| ����Ҫ��
��������һ��ģ������ѧ�Ļ���ѧϰģ�ͣ�������Դ������㲢�������и��ּ�����ֵ�Ľڵ㡣
�ݹ���������һ�������뱻����֮ǰ�������ڲ�����������磬�������ǿ��Խ�����������ʱ�������Ľṹ��ѧϰ��
����ѧϰ�����������Ʒ�з��ӹ������ˣ������ճ�����ܶ�������������ƻ����Siri�ȸ��Now֮��ġ����ܡ����֣���������ѷ�������²�Ʒ���Ƽ����棬�ٵ��ȸ��Facebookʹ�õ�����ϵͳ���������֣���һ���㡣���������ѧϰ���ڡ����ѧϰ���Ľ�չ�����˹�����Ұ����Щ��չ����AlphaGo������Χ���ʦ�����h���Լ�Χ��ͼ��ʶ��ͻ������뷽�潾�˵��²�Ʒ��
�ڱ�ϵ�е������У����ǽ������ڻ���ѧϰ����ǿ����ֿ����ձ�Ӧ�õļ�������Щ���������������ִ���ҵ����Ҫ�ĸ���ͳ�ķ��������������ѧϰ�����Ķ���ϵ������֮����Ӧ�þ;߱��ڸ������Լ������������н��о������ѧϰʵ��ı�Ҫ�����ˡ�
��ƪ������ϵ�����¡�����ѧϰ��顱���е�һ���֣������ͨ��RSS�����Խ���֪ͨ��
���������������ͼ��ʶ��֮����������������Խ��Խ�ߵľ�ȷ���Ѿ������ҵĹ�ע�����������ѧϰ���˹����ܵ��о�Ҳ��Ϊ�ձ��ˡ����㷺�ռ�Ҳ�����˳�ͻ�����Ľ��������磬������ǰ��������͵ݹ�������ļ�Ҫ˵��������������ι���һ�����ʱ�������������쳣����ĵݹ������硣Ϊʹ���ǵ����۸����壬���ǽ���ʾ�����Deeplearning4j���������磬����һ������JVM�Ŀ�Դ���ѧϰ��⡣
ʲô�������磿
��������������������ģ������ѧ��Ԫ���㷨��Ȼ��������һ���ܷ�������ȡ���������������������ѧ��Ԫ�Ĺ��ܰ����ڵ�֮������Ӻ����ÿ����Ԫ�����ļ�����ֵ����������
ͨ������һ������������Ԫ��ϵͳ�����Ƿ���ϵͳ���Ա�ѵ��ȥ��ʶ�����и��߲�ε�ģʽ�����������õ����ã�����ݹ顢���ࡢ�����Ԥ�⡣
������Ϊ������Ԫ��ԶԶ������������������һϵ�м���ڵ㣬�ڴ����ݱ�ʾΪ�������飬��Щ���������������㴫�룬ͨ��������ν�����ز㣬ֱ����һ������������������Щ������ص��������ߣ����Ľ���Ҫ��������������̡�Ȼ��Ѹ���������������Ԥ��������Ƚϣ�����Ӧ������Щ�����ϵĵر�ʵ����ǩ������������Ʋ����ȷ��֮��IJ�����������������ڵ�ļ�����ֵ������������̵��ظ�����������������Ԥ������غϡ�
ӵ������ڵ���������������������һ̨�����Ļ����ϡ�һ��Ҫע�⣬��������粻һ��Ҫ�ڶ�̨�����ķֲ�ʽϵͳ�С��ڵ㣬�ڴ���ζ�š����㷢���ĵط�����
ѵ������
Ϊ����һ�������磬����Ҫ��ѵ�����̺������������γ��л��������⡣��Ϊ���Dz������뵽����ʽ����Լ�Ҫ�������£�
���������ڵ����һ���������飨������һ����֮Ϊ�����Ķ�ά���飩��ʾ�������ݡ����磬һ��ͼƬ��ÿ�����ؿ���ͨ��һ����������ʾ��Ȼ���ṩ��һ���ڵ㡣��Щ��������ͨ��ϵͳ����������ݣ�ͨ����Щϵ���ij˷����㽫�Ŵ�������Щ���룬����������ѧ������Ҫ�ԣ����������Ƿ��Ӱ�쵽���������������ľ��ߡ�
�����ϵ��������ģ����紴������ʱ���ڽṹ������һ����֪��ÿ���ڵ�ļ���������˽ڵ��һ�������һ���������������Խڵ�������ȡ�����������յĴ̼���ǿ�ȣ������ϵ���ķ���ֵ���Ƿ��˼������ֵ��
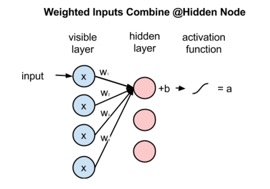
��һ����ν�����ܻ���ȫ���Ӳ㣬ÿ���ڵ������ᴫ�ݵ�������ĵ����нڵ㡣�������ͨ�������������ܲ㣬ֱ�������Ϊֹ�����������ɵľ��ߵĵط������������㣬�������������ľ��������Ԥ�ھ��ߵ����������磬���ͼƬ�е����ر�ʾ����ֻè����ֻ��������ͨ���ȶ�����IJ²�Ͱ����ڲ��Լ��е�ʵ�ʴ���������Ȼ��ʹ����Щ�����������ϵ�����Ӷ��ı�����ΪͼƬ�в�ͬ���ظ������Ҫ�Եij̶ȡ�Ŀ���Ǽ������γɵ������Ԥ�����֮��Ĵ�����ȷ�ر�ʶ�����ǹ�����è��
��Ϊ���ѧϰ��һ�����ӵĹ��̣����������������������Ʒ����Ȼ�ʺ��ܼ���Ӳ�������ʣ���ͬ���Ĵ���ϵ������һ�㣬���Բ���Ҫ�����и����Զ���ʾ�������û���
Ȼ������Ӧ��֪��һЩ�����������������纯���Ļ��������������Ǽ����������Ż��㷨�Լ�Ŀ�꺯����Ҳ��֮Ϊ��ʧ���ɱ�����������
�ü��������һ���ź��Ƿ�Ӧ�÷��͵����ӵĽڵ��Լ����͵ķ�Χ��Ƶ���õ��ļ������һ�������Ľ��ݺ�������������������һЩ��ֵ��Ϊ0��������Щ��ֵ��Ϊ1����ˣ����н��ݺ���������Ľڵ�Ҫô�����ӵĽڵ㷢��0��Ҫô����1���Ż��㷨�����������ѧϰ������ȷ��˵�Ǽ����������Ȩ�ء�ͨ��ʹ�õ��Ż��㷨������ݶ��½�����ɱ���������Ԥ�������ȵ����Ķ��������ڶԸ���ѵ������������ʱ��������ִ������Ĺ�����
������Python��Keras ������JVM��Deeplearning4j ֮��Ŀ�Դ���ʹ������Ĺ������Ժܿ����֡���������ʲô����ܹ������漰�������������������֪�ѽ�����������ƥ�䣬Ȼ��������еļܹ�ȥ��Ӧ���ʹ�ó�����
����������ͼ���Ӧ��
��ʮ�������������Ѿ���Ϊ��֪���õ��˹㷺��ʹ�á���������Ҫ��������ʹ��������������Ч�ʵõ������������
����GPU�Ծ�����������٣��Լ����ͷֲ�ʽ�����ܵĵ��������������õ��˴�������������Ϊ����ѵ�������紴�����������Ӷ��������೬���������Ѹ�ٵ�����Ѱ�Һ��ʵļܹ���
���ģ���ݼ������γɣ���ImageNet֮����ģ�������ı�ǩ���ݼ��Ѿ����������ˡ�һ����˵������ѧϰ�㷨ѵ��������Խ�࣬���Խ��ȷ��
�����������������������㷨����Ҳ��ǿ�ˣ���ʹ�������ڼ�����Ӿ���������ʶ�������������������������֪������Ŀ�������ı����в���ˢ�¾�ȷ�Եļ�¼��
��Ȼ������ܹ�������dz��������ڴ����������Ѿ��㷺Ӧ�õ���Ҫ���������͡�
ǰ��������
����һ����һ������㡢һ��������һ���������ز�������硣ǰ������������õķ��ƽ�����ӳ���κ����뵽�κ�����ĺ������������ڹ�������;��ģ�͡�
����������������ڷ���͵ݹ顣���磬���ʹ��ǰ���������������ϵ�������Ԫ���з��࣬���������������һ���ġ��Ӹ����Ͻ��������Ԫ��һ�ξ��������������Ԥ������ġ�����ȷ��˵��ÿ�������Ԫ����һ���ü�¼ƥ�����Ŀ����ԣ�Ȼ��ѿ�������ߵ����ѡ��ģ�͵�������ࡣ
����֪��֮���ǰ��������ĺô�������ʹ�ã���������������ĸ��Ӷ�Ҫ�ͣ������ҵ����ָ�����ʵ����
����������
������������ǰ�����������ƣ������������ϴ������ݵķ�ʽ��һ���ġ����Ǵ���ʽ�ϴ���ģ��������Ĵ���Ƥ�ʡ���������һ���ײ�ͼ�����ƶ�������Ŵ�֮����˲�������Щ�˲���רע��ͼ���Ӽ�����Ƭ����Ƭ��������ʶ��Ȼ�������ϵ�һϵ����Ƭ���ظ�������̡�ÿ���˲���Ѱ�ҿ��ӻ������еIJ�ͬģʽ�����磬�еĿ���Ѱ�ҵ���ˮƽ�ߣ��еĿ���Ѱ�ҵ��ǶԽ��ߣ����еĿ���Ѱ�ҵ��Ǵ�ֱ�ߡ���Щ������֪���������˲�����ͼ���Ͼ��������ǹ�������ͼ��λÿ����ÿ����ͼ���г��ֵIJ�ͬ��λ��ͼ���в�ͬ�Ķ���Сè������747��ת���е�ե֭�����γɲ�ͬ������ͼ�ף���Щͼ�����տ�����ͼ����ࡣ��ͼ�����Ƶʶ��������֤����������dz����ã���Ϊ��������������ͼ����ʽ���ӻ���ʾ���������Ծ�������ͬ�����Թ㷺Ӧ��������ʶ��ͻ���ת¼�������ϡ�
������ǰ��������ͼ��������ĶԱȡ������������Ͷ����Է���ͼ�����ǵķ�����ʽ�Dz�ͬ�ġ���Ϊ������������һ����ͨ��ͼ����ص�����ѵ��ѧ��ʶ��ÿ������������ģ���ǰ����������������ͼ����ѵ���ġ�ǰ�����������������Ǵ����ض�λ�û����ͼ���Ͻ���ѵ�����������������һ����������λ�ÿ��ܾ�ʶ���ˣ����õ����ѵ���ľ����������ǿ��������ġ�
���������粻������������ͼ����Ƶ������������ʶ��֮������������������Զ���Ԧ������
��ƪ���¹�ע���ǵݹ������磬�������������Ѿ���ͼ��ʶ�������÷dz����ˣ�����Ӧ���˽����ǵĹ��á�
�ݹ������磨RNN��
��ǰ�������粻ͬ���ݹ�����������ز�ڵ�ά��һ���ڲ�״̬��һƬ�ڴ棩�����������µ�����ʱ�����������Щ�ڵ㼴���Ի��ڵ�ǰ���������ߣ�Ҳ���Ը���֮ǰ�����������ߡ��ݹ����������ʹ���ڲ�״̬ȥ�������������������������ݣ�����ʱ�����С�
���ǿ������ڱʼ�ʶ������ʶ����־��������թ��⡢���簲ȫ��
���ڰ���ʱ��ά�ȵ����ݼ���˵��������ҳ������������־����Ӳ����ҽ���豸�����Ĵ��������ݣ�����������ͨ����¼�����ݹ�������������ʵġ����ٿ�����ʱ�䲽�������ڵ�������ϵ�����ϵ��Ҫ���˽ǰ״̬��֮ǰ��һЩ״̬������ʹ�ý����¼����ڵĵ���ǰ�����������Ҳ���������������ô��ڻ���ʱ�䷢���䶯����һ����������Ǿ����ɸô��ڲ���������ϣ�����������
��ʱ������Ƹ��ٳ���������һ�ָ��õķ����ǣ�ij�ִ洢��������¼��ġ����䡱��������ʹ֮����¼��������������е�������ͷ��ࡣ�ݹ�������֮�����ڣ��������������ز����Ρ����䡱�ڷdz����ڵ�ʱ�䴰����ѧϰ���Լ����ϵ���Щʱ���������������塣
�������У����ǽ�̽�ֵݹ��������Ӧ�ã������ַ�������Ҳ�������쳣��⡣������ʱ�䲽�������������������ʹ�ݹ������������ʱ�����������е��쳣��⡣
�ݹ��������Ӧ��
�������ǵ�ʾ����һ������������ϵļ�ػ��������������Ϊ��ʼ�ݹ����������۵ļ��������Ǻ��а����ġ�������������ʹ�õݹ������������ı��İ�����һ��һ���ַ����ڽ���һ���Ͽ��ı���ѵ��֮��ȥԤ��֮ǰ������Ϣ����һ���ַ���ʲô��
�����ַ����ɵĵݹ�������
�ݹ�������ɱ�ѵ������һϵ��ʱ�������¼�ȥ����Ӣ���ַ��������罫ѧϰƵ������һ���ַ�֮�����һ���ַ��������ڡ�the������he���͡�she����e���ڡ�h����Ȼ���������Ԥ����һ���ַ�������ͨ����ʵ��Ӣ���ı��Ա�ѵ����������
���ṩһ����ɯʿ����ʱ�����������ɸ��˵�ɯʿ���Ƿ�������ˣ����硰Ϊʲô��Salisbury�����ҵ������������ꡭ���������ṩ�㹻���Java����ʱ�������ɵĶ��������ܹ����롣
Java��һ������˼�����ӣ���Ϊ���Ľṹ�����ܶ���Ƕ������ÿ�������ţ��������������ն������رգ�������������ÿ���Ĵ����ţ������������ڸ���֮�¶�����һ���رյĴ����ţ���������������Щ������λ�ò���һ��������һ���ģ������¼���Ӱ�쵽���ľ��롣���ظ�������Щ�����ṹ���ݹ��������ȥѧϰ���ǡ�
���쳣����У����ǽ�Ҫ��������ȥѧϰ���������Ƶġ��������λ����Ե�ģʽ�������ַ������߳���������ݽṹȥ����ģ���ַ�һ���������쳣���ĵݹ����������������ݵĽṹ�Ի�֪ʲô�������������ģ���ʲô���ǡ�
�ַ����ɵ�����������չʾ�ݹ�����������ڲ�ͬʱ�䷶Χ֮��ѧϰʱ���������������ݹ���������Խ�ͬ������������������־�е��쳣����С�
Ӧ�õ��ı��У��쳣������Ҫ����������Ϊ������д������������ṹ�ġ�ͬ���ģ�������ΪҲ�нṹ������ѭ�ɱ�ѧϰ�Ŀ�Ԥ��ģʽ���ܹ�����������Ϊѵ���ĵݹ�������Ὣ�������ָ�֪������������ޱ��ľ�����Ϊ�쳣һ����
�����쳣�����Ŀʾ��
����������Ҫ��������쳣����Щ�쳣����ָ��Ӳ�����ϡ�Ӧ�ù��ϻ����֡�
���ǵ�ģ�ͽ�Ϊ���ǽ�ʾʲô
�ݹ������罫��������־������չ���Ͻ���ѵ��������־�е�ԭ������ı�����������ת��Ϊ����������
ͨ���ṩ������������־��ÿ����־����һ��ʱ��������ݹ������磬�ݹ������罫�˽�����Ԥ�ڵ�������ʲô���ġ����������������İ����ṩ��ѵ����������ʱ�������ܹ���������������Ԥ�ڵģ��������ֵ��ˡ�
ѵ��һ��������ȥʶ��Ԥ����Ϊ��һ�������������ƣ���Ϊ��ӵ�д������쳣���ݣ����������Ծ�ȷ����������쳣��Ϊ���������Լ�ӵ�е�����������ѵ�����磬�Ա�������������ע��δ���ķ�������Ϊ������Թ�����ѵ��Ҳ���ڳ�ֵ�������ѵ���ġ�
˵�����⻰����ѵ�������粻��Ҫ˵���������ض�ʱ����ض��������֪������������������ӣ���������ע�����Ӧע�����Щ�Ƚ����Ե�ʱ��ģʽ���Լ����ܲ������Ե��¼����������ϵ��
���ǽ�����һ�����ʹ��Deeplearning4j������������⣬����һ�����㷺���õĿ�Դ��⣬��������JVM�ϵ����ѧϰ������Deeplearning4jһ������Ļ�������ߣ���Щ����������ģ�Ϳ��������к��а�����DataVec�Ǹ�����ȡת�Ƽ��أ�ETL�������һϵ�й��ߣ�����Ϊģ��ѵ�������ݡ�����Sqoop�����ڼ������ݽ�Hadoopһ����DataVecͨ�����ݵ�������Ԥ��������ͱ����Ӷ����������ݼ��ؽ������硣
��������
��һ�������������͵Ĵ����������ETL��������Ҫ�ռ���Ǩ�ơ��洢���������ʸ������־��ʱ�䲽���Ĺ�ģ����Ҫȷ������������ת��������Ҫ�ܴ�Ĺ���������ΪJSON��־���ı���־�;��в���ɱ�ǩģʽ����־�����뱻��ȡ��ת��Ϊ���顣DataVec������ת�������Щ���ݡ��ڿ�������ѧϰģ��ʱ��Ϊһ�ֳ�̬����Щ���ݱ���ֽ�Ϊѵ�����ͼ��飨������������
�����ѵ��
��������ѵ��������Щ�ֽ��������ݵ�ѵ�������С�
��Ե�һ��ѵ�������У��������Ҫ����һЩ�������������������ǹ���ģ�͵ġ����á��Լ�����ν���ѵ���IJ������Ա�ģ����ʵ��������ѧϰ�����ں�����ʱ������ô�������ǽ�̽�����¼�������������ģ��ѵ����ͬʱ����Ӧ��Ѱ���ȶ��ؽ�����
Ҫע��һ�����գ��Ǿ���������ģ�ͽ���������ϡ����ݡ��ڹ�����ϵ����ݼ���ѵ������ģ�ͽ��ڸ�ѵ�������������õı��֣�������֮ǰδ�����������ݾ���������ȷ���ж��ˡ�������ѧϰ��˵�����ⲻ�ǡ����ɡ���Deeplearning4J�ṩ�����滯���ߺ͡�������ֹ�����Ӷ������ڱ���ѵ�������еĹ�����ϡ�
�������ѵ����ռ�ô�ʱ���Ӳ������GPU��ִ��ѵ�����������ѵ����ʱ�䣬�ر��������ͼ��ʶ����˵���������Ӳ�����������ijɱ���������������ѧϰ�ܹ������ܸ�Ч��ʹ��Ӳ����Ϊ��Ҫ��������Azure������ѷ֮����Ʒ����ṩ�˿��Է��ʻ���GPUʵ���Ĺ��ܣ�������������칹��Ⱥ�Ͻ���ѵ�������ּ�Ⱥ�в���������ר�õĻ���������������ҵ��������
ģ�͵��γ�
Deeplearning4J�ṩ��һ��ModelSerializer��ȥ�������ѵ����ģ�͡�һ������ѵ����ģ�Ϳ��Ա�����������֮������ѵ��ʹ�ã����磬������������������¡�
������������ִ�������쳣���ʱ����־�ļ���Ҫ�����л�Ϊͬһ��ʽ��ģ�������Ͻ���ѵ����Ȼ��������������������õ����棬����ǰ��Ƿ�������Ԥ�ڵ�������Ϊ֮�ڡ�
ʾ������
�ݹ�����������ÿ��ܿ������������ģ�
MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder()
.seed(123)
.optimizationAlgo
(OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT).iterations(1)
.weightInit(WeightInit.XAVIER)
.updater(Updater.NESTEROVS).momentum(0.9)
.learningRate(0.005)
.gradientNormalization(GradientNormalization.ClipElementWiseAbsoluteValue)
.gradientNormalizationThreshold(0.5)
.list()
.layer(0, new GravesLSTM.Builder().activation("tanh").nIn(1).nOut(10).build())
.layer(1, new RnnOutputLayer.Builder(LossFunctions.LossFunction.MCXENT)
.activation("softmax").nIn(10).nOut(numLabelClasses).build())
.pretrain(false).backprop(true).build();
MultiLayerNetwork net = new MultiLayerNetwork(conf);
net.init(); |
��������˵��һ�¼�����Ҫ�Ĵ��룺
Ϊ��ÿ��ظ��Ľ���������������ȥ��ʼ���������Ȩ�ء���������£��������ʼ��ϵ����Ϊ���ڵ�������������ʱ��ȡһ�µĽ����������Ҫ����һ�����ӣ�ʹ�����ܹ�һ��һ�������У��ʱ����ʹ��ͬ�������Ȩ�ء�
.optimizationAlgo
(OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT)
.iterations(1) |
ѡ��ʹ���ĸ��Ż��㷨���ڱ����У�ѡ���������ݶ��½���ȥ���������Ȩ���ԸĽ����÷֡�����ܲ�ϣ��ȥ������
ʹ������ݶ��½�ʱ������ݶȣ���ϵͳ�仯���������仯�Ĺ�ϵ�������������Ȼ��Ȩ���ش��ݶ��ƶ���ͼ������������С������ݶ��½�Ϊ����ָ���˼������ķ���ѧϰ�ʾ�������������ϵIJ����ж�����ѧϰ�ʹ��ߣ����������С������ͷ�������̫�ͣ���ôѵ����������ֹ������һ���������Ҫȥ�����ij�������
|






