| БрМЭЦМі: |
БОЮФРДздгкВЉПЭдА,ЮФеТжївЊДгFlumeЕФгІгУГЁОАвдМАFlumeЕФНсЙЙКЭзщМўЃЌМђЕЅЕФНщЩмСЫFlumeЃЌЯЃЭћЖдДѓМвгаАяжњЁЃ
|
|
1 .БГОА
flumeЪЧгЩclouderaШэМўЙЋЫОВњГіЕФПЩЗжВМЪНШежОЪеМЏЯЕЭГЃЌКѓгы2009ФъБЛОшдљСЫapacheШэМўЛљН№ЛсЃЌЮЊhadoopЯрЙизщМўжЎвЛЁЃгШЦфНќМИФъЫцзХflumeЕФВЛЖЯБЛЭъЩЦвдМАЩ§МЖАцБОЕФж№вЛЭЦГіЃЌЬиБ№ЪЧflume-ng;ЭЌЪБflumeФкВПЕФИїжжзщМўВЛЖЯЗсИЛЃЌгУЛЇдкПЊЗЂЕФЙ§ГЬжаЪЙгУЕФБуРћадЕУЕНКмДѓЕФИФЩЦЃЌЯжвбГЩЮЊapache
topЯюФПжЎвЛ.
2 .ИХЪі
1. ЪВУДЪЧflume?
apache Flume ЪЧвЛИіДгПЩвдЪеМЏР§ШчШежОЃЌЪТМўЕШЪ§ОнзЪдДЃЌВЂНЋетаЉЪ§СПХгДѓЕФЪ§ОнДгИїЯюЪ§ОнзЪдДжаМЏжаЦ№РДДцДЂЕФЙЄОп/ЗўЮёЃЌЛђепЪ§МЏжаЛњжЦЁЃflumeОпгаИпПЩгУЃЌЗжВМЪНЃЌХфжУЙЄОпЃЌЦфЩшМЦЕФдРэвВЪЧЛљгкНЋЪ§ОнСїЃЌШчШежОЪ§ОнДгИїжжЭјеОЗўЮёЦїЩЯЛуМЏЦ№РДДцДЂЕНHDFSЃЌHBaseЕШМЏжаДцДЂЦїжаЁЃЦфНсЙЙШчЯТЭМЫљЪОЃК
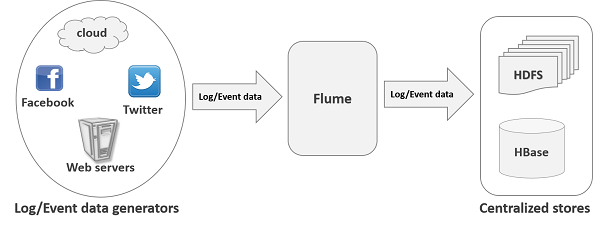
2.гІгУГЁОА
БШШчЮвУЧдкзівЛИіЕчзгЩЬЮёЭјеОЃЌШЛКѓЮвУЧЯыДгЯћЗбгУЛЇжаЗУЮЪЕуЬиЖЈЕФНкЕуЧјгђРДЗжЮіЯћЗбепЕФааЮЊЛђепЙКТђвтЭМ.
етбљЮвУЧОЭПЩвдИќМгПьЫйЕФНЋЫћЯывЊЕФЭЦЫЭЕННчУцЩЯЃЌЪЕЯжетвЛЕуЃЌЮвУЧашвЊНЋЛёШЁЕНЕФЫ§ЗУЮЪЕФвГУцвдМАЕуЛїЕФВњЦЗЪ§ОнЕШШежОЪ§ОнаХЯЂЪеМЏВЂвЦНЛИјHadoopЦНЬЈЩЯШЅЗжЮі.ЖјFlumeе§ЪЧАяЮвУЧзіЕНетвЛЕуЁЃЯждкСїааЕФФкШнЭЦЫЭЃЌБШШчЙуИцЖЈЕуЭЖЗХвдМАаТЮХЫНШЫЖЈжЦвВЪЧЛљгкДЮЃЌВЛЙ§ВЛвЛЖЈЪЧЪЙгУFLume,БЯОЙгХауЕФВњЦЗКмЖрЃЌБШШчfacebookЕФScribeЃЌЛЙгаApacheаТГіЕФСэвЛИіУїаЧЯюФПchukwaЃЌЛЙгаЬдБІTime
TunnelЁЃ
3.FlumeЕФгХЪЦ
1. FlumeПЩвдНЋгІгУВњЩњЕФЪ§ОнДцДЂЕНШЮКЮМЏжаДцДЂЦїжаЃЌБШШчHDFS,HBase
2. ЕБЪеМЏЪ§ОнЕФЫйЖШГЌЙ§НЋаДШыЪ§ОнЕФЪБКђЃЌвВОЭЪЧЕБЪеМЏаХЯЂгіЕНЗхжЕЪБЃЌетЪБКђЪеМЏЕФаХЯЂЗЧГЃДѓЃЌЩѕжСГЌЙ§СЫЯЕЭГЕФаДШыЪ§ОнФмСІЃЌетЪБКђЃЌFlumeЛсдкЪ§ОнЩњВњепКЭЪ§ОнЪеШнЦїМфзіГіЕїећЃЌБЃжЄЦфФмЙЛдкСНепжЎМфЬсЙЉвЛЙВЦНЮШЕФЪ§Он.
3. ЬсЙЉЩЯЯТЮФТЗгЩЬиеї
4. FlumeЕФЙмЕРЪЧЛљгкЪТЮёЃЌБЃжЄСЫЪ§ОндкДЋЫЭКЭНгЪеЪБЕФвЛжТад.
5. FlumeЪЧПЩППЕФЃЌШнДэадИпЕФЃЌПЩЩ§МЖЕФЃЌвзЙмРэЕФ,ВЂЧвПЩЖЈжЦЕФЁЃ
4. FlumeОпгаЕФЬиеїЃК
1. FlumeПЩвдИпаЇТЪЕФНЋЖрИіЭјеОЗўЮёЦїжаЪеМЏЕФШежОаХЯЂДцШыHDFS/HBaseжа
2. ЪЙгУFlumeЃЌЮвУЧПЩвдНЋДгЖрИіЗўЮёЦїжаЛёШЁЕФЪ§ОнбИЫйЕФвЦНЛИјHadoopжа
3. Г§СЫШежОаХЯЂЃЌFlumeЭЌЪБвВПЩвдгУРДНгШыЪеМЏЙцФЃКъДѓЕФЩчНЛЭјТчНкЕуЪТМўЪ§ОнЃЌБШШчfacebook,twitter,ЕчЩЬЭјеОШчбЧТэбЗЃЌflipkartЕШ
4. жЇГжИїжжНгШызЪдДЪ§ОнЕФРраЭвдМАНгГіЪ§ОнРраЭ
5. жЇГжЖрТЗОЖСїСПЃЌЖрЙмЕРНгШыСїСПЃЌЖрЙмЕРНгГіСїСПЃЌЩЯЯТЮФТЗгЩЕШ
6. ПЩвдБЛЫЎЦНРЉеЙ
3. FlumeЕФНсЙЙ
1. flumeЕФЭтВПНсЙЙЃК
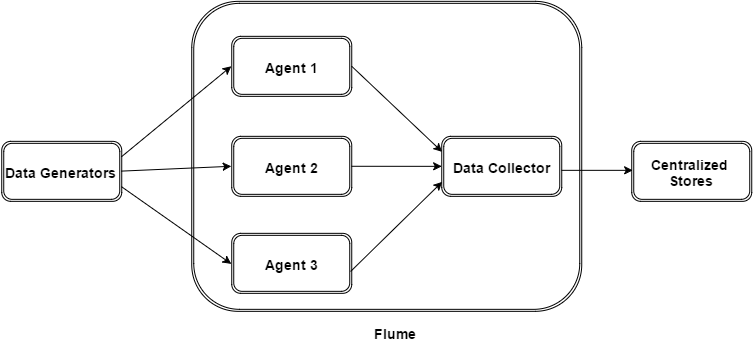
ШчЩЯЭМЫљЪОЃЌЪ§ОнЗЂЩњЦїЃЈШчЃКfacebook,twitterЃЉВњЩњЕФЪ§ОнБЛБЛЕЅИіЕФдЫаадкЪ§ОнЗЂЩњЦїЫљдкЗўЮёЦїЩЯЕФagentЫљЪеМЏЃЌжЎКѓЪ§ОнЪеШнЦїДгИїИіagentЩЯЛуМЏЪ§ОнВЂНЋВЩМЏЕНЕФЪ§ОнДцШыЕНHDFSЛђепHBaseжа
2. Flume ЪТМў
ЪТМўзїЮЊFlumeФкВПЪ§ОнДЋЪфЕФзюЛљБОЕЅдЊ.ЫќЪЧгЩвЛИізЊдиЪ§ОнЕФзжНкЪ§зщ(ИУЪ§ОнзщЪЧДгЪ§ОндДНгШыЕуДЋШыЃЌВЂДЋЪфИјДЋЪфЦїЃЌвВОЭЪЧHDFS/HBase)КЭвЛИіПЩбЁЭЗВПЙЙГЩ.
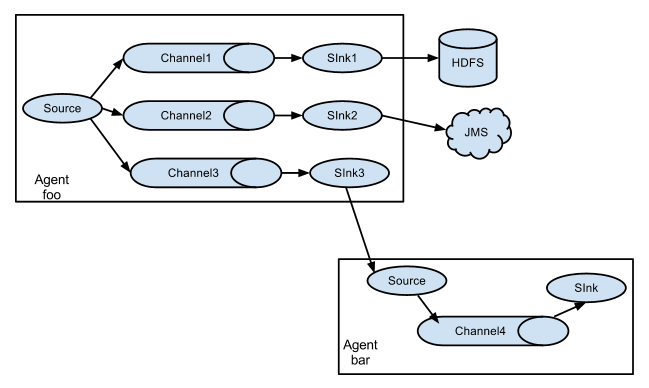
ЕфаЭЕФFlume ЪТМўШчЯТУцНсЙЙЫљЪОЃК

ЮвУЧдкНЋeventдкЫНШЫЖЈжЦВхМўЪББШШчЃКflume-hbase-sinkВхМўЪЧЃЌЛёШЁЕФОЭЪЧeventШЛКѓЖдЦфНтЮіЃЌВЂвРОнЧщПізіЙ§ТЫЕШЃЌШЛКѓдкДЋЪфИјHBaseЛђепHDFS.
3.Flume Agent
ЮвУЧдкСЫНтСЫFlumeЕФЭтВПНсЙЙжЎКѓ,жЊЕРСЫFlumeФкВПгавЛИіЛђепЖрИіAgent,ШЛЖјЖдгкУПвЛИіAgentРДЫЕ,ЫќОЭЪЧвЛЙВЖРСЂЕФЪиЛЄНјГЬ(JVM),ЫќДгПЭЛЇЖЫФФЖљНгЪеЪеМЏ,ЛђепДгЦфЫћЕФ
AgentФФЖљНгЪе,ШЛКѓбИЫйЕФНЋЛёШЁЕФЪ§ОнДЋИјЯТвЛИіФПЕФНкЕуsink,Лђепagent. ШчЯТЭМЫљЪОflumeЕФЛљБОФЃаЭ
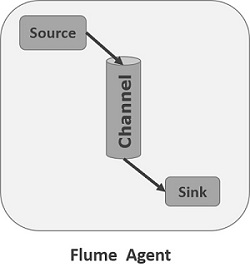
AgentжївЊгЩ:source,channel,sinkШ§ИізщМўзщГЩ.
Source:
ДгЪ§ОнЗЂЩњЦїНгЪеЪ§Он,ВЂНЋНгЪеЕФЪ§ОнвдFlumeЕФeventИёЪНДЋЕнИјвЛИіЛђепЖрИіЭЈЕРchannal,FlumeЬсЙЉЖржжЪ§ОнНгЪеЕФЗНЪН,БШШчAvro,Thrift,twitter1%ЕШ
Channel:
channalЪЧвЛжжЖЬднЕФДцДЂШнЦї,ЫќНЋДгsourceДІНгЪеЕНЕФeventИёЪНЕФЪ§ОнЛКДцЦ№РД,жБЕНЫќУЧБЛsinksЯћЗбЕє,ЫќдкsourceКЭsinkМфЦ№зХвЛЙВЧХСКЕФзїгУ,channalЪЧвЛИіЭъећЕФЪТЮё,етвЛЕуБЃжЄСЫЪ§ОндкЪеЗЂЕФЪБКђЕФвЛжТад.
ВЂЧвЫќПЩвдКЭШЮвтЪ§СПЕФsourceКЭsinkСДНг. жЇГжЕФРраЭга: JDBC channel , File
System channel , Memort channelЕШ.
sink:
sinkНЋЪ§ОнДцДЂЕНМЏжаДцДЂЦїБШШчHbaseКЭHDFS,ЫќДгchannalsЯћЗбЪ§Он(events)ВЂНЋЦфДЋЕнИјФПБъЕи.
ФПБъЕиПЩФмЪЧСэвЛИіsink,вВПЩФмHDFS,HBase.
ЫќЕФзщКЯаЮЪНОйР§:
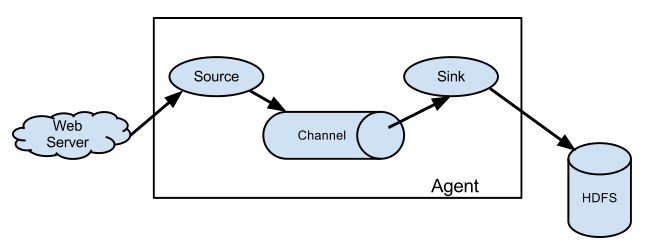
вдЩЯНщЩмЕФflumeЕФжївЊзщМў,ЯТУцНщЩмвЛЯТFlumeВхМў:
1. InterceptorsРЙНиЦї
гУгкsourceКЭchannelжЎМф,гУРДИќИФЛђепМьВщFlumeЕФeventsЪ§Он
2. ЙмЕРбЁдёЦї channels Selectors
дкЖрЙмЕРЪЧБЛгУРДбЁдёЪЙгУФЧвЛЬѕЙмЕРРДДЋЕнЪ§Он(events). ЙмЕРбЁдёЦїгжЗжЮЊШчЯТСНжж:
ФЌШЯЙмЕРбЁдёЦї: УПвЛИіЙмЕРДЋЕнЕФЖМЪЧЯрЭЌЕФevents
ЖрТЗИДгУЭЈЕРбЁдёЦї: вРОнУПвЛИіeventЕФЭЗВПheaderЕФЕижЗбЁдёЙмЕР.
3.sinkЯпГЬ
гУгкМЄЛюБЛбЁдёЕФsinksШКжаЬиЖЈЕФsink,гУгкИКдиОљКт.
|






