| БрМЭЦМі: |
БОЮФжївЊНВНтСЫХзЦњжЎЧАДЋЭГЕФencoder-decoderФЃаЭБиаыНсКЯcnnЛђепrnnЕФЙЬгаФЃЪНЃЌжЛгУAttentionЁЃЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздЭјТчЃЌгЩЛ№СњЙћШэМўСѕшЁБрМЭЦМі |
|
ТлЮФзлЪіЃК
Attention Is All You NeedетЦЊТлЮФжївЊНщЩмСЫвЛжжаТЕФЛњЦїЗвыФЃаЭЃЌИУФЃаЭПЊДДадЕФЪЙгУСЫКмЖрШЋаТЕФМЦЫуФЃЪНКЭФЃаЭНсЙЙЁЃзлКЯЗжЮіСЫЯжгаЕФжїСїЕФnlpЗвыФЃаЭЕФМДЛљгкCNNЕФПЩВЂааЖдЦфЮФБОЗвыКЭЛљгкRNNЕФLSTMУХПиГЄЖЬЦкМЧвфЪБађЗвыФЃаЭЃЌзмНсСЫСНИіФЃаЭЕФгХШБЕуВЂдкДЫЛљДЁЩЯЬсГіСЫЛљгкздзЂвтСІЛњжЦЕФЗвыФЃаЭtransformerЃЌtransformerФЃаЭУЛгаЪЙгУCNNКЭRNNЕФЗНЗЈКЭФЃПщЃЌПЊДДадЕФНЋзЂвтСІЛњжЦзїЮЊБрНтТыЦїЕФКЫаФЙЙНЈжДааЗвыВйзїЁЃ
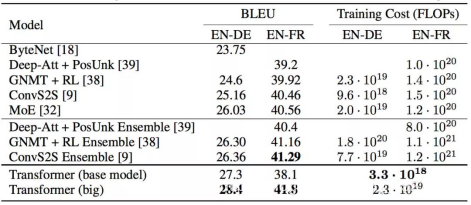
зюжеИУФЃаЭдкЭГвЛгябдЪ§ОнМЏЯТШЁЕУСЫзюМбЕФbleuжЕЃЌШЁЕУСЫЗвыФЃаЭжаЕФзюгХНсЙћЁЃtransformerФЃаЭЕФЬсГіВЛНіНіЬсЩ§СЫЯжНзЖЮЛњЦїЗвыЕФзМШЗТЪЃЌЛЙЮЊздШЛгябдДІРэЕФЦфЫћСьгђЙБЯзСЫШЋаТЕФНтОіЗНАИЃЌЛљгкtransformerФЃаЭЕФencoderНсЙЙДДдьГіСЫnlpСьгђЛљгкЮФБОдЄДІРэФЃаЭЕФвЛДѓЩёЦїBERTФЃаЭЁЃЛљгкBERTФЃаЭздШЛгкбЧДІРэЕФЦфЫћЗНУцвВШЁЕУСЫГЄзуЕФНјВНЁЃ
здДгAttentionЛњжЦдкЬсГіжЎКѓЃЌМгШыAttentionЕФSeq2SeqФЃаЭдкИїИіШЮЮёЩЯЖМгаСЫЬсЩ§ЃЌЫљвдЯждкЕФseq2seqФЃаЭжИЕФЖМЪЧНсКЯrnnКЭattentionЕФФЃаЭЁЃДЋЭГЕФЛљгкRNNЕФSeq2SeqФЃаЭФбвдДІРэГЄађСаЕФОфзгЃЌЮоЗЈЪЕЯжВЂааЃЌВЂЧвУцСйЖдЦыЕФЮЪЬтЁЃЕЋЪЧвРОЩЪеЕНвЛаЉЧБдкЮЪЬтЕФжЦдМЃЌЩёОЭјТчашвЊФмЙЛНЋдДгяОфЕФЫљгаБивЊаХЯЂбЙЫѕГЩЙЬЖЈГЄЖШЕФЯђСПЁЃетПЩФмЪЙЕУЩёОЭјТчФбвдгІИЖГЄЪБМфЕФОфзгЃЌЬиБ№ЪЧФЧаЉБШбЕСЗгяСЯПтжаЕФОфзгИќГЄЕФОфзгЃЛУПИіЪБМфВНЕФЪфГіашвЊвРРЕгкЧАУцЪБМфВНЕФЪфГіЃЌетЪЙЕУФЃаЭУЛгаАьЗЈВЂааЃЌаЇТЪЕЭЃЛШдШЛУцСйЖдЦыЮЪЬтЁЃ
дйШЛКѓCNNгЩМЦЫуЛњЪгОѕвВБЛв§ШыЕНdeep NLPжаЃЌCNNВЛФмжБНггУгкДІРэБфГЄЕФађСабљБОЕЋПЩвдЪЕЯжВЂааМЦЫуЁЃЭъШЋЛљгкCNNЕФSeq2SeqФЃаЭЫфШЛПЩвдВЂааЪЕЯжЃЌЕЋЗЧГЃеМФкДцЃЌКмЖрЕФtrickЃЌДѓЪ§ОнСПЩЯВЮЪ§ЕїећВЂВЛШнвзЁЃ
БОЦЊЮФеТДДаТЕудкгкХзЦњСЫжЎЧАДЋЭГЕФencoder-decoderФЃаЭБиаыНсКЯcnnЛђепrnnЕФЙЬгаФЃЪНЃЌжЛгУAttentionЁЃЮФеТЕФжївЊФПЕФдкгкМѕЩйМЦЫуСПКЭЬсИпВЂаааЇТЪЕФЭЌЪБВЛЫ№КІзюжеЕФЪЕбщНсЙћЁЃ
жївЊФкШнЃК
attentionЛњжЦЕФЛљБОИХФюЃК
attentionЕФЖЈвхЃК
AttentionгУгкМЦЫу"ЯрЙиГЬЖШ"ЃЌР§ШчдкЗвыЙ§ГЬжаЃЌВЛЭЌЕФгЂЮФЖджаЮФЕФвРРЕГЬЖШВЛЭЌЃЌAttentionЭЈГЃПЩвдНјааШчЯТУшЪіЃЌБэЪОЮЊНЋquery(Q)КЭkey-value pairsгГЩфЕНЪфГіЩЯЃЌЦфжаqueryЁЂУПИіkeyЁЂУПИіvalueЖМЪЧЯђСПЃЌЪфГіЪЧVжаЫљгаvaluesЕФМгШЈЃЌЦфжаШЈжиЪЧгЩQueryКЭУПИіkeyМЦЫуГіРДЕФЃЌМЦЫуЗНЗЈЗжЮЊШ§ВНЃК
ЕквЛВНЃКМЦЫуБШНЯQКЭKЕФЯрЫЦЖШЃЌгУfРДБэЪОЃК
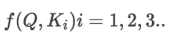
ЕкЖўВНЃКНЋЕУЕНЕФЯрЫЦЖШНјааSoftmaxВйзїЃЌНјааЙщвЛЛЏЃК
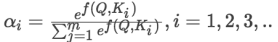
ЕкШ§ВНЃКеыЖдМЦЫуГіРДЕФШЈжиЃЌЖдVжаЫљгаЕФvaluesНјааМгШЈЧѓКЭМЦЫуЃЌЕУЕНAttentionЯђСПЃК
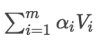
дкБОФЃаЭжаQКЭKЕФКЏЪ§МЦЫуЪЧЪЙгУЕуЛ§ЕФЗНЪНЃЌвВПЩвдЪЙгУЯрМгСЊНсЕШеыЖдЯђСПЕФВйзїЃЌдкетРяЪЙгУЕуЛ§дкгіЕНДѓЙцФЃЕФЯђСПЪБдЫЫуЕФаЇТЪЛсБШВЩгУЯрМгзЂвтСІЛњжЦИпЃЌЕЋЕуЛ§ВйзїЛсЪЙЕУЫуЗЈЕФПеМфаЇТЪИпЃЌЕБУцЖдДѓЙцФЃЯђСПЕФЪБКђЛсГ§вдвЛИіИНМгЯюРДЗХЫѕдЫЫуНсЙћетбљПЩвдМЋДѓГЬЖШЩЯЬсЩ§ЪеСВЫйЖШЁЃ
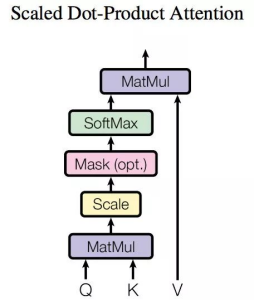
ЩЯЭМеЙЪОСЫМЦЫуattentionЕФЛљБОЙ§ГЬЃЌЦфжаЕФmaskВйзїеыЖдгыdecoderЕФself-attentionЛњжЦЃЌгЩгкдкЩњГЩНзЖЮЫљвдетРяЕФattentionМЦЫужЛФмЫуЕБЧАЕЅДЪжЎЧАЕФжЕЃЌВЛФмЙЛЖюЭтЕФМЦЫужЎКѓЕФattentionЕФжЕЃЌЦфЫћЕФдЫЫуЖМЪЧЛљгкQKVШ§ИіЯђСПЁЃ
Ъ§ОндЄДІРэЃК
дкздШЛгябдДІРэжаЮЊСЫдЫЫуКЭБэЪОЕФЗНБуетРяЛсв§ШыДЪБрТыЬхЯЕword embeddingЃЌвЛАуВЩгУword2vecФЃаЭЃЌОЙ§етИіФЃаЭИїжжгябдЕФЕЅДЪНЋЛсзЊТыЮЊвЛИіЙЬЖЈГЄЖШЕФЯђСПЃЌВЂЧвЯрЫЦЛђгаЙиСЊЕФЕЅДЪЛсЗЧГЃЕФНгНќЁЃШчЯТЭМЕФР§згЫљЪОЃК
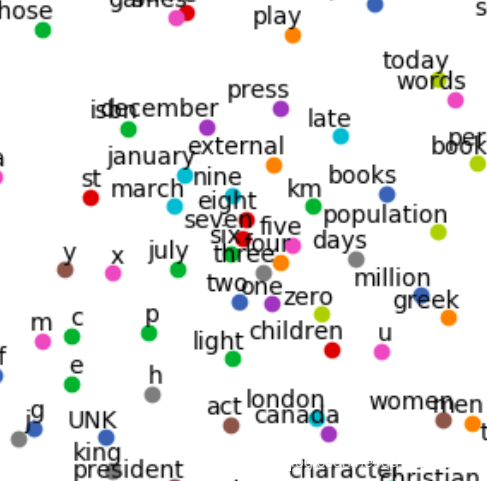
ПЩвдПДЕНЪ§зжМЏжадквЛЦ№ЁЃетРяЕФПЩЪгЛЏДЪЯђСПОЙ§СЫНЕЮЌЃЌдкБОЩэЮЌЖШЯТећИіЕЅДЪЬхЯЕЕФЛЎЗжЛсБэЯжЕФИќМгЭъУРЁЃ
НЋДЪБрТыЪфШыФЃаЭЃЌФЃаЭЪзЯШЭЈЙ§ЯпадБфЛЏзЊЛЏГі3ИіЯђСПвВОЭЪЧжЎЧАЫЕЕФQKVЯђСПЃЌНгЯТРДЭъГЩЩЯЪіattentionЛњжЦЕФдЫЫуКѓНЋНсЙћгыVЯђСПМгШЈЧѓКЭЃЌЕУЕНетИіЕЅДЪЛљгкећИіОфзгЦфЫћЕЅДЪЕФattentionЯђСПЁЃ
Multi-Head Attention
Multi-Head AttentionОЭЪЧАбScaled Dot-Product AttentionЕФЙ§ГЬзіHДЮЃЌШЛКѓАбЪфГіZКЯЦ№РДЁЃТлЮФжаЃЌЫќЕФНсЙЙЭМШчЯТЃК
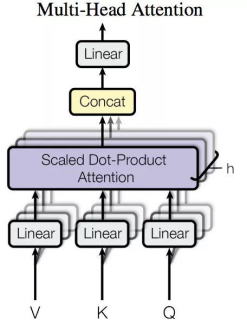
ЦфНсЙЙОЭЪЧНЋQKVЯђСПОЙ§ЯпадБфЛЏзЊЛЏЮЊВЛЭЌЕФЯђСПЃЌНЋЖрДЮЕуЛ§attentionВЂааЭЌЪБМЦЫуЃЌНЋНсЙћСЊНсЮЊвЛИіОиеѓЁЃЦфФПЕФЪЧЮЊСЫОЁПЩФмЖрЕФШЅБэеїОфзгЕФгявхЙиЯЕЃЌбЇЯАЕНОЁПЩФмЖрЕФгявхБэДяЃЌЦфВйзїЕФЙ§ГЬгааЉРрЫЦгкОэЛ§ВйзїЃЌЪЧЬиеїЬсШЁЕФвЛжжЗНЪНЁЃ
TransformerФЃаЭЕФНсЙЙЃК
2.1ЁЂPosition EmbeddingЮЛжУБрТыЃК
гЩгкФЃаЭУЛгаЪЙгУОэЛ§ВйзїКЭЛљгкЪБађЕФRNNФЃаЭЃЌЫљвдФЃаЭЮоЗЈбЇЯАЕНОфзгЕФађСаЙиЯЕЃЌетНЋЪЙЕУетИіФЃаЭжЛЪЧвЛИіДЪДќЃЌЕЅДЪдкОфзгжаЕФЮЛжУВЂВЛЛсЖдattentionМЦЫуЕФНсЙћВњЩњШЮКЮгАЯьЁЃЮЊСЫдкФЃаЭжадіМгЮЛжУБрТыЕФаХЯЂЃЌв§ШыСЫЮЛжУБрТыЛњжЦЁЃ
етРяУПИіЗжДЪЕФposition embeddingЯђСПЮЌЖШвВЪЧ , ШЛКѓНЋдБОЕФinput embeddingКЭposition embeddingМгЦ№РДзщГЩзюжеЕФembeddingзїЮЊencoder/decoderЕФЪфШыЁЃЦфжаposition embeddingМЦЫуЙЋЪНШчЯТЃК
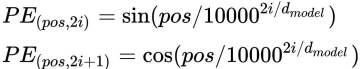
ЙЋЪНжа pos БэЪОЮЛжУindexЃЌ i БэЪОdimension indexЁЃ
Position EmbeddingБОЩэЪЧвЛИіОјЖдЮЛжУЕФаХЯЂЃЌЕЋдкгябджаЃЌЯрЖдЮЛжУвВКмживЊЃЌGoogleбЁдёЧАЪіЕФЮЛжУЯђСПЙЋЪНЕФвЛИіживЊдвђЪЧЃЌгЩгкЮвУЧгаЃК

етБэУїЮЛжУp+kЕФЯђСППЩвдБэЪОГЩЮЛжУpЕФЯђСПЕФЯпадБфЛЛЃЌетЬсЙЉСЫБэДяЯрЖдЮЛжУаХЯЂЕФПЩФмадЁЃ
2.2ЁЂPosition-wise Feed-forward NetworksЧАРЁЭјТчШЋСЌНг
дкНјааСЫAttentionВйзїжЎКѓЃЌencoderКЭdecoderжаЕФУПвЛВуЖМАќКЌСЫвЛИіШЋСЌНгЧАЯђЭјТчЃЌЖдУПИіpositionЕФЯђСПЗжБ№НјааЯрЭЌЕФВйзїЃЌАќРЈСНИіЯпадБфЛЛКЭвЛИіReLUМЄЛюЪфГіЃК
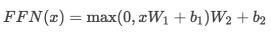
ЦфжаУПвЛВуЕФВЮЪ§ЖМВЛЭЌЁЃ
2.3ЁЂEncoderБрТыЦї
БрТыЦїдкtransformerФЃаЭжавЛЙВ6ВуЃЌЦфжаУПВугаСНИізгВуЁЃ
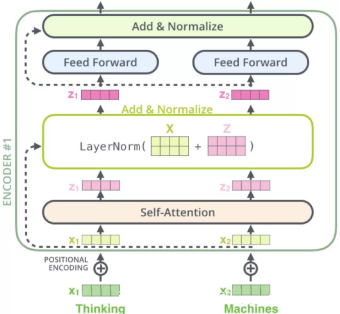
ЕквЛИізгВуЪЧmulti-head self-attention mechanismЃЌгУРДМЦЫуЪфШыЕФself-attentionЁЃ
ЕкЖўИізгВуЪЧМђЕЅЕФШЋСЌНгЭјТчЁЃдкУПИіsub-layerЮвУЧЖМФЃаЭСЫВаВюЭјТчЃЌУПИіsub-layerЕФЪфГіЖМЪЧЃК
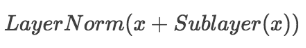
2.4ЁЂDecoderНтТыЦї
НтТыЦїдкtransformerФЃаЭжавВЪЧ6ВуЃЌЕЋНтТыЦїгаШ§ИізгВуЃК
ЕквЛИіЪЧMasked multi-head self-attentionЃЌвВЪЧМЦЫуЪфШыЕФself-attentionЃЌЕЋЪЧвђЮЊЪЧЩњГЩЙ§ГЬЃЌвђДЫдкЪБПЬ i ЕФЪБКђЃЌДѓгк i ЕФЪБПЬЖМУЛгаНсЙћЃЌжЛгааЁгк i ЕФЪБПЬгаНсЙћЃЌвђДЫашвЊзіMask
ЕкЖўИіsub-layerЪЧШЋСЌНгЭјТчЃЌгыEncoderЯрЭЌ
ЕкШ§Иіsub-layerЪЧЖдencoderЕФЪфШыНјааattentionМЦЫуЁЃ
ЭЌЪБDecoderжаЕФself-attentionВуашвЊНјаааоИФЃЌвђЮЊжЛФмЛёШЁЕНЕБЧАЪБПЬжЎЧАЕФЪфШыЃЌвђДЫжЛЖдЪБПЬ t жЎЧАЕФЪБПЬЪфШыНјааattentionМЦЫуЃЌетвВГЦЮЊMaskВйзїЁЃ
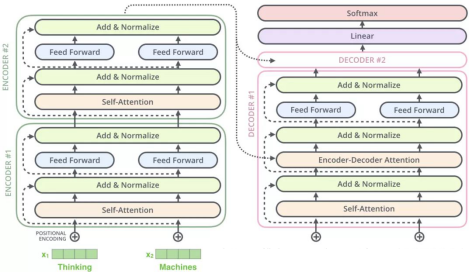
2.5ЁЂThe Final Linear and Softmax LayerШЋСЌНгЪфГіВу
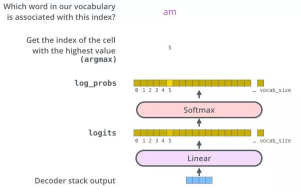
НЋDecoderЕФЖбеЛЪфГізїЮЊЪфШыЃЌДгЕзВППЊЪМЃЌзюжеНјааwordдЄВтЁЃ
ЪЕбщНсЙћгыНсТлЃК
змЬхЖјбдtransformerФЃаЭдкИїЯюЪ§ОнМЏЩЯЖМШЁЕУСЫМАЦфГіЩЋЕФНсЙћЃЌbleuжЕЖМДДдьСЫаТЕФМЧТМЁЃОЭФЃаЭЖјбдЃЌtransformerМАЦфГіЩЋЕФНтОіСЫСЫГЄОрРывРРЕЁЃ
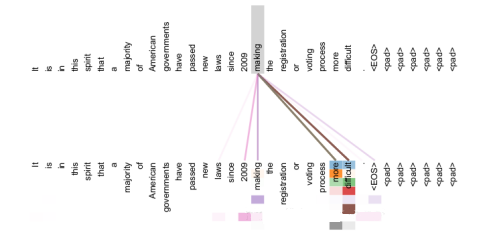
ПЩвдПДГіздзЂвтСІЛњжЦбЇЕНСЫmake...more difficultетИіЖЬгяЁЃ
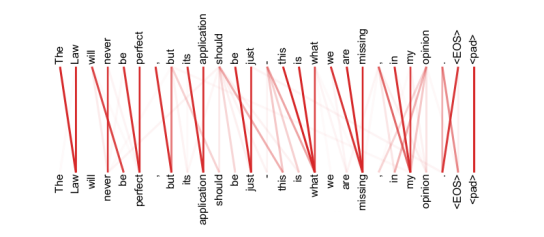
ПЩвдПДЕНздзЂвтСІЛњжЦКмКУЕФбЇЯАЕНСЫОфзгЕФгявхЙиЯЕКЭгяЗЈНсЙЙЁЃ
змНсгыЗжЮі
етЦЊТлЮФжївЊНщЩмСЫЛљгкздзЂвтСІЛњжЦЕФtransformerЛњЦїЗвыФЃаЭЁЃетИіФЃаЭзюДѓЕФЬиЕудкгыаТгБЕФФЃаЭНсЙЙКЭЧАЮРЕФдЫЫуММЧЩЃЌНЋattentionЛњжЦдЫгУЕНСЫМЋжТЁЃдкШЫФдЗвыЕФЙ§ГЬжавВЪЧЛљгкДЪвтЁЂДЪадвдМАОфзгЕФНсЙЙРДЗвыЁЃгЩДЫПЩвдЗЂЯжattentionЛњжЦКЭШЫФдЕФЗвыЙ§ГЬЗЧГЃЕФРраЭЁЃЮвУЧдкфЏРРвЛИіД§ЗвыЕФОфзгЪБЫфШЛвЊЫГађдФЖСЃЌЕЋећИіОфзгЕФЫљгаЕЅДЪЖМдкЮвУЧЕФеЦПижЎжаЃЌЩѕжСгааЉЪБКђЮвУЧПЩвдКіТдвЛаЉНсЙЙевЕНОфзгЕФжїИЩГЩЗжЁЃФЧУДЛљгкетИіЬиеїRNNЕФЗвыЙ§ГЬгЩгкЙ§гквРРЕЧАвЛИіЕЅДЪвдМАLSTMЖдгкЙ§ГЄОфзгЕФаХЯЂЖЊЪЇОЭЯдЕУВЂВЛЗћКЯШЫЕФЩњРэЬиеїЁЃ
ЫфШЛtransformerдкЗвыЩЯБэЯжЪЎЗжЧРблЕЋЫќЪЧЗЧЭМСщЭъБИЕФЃЌдкКмЖрМђЕЅЕФзжЗћДІРэСьгђВЂУЛгавЛаЉМђЕЅЕФЛљДЁФЃаЭБэЯжГіЩЋЃЌР§ШчзжЗћДЎЕФИДжЦЕШВйзїЁЃЕЋЙШИшДѓФдЭХЖгеыЖдетИіЮЪЬтЬсГіСЫЩ§МЖАцЕФtransformerФЃаЭUniversal TransformerЁЃUniversal Transformer КЭ Transformer вЛбљЕивЛДЮЭЌЪБДІРэЫљгаЕФЗћКХЃЌЕЋ Universal Transformer НгЯТРДЛсИљОнздЮвзЂвтСІЛњжЦЖдУПИіЗћКХЕФНтЪЭзіЪ§ДЮВЂааЕФбЛЗДІРэаоЪЮЁЃUniversal Transformer жаЪБМфВЂааЕФбЛЗЛњжЦВЛНіБШ RNN жаЪЙгУЕФДЎаабЛЗЫйЖШИќПьЃЌвВШУ Universal Transformer БШБъзМЕФЧАРЁ Transformer ИќМгЧПДѓЁЃUniversal TransformerгжНЋЗвыжЪСПbleuЬсЩ§СЫ0.9вВОЭЪЧЬсЩ§СЫ50%ЁЃ
TransformerФЃаЭЕФЬсГіВЛНіНіЮЊЛњЦїЗвыДДдьСЫИеКУЕФНтОіЗНАИЛљгкencoderФЃПщЕФЖбЕўЙШИшДѓФдЭХЖггжЬсГіСЫвЛжжШЋаТЕФЮФБОдЄДІРэФЃаЭBERTЁЃвдBERTФЃаЭЮЊдЄДІРэФЃаЭЩшМЦГіЕФ11ИіФЃаЭдкnlpЕФ11ИіСьгђШЋВПЫЂаТСЫзюМбЕФГЩМЈЁЃПЩМћtransformerЪЧвЛИіПЊДДадЕФФЃаЭЁЃ
ЯюФПВтЪд
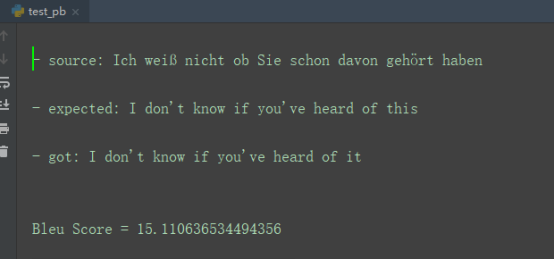
еыЖдtransformerФЃаЭЕФЯюФПдДТыЮвНјааСЫЛљБОЕФВтЪдЁЃе§жЕвЛИіе§дкНјааЕФРыЯпЗвыЕФЯюФПЃЌЮвЛљгкtransformerХмГіСЫвЛаЉФЃаЭВЂЖдФЃаЭНјааСЫМєжІСПЛЏбЙЫѕЕШВйзїВЂЭъГЩСЫАВзПЖЫвЦжЕЁЃВтЪдЕФЙ§ГЬжаЮвЗЂЯжtransformФЃаЭЗЧГЃвРРЕСМКУЕФбЕСЗЪ§ОнМЏЁЃ
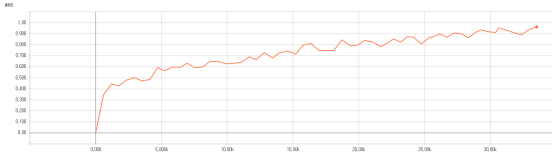
ВтЪдЪБЕФе§ШЗТЪзпЪЦ
зюжеЕУЕНЕФckptФЃаЭгыЮвзЊЛЛЕФpbФЃаЭЁЃ
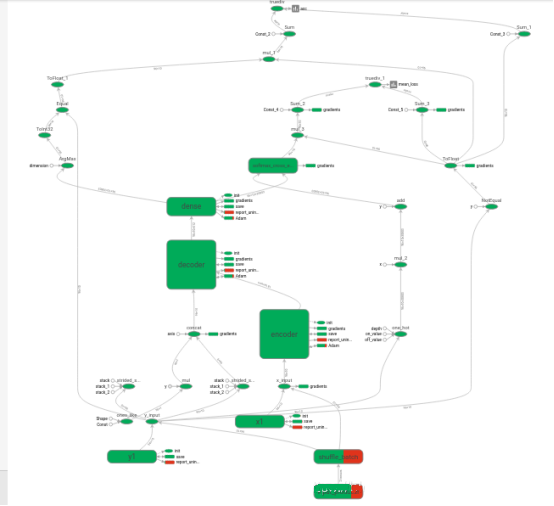
transformerФЃаЭЕФЯюФПНсЙЙЭМЃЈTensorBoardВщПДЕФЃЉ
|






