| 编辑推荐: |
本文以逻辑回归为例,介绍了基于Spark的分布式机器学习流程及其开发环境Zeppelin,希望对您的学习有所帮助。
本文来自于畅游DT时代 ,由火龙果软件Alice编辑、推荐。 |
|
一、 引言
众所周知,Spark是一款基于内存处理的分布式计算框架,能够实现流处理、SQL、机器学习、图计算等“一站式”的大数据分析。本公众号之前发表的《Spark调优101》和《Spark
GraphX分布式图计算实战》两篇文章中,介绍了Spark架构性能及图计算的相关能力。本文延续“实战”这一思路,详解如何借助Apache
Zeppelin交互式数据分析平台来构建Spark机器学习模型。
二、 Zeppelin简介
Apache Zeppelin是一款基于Web的交互式数据分析平台,默认使用Spark集群作为分析引擎,通过配置也支持包括SQL、Python、R等多种数据分析语言,提供数据库查询、动态图表展示、地图等数据可视化能力,并能够以Notebook的形式保存和分发代码及分析结果。从用户角度而言,Zeppelin提供了一种基于“数据流”的开发方式,数据分析师得以在同一个页面下依次完成数据引入-预处理-分析/建模-结果输出等一系列操作。详细介绍及部署方法请见其官网:http://zeppelin.apache.org/。
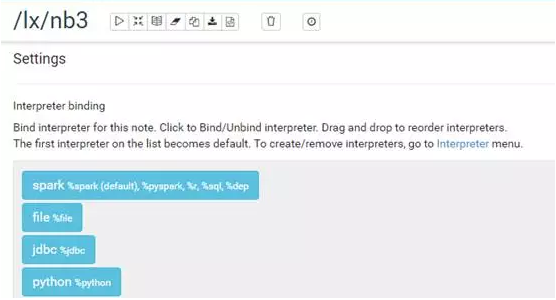
Zeppelin使用解释器(Interpreter)实现对各种语言的支持,在使用时须在对应的代码段上使用%加以注明。为便于数据进行机器学习,我们依次配置以下几个解释器:
%spark:默认解释器,由采用yarn-client模式部署的spark集群进行数据处理。
%file:HDFS命令解释器,用于直接访问存放在HDFS上的文件。
%jdbc:基于JDBC接口的SQL解释器,用于访问Hive或其他数据库。
%python:可调用各类python软件库,此处我们主要调用matplotlib进行作图。
三、 Spark机器学习流程概述
本节将简要介绍基于Spark机器学习(Machine Learning)的概念与流程。
熟悉机器学习的读者或多或少都了解过scikit-learn,这是一款使用Python的软件库,提供了丰富的机器学习模型和工具,但是受限于其单机计算能力往往无法直接应用在大数据集的模型训练上。Spark的机器学习模块(Spark
MLlib)在很多方面借鉴了scikit-learn的设计理念,在底层计算上遵循了Spark分布式计算框架,使其成为一款具备集群计算能力的机器学习架构。在Spark
ML中,模型训练用到的海量数据以分布式的结构存放在集群各节点的内存中,避免了机器学习算法的多次迭代过程中反复读写数据的步骤,从而极大提高了模型训练速度。在企业应用中,Spark
ML优势在于:可以直接对接大数据分析系统和数据仓库,读取存储在HDFS上的数据,甚至能够直接在流式处理(Spark
Streaming)中实时构建和使用机器学习模型。
Spark ML提供Scala、Python、Java和R四种语言的接口,本文主要使用原生的Scala
API进行介绍,使用其它语言可参照本文内容查阅技术文档。
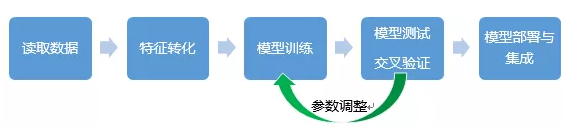
自1.6版本开始,Spark使用spark.ml作为其主要的机器学习库,使用DataFrame作为通用数据结构,用以存放样本、类型、特征向量、标签以及预测结果等各类数据;同时引入了Pipeline
概念来搭建完整的机器学习流。
DataFrame:提供了一种比RDD(弹性分布式数据集)更高层的分布式数据结构,可用于存放结构化数据,携带有列名和字段类型等结构信息(schema),类似传统数据库二维表,应用于Spark
SQL和Spark ML等组件中。
Transformer:在机器学习流程中用于将一个DataFrame(输入数据)转换成另一个DataFrame(输出数据)的函数都可称作是Transformer,包括特征提取、特征转化以及训练完成的机器学习模型等,重点在于“转化”。
Estimator:将一组输入数据(DataFrame)进行参数训练后(fit)生成机器学习模型(Transformer)的函数,例如特征归一化、逻辑回归算法等,重点在于“训练”。
Pipeline:一个包含多个Transformer和Estimator的机器学习工作流,例如对一组输入数据做多步特征提取、转换生成特征向量,再使用特征向量训练具体模型,最后将模型应用于测试数据,进行分类、预测等具体应用。
四、 构建逻辑回归模型
本节以逻辑回归为例,逐步详解使用Zeppelin和Spark机器学习模块构建机器学习模型的过程,包含数据集、代码、图表以及相关数学原理等内容,读者可自行寻找感兴趣的段落进行阅读。
软件版本:Zeppelin 0.6.0, Spark 1.6.1, Hadoop2.6.0
数据源介绍:UCI收入数据集(Adult Census Income),采集自1994年美国人口普查数据,可以从kaggle.com下载。本例中模型目的是根据数据集中的相关属性预测某个人的年收入是大于50K还是小于等于50K。这是一个二元分类问题(Binary
Classification),我们尝试使用逻辑回归(Logistic Regression)进行预测分类。数据集各项属性如下:
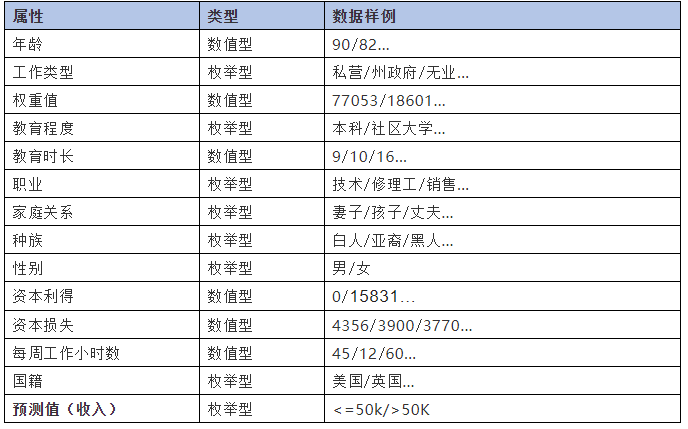
Step1:读取数据。我们在Zeppelin的代码框中输入%spark,表示接下来的代码需调用Spark进行计算。下面这段代码定义了数据结构,并按此结构从HDFS上读取相应的数据文件。
1. val customSchema
= StructType(Array(
2. StructField("age", FloatType,
true),
3. StructField("workclass", StringType,
true),
4. StructField("fnlwgt", FloatType,
true),
5. StructField("education", StringType,
true),
6. StructField("education_num", FloatType,
true),
7. StructField("marital_status",
StringType, true),
8. StructField("occupation", StringType,
true),
9. StructField("relationship", StringType,
true),
>10. StructField("race", StringType,
true),
11. StructField("sex", StringType,
true),
12. StructField("capital_gain", FloatType,
true),
13. StructField("capital_loss", FloatType,
true),
14. StructField("hours_per_week",
FloatType, true),
15. StructField("native_country",
StringType, true),
16. StructField("income", StringType,
true)))
17. //input data with specified data structure
18. val df = sqlContext.read.format("com.databricks.spark.csv").
option("header","true")
.option("quote","\"").
schema(customSchema).load("/user/luxin/adult.csv")
|
Spark读取到的结构化数据如下图所示:
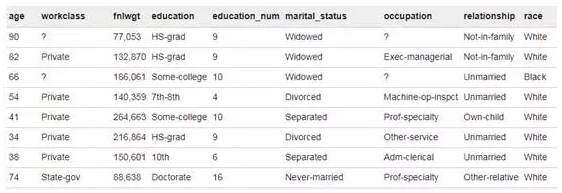
Step2:特征转化。我们知道,逻辑回归模型的输入都是数值型的数据,因此需要对数据集中的枚举类特征(例如教育程度属性中的“本科”、“高中”等值)进行赋值编码。此处使用Spark中的StringIndexer算子和OneHotEncoder算子。
1. //8 columns
transformed to numerical features
2. val categoricalColumns = Array("workclass",
"education",
"marital_status",
"occupation", "relationship",
"race", "sex", "native_country")
3. var stages = new ArrayBuffer[PipelineStage]
4.
5. for (categoricalCol<-categoricalColumns){
6. val stringIndexer = new StringIndexer()
7. .setInputCol(categoricalCol)
8. .setOutputCol(categoricalCol+"Index")
9. val encoder = new OneHotEncoder()
10. .setInputCol(categoricalCol+"Index")
11. .setOutputCol(categoricalCol+"Vec")
12. stages += (stringIndexer,encoder)
13. }
14. //convert column "income" into
"LABEL"
15. val label_stringIdx = new StringIndexer()
16. .setInputCol("income")
17. .setOutputCol("LABEL")
18. stages += label_stringIdx
19. //VectorAssembler
20. val numericalCols = Array("age",
"fnlwgt", "education_num",
"capital_gain", "capital_loss",
"hours_per_week")
21. val assembler = new VectorAssembler()
22. .setInputCols(categoricalColumns.map(p
=> p+"Vec") ++ numericalCols)
23. .setOutputCol("features")
24. stages += assembler
|
上述代码中,我们对原始数据中的8项枚举类属性进行转换,首先转换为编码序列(Index),再转化为二元向量(Vector),注意此处采用稀疏向量的表示方法。同样,我们对预测结果(收入是否大于50k)做编码,取值0和1,重命名为LABEL,如下图所示。最后,我们使用VectorAssembler算子将转换后的枚举类属性连同数值类属性共同构建成一个特征向量(Feature
Vector),特征向量的长度是所有属性的向量长度之和。
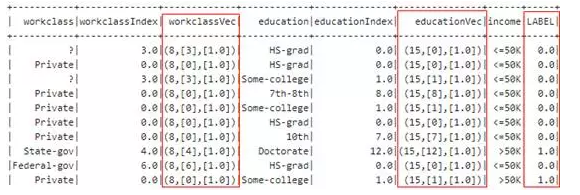
Step3:数据预处理Pipeline。上步中的各个特征转换算子都属于Spark机器学习中的Transformer,因此在上述特征向量的构建过程中,我们已经连续做了18次特征转化(8项属性分别作编码和向量转化,标签属性做1次编码,最后加上1次向量组合操作)。将这几个预处理步骤放在一个Pipeline中,构成一个完整的数据流处理,方便一次性调用。
1. val pipeline
= new Pipeline()
2. .setStages(stages.toArray)
3.
4. val pipelineModel = pipeline.fit(df)
5. val featuredData = pipelineModel.transform(df)
6. //splitdata into training and test sets
7. val splitDF = featuredData.randomSplit(Array(0.3,0.7),100L)
8. val trainDF = splitDF(0).cache()
9. val testDF = splitDF(1).cache() |
由以上经过转换的特征向量和已知的预测结果组成的数据,构成了线性回归模型的训练集(Training
Set)和测试集(Testing Set)。
Step4:逻辑回归模型训练。SparkML API已经封装了逻辑回归的训练函数LogisticRegression,调用函数对训练集数据进行拟合得到初步的模型,并使用这个模型对测试集数据进行预测,得到预测值(predication)。
1. val lr = new
LogisticRegression()
2. .setMaxIter(10)
3. .setLabelCol("LABEL")
4. .setFeaturesCol("features")
5. .setRegParam(0.3)
6. .setElasticNetParam(0.8)
7. //Train model with Training Data
8. val lrModel = lr.fit(trainDF)
9. //Make predictions on test data
10. val predictions = lrModel.transform(testDF)
|
为了解释上述参数的含义,此处对逻辑回归做一个回顾。逻辑回归的损失函数(Loss Function)可以表示为:
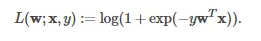
其中x为输入的特征向量;y取值-1或1,是二分类问题中的预测值(标签);w则是模型参数向量。逻辑回归建模的目的可以概括为:找到各个输入特征对应的权重系数(weights),由此构建的基于对率函数(logistic
function)的线性模型,用于对新输入的特征向量进行分类。
通常采用梯度下降法(GradientDescent)来寻找合适的参数向量:构建一个以权重向量w为变量的凸函数,通过迭代计算找到其全局最优点。这个函数称为目标函数(objective
function),具备以下形式:
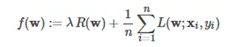
函数中的后半部分就是上述的损失函数的均值,其中n表示测试集的大小;而前半部分则是所谓的正则项(Regularizer),用于调整模型的复杂度,使其在过拟合(overfitting)和欠拟合(underfitting)之间找到平衡点,其中正则化系数λ
>0,控制正则项的权重。
在SparkML中,正则项函数R(w)采用弹性网方法(ElasticNet Method),它是另外两种正则化方法(即岭回归RidgeRegression和Lasso回归)的组合,定义如下:
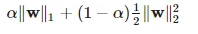
其中w1和w2分别称为L1范数和L2范数,而参数α控制着两者的重要性。L1范数是权重系数向量中各个元素绝对值之和,L2是各元素的平方和,两个范数正则化项都有助于降低过拟合风险,但L1范数更易获得“稀疏解”,使其求得的参数向量w具备更少的非零向量,以此去除更多的非相关特征,带来更优的特征选择。当α趋近于0时,模型接近于岭回归模型,当α趋近于1时,模型接近于Lasso回归模型,而当α取值在0到1之间时,模型兼具两类回归的优点。
回到我们的机器学习代码,其中设置了两个参数RegParam和 ElasticNetParam,正是对应着目标函数正则项中的参数λ和参数α。简言之,引入这两项参数可以有效避免训练出的模型出现过拟合的问题,同时降低模型的泛化误差(generalization
error)。而参数的具体取值需要通过后续步骤进一步确定。
Step5:模型评估。对于二分类问题,Spark ML提供BinaryClassificationEvalutor方法将训练出的模型应用于测试集数据进行对比评估,并可根据需求计算两类指标:ROC曲线面积和PR曲线面积。ROC曲线描绘了分类结果的“真正率”(TPR)和“假正率”(FPR)之间的关系,反映了机器学习模型的泛化能力;而PR曲线描绘了分类结果的“准确率”(precision)和“召回率”(recall)之间的关系。评估两个个模型的孰优孰劣可以通过比较ROC曲线面积或者PR曲线面积,面积较大则通常认为是一个更优的模型。此处我们选用ROC曲线面积对上述模型进行评估,得到结果areaUnderROC
= 0.5。
1. // use of
the BinaryClassificationEvaluator method to evaluate
our model.
2. val evalutor = new BinaryClassificationEvaluator()
3. .setRawPredictionCol("rawPrediction")
4. .setLabelCol("LABEL")
5. .setMetricName("areaUnderROC")
|
Step6:交叉验证(CrossValidation)。上述模型仅仅是由特定的训练集和模型训练参数(迭代次数、正则项参数等)得到的,在实际的机器学习过程中,我们需要调整参数和训练数据建立多套模型,通过比对多个模型测试结果的性能指标(如PR曲线面积或ROC曲线面积)来选择一个最优的模型。“k折交叉验证法”(k-fold
cross validation)就是这样一套评估方法:将数据集划分成k个大小相近的互斥子集,每次取k-1个子集进行训练并用余下的那个子集进行测试,最终返回这k个测试结果的均值。这样做的好处是最大限度地抹平了由于数据选择不均造成的泛化误差。
在SparkML中,交叉验证借助CrossValidator这一模型训练工具(Estimator的一种)实现。我们将希望进行比对的模型参数和交叉验证的k值输入CrossValidator,它会自动构建多个模型,计算并找到其中最优的参数组合。需要注意的是,这一操作开销巨大,因为函数需要计算所有可能的组合。下面代码中,我们分别为三个模型参数regParam,elasticNetParam和maxIter各自选定了3个候选值,并将交叉验证的k值设定为5,共需要训练(3*3*3)*5个模型并比较它们的性能。得到的最优模型的ROC曲线面积areaUnderROC
= 0.901,比之前的模型有了显著提升。
1. //Set ParamGrid
for Cross Validation
2. val paramGrid = new ParamGridBuilder()
3. .addGrid(lr.regParam, Array(0.01, 0.5, 2.0))
4. .addGrid(lr.elasticNetParam, Array(0.0,
0.5, 1.0))
5. .addGrid(lr.maxIter, Array(1, 5, 10))
6. .build()
7. //Set Estimator, Evalutor, paramGrid andFolds
for Cross Validator
8. val cv = new CrossValidator()
9. .setEstimator(lr)
10. .setEvaluator(evalutor)
11. .setEstimatorParamMaps(paramGrid)
12. .setNumFolds(5)
13.
14. val cvModel = cv.fit(trainDF)
15. val cvPredictions = cvModel.transform(testDF)
16. //evaluate the BEST(final) model
17. val cvAreaUnderROC = evalutor.evaluate(cvPredictions)
|
Step7: 使用最优模型对新数据做分类(预测)。我们采用全量数据集模拟新的输入数据。通过zeppelin的SQL查询能力(以%sql标注开始)对比预测结果与原始标签,可见大多数的预测结果是正确的,也存在着少许误差,该模型对目标数据集的预测准确率(accuracy)接近85%。考虑到机器学习的模型除了预测准确性外还要有很好的泛化性能(由ROC曲线描述),这里存在的预测误差是可以接受的。当然,我们可以通过选择其它模型(例如决策树decision
trees、boosting等)、参数调优或构建新的特征等方式进一步提高预测精度和泛化性能。

五、结语
截至目前,Spark机器学习模块支持逻辑回归、决策树、随机森林、SVM、朴素贝叶斯、线性回归、GBT、K-Means、LDA、GMM、协同过滤等学习算法以及多种特征转化和模型评估工具。使用SparkML快速构建并训练机器学习模型,而预测结果和ROC曲线、PR曲线等评估指标则通过Zeppelin直接呈现在网页页面上,方便数据科学家及时对模型修正和训练。这种交互式的模型开发方式极大地提高了机器学习过程中“训练-验证”循环的效率,也正是Spark
+ Zeppelin双剑合璧威力所在。
|






