| БрМЭЦМі: |
БОЮФРДздгкВЉПЭдАЃЌБОЮФНщЩмСЫStormШчКЮБЃжЄПЩППадвдМАзїЮЊStormЪЙгУепЃЌЮвУЧашвЊдѕУДзіЃЌВХФмГфЗжРћгУStormЕФПЩППадЁЃ
|
|
ФкШнМђНщ
StormПЩвдБЃжЄДгSpoutЗЂГіЕФУПИіЯћЯЂЖМФмБЛЭъШЋДІРэЁЃStormЕФПЩППадЛњжЦЪЧЭъШЋЗжВМЪНЕФ(distributed)ЃЌПЩЩьЫѕЕФ(scalable)ЃЌШнДэЕФ(fault-tolerant)ЁЃБОЮФНщЩмСЫStormШчКЮБЃжЄПЩППадвдМАзїЮЊStormЪЙгУепЃЌЮвУЧашвЊдѕУДзіЃЌВХФмГфЗжРћгУStormЕФПЩППадЁЃРэНтвЛаЉЪЕЯжЯИНкЃЌвВФмЙЛАяжњЮвУЧСьЮђStormЕФЩшМЦРэФюЁЃ
PS:БОЮФгУЕНСЫStormЕФвЛаЉЛљБОИХФюЃЌР§ШчBolt,ШЮЮё(Task),дЊзщ(Tuple)ЃЌШчЙћВЛЧхГўетаЉИХФюЃЌПЩвдВЮПДЮвжЎЧАаДЕФЮФеТЃКStormНщЩм(вЛ)ЃЌРэНтStormВЂЗЂЁЃЯТЮФжадЊзщ(Tuple)ЃЌИњЯћЯЂ(message)ЪЧЕШМлЕФЃЌStormжаДІРэЕФЯћЯЂЪЧгУдЊзщетжжЪ§ОнНсЙЙРДБэЪОЕФЁЃ
вЛИіЯћЯЂБЛЭъећДІРэЪЧЪВУДвтЫМЃП
СїЪНМЦЫуЕЅДЪИіЪ§ЕФР§зг
ПМТЧШчЯТЕФСїЪНМЦЫуЮФеТжаЕЅДЪИіЪ§ЕФЭиЦЫЃК
| TopologyBuilder
builder = new TopologyBuilder();
builder.setSpout("sentences", new
KestrelSpout("kestrel.backtype.com",
22133, "sentence_queue", new StringScheme()));
builder.setBolt("split", new SplitStentence(),
10).shuffleGrouping("sentences");
builder.setBolt("count", new WordCount(),
20).fieldsGrouping("split", new Fields("word")); |
етИіЭиЦЫгЩ3ИіДІРэЕЅдЊзщГЩЃКвЛИіНа"sentences"ЕФSpoutЃЌИКд№ДгKestrelЖгСажаЖСШЁОфзгВЂзїЮЊаТЕФSpoutдЊзщЗЂЫЭГіШЅЁЃУћГЦЮЊ"split"ЕФBoltЪЧSpoutдЊзщЕФЯТгЮЯћЗбЗНЃЌЫќАбНгЪеЕНОфзгЧаЗжГЩЕЅДЪВЂЗЂЫЭГіШЅЁЃУћГЦЮЊ"count"ЕФBoltЪЧ"split"
BoltЕФЯТгЮЯћЗбЗНЃЌЫќЪЙгУHashMap<String, Interger>ДцДЂСЫУПИіШЮЮёжаУПИіЕЅДЪГіЯжЕФДЮЪ§ЃЌУПДЮЖСШЁЕНаТЕФЕЅДЪдЊзщОЭШУИУЕЅДЪЕФМЦЪ§МгвЛЁЃ"count"
BoltНгЪе"split" BoltЗЂГіЕФЯћЯЂЪБЃЌЪЧЪЙгУдЊзщжаЕФ"word"(ЕЅДЪ)зжЖЮРДзїЮЊТЗгЩВпТдЃЌЫљвдЯрЭЌЕФЕЅДЪдЊзщЛсБЛТЗгЩЕНЯрЭЌЕФШЮЮё(task)РяЃЌетбљОЭФмЙЛМЦЪ§СЫЁЃ
ЯћЯЂ(дЊзщ)Ъї(message tree)
дкЯТгЮЕФBoltжаЛсЛљгкФГИіSpoutдЊзщЗЂЩфГіКмЖраТЕФдЊзщЃКОфзгжаЕФУПИіЕЅДЪЛсЩњГЩвЛИіаТдЊзщ(дкsplit
BoltЭъГЩ)ЃЌУПИіЕЅДЪЕФМЦЪ§ИќаТКѓ(дкcount BoltЭъГЩ)вВЛсДЅЗЂвЛИіаТЕФдЊзщЁЃФГИіSpoutдЊзщДЅЗЂЕФЯћЯЂЪїШчЯТЭМЃК
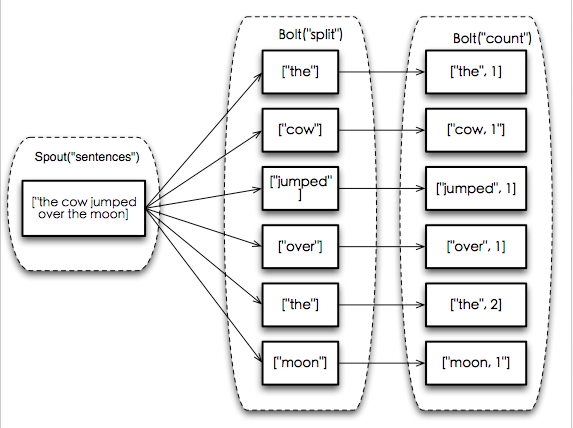
вЛИіSpoutдЊзщДЅЗЂЕФЯћЯЂЪї
ПЩвдПДЕНетПУЯћЯЂЪїЕФИљНкЕуЪЧSpoutВњЩњЕФОфзгФкШнЮЊ"the cow jumped over
the moon"ЕФдЊзщЁЃетИіSpoutдЊзщдк"split"етИіBoltРяБЛЧаЗжЮЊ6ИіЕЅДЪЃЌДЅЗЂСЫ6ИіЕЅДЪдЊзщЃЌ"count"
BoltНгЪеЕНет6ИіЕЅДЪдЊзщКѓЃЌИќаТСЫУПИіЕЅДЪЕФМЦЪ§ВЂЮЊжЎВњЩњСЫвЛИіаТЕФдЊзщЁЃ
вЛЬѕЯћЯЂБЛЁАЭъећДІРэЁБ
жИвЛИіДгSpoutЗЂГіЕФдЊзщЫљДЅЗЂЕФЯћЯЂЪїжаЫљгаЕФЯћЯЂЖМБЛStormДІРэСЫЁЃШчЙћдкжИЖЈЕФГЌЪБЪБМфРяЃЌетИіSpoutдЊзщДЅЗЂЕФЯћЯЂЪїжагаШЮКЮвЛИіЯћЯЂУЛгаДІРэЭъЃЌОЭШЯЮЊетИіSpoutдЊзщДІРэЪЇАмСЫЁЃетИіГЌЪБЪБМфЪЧЭЈЙ§УПИіЭиЦЫЕФConfig.TOPOLOGY_MESSAGE_TIMEOUT_SECSХфжУЯюРДНјааХфжУЕФЃЌФЌШЯЪЧ30УыЁЃ
дкЧАУцЯћЯЂЪїЕФР§згРяЃЌжЛгаЯћЯЂЪїжаЫљгаЕФЯћЯЂ(АќКЌвЛЬѕSpoutЯћЯЂЃЌСљЬѕsplit BoltЯћЯЂ,СљЬѕcount
BoltЯћЯЂ)ЖМБЛStormДІРэЭъСЫЃЌВХЫуЪЧетЬѕSpoutЯћЯЂБЛЭъећДІРэСЫЁЃ
ЯћЯЂБЛЭъећДІРэЛђепДІРэЪЇАм
ЕБЯћЯЂУЛгаБЛЭъећДІРэЛђепДІРэЪЇАмСЫЛсдѕУДбљЃПЮЊСЫРэНтетИіЮЪЬтЃЌгІИУЪзЯШПДвЛЯТSpoutЗЂГіЕФвЛИідЊзщЕФЩњУќжмЦкЁЃSpoutашвЊЪЕЯжЕФНгПк(НгПкЮФЕЕМћетРя)ШчЯТЃК
| public
interface ISpout extends Serializable {
void open(Map conf, TopologyContext context,
SpoutOutputCollector collector);
void close();
void nextTuple();
void ack(Object msgId);
void fail(Object msgId);
} |
ЪзЯШЃЌStormЭЈЙ§ЕїгУSpoutЕФnextTupleКЏЪ§РДДгSpoutЧыЧѓвЛИідЊзщЁЃSpoutШЮЮёЪЙгУopenКЏЪ§ШыВЮжаЬсЙЉЕФSpoutOutputCollectorРДИјSpoutШЮЮёЕФФГИіЪфГіСїЗЂЩфвЛИіаТдЊзщЁЃЕБЗЂЩфвЛИідЊзщЪБЃЌSpoutЬсЙЉСЫвЛИі"ЯћЯЂБъЪЖ"(message-id)ЃЌгУРДКѓајЪЖБ№етИідЊзщЁЃР§ШчЃЌЩЯУцЕФР§згРяЃЌsentence
SpoutДгKestrelЖгСажаЖСШЁвЛЬѕЯћЯЂЃЌШЛКѓАбKestrelЬсЙЉЕФетИіЯћЯЂЕФmessage-idзїЮЊ"ЯћЯЂБъЪЖ"РДЗЂЫЭГіШЅЁЃЯђSpoutOutputCollectorжаЗЂЫЭЯћЯЂЕФР§згШчЯТЃК
| _collector.emit(new
Values("the cow jumped over the moon"),
msgId); |
НгЯТРДЃЌдЊзщОЭБЛЗЂЫЭЕНЯТгЮЕФBoltНјааЯћЗбЃЌStormЛсИКд№ИњзйетИіSpoutдЊзщДДНЈЕФЯћЯЂЪїЁЃШчЙћStormМьВтЕНвЛИідЊзщБЛЭъећЕиДІРэСЫЃЌStormЛсЕїгУВњЩњетИідЊзщЕФSpoutШЮЮё(Spout
BoltгаЖрИіШЮЮёРДдЫаа)ЕФackКЏЪ§ЃЌВЮЪ§ЪЧSpoutжЎЧАЗЂЫЭетИіЯћЯЂЪБЬсЙЉИјStormЕФmessage-idЁЃРрЫЦЕФЃЌЕБдЊзщДІРэГЌЪБЛђДІРэЪЇАмЪБЃЌStormЛсдкдЊзщЖдгІЕФSpoutШЮЮёЩЯЕїгУfailКЏЪ§ЃЌВЮЪ§ЪЧжЎЧАSpoutЗЂЫЭетИіЯћЯЂЪБЬсЙЉИјStormЕФmessage-idЁЃетбљгІгУГЬађЭЈЙ§ЪЕЯжSpout
BoltжаЕФackНгПкКЭfailНгПкРДДІРэЯћЯЂДІРэГЩЙІКЭЪЇАмЕФЧщПіЁЃР§ШчЕБЯћЯЂДІРэГЩЙІЪБМЧТМЕБЧАДІРэЕФНјЖШЃЌЕБДІРэЪЇАмЪБЃЌжиаТЗЂЫЭЯћЯЂРДЖдетИіЯћЯЂНјаажиаТДІРэЁЃЕЋдкБОЮФЕФР§згРяfailКЏЪ§жаВЛашвЊзіШЮКЮДІРэЃЌвђЮЊетаЉдЊзщВЛЛсДгKestrelЖгСажаШЅЕєЃЌЯТДЮДгЖгСаШЁЯћЯЂЃЌШдШЛЛсШЁЕНетаЉЯћЯЂЃЌжЛгаДІРэГЩЙІКѓЃЌВХЛсДгKestrelЖгСажаеЊГ§етаЉЯћЯЂЁЃ
StormЕФПЩППадAPI
зїЮЊStormгУЛЇЃЌШчЙћЯыРћгУStormЕФПЩППадЃЌашвЊзіСНМўЪТЃК
1. ДДНЈвЛИідЊзщЪБ(ЯћЯЂЪїЩЯДДНЈвЛИіаТНкЕу)ашвЊЭЈжЊStorm
2. ДІРэЭъвЛИідЊзщЃЌашвЊЭЈжЊStorm
ЭЈЙ§етСНИіВйзїЃЌЕБЯћЯЂЪїБЛЭъШЋДІРэЭъЃЌStormОЭПЩвдСЂМДМьВтЕНЃЌДгЖјПЩвде§ШЗЕиШЗШЯетИіSpoutдЊзщДІРэГЩЙІЛђепЪЇАмЁЃStormЕФAPIЬсЙЉСЫвЛЬзМђНрЕиДІРэетаЉВйзїЕФЗНЗЈЁЃ
дЊзщДДНЈЪБЭЈжЊStorm
дкStormЯћЯЂЪї(дЊзщЪї)жаЬэМгвЛИізгНсЕуЕФВйзїНазіУЊЖЈ(anchoring)ЁЃдкгІгУГЬађЗЂЫЭвЛИіаТдЊзщЪБКђЃЌStormЛсдкФЛКѓзіУЊЖЈЁЃЛЙЪЧжЎЧАЕФСїЪНМЦЫуЕЅДЪИіЪ§ЕФР§згЃЌЧыПДШчЯТЕФДњТыЦЌЖЮЃК
| public
class SplitSentence extends BaseRichBolt {
OutputCollector _collector;
public void prepare(Map conf, TopologyContext
context, OutputCollector collector){
_collector = collector;
}
public void execute(Tuple tuple) {
String sentence = tuple.getString(0);
for(String word: sentence.split(" "))
{
_collector.emit(tuple, new Values(word));
}
_collector.ack(tuple);
}
public void declareOutputFields(OutputFieldsDeclarer
declarer) {
declarer.declare(new Fields("word"));
}
} |
УПИіЕЅДЪдЊзщЪЧЭЈЙ§АбЪфШыЕФдЊзщзїЮЊemitКЏЪ§жаЕФЕквЛИіВЮЪ§РДзіУЊЖЈЕФЁЃЭЈЙ§УЊЖЈЃЌStormОЭФмЙЛЕУЕНдЊзщжЎМфЕФЙиСЊЙиЯЕ(ЪфШыдЊзщДЅЗЂСЫаТЕФдЊзщ)ЃЌМЬЖјЙЙНЈГіSpoutдЊзщДЅЗЂЕФећИіЯћЯЂЪїЁЃЫљвдЕБЯТгЮДІРэЪЇАмЪБЃЌОЭПЩвдЭЈжЊSpoutЕБЧАЯћЯЂЪїИљНкЕуЕФSpoutдЊзщДІРэЪЇАмЃЌШУSpoutжиаТДІРэЁЃЯрЗДЃЌШчЙћдкemitЕФЪБКђУЛгажИЖЈЪфШыЕФдЊзщЃЌНазіВЛУЊЖЈЃК
| _collector.emit(new
Values(word)); |
етбљЗЂЩфЕЅДЪдЊзщЃЌЛсЕМжТетИідЊзщВЛБЛУЊЖЈ(unanchored)ЃЌетбљStormОЭВЛФмЕУЕНетИідЊзщЕФЯћЯЂЪїЃЌМЬЖјВЛФмИњзйЯћЯЂЪїЪЧЗёБЛЭъећДІРэЁЃетбљЯТгЮДІРэЪЇАмЃЌВЛФмЭЈжЊЕНЩЯгЮЕФSpoutШЮЮёЁЃВЛЭЌЕФгІгУЕФгаВЛЭЌЕФШнДэДІРэЗНЪНЃЌгаЪБКђашвЊетбљВЛУЊЖЈЕФГЁОАЁЃ
вЛИіЪфГіЕФдЊзщПЩвдБЛУЊЖЈЕНЖрИіЪфШыдЊзщЩЯЃЌНазіЖрУЊЖЈ(multi-anchoring)ЁЃетдкзіСїЕФКЯВЂЛђепОлКЯЕФЪБКђЗЧГЃгагУЁЃвЛИіЖрУЊЖЈЕФдЊзщДІРэЪЇАмЃЌЛсЕМжТSpoutЩЯжиаТДІРэЖдгІЕФЖрИіЪфШыдЊзщЁЃЖрУЊЖЈЪЧЭЈЙ§жИЖЈвЛИіЖрИіЪфШыдЊзщЕФСаБэЖјВЛЪЧЕЅИідЊзщРДЭъГЩЕФЁЃР§ШчЃК
| List<Tuple>
anchors = new ArrayList<Tuple>();
anchors.add(tuple1);
anchors.add(tuple2);
_collector.emit(anchors, new Values(word)); |
ЖрУЊЖЈЛсАбетИіаТЪфГіЕФдЊзщЬэМгЕНЖрПУЯћЯЂЪїЩЯЁЃзЂвтЖрУЊЖЈПЩФмЛсДђЦЦЯћЯЂЕФЪїаЮНсЙЙЃЌБфГЩгаЯђЮоЛЗЭМ(DAG)ЃЌStormЕФЪЕЯжМШжЇГжЪїаЮНсЙЙЃЌвВжЇГжгаЯђЮоЛЗЭМ(DAG)ЁЃдкБОЮФжаЃЌЬсЕНЕФЯћЯЂЪїИњгаЯђЮоЛЗЭМЪЧЕШМлЕФЁЃЯћЯЂжЎМфЕФЙиЯЕЪЧгаЯђЮоЛЗЭМЕФР§згМћЯТЭМЃК
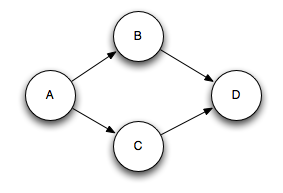
ЯћЯЂаЮГЩЕФгаЯђЮоЛЗЭМ
SpoutдЊзщAДЅЗЂСЫBКЭCСНИідЊзщЃЌЖјетСНИідЊзщзїЮЊЪфШыЃЌЙВЭЌзїгУКѓДЅЗЂDдЊзщЁЃ
дЊзщДІРэЭъКѓЭЈжЊStorm
УЊЖЈЕФзїгУОЭЪЧжИЖЈдЊзщЪїЕФНсЙЙ--ЯТвЛВНЪЧЕБдЊзщЪїжаФГИідЊзщвбОДІРэЭъГЩЪБЃЌЭЈжЊStormЁЃЭЈжЊЪЧЭЈЙ§OutputCollectorжаЕФackКЭfailКЏЪ§РДЭъГЩЕФЁЃР§ШчЩЯУцСїЪНМЦЫуЕЅДЪИіЪ§Р§згжаЕФsplit
BoltЕФЪЕЯжSplitSentenceРрЃЌПЩвдПДЕНОфзгБЛЧаЗжГЩЕЅДЪКѓЃЌЕБЫљгаЕФЕЅДЪдЊзщЖМБЛЗЂЩфКѓЃЌЛсШЗШЯ(ack)ЪфШыЕФдЊзщДІРэЭъГЩЁЃ
ПЩвдРћгУOutputCollectorЕФfailКЏЪ§РДСЂМДЭЈжЊStormЃЌЕБЧАЯћЯЂЪїЕФИљдЊзщДІРэЪЇАмСЫЁЃР§ШчЃЌгІгУГЬађПЩФмВЖзНЕНСЫЪ§ОнПтПЭЛЇЖЫЕФвЛИівьГЃЃЌОЭЯдЪОЕиЭЈжЊStormЪфШыдЊзщДІРэЪЇАмЁЃЭЈЙ§ЯдЪОЕиЭЈжЊStormдЊзщДІРэЪЇАмЃЌетИіSpoutдЊзщОЭВЛгУЕШД§ГЌЪБЖјФмИќПьЕиБЛжиаТДІРэЁЃ
StormашвЊеМгУФкДцРДИњзйУПИідЊзщЃЌЫљвдУПИіБЛДІРэЕФдЊзщЖМБиаыБЛШЗШЯЁЃвђЮЊШчЙћВЛЖдУПИідЊзщНјааШЗШЯЃЌШЮЮёзюжеЛсКФЙтПЩгУЕФФкДцЁЃ
зіОлКЯЛђепКЯВЂВйзїЕФBoltПЩФмЛсбгГйШЗШЯвЛИідЊзщЃЌжБЕНИљОнвЛЖбдЊзщМЦЫуГіСЫвЛИіНсЙћКѓЃЌВХЛсШЗШЯЁЃОлКЯЛђепКЯВЂВйзїЕФBoltЃЌЭЈГЃвВЛсЖдЫћУЧЕФЪфГідЊзщНјааЖрУЊЖЈЁЃ
Storm 0.7.0в§ШыСЫЁАЪТЮёЭиЦЫЁБ(transactional topologies)ЕФЬиадЃЌЫќШУФудкДѓЖрЪ§ГЁОАЯТФмЙЛЕУЕНЭъШЋШнДэЕФжЛБЛДІРэвЛДЮЕФЯћЯЂгявхЁЃИќЖрЙигкЪТЮяЭиЦЫЕФНщЩмМћетРя
StormдѕбљИпаЇЕФЪЕЯжПЩППадЃП
ackerШЮЮё
вЛИіStormЭиЦЫгавЛзщЬиЪтЕФ"acker"ШЮЮёЃЌЫќУЧИКд№ИњзйгЩУПИіSpoutдЊзщДЅЗЂЕФЯћЯЂЕФДІРэзДЬЌЁЃЕБвЛИі"acker"ПДЕНвЛИіSpoutдЊзщВњЩњЕФгаЯђЮоЛЗЭМжаЕФЯћЯЂБЛЭъШЋДІРэЃЌОЭЭЈжЊЕБГѕДДНЈетИіSpoutдЊзщЕФSpoutШЮЮёЃЌетИідЊзщБЛГЩЙІДІРэЁЃПЩвдЭЈЙ§ЭиЦЫХфжУЯюConfig.TOPOLOGY_ACKER_EXECUTORSРДЩшжУвЛИіЭиЦЫжаackerШЮЮёexecutorЕФЪ§СПЁЃStormФЌШЯTOPOLOGY_ACKER_EXECUTORSКЭЭиЦЫжаХфжУЕФWorkerЕФЪ§СПЯрЭЌ(ЙигкexecutorКЭWorkerЕФНщЩмЃЌВЮМћРэНтStormВЂЗЂвЛЮФ)--ЖдгкашвЊДІРэДѓСПЯћЯЂЕФЭиЦЫРДЫЕЃЌашвЊдіДѓacker
executorЕФЪ§СПЁЃ
дЊзщЕФЩњУќжмЦк
РэНтStormЕФПЩППадЪЕЯжЗНЪНЕФзюКУЗНЗЈЪЧВщПДдЊзщЕФЩњУќжмЦкКЭдЊзщЙЙГЩЕФгаЯђЮоЛЗЭМЁЃЕБЭиЦЫЕФSpoutЛђепBoltжаДДНЈвЛИідЊзщЪБЃЌЖМЛсБЛИГгшвЛИіЫцЛњЕФ64БШЬиЕФБъЪЖ(message
id)ЁЃackerШЮЮёЪЙгУетаЉidРДИњзйУПИіSpoutдЊзщВњЩњЕФгаЯђЮоЛЗЭМЕФДІРэзДЬЌЁЃдкBoltжаВњЩњвЛИіаТЕФдЊзщЪБЃЌЛсДгУЊЖЈЕФвЛИіЛђЖрИіЪфШыдЊзщжаПНБДЫљгаSpoutдЊзщЕФmessage-idЃЌЫљвдУПИідЊзщЖМаЏДјСЫздМКЫљдкдЊзщЪїЕФИљНкЕуSpoutдЊзщЕФmessage-idЁЃЕБШЗШЯвЛИідЊзщДІРэГЩЙІСЫЃЌStormОЭЛсИјЖдгІЕФackerШЮЮёЗЂЫЭЬиЖЈЕФЯћЯЂ--ЭЈжЊackerЕБЧАетИіSpoutдЊзщВњЩњЕФЯћЯЂЪїжаФГИіЯћЯЂДІРэЭъСЫЃЌЖјЧветИіЬиЖЈЯћЯЂдкЯћЯЂЪїжагжВњЩњСЫвЛИіаТЯћЯЂ(аТЯћЯЂУЊЖЈЕФЪфШыЪЧетИіЬиЖЈЕФЯћЯЂ)ЁЃ
ОйИіР§згЃЌМйЩш"D"дЊзщКЭ"E"дЊзщЪЧЛљгкЁАCЁБдЊзщВњЩњЕФЃЌФЧУДЯТЭМУшЪіСЫШЗШЯЁАCЁБдЊзщГЩЙІДІРэКѓЃЌдЊзщЪїЕФБфЛЏЁЃЭМжаащЯпПђБэЪОЕФдЊзщДњБэвбОдкЯћЯЂЪїЩЯБЛЩОГ§СЫЃК
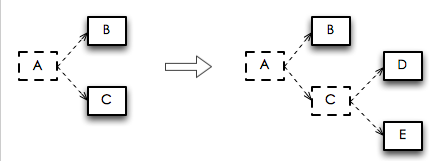
ШЗШЯдЊзщГЩЙІДІРэКѓЯћЯЂЪїЕФБфЛЏ
гЩгкдкЁАCЁБДгЯћЯЂЪїжаЩОГ§(ЭЈЙ§ackerКЏЪ§ШЗШЯГЩЙІДІРэ)ЕФЭЌЪБЃЌЁАDЁБКЭЁАEЁБвВБЛЬэМгЕН(ЭЈЙ§emitКЏЪ§РДУЊЖЈЕФ)дЊзщЪїжаЃЌЫљвдетПУЪїДгРДВЛЛсБЛЬсдчДІРэЭъЁЃ
е§ШчЩЯУцвбОЬсЕНЕФЃЌдквЛИіЭиЦЫжаЃЌПЩвдгаШЮвтЪ§СПЕФackerШЮЮёЁЃетЕМжТСЫШчЯТЕФСНИіЮЪЬтЃК
ЕБЭиЦЫжаЕФвЛИідЊзщШЗШЯБЛДІРэЭъЃЌЛђепВњЩњвЛИіаТЕФдЊзщЪБЃЌStormгІИУЭЈжЊФФИіackerШЮЮёЃП
ЭЈжЊСЫackerШЮЮёКѓЃЌackerШЮЮёШчКЮЭЈжЊЕНЖдгІЕФSpoutШЮЮёЃП
StormВЩгУЖддЊзщжааЏДјЕФSpoutдЊзщmessage-idЙўЯЃШЁФЃЕФЗНЗЈРДАбвЛИідЊзщгГЩфЕНвЛИіackerШЮЮёЩЯ(ЫљвдЭЌвЛИіЯћЯЂЪїРяЕФЫљгаЯћЯЂЖМЛсгГЩфЕНЭЌвЛИіackerШЮЮё)ЁЃвђЮЊУПИідЊзщаЏДјСЫ???МКЫљДІЕФдЊзщЪїжаИљНкЕуSpoutдЊзщ(ПЩФмгаЖрИі)ЕФБъЪЖЃЌЫљвдStormОЭФмОіЖЈЭЈжЊФФИіackerШЮЮёЁЃ
ЕБвЛИіSpoutШЮЮёВњГівЛИіаТЕФдЊзщЃЌНіашвЊМђЕЅЕФЗЂЫЭвЛИіЯћЯЂИјЖдгІЕФacker(SpoutдЊзщmessage-idЙўЯЃШЁФЃ)РДИцжЊSpoutЕФШЮЮёБъЪО(task
id)ЃЌвдДЫРДЭЈжЊackerЕБЧАетИіSpoutШЮЮёИКд№етИіЯћЯЂЁЃЕБackerПДЕНвЛИіЯћЯЂЪїБЛЭъШЋДІРэЭъЃЌЫќОЭФмИљОнДІРэЕФдЊзщжааЏДјЕФSpoutдЊзщmessage-idРДШЗЖЈВњЩњетИіSpoutдЊзщЕФtask
idЃЌШЛКѓЭЈжЊетИіSpoutШЮЮёЯћЯЂЪїДІРэЭъГЩ(ЕїгУ SpoutШЮЮёЕФackКЏЪ§)ЁЃ
ЪЕЯжЯИНк
ЖдгкгЕгаЩЯЭђНкЕуЃЈЛђепИќЖрЃЉЕФОоДѓЕФдЊзщЪїЃЌИњзйЫљгаЕФдЊзщЪїЛсКФОЁackerЪЙгУЕФФкДцЁЃackerШЮЮёВЛЯдЪОЕи(МЧТМЭъећЕФЪїаЭНсЙЙ)ИњзйдЊзщЪїЃЌЯрЗДЫќЪЙгУСЫвЛжжУПИіSpoutдЊзщжЛеМгУЙЬЖЈДѓаЁПеМфЃЈДѓдМ20зжНкЃЉЕФВпТдЁЃетИіИњзйЫуЗЈЪЧStormЙЄзїЕФЙиМќЃЌЖјЧвЪЧжиДѓЭЛЦЦжЎвЛЁЃ
вЛИіackerШЮЮёДцДЂСЫДгвЛИіSpoutдЊзщmessage-idЕНвЛЖджЕЕФгГЩфЙиЯЕspout-message-id--><spout-task-id,
ack-val>ЁЃЕквЛИіжЕЪЧДДНЈСЫетИіSpoutдЊзщЕФШЮЮёidЃЌгУРДКѓајДІРэЭъГЩЪБЭЈжЊЕНетИіSpoutШЮЮёЁЃЕкЖўИіжЕЪЧвЛИі64БШЬиЕФНазіЁАack
valЁБЕФЪ§жЕЁЃЫќЪЧМђЕЅЕФАбЯћЯЂЪїжаЫљгаБЛДДНЈЛђепБЛШЗШЯЕФдЊзщmessage-idвьЛђЦ№РДЕФжЕЁЃУПИіЯћЯЂДДНЈКЭБЛШЗШЯДІРэКѓЖМЛсвьЛђЕН"ack
val"ЩЯЃЌA xor A = 0ЃЌЫљвдЕБвЛИіЁАack valЁББфГЩСЫ0ЃЌЫЕУїећИідЊзщЪїЖМЭъШЋБЛДІРэСЫЁЃЮоТлЪЧКмДѓЕФЛЙЪЧКмаЁЕФдЊзщЪїЃЌ"ack
val"жЕЖМДњБэСЫећИідЊзщЪїжаЯћЯЂЕФДІРэзДЬЌЁЃгЩгкдЊзщmessage-idЪЧЫцЛњЕФ64БШЬиЕФећЪ§ЃЌЫљвдЭЌвЛИідЊзщЪїжаВЛЭЌдЊзщmessage-idЗЂЩњзВГЕЕФПЩФмадЬиБ№аЁЃЌвђДЫЁАack
valЁБвтЭтЕФБфГЩ0ЕФПЩФмадЗЧГЃаЁЁЃШчЙћецЕФЗЂЩњСЫетжжЧщПіЃЌЖјЧЁКУетИідЊзщвВДІРэЪЇАмСЫЃЌФЧНіНіЛсЕМжТетИідЊзщЕФЪ§ОнЖЊЪЇЁЃ
ЪЙгУвьЛђВйзїРДИњзйЯћЯЂЪїДІРэзДЬЌЕФЯыЗЈЗЧГЃгаВХЁЃвђЮЊЯћЯЂЕФЪ§СППЩФмгаГЩЧЇЩЯЭђЬѕЃЌУПИіЖМЕЅЖРИњзй(ЖСепПЩвдЫМПМЯТдѕУДИу)ЪЧЗЧГЃЕЭаЇЖјЧвВЛПЩЫЎЦНРЉеЙЕФЁЃЖјЧвВЩгУвьЛђЕФЗНЪНКѓЃЌОЭВЛвРРЕгкackerНгЪеЕНЯћЯЂЕФЫГађСЫЁЃ
ИуУїАзСЫПЩППадЕФЫуЗЈЃЌШУЮвУЧПДПДЫљгаЪЇАмЕФГЁОАЯТStormШчКЮБмУтЪ§ОнЖЊЪЇЃК
1.BoltШЮЮёЙвЕєЃКЕМжТвЛИідЊзщУЛгаБЛШЗШЯЃЌетжжГЁОАЯТЃЌетИідЊзщЫљдкЕФЯћЯЂЪїжаЕФИљНкЕуSpoutдЊзщЛсГЌЪБВЂБЛжиаТДІРэ
2.ackerШЮЮёЙвЕєЃКетжжГЁОАЯТЃЌетИіackerЙвЕєЪБе§дкИњзйЕФЫљгаЕФSpoutдЊзщЖМЛсГЌЪБВЂБЛжиаТДІРэ
3.SpoutШЮЮёЙвЕєЃКетжжГЁОАЯТЃЌашвЊгІгУздМКЪЕЯжМьВщЕуЛњжЦЃЌМЧТМЕБЧАSpoutГЩЙІДІРэЕФНјЖШЃЌЕБSpoutШЮЮёЙвЕєжЎКѓжиЦєЪБЃЌМЬајДгЕБЧАМьВщЕуДІРэЃЌетбљОЭФмжиаТДІРэЪЇАмЕФФЧаЉдЊзщСЫЁЃ
ЕїећПЩППад
ackerШЮЮёЪЧЧсСПМЖЕФЃЌЫљвддквЛИіЭиЦЫжаВЛашвЊЬЋЖрЕФackerШЮЮёЁЃПЩвдЭЈЙ§Storm UI(idЮЊ"__acker"ЕФзщМўЃЉРДЙлВьackerШЮЮёЕФадФмЁЃШчЙћЭЬЭТСППДЦ№РДВЛе§ГЃЃЌОЭашвЊЬэМгИќЖрЕФackerШЮЮёЁЃ
ШЅЕєПЩППад
ШчЙћПЩППадЮоЙиНєвЊЃЃР§ШчФуВЛЙиаФдЊзщЪЇАмГЁОАЯТЕФЯћЯЂЖЊЪЇЃЃФЧУДФуПЩвдЭЈЙ§ВЛИњзйдЊзщЕФДІРэЙ§ГЬРДЬсИпадФмЁЃВЛИњзйвЛИідЊзщЪїЛсШУДЋЕнЕФЯћЯЂЪ§СПМѕАыЃЌвђЮЊе§ГЃЧщПіЯТЃЌдЊзщЪїжаЕФУПИідЊзщЖМЛсгавЛИіШЗШЯЯћЯЂЁЃСэЭтЃЌетвВФмМѕЩйУПИідЊзщашвЊДцДЂЕФidЕФЪ§СП(жИУПИідЊзщДцДЂЕФSpout
message-id)ЃЌМѕЩйСЫДјПэЕФЪЙгУЁЃ
гаШ§жжЗНЗЈРДШЅЕєПЩППадЃК
1.ЩшжУConfig.TOPOLOGY_ACKERSЮЊ0ЁЃетжжЧщПіЯТЃЌStormЛсдкSpoutЭТГівЛИідЊзщКѓСЂТэЕїгУSpoutЕФackКЏЪ§ЁЃетИідЊзщЪїВЛЛсБЛИњзйЁЃ
2.ЕБВњЩњвЛИіаТдЊзщЕїгУemitКЏЪ§ЕФЪБКђЭЈЙ§КіТдЯћЯЂmessage-idВЮЪ§РДЙиБеетИідЊзщЕФИњзйЛњжЦЁЃ
3.ШчЙћФуВЛЙиаФФГвЛРрЬиЖЈЕФдЊзщДІРэЪЇАмЕФЧщПіЃЌПЩвддкЕїгУemitЕФЪБКђВЛвЊЪЙгУУЊЖЈЁЃгЩгкЫќУЧУЛгаБЛУЊЖЈЕНФГИіSpoutдЊзщЩЯЃЌЫљвдЕБЫќУЧУЛгаБЛГЩЙІДІРэЃЌВЛЛсЕМжТSpoutдЊзщДІРэЪЇАмЁЃ |






