| 前言
Big SQL, 是 IBM 依托其在 RDBMS 领域多年的技术积累,并结合当前大数据领域许多先进技术推出的
SQL-on-Hadoop 产品。与市场上其它产品如 Hive 不同,Big SQL 通过在 Hadoop
上运行大规模并行处理 (MPP) SQL 引擎来替代 MapReduce,极大地提高了查询速度。Big
SQL 以其无与伦比的 SQL 兼容性、丰富的企业及应用特性和各种数据源的联邦功能以及对 Hadoop
生态系统良好的支持性,为 SQL 开发人员提供了各种方式来查询和访问 Hadoop 管理的数据。内部测试表明,Big
SQL 返回结果的速度比 Apache Hive 1.2 平均快 20 倍,对于个别查询而言,其性能提升了
10 到 70 倍。为了直观地演示,作者用最新 Big SQL 4.2 和 Hive 1.2.1 做了一个简单测试,创建一张
Hadoop 表 admission 并向其中加载 20000000 行数据,然后分别通过 Hive 和
Big SQL 来查询表中所有的记录数。
清单 1. Big SQL 测试查询示例
[bigsql] 1> SELECT COUNT(*) FROM admission;
+----------+
| 1 |
+----------+
| 20000000 |
+----------+
1 row in results(first row: 0.979s; total: 0.980s) |
清单 2. Hive 测试查询示例
hive> SELECT COUNT(*) FROM admission;
OK
20000000
Time taken: 30.808 seconds, Fetched: 1 row(s) |
在上述测试场景中,Big SQL 的查询速度比 Hive 快大约 30 倍,显示出 Big SQL 强大的查询性能以及相对于其它同类产品巨大的性能优势。本文将主要介绍
Big SQL 为了增强查询性能而引入的 Hadoop 表分区以及分区消除特性。
场景介绍
我们知道,Hive 是最早的 SQL-on-Hadoop 产品,并且开源,所以目前基本所有的 Hadoop
分发版本都包含了 Hive,IBM BigInsights 也包含了 Hive。在 Big SQL 中,我们除了可以定义普通
DB2 语法的表,还可以创建 Hadoop 表和 Hbase 表,其中 Hadoop 表就是通过 Hive
Catalog 来定义的,数据存储在 Hive 中,其实质就是 Hive 表。基于前面提到的 Big SQL
相对于 Hive 所具有的性能优势,用户可以通过 Big SQL 高效查询存储在 Hive 数据仓库中的海量数据。
在 RDBMS 中,当数据量较大时,为了便于管理,经常需要创建和使用分区表。创建分区,实际上就是将表中的数据分成更小的子块,简单地说,就是把一张大表分成若干小表。每个分区可以单独管理,可以不依赖其他分区而单独发挥作用,因此可以提供更有利于可用性和性能的结构。创建分区之后,逻辑上表仍然保持其完整性,只是物理上将表中的数据存放到多个物理文件上。查询时可以通过适当的谓词过滤掉一些分区,而不需要每次都扫描整张表,从而获得查询性能的提升。
对于企业级用户,例如银行,需要将其过去十几年甚至几十年的历史交易数据存储在数据仓库中。现在假设一个场景,用户需要查询某个特定年份的交易信息,可以想象一下,面对海量的历史数据,如果用户每一次查询都需要扫描表中所有数据来得到符合条件的记录,那么其效率将会变得令人难以忍受。但是如果用户将数据按照交易时间进行分区存储和管理,那么查询时就只需要扫描特定时间分区中的数据,可以大大地节省查询时间。
Big SQL 支持表分区和分区消除,而对于 Hadoop 表,在最新的 4.2 版本中,除了支持基于列进行分区,还支持基于列表达式进行分区。所以对于上述场景,用户可以通过
Big SQL 基于列表达式分区的功能,利用 YEAR() 或 MONTH() 等时间函数基于已有的日期类型的列来定义分区。
Hadoop 分区表
在 Big SQL 中,Hadoop 表是通过 Hive Catalog 来定义的,数据也是存储在 Hive
中。创建 Hadoop 分区表并插入数据后,在分布式文件系统 (DFS) 上就会根据每个分区生成一个目录,表中每个分区的数据就存放在对应的目录下。对于有多个分区键的情况,则会根据分区键定义的顺序,逐层创建对应的目录,即根据第一个分区键创建一级目录,然后再根据第二个分区键在各个一级目录中创建二级目录,以此类推。
基本语法
Big SQL 4.2 创建 Hadoop 分区表的基本语法如下所示。
清单 3. 创建 Hadoop 分区表基本语法
.-HADOOP-----
>>-CREATE--+----+--+-----+--TABLE---+--table-name-->
'-EXTERNAL-' '-IF NOT EXISTS-'
+-PARTITIONED BY -| partitioning-element-list |----+
partitioning-element-list
.-,-------------------.
V |
|--(--+-| column-definition |----+--)-----------|
+-| partition-expression |-+
partition-expression
|--expression-AS-identifier--| |
PARTITIONED BY 从句用来定义分区键,分区键可以是数据列本身,也可以是基于数据列的一些表达式。需要注意的是,如果以数据列的表达式作为分区键,要在前面先定义这些列。
Big SQL 4.2 中,下列数据类型的列不能作为分区键。
ARRAY
ROW
而基于列表达式的分区,支持但不限于下列表达式。
运算符: +, -, *, /
标量函数: MOD(), HASH(), SUBSTRING(), LEFT(), RIGHT(), YEAR(),
MONTH(), DAY()
下列表达式不能作为分区表达式。
Subqueries
XMLQUERY or XMLEXISTS expressions
Column functions
Dereference operations or DEREF functions
User-defined or built-in functions that are non-deterministic
User-defined functions using the EXTERNAL ACTION option
User-defined functions that are not defined with NO
SQL
Host variables or parameter markers
Special registers and built-in functions that depend
on the value of a special register
Global variables
References to columns defined later in the column list
References to other generated columns
References to columns of type XML
下面通过一个实例来说明如何创建 Hadoop 分区表。在前面的场景介绍中我们提到了银行存储历史交易数据的例子,假设其交易流水信息如下表所示。
表 1. 银行交易流水信息
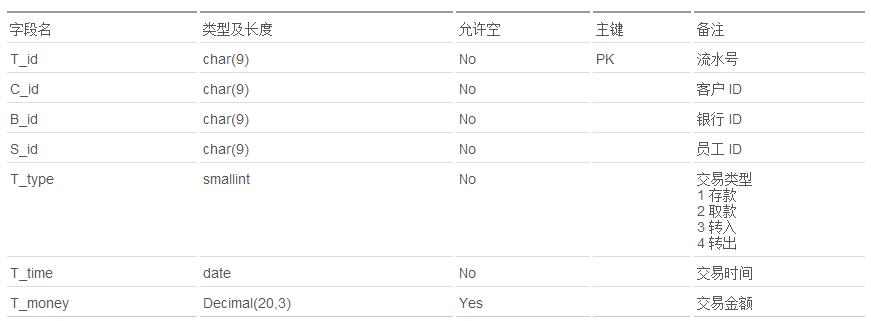
现在用户需要按照交易年份和月份来组织和管理这些数据,并同时按照交易类型把数据分类存储。基于用户需求,这里可以同时利用
Big SQL 基于列和列表达式分区的功能。首先通过 YEAR() 和 MONTH() 函数来定义两个基于交易时间的分区键,然后再直接将交易类型列定义为分区键。
清单 4. 创建 Hadoop 分区表示例
CREATE HADOOP TABLE transaction_info(
T_id char(9) not null,
C_id char(9) not null,
B_id char(9) not null,
S_id char(9) not null,
T_time date not null,
T_money decimal(20,3),
PRIMARY KEY (T_id))
PARTITIONED BY (
YEAR(T_time) AS P_year,
MONTH(T_time) AS P_month,
T_type smallint not null); |
创建好 Hadoop 分区表,只有在向数据表中加载数据之后,分布式文件系统上才会按照各个分区键的值生成对应目录。通常有三种方式向
Hadoop 表中加载数据,通过 INSERT 或者 LOAD 命令,也可以在创建表的语句中通过 LOCATION
从句来指定一个分布式文件系统的路径,然后将数据以文件的形式存放到该指定路径下。这里需要指出,对于基于列表达式的分区键,我们通过
INSERT 插入数据时,Big SQL 会根据表达式自动计算出分区值,但是对于 LOAD 或 LOCATION
命令,则需要用户事先根据表达式计算出正确的分区值并保存到数据文件中,且 Big SQL 不会校验这些数值是否正确。向上述分区表中插入几行数据。
清单 5. 插入数据示例
INSERT INTO transaction_info
VALUES
('T00000001','C00000001','B00000001','S00000001','2008-01-12',
100000.000,DEFAULT,DEFAULT,1),
('T00000002','C00000002','B00000001','S00000002','2008-01-21',
50000.000,DEFAULT,DEFAULT,3),
('T00000003','C00000003','B00000001','S00000003','2008-12-01',
20000.000,DEFAULT,DEFAULT,1),
('T00000004','C00000001','B00000001','S00000005','2009-01-12',
102522.560,DEFAULT,DEFAULT,2),
('T00000005','C00000002','B00000001','S00000002','2010-01-20',
50000.000,DEFAULT,DEFAULT,4),
('T00000006','C00000003','B00000001','S00000004','2010-02-11',
20000.000,DEFAULT,DEFAULT,1); |
这里将两个基于列表达式的分区键的值指定为 DEFAULT, Big SQL 会根据前面定义的日期类型列的值自动通过表达式计算出这两个分区键对应的值。查看分区值是否计算正确。
清单 6. 查看数据示例
[bigsql] 1> SELECT T_id, T_time, P_year,
P_month, T_type FROM transaction_info ORDER BY T_id;
+---------+-----------+-------+--------+--------+
| T_ID | T_TIME | P_YEAR | P_MONTH | T_TYPE |
+--------+--------+-------+--------+-------+
| T00000001 | 2008-01-12 | 2008 | 1 | 1 |
| T00000002 | 2008-01-21 | 2008 | 1 | 3 |
| T00000003 | 2008-12-01 | 2008 | 12 | 1 |
| T00000004 | 2009-01-12 | 2009 | 1 | 2 |
| T00000005 | 2010-01-20 | 2010 | 1 | 4 |
| T00000006 | 2010-02-11 | 2010 | 2 | 1 |
+-------+---------+-------+--------+-------+
6 rows in results(first row: 0.252s; total: 0.254s) |
查看分区
那么在向 Hadoop 分区表中加载数据之后,用户如何查看分区信息呢?这里提供三种方法。
Big SQL SYSHADOOP.HCAT_COLUMNS 视图列出了通过 Hive Catalogs
定义的 Hadoop 表的各个列的定义信息,通过该视图也可以查看分区键的相关信息。
清单 7. 通过 SYSHADOOP.HCAT_COLUMNS 查看分区信息示例
[bigsql] 1> SELECT col_name,partition
FROM SYSHADOOP.HCAT_COLUMNS WHERE TABSCHEMA=
'BIGSQL' AND TABNAME='TRANSACTION_INFO';
+----------+-----------+
| COL_NAME | PARTITION |
+----------+-----------+
| t_id | N |
| c_id | N |
| b_id | N |
| s_id | N |
| t_time | N |
| t_money | N |
| p_year | Y |
| p_month | Y |
| t_type | Y |
+----------+-----------+
9 rows in results(first row: 0.056s; total: 0.057s) |
PARTITION 列的值可以是“Y”或“N”,“Y”表示对应的列是分区键,“N”则表示不是分区键。通过
SYSHADOOP.HCAT_COLUMNS 视图并不能查看到表中有多少个分区,下面两种方式则可以查看具体的分区情况。
前面讲到,在分布式文件系统上会按照各个分区键定义的顺序逐层生成对应的目录,每个分区的数据分别存储在对应的目录下。所以如果用户需要知道
Hadoop 分区表的分区信息,可以通过相关的 Hadoop 命令在 HDFS 上查看。
清单 8. 通过 Hadoop 命令查看分区信息示例
$ hadoop fs -ls /apps/hive/warehouse/bigsql.db/transaction_info
Found 3 items
drwxrwx--- -
bigsql hadoop 0 2016-05-08 06:33
/apps/hive/warehouse/bigsql.db/transaction_info/p_year=2008
drwxrwx--- -
bigsql hadoop 0 2016-05-08 06:33
/apps/hive/warehouse/bigsql.db/transaction_info/p_year=2009
drwxrwx--- -
bigsql hadoop 0 2016-05-08 06:33
/apps/hive/warehouse/bigsql.db/transaction_info/p_year=2010
$ hadoop fs -ls
/apps/hive/warehouse/bigsql.db/transaction_info/p_year=2008
Found 2 items
drwxrwx--- -
bigsql hadoop 0 2016-05-08 06:33
/apps/hive/warehouse/bigsql.db/transaction_info/p_year=2008
/p_month=1
drwxrwx--- - bigsql hadoop 0 2016-05-08 06:33
/apps/hive/warehouse/bigsql.db/transaction_info/p_year=2008
/p_month=12
$ hadoop fs -ls
/apps/hive/warehouse/bigsql.db/transaction_info/p_year=2008/
p_month=1
Found 2 items
drwxrwx--- - bigsql hadoop 0 2016-05-08 06:33
/apps/hive/warehouse/bigsql.db/transaction_info/p_year=2008
/p_month=1/t_type=1
drwxrwx--- - bigsql hadoop 0 2016-05-08 06:33
/apps/hive/warehouse/bigsql.db/transaction_info/p_year=2008
/p_month=1/t_type=3 |
这里可以很明显地看出 HDFS 上各个分区键的层次结构。其中 bigsql.db 中 bigsql 是所创建的
Hadoop 表的 Schema,缺省情况下默认使用创建该表的用户的用户名为 Schema。通过 Hadoop
命令在 HDFS 上逐层查看分区,有时候并不那么直观,那么能不能直接将所有的分区全部列出来呢?因为在 Big
SQL 中,Hadoop 表的实质是 Hive 表,所以我们也可以直接通过 Hive 命令来查看。
清单 9. 通过 Hive 查看分区信息示例
hive> SHOW PARTITIONS transaction_info;
OK
p_year=2008/p_month=1/t_type=1
p_year=2008/p_month=1/t_type=3
p_year=2008/p_month=12/t_type=1
p_year=2009/p_month=1/t_type=2
p_year=2010/p_month=1/t_type=4
p_year=2010/p_month=2/t_type=1
Time taken: 0.562 seconds, Fetched: 6 row(s) |
分区消除
创建和使用分区的目的之一就是希望在查询数据的时候通过适当的查询谓词来过滤掉一些分区,从而避免扫描所有数据,提高查询效率,这就是分区消除。在
Big SQL 4.2 中,分区消除有两个概念,除了一般意义上的分区消除,Big SQL 4.2 还引入了延时分区消除的概念,使得分区消除的适用场景更为广泛。
分区消除 (Partition Elimination) : Big SQL 根据分区策略和查询谓词,决定查询过程中过滤掉不必要扫描的分区。
延时分区消除 (Deferred Partition Elimination):通常在 Big SQL
中,早期当查询被注册的时候便可以决定过滤掉哪些分区,但在某些情况下,需要等到 Scan 打开以及查询工作被
Scheduler 部署到各个 Worker 节点之后,才能决定过滤掉哪些分区。
实现机制
对于以数据列本身作为分区键的 Hadoop 分区表,用户在查询时只需要在分区键上添加适当的查询谓词,Big
SQL 就可以实现分区消除。而对于以列表达式作为分区键的 Hadoop 分区表,如果表达式是通过单调函数定义的,当用户在原始数据列上添加了诸如<,
<=, >, >=, = 或 in 等查询谓词,或者表达式通过非单调的确定性函数定义,用户在原始数据列上添加了=
或 in 等查询谓词,Big SQL 会根据表达式在对应的分区键上生成一个派生的查询谓词来实现分区消除。
设计一个场景,用户需要查询所有交易类型为“存款”的历史信息。
清单 10. 查询场景 1
SELECT * FROM transaction_info WHERE T_type = 1; |
在上述查询中,当查询被注册时,优化器便可以根据查询谓词决定只需要扫描分区键 T_type 的值为 1 的分区,根据上面的分区情况可知,该场景下可以消除掉
1/2 的分区。
用户需要查询某个时间段的所有历史交易信息。
清单 11. 查询场景 2
SELECT * FROM transaction_info WHERE T_time <= '2008-12-12'; |
下面是通过相关命令查看到的在这个查询中 Big SQL 实际使用了哪些查询谓词。
清单 12. 查询场景 2 谓词
PREDICATE_TEXT
----------------------------------------
(Q1.P_YEAR <= 2008)
(Q1.T_TIME <= '12/12/2008')
2 record(s) selected. |
2 record(s) selected.
可以看到除了原始数据列上的查询谓词,Big SQL 还根据分区表达式在分区键 P_year 上生成了一个派生查询谓词。这里就有一个问题了,P_year
和 P_month 都是基于日期列 T_time 的表达式定义的,为什么这里只在 P_year 上生成了派生查询谓词?原因就是前面讲到的,YEAR()
基于年份是单调的,但是 MONTH() 基于月份却不能被认为是单调的。
再设计一个场景。现在用户需要查询一些不连续的年份里的历史交易信息,用户创建了一张表 filter_table_year,表中只有一个数据列
filter_col_year 用来保存需要过滤的年份。假设向表 filter_table_year 中插入了两个年份
2008 和 2009,查询如下。
清单 13. 查询场景 3
SELECT * FROM transaction_info t, filter_table_year f WHERE t.P_year=f.filter_col_year; |
同样先通过相关命令查看这个查询中的查询谓词。
清单 14. 查询场景 3 谓词
PREDICATE_TEXT
----------------------------------------
(Q2.P_YEAR <= $INTERNAL_FUNC$())
(Q2.P_YEAR = Q1.FILTER_COL_YEAR)
(Q2.P_YEAR >= $INTERNAL_FUNC$())
3 record(s) selected. |
在这个查询中同样生成了两个新的查询谓词,这实际上也是 Big SQL 4.2 的一个新特性,这里不做详细说明。其中函数
$INTERNAL_FUNC$() 实际上是用来计算来自表 filter_table_year 中参与连接的列
filter_col_year 的最大值和最小值的。通过计算出这两个值并添加到查询谓词上,就可以确定需要查找的分区范围,实现分区消除。但是
$INTERNAL_FUNC$() 的值需要等到 Scan 打开以及查询工作被 Scheduler 部署到各个
worker 节点之后才能被计算出来,所以称为延时分区消除。
查看分区消除
用户如何查看在一次查询中有没有发生分区消除以及消除了多少分区呢?在 Big SQL 中,用户可以通过 Scheduler
的日志文件来查看分区消除信息。
如果需要查看一个查询的分区消除信息,首先需要修改配置文件 '$BIGSQL_HOME/conf/log4j-sched.properties',通过去掉下列内容中的注释符
# 来设置 Debug 模式。
清单 15. 设置 Debug 模式
# log4j.logger.com.ibm=ALL |
然后重启 Big SQL Scheduler 使设置生效。
清单 16. 重启 Big SQL Scheduler
cd /usr/ibmpacks/bigsql/4.2.0.0/bigsql/bin;
./bigsql stop -scheduler;
./bigsql start -scheduler; |
设置完成之后,提交查询,分区消除信息就会被写入 '/var/ibm/bigsql/logs/bigsql-sched.log'
中。当然,更为简单的方法是,用户还可以通过命令来收集分区信息而不需要去日志文件中查找, 以前面查询场景
3 为例。
清单 17. 查看分区消除信息示例
$BIGSQL_HOME/libexec/sched internal resetDiagInfo 2>/dev/null;
db2 "SELECT * FROM transaction_info t,
filter_table_year f WHERE t.P_year=f.filter_col_year";
T_ID C_ID B_ID S_ID T_TIME
T_MONEY P_YEAR P_MONTH T_TYPE FILTER_COL_YEAR
------ ---------- ---------------------- -----------
T00000002 C00000002 B00000001 S00000002 01/21/2008 50000.000 2008 1 3 2008
T00000003 C00000003 B00000001 S00000003 12/01/2008 20000.000 2008 12 1 2008
T00000004 C00000001 B00000001 S00000005 01/12/2009 102522.560 2009 1 2 2009
T00000001 C00000001 B00000001 S00000001 01/12/2008 100000.000 2008 1 1 2008
4 record(s) selected.
$BIGSQL_HOME/libexec/sched internal getPartitionEliminationInfo 2>/dev/null;
SchemaName.TableName eliminated/total
bigsql.transaction_info 2/6
Aggregated Total: 2/6 |
上面示例中,第一个语句的作用是清空之前的分区消除日志信息,然后提交查询,接下来就可以通过第三个语句来收集分区消除信息了。根据收集到的信息可以看到,通过分区消除过滤掉了
6 个分区中的 2 个。
结束语
虽然设计分区表,通过分区消除可以过滤掉一些不需要扫描的分区,但这并不意味着任何时候都能带来查询性能的提升,用户需要根据实际的场景,合理地选择和使用
Big SQL Hadoop 表的分区功能。通常如果用户决定使用分区功能,在向 Hadoop 分区表中加载数据之后,用户可能需要运行
ANALYZE 命令来收集表中相关列的统计信息,帮助 Big SQL 优化器选择更优的访问方案。
|






