУГЬађЃЌвдМААВШЋЁЂМрПиКЭЙмРэKafkaЕФЛљДЁЩшЪЉЁЃ
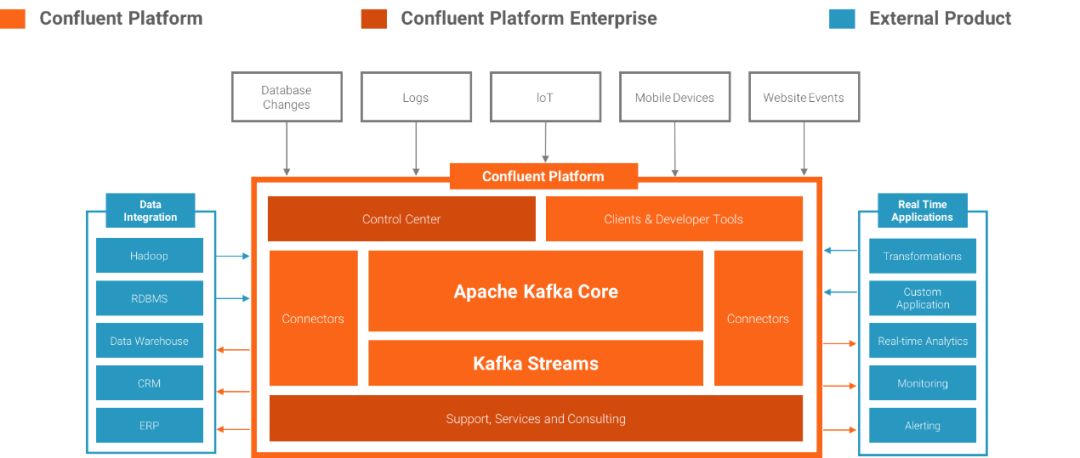
Confluent PlatformМмЙЙ
3.3.2 Kafka Connect
Kafka ConnectЃЌПЩвдИќЗНБуЕФДДНЈКЭЙмРэЪ§ОнСїЙмЕРЁЃЫќЮЊKafkaКЭЦфЫќЯЕЭГДДНЈЙцФЃПЩРЉеЙЕФЁЂПЩаХРЕЕФСїЪ§ОнЬсЙЉСЫвЛИіМђЕЅЕФФЃаЭЃЌЭЈЙ§connectorsПЩвдНЋДѓЪ§ОнДгЦфЫќЯЕЭГЕМШыЕНKafkaжаЃЌвВПЩвдДгKafkaжаЕМГіЕНЦфЫќЯЕЭГЁЃKafka
ConnectПЩвдНЋЭъећЕФЪ§ОнПтзЂШыЕНKafkaЕФTopicжаЃЌЛђепНЋЗўЮёЦїЕФЯЕЭГМрПижИБъзЂШыЕНKafkaЃЌШЛКѓЯёе§ГЃЕФKafkaСїДІРэЛњжЦвЛбљНјааЪ§ОнСїДІРэЁЃЖјЕМГіЙЄзїдђЪЧНЋЪ§ОнДгKafka
TopicжаЕМГіЕНЦфЫќЪ§ОнДцДЂЯЕЭГЁЂВщбЏЯЕЭГЛђепРыЯпЗжЮіЯЕЭГЕШЁЃ
Kafka ConnectЬиадАќРЈЃК
1.Kafka connectorЭЈгУПђМм,ЬсЙЉЭГвЛЕФМЏГЩAPI
2.ЭЌЪБжЇГжЗжВМЪНФЃЪНКЭЕЅЛњФЃЪН
3.REST НгПкЃЌгУРДВщПДКЭЙмРэKafka connectors
4.здЖЏЛЏЕФoffsetЙмРэЃЌПЊЗЂШЫдБВЛБиЕЃаФДэЮѓДІРэЕФгАЯь
5.ЗжВМЪНЁЂПЩРЉеЙ
6.Сї/ХњДІРэМЏГЩ
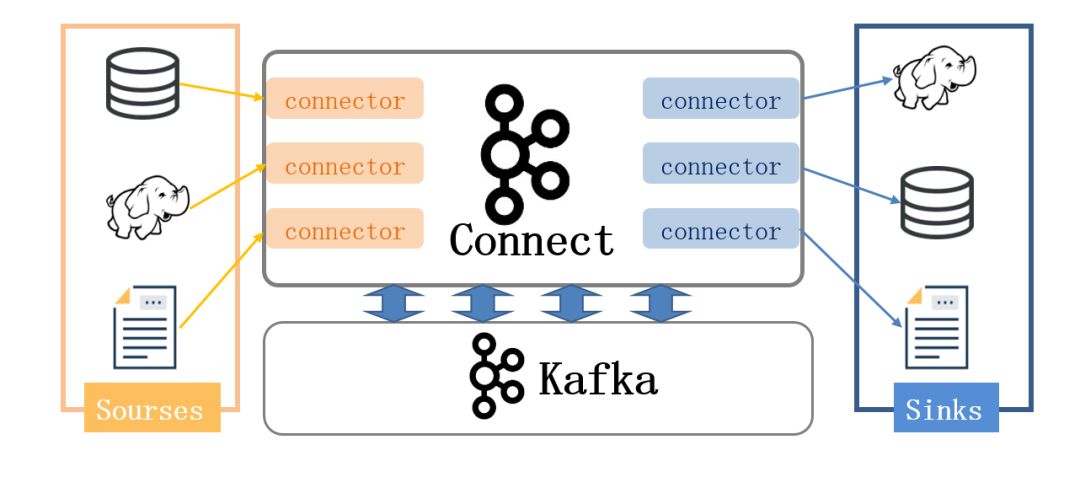
Kafka connectЙЄзїдРэ
3.4 KafkaЖЫЕНЖЫЩѓМЦ
ВЩгУПЊдДЕФChaperoneММЪѕПђМмРДЪЕЯжЖдkafkaЕФЖЫЕНЖЫЩѓМЦЁЃЦфФПБъЪЧдкЪ§ОнСїОЪ§ОнЙмЕРЕФУПИіНзЖЮЃЌФмЙЛзЅзЁУПИіЯћЯЂЃЌЭГМЦвЛЖЈЪБМфЖЮФкЕФЪ§ОнСПЃЌВЂОЁдчзМШЗЕиМьВтГіЪ§ОнЕФЖЊЪЇЁЂбгГйКЭжиИДЧщПіЁЃ
1.ЪЧЗёгаЪ§ОнЖЊЪЇЃПЪЧЃЌФЧУДЖЊЪЇСЫЖрЩйЪ§ОнЃПЫќУЧЪЧдкЪ§ОнЙмЕРЕФФФИіЕиЗНЖЊЪЇЕФЃП
2.ЖЫЕНЖЫЕФбгГйЪЧЖрЩйЃПШчЙћгаЯћЯЂбгГйЃЌЪЧДгФФРяПЊЪМЕФЃП
3.ЪЧЗёгаЪ§ОнжиИДЃП
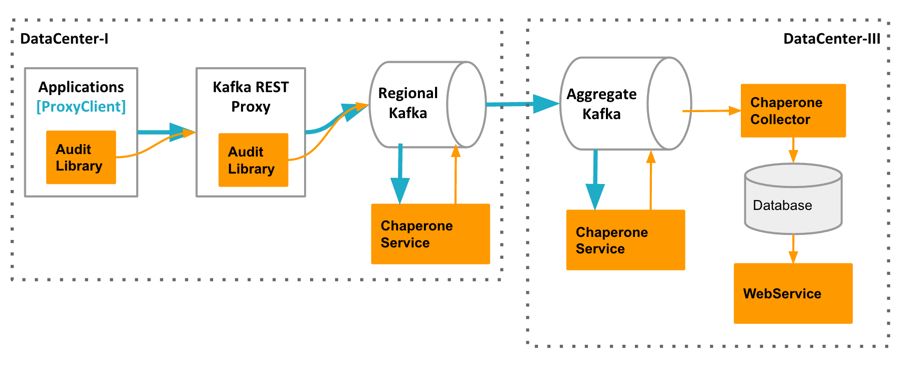
ChaperoneМмЙЙ
ChaperoneМмЙЙЃКAuditLibraryЁЂChaperoneServiceЁЂChaperoneCollectorКЭWebServiceЃЌЫќУЧЛсЪеМЏЪ§ОнЃЌВЂНјааЯрЙиМЦЫуЃЌздЖЏМьВтГіЖЊЪЇКЭбгГйЕФЪ§ОнЃЌВЂеЙЪОЩѓМЦНсЙћЁЃдкЩѓМЦЙ§ГЬжаБЃжЄУПИіЯћЯЂжЛБЛЩѓМЦвЛДЮЃЌдкВуМфЪЙгУвЛжТадЕФЪБМфДСЁЃ
ChaperoneФЃПщЩѓМЦСїГЬШчЯТЃК
1. ЩњГЩЩѓМЦЯћЯЂЃКChaperoneServiceЭЈЙ§ЖЈЪБЯђЬиЖЈЕФKafkaжїЬтЩњГЩЩѓМЦЯћЯЂРДМЧТМзДЬЌ
2. ЩѓМЦЫуЗЈЃКAuditLibraryЪЕЯжСЫЩѓМЦЫуЗЈЃЌЫќЛсЖЈЪБЪеМЏВЂДђгЁЭГМЦЪБМфДА
3. ЛёШЁЩѓМЦНсЙћЃКChaperoneCollectorМрЬ§ЬиЖЈЕФKafkaжїЬтЃЌВЂЛёШЁЫљгаЕФЩѓМЦЯћЯЂЃЌДцЕНЪ§ОнПтЃЌЩњГЩвЧБэХЬЁЃвЧБэХЬеЙЪОЃКЪ§ОнЕФЖЊЪЇЧщПіЁЂЯћЯЂЕФбгГйЧщПіЁЂВщПДУПИіжїЬтжааФЕФжїЬтзДЬЌ
4. зМШЗеЙЪОНсЙћЃКWebServiceЬсЙЉСЫRESTНгПкРДВщбЏChaperoneЪеМЏЕНЕФЖШСПжИБъЁЃЭЈЙ§етаЉНгПкЃЌЮвУЧПЩвдзМШЗЕиМЦЫуГіЪ§ОнЖЊЪЇЕФЪ§СПЁЃ
ЫФЁЂKafkaгІгУГЩЙћНщЩм
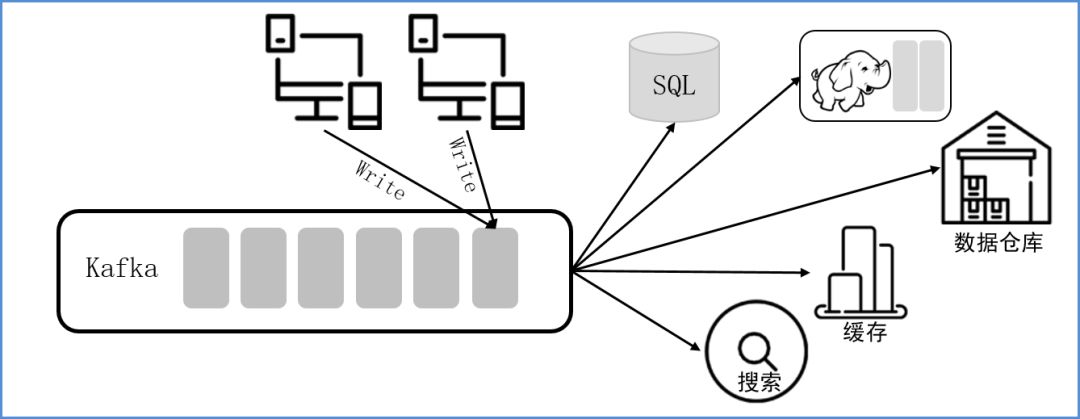
ЛљгкKafkaЕФММЪѕЬиадЃЌKafkaвбГЩЪьдЫгУгкФГЪЁЬќЕФзЪдДЗўЮёЦНЬЈЯюФПЃЌжївЊгУгкЪеМЏШежОЁЂКЃСПЪ§ОнЕФЮЂETLЃЌЮЊИївЕЮёЯЕЭГжЎМфЕФЪ§ОнЙВЯэЬсЙЉвЛИіДѓЙцФЃЯћЯЂДІРэЦНЬЈЃЌвдМАдкИїЕиЪагыЪЁЬќжЎМфаЮГЩвЛИіЪ§ОнЙмЕРЁЃ
НсКЯЖдKafkaКЭKafkaВхМўЕФЩюШыбаОПЃЌаТЕТЛуДѓЪ§ОнбаОПдКзджїбаЗЂСЫЧсСПМЖЕФFSPСїДІРэв§ЧцЃЌгУгкЧсБуЖдНгСїЪ§ОнЃЌИпаЇДІРэКЭЪЕЯжИїРрСїЪ§ОнбгеЙгІгУЁЃ
4.1 ШежООлКЯ
ЖрИіЯЕЭГжЎМфЕФШежОЭЈЙ§kafkaЛуОлЃЌЬсЙЉЩѓМЦЛђЦфЫћМрПиЯЕЭГНјааЯћЗбЁЃШежООлКЯвЛАуРДЫЕЪЧДгЗўЮёЦїЩЯЪеМЏШежОЮФМўЃЌШЛКѓЗХЕНвЛИіМЏжаЕФЮЛжУЃЈЮФМўЗўЮёЦїЛђHDFSЃЉНјааДІРэЁЃШЛЖјKafkaКіТдЕєЮФМўЕФЯИНкЃЌНЋЦфИќЧхЮњЕиГщЯѓГЩвЛИіИіШежОЛђЪТМўЕФЯћЯЂСїЁЃетОЭШУKafkaДІРэЙ§ГЬбгГйИќЕЭЃЌИќШнвзжЇГжЖрЪ§ОндДКЭЗжВМЪНЪ§ОнДІРэЁЃБШЦ№вдШежОЮЊжааФЕФЯЕЭГБШШчScribeЛђепFlumeРДЫЕЃЌKafkaЬсЙЉЭЌбљИпаЇЕФадФмКЭвђЮЊИДжЦЕМжТЕФИќИпЕФФЭгУадБЃжЄЃЌвдМАИќЕЭЕФЖЫЕНЖЫбгГйЁЃ
4.2 ЯћЯЂЯЕЭГ
ЯЕЭГжЎМфНтёюЃЌЭЈЙ§kafkaЧ§ЖЏИївЕЮёЯЕЭГжЎМфЕФЪ§ОнЙВЯэгывЕЮёСїГЬЧ§ЖЏЁЃ
БШЦ№ДѓЖрЪ§ЕФЯћЯЂЯЕЭГРДЫЕЃЌKafkaгаИќКУЕФЭЬЭТСПЃЌФкжУЕФЗжЧјЁЂШпгрМАШнДэадЃЌШУKafkaГЩЮЊСЫвЛИіКмКУЕФДѓЙцФЃЯћЯЂДІРэгІгУЕФНтОіЗНАИЁЃЯћЯЂЯЕЭГвЛАуЭЬЭТСПЯрЖдНЯЕЭЃЌЕЋЪЧашвЊИќаЁЕФЖЫЕНЖЫбгЪБЃЌВЂГЃГЃвРРЕгкKafkaЬсЙЉЕФЧПДѓЕФГжОУадБЃеЯЁЃдкетИіСьгђЃЌKafkaзувдцЧУРДЋЭГЯћЯЂЯЕЭГЃЌШчActiveMRЛђRabbitMQЁЃ
4.3 Ъ§ОнЙмЕР
KafkaШУМЏГЩЙЄзїжЛашСЌНгЕНвЛИіЕЅЖРЕФЙмЕРЃЌЖјЮоашСЌНгЕНУПИіЪ§ОнЩњВњЗНгыЯћЗбЗНЁЃ
KafkaЬсЙЉЪ§ОнЙмЕРЃЌШУЖрИіЕиЪаИїжжРраЭЕФЪ§ОнзЪдДЃЌМЏГЩЪБВЛашвЊжЊЕРдЪМЪ§ОндДЕФЯИНкЃЌЗЂВМЪ§ОнЪБвВВЛашвЊжЊЕРФФИігІгУГЬађЛсЯћЗбКЭМгдиетаЉЪ§ОнЃЌдіМгаТЯЕЭГЃЌвВжЛашвЊНгШыЯжгаЕФKafkaСїЪ§ОнЦНЬЈОЭПЩвдЁЃ
ФГЪЁЬќKafkaЪ§ОнЙмЕРАИР§
4.4 ETLСїЫЎЯп
ЮДв§ШыkafkaЪБЃЌЪ§ОнЕФETLЙ§ГЬашЩњГЩСйЪБЪ§ОнПтЃЌЖрДЮВњЩњТфЕиЕФЮФМўЃЌКФЗбФкДцЃЌЖјЧвдкдйЕїгУСйЪБЪ§ОнПтЪБЃЌЛсКФгУФкДцЁЃетбљКёжиЕФМмЙЙвВВЛОпБИСїЪ§ОнДІРэФмСІЁЃ
в§ШыkafkaКѓЃЌЪЕЯжЮЂETLЁЃЭЈЙ§KafkaЖдНгСїДІРэв§ЧцЃЌМђЛЏELTСїГЬЃЌЯИЛЏЪ§ОнДІРэВуДЮЃЌЕЭбгЪБЛёШЁФПБъЪ§ОнЁЃ
ЮЂETLгХЕуЃК
1.ЮоЗьЯЮНгСїДІРэв§ЧцЃЌЭъГЩЪ§ОнПьЫйETL
2.kafkaЙЙНЈвЛИіПЩЩьЫѕЕФЃЌПЩППЕФЪ§ОнСїЭЈЕР
3.НЛЛЅЕЭбгГй
4.ЮЂETLЪЕЯжЧсБуЕФЪ§ОнДІРэСїГЬ
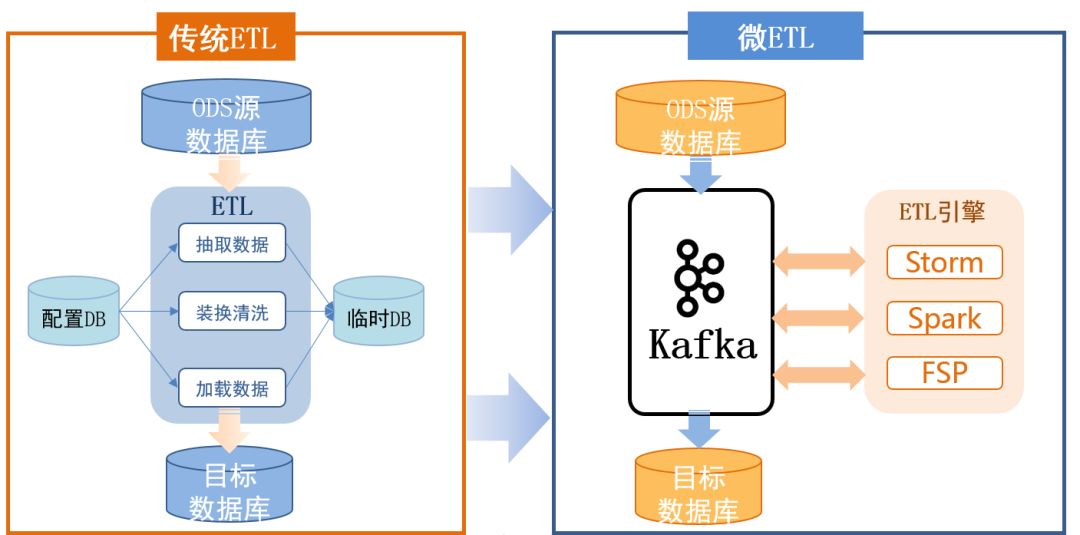
ДЋЭГETLгыЮЂETLЕФЖдБШ
4.5 FSPСїДІРэв§Чц
4.5.1 FSPМмЙЙ
FSPМмЙЙ
СїДІРэЦНЬЈЃКЖдСїЪ§ОнЃЌЬсЙЉКЫаФДІРэв§ЧцЃЌСїВЩМЏЙЄОпЕФПЩХфжУЛЏЙмРэЦНЬЈ
КЫаФДІРэв§ЧцЃКPIPELINEDBдЪаэЮвУЧЭЈЙ§sqlЕФЗНЪНЃЌЖдЪ§ОнСїзіВйзїЃЌВЂАбВйзїНсЙћДЂДцЦ№РДЃЛKafkaВхМўПЩРЉеЙkafkaЙІФмЃЌЪЕЯжSQL
on kafkaЕФИїРрСїЪ§ОнЕФбгеЙгІгУ
СїВЩМЏЙЄОпМЏЃКKafkacatЪЕЯжKafkaгы sqluldrЁЂcopyЪеМЏЕФЪ§ОнЕФЖдНгЃЌЪЕЯжСїЪ§ОнЕФВЩМЏ
4.5.2 Kafkacat
4.5.2.1 зЅШЁЗЂЫЭЯћЯЂЕФЙЄОп
KafkacatЪЧNON JVM TOOLЃЌЫйЖШПьЃЌЧсБуЃЌОВЬЌБрвыаЁгк150kbЃЌЬсЙЉдЊЪ§ОнСаБэеЙЪОМЏШК/ЗжЧј/жїЬтЁЃ
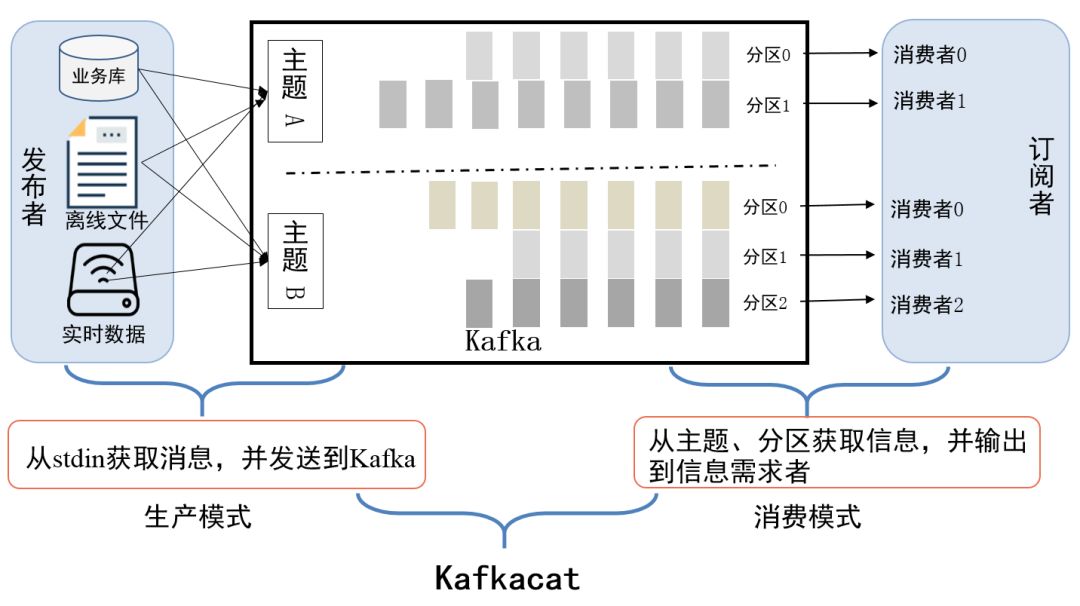
KafkacatЙЄзїФЃЪН
4.5.2.2 ЭЈЙ§kafkacatУќСюМгдиЪ§ОнЩњГЩGPЭтВПБэ
ЭЈЙ§KafkacatЪЕЯжGPгыkafkaЕФЪ§ОнЖдНгЃКkafkacatЙЄОпИљОнЭтВПБэавщПЩвдЛёШЁGPКЭkafkaЕФЪ§ОнЃЌВЂЩњГЩЭтВПБэЃЌЪЕЯжЪ§ОнЕФВЂааМгдиЁЃвдЭтВПБэЕФаЮЪНЪЕЯжЪ§ОнИёЪНДэЮѓааЕФШнДэДІРэ
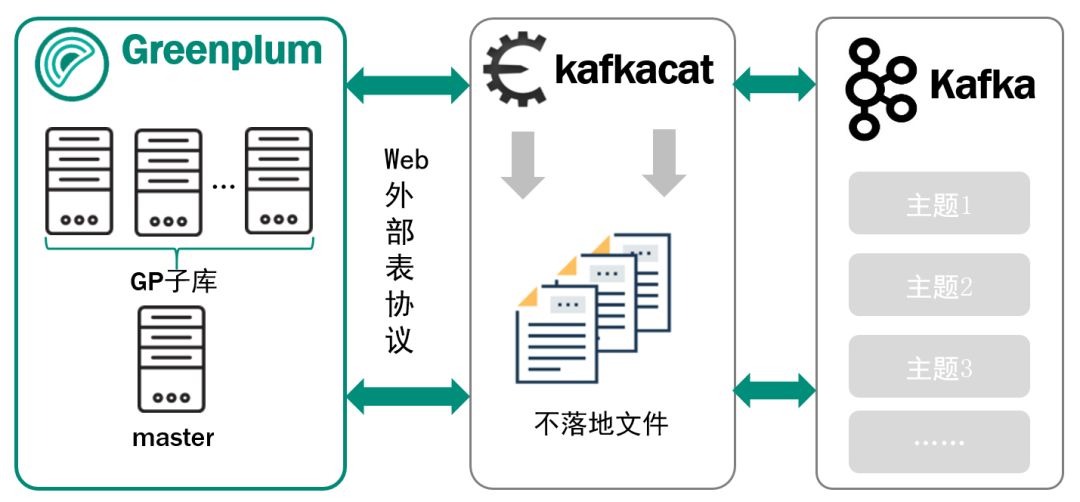
Kafkacat МгдиGPЭтВПБэ
ЮхЁЂKafkaбгеЙгІгУеЙЭћ
ећКЯNiFiгыkafkaЃЌВЂНЋMiNiFiзїЮЊЪ§ОнВЩМЏЦїВМЗХЕНЖдЖЫЪ§ОндДЃЌаЮГЩвЛЬѕПЩЭиеЙВЂСїЖЏЕФСїЪНЪ§ОнДІРэЩњВњЯпЁЃ
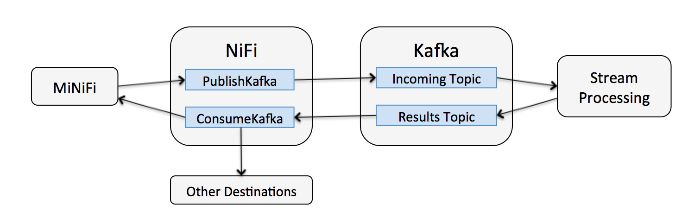
KafkaгыNiFiНсКЯ
5.1 NiFiНщЩм
NiFiЪЧвЛИівзгУЁЂЧПДѓЁЂПЩППЕФЪ§ОнДІРэгыЗжЗЂЯЕЭГЁЃМђЕЅРДЫЕЃЌNiFiЪЧгУгкздЖЏЛЏЙмРэЯЕЭГжЎМфЕФЪ§ОнСїЁЃЭЈЙ§гыKafkaЕФЖдНгЃЌЬсЙЉПЩЪгЛЏУќСюгыПижЦЃЌЪЕЯжЪ§ОнСїЕФеЙЪОгыБрМДІРэЙІФмЃЌЪЕЯжЪ§ОнСїЕФШЋГЬзЗзйЁЃ
NiFiЬиЕуЃК
1.ПЩЪгЛЏУќСюгыПижЦ
ЛљгкWebЕФгУЛЇНчУцЃЌЮоЗьЬхбщЩшМЦЃЌМрЪгЃЌПижЦЪ§ОнСїЁЃ
2. ИпРЉеЙад
NiFiЭЈЙ§ЬсЙЉздЖЈвхРрзАдиЦїФЃаЭЃЌРДШЗБЃУПИіРЉеЙзщМўжЎМфЕФдМЪјЙиЯЕБЛЯожЦдкЗЧГЃгаЯоЕФГЬЖШЁЃвђДЫЃЌдкДДНЈРЉеЙзщМўЪБЃЌОЭВЛгУдйЙ§ЖрЙизЂЦфЪЧЗёЛсгыЦфЫћзщМўВњЩњГхЭЛЁЃЪ§ОнСїДІРэГЬађФмЙЛвдПЩдЄВтКЭПЩжиИДЕФФЃЪНжДааЁЃ
3. Ъ§ОнЛибЙ
NiFiЬсЙЉЫљгаЖгСаЪ§ОнЕФЛКДцЃЌВЂЧвдкЖгСаДяЕНжИЖЈЯожЦЛђепГЌЪБЕФЪБКђЃЌФмЙЛЬсЙЉЪ§ОнЛибЙЁЃ
4. ИпЖШПЩХфжУ
Ъ§ОнЖЊЪЇШнДэКЭБЃжЄНЛИЖЃЌЕЭбгГйКЭИпЭЬЭТСПЃЌЖЏЬЌгХЯШМЖЃЌСїПЩвддкдЫааЪБаоИФЁЃ
5. АВШЋад
ЯЕЭГМфЃЌNiFiПЩвдЭЈЙ§ЫЋЯђSSLНјааЪ§ОнМгУмЁЃВЂЧвПЩвддЪаэдкЗЂЫЭгыНгЪеЖЫЪЙгУЙВЯэУмдПЃЌМАЦфЫћЛњжЦЖдЪ§ОнСїНјааМгУмгыНтУмЁЃ
гУЛЇгыЯЕЭГМфЃЌNiFiдЪаэЫЋЯђSSLМјЖЈЃЌВЂЧвЬсЙЉПЩВхШыЪкШЈФЃЪНЃЌвђДЫПЩвдПижЦгУЛЇЕФЕЧТМШЈЯоЃЈР§ШчЃКжЛЖСШЈЯоЁЂЪ§ОнСїЙмРэепЁЂЯЕЭГЙмРэдБЃЉЁЃ
5.2 NiFiЪЕЯжЭГвЛЪЕЪБВЩМЏЪ§ОнЕФЗжВМЪНСїЦНЬЈ
Ъ§ОнЪЕЪБВЩМЏЦїMiNiFiЃК
1.ЪЕЯждіСПЪ§ОнКЭСїЪ§ОнЕФЪЕЪБВЩМЏЃЌЖјВЛЪЧДЋЭГЕФЖЈЪБВЩМЏЃЌЪЕЯжСЫИќЯИжТЛЏЕФЪ§ОнЛёШЁ
2.ПЩжЇГжЖржжЪ§ОндДЃЌЪЪгУадЧП
3.ЪЕЯжЖЫЕНЖЫЕФЪ§ОнВЩМЏ
ЗжВМЪНСїЦНЬЈNiFiЃК
1.ВЩМЏЖјРДЕФЪ§ОнЃЌаЮГЩЪ§ОнСїЃЌВЂЖдЪ§ОндДНјааздЖЏМЧТМЃЌЫїв§ЃЌИњзй
2.ОЋШЗПижЦЪ§ОнСї
3.NIFIЕЅНкЕуЕФадФмЪЧУПУыДІРэАйезМЖЪ§ОнЃЌДюНЈNIFIМЏШКПЩвдЬсЩ§ЕНУПУыДІРэGМЖБ№Ъ§Он
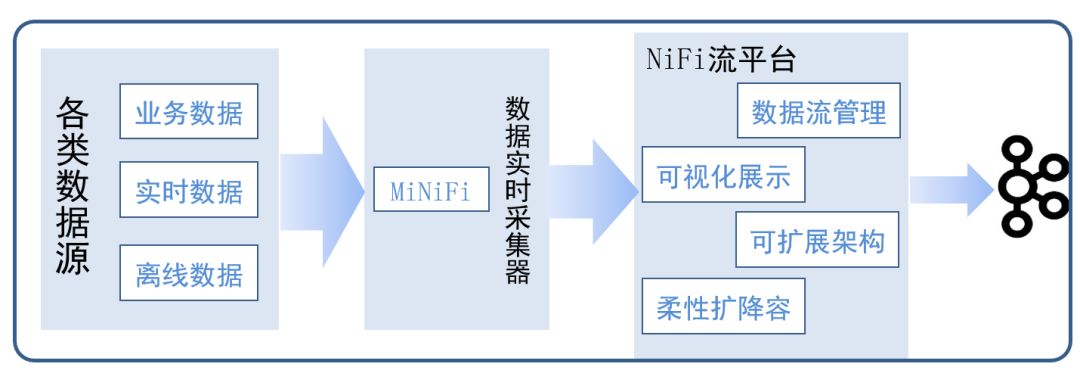
NiFiЗжВМЪНСїЦНЬЈ
|






