| БрМЭЦМі: |
БОЮФРДздгкbiaodianfuЃЌЮФеТНщЩмСЫдкаЁГЬађЖЫЃЌЪЙгУЬкбЖдЦдЦжЧAIгІгУЗўЮёРДНјааШЫСГЪЖБ№МьВтЗжЮіЃЌЪЕЯжШЫСГЪЖБ№ЕШЙІФмЁЃ |
|
ЪВУДЪЧK-НќСкЫуЗЈЃП
KНќСкЗЈ(k-nearest neighbor, k-NN)ЪЧ1967ФъгЩCover TКЭHart
PЬсГіЕФвЛжжЛљБОЗжРргыЛиЙщЗНЗЈЁЃЫќЕФЙЄзїдРэЪЧЃКДцдквЛИібљБОЪ§ОнМЏКЯЃЌвВГЦзїЮЊбЕСЗбљБОМЏЃЌВЂЧвбљБОМЏжаУПИіЪ§ОнЖМДцдкБъЧЉЃЌМДЮвУЧжЊЕРбљБОМЏжаУПвЛИіЪ§ОнгыЫљЪєЗжРрЕФЖдгІЙиЯЕЁЃЪфШыУЛгаБъЧЉЕФаТЪ§ОнКѓЃЌНЋаТЕФЪ§ОнЕФУПИіЬиеїгыбљБОМЏжаЪ§ОнЖдгІЕФЬиеїНјааБШНЯЃЌШЛКѓЫуЗЈЬсШЁбљБОзюЯрЫЦЪ§Он(зюНќСк)ЕФЗжРрБъЧЉЁЃвЛАуРДЫЕЃЌЮвУЧжЛбЁдёбљБОЪ§ОнМЏжаЧАkИізюЯрЫЦЕФЪ§ОнЃЌетОЭЪЧk-НќСкЫуЗЈжаkЕФГіДІЃЌЭЈГЃkЪЧВЛДѓгк20ЕФећЪ§ЁЃ
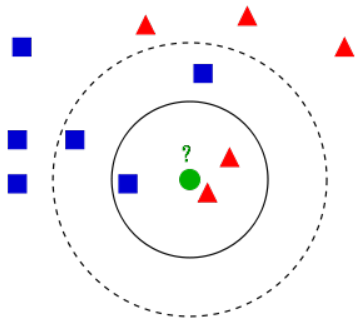
kНќСкЫуЗЈР§згЁЃВтЪдбљБОЃЈТЬЩЋдВаЮЃЉгІЙщШывЊУДЪЧЕквЛРрЕФРЖЩЋЗНаЮЛђЪЧЕкЖўРрЕФКьЩЋШ§НЧаЮЁЃШчЙћk=3ЃЈЪЕЯпдВШІЃЉЫќБЛЗжХфИјЕкЖўРрЃЌвђЮЊга2ИіШ§НЧаЮКЭжЛга1Иіе§ЗНаЮдкФкВрдВШІжЎФкЁЃШчЙћk=5ЃЈащЯпдВШІЃЉЫќБЛЗжХфЕНЕквЛРрЃЈ3Иіе§ЗНаЮгы2ИіШ§НЧаЮдкЭтВрдВШІжЎФкЃЉЁЃ
ШчЩЯЫљЪіЃЌетРяKжЕЕФДѓаЁПЩвдШЮвтЩшЖЈЃЈЕБK=1ЪБЃЌГЦЫуЗЈЮЊзюНќСкЫуЗЈЃЉЃЌЕЋЪЧkжЕЕФбЁдёЛсЖдKNNЕФНсЙћВњЩњжиДѓгАЯьЃЌвђДЫKжЕЕФбЁдёОпгаМЋЦфживЊЕФвтвхЁЃ
ЕБбЁдёЕФKжЕНЯаЁЪБЃЌгУгкдЄВтЕФбЕСЗЪ§ОнМЏдђНЯаЁЃЌДЫЪБНќЫЦЮѓВюЛсМѕаЁЃЌЕЋЪЧЦфЙРМЦЮѓВюЛсдіДѓЃЌдЄВтНсЙћЖдНќСкЕФЪЕР§ЕуЗЧГЃУєИаЁЃШєДЫЪБНќСкЕФЪЕР§ЕуЪЧдыЩљЃЌдЄВтОЭЛсГіДэЁЃ
ЕБбЁдёЕФKжЕНЯДѓЪБЃЌгУгкдЄВтЕФбЕСЗЪ§ОнМЏдђНЯДѓЃЌДЫЪБЙРМЦЮѓВюЛсМѕаЁЃЌЕЋЪЧЦфНќЫЦЮѓВюгжЛсдіДѓЃЌДЫЪБгыЪфШыЪЕР§НЯдЖ(ВЛЯрЫЦ)ЕФЪЕР§вВЛсЖддЄВтЦ№зїгУЃЌЪЙдЄВтЗЂЩњДэЮѓЁЃ
дкЪЕМЪЕФгІгУжаЃЌЭЈГЃЛсбЁдёНЯаЁЕФKжЕЁЃгЩгкKжЕаЁЪБвтЮЖзХећЬхЕФФЃаЭБфЕУИДдгЃЌШнвзаЮГЩЙ§ФтКЯЃЌвђДЫЭЈГЃВЩгУНЛВцбщжЄЕФЗНЪНбЁдёзюгХЕФKжЕЁЃ
KNNЫуЗЈЕФгХШБЕу
гХЕуЃКОЋЖШИпЁЂЖдвьГЃжЕВЛУєИаЁЂЮоЪ§ОнЪфШыМйЖЈ
ШБЕуЃКМЦЫуИДдгЖШИпЁЂПеМфИДдгЖШИпЃЈдкИпЮЌЧщПіЯТЃЌЛсгіЕНЁКЮЌЪ§джФбЁЛЕФЮЪЬтЃЉ
KNNЫуЗЈШ§вЊЫи
KNNЫуЗЈЮвУЧжївЊПМТЧШ§ИіживЊЕФвЊЫиЃЌЖдгкЙЬЖЈЕФбЕСЗМЏЃЌжЛвЊетШ§ЕуШЗЖЈСЫЃЌЫуЗЈЕФдЄВтЗНЪНвВОЭОіЖЈСЫЁЃетШ§ИізюжеЕФвЊЫиОрРыЖШСПЁЂ
kжЕЕФбЁдёКЭЗжРрОіВпЙцдђОіЖЈЁЃ
ОрРыЖШСП
ЬиеїПеМфжаСНИіЪЕР§ЕуЕФОрРыЪЧСНИіЪЕР§ЕуЯрЫЦГЬЖШЕФЗДгГЁЃkНќСкФЃаЭЕФЬиеїПеМфвЛАуЪЧnЮЌЪЕЪ§ЯђСППеМф ЃЌЪЙгУЕФОрРыЪЧвЛАуЪЧХЗЪНОрРыЃЌвВПЩвдЪЧЦфЫћОрРыЁЃгЩВЛЭЌЕФОрРыЖШСПЫљШЗЖЈЕФзюНќСкЕуЪЧВЛЭЌЕФЁЃ
KжЕЕФбЁдё
kжЕЕФДѓаЁОіЖЈСЫСкгђЕФДѓаЁЁЃНЯаЁЕФkжЕЪЙЕУдЄВтНсЙћЖдНќСкЕФЕуЗЧГЃУєИаЃЌШчЙћНќСкЕФЕуЧЁКУЪЧдыЩљЃЌдђдЄВтБуЛсГіДэЁЃЛАОфЛАЫЕЃЌkжЕЕФМѕаЁвтЮЖзХећЬхФЃаЭБфЕУИДдгЃЌШнвзЗЂЩњЙ§ФтКЯЁЃНЯДѓЕФkжЕЛсШУЪфШыЪЕР§жаНЯдЖЕФЃЈВЛЯрЫЦЕФЃЉбЕСЗЪЕР§ЖддЄВтЦ№зїгУЃЌЪЙдЄВтЗЂЩњДэЮѓЃЌkжЕЕФдіДѓвтЮЖзХећЬхФЃаЭБфЕУМђЕЅЁЃдкЪЕМЪЕФгІгУжаЃЌвЛАуВЩгУвЛИіБШНЯаЁЕФKжЕЁЃВЂВЩгУНЛВцбщжЄЕФЗНЗЈЃЌбЁШЁвЛИізюгХЕФKжЕЁЃвЛИіМЋЖЫЪЧkЕШгкбљБОЪ§mЃЌдђЭъШЋУЛгаЗжРрЃЌДЫЪБЮоТлЪфШыЪЕР§ЪЧЪВУДЃЌЖМжЛЪЧМђЕЅЕФдЄВтЫќЪєгкдкбЕСЗЪЕР§жазюЖрЕФРрЃЌФЃаЭЙ§гкМђЕЅЁЃ
ЗжРрОіВпЙцдђОіЖЈ
kНќСкЗЈжаЕФЗжРрЙцдђЭљЭљЪЧЖрЪ§БэОіЃЌМДгЩЪфШыЪЕР§ЕФkИіНќСкЕФбЕСЗЪЕР§жаЕФЖрЪ§РрОіЖЈЪфШыЕФЪЕР§ЁЃЕЋетИіЙцдђДцдквЛИіЧБдкЕФЮЪЬтЃКгаПЩФмЖрИіРрБ№ЕФЭЖЦБЪ§ЭЌЮЊзюИпЁЃетИіЪБКђЃЌПЩвдЭЈЙ§вдЯТМИИіЭООЖНтОіИУЮЪЬтЃК
ДгЭЖЦБЪ§ЯрЭЌЕФзюИпРрБ№жаЫцЛњЕибЁдёвЛИіЃЛ
ЭЈЙ§ОрРыРДНјвЛВНИјЦБЪ§МгШЈЃЛ
МѕЩйKЕФИіЪ§ЃЌжБЕНевЕНвЛИіЮЈвЛЕФзюИпЦБЪ§БъЧЉЁЃ
НќСкЫуЗЈжаЕФЗжРрОіВпЖрВЩгУЖрЪ§БэОіЕФЗНЗЈНјааЁЃЫќЕШМлгкбАЧѓОбщЗчЯезюаЁЛЏЁЃ
K-НќСкЫуЗЈЕФЪЕЯж
ЯпадЩЈУш
KNNЕФзюМђЕЅЦгЫиЕФЗНЗЈМДжБНгЯпадЩЈУшЃЌДѓжТВНжшШчЯТЃК
МЦЫуД§дЄВтЪ§ОнгыИїбЕСЗбљБОжЎМфЕФОрРы
АДееОрРыЕндіХХађ
бЁдёОрРызюаЁЕФkИіЕу
МЦЫуетkИіЕуРрБ№ЕФЦЕТЪЃЌзюИпЕФМДЮЊД§дЄВтЪ§ОнЕФРрБ№ЁЃ
import math
from collections import defaultdict
class KNN(object):
def __init__(self, k=2):
self.data = None
self.k = k
@staticmethod
def distance(p1, p2):
x1, y1 = p1
x2, y2 = p2
x_ = x2 - x1
y_ = y2 - y1
return math.sqrt(x_ ** 2 + y_ ** 2)
def fit(self, X, y):
self.data = dict(zip(X, y))
def predict(self, point):
distances = {}
for p, _ in self.data.items():
distances[p] = self.distance(p, point)
sort_distances = dict(sorted(distances.items(),
key=lambda x: x[1]))
topk = defaultdict(int)
for idx, (p, v) in enumerate(sort_distances.items()):
if idx == self.k - 1:
break
topk[self.data[p]] += 1
topk = sorted(topk.items(), key=lambda x: -x[1])
return topk[0][0]
if __name__ == '__main__':
points = [(1, 1), (1, 1.2), (0, 0), (0, 0.2),
(3, 0.5), (3.3, 0.9)]
labels = ['A', 'A', 'B', 'B', 'C', 'C']
knn = KNN()
knn.fit(points, labels)
label = knn.predict((0.9, 0.7))
print(label) |
KDЪї
ЯпадЩЈУшЗЧГЃКФЪБЃЌЮЊСЫЬсИпkНќСкЫбЫїЕФаЇТЪЃЌПЩвдПМТЧЪЙгУЬиЪтЕФНсЙЙДцДЂбЕСЗЪ§ОнЃЌвдМѕЩйМЦЫуОрРыЕФДЮЪ§ЁЃkdЪїЪЧвЛжжЖдkЮЌПеМфЕФЪЕР§ЕуНјааДцДЂвдБуЖдЦфНјааПьЫйМьЫїЕФЪїаЮЪ§ОнНсЙЙЁЃkdЪїЪЧЖўВцЪїЃЌБэЪОЖдkЮЌПеМфЕФвЛИіЛЎЗж(partition)ЃЌЙЙдьkdЪїЯрЕБгкВЛЖЯгУДЙжБгкзјБъжсЕФГЌЦНУцНЋkЮЌПеМфЧаЗжЃЌЙЙГЩвЛЯЕСаЕФkЮЌГЌОиаЮЧјгђЁЃkdЪїжаЕФУПИіНкЕуЖдгІвЛИіkЮЌГЌОиаЮЧјгђЁЃ
KDЪї(k-dimensional tree)ЃЌвВПЩГЦжЎЮЊKЮЌЪїЃЌПЩвдгУИќИпЕФаЇТЪРДЖдПеМфНјааЛЎЗжЃЌВЂЧвЦфНсЙЙЗЧГЃЪЪКЯбАевзюНќСкОгКЭХізВМьВтЁЃЖдгк2ЮЌПеМфЃЌKDЪїПЩГЦЮЊ2DЪїЃЌвђЮЊПеМфжЛгаСНИізјБъжсЃЛЖдгк3ЮЌПеМфЃЌKDЪїПЩГЦЮЊ3DЪїЃЌПеМфжагаШ§ИізјБъжсЃЛвдДЫРрЭЦЁЃ
ЖдгкВЛЭЌЮЌЖШЕФПеМфЃЌKDЪїЕФЙЙНЈЫМТЗЭъШЋвЛжТЁЃЯТУцвдЖўЮЌПеМфЮЊР§ЁЃKDЪїЕФБОжЪЪЧвЛИіЖўВцЪїЃЌМДвЛИіИљНкЕуЃЌЛЎЗжЮЊзѓзгЪїКЭгвзгЪїЁЃЫљвдKDЪїЕФЙЙНЈЮоЗЧЪЧСНИіЮЪЬтЃКИљНкЕуЕФбЁдёЃЌзѓгвзгЪїЕФЛЎЗжЙцдђЁЃ
вдЯТЪЧKDЪїЕФЙЙНЈЙ§ГЬЁЃ
бЁЖЈвЛИіжсЃЌБШШчXжсЃЌбЁдёетИіжсЩЯЕФжаЮЛЪ§ЕФЫљдкЕуЮЊИљНкЕу
ЫљгаXБШжаЮЛЪ§XаЁЕФЃЌЖМЛЎЗжЮЊзѓзгЪїЃЛЗДжЎЃЌдђЛЎЗжЮЊгвзгЪї
ЖдгкзѓгвСНИізгЪїЃЌжиИДЕквЛВНЃЌЕЋЪЧашвЊАбЛЎЗжжсЛЛГЩСэЭтвЛИіжсЃЈYЃЉМЬај
жиИДвдЩЯЙ§ГЬЃЌжБЕНЫљгаЕуЖММгШыKDЪїжа
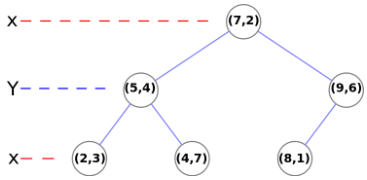
вдЩЯЭМОйР§ЃЌЕквЛВНЖдXжсНјааЛЎЗжЃЌЕу(7,2)ЕФXзјБъ7ЮЊЫљгаXзјБъЕФжаЮЛЪ§ЃЌЦфБЛШЗСЂЮЊИљНкЕуЃЛXзјБъБШ7аЁЕФЕу(5,4)ЁЂ(2,3)ЁЂ(4,7)БЛЛЎЗжЕНзѓзгЪїЃЛXзјБъБШ7ДѓЕФЕу(9,6)ЁЂ(8,1)БЛЛЎЗжЕНгвзгЪїЁЃЖдгкзѓзгЪї(5,4)ЁЂ(2,3)ЁЂ(4,7)ЃЌЖдЫќУЧЕФYжсНјааЛЎЗжЃЌЕу(5,4)ЕФYзјБъ4ЮЊЫљгазѓзгЪїЕФYзјБъЕФжаЮЛЪ§ЃЌЦфБЛШЗСЂЮЊзѓзгЪїЕФИљНкЕуЃЛYзјБъБШ4аЁЕФЕу(2,3)БЛЛЎЗжЮЊзѓзгЪїЃЛYзјБъБШ4ДѓЕФЕу(4,7)БЛЛЎЗжЮЊгвзгЪїЁЃЖдгкгвзгЪї(9,6)ЁЂ(8,1)ЃЌКЭзѓзгЪїЭЌРэЃЌвВЪЧЖдYжсНјааЛЎЗжЁЃДЫЪБЫљгаЕуЖМвбОМгШыЕНKDЪїжаЃЌДДНЈНсЪјЁЃ
вЛИіжБЙлЕФРэНтЪЧЃЌДДНЈЗНЪНПДЦ№РДгаЕуЯёЖдПеМфКсзнЧаЕАИтЕФЗНЪНЃЌЖдгк2DПеМфЃЌЕквЛЕЖбизХXжсНЋПеМфЛЎЗжЮЊСНАыЃЌЕкЖўЕЖгжбизХYжсЗжБ№НЋвбОЛЎЗжКУЕФСНАыдйЛЎЗжЮЊСНАыЃЌЕкШ§ЕЖгжМЬајбизХXжсНјааЛЎЗжЁЁжБЕНЫљгаЕуЖМТфШыKDЪїжаЁЃЖдгк3DПеМфЃЌдђЪЧбизХX->Y->Z->XДЫРрЕФбЛЗвРДЮЖдПеМфНјааЖдАыЗжИюЁЃЃЈОіЖЈдкФФИіЮЌЖШЩЯНјааЗжИюЪЧгЩЫљгаЪ§ОндкИїИіЮЌЖШЕФЗНВюОіЖЈЕФЃЌЗНВюдНДѓЫЕУїИУЮЌЖШЩЯЕФЪ§ОнВЈЖЏдНДѓЃЌИќгІИУдйИУЮЌЖШЩЯЖдЕуНјааЛЎЗжЁЃР§ШчxЮЌЖШЗНВюНЯДѓЃЌЫљвдвдxЮЌЖШЗНЯђЛЎЗжЁЃЃЉ
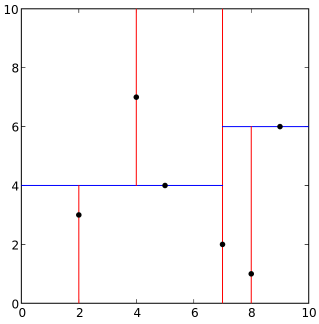
ЙЙНЈЭъвЛПХKD-TREEжЎКѓЃЌШчКЮЪЙгУЫќРДзіKNNМьЫїФиЃПгУЯТУцЕФ20sЕФGIFЖЏЛРДБэЪОЃК
вдЯТЪЧбАевзюНќСкОгЫуЗЈЕФУшЪіЃК
НЈСЂвЛИіПеЕФеЛS
ЖдгкИјЖЈЕФВщбЏЕуPЃЌбизХИљНкЕуБщРњећИіKDЪїЃЌжБЕНВЛФмдйБщРњЮЊжЙЃЌНЋУПИіБщРњЕФЕуЖМШыеЛЃЈPushЃЉ
БщРњЕФЙ§ГЬЗЧГЃМђЕЅЃЌЖдгкKDЪїжаЕФЕуКЭетИіЕуЕФЛЎЗжзјБъЃЌШчЙћВщбЏЕуБШетИіЕуЕФЛЎЗжзјБъДѓЃЌдђМЬајБщРњетИіЕуЕФгвзгЪїЃЌЗёдђБщРњетИіЕуЕФзѓзгЪї
ШєеЛЗЧПеЃЌПЊЪМбЛЗЃЌЩшзюСкНќОрРыЮЊЮоЧюДѓ
НЋеЛЖЅЕФЕуPЕЏГіЃЈPopЃЉЃЌМЦЫуВщбЏЕугыжЎЕФОрРыDistЃЌШчЙћDistаЁгкзюСкНќОрРыЃЌдђИќаТзюНќСкОрРыЮЊDistЃЌЭЌЪБИќаТзюСкНќЕуЮЊP
ХаЖЯЕуPЕФЛЎЗжжсЃЌШєВщбЏЕуЕНЛЎЗжжсЕФОрРыаЁгкзюНќСкОрРыЃЌдђЫЕУїдкЛЎЗжжсЕФСэЭтвЛВрЛЙПЩФмДцдкИќСкНќЕФЕуЃЌашвЊдкЛЎЗжжсЕФСэвЛВрЕФИљНкЕудйжДаавЛДЮБщРњЃЌНЋУПИіБщРњЕФЕуЖМШыеЛЃЈPushЃЉ
ШєеЛЮЊПеЃЌдђжежЙбЛЗЃЌЗЕЛиНсЙћ
вдЩЯЫуЗЈгУЕНСЫеЛРДФЃФтЕнЙщЃЌБмУтСЫЕнЙщЕФКЏЪ§ЩюВуЕїгУКЭЗЕЛиЕФПЊЯњЁЃ
KDЪїжЎЫљвдШчДЫИпаЇЕФдвђдкгкЕкСљВНЃЌвВОЭЪЧМєжІЁЃШчЩЯЭМЫљЪОЃЌдквбОЫбЫїЕНBЪБЃЌЗЂЯжЦфЕНBЕФОрРыЃЌвЊБШЕНAЕФгвзгЪїЕФЦНУцОрРыЛЙИќЖЬЃЌЫљвдећИіAЕФгвзгЪїЖМБЛМєжІЃЌвЛЯТзгМєШЅСЫвЛАыЕФЕуЁЃ
# -*- coding:
utf-8 -*-
import math
from collections import defaultdict
class KNN(object):
def __init__(self, topk=3):
self.data = None
self.store = {}
self.topk = topk
def build_kdtree(self, points, depth=0):
n = len(points)
if n <= 0: # ШчЙћЕБЧАзгПеМфвбОУЛгаЕуСЫдђЙЙНЈЙ§ГЬНсЪј
return None
axis = depth % 2 # МЦЫуЕБЧАбЁдёЕФзјБъжс
sorted_points = sorted(points, key=lambda point:
point[axis]) # ЖдЕБЧАзгПеМфЕФЕуИљОнЕБЧАбЁдёжсЕФжЕНјааХХађ
median = n // 2 # жаЮЛЪ§ШЁХХађКѓзјБъЕуЕФжаМфЮЛжУЕФЪ§
return {
'point': sorted_points[median], # ЕБЧАИљНсЕу
'left': self.build_kdtree(sorted_points[:median],
depth + 1), # НЋГЌЦНУцзѓБпЕФЕуНЛгЩзѓзгНсЕуЕнЙщВйзї
'right': self.build_kdtree(sorted_points[median
+ 1:], depth + 1) # ЭЌРэЃЌНЋГЌЦНУцгвБпЕФЕуНЛгЩгвзгНсЕуЕнЙщВйзї
}
@staticmethod
def distance(p1, p2):
if p1 is None or p2 is None:
return 0
x1, y1 = p1
x2, y2 = p2
x_ = x2 - x1
y_ = y2 - y1
return math.sqrt(x_ ** 2 + y_ ** 2)
def closer_distance(self, point, p1, p2):
d1 = self.distance(point, p1)
d2 = self.distance(point, p2)
if p1 is None:
return (p2, d2)
if p2 is None:
return (p1, d1)
return (p1, d1) if d1 < d2 else (p2, d2)
def kdtree_closest_point(self, root, point, depth=0):
if root is None:
return None
axis = depth % 2
next_branch = None
opposite_branch = None
# вдЯТжївЊЪЧБШНЯЕБЧАЕуЕНИљНсЕуКЭСНИізгНсЕужЎМфЕФОрРы
if point[axis] < root['point'][axis]:
next_branch = root['left']
opposite_branch = root['right']
else:
next_branch = root['right']
opposite_branch = root['left']
best, closer_dist = self.closer_distance(
point,
self.kdtree_closest_point(
next_branch,
point,
depth + 1),
root['point']
)
if self.distance(point, best) > abs(point[axis]
- root['point'][axis]):
best, closer_dist = self.closer_distance(
point,
self.kdtree_closest_point(
opposite_branch,
point,
depth + 1),
best
)
# ДЂДцОрРыЃЌСєзїЭЖЦБгУ
if best in self.store and self.store[best] >
closer_dist:
self.store[best] = closer_dist
else:
self.store[best] = closer_dist
return best
def fit(self, X, y):
self.data = dict(zip(X, y))
self.kdtree = self.build_kdtree(X)
def predict(self, point):
# best ЪЧзюСкНќЕФЕу
best = self.kdtree_closest_point(self.kdtree,
point)
sorted_stores = sorted(self.store.items(), key=lambda
x: x[1])[:self.topk]
counter = defaultdict(int)
for candidates, score in sorted_stores:
counter[self.data[candidates]] += 1
# АДееЭЖЦБЪ§НЕађХХСа
sorted_counter = sorted(counter.items(), key=lambda
x: -x[1])
counter = list(counter.items())
if len(counter) > 1:
if counter[0][1] != counter[1][1]:
best = counter[0][1]
return self.data[best]
if __name__ == '__main__':
points = [(1, 1), (1, 1.2), (0, 0), (0, 0.2),
(3, 0.5), (3.3, 0.9)]
labels = ['A', 'A', 'B', 'B', 'C', 'C']
knn = KNN(topk=3)
knn.fit(points, labels)
label = knn.predict((0.9, 0.9))
print(label) |
|






