| БрМЭЦМі: |
| БОЮФРДздгкМђЪщЃЌБОЮФжївЊНВСЫБШЬиБвБГКѓЕФУмТыбЇдРэЃЌБОжЪЩЯРДЫЕЃЌБШЬиБвКЭУмТыбЇЪЧШкЮЊвЛЬхЕФЃЌБШЬиБвЪЧздДјАВШЋЪєадЕФЪ§зжЛѕБвЁЃ |
|
ЉЁЂађбд
ЛѕБвгЩгкЦфЬьШЛЪєадОіЖЈСЫЦфгыАВШЋВЛПЩЗжИюЕФСЊЯЕЃЌДгзюдчЕФН№ПтЁЂБЃЯеЙёЁЂякОжЕНКѓРДЕФATMЛњЁЂдЫГЎГЕЃЛДгДцелЕНвјааПЈЃЌДгПкСюПЈЕНгХЖмЃЌАВШЋММЪѕЕФНјВНвЛВНВНЭЦЖЏзХН№ШкЗРЛЄСьгђЕФИќаТЁЃ
ДЋЭГЕФЛѕБвЕФАВШЋашЧѓЃЌУмТыбЇЪЧАВШЋЪжЖЮЃЌЪЧДгЁАПЩгУЁБЕНЁААВаФгУЁБЕФЩ§МЖЁЃЖјЖдБШЬиБвРДЫЕЃЌУмТыбЇБОЩэОЭЪЧБШЬиБвЬхЯЕЕФвЛВПЗжЃЌУЛгаУмТыбЇжЇГХЕФБШЬиБвЬхЯЕЛсЭъШЋБРЫњЃЌГЙЕзЁАВЛПЩгУЁБЁЃБОжЪЩЯРДЫЕЃЌБШЬиБвКЭУмТыбЇЪЧШкЮЊвЛЬхЕФЃЌБШЬиБвЪЧздДјАВШЋЪєадЕФЪ§зжЛѕБвЁЃвђДЫЃЌЖдБШЬиБвгУЛЇРДЫЕЃЌСЫНтБШЬиБвБГКѓЕФУмТыбЇРэТлЃЌгажњгкИќКУЕФРэНтБШЬиБвЃЛЭЌЪБЃЌЭЈЙ§УмТыбЇРэТлЕФЗжЯэЃЌвВПЩвдЫГБуИаЪмвЛЯТШЫРржЧЛлЕФЮАДѓЁЃБЯОЙЃЌдкЮвблРяЃЌУмТыбЇРэТлЪЧДѓСПДЯЛлЕФЭЗФдЩѓЩїЫМПМЕФНсЙћЃЌОЋжТЖјгжЧЩУюжЎДІБШБШНдЪЧЁЃ
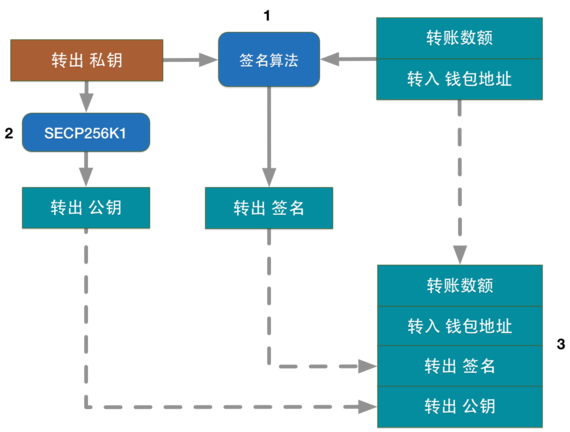
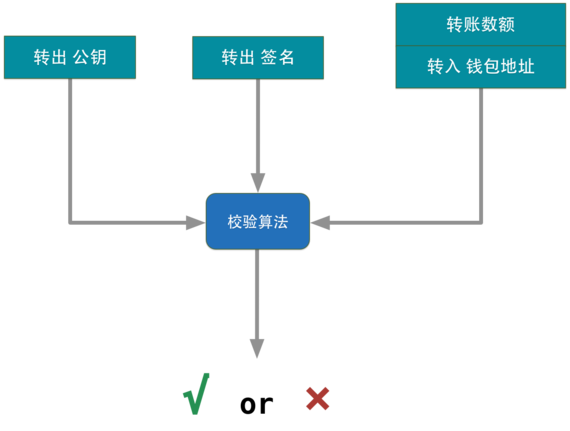
вЛЁЂУмТыбЇРэТл
БШЬиБвБОЩэВЂУЛгаДДдьаТЕФУмТыбЇГЩЙћЃЌЕЋБШЬиБвРћгУЯжгаУмТыбЇГЩЙћЙЙНЈСЫвЛИіСюШЫОЊЦцЕФШЋаТЕФЪ§зжЛѕБвЪРНчЃКШЅжааФЛЏЁЂЧјПщСДЁЂПЩБрГЬЛѕБвЕШГЩЙћМДЪЙХзПЊБШЬиБвБОЩэЖјбдвВЪЧжЕЕУдоЩЭЕФЖДМћЁЃ
ЪзЯШЃЌЯжДњУмТыбЇРэТлЕФЙВЪЖзёбЁАПТПЫЛєЗђддђЁБЃК
ПТПЫЛєЗђддђгЩАТЙХЫЙЬиЁЄПТПЫЛєЗђдк19ЪРМЭЬсГіЃКУмТыЯЕЭГгІИУОЭЫуБЛЫљгаШЫжЊЕРЯЕЭГЕФдЫзїВНжшЃЌШдШЛЪЧАВШЋЕФЁЃ
етИіЪЧЪВУДвтЫМФиЃЌФУдПГзКЭЫјЕФР§згРДЫЕЃЌбажЦКЭЩњВњЫјОпЃЈАќРЈдПГзЃЉЕФЙЄвеЪЧЭъШЋЙЋПЊЕФЃЌЫјОпБЛЙЅЦЦжЛгаСНжжПЩФмЃКвЛЪЧжЄУїЙЄвегаТЉЖДЃЌВЛашвЊФУЕНдзАдПГзвВФмДђПЊЁЃЖўЪЧЧюОЁИїжждПГзПЩФмЃЌдкПЩНгЪмЕФЪБМфРяФмЙЛДгИХТЪвтвхЩЯЪдГіРДЃЈБЉСІЦЦНтЃЉЁЃ
ЫуЗЈЪЧЙЋПЊЕФЃЌЮЈвЛашвЊБЃЛЄЕФЪЧУмдПЃЌетЪЧЮвУЧЯТЮФЬжТлЕФЛљДЁЁЃ
1.ЗЧЖдГЦМгУм
ЯШПДЖдГЦМгУмКмКУРэНтвВЗћКЯжБОѕЃК
ЖдГЦМгУмЃКЖдЭЌвЛЗнУєИаЪ§ОнЃЌМгУмНтУмУмдПЪЧЯрЭЌЕФЁЃ
ЗЧЖдГЦМгУмФиЃК
ЗЧЖдГЦМгУмЫуЗЈашвЊСНИіУмдПЃКЙЋПЊУмдПЃЈpublickeyЃЉКЭЫНгаУмдПЃЈprivatekeyЃЉЁЃЙЋПЊУмдПгыЫНгаУмдПЪЧвЛЖдЃЌШчЙћгУЙЋПЊУмдПЖдЪ§ОнНјааМгУмЃЌжЛгагУЖдгІЕФЫНгаУмдПВХФмНтУмЃЛШчЙћгУЫНгаУмдПЖдЪ§ОнНјааМгУмЃЌФЧУДжЛгагУЖдгІЕФЙЋПЊУмдПВХФмНтУмЁЃвђЮЊМгУмКЭНтУмЪЙгУЕФЪЧСНИіВЛЭЌЕФУмдПЃЌЫљвдетжжЫуЗЈНазїЗЧЖдГЦМгУмЫуЗЈЁЃ ЗЧЖдГЦМгУмЫуЗЈЪЕЯжЛњУмаХЯЂНЛЛЛЕФЛљБОЙ§ГЬЪЧЃКМзЗНЩњГЩвЛЖдУмдПВЂНЋЦфжаЕФвЛАбзїЮЊЙЋгУУмдПЯђЦфЫќЗНЙЋПЊЃЛЕУЕНИУЙЋгУУмдПЕФввЗНЪЙгУИУУмдПЖдЛњУмаХЯЂНјааМгУмКѓдйЗЂЫЭИјМзЗНЃЛМзЗНдйгУздМКБЃДцЕФСэвЛАбзЈгУУмдПЖдМгУмКѓЕФаХЯЂНјааНтУмЁЃ
ЮвУЧгУвЛЗљЭМРДЫЕУїЃК

дкЩЯЮФЕФЗЧЖдГЦМгУмВПЗжЃЌУмдПAОЭЪЧЙЋПЊУмдПЃЈМђГЦЙЋдПЃЉЃЌУмдПBОЭЪЧЫНгаУмдПЃЈМђГЦЫНдПЃЉЁЃЕРРэЖМЖЎЃЌЮЪЬтгавтЫМдкЪВУДЕиЗНФиЃПЗЧЖдГЦМгУмЗНЪНЯТУмдПAКЭУмдПBЪЧдѕУДевЕНЕФвдМАдѕУДЪЕЯжЕФЃПЮвУЧОйР§ЫЕУїЃК
МйЩшЮвУЧЯждквбОевЕНСЫЃЈОпЬхдѕУДевЕФКѓУцЛсНВЃЉЙЋдПЃЈ3233,17ЃЉКЭЫНдП(3233, 2753)ЁЃ
зЂвтЃЌЙЋдПКЭЫНдПВЛвЛЖЈжЛгавЛИіЪ§зжЃЌЪЧПЩвдгаЖрИіЕФЃЌОпЬхМИИіЪ§зжвРРЕгкЗЧЖдГЦМгУмЫуЗЈЁЃ
МйЩшЯждкУїЮФД§МгУмаХЯЂЪЧЪ§зж65ЃЌЮвУЧЪзЯШИјГіМгУмЙЋЪНЃК

НтЪЭвЛЯТЃЌcДњБэМгУмКѓЪ§зжЃЌЃЈnЃЌeЃЉЖдгІЮвУЧЕФЙЋдПЖдЃЌmДњБэУїЮФЃЌЁдЕФвтЫМЪЧЭЌФЃдЫЫуЃЌБШШч60Ёд4ЃЈmod 7ЃЉ,60Жд4ШЁФЃКѓЕШгк4ЁЃКУСЫЮвУЧПЊЪММЦЫуУмЮФЃК

УмЮФЪЧ2790ЃЌШчКЮНтУмФиЃЌНтУмЙЋЪНЃК

dЖдгІЫНдПЕФ2753ЃЌЦфгрзжФИКЭМгУмЙ§ГЬЯрЭЌЃЌгкЪЧНтУмдЫЫуЮЊЃК
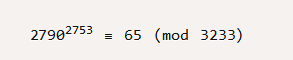
ЮвУЧЕУЕНСЫдРДЕФУїЮФЪ§Он65ЃЌетИіР§згПЩвдПДЕНМгУмКЭНтУмЪ§ОнЪЧВЛЭЌЕФЁЃ
вдЩЯЮвУЧОйР§ЪЙгУЕФЫуЗЈЪЧДѓУћЖІЖІЕФЕиЧђжїСїЗЧЖдГЦМгУмЫуЗЈRSAЃЌгаЙиRSAЕФНщЩмВЮПМШювЛЗхРЯЪІЕФЮФеТЁЃЪЕМЪЩЯЮвЩЯУцгУЕНЕФЪ§зжвВГіздИУЮФЃЌЪЕдкЪЧЪБМфгаЯоЮоЗЈЩюШыНВНтRSAЕФЯИНкДѓМвПЩвдздаабЇЯАЁЃБШЬиБвЬхЯЕЪЕМЪЪЙгУЕФЗЧЖдГЦЫуЗЈЪЧЭждВЧњЯпМгУмЃЈECCЃЉЃЌПЩвдЕНетРяЯъЯИСЫНтЁЃ
ДгЩЯУцЕФР§згЮвУЧжЊЕРТњзуЗЧЖдГЦМгУмЕФУмдПЖдЪЧДцдкЕФЃЌЭЌЪБЮвУЧвВзіСЫМгНтУмГЂЪдЁЃЪЕМЪЩЯЃЌЗЧЖдГЦМгУмЫуЗЈЕФКЫаФвРРЕгкЬиЖЈЕФЪ§бЇФбЬтЃЌБШШчЩЯЮФЕФRSAвРРЕгкДѓЪ§ЗжНтФбЬтЃЌШчЙћИУФбЬтБЛЦЦНтСЫЃЌЫуЗЈБОЩэвВОЭБЛЙЅЦЦСЫЁЃСэЭтЃЌЮвЖСбаЕФЪБКђЛЙзіСЫRSAОиеѓРЉеЙЃЌНЋЦфЫуЗЈЛљДЁДгЫиЪ§РЉеЙЕНОиеѓЃЌгааЫШЄЕФПЩвдМЬајНЛСїЁЃ
ЗЧЖдГЦЫуЗЈЭЈЙ§ЙЋЫНт_ЗжБ№МгНтУмЗНЪНИјаХЯЂНЛЛЛДјРДСЫОоДѓЕФБфЛЏЃЌОпЬхБэЯждкЃК
1ЃЉдкВЛАВШЋЕФЛЗОГжаДЋЕнУєИааХЯЂГЩЮЊПЩФмЁЃДгЩЯЮФПЩвджЊЕРЃЌЙЋдПЪЧЭъШЋЙЋПЊШЮвтДЋВЅЕФЃЌЭЈЙ§ЙЋдПЪЧЮоЗЈЃЈЛђМЋЦфРЇФбЃЉЭЦЫуГіЫНдПЕФЃЌЫНдПЪЧВЛЙЋПЊВЛЗЂЫЭВЛДЋВЅЕФЃЌНіНіЯћЯЂНгЪеЗНжЊЕРОЭПЩвдЃЌЦфЫћШЮКЮШЫЖМВЛашвЊжЊЕРЁЃ
2ЃЉЖрЗНЭЈаХЫљашУмдПЪ§СПМБОчМѕЩйЃЌУмдПЮЌЛЄЙЄзїБфЕУвьГЃМђЛЏЁЃБШШчNИіЛЅВЛаХШЮЧвЛЅгаЭЈаХашЧѓЕФШЫЃЌШчЙћЪЙгУЖдГЦМгУмЫуЗЈЃЌдђашвЊNЃЁ/2ИіУмдПЃЌШчЙћЪЙгУЗЧЖдГЦМгУмНіашвЊNИіМДПЩЃЈУПИіШЫжЛашвЊЮЌЛЄздМКЕФЙЋЫНт_ЖдЃЌЮоТлКЭЖрЩйШЫЭЈаХЃЉЁЃ
3ЃЉЛљгкЗЧЖдГЦМгУмЗЂеЙЦ№РДЕФЪ§зжЧЉУћММЪѕЃЈМћЯТЮФЯъЪіЃЉДгЪ§бЇвтвхЩЯНтОіСЫзджЄЩэЗнЮЪЬтЃЌЪЙЕУаХЯЂНгЪеепПЩвдШЗШЯЯћЯЂЗЂЫЭЗНЩэЗнаХЯЂЧвВЛПЩИќИФЁЃ
4ЃЉУмТыбЇЮЪЬтЖдЪ§бЇЮЪЬтЕФвРРЕПеЧАЬсИпЁЃжЎЧАПДЫЦЮогУЕФЩѕжСЙХРЯЕФЪ§бЇФбЬтБШШчЪ§ТлЁЂРыЩЂЖдЪ§ЕШдкДЫДѓЗХвьВЪЃЌЦФгааЉаІРДРЯЪІдкЁЖАбЪБМфЕБзіХѓгбЁЗРяУцБэДяЕФ"ММВЛбЙЩэ"ЕФЯжЪЕгГЩфЁЃ
2.ЩЂСаЃЈЙўЯЃЃЉЫуЗЈ
ЮвУЧЪЙгУИїжждЦХЬЁЂащФтДцДЂПеМфгІгУЕФЪБКђвЛЖЈЖМгаРрЫЦЕФЬхЛсЃЌЩЯДЋвЛИіУїУїКмДѓЕФЮФМўЃЌПЩЪЧЫйЖШШДЗЧГЃПьЃЌЖјгаЪБЩЯДЋвЛИіаЁЕУЖрЕФЮФМўШДЫЦКѕНјЖШЬѕвЊзпКмОУЁЃетжжЯжЯѓЕФПЩФмЕФвЛИіУиУмОЭЪЧНгЯТРДвЊНВЕФЩЂСаЫуЗЈЃЈвВНаЪ§ОнеЊвЊЛђепЙўЯЃЫуЗЈЃЌЙўЯЃЪЧHASHЕФвєвыЃЉЁЃ
ЪЕМЪЩЯЃЌдЦХЬРрВњЦЗЖдЯрЭЌЮФМўжЛЛсБЃСєвЛЗнецЪЕЕФДцДЂЃЌЖрИіЪЙгУЯрЭЌЮФМўЕФгУЛЇжЛашЁАЫїв§ЁБЕНИУДцДЂЮЛжУМДПЩЁЃХаЖЯСНИіЮФМўЪЧЗёЯрЭЌгУЕНЕФОЭЪЧЩЂСаЫуЗЈЃК
ЩЂСаЫуЗЈНЋШЮвтГЄЖШЕФЖўНјжЦжЕгГЩфЮЊНЯЖЬЕФЙЬЖЈГЄЖШЕФЖўНјжЦжЕЃЌетИіаЁЕФЖўНјжЦжЕГЦЮЊЙўЯЃжЕЁЃЙўЯЃжЕЪЧвЛЖЮЪ§ОнЮЈвЛЧвМЋЦфНєДеЕФЪ§жЕБэЪОаЮЪНЁЃШчЙћЩЂСавЛЖЮУїЮФЖјЧвФФХТжЛИќИФИУЖЮТфЕФвЛИізжФИЃЌЫцКѓЕФЩЂСажЕЖМНЋВњЩњВЛЭЌЕФжЕЁЃвЊевЕНЩЂСаЮЊЭЌвЛИіжЕЕФСНИіВЛЭЌЕФЪфШыЃЌдкМЦЫуЩЯЪЧВЛПЩФмЕФЃЌЫљвдЪ§ОнЕФЩЂСажЕПЩвдМьбщЪ§ОнЕФЭъећадЁЃвЛАугУгкПьЫйВщевКЭМгУмЫуЗЈЁЃ
БОжЪЩЯЃЌЩЂСаЫуЗЈЕФФПЕФВЛЪЧЮЊСЫЁАМгУмЁБЖјЪЧЮЊСЫГщШЁЁАЪ§ОнЬиеїЁБЃЌФувВПЩвдАбИјЖЈЪ§ОнЕФЩЂСажЕРэНтЮЊИУЪ§ОнЕФЁАжИЮЦаХЯЂЁБЃЌвЛИіПЩППЕФЩЂСаЫуЗЈFашвЊТњзуЃК
1. ЖдгкИјЖЈЕФЪ§ОнMЃЌКмШнвзЫуГіЙўЯЃжЕX=FЃЈMЃЉЃЛ
2. ИљОнXЮоЗЈЫуГіMЃЛ
3. КмФбевЕНMКЭNСюFЃЈMЃЉ=FЃЈNЃЉЁЃ
ЮвРДНтЪЭвЛЯТЃК
ЖдгкЕквЛЕуЃЌЭЈГЃЙўЯЃжЕЕФГЄЖШЪЧЙЬЖЈЕФЃЈЮЊЪВУДЙЬЖЈЃЌвЛИіКмживЊЕФдвђЪЧБугкЙЙдьЭЈаХАќНсЙЙЃЌЩЂСаЕФгІгУГЁОАЭЈГЃЪЧВЛПЩППЕФЭјТчДЋЪфЖјЗЧБОЕиДцДЂЃЉЃЌБШШчБШЬиБвЪЙгУЕФSHA256еЊвЊЫуЗЈЖдШЮвтГЄЖШЕФЪфШыИјГіЕФЪЧ256bitЕФЪфГіЁЃ
ЖдгкЕкЖўЕуЃЌЩЂСаЫуЗЈЪЧВЛПЩФцЕФЃЌЩѕжСЪЧвдЖЊЪЇВПЗждЪМаХЯЂзїЮЊДњМлЃЌвђДЫЮвИіШЫШЯЮЊЩЂСаМгУмЫуЗЈЕФЬсЗЈЪЧгаЮЪЬтЕФЃЌМгУмвтЮЖзХПЩвдНтУмЃЌЕЅДПЕФШХТвГЦЮЊМгУмВЂВЛКЯЪЪЁЃвВаэЫљЮНЕФЩЂСаМгУмЪЧКЭЩЂСааЃбщЖдгІЕФЃЌвВОЭЫЕСНжжгІгУЕФГЁОАВЛЭЌЃЌЩЂСаМгУмЕФКЫаФЪЧШХТвЃЌЩЂСааЃбщЕФКЫаФЪЧаЃбщЁЃ
ЖдгкЕкШ§ЕуЃЌетЪЧЩЂСаКЏЪ§еце§ЕФЬєеНЁЃМйЩшевЕНСЫвЛЖдЃЈM,NЃЉЪЙЕУЕШЪНГЩСЂОЭГЩЮЊИУЫуЗЈевЕНСЫвЛДЮХізВЃЌЖдЩЂСаЫуЗЈНЁзГадЕФЗжЮіОЭЪЧЗжЮіЦфПЙЧПХізВФмСІЁЃПЩвдРэНтЕФЪЧЃЌХізВЕФГіЯжНЋЪЙЕУЩЂСаЫуЗЈБОЩэДцдкЕФвтвхЯћЪЇСЫЃЌвђЮЊЗЂЯжСЫВЛЭЌЕФШЫгЕгаЯрЭЌЕФжИЮЦЁЃ
БШЬиБвЪЙгУЕФЩЂСаЫуЗЈЪЧSHA256ЃЌЫћЪЧАВШЋЩЂСаЫуЗЈSHAЃЈSecure Hash AlgorithmЃЉЯЕСаЫуЗЈЕФвЛжжЃЈСэЭтЛЙгаSHA-1ЁЂSHA-224ЁЂSHA-384 КЭ SHA-512 ЕШБфЬхЃЉЃЌSHAЪЧУРЙњЙњМвАВШЋОж ЃЈNSAЃЉ ЩшМЦЃЌУРЙњЙњМвБъзМгыММЪѕбаОПдКЃЈNISTЃЉ ЗЂВМЕФЃЌжївЊЪЪгУгкЪ§зжЧЉУћБъзМЃЈDigitalSignature Standard DSSЃЉРяУцЖЈвхЕФЪ§зжЧЉУћЫуЗЈЃЈDigital Signature Algorithm DSAЃЉЁЃПЩвдЕНетРяЯъЯИСЫНтЁЃ
зюКѓЃЌЮввЊНтЪЭвЛЯТЖўДЮЩЂСаЮЪЬтЃЌПДЙ§БШЬиБвавщЕФЖСепПЩФмзЂвтЕНЙЄзїСПжЄУїКЭУмдПБрТыЙ§ГЬжаЖрДЮЪЙгУСЫЖўДЮЙўЯЃЃЌШчSHA256ЃЈSHA256ЃЈkЃЉЃЉЛђепRIPEMD160(SHA256(K))ЃЌетжжЗНЪНДјРДЕФКУДІЪЧдіМгСЫЙЄзїСПЛђепдкВЛЧхГўавщЕФЧщПіЯТдіМгЦЦНтФбЖШЃЌДгАВШЋадНЧЖШВЂУЛгаЯджјдіМгЃЈШчЙћЪЧБЉСІЧюОйЦЦНтЕФЛАЃЌашвЊдіМгвЛБЖЦЦНтЪБМфЃЉЁЃеце§ЕФЖўДЮЙўЯЃЪЧЛљгкМгбЮЕФЙўЯЃЃЌЪВУДвтЫМФиЃПЖдгкЬиЖЈЕФД§ЩЂСаЪ§ОнКЭЬиЖЈЕФЩЂСаЫуЗЈЃЌПЩвджЊЕРЩЂСажЕЪЧвЛЖЈЕФЃЌетжжЧщПіЯТШчЙћгУЩЂСаБЃЛЄУєИаЪ§ОнЃЈРэТлЩЯЪЧВЛКЯЪЪЕФЃЌЕЋЪЧЙњФкЭтДцдкДѓСПЕФЪЙгУЩЂСаРДБЃЛЄгУЛЇУмТыЕФЧщПіЃЉЃЌФЧОЭКмШнвзЪЙгУзжЕфЙЅЛїЗДЯђЭЦЫуЃЌБШШчЮвМЦЫу123456ЕФSHA256жЕОЭПЩвдЗДЭЦСЫЃЌНтОіАьЗЈОЭЪЧЯШзівЛДЮЩЂСаЃЌдйМгвЛДЮЫцЛњЪ§ОнвдКѓдйзівЛДЮЩЂСаЃЌЫцЛњЪ§ОнОЭЪЧЫљЮНЕФбЮЁЃ
3.Ъ§зжЧЉУћ
гаСЫЗЧЖдГЦМгУмКЭЩЂСаЫуЗЈЕФзМБИЃЌЮвУЧЯждкПЩвдНјвЛВНШЯЪЖЪ§зжЧЉУћСЫЁЃЙЫУћЫМвхЃЌЪ§зжЧЉУћОЭЪЧдкЪ§зжЪРНчРягУгкЩэЗнБцЪЖЕФвЛжжНтОіЗНАИЁЃВЛашвЊЦяЗьеТЃЌЦяЗьЧЉУћЃЌвВВЛашвЊБЪМЃзЈМвЃЌЪ§зжЧЉУћМДОпгаВЛПЩЕжРЕадЁЃ
МђЕЅЕиЫЕ,ЫљЮНЪ§зжЧЉУћОЭЪЧИНМгдкЪ§ОнЕЅдЊЩЯЕФвЛаЉЪ§Он,ЛђЪЧЖдЪ§ОнЕЅдЊЫљзїЕФУмТыБфЛЛЁЃетжжЪ§ОнЛђБфЛЛдЪаэЪ§ОнЕЅдЊЕФНгЪеепгУвдШЗШЯЪ§ОнЕЅдЊЕФРДдДКЭЪ§ОнЕЅдЊЕФЭъећадВЂБЃЛЄЪ§Он,ЗРжЙБЛШЫ(Р§ШчНгЪееп)НјааЮБдьЁЃЫќЪЧЖдЕчзгаЮЪНЕФЯћЯЂНјааЧЉУћЕФвЛжжЗНЗЈ,вЛИіЧЉУћЯћЯЂФмдквЛИіЭЈаХЭјТчжаДЋЪфЁЃЛљгкЙЋдПУмТыЬхжЦКЭЫНдПУмТыЬхжЦЖМПЩвдЛёЕУЪ§зжЧЉУћ,жївЊЪЧЛљгкЙЋдПУмТыЬхжЦЕФЪ§зжЧЉУћЁЃ
ЩЯЪіНтЪЭЩдЯдбЇЪѕЃЌЮвУЧЛЛжжЫЕЗЈБэЪіЃКЫљЮНЪ§зжЧЉУћОЭЪЧЧЉУћШЫгУздМКЕФЫНдПЖдД§ЧЉУћЪ§ОнЕФеЊвЊНјааМгУмЕУЕНЕФжЕОЭЪЧЧЉУћжЕЁЃЧЉУћепЗЂЫЭЪ§ОнЧЉУћЪБашвЊАбД§ЧЉУћЪ§ОнКЭЧЉУћжЕвЛЦ№ЗЂЫЭИјЖдЗНЁЃ
зЂвтЃЌЧЉУћЖдЯѓВЂЗЧД§ЧЉУћЪ§ОнЖјЪЧД§ЧЉУћЪ§ОнЕФеЊвЊЃЌЮЊЪВУДФиЃПвђЮЊЗЧЖдГЦМгУмЕФЫйЖШЭЈГЃЖМБШНЯТ§ЃЌжБНгЖддЪМЪ§ОнЫНдПМгУмЪЧКмТ§ЕФЖјЧввВУЛгаБивЊЁЃ
ШчКЮбщжЄЧЉУћФиЃПНгЪеЗНЪзЯШЪЙгУЧЉУћепЕФЙЋдПЖдЧЉУћжЕНтУмМДПЩЕУЕНеЊвЊжЕЃЌШЛКѓЪЙгУдМЖЈЕФЫуЗЈЖдД§ЧЉУћЪ§ОнНјааЩЂСадЫЫуКѓКЭНтУмЕУЕНЕФеЊвЊжЕНјааБШНЯМДПЩбщжЄЁЃ
етРягавЛИіЭМаЮЛЏЕФЪ§зжЧЉУћЙ§ГЬгажњгкРэНтЪ§зжЧЉУћЕФећИіЙ§ГЬЁЃ
ДгвдЩЯЪ§зжЧЉУћЕФећИіЙ§ГЬУшЪіРДПДЃЌЪ§зжЧЉУћЕФКЫаФдкгкЧЉУћЃЌдкгкжЄУїетЗнЪ§ОнЪЧЧЉУћепЗЂГіЕФЁЂВЛПЩЕжРЕЕФЁЃД§ЧЉУћЪ§ОнБОЩэЕФБЃУмВЛЪЧЪ§зжЧЉУћЗНАИвЊПМТЧЕФЮЪЬтЁЃ
4.ПЩЖСадБрТы
бЯИёРДНВЃЌБрТыВПЗжВЛЪЧУмТыбЇРэТлЕФКЫаФФкШнЃЌВЛЙ§ЮЊСЫБугкЯТЮФФмЫЕЧхГўЃЌЮвОЭАбПЩЖСадБрТыЗХЕНетРяМђЕЅЫЕЫЕЁЃ
ПЩЖСадБрТыКмКУРэНтЃЌОЭЪЧВЛИФБфаХЯЂФкШнНіИФБфФкШнЕФБэЯжаЮЪНЃЌВПЗжБрТыЗНЪНЛЙМгШыСЫШнДэаЃбщЙІФмЃЌЭЈГЃЪЧЮЊСЫБЃжЄИќКУЕФЭЈаХДЋЪфЁЃ
БШШчЖўНјжЦЕФ1111ЖдгІЪЎНјжЦЕФ15етОЭЪЧвЛДЮБрТыЁЃЪЧгУЪЎНјжЦЖдЖўНјжЦНјааБрТыЃЌЯждкгаИіЮЪЬтЃЌЮвФУЕНвЛИіБрТыКѓЕФЪ§ОнЃЌШчКЮжЊЕРИУЪ§ОнЪЧЪЙгУСЫФФжжаЮЪНЕФБрТыФиЃПетИіЪЧЭЈЙ§ЧАзКРДЪЕЯжЕФЃЌР§ШчЃЌБШЬиБвЕижЗЕФЧАзКЪЧ0ЃЈЪЎСљНјжЦЪЧ0x00ЃЉЃЌЖјЖдЫНдПБрТыЪБЧАзКЪЧ128ЃЈЪЎСљНјжЦЪЧ0x80ЃЉЁЃ
ЖўЁЂБШЬиБвЪЕМљ
ДгЯждкПЊЪМЃЌЮвУЧПЊЪМецЕЖЪЕЧЙСЫЃЌЯШПДПДБШЬиБвЕФБрТыЪРНчЁЃ
1.Base58КЭBase58CheckБрТы
етРяЧыдЪаэЮвФУРДжївхЃЌЮвОѕЕУЭѕУыЕШЖрЮЛРЯЪІЗвыЕФAndreas M. AntonopoulosЫљжјЁЖОЋЭЈБШЬиБвЁЗЖдетИіЮЪЬтвбОНтЪЭЕФКмЧхГўСЫЃЌИќЯъЯИЕФУшЪіЛЙПЩвдПДПДетРяЁЃ
ЮЊСЫИќМђНрЗНБуЕиБэЪОГЄДЎЕФЪ§зжЃЌаэЖрМЦЫуЛњЯЕЭГЛсЪЙгУвЛжжвдЪ§зжКЭзжФИзщГЩЕФДѓгкЪЎНјжЦЕФБэЪОЗЈЁЃР§ШчЃЌДЋЭГЕФЪЎНјжЦМЦЪ§ЯЕЭГЪЙгУ0-9ЪЎИіЪ§зжЃЌЖјЪЎСљНјжЦЯЕЭГЪЙгУСЫЖюЭтЕФ A-F СљИізжФИЁЃвЛИіЭЌбљЕФЪ§зжЃЌЫќЕФЪЎСљНјжЦБэЪООЭЛсБШЪЎНјжЦБэЪОИќЖЬЁЃИќНјвЛВНЃЌBase64ЪЙгУСЫ26ИіаЁаДзжФИЁЂ26ИіДѓаДзжФИЁЂ10ИіЪ§зжвдМАСНИіЗћКХЃЈР§ШчЁА+ЁБКЭЁА/ЁБЃЉЃЌгУгкдкЕчзггЪМўетбљЕФЛљгкЮФБОЕФУННщжаДЋЪфЖўНјжЦЪ§ОнЁЃBase64ЭЈГЃгУгкБрТыгЪМўжаЕФИНМўЁЃBase58ЪЧвЛжжЛљгкЮФБОЕФЖўНјжЦБрТыИёЪНЃЌгУдкБШЬиБвКЭЦфЫќЕФМгУмЛѕБвжаЁЃетжжБрТыИёЪНВЛНіЪЕЯжСЫЪ§ОнбЙЫѕЃЌБЃГжСЫвзЖСадЃЌЛЙОпгаДэЮѓеяЖЯЙІФмЁЃBase58ЪЧBase64БрТыИёЪНЕФзгМЏЃЌЭЌбљЪЙгУДѓаЁаДзжФИКЭ10ИіЪ§зжЃЌЕЋЩсЦњСЫвЛаЉШнвзДэЖСКЭдкЬиЖЈзжЬхжаШнвзЛьЯ§ЕФзжЗћЁЃОпЬхЕиЃЌBase58ВЛКЌBase64жаЕФ0ЃЈЪ§зж0ЃЉЁЂOЃЈДѓаДзжФИoЃЉЁЂlЃЈаЁаДзжФИLЃЉЁЂIЃЈДѓаДзжФИiЃЉЃЌвдМАЁА+ЁБКЭЁА/ЁБСНИізжЗћЁЃМђЖјбджЎЃЌBase58ОЭЪЧгЩВЛАќРЈЃЈ0ЃЌOЃЌlЃЌIЃЉЕФДѓаЁаДзжФИКЭЪ§зжзщГЩЁЃ
ашвЊзЂвтЕФЪЧЃЌBase58БрТыЪЧВЛКЌаЃбщаХЯЂЕФЃЌBase58CheckЪЧвЛжжГЃгУдкБШЬиБвжаЕФBase58БрТыИёЪНЃЌдіМгСЫДэЮѓаЃбщТыРДМьВщЪ§ОндкзЊТМжаГіЯжЕФДэЮѓЁЃаЃбщТыГЄ4ИізжНкЃЌЬэМгЕНашвЊБрТыЕФЪ§ОнжЎКѓЁЃ
ЮЊСЫЪЙгУBase58CheckБрТыИёЪНЖдЪ§ОнЃЈЪ§зжЃЉНјааБрТыЃЌЪзЯШЮвУЧвЊЖдЪ§ОнЬэМгвЛИіГЦзїЁААцБОзжНкЁБЕФЧАзКЃЌетИіЧАзКгУРДУїШЗашвЊБрТыЕФЪ§ОнЕФРраЭЁЃР§ШчЃЌБШЬиБвЕижЗЕФЧАзКЪЧ0ЃЈЪЎСљНјжЦЪЧ0x00ЃЉЃЌЖјЖдЫНдПБрТыЪБЧАзКЪЧ128ЃЈЪЎСљНјжЦЪЧ0x80ЃЉЁЃ Бэ4-1ЛсСаГівЛаЉГЃМћАцБОЕФЧАзКЁЃ
НгЯТРДЃЌЮвУЧМЦЫуЁАЫЋЙўЯЃЁБаЃбщТыЃЌвтЮЖзХвЊЖджЎЧАЕФНсЙћЃЈЧАзККЭЪ§ОнЃЉдЫааСНДЮSHA256ЙўЯЃЫуЗЈЃК
checksum = SHA256(SHA256(prefix+data))
дкВњЩњЕФГЄ32ИізжНкЕФЙўЯЃжЕЃЈСНДЮЙўЯЃдЫЫуЃЉжаЃЌЮвУЧжЛШЁЧА4ИізжНкЁЃет4ИізжНкОЭзїЮЊаЃбщТыЁЃаЃбщТыЛсЬэМгЕНЪ§ОнжЎКѓЁЃНсЙћгЩШ§ВПЗжзщГЩЃКЧАзКЁЂЪ§ОнКЭаЃбщТыЁЃ
2.УмдПЁЂЕижЗгыЧЎАќ
ЯШЫЕНсТлЃК
1.УмдПЭЈГЃжИЕФЪЧБЃЛЄБШЬиБвзЪВњЕФЖдгІгкЫљгаШЈгУЛЇЕФЫНдПЃЌИіБ№ЪБКђвВЛсФЃК§ЕФЭГГЦЫНдПКЭЙЋдПЮЊУмдПЃЌетРяЮвУЧвдЯСвхЕФЫНдПНтЪЭЮЊзМЁЃ
2.ЕижЗДѓВПЗжЧщПіЯТЪЧжИЖдЙЋдПЕФЗтзАЃЈИіБ№ЪБКђГ§СЫЙЋдПЛЙгаНХБОЃЉЁЃ
3.ЧЎАќЪЧЫНдПЕФШнЦїЃЌЭЈГЃЭЈЙ§гаађЮФМўЛђепМђЕЅЕФЪ§ОнПтЪЕЯжЁЃБШЬиБвЧЎАќАќКЌЫНдПКЭЙЋдПЪ§ОнЃЌОЁЙмЙЋдПЪ§ОнРэТлЪЧЪЧВЛашвЊДцДЂЕФЁЃ
2.1ЫНдПБЃЛЄ
ЫНдПБиаыБЃУмЁЃЫНдПЕФЛњУмадашЧѓЪТЪЕЧщПіЪЧЃЌдкЪЕМљжаЯрЕБФбвдЪЕЯжЃЌвђЮЊИУашЧѓгыЭЌбљживЊЕФАВШЋЖдЯѓПЩгУадЯрЛЅУЌЖмЁЃЕБФуашвЊЮЊСЫБмУтЫНдПЖЊЪЇЖјДцДЂБИЗнЪБЃЌЛсЗЂЯжЮЌЛЄЫНдПЫНУмадЪЧвЛМўЯрЕБРЇФбЕФЪТЧщЁЃЭЈЙ§УмТыМгУмФкгаЫНдПЕФЧЎАќПЩФмвЊАВШЋвЛЕуЃЌЕЋФЧИіЧЎАќвВашвЊБИЗнЁЃгаЪБЃЌР§ШчгУЛЇвђЮЊвЊЩ§МЖЛђжизАЧЎАќШэМўЃЌЖјашвЊАбУмдПДгвЛИіЧЎАќзЊвЦЕНСэвЛИіЁЃЫНдПБИЗнвВПЩФмашвЊДцДЂдкжНеХЩЯЃЈВЮМћЁА4.5.4 жНЧЎАќЁБвЛНкЃЉЛђепЭтВПДцДЂНщжЪРяЃЌБШШчUХЬЁЃЕЋШчЙћвЛЕЉБИЗнЮФМўЪЇЧдЛђЖЊЪЇФиЃПетаЉУЌЖмЕФАВШЋФПБъЭЦНјСЫБуаЏЁЂЗНБуЁЂПЩвдБЛжкЖрВЛЭЌЧЎАќКЭБШЬиБвПЭЛЇЖЫРэНтЕФМгУмЫНдПБъзМBIP0038ЕФГіЬЈЁЃ
BIP0038ЬсГіСЫвЛИіЭЈгУБъзМЃЌЪЙгУвЛИіПкСюМгУмЫНдПВЂЪЙгУBase58CheckЖдМгУмЕФЫНдПНјааБрТыЃЌетбљМгУмЕФЫНдПОЭПЩвдАВШЋЕиБЃДцдкБИЗнНщжЪРяЃЌАВШЋЕидкЧЎАќМфДЋЪфЃЌБЃГжУмдПдкШЮКЮПЩФмБЛБЉТЖЧщПіЯТЕФАВШЋадЁЃетИіМгУмБъзМЪЙгУСЫAESЃЌетИіБъзМгЩNISTНЈСЂЃЌВЂЙуЗКгІгУгкЩЬвЕКЭОќЪТгІгУЕФЪ§ОнМгУмЁЃ
2.2ЙЋдПгыЕижЗ
ЮвУЧжЊЕРБШЬиБвавщЕФЧјПщСДЪЕМЪЩЯЪЧЖдНЛвзЕФЮЌЛЄЖјВЛЪЧЖдеЫЛЇЕФЮЌЛЄЃЌНЛвзЪ§ОнБОЩэВЂВЛашвЊЫНдПЃЌвђДЫЖдЙЋдПЕФЗтзАвВОЭЪЧЕижЗОЭЯдЕУИёЭтживЊЃЌашвЊМцЙЫАВШЋЃЌаЇТЪКЭРЉеЙЁЃ
ДгЙЋдПЕНЕижЗОРњСЫШчЯТЙ§ГЬЃК
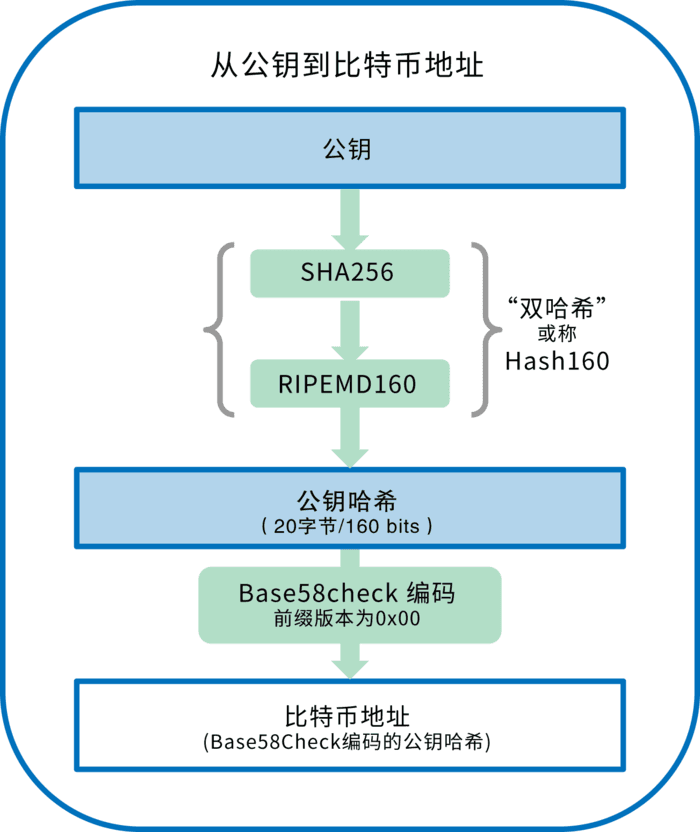
A = RIPEMD160(SHA256(K))
ЙЋЪНжаЃЌKЪЧЙЋдПЃЌAЪЧЩњГЩЕФБШЬиБвЕижЗЁЃБШЬиБвЕижЗгыЙЋдПВЛЭЌЁЃБШЬиБвЕижЗЪЧгЩЙЋдПОЙ§ЕЅЯђЕФЙўЯЃКЏЪ§ЩњГЩЕФ
вдЙЋдП K ЮЊЪфШыЃЌМЦЫуЦфSHA256ЙўЯЃжЕЃЌВЂвдДЫНсЙћМЦЫуRIPEMD160 ЙўЯЃжЕЃЌЕУЕНвЛИіГЄЖШЮЊ160БШЬиЃЈ20зжНкЃЉЕФЪ§зжКѓНјааBase58CheckБрТыМДПЩЕУЕНБШЬиБвЕижЗЁЃДгБрТыЪ§ОнНсЙЙЕФЪгНЧПДЃЌЪЧЯТЭМЃК
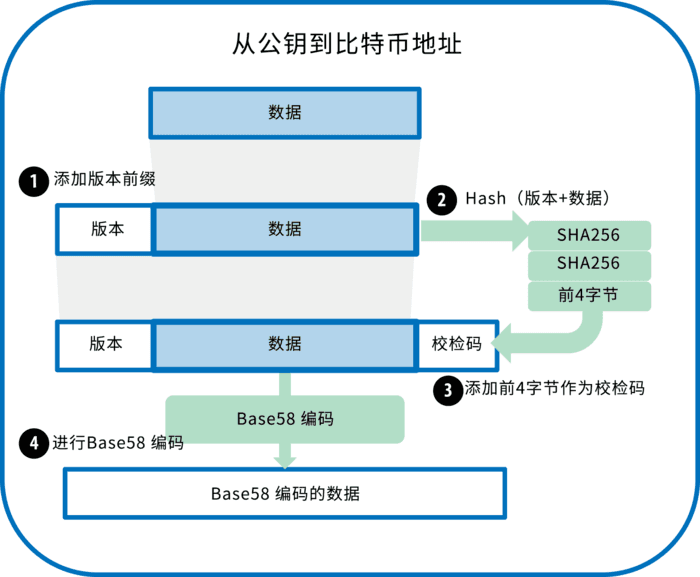
ашвЊзЂвтЕФЪЧЃЌДгЕижЗвбОЮоЗЈЗДЭЦЙЋдПаХЯЂЃЌвђДЫЃЌашвЊНЋЫНдПвдМАЖдгІЕФЙЋдПЁЂЕижЗвЛЦ№ДцДЂЁЃ
2.3БШЬиБвЧЎАќ
БШЬиБвЧЎАќвЊНтОіЕФКЫаФЮЪЬтЪЧЫНдПЙмРэЃЌдчЦкЕФЗНЪНЪЧЫцЛњЩњГЩЫНдПГиВЂвЛДЮвЛУмЃЌетЕБШЛЪЧАВШЋадКмИпЕФЗНАИЁЃЕЋЪЧЖдДцДЂЃЌЕМШыЕМГіБИЗнДјРДСЫМЋДѓЕФЬєеНЃЌБЯОЙЫНдПЖЊСЫЫвВУЛгаАьЗЈЁЃИФНјЕФЫНдПЙмРэАьЗЈНЋЫНдПСДЪНЙмРэЦ№РДСЫЃЌМћЯТЭМЃК
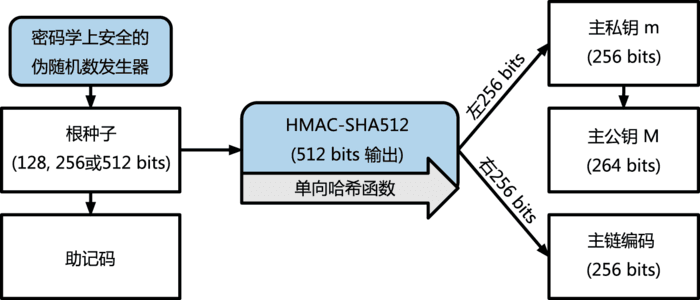
ЩњГЩСДЪННсЙЙЕФЙ§ГЬШчЯТЃК
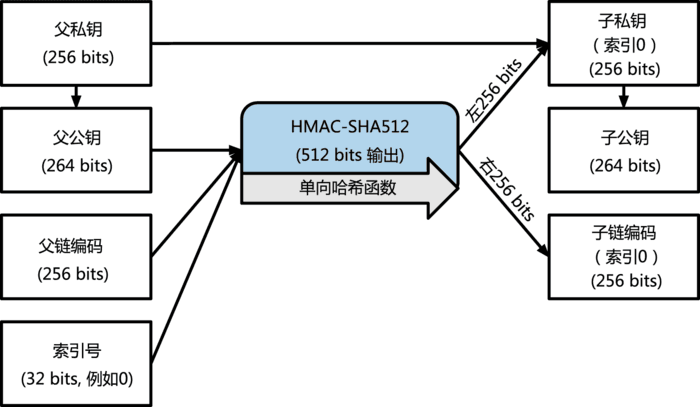
3.ЧјПщСД
ЧјПщСДПЩвдРэНтЮЊЪ§ОнНсЙЙИХФюжаЕФСДБэЃЈКЭЯпадБэТдгаВЛЭЌЕФЪЧПЩФмгаЗжВцЃЉЃЌетРяЮвУЧжЛашвЊДѓжТСЫНтЧјПщЪ§ОнНсЙЙвдМАУПвЛПщДѓжТЕФвтЫМЃЌетаЉНсЙЙаХЯЂНЋЛсдкНЛвзКЭЭкПѓВПЗжНјааЯъЯИНВНтЁЃ
ЧјПщСДПЩвдРэНтЮЊдЫаадкШЅжааФЛЏЭјТчжаЕФЃЌЫљгаНкЕуЃЈЭкПѓНкЕуЃЉЙВЭЌЮЌЛЄЕФНЛвзЪ§ОнПтЃЌетИіЪ§ОнПтЪЧвдСДЪНЕФаЮЪНзщжЏНЛвзЪ§ОнЕФЃЌУПвЛИіСДБэЕФПщБЛГЦЮЊЧјПщЛђепblockЁЃ
3.1 ЧјПщНсЙЙ
ЧјПщЪЧвЛжжБЛАќКЌдкЙЋПЊеЫВОЃЈЧјПщСДЃЉРяЕФОлКЯСЫНЛвзаХЯЂЕФШнЦїЪ§ОнНсЙЙЁЃЫќгЩвЛИіАќКЌдЊЪ§ОнЕФЧјПщЭЗКЭНєИњЦфКѓЕФЙЙГЩЧјПщжїЬхЕФвЛГЄДЎНЛвззщГЩЁЃ

ЩЯБэжаЕФ1-9гІИУЪЧ1-9ИізжНкЃЌЗёдђЛсв§Ц№ЦчвхЁЃ
3.2 ЧјПщЭЗ
ЧјПщЭЗгЩШ§зщЧјПщдЊЪ§ОнзщГЩЁЃЪзЯШЪЧвЛзщв§гУИИЧјПщЙўЯЃжЕЕФЪ§ОнЃЌетзщдЊЪ§ОнгУгкНЋИУЧјПщгыЧјПщСДжаЧАвЛЧјПщЯрСЌНгЁЃЕкЖўзщдЊЪ§ОнЃЌМДФбЖШЁЂЪБМфДСКЭnonceЃЌгыЭкПѓОКељЯрЙиЁЃЕкШ§зщдЊЪ§ОнЪЧmerkleЪїИљЃЈвЛжжгУРДгааЇЕизмНсЧјПщжаЫљгаНЛвзЕФЪ§ОнНсЙЙЃЉЁЃ
NonceЁЂФбЖШФПБъКЭЪБМфДСЛсгУгкЭкПѓЙ§ГЬЃЌMerkleИљгУРДЫїв§КЭзщжЏИУЧјПщЫљгаЕФНЛвзаХЯЂЃЌЦфНсЙЙМћЯТвЛНкЁЃ
вђДЫЧјПщЭЗжЎМфЕФСЌНгДѓдМЯёЯТЭМЫљЪОЃК

ДгЩЯЭМЮвУЧПЩвджЊЕРШчКЮБмУтЫЋжижЇИЖЮЪЬтЃЌвђЮЊЪеПюШЫгаАьЗЈЖдетБЪжЇИЖжЎЧАЕФЫљгаЯћЯЂНјааМьЫїжБжСзЗЫнЕНдЪМЕФЭкПѓЧјПщЃЌЪЕМЪЩЯБШЬиБвЪРНчРяЕФУПвЛУЖБШЬиБвЖМЪЧБЛБъМЧПЩЫндДЃЌЫЋжижЇИЖЪЧПЩвдБмУтЕФЁЃ
3.3 Merkle Tree
Merkle TreeЃЌЪЧвЛжжЪїЃЈЪ§ОнНсЙЙжаЫљЫЕЕФЪїЃЉЃЌЭјЩЯДѓЖМГЦЮЊMerkle Hash Tree,етЪЧвђЮЊ ЫќЫљЙЙдьЕФMerkle TreeЕФЫљгаНкЕуЖМЪЧHashжЕЁЃMerkle TreeОпгавдЯТЬиЕуЃК
1. ЫќЪЧвЛжжЪїЃЌПЩвдЪЧЖўВцЪїЃЌвВПЩвдЖрВцЪїЃЌЮоТлЪЧМИВцЪїЃЌЫќЖМОпгаЪїНсЙЙЕФЫљгаЬиЕуЃЛ
2. MerkleЪїЕФвЖзгНкЕуЩЯЕФvalueЃЌЪЧгЩФужИЖЈЕФЃЌетжївЊПДФуЕФЩшМЦСЫЃЌШчMerkle Hash TreeЛсНЋЪ§ОнЕФHashжЕзїЮЊвЖзгНкЕуЕФжЕЃЛ
3 ЗЧвЖзгНкЕуЕФvalueЪЧИљОнЫќЯТУцЫљгаЕФвЖзгНкЕужЕЃЌШЛКѓАДеевЛЖЈЕФЫуЗЈМЦЫуЖјЕУГіЕФЁЃШчMerkle Hash TreeЕФЗЧвЖзгНкЕуvalueЕФМЦЫуЗНЗЈЪЧНЋИУНкЕуЕФЫљгазгНкЕуНјаазщКЯЃЌШЛКѓЖдзщКЯНсЙћНјааhashМЦЫуЫљЕУГіЕФhash valueЁЃ
Р§ШчЃЌЯТЭМОЭЪЧвЛИіMerkle Hash TreeаЮзДЃЌШчЙћЫќЪЧMerkle Hash TreeЃЌдђНкЕу7ЕФhash valueБиаыЪЧЭЈЙ§НкЕу15ЁЂ16ЩЯЕФvalueМЦЫуЖјЕУЕН.
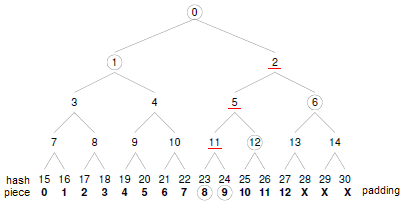
дкДІРэБШЖдЛђбщжЄЕФгІгУГЁОАжаЪБЃЌЬиБ№ЪЧдкЗжВМЪНЛЗОГЯТНјааБШЖдЛђбщжЄЪБЃЌMerkle TreeЛсДѓДѓМѕЩйЪ§ОнЕФДЋЪфСПвдМАМЦЫуЕФИДдгЖШЁЃР§ШчЃЌОЭФУЭМвЛОйР§ЃЌМйШчЪЧ 15,16.......30ЪЧвЛИіИіЪ§ОнПщЕФhashжЕЃЌЮвАбетаЉЪ§ОнДгAДЋЪфЕНBЃЌЪ§ОнДЋЪфЕНBКѓЃЌЮвЯыбщжЄЯТДЋЪфЕНBЩЯЕФЪ§ОнЕФгааЇадаЭЃЈбщжЄЪ§ОнЪЧЗёдкДЋЪфЙ§ГЬжаЗЂЩњБфЛЏЃЉЃЌжЛашвЊбщжЄA КЭ BЩЯЫљЙЙдьЕФMerkle
TreeЕФrootНкЕужЕЪЧЗёвЛжТМДПЩЃЌШчЙћвЛжТЃЌБэЪОЪ§ОнЪЧгааЇЕФЃЌДЋЪфЙ§ГЬжаУЛгаЗЂЩњИФБфЁЃМйШчдкДЋЪфЙ§ГЬжаЃЌ15ЖдгІЕФЪ§ОнБЛШЫДлИФЃЌЭЈЙ§Merkle TreeКмШнвзЖЈЮЛевЕНЃЈвђЮЊДЫЪБЃЌНкЕу0,1,3,7,15ЖдгІЕФhashжЕЖМЗЂЩњСЫБфЛЏЃЉ
ашвЊНтЪЭЕФЪЧНЛвзЪ§ОнЪЧдѕУДЙЙНЈГЩЪ§ЕФФиЃЌЦфЪЕКмМђЕЅЃКЪзЯШНЋЫљгаНЛвззїЮЊвЖзгНкЕуЃЌСНСНЯрСкЗжзщЃЈзмЕФНЛвзЪ§СПШчЙћЪЧЦцЪ§ОЭАбЕЅИіЕФФЧИіИДжЦвЛЗнЃЉЃЌШЛКѓЖдУПвЛЖдНЛвзЗжБ№МЦЫуЙўЯЃВЂвРДЫЯђЩЯЙЙНЈЪїжБжСИљНкЕуЃЌШчЯТЭМЫљЪОЃК
4.НЛвз
дйДЮЧПЕїЕФЪЧЃЌБШЬиБвЭјТчжаСїзЊЕФЪЧНЛвзаХЯЂЃЌУПИіеЫЛЇЕФгрЖюЪЧЭЈЙ§НЛвзаХЯЂЭЦЫуГіРДЕФЃЌНЛвзаХЯЂЪЧЫЋЯђЕФЃЌгавЛИіЪфШыБиЖЈЖдгІвЛИіЪфГіЁЃ
3.1НЛвзЪфШыЪфГі
УПвЛБЪНЛвз,outЕФзмЖюгІИУЕШгкinЕФзмЖюЁЃЕЋЪЧ,дкетИіНЛвзЕЅРя,жЛЛсгаoutЕФValue,УЛгаinЕФValue,ЖјЪЧЭЈЙ§inЕФPerviousгыindex,зЗЫнЕНЩЯвЛИіНЛвзЕЅЕФФГвЛИіout,ЛёЕУValueЁЃ
вЛДЮsend bitcoin,ЪЃЯТЕФЧЎ,гІИУoutИјздМК,ЗёдђетИіЧЎОЭЖЊСЫЁЃ
ЧщПіСаОй:
Ювга10ИіBTC,ЪЧФГвЛДЮНЛвзЛёЕУЕФ,ЮввЊЫЭИјХѓгбA,10ИіBTCЁЃетЪБКђ,гавЛИіin,вЛИіoutЁЃ
Ювга10ИіBTC,ЪЧФГвЛДЮНЛвзЛёЕУЕФ,ЮввЊЫЭИјХѓгбA,5ИіBTC,етЪБКђ,гавЛИіin,СНИіout,вЛИіжИЯђХѓгб5ИіBTC,вЛИіжИЯђЮвздМК,ЕУЕНЪЃЯТЕФ5ИіBTCЁЃ
Ювга10ИіBTC,ЪЧвдЧАЕФСНДЮНЛвзЛёЕУЕФ,ЮввЊЫЭИјХѓгбA,10ИіBTC,етЪБКђ,гаСНИіin,вЛИіoutЁЃ
Ювга10ИіBTC,ЪЧвдЧАЕФСНДЮНЛвзЛёЕУЕФ,ЦфжавЛДЮЛёЕУСЫ6ИіBTC,СэвЛДЮЛёЕУСЫ4ИіBTC,ЮввЊЫЭИјЮвЕФХѓгб7ИіBTC,етЪБКђ,гаСНИіin,СНИіoutЁЃ
БШЬиБвНЛвзЕФЛљБОЕЅЮЛЪЧЮДОЪЙгУЕФвЛИіНЛвзЪфГіЃЌМђГЦUTXOЁЃUTXOЪЧВЛФмдйЗжИюЁЂБЛЫљгаепЫјзЁЛђМЧТМгкЧјПщСДжаЕФВЂБЛећИіЭјТчЪЖБ№ГЩЛѕБвЕЅЮЛЕФвЛЖЈСПЕФБШЬиБвЛѕБвЁЃетОфЛАЪВУДвтЫМФиЃПБШЬиБвНЛвзГ§СЫЭкПѓЛёШЁвдЭтЃЌЖМЪЧСуКЭЕФЃЌвђЮЊЧјПщСДВЛЮЌЛЄгрЖюаХЯЂвВУЛгагрЖюИХФюЃЌЧјПщСДжЛгаНЛвзаХЯЂЁЃОйИіР§згЃЌФуга10ИіБШЬиБвЯждкашвЊжЇИЖ2ИіГіШЅЃЌФЧУДНЛвзЪ§ОнЮЌЛЄЕФЪЧвЛИіЪфШыЃЈЮДОЪЙгУЕФ10ИіБШЬиБвЃЉКЭ2ИіЪфГіЃЈвЛИіЪЧ2ИіБвЖдгІЕФЕижЗЃЉЃЌЛЙгавЛИіЪЧ8ИіБвЖдгІЕижЗЪЧФуздМКЕФЕижЗЁЃ
3.2НЛвзЙ§ГЬ
НЛвзЕФЛљБОЫпЧѓЃЌЪЧИЖПюШЫЃЈpayerЃЉЛуПюИјЪеПюШЫЃЈpayeeЃЉЁЃММЪѕЬєеНЪЧМгУмЃЈcryptographyЃЉЃЌФПЕФЪЧВЛШУЕкШ§епНиЛёЩѕжСДлИФЛуПюН№ЖюЁЃ
ЯТЭМНтЪЭСЫ Owner0 Иј Owner1вдМАКѓај ЛуПюЕФНЛвзЛњжЦЃЌНиЭМШчЯТЁЃ
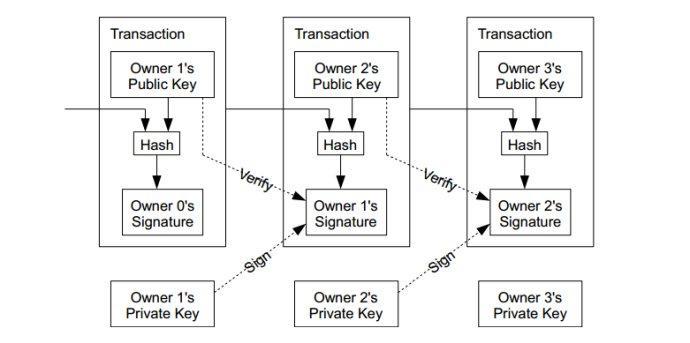
1. Owner0 ЯШВщЕН Owner1 ЕФЙЋдПЁЃгУ Owner1 ЕФЙЋдПЃЈPublic KeyЃЉАбЛуПюЯъЧщМгУмЁЃетбљЃЌжЛга Owner1 БОШЫгУздМКЕФЫНдПЃЈPrivate KeyЃЉЃЌВХФмДђПЊМгСЫУмЕФЛуПюЯъЧщЁЃдкЭМР§жаЃЌУЛгаЛЛуПюЯъЧщЁЃВЛЙ§етИіаЁаЁЕФа№ЪіЕФЪшКіЮоЗСДѓбХЁЃ
2. ЮЊСЫЗНБу Owner1 бщжЄетБЪЛуПюЕФШЗРДзд Owner0ЃЌЖјВЛЪЧБ№ШЫЃЌOwner0 ЗЂГіЕФЛуПюЕЅРяЃЌГ§СЫгаМгСЫУмЕФЛуПюЯъЧщЃЌЛЙга Owner0 ЕФЪ§зжЧЉУћЃЈSignatureЃЉЁЃOwner1 ФУЕНЛуПюЪБЃЌЮЊСЫбщжЄетБЪЛуПюЕФШЗРДзд Owner0ЃЌЫћПЩвдгУ Owner0 ЕФЙЋдПЃЌРДбщжЄЛуПюЕЅжа Owner0 ЕФЪ§зжЧЉУћЁЃ
3. Owner0 ЗЂГіЛуПюЕЅЪБЃЌЛуПюЕЅВЛНіНіЭЖЕнЕН Owner1ЃЌЖјЧвЛЙвЊЙуЖјИцжЎЃЌШЮКЮШЫжЛвЊдИвтВЮгы BitCoin ЩѓМЦЃЌЖМПЩвдЪеЕНШЋЧђЫљгаШЫЗЂГіЕФЫљгаЛуПюЕЅЁЃ
4. бигУ 1ЁЂ2ЁЂ3 ЕФдРэЃЌOwner1 Иј Owner2 ЛуПюЃЌШЛКѓ Owner2 Иј Owner3 ЛуПюЁЃBitCoin ЭЈЙ§ Hash ЛњжЦЃЌАбЩцМАЭЌвЛУЖ BitCoin ЕФЫљгаЛуПюНЛвзЃЈTranactionЃЉДЎСЌЦ№РДЃЌФПЕФЪЧЮЊСЫзЗВщжиИДИЖПюЃЈdouble spendingЃЉЕФЦлеЉааЮЊЁЃ
ЕЅЖРРДПДНЛвзДДНЈЙ§ГЬЃК
ЪеПюЗНЖдНЛвзНјаабщжЄЃК
4.ЭкПѓдРэ
ЭкПѓЕФБОжЪвтвхЪЧЭкПѓНкЕуељЖсМЧеЫШЈЃЁжїЙлЩЯРДЫЕЃЌЭкПѓНкЕуЛёЕУСЫЭкПѓНБРјМАНЛвзЗбЃЌПЭЙлЩЯРДЫЕЃЌетБЃжЄСЫЧјПщСДАДееЬиЖЈЙцдђГжајЮШЖЈЕФБЛЮЌЛЄЁЃ
ЭкПѓЕФОпЬхЪЕЯжОЭЪЧдкФбЖШвЛЖЈЕФЧщПіЯТЭЈЙ§БЉСІЫЋSHA256ЙўЯЃдЫЫуЛёШЁТњзуФбЖШtagetЕФNonceжЕЃЌЫљЮНЕФЙЄзїСПжЄУїОЭЪЧЮоЪ§ДЮЙўЯЃдЫЫуЧюОйВЂБШЖдЕФЙ§ГЬЁЃ
ЁАЭкПѓЁБЫуЗЈЮвУЧПЩвдВЮПМЧјПщЭЗНсЙЙНтЫЕШчЯТЃК
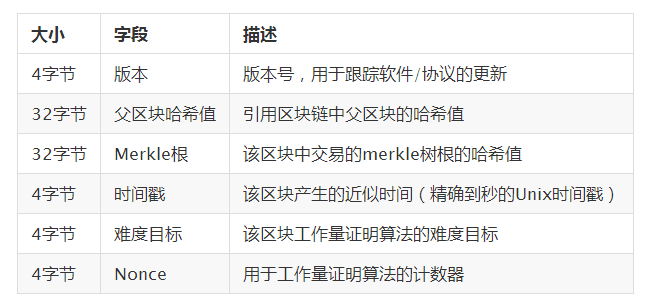
ЕквЛВНЃКевЕНЧјПщАцБОКХversionЁЃ
ЕкЖўВНЃКевЕНЩЯвЛИіЧјПщЕФhashжЕЃЈИИЧјПщЙўЯЃжЕЃЉЃКprev_hashЁЃ
ЕкШ§ВНЃКЪфШыМЧТМНЛвзЕФhashЪїЕФИљНкЕуhashжЕЃЈMerkleИљЃЉЃКroot_hashЁЃ
ЕкЫФВНЃКИќаТЕФЪБМфЃЈЪБМфДСЃЉ:timeЁЃ
ЕкЮхВНЃКШЋЭјЕБЧАФбЖШЃЈФбЖШФПБъЃЉ:difficulty
еыЖдФбЖШФПБъашвЊЫЕУїЃК
ФбЖШдкЧјПщжавдЁАЮВЪ§-жИЪ§ЁБЕФИёЪНЃЌБрТыВЂДцДЂЃЌетжжИёЪНГЦзїЁАФбЖШЮЛЁБЁЃетжжБрТыЕФЪззжНкБэЪОжИЪ§ЃЌКѓУцЕФ3зжНкБэЪОЮВЪ§(ЯЕЪ§)ЁЃвдЧјПщ277316ЮЊР§ЃЌФбЖШЮЛЕФжЕЮЊ0x1903a30cЃЌ0x19ЪЧжИЪ§ЃЈexponentЃЉЕФЪЎСљНјжЦИёЪНЃЌКѓАыВП0x03a30cЪЧЯЕЪ§ЃЈcoefficientЃЉЁЃ
ЕкСљВНЃКздМКеввЛИіЫцЛњЪ§NonceЃКетИіОЭЪЧЗДИДЪдЕФВПЗжЃЌВЛЖЯЕндіИУЪ§зжВЂзіЙўЯЃдЫЫужБЕНЖдгІЙўЯЃжЕаЁгкФбЖШжИЖЈЕФtagetжЕЁЃ
АбвдЩЯ6ИіВЮЪ§зїЮЊЪфШыЃЌзіЖўДЮSHA256дЫЫуЃЌаЮЫЦгк
SHA256(SHA256(version , prev_hash , root_hash , time , difficulty, random))
зюжеЕУЕННсЙћresultЁЃзюКѓАбНсЙћresultЬсНЛИјЯЕЭГЃЌгЩЯЕЭГХаЖЯетИіМЦЫуНсЙћЪЧЗёгааЇЃЈresult<targetЮЊгааЇ)ЁЃШєХаЖЈНсЙћЮЊгааЇЃЌФуОЭВњЩњСЫвЛИіаТЕФЧјПщЃЌВЂЛсИцжЊШЋЭјЁЃ
targetЭЈЙ§difficultyПЩвдМЦЫуЕУЕНЃК
target = coefficient * 2^(8 * (exponent ЈC 3))
ЫуЗЈЙцЖЈЃКвЛИіаТЕФЧјПщЕФЕквЛБЪНЛвзБиаыНЋЬиЖЈЪ§ФПЕФБШЬиБвЗЂЕНФГИіЕижЗЃЌЕБШЛетИіЕижЗПЯЖЈЛсЩшГЩЭкПѓШЫздМКЕФБШЬиБвЕижЗЃЌДгЖјЛёЕУЯЕЭГЕФБШЬиБвНБРјЁЃ
5.змНс
БШЬиБвРэТлвдУмТыбЇЮЊжЇГХЃЌЙЙНЈСЫвЛИіЭъБИЁЂАВШЋЁЂШЅжааФЛЏЕФЪ§зжЛѕБвЬхЯЕЃЌНтОіСЫЪ§зжзЪВњЫљгаШЈЮЪЬтЁЂЫЋжижЇИЖЮЪЬтЁЂЯжЪЕЪРНчЕФЭЈЛѕХђеЭЮЪЬтЩѕжСЛЙдЄСєСЫЛњжЦЪЙЕУЙЙНЈдкзЪВњзЊвЦжЎЩЯЕФжЧФмКЯЭЌГЩЮЊПЩФмЁЃБШЬиБвЕБШЛЪЧЮАДѓЕФДДдьЃЌЦкД§БШЬиБвгаИќКУЕФЮДРДЁЃ
СэЭтЃЌБОЪщГЩЮФЙ§ГЬжаВЮПМСЫЭѕУыЕШРЯЪІЗвыЕФЁЖОЋЭЈБШЬиБвЁЗЃЌРюОћЕШРЯЪІЕФЁЖБШЬиБвЁЗвдМААЭБШЬиЩчЧјЕФДѓСПжЊЪЖЃЌИааЛЫћУЧЁЃ
зюКѓЃЌИааЛДѓМвКЭЮввЛЦ№ВЮгыетДЮЗжЯэЃЌЛЖгДѓМвЬэМгЛђЩЈУшЯТУцЕФЖўЮЌТыМгЮвЕФИіШЫЮЂаХКХ zbren_imМЬајНЛСїЁЃ
|






